目标检测——YOLO算法解读(通俗易懂版)-程序员宅基地
论文:You Only Look Once: Unified, Real-Time Object Detection
作者:Joseph Redmon, Santosh Divvala, Ross Girshick, Ali Farhadi
链接:https://arxiv.org/abs/1506.02640
代码:http://pjreddie.com/yolo/
yolo系列检测算法开山之作,通过仔细研读论文及代码,尝试用通俗简单的文字来解读一下yolo检测算法的思想
YOLO系列算法解读:
PP-YOLO系列算法解读:
1、算法概述
之前的检测算法,例如R-CNN系列都是将检测当作分类来看待(通过算法遍历或者学习得到候选框,然后分类),但是YOLO算法将检测看作回归问题来解决,整个过程是一个端到端的过程,速度相较于前面的检测算法有非常大的提升,单张图片推理速度达到45帧/秒,Fast YOLO版本可以达到155帧/秒。

文章创新点:
1、由于检测被看作是回归问题,所以网络结构非常简单,图片只需经过一次网络前向推理就可以得到最终的预测框及类别。
2、yolo是基于全局图片进行推理,不像滑窗和region proposal-base算法那样只是基于感兴趣区域做推理。由于yolo训练和推理都是基于整张图片,而Fast R-CNN是基于局部感兴趣区域训练,所以它将背景误认为目标的错误较多,yolo相对于Fast R-CNN的背景误报少了一半。
3、yolo能学习到目标的通用化表示特征,相较于其他之前的检测算法如DPM、R-CNN系列,泛化性能更强。
不足之处:YOLO在精度上仍然落后于最先进的检测算法。虽然它可以快速识别图像中的目标,但很难精确定位某些目标,尤其是小目标。
2、YOLO细节
2.1 由分类到检测

分类任务中,上图经过卷积神经网络,最终输出one-hot向量,假如分类类别为10类(猫为第二个类别),则图片的类别预测过程为:image->conv+bn+relu+pooling->…->fc(10)->one-hot向量,我们期望得到0100000000的输出结果,该输出结果是一个向量。
而对于检测任务,对于上图中的单个目标单个类别而言,其实也是输出一个向量,如下:

该目标框可以用(cx,cy,w,h)来表示,其中(cx,cy)是矩形框中心点坐标,w,h是矩形框的宽高;当然,也可以用(x1,y1,w,h)或者(x1,y1,x2,y2)等方式来表示,其中(x1,y1)代表矩形框左上角点坐标,(x2,y2)代表矩形框右下角点坐标。但说到底,这些表示矩形框的形式都是一个向量,所以对于这种单类别单目标的检测任务,就可以看成分类一样,image->conv+bn+relu+pooling->…->fc(5)->(c,cx,cy,w,h),其中c表示这个框是否是目标的概率,也叫目标置信度。
如何训练这种单类别单目标的检测任务呢?
找上千张类似上图这种图片中单个猫的图片标注,图片标签设置为(1,cx*,cy*,w*,h*),1代表图片中的标注是存在真实目标的,(cx*,cy*,w*,h*)代表标注目标的groundtruth,这样就可以通过网络conv+bn+relu+pooling->…->fc(5)输出的预测值(c,cx,cy,w,h)与groundtruth标注(1,cx*,cy*,w*,h*)通过常用的均方误差或者平方和误差完成网络的训练。
注意这种方式从本质上区别于R-CNN系列的区域候选框加分类的检测方式,传统的检测方法包括R-CNN系列本质上都是训练一个二分类器用于对候选框区分背景/前景,然后进行bounding box微调。候选框的选取,传统方式有滑动窗口,R-CNN,Fast R-CNN用的Selective Search,Fast R-CNN用的RPN网络学习出来的。而上面提到的方式是直接通过网络回归出目标框,简单很多。如下图对比效果

上一种是单个类别单个目标的情况,下面上难度,对于如下单类别多目标的情况又该如何?

