kafka小白教程从入门到精通_kafka 教程-程序员宅基地
技术标签: kafka小白教程 spark kafka 大数据
kafka小白教程
kafka介绍
kafka的概念
Kafka(底层源码使用scala语言实现):
kafka分布式集群的搭建
kafka分布式集群的实操:
1)命令行客户端(测试)
主题的CRUD操作
发布消息
订阅消息
2)使用Java API来操作kafka分布式集群:
发布消息
订阅消息
kafka内部原理
自定义分区
消息拦截器
理论:
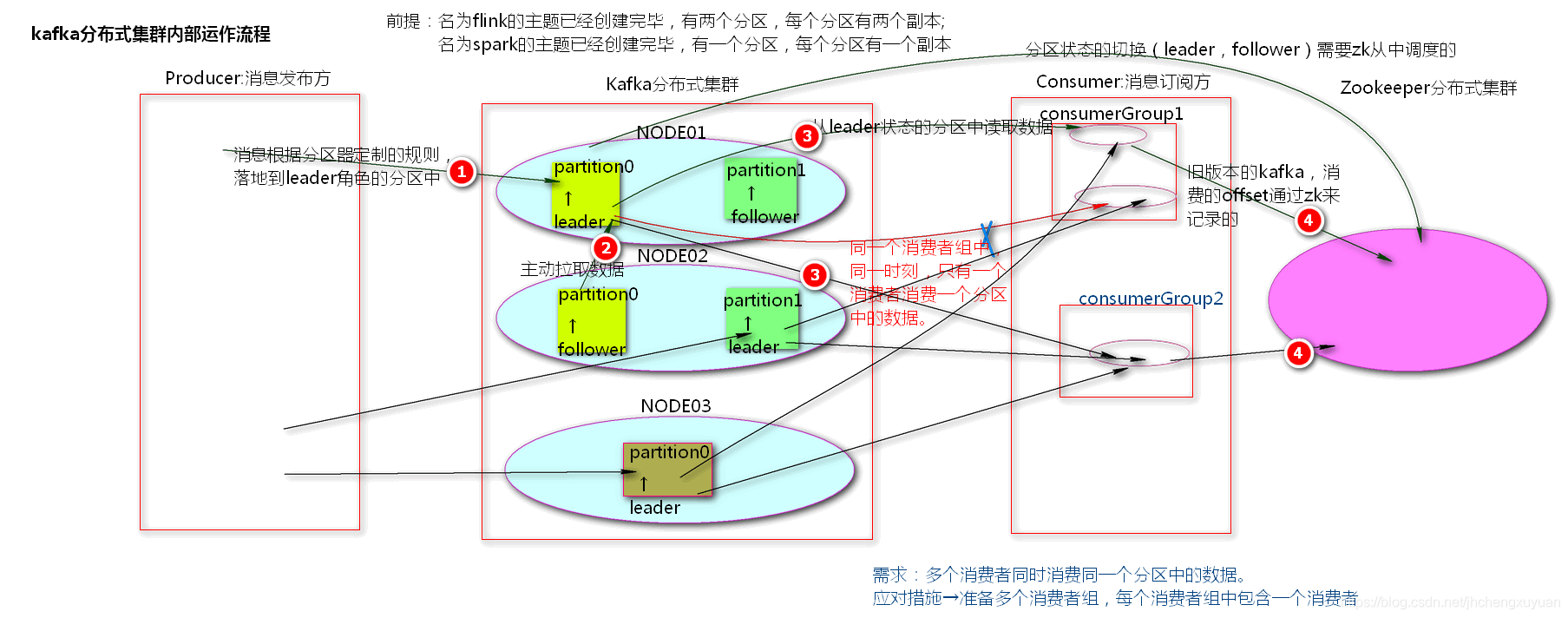
kafka分布式集群内部运作流程
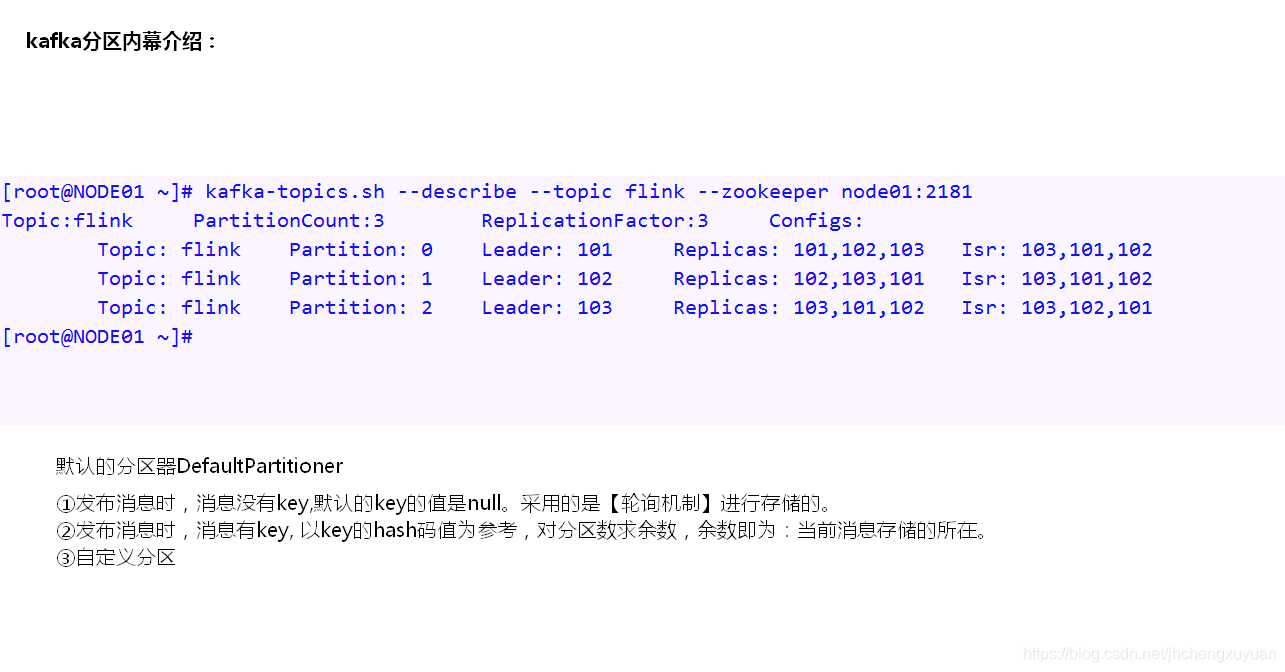
kafka分区内幕介绍
Kafka与flume的整合
kafka介绍
说明:
①kafka:分布式存储消息的中间件。
②每个kafka服务器内部维护着一个消息队列。
③kafka消息服务器要正常发挥作用,必须得借助:
a)消息的发布方(生产者):源源不断产生消息,送往消息服务器存储起来。默认消息在消息服务器驻留的时间是7天。
b)消息的订阅方(消费者):从消息服务器所维护的消息队列中读取相应的消息。
④kafka消息框架涉及到的一些概念:
代理:broker→kafka分布式集群中某一台kafka服务器(所在的节点)
主题:topic →就是消息(Message)的分类名
消息:Message → kafka消息服务队列中存储的每条数据
分区:Partition →主题创建时需要指定好分区数,是消息最终存储的所在(目的地)
副本:refactor →主题创建时需要指定好分区的副本数。
消费者组:cosumer group→每个消费者都必须属于消费者组的,即使没有指定,也有默认的消费者组。
⑤消息模型:
a)点对点:(point to point)一个消息只能被一个消费者所消费,消费完毕后就清除。
b)发布和订阅:(publish and subcribe)一个消息可以被所有的消费者所订阅。←kafka内部采取的模型
⑥特点:
高吞吐量
持久性
分布式
kafka单机版安装
前提:开启zk集群
安装步骤:
①解压: opt]# tar -zxvf soft/kafka_2.11-1.0.2.tgz
②重命名:opt]# mv kafka_2.11-1.0.2/ kafka
③添加KAFKA_HOME至环境变量:/etc/profile.d/bigdate.sh
export KAFKA_HOME=/opt/kafaka
export PATH=$PATH:$KAFKA_HOME/bin
④source生效
⑤修改资源文件(*.properties ~>资源文件; *.xml, *.yml ~>配置文件; 所有的:*.properties,*.xml, *.yml 也可以统称为配置文件)
配置相关参数:$KAFKA_HOME/config/server.properties ~>用来定制kafka服务器启动时相应的参数
主要参数:broker.id、log.dirs、zookeeper.connect
broker.id=101
log.dirs=/opt/logs/kafka [kafka数据的存放目录]
zookeeper.connect=NODE01:2181,NODE02:2181,NODE03:2181
注意:若是单机版,可以配置为:
zookeeper.connect=NODE01:2181
listeners=PLAINTEXT://NODE01:9092(kafka实例broker监听默认端口9092,配置listeners=PLAINTEXT://:9092)
⑥启动:(前提:启动zookeeper集群)
$KAFKA_HOME/bin/kafka-server-start.sh [-daemon] server.properties
-daemon 可选,表示后台启动kafka服务
kafka-server-stop.sh ~>停止kafka服务
⑦如何验证成功:
开启kafka服务器后,通过jps查看进程,会出现一个名为kafka的进程。
kafka分布式集群的搭建
介绍
说明:
①在单机的基础之上,只要修改server.properties配置文件中的broker.id是其在集群能够保证唯一即可,
②kafka集群中的节点没有主从之分,大家都是一样的,在每一台机器上启动方式和单机启动一致(kafka-server-start.sh)
③需要修改的操作:
a)修改资源文件server.properties
listeners=PLAINTEXT://机器名或是ip:9092
broker.id=xx
b)跨节点拷贝环境变量配置文件/etc/profile.d/bigdata.sh到另外两台机器上
c)跨节点拷贝/opt/kafka到另外两台机器上
scp -r /opt/kafka root@node02:/opt/
注意点说明
若是kafka曾经安装过,需要
①删除zookeeper所维护的一些元数据信息(zNode),如:
topics, config, consumer,producer
②删除kafka特定的目录(kafka消息队列最终持久化数据的所在):
如:/opt/kafka/kafka-logs
否则,kafka分布式集群不能正常启动。现象:kafka进程会宕掉。
kafka分布式集群的实操
命令行客户端(测试)
关于主题的操作(crud,c:create,r:retreive,u:update,d:delete)
kafka-topics.sh介绍
1,shell脚本的作用:
Create:新建主题
delete:删除主题
describe:查看主题的详情
change a topic:更新主题
2,关键参数:
--alter 修改主题
--create Create a new topic(创建主题).
--delete Delete a topic(删除主题)
--describe List details for the given topics(显示出给定主题的详情).
--list List all available topics(罗列出kafka分布式集群中所有有效的主题名).
--partitions 创建或是修改主题时通过该参数指定分区数。
--replication-factor 创建修改主题时通过该参数指定分区的副本数。
--topic 指定主题名
--zookeeper:用来指定zookeeper分布式集群
新建主题
需求1:新建名为hadoop的主题,要求分区数1,副本数1
需求2:新建名为spark的主题,要求分区数2,副本数3
需求3:新建名为flink的主题,要求分区数3,副本数3
实操效果:
[root@NODE02 ~]# kafka-topics.sh --create --topic hadoop --zookeeper node01:2181 --partitions 1 --replication-factor 1
Created topic "hadoop".
[root@NODE02 ~]# kafka-topics.sh --create --topic spark --zookeeper node01:2181,node02:2181,node03:2181 --partitions 2 --replication-factor 3
Created topic "spark".
[root@NODE02 ~]# kafka-topics.sh --create --topic flink --zookeeper node01:2181,node02:2181,node03:2181 --partitions 3 --replication-factor 3
Created topic "flink".
注意点:
[root@NODE02 ~]# kafka-topics.sh --create --topic storm --zookeeper node01:2181,node02:2181,node03:2181 --partitions 3 --replication-factor 4
Error while executing topic command : Replication factor: 4 larger than available brokers: 3.
