知识分享系列四:智算服务-程序员宅基地
智算服务
随着国家“东数西算”工程的启动,算力产业发展进入快车道,推动构建于算力网络之上的算网应用快速发展。伴随大模型训练全真互联等人工智能浪潮的兴起,将全社会带入智算时代,智算服务成为激发数字经济发展的新动能、新引擎,一方面新场景激发算网新应用诞生,另一方面技术演进促进传统算网应用焕发新活力。
对此,国内外已形成建设智算服务共识,通过政策支撑、资金扶持等方式推动智算服务发展,助力其“内修”——从感知、部署技术到调度技术优化,提升智能算力利用率、生产率;“外治”——推陈出新、由浅入深,扩展算网应用场景支持广度与深度。
本文介绍了智算相关的基本概念、智算发展背景、新一代AI基础设施相关内容、智算服务关键技术以及算网应用的未来发展趋势。
目录
2.2.1 传统计算基础设施无法满足大模型、生成式AI的新要求
4.2.1 智能算力感知: 构建智算感知能力体系,为资源细粒度优化提供依据
4.2.2 智能算力共享:精准隔离,有效提升智算应用部署密度
4.2.3 混合部署: 智算应用分级QoS,削峰填谷,充分利用空闲算力
4.3.1 高性能计算: 提升单节点计算能力,并向分布式、混合并行模式演进
4.3.2 高性能网络: 建设高性能通信网络,有效提升智能算力集群性能
4.3.4 计算加速框架: 集成模型工具箱,大幅提升大模型生产效率
5.2 服务模式上,将形成通用应用与专用应用长期并存、高效协同的模式
5.3 发展格局上,跨架构、跨地域“双跨”应用将有力支撑全国算网一体化发展
一、基本概念
1.1 算力
算力的狭义定义是一台计算机具备的理论上最大的每秒浮点运算次数(FLOPS)。但是,计算机不光具有运算能力,还有数据存储与访问能力、与外界的数据交换能力、数据显示能力等。所以广义上,算力是计算机设备或计算/数据中心处理信息的能力,是计算机硬件和软件配合共同执行某种计算需求的能力。常用的计量单位:
- 每秒运算次数(OPS);
- 每秒执行的浮点数运算次数(Flops,1 E Flops = 10^18 Flops);
- 每秒哈希运算次数(Hash/s);
- T=10^12 Tera(兆,万亿),P=10^15 Peta(千兆,千万亿),E=10^18 Exa(百京,百亿亿)。
计算能力的分类:
- 通用计算:以CPU提供计算能力;
- 异构计算:以GPU、NPU、FPGA提供计算能力。
计算能力的量度角度:
- 性能:通俗讲就是完成任务所需要的时间;
- 功耗:功率的损耗指设备、器件等输入功率和输出功率的差额;
- 成本:计算机的成本跟芯片成本紧密相关。
1.2 云计算、超算和智算
云计算、超算和智算相互联系的同时,也各有侧重。数据中心相对应可分为三类:云数据中心、超算中心和智算中心。
表1 云数据中心、超算中心和智算中心对比
| 主要指标 |
云数据中心 |
超算中心 |
智算中心 |
| 建设目的 |
帮助用户降本增效或提升盈利水平 |
面向科研人员和科学计算场景提供支撑服务 |
促进AI产业化、产业AI化、政府治理智能化 |
| 技术标准 |
标准不一、重复建设;CSP内部互联、跨CSP隔离;安全水平参差不齐 |
采用并行架构,标准不一,存在多个技术路线,互联互通难度较大 |
统一标准、统筹规划;开放建设、互联互通互操作;高安全标准 |
| 具体功能 |
能以更低成本承载企业,政府等用户个性化、规模化业务应用需求 |
以提升国家及地方自主科研创新能力为目的,重点支持各种大规模科学计算和工程计算任务 |
算力生产供应平台、数据开放共享平台、智能生态建设平台、产业创新聚集平台 |
| 应用领域 |
在各行各业都有应用 |
基础科学研究、航天、国防、石油勘探、气候建模、基因组测序、地震模拟、药物研发等 |
面向 AI典型应用场景,,在金融风控、智能制造、医疗诊断等场景中展现出巨大潜力 |
| 基础架构 |
通常包括服务器、存储系统、网络设备和数据中心管理系统等,注重可扩展性、灵活性和可靠性 |
通常包括数千个高性能计算机节点、存储系统和网络设备,注重计算性能、存储能力 |
通常包括Al芯片、高性能算力机组、大规模存储系统和高速网络设备,注重AI特定的计算需求 |
| 计算类型 |
分布式计算 |
并行计算 |
分布式计算 |
| 计算方式 |
通过虚拟化技术将多个物理服务器组成一个虚拟化的计算环境 |
采用并行计算的方式,将任务分配给多个计算节点进行计算,节点之间数据交换的延迟要求非常高 |
通常采用分布式计算的方式,将数据分散到多个计算节点上进行处理 |
| “投-建-运”模式 |
行业巨头或者政府投资建设,其它用户按需付费使用;以数据服务盈利,企业自主运营 |
政府科研单位投资建设运营 |
政府主导下的政企合作共建模式政府出资指导建设,企业承建运营 |
1.3 并行计算与分布式计算
计算类型主要有两种,包括并行计算和分布式计算。单个处理器只执行计算机系统中的一个任务,这不是一种有效的方式。
1.并行计算
- 基本思想是用多个处理器来协同求解同一问题,即将被求解的问题分解成若干个部分,各部分均由一个独立的处理机来并行计算;
- 并行计算系统既可以是专门设计的、含有多个处理器的超级计算机,也可以是以某种方式互连的若干台独立计算机构成的集群;
- 并行计算的典型场景:使用一台超级计算机,计算大规模数学问题。
2.分布式计算
- 分布式计算使多台计算机能够相互通信并实现一个目标,所有这些计算机都通过网络进行通信和协作。
如果是在多个计算机运行计算时,采取并行计算的话,多个计算机处理的任务是一样的,单个计算机的多处理器处理的任务是不同的;而采取分布式计算的话,多个计算机处理的任务是不同的。
1.4 算力中心
1.4.1 超算中心
目前,全国国家超级计算中心有14座,分别位于天津、广州、长沙、深圳、济南、无锡、郑州、昆山、成都和西安等城市。
2023年4月17日,科技部启动了国家超算互联网工作,旨在以互联网思维运营超算中心,构建一体化超算算力网络和服务平台。按照计划,到2025年底,国家超算互联网将形成技术先进、生态完善的总体布局。此外,我国还制定了“十四五”期间的超算发展规划,明确了未来将围绕内蒙和成渝两个枢纽进行建设,以满足西部地区和全国各领域的需求。
表2 超算中心介绍
| 序号 |
超算中心 |
介绍 |
| 1 |
无锡超算 |
成立于2006年11月,经国家科技部批准成立,由国家科技部、江苏省和无锡市三方共同投资建设。中心坐落在风景秀丽的江苏省无锡市蠡园经济开发区,拥有世界上首台峰值运算性能超过每秒十亿亿次浮点运算能力的超级计算机——“神威·太湖之光”,峰值125.436P Flops |
| 2 |
天津超算 |
2009年5月批准成立的首家国家级超级计算中心,部署有2010年11月世界超级计算机TOP500排名第一的“天河一号”超级计算机和“天河三号”原型机系统,构建有超算中心、云计算中心、电子政务中心、大数据和人工智能研发环境,峰值1000P Flops |
| 3 |
深圳超算(深圳云计算中心) |
是2009年获国家科技部批准成立的国家级超算中心,为深圳建市以来规模最大的国家级重大科技创新基础设施之一。深圳超算配置了世界Top级超级计算机系统,运算速度达每秒千万亿次。当前,深圳超算已启动升级换代工程,落户光明科学城大科学装置区。2010年9月运营,理论峰值性能3P Flops,二期规划2000P Flops |
| 4 |
长沙超算 |
2010年10月批准组建,是科技部批准建立的全国第三家、中西部第一家国家超级计算中心,由湖南省政府投资建设,湖南大学运营管理,国防科技大学提供技术支撑。中心坐落于湖南大学南校区内,占地面积43.25亩,总建筑面积2.7万平方米 中心拥有“天河”系列超级计算机、“天河·天马”计算集群等计算平台。其中2022年建成的天河新一代主机系统采用全国产设备,峰值计算性能达200P Flops(64位精度),可提供1000P Ops人工智能算力(16位精度) |