根据全卷积网络思想,特征图区域和原图区域在空间位置上是对应关系,所以对于这种单类别多目标的图片,我们可以“分而治之”,将上图横竖切分成4个区域,每个区域就是单类别单目标这种简单形式了,效果如下:
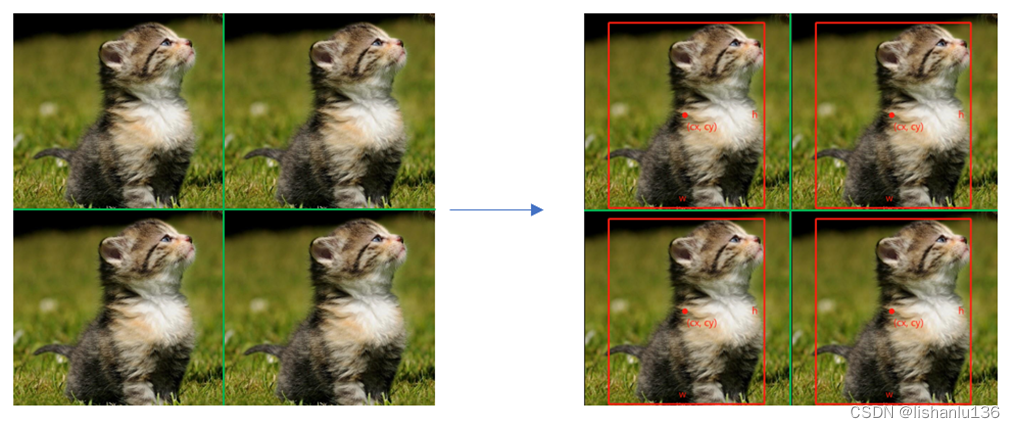
所以网络输出形式由单个目标变成多个目标就成为了如下形式:

对于如下图比较复杂的多目标情况,我们可以切分得更细,例如4x4,输出16个矩形框来预测目标,如下:
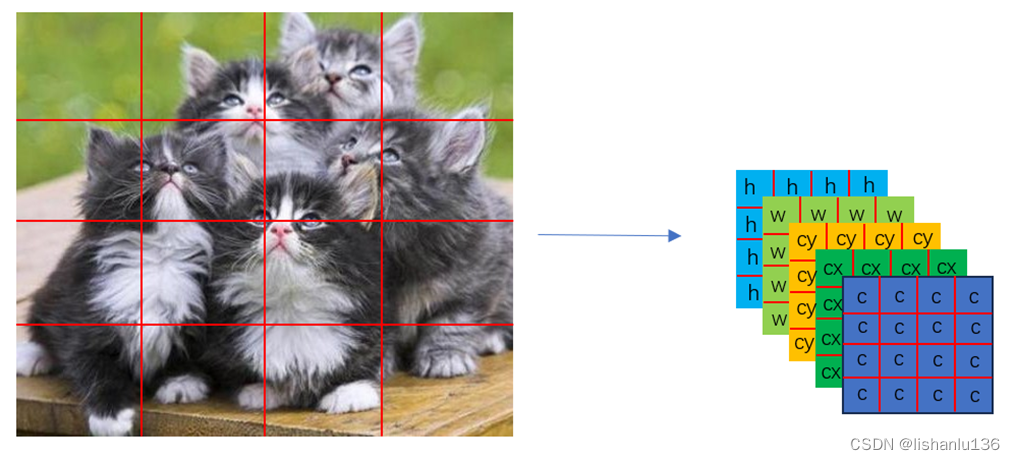
图中只有5只猫,我们用16个矩形框来预测,显然是冗余的,但是最终输出的预测框,只要c值置信度未达到我们设置的阈值,我们最终会视为此区域不包含目标,例如上图最左上角区域。针对上图这种复杂的多目标,我们该如何确定具体哪个区域负责回归哪个目标呢?yolo给的回答是目标的groundtruth矩形框的中心点落在哪个区域,哪个区域就负责回归这个目标,如在上图检测猫头的任务对应的区域c值设置为:

左上角区域我们设置groundtruth时c值为0,代表背景,此区域在训练过程中也就不需要回归矩形框。
介绍到这里,虽然举的例子还是比较简单,但是有点yolo的雏形了。针对于更广泛的情况:1、划分的区域中存在多个目标怎么办?(即多个groundtruth标注框中心点落在同一个区域),2、目标存在多个类别怎么办? 这些才是常见目标检测任务遇到的情况,这也是上述例子的推广,针对这些情况的处理方式都将在yolo中得到体现。
2.2 YOLO网络设计
根据2.1节提到的例子推广第一种情况:划分的区域中存在多个目标怎么办?
简单的做法,我们可以把区域划分得更细,这样就能减少多个groundtruth标注框中心点落在同一个区域的概率,但这种做法治标不治本,划分得多细也没有定论。YOLO的做法是将图片切分成7x7大小的区域,每个区域设置两个bounding box用于匹配落在同一区域的多个groundtruth,所以这也导致了YOLO最多预测98个(7x7x2)矩形框输出。
针对推广的第二种情况:目标存在多类别怎么办?
YOLO的做法是对每个区域做softmax分类即可。
YOLO网络设计的弊端:虽然一个区域设置两个bounding box匹配groundtruth用于适应不同尺度目标,但是一个区域只能预测一个类别,若真的在一个区域出现两个目标,即使两个bounding box都预测到了,根据类别限制也只能取一个。综上所述,yolo的基本思想就是“分而治之”,它将图片切分成7x7大小的区域块,然后每个区域设置两个bounding box以适应不同尺度的目标,再在每个区域中去回归目标框。
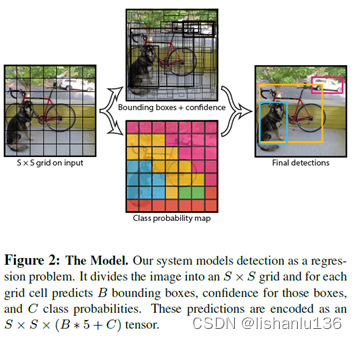
针对于VOC数据设计的YOLO最后输出tensor为7x7x(2x5+20),20代表VOC数据集的类别,不包含背景类。YOLO网络是基于GoogLeNet设计的,总共包含24个卷积层和两个全连接层;Fast YOLO只含有9个卷积层和更少的卷积核,YOLO网络结构如下图:

2.3 YOLO训练过程
有监督的预训练,GoogLeNet用ImageNet1000-class数据集预训练得到top-5精度88%的模型,取前20个卷积层然后接average-pooling和全连接层。对于检测任务,输入由原来的224x224调整到448x448。
输出设置,针对最后一层的概率输出和预测框输出,都归一化到0-1,宽高wh是矩形框宽高与图像的宽高比值,预测框x,y是相对于该区域格子位置的偏移量,所以也是0-1的范围。
损失函数设置,网络最后一层采用线性激活函数,误差采用平方和误差(sum-squared error)。为了处理正负样本不平衡问题,作者将有目标的回归损失和没目标的noobj损失设置了权重,分别为5和0.5。由于平方和误差针对大目标和小目标的权重是一样的,但是目标检测任务需要的是小目标框对小偏差比大目标对小偏差更加敏感,这样才能加大对小目标的学习力度,所以作者对bounding box做了开根号处理。损失函数公式如下:

如何确定区域块(grid)内哪个bounding box负责预测groundtruth?
答:groundtruth中心点落入这个grid内,该grid内的所有bounding box和该groundtruth做IoU,最大IoU对应的bounding box负责预测该groundtruth。
训练设置,基于VOC2007和2012数据集训练了135个epochs,batchsize设置为64,momentum设置0.9,decay设置为0.0005。学习率根据epochs调节:第一个epoch采用10-3->10-2,然后直到75个epoch都采用10-2,75到105个epoch采用10-3,最后105到135采用10-4。为了避免过拟合,作者也采用了dropout和数据增强,dropout rate设置为0.5,数据增强引入了原始图像大小的20%的随机缩放和平移和HSV空间的最高1.5倍的随机调整曝光度和饱和度。
2.4 YOLO推理过程
就像前面描述的那样,网络预测每张图像的98个边界框和每个框的类概率。YOLO的网格设计在边界框预测中加强了空间多样性,通常情况下,一个对象目标落在哪个网格单元是很清楚的,网络也只会预测每个对象的一个框。但是针对于大的同时跨越几个grid cell的目标对象,通常需要用nms(非极大值抑制,Non-maximal suppression)来合并重复预测框了。
2.5 YOLO的限制
YOLO对边界框预测施加了很强的空间约束,因为每个网格单元只能预测两个框,并且只能有一个类。这个空间约束限制了YOLO模型可以预测的附近物体的数量,YOLO模型难以处理成群出现的小物体,比如鸟群。由于预测的bounding box(也就是后面的anchor)设置是基于VOC数据集得到的,所以难以推广到其他宽高比的目标对象。网络结构包含多个下采样,用于预测边界框的特征比较粗糙,后续期待更强的主干网络。
3、实验结果
YOLO与近期Real-Time算法在VOC2007数据集上比较结果如下:
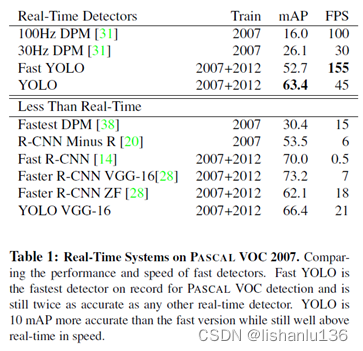
与传统检测算法相比,YOLO在mAP和速度方面都有很大提升,与R-CNN系列深度学习方法相比,都用VGG-16作为主干网络的情况下,mAP有一定差距,但是速度提升很大。
YOLO在VOC2012竞赛上的榜单情况如下:
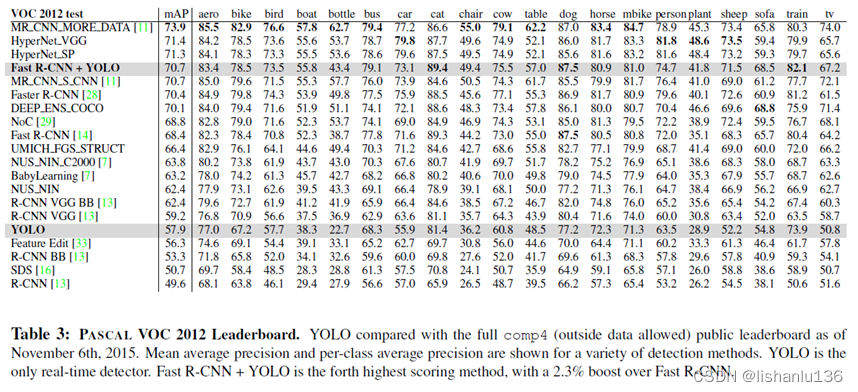
可以看到YOLO算法距离top算法的mAP还有一定差距,特别是在小目标问题上,例如瓶子、羊和电视/监视器等类别。
4、创新点和不足
- 创新点:
1、利用“分而治之”的思想,将检测任务当做回归问题看待,一次完成全部的检测工作,速度极快。
2、基于整张图片提取特征,相比R-CNN系列采用的局部特征得到的背景误报情况少很多。 - 不足:
1、精度相对于R-CNN系列的二阶段检测方法还是有差距,直接预测矩形框坐标的方式不及R-CNN系列基于提议框预测偏移量的方式;
2、网络最终输出的预测框数量限制于区域网络数的设置及bounding box数量设置,对检测密集目标效果不好,对检测小目标也不好;
3、bounding box依照数据集中目标而定,所以难以推广到其他目标,其他目标的话需要修改bounding box的宽高比。
4、YOLO主干网络提取特征能力不足,后续需要改进。
智能推荐
html鼠标循环滚动代码大全,jQuery 列表自动循环滚动鼠标悬停时停止滚动的实现代码(图文)...-程序员宅基地
文章浏览阅读418次。要求实现:页面中一个小的区域循环滚动展示新闻(公告、活动、图片等等),并且,鼠标悬停时停止滚动并提示,离开后,继续滚动。演示效果图:1,html页面代码示例:2,css代码代码示例:ui,li {list-style: none;}#news{height: 75px;overflow: hidden;}3,关键部分---js文件:$(function() {var $this = $("#new..._html实现向上无缝滚动列表,鼠标悬浮时暂停,鼠标离开时继续滚动
python编程手机软件哪个好,用手机编程python的软件_打开代码的软件-程序员宅基地
文章浏览阅读888次,点赞23次,收藏17次。大家好,小编来为大家解答以下问题,python编程手机软件哪个好,用手机编程python的软件,现在让我们一起来看看吧!_打开代码的软件
Syntax Error: Error: Node Sass version 6.0.1 is incompatible with ^4.0.0-程序员宅基地
文章浏览阅读1.2k次。Syntax Error: Error: Node Sass version 6.0.1 is incompatible with ^4.0.0,提示:Error: Rule can only have one resource source (provided resource and test + include + exclude)_syntax error: error: node sass version 6.0.1 is incompatible with ^4.0.0.