原因:副本一般是跨节点存储的。从安全性的角度考虑,不允许在一台节点上存在相同的副本(若是可以的话,硬盘要是破坏了,多个相同副本中的数据都会丢失,不安全!!)。
查询主题
方式1:--list参数,查看当前kafka分布式集群中存在的有效的主题名
方式2:--describe参数,查看当前kafka分布式集群中存在的有效的主题的详情(主题名,分区数,副本的分布,分区的角色→leader,follower,同一时刻,只有leader角色的分区才能接收读写操作)
实操效果:
[root@NODE02 ~]# kafka-topics.sh --zookeeper node01:2181 --list
flink
hadoop
spark
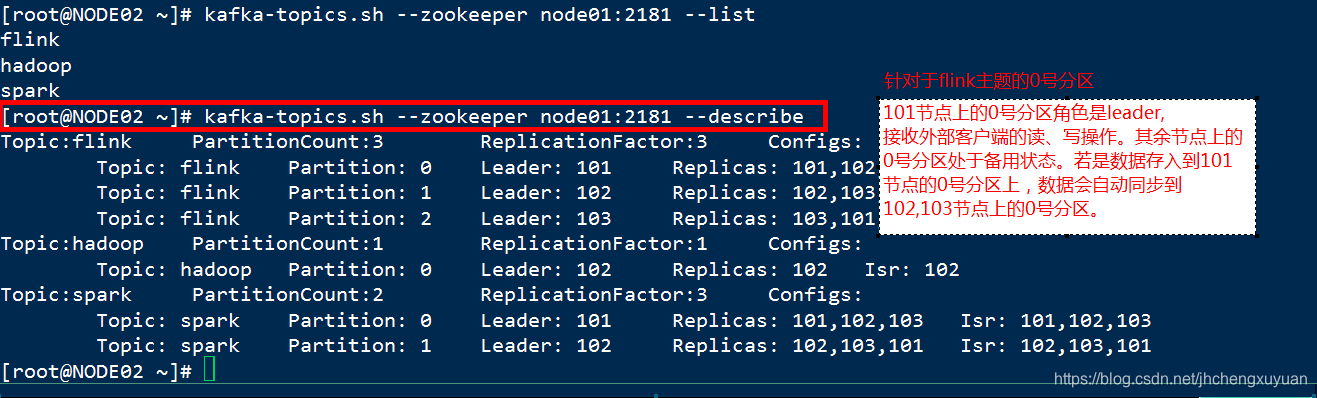
[root@NODE02 ~]# kafka-topics.sh --zookeeper node01:2181 --describe
Topic:flink PartitionCount:3 ReplicationFactor:3 Configs:
Topic: flink Partition: 0 Leader: 101 Replicas: 101,102,103 Isr: 101,102,103
Topic: flink Partition: 1 Leader: 102 Replicas: 102,103,101 Isr: 102,103,101
Topic: flink Partition: 2 Leader: 103 Replicas: 103,101,102 Isr: 103,101,102
Topic:hadoop PartitionCount:1 ReplicationFactor:1 Configs:
Topic: hadoop Partition: 0 Leader: 102 Replicas: 102 Isr: 102
Topic:spark PartitionCount:2 ReplicationFactor:3 Configs:
Topic: spark Partition: 0 Leader: 101 Replicas: 101,102,103 Isr: 101,102,103
Topic: spark Partition: 1 Leader: 102 Replicas: 102,103,101 Isr: 102,103,101
PartitionCount:topic对应的partition的个数
ReplicationFactor:topic对应的副本因子,说白就是副本个数(包含自己,与hdfs上的副本数相同)
Partition:partition编号,从0开始递增
Leader:当前partition起作用的breaker.id
Replicas: 当前副本数据所在的breaker.id,是一个列表
Isr:当前kakfa集群中可用的breaker.id列表
修改主题
1,不能修改副本因子,否则报错,实操效果如下:
[root@NODE02 ~]# kafka-topics.sh --alter --zookeeper node02:2181 --topic hadoop --replication-factor 2
可以通过一个脚本kafka-reassign-partitions.sh这个重新指定
Option "[replication-factor]" can't be used with option"[alter]"
2,可以修改分区数,实操效果如下:
[root@NODE02 ~]# kafka-topics.sh --alter --zookeeper node02:2181 --topic hadoop --partitions 2
WARNING: If partitions are increased for a topic that has a key, the partition logic or ordering of the messages will be affected
Adding partitions succeeded!
[root@NODE02 ~]# kafka-topics.sh --zookeeper node02:2181 --topic hadoop --describe
Topic:hadoop PartitionCount:2 ReplicationFactor:1 Configs:
Topic: hadoop Partition: 0 Leader: 102 Replicas: 102 Isr: 102
Topic: hadoop Partition: 1 Leader: 103 Replicas: 103 Isr: 103
注意:
①只能增加分区数,不能减少分区数。实操效果如下:
[root@NODE02 ~]# kafka-topics.sh --alter --zookeeper node02:2181 --topic hadoop --partitions 1
-------可以通过这个参数更改分区数,动态的,当增加节点后可以这样更改副本数
kafka-reassign-partitions.sh --zookeeper 192.168.80.10 --reassignment-json-file ./test.json --execute
{"version":1,
"partitions":[
{"topic":"test","partition":0,"replicas":[0,1,2]},
{"topic":"test","partition":1,"replicas":[0,1,2]},
{"topic":"test","partition":2,"replicas":[0,1,2]}
]}
------
WARNING: If partitions are increased for a topic that has a key, the partition logic or ordering of the messages will be affected
Error while executing topic command : The number of partitions for a topic can only be increased. Topic hadoop currently has 2 partitions, 1 would not be an increase.
[2019-11-12 11:29:04,668] ERROR org.apache.kafka.common.errors.InvalidPartitionsException: The number of partitions for a topic can only be increased. Topic hadoop currently has 2 partitions, 1 would not be an increase.
(kafka.admin.TopicCommand$)
②主题名不能修改,修改主题时,主题名是作为修改的条件存在的。
删除主题
删除名为hadoop的主题,实操效果如下:
[root@NODE02 flink-0]# kafka-topics.sh --list --zookeeper node01:2181
flink
hadoop
spark
[root@NODE02 flink-0]# kafka-topics.sh --delete --topic hadoop --zookeeper node03:2181
Topic hadoop is marked for deletion.
Note: This will have no impact if delete.topic.enable is not set to true.
[root@NODE02 flink-0]# cd ..