| 5 |
济南超算 |
由国家科技部批准成立,创建于2011年,是从事智能计算和信息处理技术研究及计算服务的综合性研究中心,也是我国首台完全采用自主处理器研制千万亿次超级计算机“神威蓝光”的诞生地,总部位于济南市超算科技园 |
| 6 |
广州超算 |
2014年建成,围绕“天河二号”超级计算机推进高性能计算与大数据深度融合。坐落在风景秀丽的广州大学城中山大学东校区,总建筑面积42332平方米(地上5层,约32332平方米),其中机房及附属用房面积约17500平方米,一期峰值100P Flops |
| 7 |
郑州超算 |
2019年4月科技部批复建设的第七家国家超级计算中心,是“十三五”期间国家在河南部署的重大科技创新平台。中心位于“郑州大学国家大学科技园”内,配备新一代高性能计算机——“嵩山”超级计算机,理论峰值计算能力100P Flops,存储容量100PB |
| 8 |
昆山超算 |
2020年,总投资20多亿元的国家超级计算昆山中心建设项目顺利通过科技部组织的专家验收,成为江苏省第二个、国家第八个超级计算中心 |
| 9 |
成都超算 |
坐落于中国西部(成都)科学城兴隆湖畔,项目占地36亩,总建筑面积约6.17万平方米。中心于2020年9月完成一期峰值性能170 P Flops的超算系统建设,总规划300P Flops |
| 10 |
太原超算 |
由山西云时代公司与山西大学共同承建,于2021年10月通电试运行,并于2022年3月底通过科技部验收评审,正式纳入国家序列管理。业务主机及算力:“太行一号”,300P Flops(FP64),800P Flops(FP16) |
| 11 |
西安超算 |
于2020年8月批准成立,是继天津、深圳、广州等之后的第11家国家级超级计算中心。该中心拟建设立足西安、面向西北、辐射一带一路的大数据应用中心,实现计算服务、科研创新、产业创新三位一体的发展平台。项目一期规划具备300 P FLOPS FP16(每秒30亿亿次半精度浮点计算)计算能力,是除深圳鹏城云脑外全国第二大人工智能计算中心,也是西北首个大规模人工智能算力集群中心 |
| 12 |
中新(重庆)互联互通国际超算中心 |
2020年5月开启建设,是中国第一个纯商业超算中心,也是西部地区第一个国际化超算中心。由重庆移动、国家超级计算无锡中心、新加坡MGN公司、新加坡Archanan超算软件公司和寰球超算(重庆)科技公司等联合打造。总投资3亿元,将分为两期建设,一期8.7P Flops,二期38P Flops |
| 13 |
乌镇超算(乌镇之光) |
中心位于乌镇高新技术产业园,总用地30亩,建筑面积约5万平方米,总投资22亿,2022年5月投入正式运营,成为浙江唯一、全国第14个国家超算中心。国家超算乌镇中心一期已建设完成双精度浮点运算理论峰值181.9P,持续性能达到115.1P,存储容量达60PB,计算机网络设备带宽峰值200Gb/s,整体计算能力达到国际TOP10的水平 |
| 14 |
文昌航天超算中心 |
项目建设用地约60亩,总建筑面积2万多平方米,总投资约12亿元,2022年年底投入运营使用 |
1.4.2 智算中心
随着下游算力需求集中的集中爆发和“东数西算”的推进,各级政府、运营商、互联网企业纷纷开启智算中心建设计划。在2023年6月27日举行的中国移动创新技术论坛上,中国移动研究院院长黄宇红表示,公司正在建设的“人工智能大平台”有望作为新型人工智能基础设施,支持国民经济主体使用通用智能大模型和行业大模型,实现对于数据的高质量运用。
1.政府主导建设的智算中心通常作为公共基础设施存在,用于支持地方产业与AI相互融合,推动产业集群化发展。
在“十四五”规划的引领下,目前已有超过30座城市布局智算中心,经典案例包括京津冀大数据智算中心、长沙5A级智能计算中心等。国家工业信息安全发展研究中心发布的《智能计算中心2.0时代展望报告》指出,智算中心已经由1.0 时代的粗放式发展阶段进入到2.0时代的精细化发展阶段,仍需要在通用和专用算力的融合、完善一体化的服务体系、部署能耗低碳化技术、实现算力价格的普惠、从建起来到用起来等方面提供解决方案。
表3 政府主导的智算中心(部分)
| 名称 |
地点 |
建设内容 |
建设进展 |
| 北京数字经济算力中心 |
北京市朝阳区 |
1000P F1ops以上的人工智能算力平台 |
规划阶段 |
| 河北人工智能计算中心 |
廊坊开发区 |
该项目总投资5.9亿元,建筑面积1.2万平方米,规划建设100P计算能力 |
一期完工 |
| 京津冀大数据智能算力中心 |
天津市武清开发区 |
中国电信“天翼云”全国四大云计算核心基地之一,占地面积246亩,规划总建筑面积37.2万平方米,总投资约102亿元 |
一期建成 |
| 天津人工智能计算中心 |
天津市河北区 |
总建筑面积1.57万平方米,总投资约12.7亿元人民币,可提供300P人工智能算力系统 |
一期完工 |
| 长沙5A级智算中心 |
湖南省长沙 |
2022年11月4日揭牌上线。基于“1+N”平台建设模式,采用浸没式相变液冷技术和冷板式冷却技术,PUE 仅为1.04 |
投入运营 |
| 南京智能计算中心 |
南京市麒麟科技创新园 |
AI计算能力达每秒800P |
投入运营 |
| 太湖量子智算中心 |
无锡市滨湖区 |
采用“量子+经典”混合智算中心集群架构,大幅提升算力性能 |
投入运营 |
| 吴淞江智能计算中心 |
江苏省昆山市 |
占地面积89.83亩,建设总面积21万平方米,建成后将重点引进中科寒武纪等领先的智能计算企业 |
一期建设 |
| 宁波人工智能超算中心 |
浙江省宁波市 |
100P(FP16)半精度人工智能算力、50P(FP64)双精度高性能计算算力 |
投入运营 |
| 杭州人工智能计算中心 |
杭州市滨江区 |
前两期已按照140P Flops@FP16 AI算力完成建设,其中AI 算力子系统和AI算力使能子系统采用昇腾技术路线,采用冷板散热和液冷门散热模式,云平台软件服务系统由华为ModelArts AI集群软件服务及华为HCSO混合云平台组成,AI集群网络与安全子系统采用华为及华荣的路由交换及安全设备 2023年12月15日,杭州高新智能科技有限公司发布《杭州人工智能计算中心(三期一阶段)AI集群系统设备采购项目》招标公告,总额 19408.424万元,目标最终达到240P Flops@FP16 AI算力 |
投入运营 |
| 图灵小镇AIGC智算中心 |
杭州市萧山区 |
2023年8月,由萧山区、新华三集团、中国移动浙江公司共建的人工智能新高地图灵小镇在钱江世纪城起笔。经过半年筹备,中心已部署808P先进智算能力,为省市乃至全国的企业、研究机构、高校院所提供AI与通用算力支持、创新应用孵化、科研人才培养等服务 |
投入运营 |
| 淮海智算中心 |
安徽省宿州市 |
总体投资10亿元,全面建成后智能算力性能可达300P/秒 |
建设阶段 |
| 广州人工智能公共算力中心 |
广东省广州市 |
一期规划建设100P人工智能算力,未来五年则规划达到1000P |
投入运营 |
| 成都智算中心 |
成都市高新区 |
算力达到300P FLOPS FP16 |
投入运营 |
| 沈阳人工智能计算中心 |
沈阳市浑南区 |
项目一期建设规模100P FLOPS算力,后期规划扩容至300P FLOPS算力 |
投入运营 |
| 武汉人工智能计算中心 |
武汉东湖高新区 |
一期建设内容包括100P AI算力+4P HPC算力以及215P AI+8P HPC总规模的配套基础设施,二期扩容100P AI算力 |
二期完工 |
| 中原人工智能计算中心 |
河南省许昌市 |
项目整体规划为300P AI算力,总投资15亿元,分两期建设 |
