重磅!Meta 发布 Llama 3,前所未有的强大功能和多模态能力|TodayAI_llama3多模态-程序员宅基地
技术标签: llama 语言模型 人工智能 TodayAI日报 AIGC 开源

Meta今日宣布推出其最新一代尖端开源大型语言模型Llama 3。该模型预计很快将在多个领先的云服务平台上线,包括AWS、Databricks、Google Cloud、Hugging Face、Kaggle、IBM WatsonX、Microsoft Azure、NVIDIA NIM和Snowflake。
Llama 3模型得到了AMD、AWS、Dell、Intel、NVIDIA和Qualcomm等硬件平台的大力支持。Meta表示,他们致力于负责任地开发和推广Llama 3,为此引入了多项新的信任与安全工具,例如Llama Guard 2、Code Shield和CyberSec Eval 2。
在接下来的几个月中,Meta计划引入多项新功能,提供更长的上下文窗口、更多的模型尺寸选择,并进一步提升性能。此外,Meta还计划发布有关Llama 3的研究论文,以分享其技术细节和成就。
Llama 3技术使Meta AI成为全球领先的AI助手之一,旨在通过学习、完成任务、创造内容及更多方式增强用户智能和减轻负担。用户现已能够体验Meta AI的服务。
Meta同时推出了Llama 3的两个版本,包括预训练和指令微调的语言模型,分别具有8B和70B的参数,以支持广泛的应用场景。该模型在各种行业基准测试中展示了卓越性能,并引入了改进的推理功能。Meta坚信,这些都是目前最优秀的同类开源模型。
为了维护开放和共享的精神,Meta已将Llama 3交由社区使用,期望激发AI技术在整个技术堆栈中的创新,从应用开发到开发者工具,再到评估和推理优化等。Meta热切期待看到社区使用Llama 3取得的成果,并希望收到广泛的反馈。
尽早并频繁发布的策略
Meta已设定其新一代开源大型语言模型Llama 3的发展目标,旨在建构能够与当前市场上顶尖的专有模型竞争的优秀模型。公司计划依据开发者社区的反馈来增强Llama 3的整体实用性,并持续在负责任地使用和部署大型语言模型的领域中发挥领导作用。
为了贯彻开源精神,Meta采取了尽早并频繁发布的策略,确保社区在模型仍在开发阶段时即可访问和使用这些工具。作为Llama 3系列的首款产品,今天发布的模型主要基于文本处理。
Meta的近期计划包括扩展Llama 3的功能,使其支持多语言和多模态输入,并提供更长的上下文理解能力。此外,公司还致力于在模型的核心功能,如推理和编程上,持续提升性能,以满足更广泛的应用需求。
显著的性能提升
Meta的最新8B和70B参数模型Llama 3在先前版本Llama 2的基础上实现了显著的性能提升,设定了大型语言模型的新标准。这两个模型通过预训练和训练后的改进,已成为同类规模中的领先者。

具体来说,这些模型在减少错误拒绝率、提高对齐度以及增加模型响应多样性方面实现了显著的进步。

此外,Meta还大幅提升了模型在推理、代码生成和指令遵循等关键功能上的能力,进一步增强了Llama 3的指导性和实用性。

庞大的训练数据集
为了开发出卓越的语言模型,Meta投入了大量资源以策划一个庞大且高质量的训练数据集,这是培养成功的语言模型的关键因素。Llama 3模型在预训练阶段使用了超过15T的令牌,这些令牌均来自公开可获取的数据源。相比于Llama 2, Llama 3使用的训练数据集增加了七倍,其中包含的代码量也增加到了四倍。