[root@NODE02 kafka-logs]# kafka-topics.sh --list --zookeeper node01:2181
flink
spark
[root@NODE02 kafka-logs]# ll
total 20
-rw-r--r-- 1 root root 4 Nov 12 11:34 cleaner-offset-checkpoint
drwxr-xr-x 2 root root 141 Nov 12 10:51 flink-0
drwxr-xr-x 2 root root 141 Nov 12 10:51 flink-1
drwxr-xr-x 2 root root 141 Nov 12 10:51 flink-2
-rw-r--r-- 1 root root 4 Nov 12 11:34 log-start-offset-checkpoint
-rw-r--r-- 1 root root 56 Nov 12 10:29 meta.properties
-rw-r--r-- 1 root root 54 Nov 12 11:34 recovery-point-offset-checkpoint
-rw-r--r-- 1 root root 54 Nov 12 11:35 replication-offset-checkpoint
drwxr-xr-x 2 root root 141 Nov 12 10:51 spark-0
drwxr-xr-x 2 root root 141 Nov 12 10:51 spark-1
注意:
①针对于kafka的版本kafka-1.0.2,在server.properties资源文件中,参数delete.topic.enable默认值是true。就是物理删除。(低版本的kafka,如:0.10.0.1,确实是逻辑删除)
②通过zookeeper进行确认,并且删除了元数据信息。
[zk: node03(CONNECTED) 11] ls /brokers/topics
[flink, spark]
关于消息的发布和订阅
kafka-console-producer.sh→进行消息的发布(生产)
参数说明如下:
--broker-list <String: broker-list> REQUIRED: The broker list string in
the form HOST1:PORT1,HOST2:PORT2. 用来标识kafka分布式集群中的kafka服务器列表
--topic <String: topic> REQUIRED: The topic id to produce
messages to. 指定主题名(消息属于哪个主题的)
其余的参数使用默认值即可。
说明:
①上述的shell脚本后,会进入到阻塞状态,启动一个名为ConsoleProducer的进程
②在控制台录入消息,一行就是一条消息,回车后,送往kafka分布式集群中的MQ(message queue)存储起来。
kafka-console-consumer.sh→进行消息的订阅(消费)
参数名:
--blacklist <String: blacklist> Blacklist of topics to exclude from
consumption. 用来指定黑名单。使用该参数的时机:
对绝大多数的主题感兴趣,对极少数主题不感兴趣。此时,可以将这些不感兴趣的主题名置于黑名单列表中。
--whitelist <String: whitelist> Whitelist of topics to include for
consumption. 用来指定白名单列表。 使用该参数的时机:
对极少数主题感兴趣,对绝大多数的主题不感兴趣。可以将感兴趣的主题置于到白名单列表中。
--zookeeper <String: urls> REQUIRED (only when using old
consumer): The connection string for
the zookeeper connection in the form
host:port.针对于旧的kafka版本,消费的偏移量通过zookeeper来进行维护的。偏移量:记录的是订阅消息的进度,就是消息数。
--bootstrap-server <String: server to REQUIRED (unless old consumer is
connect to> used): The server to connect to.针对于新版本的kafka,消费的偏移量的维护是通过kafka分布式集群自身的一个名为__consumer_offsets主题来维护来维护的。
--from-beginning If the consumer does not already have
an established offset to consume
from, start with the earliest
message present in the log rather
than the latest message. 从头开始消费。否则,不带该参数,只会订阅新产生的消息(前提:订阅方要提前启动。)。
说明:
①上述的shell脚本后,会进入到阻塞状态,启动一个名为ConsoleConsumer的进程
②会读取特定主题相应分区中存储的消息。
a)若是带了参数--from-beginning ,读取该主题所有分区中的数据
b)若是不带参数--from-beginning,当前的订阅方接收不到历史的消息,只能接收到该进程启动后,新产生的消息。
③若是带--zookeeper参数,消费的offset(偏移量),该偏移量通过zookeeer进行维护。如:
[zk: node03(CONNECTED) 44] get /consumers/console-consumer-37260/offsets/spark/1
2
cZxid = 0x10b0000020e
ctime = Tue Nov 12 14:16:03 CST 2019
mZxid = 0x10b0000020e
mtime = Tue Nov 12 14:16:03 CST 2019
pZxid = 0x10b0000020e
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 1
numChildren = 0
④针对于消费offset的维护,高版本的kafka中,若是使用zookeeper来维护,有警告:
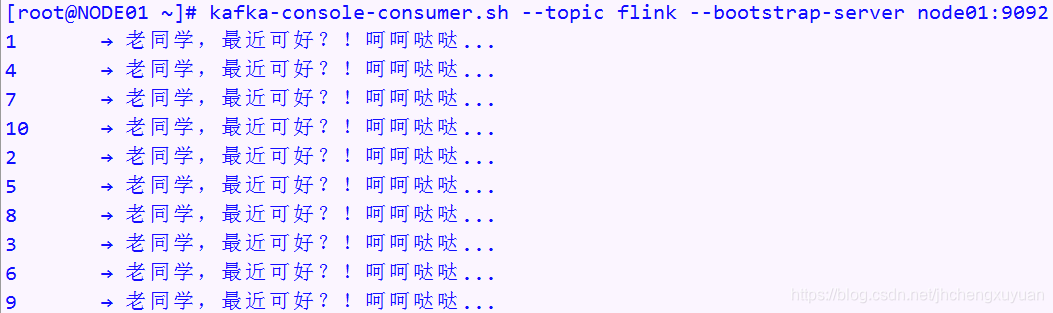
[root@NODE03 kafka-logs]# kafka-console-consumer.sh --topic spark --zookeeper node01:2181
Using the ConsoleConsumer with old consumer is deprecated and will be removed in a future major release. Consider using the new consumer by passing [bootstrap-server] instead of [zookeeper].
how do you do?
⑤针对于消费offset的维护,高版本的kafka中,建议kafka分布式集群来维护,会自动创建一个名为__consumer_offsets的主题,该主题默认有50个分区,每个分区默认有一个副本(可以在server.properties文件中手动进行定制):
[root@NODE03 ~]# kafka-topics.sh --describe --topic __consumer_offsets --zookeeper node01:2181
Topic:__consumer_offsets PartitionCount:50 ReplicationFactor:1 Configs:segment.bytes=104857600,cleanup.policy=compact,compression.type=producer
Topic: __consumer_offsets Partition: 0 Leader: 102 Replicas: 102 Isr: 102
Topic: __consumer_offsets Partition: 1 Leader: 103 Replicas: 103 Isr: 103
Topic: __consumer_offsets Partition: 2 Leader: 101 Replicas: 101 Isr: 101
Topic: __consumer_offsets Partition: 3 Leader: 102 Replicas: 102 Isr: 102
Topic: __consumer_offsets Partition: 4 Leader: 103 Replicas: 103 Isr: 103
Topic: __consumer_offsets Partition: 5 Leader: 101 Replicas: 101 Isr: 101
Topic: __consumer_offsets Partition: 6 Leader: 102 Replicas: 102 Isr: 102
Topic: __consumer_offsets Partition: 7 Leader: 103 Replicas: 103 Isr: 103
Topic: __consumer_offsets Partition: 8 Leader: 101 Replicas: 101 Isr: 101
Topic: __consumer_offsets Partition: 9 Leader: 102 Replicas: 102 Isr: 102
Topic: __consumer_offsets Partition: 10 Leader: 103 Replicas: 103 Isr: 103
Topic: __consumer_offsets Partition: 11 Leader: 101 Replicas: 101 Isr: 101