投入运营 |
| 哈尔滨人工智能先进计算中心 |
哈尔滨平房区 |
项目投资4.3亿元,一期运算速度每秒55P |
投入运营 |
2.三大运营商积极发展算力建设、相继开启智算中心的建设探索。
运营商推动建设的智算中心具有一定公共服务属性,成为政府主导的算力基础设施建设的良好补充。
- 中国移动:在“5G 创新引领数智融合共赢”发布会上,中国移动表示将大力推进算力资源建设,争取到2025年突破20百亿亿次/秒(E FLOPS),同时拟于2024年投产中国移动超大规模智算中心。
- 中国电信:提出将打造数网协同、数云协同、云边协同、绿色智能的多层次算力设施体系,构建京津冀区域“1+1+X”智算中心体系,并由北京电信持续赋能京津冀大数据智能算力中心。中国电信在内蒙古、贵州、宁夏等地建设公共智算中心,建设了京津冀大数据智能算力中心、中国电信安徽智算中心(2.2E FLOPS),2023上半年新增智算规模1.8E Flops,达到4.7E Flops,增幅达62%。
- 中国联通:在山东(青岛)、福建、广东(广州)等地积极布局智算项目,与国家超算广州分中心合作,联合建设“国家超级计算广州中心-联通分中心”,将面向9大行业领域提供算力服务,助推数字经济创新发展。
3.以百度、阿里、腾讯为代表的互联网企业也纷纷建设智算中心,以推动自身业务发展更好地推动客户人工智能场景落地。
表4 企业主导的智算中心(部分)
| 名称 |
地点 |
建设内容 |
建设进展 |
| 阿里云张北超级智算中心 |
张家口张北县 |
2022年8月30日,位于张家口张北县的阿里云张北超级智算中心正式启动。总建设规模为12E FLOPS AI算力,是全球最大的智算中心 |
投入运营 |
| 阿里云乌兰察布智算中心 |
内蒙古乌兰察布 |
位于内蒙古乌兰察布市,建设规模为3E FLOPS的 AI算力,可将自动驾驶模型训练提速近170倍,年平均PUE小于1.2 |
建设阶段 |
| 腾讯长三角(上海)人工智能先进计算中心 |
上海市松江区 |
项目总占地236亩,建筑面积超50万平,总投资超450亿元。预计建成后服务器数量将达到80万台,算力是目前世界排名第一的超算中心的10倍,届时将成为全国单体规模最大、达到世界领先水平的数据中心 |
建设阶段 |
| 腾讯智慧产业长三角(合肥)智算中心 |
合肥高新区 |
2021年7月9日正式揭牌,采用腾讯第四代TBlock等高端模块化技术 |
投入运营 |
| 商汤科技人工智能计算中心 |
上海市临港区 |
位于上海市临港区,是华东地区首个落地运营的超大型人工智能计算中心,2022年1月24日,项目启动运营,总建筑面积13万平方米,一期建设5000个机柜,峰值训练算力3.74E FLOPS,存储160PB。 |
投入运营 |
| 百度智能云-昆仑芯(盐城)智算中心项目 |
江苏省盐城市 |
位于江苏省盐城市,算力规模达到200P FLOPS,基于百度人工智能计算架构、昆仑芯通用AI计算处理器、百度百舸·AI异构计算,打造出的可以服务包括全链路自动驾驶研发在内的人工智能技术研发平台 |
投入运营 |
| 百度智能云(济南)智算中心 |
山东济南明水区 |
于2023年3月21日揭牌,是百度落地山东的首个“智算中心基地”,将作为云计算、IOT、大数据、人工智能四大先导产业高地,向整个山东以及华北华东区域辐射。 |
投入运营 |
| 吉利星睿智算中心 |
浙江湖州 |
2024年初,云端总算力已由2023年的81亿亿次/秒,扩容到102亿亿次/秒(1.02 E FLOPS) |
一期建成 |
| 重庆嘉云智能算力中心 |
两江新区水土新城 |
项目整体规划面积约80亩,总投资人民币30亿元 |
投入运营 |
| 克拉玛依浪潮智算中心 |
克拉玛依市 |
项目于2022年2月揭牌,是浪潮集团投资建设的西北五省区第一个智算中心,投资2亿元 |
投入运营 |
| 毫末智行智算中心MANA OASIS——雪湖·绿洲 |
山西大同 |
由毫末智行与字节跳动旗下火山引擎联合打造,于2023年1月发布,是目前中国自动驾驶行业最大智算中心,建成后每秒浮点运算可达670P FLOPS,存储带宽每秒2T,通信带宽每秒800G |
建设阶段 |
二、背景介绍
2.1 大模型、生成式AI推动AI 2.0时代到来
2023年是人工智能发展的分水岭,大模型、生成式AI的发展带动了人工智能领域的范式转换,AI 2.0时代已经来临。在此之前,人工智能通过模式检测或遵循规则来帮助分析数据和做出预测,更像是一种“分类器””,而 AI 2.0 时代则开启了新阶段:基于大模型的生成式AI。生成式AI 可以通过数据训练进而模仿人类的创造过程,将人工智能从传统的“分类器”进化成“生成器”。这样本质上的变化,让 AI发展到了一个全新的时代。Gartner 预测,到 2027年,高速增长的生成式AI将会贡献全球人工智能支出的42%,规模将超过1800亿美元,2023年到2027年的复合增长率高达169.7%。
另外,作为生成式AI发展的基础,大模型也在高速发展。IDC数据显示,截止2023年11月底,中国市场发布的大模型已经超过300个。生成式AI的颠覆性潜能得到越来越多的企业认可,企业不再追问何为生成式 AI,而是希望了解生成式Al的投入能带来哪些具体业务价值。Gartner预测,到2026年,超过80%的企业将使用生成式AI的API或模型,或在生产环境中部署支持生成式AI 的应用,而在2023年初这一比例不到5%。企业通过以下一系列举措,不断推动 AI无处不在的愿景实现:
- 加强生成式AI领域的投资,应用部署获得持续动力;
- 改变现有AI战略,驱动生成式AI覆盖公司业务全流程;
- 拥抱生成式 AI,促使AI与员工实现协同创新。
AI产业链将会一步成熟分化,上下游的产业角色和环节不断增多,开始需要全新的基础设施来实现更好的支撑,其带来的影响如下:
- 智能算力成为AI产业发展的关键支撑要素。大模型训练趋势下,企业将更多地使用AI就绪的数据中心设施或GPU集群,从而缩短部署时间,降低设施的长期投资成本。适合大模型训练的智能算力已经成为算力增长的主要动力。
- 人工智能生产范式转向以大模型为核心的开发路径。
- 作为新的生产力工具,生成式AI应用发展进入大航海时代。最早,以ChatGPT、Midjourney为代表的文生文、文生图应用推向市场并获得高速增长的用户群体。随后,音频生成、视频生成、多模态生成类的应用,以及面向不同行业领域或用户群体的工具类应用,如代码生成、Copilot、数字人、营销工具、聊天助手等,不断推向市场。
2.2 AI 2.0时代对AI基础设施提出了全新要求
进入AI 2.0 时代,传统针对移动互联时代应用、以CPU为中心的云计算基础设施,无法满足大模型训练、生成式AI应用爆发所带来的挑战,这些新的挑战对AI基础设施的关键环节都提出了全新的要求,包括算力、算法平台、数据以及围绕三个环节的工程系统建设:
2.2.1 传统计算基础设施无法满足大模型、生成式AI的新要求
大模型训练、生成式AI应用不仅对GPU或异构计算的需求大幅增加,传统CPU算力已经无法满足;还对GPU集群的计算效率、稳定性等方面的提出诸多要求,算力不是一个简单的堆砌,而是要转为大模型而优化的复杂的系统性工程:
- 以GPU为核心的AI算力需求爆发性增长。以OpenAI为例,训练一次 1750亿参数的GPT-3模型大概需要的算力约为3640 PFlops-day,共使用了1024块A100(GPU)训练34天。GPT-4参数量大约是GPT-3的 500倍,用了约2万-3万张A100,训练1个月左右的时间。
- 高性能和高效率成为算力基础设施的关键。为了更好支持大模型训练,多机多卡组成大集群分布式训练成为必选。但大集群不等于大算力,在分布式训练下,集群中由于网络通信或数据缓存等问题都会造成大型训练效率降低。
