随机森林简单回归预测_随机森林回归预测模型-程序员宅基地
随机森林(RandomForest)简单回归预测
随机森林是bagging方法的一种具体实现。它会训练多棵决策树,然后将这些结果融合在一起就是最终的结果。随机森林可以用于分裂,也可以用于回归。主要在于决策树类型的选取,根据具体的任务选择具体类别的决策树。
对于分类问题,一个测试样本会送到每一颗决策树中进行预测,然后投票,得票最多的类为最终的分类结果;
对于回归问题,随机森林的预测结果是所有决策树输出的均值。
本文介绍利用随机森林进行时间序列的简单回归预测,满足大部分科研需求。
介绍
随机森林的优点:
在数据集上表现良好,两个随机性的引入,使得随机森林不容易陷入过拟合,但是对于小数据集还是有可能过拟合,所以还是要注意;
两个随机性的引入,使得随机森林具有很好的抗噪能力;
它能够处理很高维的数据,并且不用做特征选择,对数据集的适应能力强。既能处理离散性数据,也能处理连续型数据,数据集无需规范化;
在创建随机森林的时候,对generalization error使用的是无偏估计;
训练速度快,可以得到变量重要性排序;
在训练过程中,能够检测到feature间的互影响;
容易做成并行化方法;
实现比较简单
随机森林的缺点:
对于小数据集和低维的数据效果可能不是很好。
整个模型为黑盒,没有很强的解释性。
由于随机森林的两个随机性,导致运行结果不稳定。
数据准备
安装所需要的py库
pip install sklearn导入所需要的包
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.multioutput import MultiOutputRegressor单输出回归
预测给定输入的单个数字输出。
随机构建训练集和测试集
rng = np.random.RandomState(1)
X = np.sort(200 * rng.rand(600, 1) - 100, axis=0)
y = np.array([np.pi * np.sin(X).ravel()]).T
y += (0.5 - rng.rand(*y.shape))
#x和y的shape为(600, 1) (600, 1)
X_train, X_test, y_train, y_test = train_test_split(
X, y, train_size=400, test_size=200, random_state=4)
#X_train, X_test, y_train, y_test的shape
#为(400, 1) (200, 1) (400, 1) (200, 1)构建模型并进行预测
#定义模型
regr_rf = RandomForestRegressor(n_estimators=100, max_depth=30,
random_state=2)
# 集合模型
regr_rf.fit(X_train, y_train)
# 利用预测
y_rf = regr_rf.predict(X_test)
#评价
print(regr_rf.score(X_test, y_test))作图
plt.figure()
s = 50
a = 0.4
plt.scatter(X_test, y_test, edgecolor='k',
c="navy", s=s, marker="s", alpha=a, label="Data")
plt.scatter(X_test, y_rf, edgecolor='k',
c="c", s=s, marker="^", alpha=a,
label="RF score=%.2f" % regr_rf.score(X_test, y_test))
plt.xlim([-6, 6])
plt.xlabel("X_test")
plt.ylabel("target")
plt.title("Comparing random forests and the test")
plt.legend()
plt.show()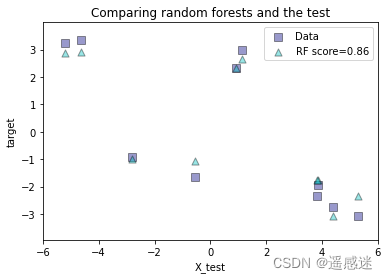
多输出回归
根据输入预测两个或多个数字输出。
随机构建训练集和测试集,这里构建的是一个x对应两个y
rng = np.random.RandomState(1)
X = np.sort(200 * rng.rand(600, 1) - 100, axis=0)
y = np.array([np.pi * np.sin(X).ravel(), np.pi * np.cos(X).ravel()]).T
y += (0.5 - rng.rand(*y.shape))
#x和y的shape为(600, 1) (600, 2)
X_train, X_test, y_train, y_test = train_test_split(
X, y, train_size=400, test_size=200, random_state=4)
