Java常用集合之ArrayList(深入源码)_java arraylist-程序员宅基地
目录
(1)ArrayList概述
ArrayList继承自AbstractList,实现了List接口。
可以存储多个null元素
底层是数组实现,可以动态扩容
实现了 RandomAccess、Cloneable、Serializable 接口,所以ArrayList 是支持随机访问、复制、序列化的。
线程不安全。
(2)ArrayList特点
- ArrayList底层数据结构是数组,查询快,增删慢
- ArrayList更适合检索和在末尾插入或删除(数组的特性)
- 顺序存储
重点:
- 无参构造懒分配空间
- 手动扩容到指定大小
(3)ArrayList三种遍历方式

需要说明的是,遍历ArrayList时,通过索引值遍历效率最高,for循环遍历次之,迭代器遍历最低。
(4)ArrayList源码分析
ArrayList的源码有这些亮点:
- 无参构造懒分配空间
- 使用位运算计算出旧容量的1.5倍,作为新的容量
- 一个小细节:源码中判断时,使用“ 扩容后的容量-需求容量<0 ”来作为条件判断,效率要比“扩容后的容量 < 需求容量”更高
- 在扩容方法中,额外判断了如果增长到1.5倍容量依然不够的情况,设计非常严谨
- 向外提供了手动扩容方法,直接调用扩容方法,上面的判断就起作用了。
- 允许存入null值,也允许按照值删除数据,所以对null做了特殊判断:如果为null就用==比较,如果不为null就用equals()比较
1、成员变量
ArrayList定义了两个成员变量,用来记录集合的大小:

size:集合的当前容量
elementData.length:集合的最大容量(当前存储用数组的长度)
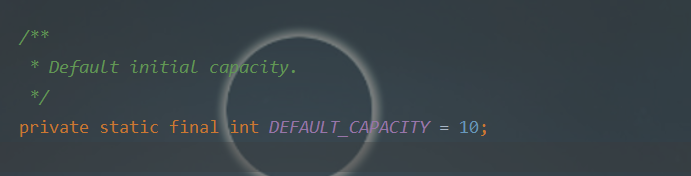
用常量声明了默认的初始存储容量:
还声明了三个数组:
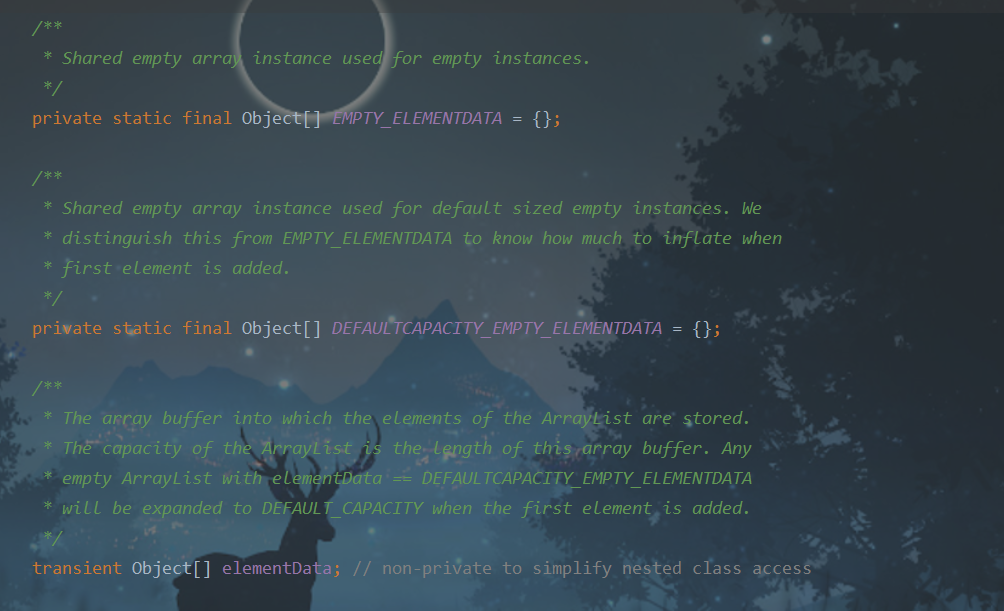
其中,elementData是实际存储的数组
EMPTY_ELEMENTDATA:如果使用有参构造器实例化,就使用这个数组引用
DEFAULTCAPACITY_EMPTY_ELEMENTDATA:如果使用无参构造器实例化,就使用这个数组引用
这个机制可以让ArrayList知道,elementData是从有参构造还是无参构造实例化的,以便确认如何扩容。
ArrayList为了实现懒加载,做了哪些事情
首先,只有调用无参构造才会触发懒加载,使用有参构造会立即初始化数组容量,这个很合理
如果使用懒加载,那么思路是,在第一次加入元素时,给数组初始化容量。
- 这就要求必须能够区分,这个ArrayList是有参构造出的,还是无参构造出的
- 原因是,如果不进行判断,就会在第一次加入元素时,覆盖已经通过有参构造初始化好的数组。
- 做法是,使用不同的数组引用进行区分。
2、构造方法
无参构造器:

意思是,将DEFAULTCAPACITY_EMPTY_ELEMENTDATA这个数组用作存储。
此时这个数组是空的,在第一次添加元素时,数组才会分配容量
指定容量的有参构造器:
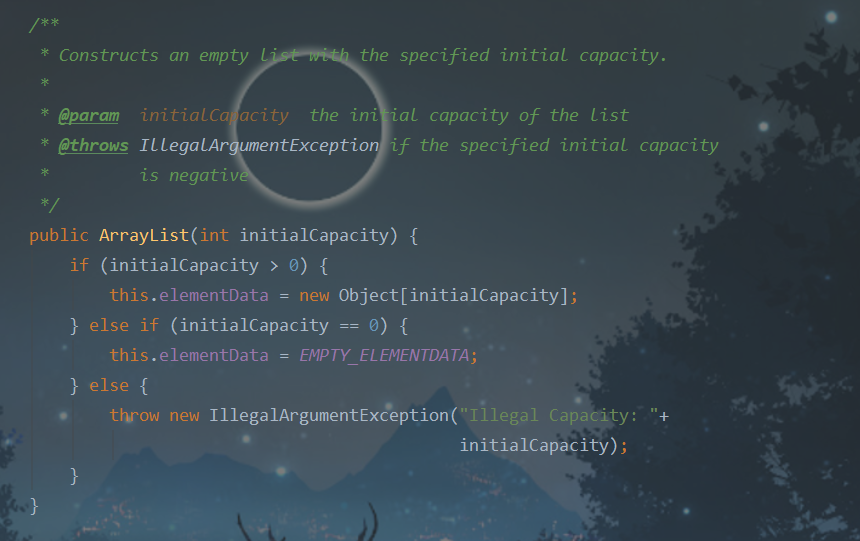
实例化时,指定集合容量initialCapacity。
如果这个值大于0,就创建一个等容量的Object数组,注意这个数组也是空的,但容量已经分配了。
如果这个值等于0,就使用EMPTY_ELEMENTDATA这个数组作为存储数组;
如果这个值小于0,抛出异常:不合法的参数。
使用指定Collection集合来构造ArrayList的有参构造器:
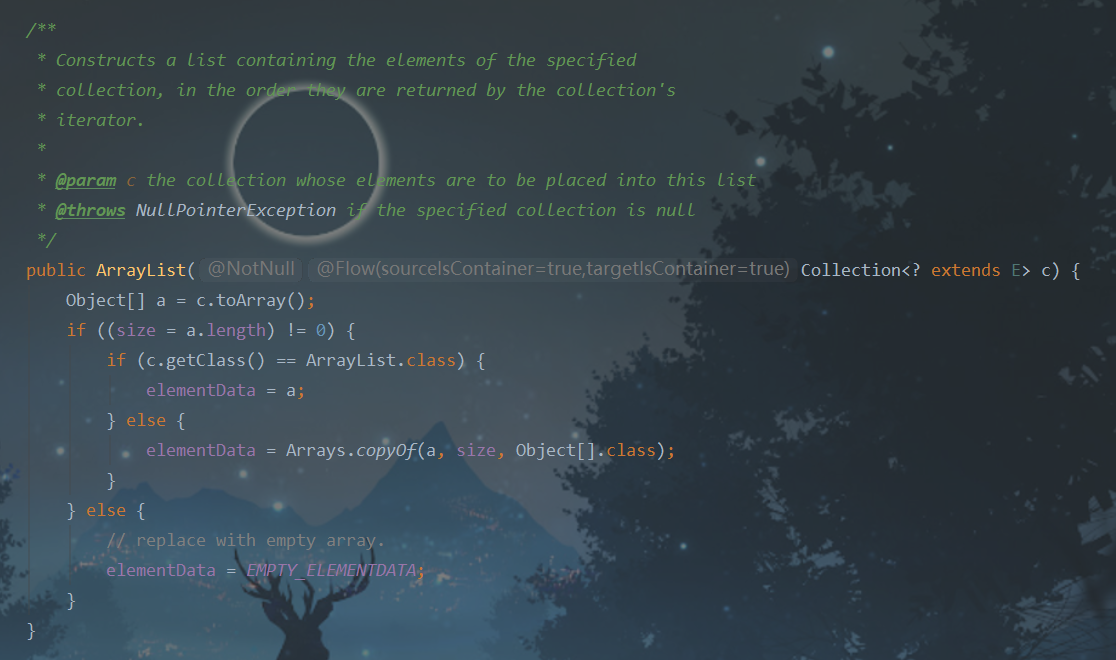
将给出的Collection集合转化为数组,并赋值给elementData。
如果传入的集合为空,就使用EMPTY_ELEMENTDATA这个数组作为存储数组,相当于new ArrayList(0)。
否则,判断集合的类型是否为一个Object类型的数组,如果不是,就转换成Object类型的数组。
ArrayList有参构造与无参构造的区别
无参构造时,不会分配数组空间,只有第一次添加元素时才会分配默认的10个容量。
有参构造时,根据传入的参数,创建出对应容量的Object数组。
使用有参构造和无参构造,对应的数组引用不同,对应不同的扩容策略。
3、add()
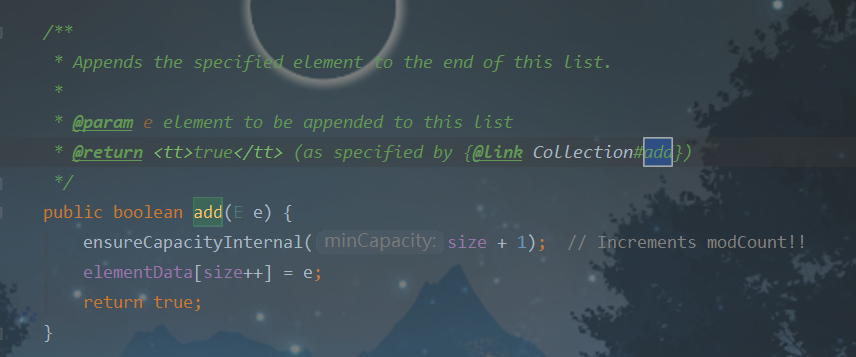
add():调用ensureCapacityInternal()方法,传入当前集合的大小size+1,然后将新的元素放入当前size的下一个位置。