- 独占式、大规模、长时间训练对GPU集群稳定性提出更高要求。大模型训练需要长时间占据规模庞大的GPU集群,这导致单个节点发生故障就使得整个训练中断,且故障原因和位置难以迅速界定。以Meta的 OPT-17B训练为例,理论上在1000个80G A100上训练 3000 亿个单词,需要33天,而实际训练却用了90天,期间出现了112次故障,其中主要是硬件故障导致手动重启35次,自动重启约70次。
2.2.2 数据质量和效率决定大模型的高质量发展之路
高质量数据决定大模型性能和价值观,对数据的获取、清洗、标注等工作带来了更大挑战,需要更高效的AI数据管理流程来匹配大模型时代的新需求。而大模型的训练和应用过程还可能涉及用户隐私和敏感数据等,需要采取有效的数据治理手段来保障隐私和数据安全。
- 构建性能强大和价值对齐的大模型,数据质量和效率是关键。传统数据处理“作坊式”的工作模式,已无法满足大模型训练和迭代激增的“工业化”数据需求。打造高效的“智能化数据处理流水线”成为关键,弥补传统重人力投入带来的高成本、低效率等问题。
- 保障数据安全和用户隐私,需要更高效的数据治理手段。企业在使用生成式AI将会面临更加突出的用户隐私和数据安全问题。例如,企业开发人员使用AI代码辅助生成工具时,一般需要上传企业已有代码库,使大模型给出更精准的代码预测结果。
- Maas促进大模型生态体系建立,推动大模型应用规模化落地。Maas 模式有助于AI产业链的高效分工,其中一部分技术实力强和AI专家资源丰富的厂商成为Maas主要提供者。
2.3 智算成科技发展新驱动,各国抢抓智算服务发展机遇
2.3.1 全球各国布局智算服务,拉开新一轮科技竞赛序
伴随智慧出行、智能制造等产业智能化的程度的提升,以及元字宙、大模型等新兴应用场景的发展,全球对智能算力的需求激增,进入了智算服务的新一轮增长期。政策上,美国白宫科技政策办公室发布《国家人工智能战略研发计划》,此政策对AI研发关键领域、投资重点领域等内容进行规范,以确保美国在AI领域的领先地位;2023年,欧盟议会成员就《人工智能法》达成政治协议,该法案将管辖所有人工智能产品或服务的提供方,涵盖可以生成内容、预测、建议或影响环境的决策的系统。算力规模上,根据中国信息通信研究院《中国算力发展指数白皮书(2022年)》统计,2021年全球智能算力规模达232E FLOPS,2030年预计达到52.5Z FLOPS,平均年增速超过80%,占全球算力总规模的93%以上,智算算力将成为全球算力规模增长的主要驱动力。研发投入上,2020年美国《无尽前沿法案》中提出拟在未来5年投入1000亿美元研发包括芯片、人工智能在内的10大关键技术;2021年4月,欧盟以条例的形式通过“数字欧洲计划”,对包括人工智能在内的项目进行投资,总额达75.9亿欧元。
2.3.2 我国大力发展智算服务,产业布局提速
政策上,《新型数据中心发展三年行动计划(2021-2023年)》指出,引导新型数据中心智能化建设,加快高性能智能计算中心部署,支撑各类智能应用。《“十四五”数字经济发展规划》指出要推动智能计算中心有序发展,打造智能算力、通用算法和开发平台一体化的新型智能基础设施,提供体系化的人工智能服务。算力规模上,2021年我国智能算力规模达到104E FLOPS,在我国算力总规模中占比超过50%,增速为85%,成为算力规模增长的主要驱动。2022年中国人工智能核心产业规模已达5080亿元人民币。研发投入上,北京、上海、广东、山东等地设立专项基金用于人工智能相关技术、标准的研发和应用,打造泛在、标准的智算服务。
2.4 算网应用连接技术与用户,多样产业角色入局共建
算网应用构建于算力网络之上,以服务形式将算力网络技术能力统一输出给用户及应用场景。运营商、云服务商等不同产业角色均投入到算网应用的建设中来,运营商依托其强大的网络能力,打造连接云、边、端资源、服务一体化的算力网络,如中国移动《算力网络白皮书》中提出建设“网络无所不达、算力无所不在、智能无所不及”的算力网络;中国电信规划“核心+省+边缘+端”四级架构AI算力网络,提供算网数智等多要素融合的AI算力服务;中国联通将打造基于算网融合设计的服务型算力网络,构建云网边一体化智能调度和能力开放体系。云服务商依托其成熟的虚拟化技术与算力编排调度技术,建设统一资源管理平台,如“星辰算力调度平台”可实现异构算力资源灵活调度、弹性伸缩。
三、新一代AI基础设施
3.1 定义
新一代AI基础设施的定义:以大模型能力输出为核心平台,集成算力资源、数据服务和云服务,专门设计用于最大限度提升大模型和生成式AI应用的表现:数据准备与管理、大模型训练、推理、模型能力调用、生成式AI应用部署。企业通过新一代AI基础设施开发和运行生成式AI业务和客户应用程序,以及基模型和行业模型的训练与微调。
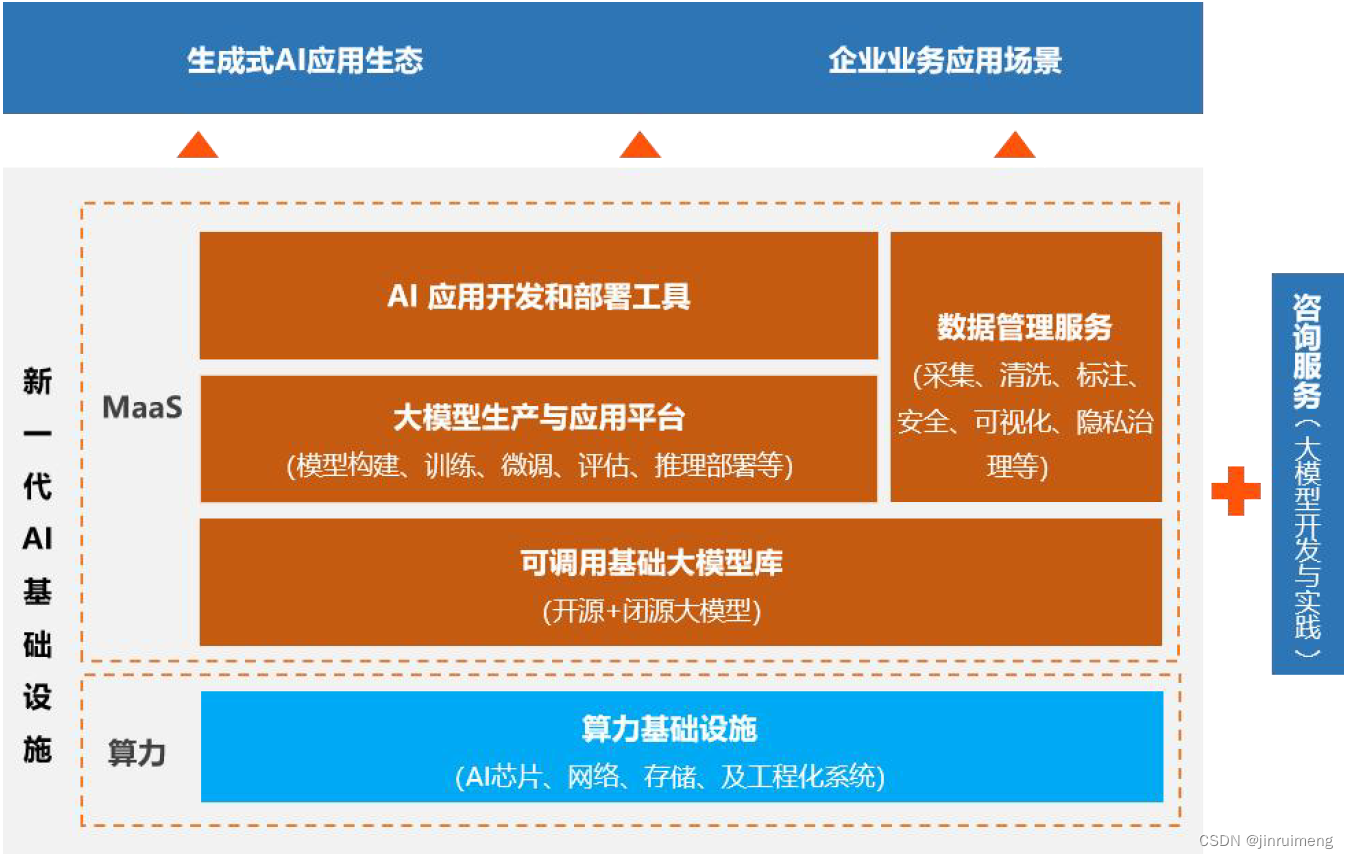
图1 新一代AI基础设施主要由算力、MaaS及相关工具构成
算力基础设施,为大模型训练和推理提供全面的计算、存储等产品及服务,具有“大算力、高协同、强扩展”的基本特性:
- 由高性能异构集群组成强大的算力底座作为算力支撑,具备高互联的计算网络、高性能的文件存储和大规模的AI算力资源。
- 高度的软硬件系统协同为保障,护航大模型任务的高效、稳定运行。在建构硬件层面的算力集群过程中,融合大模型分布式训练对计算、网络、存储的需求特点,高度集成AI软件能力,充分关注数据传输、任务调度、并行优化、资源利用、故障监测等,设计和构建高性能、弹性灵活、高容错的集群系统,保障训练和推理的高效、稳定运行。
- 具备非常强的线性扩展能力,提供弹性灵活的云原生服务。将GPU等 AI算力资源容器化、资源池化,在高弹性、高可用、高安全性的云原生架构下,使算力的管理能力拓展到整个智算中心,实现对AI计算资源的灵活调度远程共享等目标,可以轻易支持万卡万参的大模型训练迭代。
Maas平台层为大模型应用落地提供完整的服务和工具链体系,包括基础大模型库、大模型生产平台、数据管理平台、应用程序开发等主要部分。针对不同用户需求,Maas平台层可以提供不同服务类型:
- 提供预构建的基础大模型及API,包括开源和闭源的大模型,允许用户调用API,直接获取大模型相关的能力和服务,降低客户的使用成本,快速满足多个业务场景需求。
- 提供一站式大模型开发工具及服务,包括模型训练、微调、评估、推理部署等,支持用户训练新的模型,或根据不同行业和业务场景进行微调,快速生成满足自身需求的专属大模型,强化大模型在细分领域的专项能力,推动大模型在不同行业领域的快速落地。
- 提供AI原生应用开发工具,满足用户基于大模型开发AI原生应用需求,赋能和重塑上层AI应用生态发展,为终端用户提供更卓越的生成式AI体验。
- 提供预构建的高质量数据集及AI数据管理服务,包括数据清洗、标注、安全、合规等,降低用户在数据层面上的投入和成本,保障隐私和数据安全。
3.2 主要特点
新一代AI基础设施不是传统云的AI化,两者具有明显定位和发展路径的差别。新一代AI基础设施主要面向产业用户,为超大模型研发训练、区域行业及应用孵化创新提供AI基座,并跟随产业区域落地向周边辐射,通过可持续运营带动区域经济智能化发展。
- “建运一体”的智算中心充分发挥基础设施效益,支持区域智能化经济发展。智算中心不仅是新一代AI基础设施的物理载体,还是集公共算力服务、数据开放共享、智能生态建设和产业创新聚集四大功能于一体的综合服务平台。国家信息中心《智能计算中心创新发展指南》测算,在智算中心实现80%应用水平下,区域对智算中心的投资可带动AI核心产业增长2.9~3.4倍、带动相关产业增长约36~42倍。因此,“建好”智算中心不是目的,只有“用好”才能发挥效益。
- “大中心+节点”布局,建设跨地域互补、协同调度的超大规模AI算力网络。大模型研发及预训练需要低成本、大规模的AI算力资源支持,而在应用阶段会更注重满足训练和推理一体需求。如何平衡不同需求下的算力供给,最大效率的使用算力资源非常关键。