#X_train, X_test, y_train, y_test的shape
#为(400, 1) (200, 2) (400, 1) (200, 2)构建模型并进行预测
这里尝试了利用随机森林和包装器类两种方法
#定义模型
max_depth = 30
regr_multirf = MultiOutputRegressor(RandomForestRegressor(n_estimators=100, max_depth=max_depth, random_state=0))
# 拟合模型
regr_multirf.fit(X_train, y_train)
#定义模型
regr_rf = RandomForestRegressor(n_estimators=100, max_depth=max_depth,
random_state=2)
# 拟合
regr_rf.fit(X_train, y_train)
#预测
y_multirf = regr_multirf.predict(X_test)
y_rf = regr_rf.predict(X_test)作图
plt.figure()
s = 50
a = 0.4
plt.scatter(y_test[:, 0], y_test[:, 1], edgecolor='k',
c="navy", s=s, marker="s", alpha=a, label="Data")
plt.scatter(y_multirf[:, 0], y_multirf[:, 1], edgecolor='k',
c="cornflowerblue", s=s, alpha=a,
label="Multi RF score=%.2f" % regr_multirf.score(X_test, y_test))
plt.scatter(y_rf[:, 0], y_rf[:, 1], edgecolor='k',
c="c", s=s, marker="^", alpha=a,
label="RF score=%.2f" % regr_rf.score(X_test, y_test))
plt.xlim([-6, 6])
plt.ylim([-6, 6])
plt.xlabel("target 1")
plt.ylabel("target 2")
plt.title("Comparing random forests and the multi-output meta estimator")
plt.legend()
plt.show()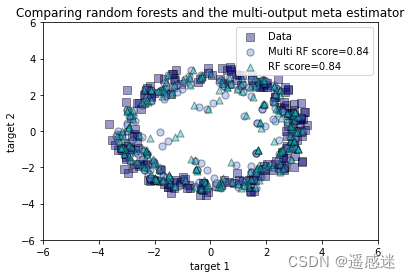
欢迎关注vx公众号遥感迷,更多东西静待发布

智能推荐
【科普】显示器连接线有哪几种都长什么样子_显示器连接线有几种-程序员宅基地
文章浏览阅读1.1w次。显示器连接线有3种 HDMI连接线、VGA连接线、DVI连接线、DP连接线。1、DPDP(DisplayPort)是第一个依赖数据包化数据传输技术的显示通信端口,这种数据包化传输技术可以在以太网、USB和PCI Express等技术中找到。它既可以用于内部显示连接,也可以用于外部的显示连接。DP(DisplayPort)与HDMI接口类似,支持视频和音频同时传输。部分版本支持USB接口、type-C兼容HDMI、DVI旧型号接口,相比HDMI拥有更高的带宽。 DP1.4最高达32.4Gbps的带宽,可_显示器连接线有几种
PyQt中QComBox自定义属性,并能够获得所选内容的复选框_qt combox通过自定义数据获取当前文本-程序员宅基地
文章浏览阅读1.5k次。网上找不到合适的自定义item内容并能够获得复选内容的combox,所以自己写了个,有需要的直接拿去用即可:from PyQt5.QtWidgets import QComboBox, QLineEdit, QListWidget, QCheckBox, QListWidgetItemfrom PyQt5 import QtWidgetsimport sysclass ComboCheck..._qt combox通过自定义数据获取当前文本
IDEA导入github项目_idea怎么导入github的项目-程序员宅基地
文章浏览阅读2.1w次,点赞8次,收藏28次。首先在IDEA设置上github的用户名和密码 :然后配置git然后导入github上的项目 New->Project from Version Contro->Git把github上地址复制到上面,注意选择“Use SSH”注意:如果报 ssh key的错误,就查看本地上是否有公私钥,地址 C:\Users\dingaimin\.ssh如果没有 .ssh,就需要用git bash创建..._idea怎么导入github的项目
Could not execute JDBC batch update_non-atomic batch failure-程序员宅基地