ensureCapacityInternal()方法会调用ensureExplicitCapacity()方法,传入calculateCapacity()方法的返回值。
先来看calculateCapacity()方法:

它的作用是返回集合所需的容量。
传入当前的存储数组,以及当前需求的最小容量。(这个容量是当前集合长度+1,即能成功放入新元素后的集合长度。)
判断,如果当前集合是无参构造创建的空数组,就返回最小容量和默认初识容量(10)之中的最大值。
否则,返回最小容量。
为什么这么设计?因为使用无参构造器,真正的初始化动作是在这里发生的,第一次扩容时,将集合长度设置为10。
再来看ensureExplicitCapacity()方法:

modCount:定义在AbstractList中,记录修改集合的次数,用于迭代器的快速失败机制。
传入当前所需最小容量,如果它超出了当前集合的容量,就调用grow()方法,进行扩容操作。
4、grow()
grow()方法:

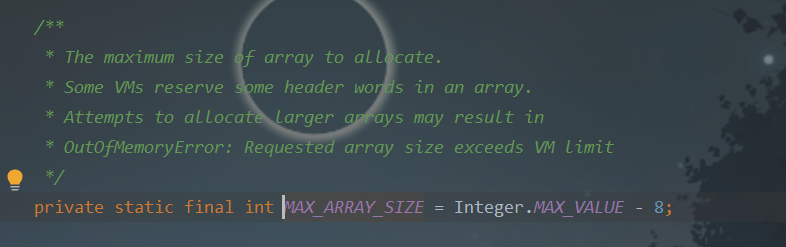
oldCapacity:当前集合的最大容量
newCapacity:当前集合容量的1.5倍(将oldCapacity 右移一位,其效果相当于oldCapacity /2,位运算的效率很高。)
但1.5倍的容量可能满足不了需求,可能太小,可能太大。所以之后检查新容量与需求容量的大小。
如果需求容量更大,那么新容量不够,就让需求容量成为新容量。
MAX_ARRAY_SIZE:允许的最大容量
如果新容量超过了允许的最大容量,就调用hugeCapacity()方法:
如果最小容量发生了整型溢出,超过了int类型的最大值,变成了负数,就抛出内存溢出异常。
如果最小容量比最大容量大,就返回整型的最大值,否则返回允许的最大值。
这个方法的作用是,如果需求最小容量非常大,判断它是否合法,如果合法,就满足它。
有了目标容量,就调用Arrays.copyOf()方法,进行扩容。
一个细节
既然向ArrayList中添加元素,都是一个一个调用add()方法,为什么在扩容方法中需要考虑,将容量扩大1.5倍后依然不够用的情况?
它的设计思路是这样的:
- 这个方法需要保证绝对的可靠,而不管上游是在什么具体场景下调用它
- 相应的,ArrayList提供了手动扩容的方法,可以传入一个具体的容量值,它的底层就调用了这个扩容方法,用到了上面提到的逻辑。
扩容的细节
调用add()方法,会先进行扩容的判断,如果发生扩容,会将当前的存储数组替换成扩容后的数组,而旧的内容不变,所以size不需要更新,新元素直接插入size+1的位置即可。
5、动态扩容机制
无参构造创建ArrayList,默认不会分配数组空间,在第一次添加元素时才会扩容到10。如果使用有参构造,那么会创建指定容量的数组空间。
在添加元素时,会先判断是否需要扩容,如果需要,就扩容到原先容量的1.5倍,新的容量是通过位运算实现的
扩容的底层是Arrays.copyOf()实现的,而Arrays.copyOf()的底层是System.copyof(),如果直接调用System.copyof(),效率会更高。
但是在remove()方法中是直接调用的此处的System.copyof()。考量可能是:
-
扩容操作比起移除操作来说,发生得不那么频繁,可以使用封装好的方法来简化代码
-
Arrays.copyOf()只需要传入一个数组和一个容量,就能返回一个扩容好的新数组。很符合扩容的需求
-
移除操作是需要把要删除元素的后面整体往前搬移一格,Arrays.copyOf()实现不了,只能调用底层的System.copyof()
ArrayList的最大存储容量:Integer.MAX_VALUE
6、remove方法
从数组中删除一个元素,需要整体挪动一些元素,所以删除方法也很有意思。

通过索引获取元素,先检查索引是否合法:

之后增加操作次数,获取要删除的元素:

之后判断,要删除的元素是否为数组的最后一个元素。如果不是,就需要将被删除数之后的元素,整体向前复制一位
最后,删除数组的最后一个元素,返回删除的元素值。

通过元素值来删除元素
首先判断元素是否为null,如果是,就遍历数组,用==找到第一个null,删除它。
如果不为null,就遍历数组,用equals找到第一个该元素,删除它。
只要找到一个符合的下标,就会删除,返回true。
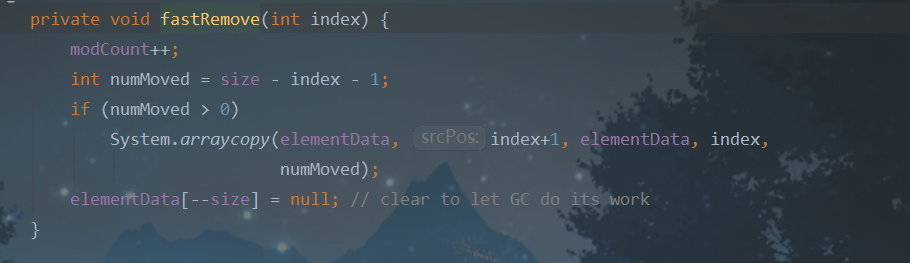
快速删除,不会判断索引是否合法,也不会返回被删除的元素值。
这是个private方法,只能内部调用,所以不会出问题,减少非法判断,提升了一些效率。
Arrays.copyOf()方法

