Prometheus 一文带你搞懂标签label的作用_prometheus label-程序员宅基地
技术标签: Prometheus prometheus
标签管理
标签的作用
不同的标签代表不同的时间序列,即通过指定标签查询指定数据。
指标+标签实现了查询条件的作用,可以指定不同的标签过滤不同的数据
Metadata标签

在抓取被监控端就会带上这些标签,这些标签就是声明要采集谁,协议是什么,以及暴露的接口是谁
一般来说元标签只是普罗米修斯去使用,我们一般不会让其做什么事情,并且这些标签是不会写到数据库当中的,使用promql是查询不到这些标签的,因为这些标签只是普罗米修斯内部去使用的,不会存储在时序数据库供我们查询
自定义标签
可以自定义标签,有了这些标签可以针对特定的标签去查询,比如根据机房,或者项目查询某些机器
添加的标签越多,查询的维度越细
- job_name: 'BJ Linux Server'
basic_auth:
username: prometheus
password: 123456
static_configs:
- targets: ['192.168.179.99:9100']
labels:
idc: tongniu
project: www
- job_name: 'Shanghai Linux Server'
basic_auth:
username: prometheus
password: 123456
static_configs:
- targets: ['192.168.179.99:9100']
labels:
idc: sss
project: blog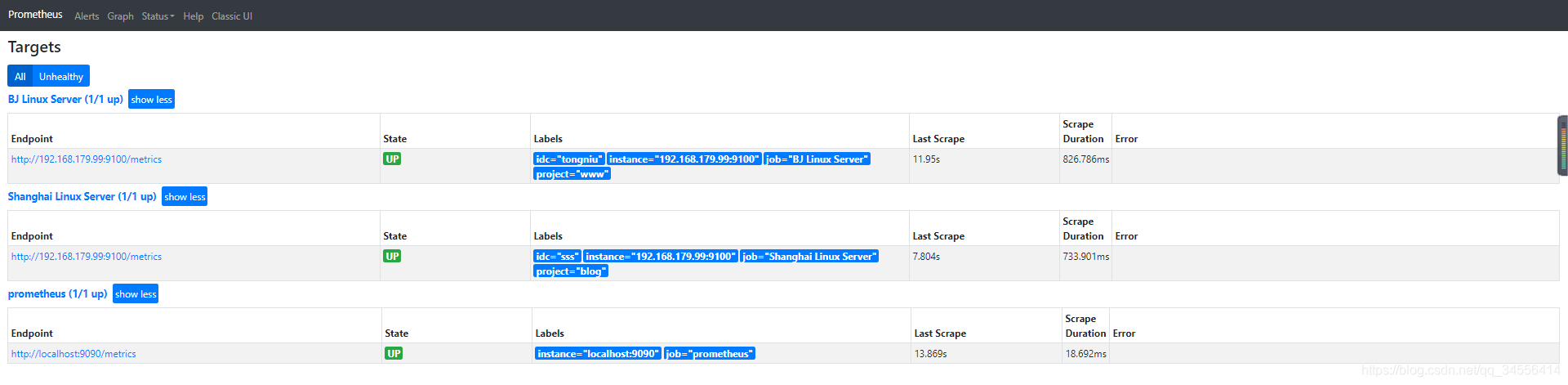
可以看到基于自定义标签实现多维度的查询

重新标记标签
重新标记目的:为了更好的标识监控指标。

重新标记标签一般用途:
• 动态生成新标签 根据已有的标签生成新标签
• 过滤采集的Target
• 删除不需要或者敏感标签
• 添加新标签
action:重新标记标签动作
• replace:默认,通过regex匹配source_label的值,使用replacement来引用表达式匹配的分组,分组使用$1,$2...引用(正则匹配,提取字段重新创建新标签,注意这里是创建新的标签)
• keep:删除regex与连接不匹配的目标 source_labels , keep drop就是让普罗米修斯采集和不采集哪些目标
• drop:删除regex与连接匹配的目标 source_labels
• labeldrop:删除regex匹配的标签
• labelkeep:删除regex不匹配的标签
• labelmap:匹配regex所有标签名称,并将捕获的内容分组,用第一个分组内容作为新的标签名(使用正则提取出多个字段,使用匹配到的作为新标签名,但是标签的内容不会改变,相对于对原有标签换了个名字)
重新标记标签:重命名标签
场景1:动态生成添加标签(对已有的标签重新标记)
- job_name: 'Linux Server'
basic_auth:
username: prometheus
password: 123456
static_configs:
- targets: ['192.168.179.99:9100']
metric_relabel_configs:
- action: replace
source_labels: ["instance"]
regex: (.*):([0-9]+) # 正则匹配标签值,( )分组
replacement: $1 # 引用分组匹配的内容
target_label: "ip"可以看到该标签已经进入数据库里面了,这样就根据源标签通过正则匹配动态生成了新的标签

重新标记标签:过滤Target
- job_name: 'Linux Server'
basic_auth:
username: prometheus
password: 123456
static_configs:
- targets: ['192.168.179.99:9100']
relabel_configs:
- action: drop
regex: "192.168.179.99:9100" # 正则匹配标签值
source_labels: ["_address_"]在target里面就没有了,在普罗米修斯里面就看不到该台机器,同时exporter也不会被停止,这样就完成过滤目标需求
重新标记标签:删除标签
有些标签不希望被存储上,那么可以使用 labeldrop:删除regex匹配的标签去完成不需要入库 将里面的标签删除掉,在入库之前删除
- job_name: 'Linux Server'
basic_auth:
username: prometheus
password: 123456
static_configs:
- targets: ['192.168.179.99:9100']
relabel_configs:
- action: labeldrop
regex: "job" #正则匹配标签名称可以看到job标签被删除

总结以及普罗米修斯监控K8S标签案例
标签的作用
- 可以基于已有的标签,生成一个标签
- 也可以创建新的标签
- 还可以过滤标签,不想采集哪些
- 哪些标签不要了也可以将其删除
keep
Keep只有匹配的才会去采集数据,不匹配的就不采集。下面意思就是pod当中有些注解中声明了prometheus_io_scrape这个字段,那么就会把你纳入监控,如果没有声明就不会纳入监控。也就是k8s当中部署了这么多pod,谁要监控,谁不要被监控,在部署service可以指定是否需要采集,如果需要采集需要在注解当中声明prometheus_io_scrape: true
在service 和pod里面声明配置注解,那么就会采集注解里面含有这个值的
annotations:
prometheus.io/scrape: 'true'# Service没配置注解prometheus.io/scrape的不采集
- action: keep
regex: true
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_scrape
replace
处理监控pod连接的ip地址,api接口,还有协议都需要重新标记默认的字段
# 重命名采集目标协议
- action: replace
regex: (https?)