Topic: __consumer_offsets Partition: 12 Leader: 102 Replicas: 102 Isr: 102
Topic: __consumer_offsets Partition: 13 Leader: 103 Replicas: 103 Isr: 103
Topic: __consumer_offsets Partition: 14 Leader: 101 Replicas: 101 Isr: 101
Topic: __consumer_offsets Partition: 15 Leader: 102 Replicas: 102 Isr: 102
Topic: __consumer_offsets Partition: 16 Leader: 103 Replicas: 103 Isr: 103
Topic: __consumer_offsets Partition: 17 Leader: 101 Replicas: 101 Isr: 101
Topic: __consumer_offsets Partition: 18 Leader: 102 Replicas: 102 Isr: 102
Topic: __consumer_offsets Partition: 19 Leader: 103 Replicas: 103 Isr: 103
Topic: __consumer_offsets Partition: 20 Leader: 101 Replicas: 101 Isr: 101
Topic: __consumer_offsets Partition: 21 Leader: 102 Replicas: 102 Isr: 102
Topic: __consumer_offsets Partition: 22 Leader: 103 Replicas: 103 Isr: 103
Topic: __consumer_offsets Partition: 23 Leader: 101 Replicas: 101 Isr: 101
Topic: __consumer_offsets Partition: 24 Leader: 102 Replicas: 102 Isr: 102
Topic: __consumer_offsets Partition: 25 Leader: 103 Replicas: 103 Isr: 103
Topic: __consumer_offsets Partition: 26 Leader: 101 Replicas: 101 Isr: 101
Topic: __consumer_offsets Partition: 27 Leader: 102 Replicas: 102 Isr: 102
Topic: __consumer_offsets Partition: 28 Leader: 103 Replicas: 103 Isr: 103
Topic: __consumer_offsets Partition: 29 Leader: 101 Replicas: 101 Isr: 101
Topic: __consumer_offsets Partition: 30 Leader: 102 Replicas: 102 Isr: 102
Topic: __consumer_offsets Partition: 31 Leader: 103 Replicas: 103 Isr: 103
Topic: __consumer_offsets Partition: 32 Leader: 101 Replicas: 101 Isr: 101
Topic: __consumer_offsets Partition: 33 Leader: 102 Replicas: 102 Isr: 102
Topic: __consumer_offsets Partition: 34 Leader: 103 Replicas: 103 Isr: 103
Topic: __consumer_offsets Partition: 35 Leader: 101 Replicas: 101 Isr: 101
Topic: __consumer_offsets Partition: 36 Leader: 102 Replicas: 102 Isr: 102
Topic: __consumer_offsets Partition: 37 Leader: 103 Replicas: 103 Isr: 103
Topic: __consumer_offsets Partition: 38 Leader: 101 Replicas: 101 Isr: 101
Topic: __consumer_offsets Partition: 39 Leader: 102 Replicas: 102 Isr: 102
Topic: __consumer_offsets Partition: 40 Leader: 103 Replicas: 103 Isr: 103
Topic: __consumer_offsets Partition: 41 Leader: 101 Replicas: 101 Isr: 101
Topic: __consumer_offsets Partition: 42 Leader: 102 Replicas: 102 Isr: 102
Topic: __consumer_offsets Partition: 43 Leader: 103 Replicas: 103 Isr: 103
Topic: __consumer_offsets Partition: 44 Leader: 101 Replicas: 101 Isr: 101
Topic: __consumer_offsets Partition: 45 Leader: 102 Replicas: 102 Isr: 102
Topic: __consumer_offsets Partition: 46 Leader: 103 Replicas: 103 Isr: 103
Topic: __consumer_offsets Partition: 47 Leader: 101 Replicas: 101 Isr: 101
Topic: __consumer_offsets Partition: 48 Leader: 102 Replicas: 102 Isr: 102
Topic: __consumer_offsets Partition: 49 Leader: 103 Replicas: 103 Isr: 103
⑥关于偏移量的维护:
a)真实项目中一般需要手动进行维护,达到的效果是:偏移量被某个同类型的进程所独享。
b)偏移量的维护,可选的方案很多:
zookeeper
redis →使用得较多
hbase
rdbms(mysql,oracle等等)
⑦白名单:
情形1:通过kafka维护偏移量:
[root@NODE02 bin]# kafka-console-consumer.sh --whitelist 'storm|spark' --bootstrap-server node02:9092,node01:9092,node03:9092 --from-beginning
呵呵 大大
storm storm
ok ok ok
最近可好?
how do you do?
hehe da da
今天参加了天猫双十一晚会,很happy!
are you ok?
storm 哦
hehe
are you ok?
好不好啊?
yes, I do.
和 呵呵哒
新的一天哦
hehe da da
情形2:通过zookeeper维护偏移量 (高版本不推荐了)
[root@NODE02 bin]# kafka-console-consumer.sh --whitelist storm,spark --zookeeper node01:2181 --from-beginningUsing the ConsoleConsumer with old consumer is deprecated and will be removed in a future major release. Consider using the new consumer by passing [bootstrap-server] instead of [zookeeper].
are you ok?
好不好啊?
yes, I do.
和 呵呵哒
新的一天哦
hehe da da
ok ok ok
呵呵 大大
storm storm
最近可好?
how do you do?
hehe da da
今天参加了天猫双十一晚会,很happy!
are you ok?
storm 哦
hehe
⑧黑名单:
情形1:通过kafka维护偏移量:
[root@NODE02 bin]# kafka-console-consumer.sh --blacklist storm --bootstrap-server node02:9092,node01:9092,node03:9092 --from-beginning
Exactly one of whitelist/topic is required.
注意:上述的方式,参数“--blacklist”不能单独使用,需要与--whitelist参数或者是--topic参数结合在一起使用。若是一起使用,显得累赘。一般不要带--blacklist。
情形2:通过zookeeper维护偏移量 (不推荐使用)
[root@NODE02 bin]# kafka-console-consumer.sh --blacklist storm,spark --zookeeper node01:2181 --from-beginningUsing the ConsoleConsumer with old consumer is deprecated and will be removed in a future major release. Consider using the new consumer by passing [bootstrap-server] instead of [zookeeper].