7、ensureCapacity()
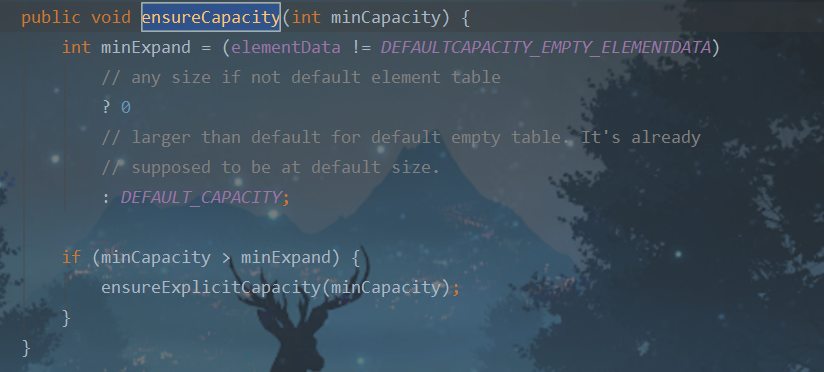
这个方法是public的,在ArrayList源码内部没有进行调用,是留给用户调用的。
这个方法可以让我们手动去给集合扩容。
如果事先知道要给ArrayList中添加的元素个数,就可以通过这个方法一次性给ArrayList扩容,避免数据添加过程中发生多次扩容,可以大大减少时间消耗。
不过这个扩容只能保证容量大于这个值,扩容后的集合并不一定是这个值。因为如果当时集合容量的1.5倍大于这个值,就会采用增长1.5倍的策略。
8、get()
get方法没有直接返回数组对应索引的元素,而是先调用rangeCheck,再调用elementData。
这个elementData,就是直接返回数组对应索引的元素

rangeCheck会做出检查,如果传入的索引超过了当前集合的长度,就抛出异常。
9、常见问题
为什么ArrayList线程不安全,增删效率低,还经常被使用
ArrayList的最大优势是支持随机访问,所以在查询操作多,增删操作少的场景很适用。
如果涉及频繁的增删,可以使用LinkedList
如果需要线程安全,可以使用Vector
ArrayList(int initialCapacity)会不会初始化数组大小?
调用有参构造指定ArrayList容量,会初始化数组大小:

但不会初始化List集合的大小,size为0,所以此时直接操作集合,不会操作数组中的默认0,而是会抛出异常:下标越界。
ArrayList的插入、删除操作一定慢?
具体效率取决于操作数在数组中的位置。
最好情况,操作数在数组末尾,且没有发生扩容,那么插入、删除的时间复杂度都是O(1),不涉及数据搬移。
所以,ArrayList用来做栈很合适。因为入栈、出栈操作都发生在数组末尾,效率不受影响
ArrayList适合做队列吗?
队列是FIFO的,两端都会涉及操作数据,那么必然会发生数组头部数据的操作,效率就很低,因为涉及到最坏情况的全体数据搬移操作,比较耗费性能。
数组适合做队列吗?
数组非常适合,我们可以做一些优化,用两个偏移量来标记数组的读位置和写位置,可以对索引进行取模构建环形队列,或者使用动态的索引,总之可以灵活利用数组的空间,避免强制的数据搬移即可。
为什么ArrayList通常情况下最大容量是Integer.Max_Value - 8 ?
这是由于某些VM会在数组头部保留一些头字,尝试分配更大的数组可能导致OOM。
智能推荐
前端设置条件限制form表单提交到后端解决方案_jsp前端页面将表单是否提交成功作为限制条件-程序员宅基地
文章浏览阅读375次。<script src="js/jquery-1.8.3.min.js" type="text/javascript"></script> <script type="text/javascript"> function checkName() { var name = document.getElementB..._jsp前端页面将表单是否提交成功作为限制条件
计算机网络sequence number,TCP协议中SequenceNumber和Ack Numbe-程序员宅基地
文章浏览阅读1k次。Sequence Numberlzyws7393074532892018-04-25Number Sequenceqq_391789932452017-09-21理解TCP序列号(Sequence Number)和确认号(Acknowledgment Number)hebbely9822017-01-14Number Sequence(规律)l25336363712902017-07-18Numb..._ack num
计算机系统启动项设置密码,电脑开机第一道密码怎么设置 - 卡饭网-程序员宅基地
文章浏览阅读5.9k次。笔记本电脑怎么进CMOS密码巧设置笔记本电脑怎么进CMOS密码巧设置 笔记本电脑为了保护用户的数据安全,往往采用加密的方式,最常见的还是CMOS密码加密技术。为了让你的重要数据更加安全,你可能需要设置不同的密码,这也就要求你记住许多密码。对于笔记本电脑用户来说,真的需要设置一道道密码关卡吗?非也非也! 一、认识与设置笔记本电脑的CMOS密码 笔记本电脑的CMOS密码大致分为超级密码(Supervi..._电脑第一道密码修改
VulnHub靶机-Jangow: 1.0.1_jangow01-程序员宅基地
文章浏览阅读2.5k次,点赞2次,收藏5次。迟到的文章,就当库存发出来吧~_jangow01
spark实战之RDD的cache或persist操作不会触发transformation计算_spark cache和persist不生效-程序员宅基地
文章浏览阅读1.7w次,点赞2次,收藏5次。默认情况下RDD的transformation是lazy形式,实际计算只有在ation时才会进行,而且rdd的计算结果默认都是临时的,用过即丢弃,每个action都会触发整个DAG的从头开始计算,因此在迭代计算时都会想到用cache或persist进结果进行缓存。敝人看到很多资料或书籍有的说是persist或cache会触发transformation真正执行计算,有的说是不会!敝人亲自实验了一把..._spark cache和persist不生效