- 侧重国产化生态建设,增强基础设施的自主可控。搭建基于国产软硬件的AI基础设施,研发全栈国产化大模型,逐步形成自主可控的AI大模型产业生态关乎国家安全和战略发展。

图2 新一代AI基础设施面对的是不同于传统云的业务要求
3.3 社会价值
新一代AI基础设施降低了大模型开发和应用的门槛,在政企服务、产业和科研创新等方面创造更大的社会价值。具体来看包括三方面:
- 构建政务大模型,“一模通办”为政务服务提质增效。将原本分散、碎片化的政务应用,用一个性能强大、底座统一的大模型来承载,将大模型能力融入到数字政府的全流程场景中,无需为不同场景重复开发。
- 打造人工智能产业高地,大模型激发区域产业创新活力。一方面,将加快推进传统产业上下游各个环节的智能化转型。例如,在农业领域,可以结合遥感数据开发出专属的遥感农业大模型,将AI技术下沉到水田农地,在种植业监测、耕地用途管理、涉农金融等细分领域助力数字农业技术的升级和推广。另一方面,将催生新业态、新模式的不断涌现。例如,Maas 模式将重塑传统云服务市场格局,将会出现大量行业大模型精调企业,作为通用大模型和企业之间的中间层,助力通用大模型转化为行业大模型。还有海量 A1原生应用开发企业、云原生安全创新公司等,将打通产业智能化的最后一公里。
- 赋能科学大模型,激发人工智能驱动科学研究(Al for Science)的新范式。基于大模型对原子运动规律、物质性质等进行预测和模拟,也可对医学图像天文图像等进行更好的识别和理解,加速科学实验的自动化和智能化,实现自动化合成、自动化表征等。目前,在生物制药、气象预报、地震探测、材料研发等科研领域,大模型技术已带来了巨大的突破。
3.4 企业价值
基于新一代AI基础设施,企业可以高效部署生成式AI应用,充分利用生成式AI推动各项创新优化。具体来看:
- 帮助企业实现业务洞察和流程优化,提高决策和生产效率。大模型可以提供高效的数据分析和预测功能,帮助企业提升决策效率,还可以帮助企业实现流程自动化,减少重复劳动,从而提高生产效率。
- 推动大模型应用融入日常办公中,改变工作模式的同时提升员工效率。大型能够帮助员工快速写文本、写PPT、写代码、分析报表等,成为员工的办公助手。
- 帮助企业在个性化、智能化服务等方面进一步提升客户价值。企业可以基于大模型能力,为客户提供个性化产品和服务,也可以结合生成式AI、数字人等,以更自然、智能化的交互形式,成为客户的个性化助手。
- 为企业在产品/服务、业务模式、技术等方面提供更大的创新空间。企业创新投入高,大模型技术可以有效降低创新试错成本,同时加大创新发现的可能。

图3生成式AI为企业带来四方面业务红利
3.5 厂商格局
AI 2.0时代出现了两个新的市场发展空间,一个是基于大模型的生成式AI应用,也是爆发最快,但是落地机会依然处于探索期;另外一个则是为大模型和生成式AI提供基础设施,包括算力、MaaS等一系列服务,进而支撑前者的高速发展。“要想富,先修路”,新一代AI基础设施就是AI 2.0时代的“路”,是支撑大模型、生成式AI繁荣发展的基座。在此背景下,AI基础设施市场在2023年进入高速发展阶段,越来越多的厂商进入,根据自身产品技术的布局和优势提供AI基础设施服务体系。
AI基础设施市场依然处于高速竞争的初级阶段,从进入该市场不同厂商的所属类别来看,AI基础设施厂商格局基本由云计算、AI原生、硬件系统三类厂商构成。三类厂商的业务出发点和产品规划方向分别具有以下特点:
- 云计算厂商依托其成熟的云平台加强 AI 相关产品体系的建设。此类别厂商以阿里云、百度智能云等传统云计算厂商为代表,在大模型、生成式AI爆发之际,全面升级云计算基础设施以适应AI 2.0时代对基础设施提出的新要求。升级手段包括启动GPU集群的建设和相应工程化系统建设,加强原机器学习平台面向大模型的分布式训练能力,高带宽网络的连接,以及培育自身对AI技术发展的理解等。2023年11月,阿里云在云栖大会上宣布,面向智能时代,阿里云将通过从底层算力到AI 平台再到模型服务的全栈技术创新,升级云计算体系。2023年12月,百度表示,为满足大型落地需求,正在基于“云智一体”战略重构云计算服务。
- AI原生厂商基于领先的AI产品体系的积累进一步巩固算力资源投入。“春江水暖鸭先知”,作为长期浸淫AI产业的AI原生厂商,以商汤科技、科大讯飞为代表,也在不断加强基础设施产品矩阵的规划。由于已经拥有成熟的AI原生产品技术以及领先的经验洞察,此类厂商更加重视的是在算力资源层面的布局,以及逐步发展开拓以云服务为核心的交付能力,同时也在不断加强对于Maas平台的建设。2021年初,商汤科技正式对外公布其AI基础设施战略布局,并建设上海临港AIDC作为 AI基础设施的物理载体,力求打通算力、算法和平台,全面构建面向AI时代的基础设施。
- 硬件厂商凭借算力产品的优势布局逐步加强AI产品技术的布局。传统硬件厂商,分别从自身原有的服务器或芯片开始加强布局AI基础设施,满足用户的训练与推理需求。IDC数据显示,作为服务器市场中的关键组成部分,AI服务器市场增速最高,2023 年中国市场规模将达91亿美元,同比增长82.5%,2027年将达到134美元,五年年复合增长率为 21.8%,此领域的代表厂商有浪潮、新华三等。浪潮作为AI服务器出货量领先的厂商之一还在不断加强对AI平台能力的补齐,同时在近期推出了“源 2.0”基础大模型,并宣布全面开源,进一步完善自身的AI基础设施体系。
表5 新一代AI基础设施厂商格局一览
| 云计算厂商 |
AI原生厂商 |
硬件系统厂商 |
|
| 主要特征 |
从云计算进入AI基础设施市场,重点提升算力层面的智能化、加强Maas服务能力 |
从AI原生进入AI基础设施市场,重点加强算力层面的建设和云交付能力的构建 |
从传统算力设备进入AI基础设施市场,重点布局AI相关的产品技术与应用服务 |
| 优势 |
具有丰富节点布局的云数据中心,以及经受过业务发展锤炼的云计算平台及相关产品 |
领先的技术积累使其能够快速进入并领先于生成式AI 发展趋势,同时拥有深厚的AI落地应用的经验,基础设施从一开始就是面向AI原生体系 |
深度研发算力硬件设施,如 AI服务器、AI 芯片,不断提升计算能力和处理效率,在算力层拥有领先的技术储备 |
| 挑战 |
面对AI 2.0时代,需要加强生成式AI技术的研发能力和储备,对现有的云计算基础设施进行全面升级和重构 |
加强算力资源的投资与建设,尤其要开始布局智算中心网络并提升商业化运营能力 |
需补齐AI相关的技术积累和产品矩阵,还要思考如何从硬件供应商向技术服务提供商的身份转变 |
| 代表厂商 |
阿里云、百度智能云、火山引擎、腾讯云等 |
第四范式、科大讯飞、旷视、商汤科技等 |
华为、寒武纪、浪潮、新华三等 |
四、智算服务关键技术
智算服务通常包括算力资源、算法模型、算力应用等多种服务,用户可以根据需要灵活选择和组合使用。智算服务广泛应用于机器学习、大数据分析、科学计算、图像处理等领域,在朝着绿色、多模态、泛在演进。
4.1 智算服务发展聚焦绿色、多模态与泛在
4.1.1 绿色:用“连接”引领低碳生活,助力产业低碳转型
在数字经济时代,计算力即生产力。但随着算力的增长,数据中心的能耗也在增加。在碳达峰和碳中和的背景下,提高效率、降低能耗是未来产业发展的一个重要课题。加快实现自身运营的碳中和,是企业碳中和行动的首要目标。