flink 哦
使用Java API来操作kafka分布式集群
前提
①maven工程,pom依赖
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.kafka/kafka-clients -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.11.0.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.kafka/kafka -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.12</artifactId>
<version>0.11.0.0</version>
</dependency>
</dependencies>
②启动zookeeper分布式集群,kafka分布式集群
③将资源文件consumer.properties→用来定制消息订阅方的参数
producer.properties→用来定制消息发布方的参数
拷贝到项目的resources资源目录下
③熟悉涉及到的api:
消息的发布:
KafkaProducer<Key,Value> →发布消息的核心类,若是不指定消息的key,默认值是null
ProducerRecord → 对每条消息的封装
消息的订阅:
KafkaConsumer
发布消息
方案1:发布单条消息
源码以及效果
package com.qf.demo01_producer;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
/**
* Description:自定义消息发布方演示<br/>
* Copyright (c) ,2019 , Jansonxu <br/>
* This program is protected by copyright laws. <br/>
* Date: 2019年11月12日
*
* @author 郭佳豪
* @version : 1.0
*/
public class MyMsgProducerDemo {
public static void main(String[] args) {
//步骤:
Producer<Integer, String> producer = null;
try {
//①准备Properties的实例,并将资源目录下的配置文件producer.properties中定制的参数封装进去
Properties properties = new Properties();
properties.load(MyMsgProducerDemo.class.getClassLoader().getResourceAsStream("producer.properties"));
//②KafkaProducer实例的创建
producer = new KafkaProducer(properties);
//③准备消息
ProducerRecord<Integer, String> record = new ProducerRecord<>("flink", 1, "老同学,最近可好?!");
//④发布消息
producer.send(record);
} catch (Exception e) {
e.printStackTrace();
} finally {
//⑤资源释放
if (producer != null) {
producer.close();
}
}
}
}

方案2:发布多条消息
源码以及效果
package com.qf.demo01_producer;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
/**
* Description:自定义消息发布方演示,发布多条消息<br/>
* Copyright (c) ,2019 , Jansonxu <br/>
* This program is protected by copyright laws. <br/>
* Date: 2019年11月12日
*
* @author 郭佳豪
* @version : 1.0
*/
public class MyMsgProducerDemo2 {
public static void main(String[] args) {
//步骤:
Producer<Integer, String> producer = null;
try {
//①准备Properties的实例,并将资源目录下的配置文件producer.properties中定制的参数封装进去
Properties properties = new Properties();
properties.load(MyMsgProducerDemo2.class.getClassLoader().getResourceAsStream("producer.properties"));
//②KafkaProducer实例的创建
producer = new KafkaProducer(properties);
//③通过循环模拟发布多条消息
for(int i=2;i<=11;i++){
//a)准备消息
ProducerRecord<Integer, String> record = new ProducerRecord<>("flink", i, i+"\t→ 老同学,最近可好?!");
//b) 发布消息
producer.send(record);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
//⑤资源释放
if (producer != null) {
producer.close();
}
}
}
}
方案3:追踪每条消息发布后的轨迹
源码以及效果
package com.qf.demo01_producer;
import org.apache.kafka.clients.producer.*;
import java.util.Properties;
/**
* Description:自定义消息发布方演示,发布多条消息,追踪每条消息的最终的归宿<br/>
* Copyright (c) ,2019 , Jansonxu <br/>
* This program is protected by copyright laws. <br/>
* Date: 2019年11月12日
*
* @author 郭佳豪
* @version : 1.0
*/
public class MyMsgProducerDemo3 {
public static void main(String[] args) {
//步骤:
Producer<Integer, String> producer = null;
try {
//①准备Properties的实例,并将资源目录下的配置文件producer.properties中定制的参数封装进去
Properties properties = new Properties();
properties.load(MyMsgProducerDemo3.class.getClassLoader().getResourceAsStream("producer.properties"));
//②KafkaProducer实例的创建
producer = new KafkaProducer(properties);
//③通过循环模拟发布多条消息
for (int i = 1; i <= 10; i++) {
//a)准备消息
ProducerRecord<Integer, String> record = new ProducerRecord<>("flink", i, i + "\t→ 老同学,最近可好?!呵呵哒哒...");
//b) 发布消息
producer.send(record, new Callback() {
/**
* 当前待发送的消息发送完毕后,下述方法会被回调执行
*
* @param metadata
* @param exception
*/
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
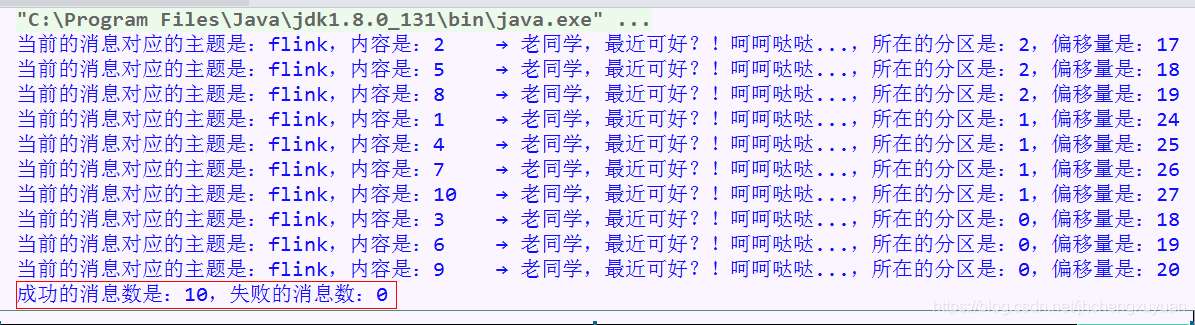
System.out.printf("当前的消息对应的主题是:%s,内容是:%s,所在的分区是:%d,偏移量是:%d%n",
metadata.topic(), record.value(), metadata.partition(), metadata.offset());
}
});
}
} catch (Exception e) {
e.printStackTrace();
} finally {
//⑤资源释放
if (producer != null) {
producer.close();
}
}
}
}

消息的订阅
订阅当前新发布的个别消息(latest)
package com.qf.demo02_consumer;
import org.apache.kafka.clients.consumer.Consumer;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.util.Arrays;
import java.util.Properties;
/**
* Description:自定义消息订阅方演示,订阅最新的消息,接收个别消息<br/>
* Copyright (c) ,2019 , Jansonxu <br/>
* This program is protected by copyright laws. <br/>
* Date: 2019年11月12日
*
* @author 郭佳豪
* @version : 1.0
*/
public class MyMsgConsumerDemo {
public static void main(String[] args) {
//步骤:
Consumer<Integer, String> consumer = null;
try {
//①Properties的实例,将consumer.properties资源文件中的参数设置封装进去
Properties properties = new Properties();
properties.load(MyMsgConsumerDemo.class.getClassLoader().getResourceAsStream("consumer.properties"));
//②KafkaConsumer
consumer = new KafkaConsumer(properties);
//③指定订阅的主题
consumer.subscribe(Arrays.asList("flink"));
//④正式开始进行订阅
ConsumerRecords<Integer, String> records = consumer.poll(5000);