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_scheme
target_label: __scheme__
# 重命名采集目标指标URL路径
- action: replace
regex: (.+)
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_path
target_label: __metrics_path__
# 重命名采集目标地址
- action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
source_labels:
- __address__
- __meta_kubernetes_service_annotation_prometheus_io_port
target_label: __address__
这里就可以使用新的标签kubernetes_namespace在promql里面基于命名空间这个标签去查询了,因为 __meta_kubernetes_namespace这个标签是不会被存储的
# 生成命名空间标签
- action: replace
source_labels:
- __meta_kubernetes_namespace
target_label: kubernetes_namespace实际访问指标接口 https://NodeIP:10250/metrics/cadvisor 这个接口只能APISERVER访问,故此重新标记标签使用APISERVER代理访问
这个就是直接指定标签的值,也就是将采集的地址换为我指定的地址
# 修改NodeIP:10250为APIServerIP:6443
- action: replace
regex: (.*)
source_labels: ["__address__"] 源标签配匹为address
target_label: __address__
replacement: 192.168.31.61:6443labelmap
做上面这些事情是有两个阶段的,一个是采集之前,一个是采集之后,如果在采集之前重新定义标签没生效,那么可以使用采集之后的标签(因为使用的是k8s的服务发现,不管用的是哪个服务发现,默认带的都是源标签__meta_kubernetes_node_label 比如consul那么就是以consul开头的,这些不同服务发现的标签就是为了新标签的生成,就是为了更加好的标识监控指标,源标签是不会入库的)
relabel_configs:
# 将标签(.*)作为新标签名,原有值不变(新的标签名字会被入库查询)
- action: labelmap
regex: __meta_kubernetes_node_label_(.*) (.*) ,以其开头所有值匹配到,用这个匹配的值作为新的标签名字,新的标签名字就可以入库,就会被查询,因为元标签以下划线开头的是不会入库的,后面是用不了的/这样做的目的就是将后面(.*)匹配的值作为一个新标签,并且将原有值赋予新标签,后面可以基于这个新标签查询数据了
智能推荐
攻防世界_难度8_happy_puzzle_攻防世界困难模式攻略图文-程序员宅基地
文章浏览阅读645次。这个肯定是末尾的IDAT了,因为IDAT必须要满了才会开始一下个IDAT,这个明显就是末尾的IDAT了。,对应下面的create_head()代码。,对应下面的create_tail()代码。不要考虑爆破,我已经试了一下,太多情况了。题目来源:UNCTF。_攻防世界困难模式攻略图文
达梦数据库的导出(备份)、导入_达梦数据库导入导出-程序员宅基地
文章浏览阅读2.9k次,点赞3次,收藏10次。偶尔会用到,记录、分享。1. 数据库导出1.1 切换到dmdba用户su - dmdba1.2 进入达梦数据库安装路径的bin目录,执行导库操作 导出语句:./dexp cwy_init/[email protected]:5236 file=cwy_init.dmp log=cwy_init_exp.log 注释: cwy_init/init_123..._达梦数据库导入导出
js引入kindeditor富文本编辑器的使用_kindeditor.js-程序员宅基地
文章浏览阅读1.9k次。1. 在官网上下载KindEditor文件,可以删掉不需要要到的jsp,asp,asp.net和php文件夹。接着把文件夹放到项目文件目录下。2. 修改html文件,在页面引入js文件:<script type="text/javascript" src="./kindeditor/kindeditor-all.js"></script><script type="text/javascript" src="./kindeditor/lang/zh-CN.js"_kindeditor.js
STM32学习过程记录11——基于STM32G431CBU6硬件SPI+DMA的高效WS2812B控制方法-程序员宅基地
文章浏览阅读2.3k次,点赞6次,收藏14次。SPI的详情简介不必赘述。假设我们通过SPI发送0xAA,我们的数据线就会变为10101010,通过修改不同的内容,即可修改SPI中0和1的持续时间。比如0xF0即为前半周期为高电平,后半周期为低电平的状态。在SPI的通信模式中,CPHA配置会影响该实验,下图展示了不同采样位置的SPI时序图[1]。CPOL = 0,CPHA = 1:CLK空闲状态 = 低电平,数据在下降沿采样,并在上升沿移出CPOL = 0,CPHA = 0:CLK空闲状态 = 低电平,数据在上升沿采样,并在下降沿移出。_stm32g431cbu6
计算机网络-数据链路层_接收方收到链路层数据后,使用crc检验后,余数为0,说明链路层的传输时可靠传输-程序员宅基地
文章浏览阅读1.2k次,点赞2次,收藏8次。数据链路层习题自测问题1.数据链路(即逻辑链路)与链路(即物理链路)有何区别?“电路接通了”与”数据链路接通了”的区别何在?2.数据链路层中的链路控制包括哪些功能?试讨论数据链路层做成可靠的链路层有哪些优点和缺点。3.网络适配器的作用是什么?网络适配器工作在哪一层?4.数据链路层的三个基本问题(帧定界、透明传输和差错检测)为什么都必须加以解决?5.如果在数据链路层不进行帧定界,会发生什么问题?6.PPP协议的主要特点是什么?为什么PPP不使用帧的编号?PPP适用于什么情况?为什么PPP协议不_接收方收到链路层数据后,使用crc检验后,余数为0,说明链路层的传输时可靠传输
软件测试工程师移民加拿大_无证移民,未受过软件工程师的教育(第1部分)-程序员宅基地
文章浏览阅读587次。软件测试工程师移民加拿大 无证移民,未受过软件工程师的教育(第1部分) (Undocumented Immigrant With No Education to Software Engineer(Part 1))Before I start, I want you to please bear with me on the way I write, I have very little gen...