为了满足即将推出的多语言用例,Llama 3的预训练数据集中超过5%的内容是覆盖30多种语言的高质量非英语数据。尽管如此,开发团队并不期望这些非英语语言的性能能完全与英语相匹敌。
为了确保Llama 3在最优质的数据上进行训练,Meta开发了一系列数据过滤管道,包括启用启发式过滤器、不适宜工作内容(NSFW)过滤器、语义去重技术以及用于预测数据质量的文本分类器。值得一提的是,先前版本的Llama模型在识别高质量数据方面表现卓越,因此Meta利用Llama 2生成了推动Llama 3的文本质量分类器的训练数据。
通过广泛的实验评估混合不同来源数据的最佳方式,Meta能够选择一个优化的数据组合,确保Llama 3在多种应用场景中,如小知识点问题、科学技术工程数学(STEM)、编程和历史知识等,都能有出色的表现。
扩大训练规模
在Meta的最新Llama 3模型开发过程中,公司为了有效地利用其庞大的预训练数据集,投入了大量资源扩大训练规模。这包括制定一系列详细的下游基准评估规模法则,以选择最佳数据组合并做出明智的计算资源分配决策。这些规模法则还使公司能够预测最大模型在关键任务上的表现,如基于HumanEval基准的代码生成,这些预测在实际训练模型前已经进行。
在开发Llama 3的过程中,Meta观察到几个新的规模行为模式。例如,尽管8B参数模型的最佳训练计算量对应于大约200B个令牌,但模型性能随着训练量增加至两个数量级后仍然在提高。公司的8B和70B参数模型在训练达到15T令牌后,性能持续呈对数线性提升。大型模型虽然可以用较少的训练计算匹配较小模型的性能,但较小模型由于在推理过程中更高的效率,通常更受青睐。
为了优化其最大的Llama 3模型,Meta结合了数据并行化、模型并行化和流水线并行化三种类型的并行化策略。在使用高达16K GPU进行训练时,其最高效的实现计算利用率超过400 TFLOPS每GPU。此外,Meta在两个定制构建的24K GPU集群上进行了训练。为了最大化GPU运行时间,公司开发了一个先进的训练堆栈,能够自动检测、处理和维护错误,并且显著提高了硬件可靠性和静默数据腐败检测机制。新的可扩展存储系统减少了检查点和回滚的开销,这些改进使整体有效训练时间超过95%,将Llama 3的训练效率提高了约三倍。
指令微调
在开发Llama 3模型的过程中,Meta采用了创新的指令微调技术以最大化其预训练模型在聊天应用场景中的效能。该公司的微调方法包括监督式微调(SFT)、拒绝采样、邻近策略优化(PPO)以及直接策略优化(DPO)。特别是在SFT中使用的提示和在PPO及DPO中使用的偏好排名对模型性能的提升有着显著影响。
Meta对这些数据进行了精心策划,并对人类注释员提供的注释进行了多轮质量保证,这些都是模型质量提升的关键因素。通过PPO和DPO学习偏好排名,Llama 3在推理和编程任务上的表现也得到了显著提高。公司观察到,当模型面对难以回答的推理问题时,它有时能够生成正确的推理轨迹,即模型知道如何得出正确答案,但之前不知道如何选取它。通过偏好排名的训练,模型学会了如何选取正确的答案,从而提高了整体性能和应用效果。
与Llama 3共建
在最近的Llama 3发布中,Meta推出了新的信任与安全工具,旨在使开发者能够更容易地定制Llama 3以支持相关用例,并推动最佳实践和开放生态系统的改进。这些工具包括带有Llama Guard 2和Cybersec Eval 2的更新组件以及新引入的Code Shield,一个用于过滤生成的不安全代码的推理时保护装置。