html文字滚动_html滚动-程序员宅基地
文章浏览阅读2.4k次。HTML之marquee(文字滚动)详解语法:以下是一个最简单的例子:代码如下:Hello, World下面这两个事件经常用到:onMouseOut=“this.start()” :用来设置鼠标移出该区域时继续滚动onMouseOver=“this.stop()”:用来设置鼠标移入该区域时停止滚动代码如下:onMouseOut=“this.start()” :用来设置鼠标移出该区域时继续滚动 onMouseOver=“this.stop()”:用来设置鼠标移入该区域时停止滚动这是一个完_html滚动
随便推点
树莓派GPIO简单操作_树莓派怎么读取gpio口上的信息-程序员宅基地
文章浏览阅读637次。树莓派的GPIO操作被抽象为文件读写,下面以一个例子来说明GPIO操作。_树莓派怎么读取gpio口上的信息
【汽车电子】浅谈车载系统QNX_车机qnx虚拟化软件系统架构-程序员宅基地
文章浏览阅读1.7k次。QNX是一种商用的遵从POSIX规范的类Unix实时操作系统,目标市场主要是面向嵌入式系统。它可能是最成功的微内核操作系统之一。QNX是一种商用的类Unix实时操作系统,遵从POSⅨ规范,目标市场主要是嵌入式系统[1]。QNX成立于1980年,是加拿大一家知名的嵌入式系统开发商。QNX的应用范围极广,包含了:控制保时捷跑车的音乐和媒体功能、核电站和美国陆军无人驾驶Crusher坦克的控制系统[2],还有RIM公司的BlackBerry PlayBook平板电脑。_车机qnx虚拟化软件系统架构
信号发生器设计VHDL代码Quartus仿真_vhdl正弦波信号发生器-程序员宅基地
文章浏览阅读1k次,点赞20次,收藏22次。代码功能:信号发生器设计信号发生器由波形选择开关控制波形的输出,分别能输出正弦波、方汉和三角波三种波形,波形的周期为2秒(由40M有源晶振分频控制)。考虑程序的容量,每种波形在一个周期内均取16个取样点,每个样点数据是8位(数值范围:00000000~1111111)要求将D/A变换前的8位二进数据(以十进制方式)输出到数码管动态演示出来。_vhdl正弦波信号发生器
笔记-Java线程概述_java 线程概述-程序员宅基地
文章浏览阅读629次。Java Concurrency in Practice中对线程安全的定义:当多个线程访问一个类时,如果不用考虑这些线程在运行时环境下的调度和交替运行,并且不需要额外的同步及在调用方代码不必做其他的协调,这个类的行为仍然是正确的,那么这个类就是线程安全的。显然只有资源竞争时才会导致线程不安全,因此无状态对象永远是线程安全的 。过多的同步会产生死锁的问题,死锁属于程序运行的时_java 线程概述
MATLAB从文件读取数据_matlab读取数据-程序员宅基地
文章浏览阅读1.2w次,点赞10次,收藏61次。读取表单Sheet2中部分信息。_matlab读取数据
【实践】基于spark的CF实现及优化_spark cf-程序员宅基地
文章浏览阅读1.4w次。最近项目中用到ItemBased Collaborative Filtering,实践过spark mllib中的ALS,但是因为其中涉及到降维操作,大数据量的计算实在不能恭维。所以自己实践实现基于spark的分布式cf,已经做了部分优化。目测运行效率还不错。以下代码package modelimport org.apache.spark.broadcast.Broadcastimp_spark cf