大数据框架之Hadoop:HDFS(六)DataNode(面试开发重点)-程序员宅基地
文章浏览阅读760次。DataNode(面试开发重点)_datanode
Python 基于 OpenCV 视觉图像处理实战 之 OpenCV 简单人脸检测/识别实战案例 之七 简单进行人脸检测并添加面具特效实现
Python是一种跨平台的计算机程序设计语言。是一种面向对象的动态类型语言,最初被设计用于编写自动化脚本(shell),随着版本的不断更新和语言新功能的添加,越多被用于独立的、大型项目的开发。Python是一种解释型脚本语言,可以应用于以下领域: Web 和 Internet开发、科学计算和统计、人工智能、教育、桌面界面开发、软件开发、后端开发、网络爬虫。这里使用 Python 基于 OpenCV 进行视觉图像处理,......
使用UmcFramework和unimrcpclient.xml连接多个SIP设置的配置指南及C代码示例
在多媒体通信领域,MRCP(Media Resource Control Protocol)协议被广泛用于控制语音识别和合成等媒体资源。UniMRCP是一个开源的MRCP实现,提供了客户端和服务端的库。UmcFramework是一个基于UniMRCP客户端库的示例应用程序框架,它帮助开发者快速集成和测试MRCP客户端功能。本文将详细介绍如何使用UmcFramework和unimrcpclient.xml配置文件连接到多个SIP设置,以及如何用C代码进行示例说明。
随便推点
Hadoop环境搭建(保姆级教学)_hadoop平台搭建步骤-程序员宅基地
文章浏览阅读5.4k次,点赞10次,收藏64次。HADOOP环境搭建过程详解_hadoop平台搭建步骤
ZooKeeper实战之ZkClient客户端实现负载均衡_zookeeper实现负载均衡案例-程序员宅基地
文章浏览阅读1.9k次。声明:此博客为学习笔记,学习自极客学院ZooKeeper相关视频;非常感谢众多大牛们的知识分享。相关概念:负载均衡(相关节点)架构图:说明:每当往集群中新增一个工作服务器时,都会再/server节点下创建一个对应的临时节点,该节点中应含有该服务器 的连接信息以及均衡标识等。当客户端需要连接worker server时,就会先读取/servers节点下的所..._zookeeper实现负载均衡案例
Android 枚举 VS 枚举注解_android 枚举注解-程序员宅基地
文章浏览阅读448次。枚举注解替换枚举java 虚拟机内存分配java 内存区域可分为方法区 存放虚拟机加载的类信息,常量,静态变量等数据。虚拟机栈 java 方法执行的内存模型:每个方法在执行的时候创建的栈帧,包括存储局部变量表,操作数栈,动态链接,方法出口等信息。本地方法栈 主要与Native相关堆 存放对象实例。程序计数器 当前线程执行的字节码行号指示器。java 数据类型占内存大小java 数据类型分为基本数据类型和引用数据类型。在32位系统上基本数据类型,本文中中的所有内存空间大小都在_android 枚举注解
HDU1715--第i个斐波那契数 大菲波数_返回第i个斐波那契数-程序员宅基地
文章浏览阅读486次。HDU1715:大菲波数求第i个斐波那契数问题(与HDU1316类似,但更简单):总结:数组开多大?题目中让求的最大的是第1000个斐波那契数是多少,由于f[0]不用,所以数组开到1001。import java.util.Scanner;import java.math.BigInteger;public class Main { public static void main..._返回第i个斐波那契数
轻松搭建CAS 5.x系列(5)-增加密码找回和密码修改功能-程序员宅基地
文章浏览阅读418次。概述说明CAS内置了密码找回和密码修改的功能; 密码找回功能是,系统会吧密码重置的连接通过邮件或短信方式发送给用户,用户点击链接后就可以重置密码,cas还支持预留密码重置的问题,只有回答对了,才可以重置密码;系统可配置密码重置后,是否自动登录; 密码修改功能是,用户登录后输入新密码即可完成密码修改。安装步骤`1. 首先,搭建好cas sso server您需要按..._修改cas默认用户密码
springcloud(七) feign + Hystrix 整合 、-程序员宅基地
文章浏览阅读141次。之前几章演示的熔断,降级 都是 RestTemplate + Ribbon 和RestTemplate + Hystrix ,但是在实际开发并不是这样,实际开发中都是 Feign 远程接口调用。Feign + Hystrix 演示: eruka(略)order 服务工程: pom.xml<?xml version="1.0" encoding="U..._this is order 服务工程