随便推点
Thinkpad X250 secure boot failed 启动失败问题解决_安装完系统提示secureboot failure-程序员宅基地
文章浏览阅读304次。Thinkpad X250笔记本电脑,装的是FreeBSD,进入BIOS修改虚拟化配置(其后可能是误设置了安全开机),保存退出后系统无法启动,显示:secure boot failed ,把自己惊出一身冷汗,因为这台笔记本刚好还没开始做备份.....根据错误提示,到bios里面去找相关配置,在Security里面找到了Secure Boot选项,发现果然被设置为Enabled,将其修改为Disabled ,再开机,终于正常启动了。_安装完系统提示secureboot failure
C++如何做字符串分割(5种方法)_c++ 字符串分割-程序员宅基地
文章浏览阅读10w+次,点赞93次,收藏352次。1、用strtok函数进行字符串分割原型: char *strtok(char *str, const char *delim);功能:分解字符串为一组字符串。参数说明:str为要分解的字符串,delim为分隔符字符串。返回值:从str开头开始的一个个被分割的串。当没有被分割的串时则返回NULL。其它:strtok函数线程不安全,可以使用strtok_r替代。示例://借助strtok实现split#include <string.h>#include <stdio.h&_c++ 字符串分割
2013第四届蓝桥杯 C/C++本科A组 真题答案解析_2013年第四届c a组蓝桥杯省赛真题解答-程序员宅基地
文章浏览阅读2.3k次。1 .高斯日记 大数学家高斯有个好习惯:无论如何都要记日记。他的日记有个与众不同的地方,他从不注明年月日,而是用一个整数代替,比如:4210后来人们知道,那个整数就是日期,它表示那一天是高斯出生后的第几天。这或许也是个好习惯,它时时刻刻提醒着主人:日子又过去一天,还有多少时光可以用于浪费呢?高斯出生于:1777年4月30日。在高斯发现的一个重要定理的日记_2013年第四届c a组蓝桥杯省赛真题解答
基于供需算法优化的核极限学习机(KELM)分类算法-程序员宅基地
文章浏览阅读851次,点赞17次,收藏22次。摘要:本文利用供需算法对核极限学习机(KELM)进行优化,并用于分类。
metasploitable2渗透测试_metasploitable2怎么进入-程序员宅基地
文章浏览阅读1.1k次。一、系统弱密码登录1、在kali上执行命令行telnet 192.168.26.1292、Login和password都输入msfadmin3、登录成功,进入系统4、测试如下:二、MySQL弱密码登录:1、在kali上执行mysql –h 192.168.26.129 –u root2、登录成功,进入MySQL系统3、测试效果:三、PostgreSQL弱密码登录1、在Kali上执行psql -h 192.168.26.129 –U post..._metasploitable2怎么进入
Python学习之路:从入门到精通的指南_python人工智能开发从入门到精通pdf-程序员宅基地
文章浏览阅读257次。本文将为初学者提供Python学习的详细指南,从Python的历史、基础语法和数据类型到面向对象编程、模块和库的使用。通过本文,您将能够掌握Python编程的核心概念,为今后的编程学习和实践打下坚实基础。_python人工智能开发从入门到精通pdf