文章浏览阅读3.4k次。014-10-11 14:58:30,951 [org.hibernate.util.JDBCExceptionReporter]-[WARN] SQL Error: -99999, SQLState: null2014-10-11 14:58:30,952 [org.hibernate.util.JDBCExceptionReporter]-[ERROR] Non-atomic batch f_non-atomic batch failure
COCO数据集人体姿态估计关键点检测评估_coco关键点-程序员宅基地
文章浏览阅读1.4w次,点赞15次,收藏117次。MS COCO数据集人体关键点评估(Keypoint Evaluation)_coco关键点
web复制功能实现-程序员宅基地
文章浏览阅读1.2k次。web复制功能实现html部分html部分此处真正需要的是btn,其他的都是样式上的设置<a class="mui-navigate-right btn"> <span class="mui-icon iconfont icon-kefu" style="color: #F5A623;"></span> 联系客服</a>
随便推点
STC16f40k128 使用VOFA+进行电机PID参数整定_vofa 电机闭环-程序员宅基地
文章浏览阅读4.9k次,点赞10次,收藏108次。VOFA+是一个串口调试助手,但凭它简单的通信协议、数据可视化以及频域分析,三维打印等优点在众多串口调试助手中脱颖而出。就凭一个打印波形,屁颠屁颠就冲这软件来了。_vofa 电机闭环
NTP注意事项_localhost: timed out, nothing received-程序员宅基地
文章浏览阅读3.1k次。NTP注意事项注意一:首先是关于时区的问题,经度的零点在 Greenwich,因此就有了 GMT(Greenwich Mean Time) 的概念,GMT 以东的快(+),以西的慢(-),比如大陆就是 GMT+8,也就是比 GMT 快 8 h。GMT 为 0 点的时候,大陆已经早上 8 点了。然后还有个国际日期变更线的问题,这个在太平洋上,也就是精读为 180 的那_localhost: timed out, nothing received
BZOJ 2151 种树(可反悔贪心,链表)【BZOJ千题计划】就图一乐_bzoj 链表-程序员宅基地
文章浏览阅读453次。【BZOJ修复计划 #16】BZOJ 2151 种树【国家集训队2011】_bzoj 链表
mybatis源码编译的一些坑_could not compute the year of the last git commit -程序员宅基地
文章浏览阅读822次。 讲道理,如果mybatis和mybatis-parent的版本号一致的话,大概率是不会遇到坑的。但是不排除某些人的自残倾向,非要用不同版本的mybatis和mybatis-parent,这样的话可能会遇到以下这些坑:“cannot resolve plugins xxx”的问题:导致这个问题的原因是没有指定插件的版本号,在pom文件中为相应插件指定version即可,例如:或者干脆注释掉:“Cannot resolve plugin org.apache.maven.plugins:mav_could not compute the year of the last git commit for file
Linux上ftp传输文件怎么改名,Linux Ftp上传文件变更(MD5值变更)-程序员宅基地
文章浏览阅读1.5k次。最近遇到一个很棘手的问题. 问题很简单:一般情况下使用ftp上传就是这个样子:如下脚本:$ vim copy.sh#! /bin/bashremote_path=远程地址if [ -f $1 ]thenftp -i -n <open ftp服务器user 账户名 密码put $1 $remote_path$1quitUPLOADfi这是文本文件内容. vim会默认在文件末尾追加\n$ vim..._ftp linux 重命名文件
Go 语言搭建个人博客(qiucode.cn 重构篇 一)_golang 开发的多用户博客-程序员宅基地
文章浏览阅读744次。在下图所示目录中创建一个新文件夹(新目录),当然咯,你大可在你电脑的任何位置新建一个目录。浏览器: Chrome (在版本上没有特别要求)想要搭建一个简单的 HTTP 服务器端,需调用。极力推崇的最新管理项目的方案,这种方式摆脱了。命令行处于监听状态,打开浏览器,在地址栏输入。windows 系统版本: win 8.1。执行以上命令后,会在当前目录下自动生成。golang 版本: 1.19。函数进行路由注册,而后通过。函数来开启对客户端的监听。进行管理的,毕竟这是。所在目录下管理项目。_golang 开发的多用户博客