此外,Meta还与torchune合作开发了Llama 3,这是一个全新的PyTorch原生库,旨在简化编写、微调和实验大型语言模型(LLMs)的过程。torchune库提供了内存高效且易于修改的训练配方,完全使用PyTorch编写。该库已与Hugging Face、Weights & Biases和EleutherAI等流行平台集成,并支持Executorch,以便在各种移动和边缘设备上高效运行推理。
Meta提供了全面的入门指南,从下载Llama 3开始,覆盖提示工程和与LangChain的集成,指导开发者在生成式AI应用中进行规模部署。这一系列工具和资源旨在增强Llama 3的可定制性和易用性,同时确保其在各种应用场景中的安全性和效率。
负责任的部署
Meta在设计其最新的Llama 3模型时,采取了一种系统级的方法,旨在确保其模型不仅在行业中以负责任的方式部署,同时也能最大限度地提供帮助。公司视Llama模型为更广泛系统的一部分,使开发者能够根据自己的独特目标设计系统,将Llama模型作为核心组成部分。
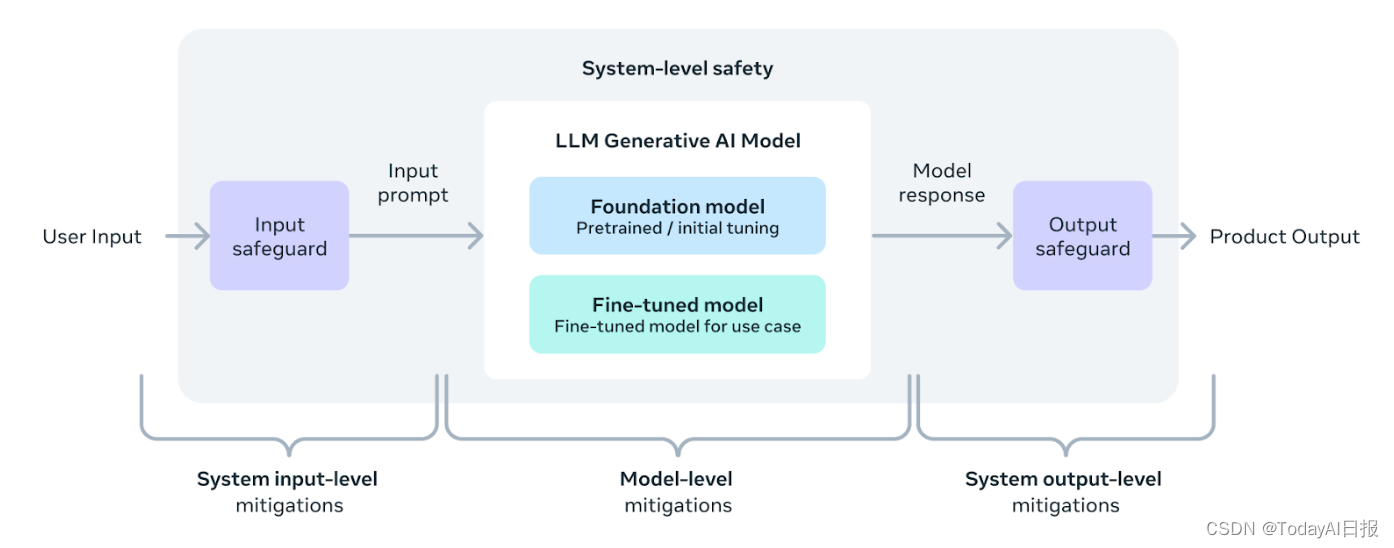
在确保模型安全性方面,指令微调发挥了关键作用。Llama 3的指令微调模型已经通过了一系列内部和外部的红队安全测试,这些测试包括由人类专家和自动化系统执行的对抗性提示生成,以诱发并识别潜在的问题响应。例如,Meta对模型在化学、生物和网络安全等高风险领域的误用进行了全面测试,这些测试旨在评估和减少滥用风险。
此外,Llama Guard模型被设计为一个安全提示和响应的基础框架,可以根据具体应用需求进行灵活微调,创建新的分类法。最新的Llama Guard 2采用了最近宣布的MLCommons分类法,支持这一重要行业标准的发展。同时,CyberSecEval 2在其前身基础上进行了扩展,增加了对LLM的安全性能评估,包括防止其代码解释器被滥用、网络安全能力被恶意利用和对提示注入攻击的抵抗力。
最后,Meta引入了Code Shield,增强了对推理时过滤不安全代码的支持,提供了围绕不安全代码建议、代码解释器滥用预防和安全命令执行的风险缓解措施。这些努力的详细描述可在公司发布的模型卡和技术论文中找到。
全球范围的部署
Llama 3模型即将在全球范围内的所有主要平台上推出,包括各大云服务提供商和模型API提供商,预计将实现广泛的可访问性。
根据Meta的基准测试,Llama 3的新标记器在令牌效率上有显著提升,与前代模型Llama 2相比,令牌使用量减少了多达15%。此外,群组查询注意力(GQA)技术已被整合到Llama 3的8B版本中。尽管Llama 3的参数量比Llama 2的7B版本多出1B,但得益于标记器效率的提升和GQA的添加,Llama 3保持了与Llama 2相当的推理效率。
对于希望了解如何利用这些新功能的开发者,Meta推荐查阅Llama Recipes,这是一系列包含从微调到部署再到模型评估各个环节的开源代码示例,旨在帮助用户最大化Llama 3模型的应用潜力。
Meta的未来计划
Meta的新语言模型Llama 3已经发布了其8B和70B参数版本,这只是该公司为Llama 3计划发布的众多内容的开始。Meta还计划在未来几个月推出多个功能更加丰富的模型,包括多模态性、多语言对话能力、更长的上下文窗口以及更强大的总体性能。其中,最大的模型已经达到了400B参数,虽然这些模型仍在训练中,但Meta团队对其发展趋势表示非常期待。