//⑤分析订阅后的结果
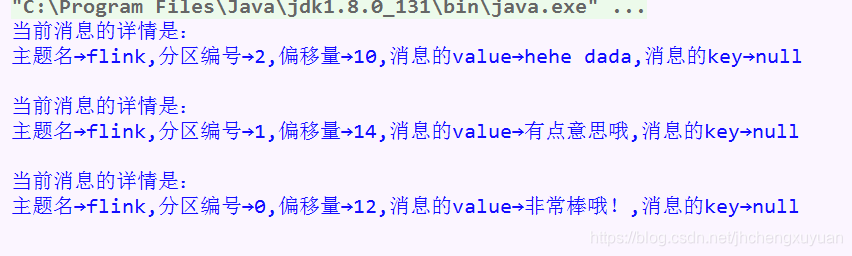
for (ConsumerRecord<Integer, String> record : records) {
String topic = record.topic();
int partition = record.partition();
long offset = record.offset();
String value = record.value();
Integer key = record.key();
System.out.printf("当前消息的详情是:%n主题名→%s,分区编号→%d,偏移量→%d,消息的value→%s,消息的key→%d%n%n",
topic, partition, offset, value, key
);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
//⑥资源释放
if (consumer != null) {
consumer.close();
}
}
}
}


循环订阅消息
package com.qf.demo02_consumer;
import org.apache.kafka.clients.consumer.Consumer;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.util.Arrays;
import java.util.Properties;
/**
* Description:自定义消息订阅方演示,订阅最新的消息,循环接收消息<br/>
* Copyright (c) ,2019 , Jansonxu <br/>
* This program is protected by copyright laws. <br/>
* Date: 2019年11月12日
*
* @author 郭佳豪
*
* @version : 1.0
*/
public class MyMsgConsumerDemo2 {
public static void main(String[] args) {
//步骤:
Consumer<Integer, String> consumer = null;
try {
//①Properties的实例,将consumer.properties资源文件中的参数设置封装进去
Properties properties = new Properties();
properties.load(MyMsgConsumerDemo2.class.getClassLoader().getResourceAsStream("consumer.properties"));
//②KafkaConsumer
consumer = new KafkaConsumer(properties);
//③指定订阅的主题
consumer.subscribe(Arrays.asList("flink"));
//④循环接收消息
while(true){
//④正式开始进行订阅
ConsumerRecords<Integer, String> records = consumer.poll(1000);
//⑤分析订阅后的结果
for (ConsumerRecord<Integer, String> record : records) {
String topic = record.topic();
int partition = record.partition();
long offset = record.offset();
String value = record.value();
Integer key = record.key();
System.out.printf("当前消息的详情是:%n主题名→%s,分区编号→%d,偏移量→%d,消息的value→%s,消息的key→%d%n%n",
topic, partition, offset, value, key
);
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
//⑥资源释放
if (consumer != null) {
consumer.close();
}
}
}
}


从源头开始订阅所关注的各个主题的消息
package com.qf.demo02_consumer;
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.TopicPartition;
import java.util.Arrays;
import java.util.Collection;
import java.util.Properties;
/**
* Description:自定义消息订阅方演示,订阅最新的消息,从头开始订阅所关注主题所有的消息<br/>
* Copyright (c) ,2019 , Jansonxu <br/>
* This program is protected by copyright laws. <br/>
* Date: 2019年11月12日
*
* @author 郭佳豪
* @version : 1.0
*/
public class MyMsgConsumerDemo3 {
public static void main(String[] args) {
//步骤:
Consumer<Integer, String> consumer = null;
try {
//①Properties的实例,将consumer.properties资源文件中的参数设置封装进去
Properties properties = new Properties();
properties.load(MyMsgConsumerDemo3.class.getClassLoader().getResourceAsStream("consumer.properties"));
//②KafkaConsumer
consumer = new KafkaConsumer(properties);
//③指定订阅的主题
final Consumer<Integer, String> finalConsumer = consumer;
consumer.subscribe(Arrays.asList("flink", "storm", "spark"), new ConsumerRebalanceListener() {
@Override
public void onPartitionsRevoked(Collection<TopicPartition> partitions) {
}
/**
* 从各个分区的开始位置进行订阅
* @param partitions
*/
@Override
public void onPartitionsAssigned(Collection<TopicPartition> partitions) {
finalConsumer.seekToBeginning(partitions);
}
});
//④循环接收消息
while (true) {
//④正式开始进行订阅
ConsumerRecords<Integer, String> records = consumer.poll(1000);
//⑤分析订阅后的结果
for (ConsumerRecord<Integer, String> record : records) {
String topic = record.topic();
int partition = record.partition();
long offset = record.offset();
String value = record.value();
Integer key = record.key();
System.out.printf("当前消息的详情是:%n主题名→%s,分区编号→%d,偏移量→%d,消息的value→%s,消息的key→%d%n%n",
topic, partition, offset, value, key
);
}
//所有的消息订阅完毕,就退出
if (records.isEmpty()) {
break;
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
//⑥资源释放
if (consumer != null) {
consumer.close();
}
}
}
}

kafka自定义分区
分析
步骤:
1,设计一个子类继承分区父类,重写其中的partition方法,在该方法中定制分区规则
2,修改producer.properties文件,指定自定的分区类
源码以及效果
package com.qf.demo03_partition;
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import org.apache.kafka.common.PartitionInfo;
import java.util.List;
import java.util.Map;
/**
* Description:自定义分区<br/>
* Copyright (c) ,2019 , Jansonxu <br/>
* This program is protected by copyright laws. <br/>
* Date: 2019年11月13日
*
* @author 郭佳豪
* @version : 1.0
*/
public class MyPartition implements Partitioner {
/**
* 下述方法在消息存储到相应分区之前,都会被回调一次。
* 原因:消息得找到自己存储的所在。
*
* @param topic 主题名
* @param key 消息的key
* @param keyBytes key对应的字节数组
* @param value 消息的value
* @param valueBytes value对应的字节数组
* @param cluster kafka分布式集群
* @return
*/
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
//思路:
//①获得当前主题的分区数
List<PartitionInfo> partitionInfos = cluster.availablePartitionsForTopic(topic);
int totalPartitionNum = partitionInfos.size();
//②关于key
// a)key≠null, key的hash码值对分区数求余数,余数即为当前消息所对应的分区编号
//b)key=null, 根据value来计算
//i)value ≠null, value的hash码值对分区数求余数,余数即为当前消息所对应的分区编号
//ii)value=null, 直接返回默认的分区编号,如:0.