大型数据中心、边缘数据中心和5G基站等更多信息化基础设施建设进一步使得电信运营商的能耗成本支出和碳排放快速增长,给电信运营商的可持续发展带来巨大挑战。在“双碳”背景下,如何实现自身降碳目标,并保持可持续增长成为电信运营商在数字经济时代亟待解决的问题。三大电信运营商均已发布碳达峰碳中和绿色行动计划,全面启动双碳绿色行动,用创新催生“新绿色”。中国移动发布的《碳达峰碳中和白皮书》,明确了“十四五”节能降碳工作目标:到“十四五”期末,公司单位电信业务总量综合能耗、单位电信业务总量碳排放下降率均不低于20%,企业自身节电量较“十三五”翻两番、超过400亿度,企业2025年自身碳排放控制在5600万吨以内,助力经济社会减排量较“十三五”翻一番、超过16亿吨。中国联通发布《“碳达峰、碳中和”十四五行动规划》,聚焦5大绿色发展方向。一是推动移动基站低碳运营,推广极简建站、潮汐节能等技术,有席提高清洁能源占比;二是建设绿色低碳数据中心,通过供电降损简配、空调利用自然冷源等,提高系统能效;三是深入推进各类通信机房绿色低碳化重构;四是加快推进网络精简优化,老旧设备退网;五是提高智慧能源管理水平。中国电信发布的碳达峰、碳中和行动计划是在“十四五”期末,实现单位电信业务总量综合能耗和单位电信业务总量碳排放下降23%。在“十四五”期间,实现4/5G网络共建共享节电量超过450亿度,新建5G基站节电比例不低于20%:大型、超大型数据中心占比超过80%,新建数据中心PUE低于1.3。另外,下一步中国电信将重点从三个方面推进“双碳”工作:一是建设绿色新云网,打造绿色新运营;二是构建绿色新生态,赋能绿色新发展;三是催生绿色新科技,筑牢绿色新支撑。腾讯于2022年2月发布《腾讯碳中和目标及行动路线报告》,以“减排和绿色电力优先、抵消为辅”的原则,包括节能提效、可再生能源替代、碳抵消等,提出“不晚于2030年,实现自身运营及供应链的全面碳中和。”从节能提效、可再生能源、碳抵消等三个方面开展重点行动,用科技助力实现零碳排放。通过引领绿色低碳生活、助力产业低碳转型,推动社会经济可持续发展。
4.1.2 多模态:AIGC技术大爆发,成为数智发展新引擎
基础的生成算法模型不断突破创新。比如为人熟知的GAN、Transformer、扩散模型等,这些模型的性能、稳定性、生成内容质量等不断提升。得益于生成算法的进步,AIGC现在已经能够生成文字、代码、图像、语音、视频、3D物体等各种类型的内容和数据。
多模态技术推动了AIGC的内容多样性,进一步增强了AIGC模型的通用化能力。多模态技术使得语言文字、图像、音视频等多种类型数据可以互相转化和生成。比如CLIP模型,它能够将文字和图像进行关联,并且关联的特征非常丰富。这为后续文生图、文生视频类的AIGC应用的爆发奠定了基础。
4.1.3 泛在:让智能算力像水一样流动,随时随地按需取用
智算服务的泛在化意味着更多的人可以获得高效的计算资源和先进的机器学习算法,不再需要拥有昂贵的硬件设备或深厚的技术背景。更多的企业和个人可以基于业务,利用先进的算力和模型,开发出更加创新和高效的算力应用和服务,从而推动整个产业的快速发展。
4.2 资源全面感知、精准调度,提升智能算力利用率
当前算力资源的使用还处于粗放式的发展,从目前的统计数据来看,算力的使用率低于30%,造成了大量的计算资源和能源成本的浪费。
大量算力应用场景对算力资源的某些方面的可用性存在特殊要求,不同在线或离线业务对算力服务的质量要求于差万别。从供给侧来看,传统无差别算力服务提供模式无法为差异化应用需求提供个性化的可靠保障。按同样的要求进行规划保障,容易造成算力资源大量浪费或无法满足业务需求的两种极端情况。因此在提升算力利用率的同时,需要保障算力服务的可用性。通过算力虚拟化、算力隔离、算力感知、混合部署和调度等技术,来实现不同SLA要求的智算服务的可靠性保障。
4.2.1 智能算力感知: 构建智算感知能力体系,为资源细粒度优化提供依据
算力感知是算力调度的基础,通过建立算力感知的技术指标体系,一方面可定义业务应用的算力参数需求,如计算性能、网络时延等,另一方面定义算力运行的可观测性指标,包括全维度硬件O0S指标,如CPU、IO、内存、网络等。
通过算力应用的运行情况,可对算力应用进行画像,感知业务实际的资源用量,为业务智能推荐资源需求,智能预测峰值算力资源,做到按需弹性扩缩容,随取随用。
4.2.2 智能算力共享:精准隔离,有效提升智算应用部署密度
随着机器学习的不断发展,GPU的性能越来越强,提供并行算力已非常普遍。在实际的使用过程中,通常将完整的GPU卡分配给一个容器,对于模型开发和模型推理等场景资源浪费严重。因此通过GPU共享技术,可有效的提升算力应用的部署密度,提升GPU的利用率。
GPU共享需要解决容器间算力和显存精细隔离的问题,支持算力和显存的灵活配置,从而在精细切分GPU资源,最大程度保证业务稳定的前提下,大幅提升GPU利用率,以达到节约GPU资源成本的目的。同时需具备良好的兼容性和云原生的支持,实现业务无感接入。
4.2.3 混合部署: 智算应用分级QoS,削峰填谷,充分利用空闲算力
提高算力集群资源利用率,可对不同优先级的业务应用进行混合部署,通过不同的组合方式,如错峰业务组合、计算型和内存型任务的组合等,运行更多的算力任务。混合部署对算力隔离和精细调度要求高,只有对计算和显存提供强有力的QoS保障和完全的隔离能力,才能使得算力共享带来的利用率提升的同时,满足不同算力服务的可用性要求。
4.2.4 智能算力调度:一体化精准调度,最大化算力价值
通过算力感知,可分析算力的整体效率,提供可靠、便利、智能的算力调度优化技术方案,以满足算力应用的分级QoS和SLA要求,实现算力的调度优化。
算力调度的优化包括节点亲和性调度、基于负载的动态调度、基于SLA保障的重调度等。利用亲和性调度找到适配业务任务的资源,通过动态调度实现资源的总体负载优化,同时通过重调度保障业务的可用性。
基于动态调度策略,可解决资源碎片的问题,提高装箱率回收业务波谷时的冗余,通过算力应用弹性和混合部署,做到按需使用。对于固定资源池,对负载峰值在不同时段的在线应用、离线应用进行混部,做到分时复用,实现资源的池化、共享以及隔离。
4.3 提升智算生产率,推动算力泛在化发展
智算生产率提升指的是通过技术手段实现生产效率和质量的提升,降低生产成本,提高竞争力。智算生产率提升还有助于节约资源,实现经济可持续发展。因此,智算生产力提升已经成为算力经济低碳化、普惠化发展的重要手段,是推动社会进步和经济发展的重要动力之一。
智算生产率体现了智能计算技术在生产过程中所创造的产出价值与所投入资源之比,反映了智能计算技术在生产中创造价值的效率和贡献。
以大模型生产为例,近几年NLP预训练模型规模的发展,模型已经从亿级发展到了万亿级参数规模。2018年BERT模型最大参数量为3.4亿,2019年GPT-2为十亿级参数的模型。2020年发布的百亿级规模有T5和T-NLG,以及千亿参数规模的GPT-3。在2021年末,Google发布了Switch Transformer,首次将模型规模提升至万亿。
然而硬件发展的速度难以满足Transformer模型规模发展的需求。近四年中,模型参数量增长了十万倍,随着模型训练的要求越来越高,动辄需要数千卡的资源投入,需要更多的算力和时间,这导致了更高的资源成本。
因此,提高智能算力的生产率,能有效的减少算力投入的门槛,缩短生产时间,是算力普惠的关键路径。智算生产率提升的关键一方面在于构建高性能智算集群平台能力,包括提供高性能的计算、网络、存储能力,另一方面在于提供智算的加速框架层优化及模型优化等。高性能智算集群是基于高性能计算和人工智能技术的计算机集群,旨在提供更高的计算性能和更快的人工智能应用速度。高性能智算集群可用于执行大规模、高计算密度的人工智能任务,如NLP预训练模型,它可以提供更快的计算速度和更高的精度,以便处理大型数据集和复杂的计算任务。通过对算力、网络架构和存储性能进行协同优化,能够为大模型训练提供高性能、高带宽、低延迟的智算能力支撑。高性能智算集群具备计算性能强、通信能力强、存储读取快等特点。
4.3.1 高性能计算: 提升单节点计算能力,并向分布式、混合并行模式演进