一旦Llama 3的开发和训练完成,Meta还计划发布一篇详细的研究论文,以深入介绍这些模型的技术和性能。为了让公众提前了解这些模型的当前状态,Meta提供了一些关于其最大语言模型(LLM)的发展趋势的快照,尽管需要注意,这些数据基于目前仍在训练中的Llama 3的早期检查点,并且今天发布的模型尚未支持这些新功能。
Meta强调,他们致力于持续发展和开发一个开放的AI生态系统,并负责任地发布其模型。公司一直认为,开放性能够带来更优质、更安全的产品,加速创新,并促进市场的整体健康。这种策略不仅对Meta有利,对整个社会同样有益。目前,Llama 3已在全球领先的云平台、托管服务和硬件平台上提供,并且未来将会有更多的扩展。

智能推荐
while循环&CPU占用率高问题深入分析与解决方案_main函数使用while(1)循环cpu占用99-程序员宅基地
文章浏览阅读3.8k次,点赞9次,收藏28次。直接上一个工作中碰到的问题,另外一个系统开启多线程调用我这边的接口,然后我这边会开启多线程批量查询第三方接口并且返回给调用方。使用的是两三年前别人遗留下来的方法,放到线上后发现确实是可以正常取到结果,但是一旦调用,CPU占用就直接100%(部署环境是win server服务器)。因此查看了下相关的老代码并使用JProfiler查看发现是在某个while循环的时候有问题。具体项目代码就不贴了,类似于下面这段代码。while(flag) {//your code;}这里的flag._main函数使用while(1)循环cpu占用99
【无标题】jetbrains idea shift f6不生效_idea shift +f6快捷键不生效-程序员宅基地
文章浏览阅读347次。idea shift f6 快捷键无效_idea shift +f6快捷键不生效
node.js学习笔记之Node中的核心模块_node模块中有很多核心模块,以下不属于核心模块,使用时需下载的是-程序员宅基地
文章浏览阅读135次。Ecmacript 中没有DOM 和 BOM核心模块Node为JavaScript提供了很多服务器级别,这些API绝大多数都被包装到了一个具名和核心模块中了,例如文件操作的 fs 核心模块 ,http服务构建的http 模块 path 路径操作模块 os 操作系统信息模块// 用来获取机器信息的var os = require('os')// 用来操作路径的var path = require('path')// 获取当前机器的 CPU 信息console.log(os.cpus._node模块中有很多核心模块,以下不属于核心模块,使用时需下载的是
数学建模【SPSS 下载-安装、方差分析与回归分析的SPSS实现(软件概述、方差分析、回归分析)】_化工数学模型数据回归软件-程序员宅基地
文章浏览阅读10w+次,点赞435次,收藏3.4k次。SPSS 22 下载安装过程7.6 方差分析与回归分析的SPSS实现7.6.1 SPSS软件概述1 SPSS版本与安装2 SPSS界面3 SPSS特点4 SPSS数据7.6.2 SPSS与方差分析1 单因素方差分析2 双因素方差分析7.6.3 SPSS与回归分析SPSS回归分析过程牙膏价格问题的回归分析_化工数学模型数据回归软件
利用hutool实现邮件发送功能_hutool发送邮件-程序员宅基地
文章浏览阅读7.5k次。如何利用hutool工具包实现邮件发送功能呢?1、首先引入hutool依赖<dependency> <groupId>cn.hutool</groupId> <artifactId>hutool-all</artifactId> <version>5.7.19</version></dependency>2、编写邮件发送工具类package com.pc.c..._hutool发送邮件
docker安装elasticsearch,elasticsearch-head,kibana,ik分词器_docker安装kibana连接elasticsearch并且elasticsearch有密码-程序员宅基地
文章浏览阅读867次,点赞2次,收藏2次。docker安装elasticsearch,elasticsearch-head,kibana,ik分词器安装方式基本有两种,一种是pull的方式,一种是Dockerfile的方式,由于pull的方式pull下来后还需配置许多东西且不便于复用,个人比较喜欢使用Dockerfile的方式所有docker支持的镜像基本都在https://hub.docker.com/docker的官网上能找到合..._docker安装kibana连接elasticsearch并且elasticsearch有密码
随便推点
Python 攻克移动开发失败!_beeware-程序员宅基地
文章浏览阅读1.3w次,点赞57次,收藏92次。整理 | 郑丽媛出品 | CSDN(ID:CSDNnews)近年来,随着机器学习的兴起,有一门编程语言逐渐变得火热——Python。得益于其针对机器学习提供了大量开源框架和第三方模块,内置..._beeware
Swift4.0_Timer 的基本使用_swift timer 暂停-程序员宅基地
文章浏览阅读7.9k次。//// ViewController.swift// Day_10_Timer//// Created by dongqiangfei on 2018/10/15.// Copyright 2018年 飞飞. All rights reserved.//import UIKitclass ViewController: UIViewController { ..._swift timer 暂停
元素三大等待-程序员宅基地
文章浏览阅读986次,点赞2次,收藏2次。1.硬性等待让当前线程暂停执行,应用场景:代码执行速度太快了,但是UI元素没有立马加载出来,造成两者不同步,这时候就可以让代码等待一下,再去执行找元素的动作线程休眠,强制等待 Thread.sleep(long mills)package com.example.demo;import org.junit.jupiter.api.Test;import org.openqa.selenium.By;import org.openqa.selenium.firefox.Firefox.._元素三大等待
Java软件工程师职位分析_java岗位分析-程序员宅基地
文章浏览阅读3k次,点赞4次,收藏14次。Java软件工程师职位分析_java岗位分析
Java:Unreachable code的解决方法_java unreachable code-程序员宅基地
文章浏览阅读2k次。Java:Unreachable code的解决方法_java unreachable code
标签data-*自定义属性值和根据data属性值查找对应标签_如何根据data-*属性获取对应的标签对象-程序员宅基地
文章浏览阅读1w次。1、html中设置标签data-*的值 标题 11111 222222、点击获取当前标签的data-url的值$('dd').on('click', function() { var urlVal = $(this).data('ur_如何根据data-*属性获取对应的标签对象