大模型进入万亿参数时代,训练数据量和模型参数量发生了两个关键层次的变化,一是随着数据量的扩大,从单卡训练转变为分布式训练,二是数据并行训练升级到多维混合并行训练。
在数据并行方案中,数据集被切分成后分配给各卡并行处理。每张卡上运行完整的模型,保证了各卡之间模型的一致性。在模型参数特别大的情况下,如千亿级别,单卡已无法容纳完整模型,因此除数据并行外,需要同时采用模型并行的方案,实行多维的混合并行训练。
因此在构建高性能算力集群,需要对处理器、网络架构和存储性能进行全面优化,一方面优化单计算节点运行时的I/O、CPU预处理、CPU/GPU数据通信、GPU计算等方面的性能开销,另一方面需要解决大模型场景下多节点协作的性能损耗问题,为大模型训练提供高性能、高带宽、低延迟的高性能计算支撑。
4.3.2 高性能网络: 建设高性能通信网络,有效提升智能算力集群性能
当模型达到一定规模时,需要实现分布式的多维混合并行训练,计算节点间存在海量的数据交互需求。随着集群规模扩大,通信性能会直接影响训练效率,通过高性能网络架构保障算力性能的线性增长是有效发挥算力集群性能的关键因素。如“东数西算”宁夏枢纽搭建的智算无损网络,实现单GPU服务器之间800G的大带宽;“星脉”网络搭载了3.2T的超高通信带宽,在同样的GPU卡上星脉网络相较前一代网络,将集群整体算力提升20%。高性能通信网络使得超大算力集群能保持优秀的通信开销比和吞吐性能,并支持单集群高达十万卡级别的组网规模,满足更大规模的大模型训练及推理。
另外面对定制设计的高性能组网架构,开源的集合通信库(比如NCCL)并不能将网络的通信性能发挥到极致,从而影响大模型训练的集群效率。为此需要开发高性能通信加速库,在网卡设备管理、全局网络路由、拓扑感知亲和性调度、网络故障自动告警等方面融入了高性能定制设计的解决方案,以此提升大模型训练的集群效率,优化大模型训练的负载性能,减少网络原因导致的训练中断问题。
4.3.3 高性能存储: 提升缓存命中率,降低数据读取耗时
大量计算节点同时读取一批数据集,需要尽可能缩短加载时长。对于文件存储、对象存储架构,需要具备TB级吞吐能力和千万级IOPS,充分满足大模型训练的大数据量存储要求。
超大带宽:可以提供超大的内网带宽,满足机器学习场景大带宽需求。
多数据源支持:可对接多种数据源,允许存储任意规模的结构化、半结构化、非结构化数据。
性能加速:通过数据多级加速服务,实现超越本地HDFS的性能。可以利用数据加速器结合对象存储作为数据存储底座的成本优势,为数据生态中的计算应用提供统一的数据入口,加速海量数据分析、机器学习、人工智能等业务访问存储的性能。相比直接读写对象存储上的数据,数据加速器能够为上层计算应用带来十倍以上的性能提升,极大地提高生产效率。此外,数据加速器需要具备分布式集群架构,具备弹性、高可靠、高可用等特性;为上层计算应用提供统一的命名空间和访问协议,方便用户在不同的存储系统管理和流转数据。
4.3.4 计算加速框架: 集成模型工具箱,大幅提升大模型生产效率
数据科学是推动AI发展的关键力量之一,而AI能够改变各行各业。 但是,驾驭AI的力量是一个复杂挑战。 开发基于AI的应用程序涉及许多个步骤(包括数据处理、特征工程、机器学习、验证和部署),而且每个步骤都要处理大量数据和执行大规模的计算操作。需要使用加速计算技术加速数据科学工作流。
以NVIDIA为例,推出软件加速库的集合CUDA-XAl来加速计算。这些库建立在CUDA(NVIDIA的开创性并行编程模型)之上,提供对于深度学习、机器学习和高性能计算必不可少的优化功能。这些库包括cuDNN(用于加速深度学习基元)、CuML(用于加速数据科学工作流程和机器学习算法)、NVIDIA TensorRT(用于优化受训模型的推理性能)、cuDF(用于访问pandas之类的数据科学API)、cuGraph(用于在图形上执行高性能分析)等。这些库加快了基于 A1 的应用程序的开发和部署速度。
但随着模型参数的快速增长,万亿参数的模型训练仅参数和优化器状态便需要1.7TB以上的存储空间,至少需要数百张高端训练卡,这还不包括训练过程中产生的激活值所需的存储。在这样的背景下,大模型训练受限于巨大的准入门槛。
在大模型训练中,多级存储访问带宽的不一致很容易导致硬件资源闲置,如何减少硬件资源的闲置时间是大模型训练优化的一大挑战。
模型训练时的模型状态存储于CPU中,在模型训练过程中会不断拷贝到GPU,这就导致模型状态同时存储于CPU和GPU中,这种冗余存储是对本就捉肘见襟的存储空间的严重浪费,如何彻底的去处这种冗余,对低成本训练大模型至关重要。
如在存储优化方面,可采用显存、内存统一存储视角,来扩充存储容量的上限。如太极AngeIPTM,基于ZERO策略,将模型的参数、梯度、优化器状态以模型并行的方式切分到所有GPU,自研ZeRO-Cache框架把内存作为二级存储ofload参数、梯度、优化器状态到CPU内存,同时也支持把SSD作为第三级存储。
综合以上分析,算力作为数字经济时代的重要生产力,其产出不仅和算力的投入有关,同时和算力的利用率、生产率、以及算力服务化的水平相关。通过提升算力的利用率和生产率可大幅优化算力的投入产出比。
电信运营商作为算力网络建设的主要参与方,在碳达峰和碳中和的背景下,通过技术演进,提高算力效率、降低能耗,是其实现产业碳中和的关键路径;而电信运营商通过算力赋能干行百业的高质量发展,必然要求实现算力随取随用的泛在化和无限可能的智能化。
云服务商在智算中心建设、智算云效能增强、视频云算力平台建设、算力资源融合等应用场景与电信运营商能形成较好的能力互补,在算力优化方面,采用驱动层的GPU共享技术、基于内核层的算力感知和隔离技术、基于调度层的成本优化组件,来提升整体算力利用率;在智算生产方面,采用基于网络层的高性能RDMA网络通信加速库,基于框架层输出统一视角存储管理、高性能MOE、自动流水并行等框架加速能力,基于模型层的算子、编译、计算图等模型优化能力,全面提升智算生产率;在算力服务应用方面,采用音视频编解码、传输、识别、质检、增强等解决方案,提升场景化连接能力。
五、算网应用未来发展趋势
5.1 应用发展上,MaaS 将引领算网应用新一轮产业变革
模型即服务(Model as a Service)是指通过云服务将数据处理和机器学习模型的功能集成到现有业务中,为企业提供智能化、自动化的解决方案。通过MaaS 的数据处理、数据分析、智能决策、模型训练等能力,帮助客户构建自有的行业大模型应用,将成为算网应用的新发展方向。MaaS支持用户直接访问和使用典型模型,无需在模型开发和训练投入更多精力,极大地节省了时间和资源投入。MaaS有效支撑算网新应用深化产业渗透,将成为提升企业和个人生产与生活效率的主要方式之一。
5.2 服务模式上,将形成通用应用与专用应用长期并存、高效协同的模式
“通用算力+专用算力”将成为人工智能算力基础设施的关键。算力基础设施应满足广泛应用场景的通用性,并支持高要求个性化应用场景的高效性。随着全球数据量的指数级增长,人工智能、区块链、数据中心和边缘计算等场景对算力的需求不断增强,为了应对多元化的算力需求和应用场景,未来基础计算架构将不断引入更多种类的基础资源来加速计算,除基础通用计算的CPU计算单元外,还包括如GPU、DPU以及AI加速芯片等异构资源以及专用硬件计算芯片等。现阶段芯片提供商多依靠自身硬件条件构建计算架构,彼此之间存在较大差异,难以实现应用跨架构的开发、迁移等。未来将通过开源框架、开源接口等方式建立统一、规范且支持屏蔽底层软硬差异的计算架构平台,支撑不同类型资源间实现联合协作,从底层优化算力服务性能。
5.3 发展格局上,跨架构、跨地域“双跨”应用将有力支撑全国算网一体化发展
算力服务依托相对成熟的云计算技术,综合考虑用户计算需求,算力、网络等多样资源状态,构建全域一体、算网融合的多要素融合编排体系,完成从调度单一资源到调度多样资源的跃迁。具备多要素融合编排调度能力的算网大脑产品已成为算力服务在融合调度领域的典型落地实践,将来,可以根据算力的性能、模态、单价等信息的综合判断,形成可支持跨架构、跨地域的算网编排方案,并完成相关资源部署,以支多场景运算需求。
参考文献
1. 2023新一代人工智能基础设施白皮书——商汤科技&智算联盟
2. 2023智算赋能算网新应用白皮书——腾讯云
3.并行计算和分布式计算的区别——https://www.vsdiffer.com/vs/parallel-computing-vs-distributed-computing.html
4.并行计算和分布式计算有什么区别——https://www.yisu.com/zixun/237954.html
5.我国的超算中心、智算中心、数据中心有多少?在哪里?啥规模?——https://blog.csdn.net/j6UL6lQ4vA97XlM/article/details/131136640
6.我国算力处高增长阶段,全国30城建智算中心|新京智库——https://baijiahao.baidu.com/s?id=1774800921059026749&wfr=spider&for=pc
7.智算中心建设方兴未艾,产业链有望持续受益——华创证券研究所
智能推荐
while循环&CPU占用率高问题深入分析与解决方案_main函数使用while(1)循环cpu占用99-程序员宅基地
文章浏览阅读3.8k次,点赞9次,收藏28次。直接上一个工作中碰到的问题,另外一个系统开启多线程调用我这边的接口,然后我这边会开启多线程批量查询第三方接口并且返回给调用方。使用的是两三年前别人遗留下来的方法,放到线上后发现确实是可以正常取到结果,但是一旦调用,CPU占用就直接100%(部署环境是win server服务器)。因此查看了下相关的老代码并使用JProfiler查看发现是在某个while循环的时候有问题。具体项目代码就不贴了,类似于下面这段代码。while(flag) {//your code;}这里的flag._main函数使用while(1)循环cpu占用99
【无标题】jetbrains idea shift f6不生效_idea shift +f6快捷键不生效-程序员宅基地
文章浏览阅读347次。idea shift f6 快捷键无效_idea shift +f6快捷键不生效
node.js学习笔记之Node中的核心模块_node模块中有很多核心模块,以下不属于核心模块,使用时需下载的是-程序员宅基地
文章浏览阅读135次。Ecmacript 中没有DOM 和 BOM核心模块Node为JavaScript提供了很多服务器级别,这些API绝大多数都被包装到了一个具名和核心模块中了,例如文件操作的 fs 核心模块 ,http服务构建的http 模块 path 路径操作模块 os 操作系统信息模块// 用来获取机器信息的var os = require('os')// 用来操作路径的var path = require('path')// 获取当前机器的 CPU 信息console.log(os.cpus._node模块中有很多核心模块,以下不属于核心模块,使用时需下载的是
数学建模【SPSS 下载-安装、方差分析与回归分析的SPSS实现(软件概述、方差分析、回归分析)】_化工数学模型数据回归软件-程序员宅基地
文章浏览阅读10w+次,点赞435次,收藏3.4k次。SPSS 22 下载安装过程7.6 方差分析与回归分析的SPSS实现7.6.1 SPSS软件概述1 SPSS版本与安装2 SPSS界面3 SPSS特点4 SPSS数据7.6.2 SPSS与方差分析1 单因素方差分析2 双因素方差分析7.6.3 SPSS与回归分析SPSS回归分析过程牙膏价格问题的回归分析_化工数学模型数据回归软件
利用hutool实现邮件发送功能_hutool发送邮件-程序员宅基地
文章浏览阅读7.5k次。如何利用hutool工具包实现邮件发送功能呢?1、首先引入hutool依赖<dependency> <groupId>cn.hutool</groupId> <artifactId>hutool-all</artifactId> <version>5.7.19</version></dependency>2、编写邮件发送工具类package com.pc.c..._hutool发送邮件
docker安装elasticsearch,elasticsearch-head,kibana,ik分词器_docker安装kibana连接elasticsearch并且elasticsearch有密码-程序员宅基地
文章浏览阅读867次,点赞2次,收藏2次。docker安装elasticsearch,elasticsearch-head,kibana,ik分词器安装方式基本有两种,一种是pull的方式,一种是Dockerfile的方式,由于pull的方式pull下来后还需配置许多东西且不便于复用,个人比较喜欢使用Dockerfile的方式所有docker支持的镜像基本都在https://hub.docker.com/docker的官网上能找到合..._docker安装kibana连接elasticsearch并且elasticsearch有密码
随便推点
Python 攻克移动开发失败!_beeware-程序员宅基地
文章浏览阅读1.3w次,点赞57次,收藏92次。整理 | 郑丽媛出品 | CSDN(ID:CSDNnews)近年来,随着机器学习的兴起,有一门编程语言逐渐变得火热——Python。得益于其针对机器学习提供了大量开源框架和第三方模块,内置..._beeware
Swift4.0_Timer 的基本使用_swift timer 暂停-程序员宅基地
文章浏览阅读7.9k次。//// ViewController.swift// Day_10_Timer//// Created by dongqiangfei on 2018/10/15.// Copyright 2018年 飞飞. All rights reserved.//import UIKitclass ViewController: UIViewController { ..._swift timer 暂停
元素三大等待-程序员宅基地
文章浏览阅读986次,点赞2次,收藏2次。1.硬性等待让当前线程暂停执行,应用场景:代码执行速度太快了,但是UI元素没有立马加载出来,造成两者不同步,这时候就可以让代码等待一下,再去执行找元素的动作线程休眠,强制等待 Thread.sleep(long mills)package com.example.demo;import org.junit.jupiter.api.Test;import org.openqa.selenium.By;import org.openqa.selenium.firefox.Firefox.._元素三大等待
Java软件工程师职位分析_java岗位分析-程序员宅基地
文章浏览阅读3k次,点赞4次,收藏14次。Java软件工程师职位分析_java岗位分析
Java:Unreachable code的解决方法_java unreachable code-程序员宅基地
文章浏览阅读2k次。Java:Unreachable code的解决方法_java unreachable code
标签data-*自定义属性值和根据data属性值查找对应标签_如何根据data-*属性获取对应的标签对象-程序员宅基地
文章浏览阅读1w次。1、html中设置标签data-*的值 标题 11111 222222、点击获取当前标签的data-url的值$('dd').on('click', function() { var urlVal = $(this).data('ur_如何根据data-*属性获取对应的标签对象