if (key != null) {
return key.hashCode() % totalPartitionNum;
} else {
if (value != null) {
return value.hashCode() % totalPartitionNum;
} else {
return 0;
}
}
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> configs) {
}
}

消息拦截器
介绍
①在消息发送到kafka分布式集群之前,针对于一些共通的业务处理,建议使用拦截器。如:对每条消息添加一个共通的前缀(如:时间戳),对消息中包含一些反动的信息进行筛选
②还可以监测到消息发送的状态(成功,失败)
③需求:实现一个简单的双interceptor组成的拦截链。第一个interceptor会在消息发送前将时间戳信息加到消息value的最前部;第二个interceptor会在消息发送后更新成功发送消息数或失败发送消息数。
④核心api:ProducerIntercepter
源码以及效果
package com.qf.demo04_intercepter;
import org.apache.kafka.clients.producer.*;
import java.util.Collection;
import java.util.Collections;
import java.util.LinkedList;
import java.util.Properties;
/**
* Description:自定义拦截器使用演示<br/>
* Copyright (c) ,2019 , Jansonxu <br/>
* This program is protected by copyright laws. <br/>
* Date: 2019年11月12日
*
* @author 郭佳豪
* @version : 1.0
*/
public class InteceptorUsageDemo {
public static void main(String[] args) {
//步骤:
Producer<Integer, String> producer = null;
try {
//①准备Properties的实例,并将资源目录下的配置文件producer.properties中定制的参数封装进去
Properties properties = new Properties();
properties.load(InteceptorUsageDemo.class.getClassLoader().getResourceAsStream("producer.properties"));
//将拦截器封装到properties实例中,作为参数来构建KafkaProducer
Collection<String> params = new LinkedList<>();
Collections.addAll(params, "com.qf.demo04_intercepter.TimeIntecepter",
"com.qf.demo04_intercepter.StatusIntecepter");
properties.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, params);
//②KafkaProducer实例的创建
producer = new KafkaProducer(properties);
//③通过循环模拟发布多条消息
for (int i = 1; i <= 10; i++) {
//a)准备消息
ProducerRecord<Integer, String> record = new ProducerRecord<>("flink", i, i + "\t→ 老同学,最近可好?!呵呵哒哒...");
//b) 发布消息
producer.send(record, new Callback() {
/**
* 当前待发送的消息发送完毕后,下述方法会被回调执行
*
* @param metadata
* @param exception
*/
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
System.out.printf("当前的消息对应的主题是:%s,内容是:%s,所在的分区是:%d,偏移量是:%d%n",
metadata.topic(), record.value(), metadata.partition(), metadata.offset());
}
});
}
} catch (Exception e) {
e.printStackTrace();
} finally {
//⑤资源释放
if (producer != null) {
producer.close();
}
}
}
}
package com.qf.demo04_intercepter;
import org.apache.kafka.clients.producer.ProducerInterceptor;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Date;
import java.util.Map;
/**
* Description:时间戳拦截器(作用:给每条消息添加上统一的时间前缀)<br/>
* Copyright (c) ,2019 , Jansonxu <br/>
* This program is protected by copyright laws. <br/>
* Date: 2019年11月13日
*
* @author 郭佳豪
* @version : 1.0
*/
public class TimeIntecepter implements ProducerInterceptor<Integer, String> {
/**
* 每条消息发送之前,下述方法会被执行
*
* @param record
* @return
*/
@Override
public ProducerRecord<Integer, String> onSend(ProducerRecord<Integer, String> record) {
return new ProducerRecord<Integer, String>(record.topic(), record.partition(),
record.timestamp(), record.key(),
new Date() + "→" + record.value(), record.headers());
}
@Override
public void onAcknowledgement(RecordMetadata metadata, Exception exception) {
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> configs) {
}
}
package com.qf.demo04_intercepter;
import org.apache.kafka.clients.producer.ProducerInterceptor;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Map;
/**
* Description:状态戳拦截器(作用:用来监测成功或是失败的消息数)<br/>
* Copyright (c) ,2019 , Jansonxu <br/>
* This program is protected by copyright laws. <br/>
* Date: 2019年11月13日
*
* @author 郭佳豪
* @version : 1.0
*/
public class StatusIntecepter implements ProducerInterceptor<Integer, String> {
/**
* 成功消息数
*/
private int successCnt;
/**
* 失败消息数
*/
private int failureCnt;
@Override
public ProducerRecord<Integer, String> onSend(ProducerRecord<Integer, String> record) {
return record;
}
/**
* 每次发送完毕一条消息,下述的方法会被回调执行
* <p>
* Ack: 应答机制
*
* @param metadata
* @param exception
*/
@Override
public void onAcknowledgement(RecordMetadata metadata, Exception exception) {
//根据参数2来判断消息是否发送成功
//=null,成功
//≠null,失败
if (exception == null) {
successCnt += 1;
} else {
failureCnt += 1;
}
}
@Override
public void close() {
//显示结果
System.out.printf("成功的消息数是:%d,失败的消息数:%d%n", successCnt, failureCnt);
}
@Override
public void configure(Map<String, ?> configs) {
}
}

kafka相关的理论
kafka分布式集群内部运作流程入图片描述](https://img-blog.csdnimg.cn/20191113215621457.png?x-oss-process=image/watermark,tyZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2poY2hlbmd4dXl1YW4=,size_16,color_FFFFFF,t_70)
kafka分区内幕介绍
 rmark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2poY2hlbmd4dXl1YW4=,size_16,color_FFFFFF,t_70)
rmark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2poY2hlbmd4dXl1YW4=,size_16,color_FFFFFF,t_70)
Kafka与flume的整合
说明
步骤:
1,编辑配置文件
# flume-kafka.properties: 用来定制agent的各个组件的行为(source,channel,sink)
############################################
# 对各个组件的描述说明
# 其中a1为agent的名字
# r1是a1的source的代号名字
# c1是a1的channel的代号名字
# k1是a1的sink的代号名字
############################################
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 用于描述source的,类型是netcat网络,telnet
a1.sources.r1.type = netcat
# source监听的网络ip地址和端口号
a1.sources.r1.bind = NODE01
a1.sources.r1.port = 44444
# 用于描述channel,在内存中做数据的临时的存储
a1.channels.c1.type = memory
# 该内存中最大的存储容量,1000个events事件
a1.channels.c1.capacity = 1000
# 能够同时对100个events事件监管事务
a1.channels.c1.transactionCapacity = 100
# 用于描述sink,类型是日志格式,用于定制消息发布方的参数
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.topic = hive
a1.sinks.k1.brokerList = NODE01:9092,NODE02:9092,NODE03:9092
a1.sinks.k1.requiredAcks = 1
a1.sinks.k1.batchSize = 20
# 将a1中的各个组件建立关联关系,将source和sink都指向了同一个channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
2,开启flume日志采集服务(后台)~> -Dflume.root.logger=INFO,console
flume-ng agent --conf-file flume-kafka.properties --name a1
以后台进程的方式启动:
nohup flume-ng agent --conf-file flume-kafka.properties --name a1 > /dev/null 2>&1 &
3,使用netcat向4444端口写入
> nc NODE01 44444
hello are you ready?
_____________
前提:
需要安装telnet或者是netcat
运行方式总结:
一:telnet
需要在centOS上面安装telnet(注意:在线安装方式 yum install telnet)
启动flumn-agent
启动telnet:
telnet NODE01 44444
二:netcat(注意:在线安装方式 yum install -y nc)
安装发给大家的nc.xx.rpm
rpm -ivh nc.xx.rpm-path
启动flumn-agent
启动nc进程
nc NODE01 44444
______________
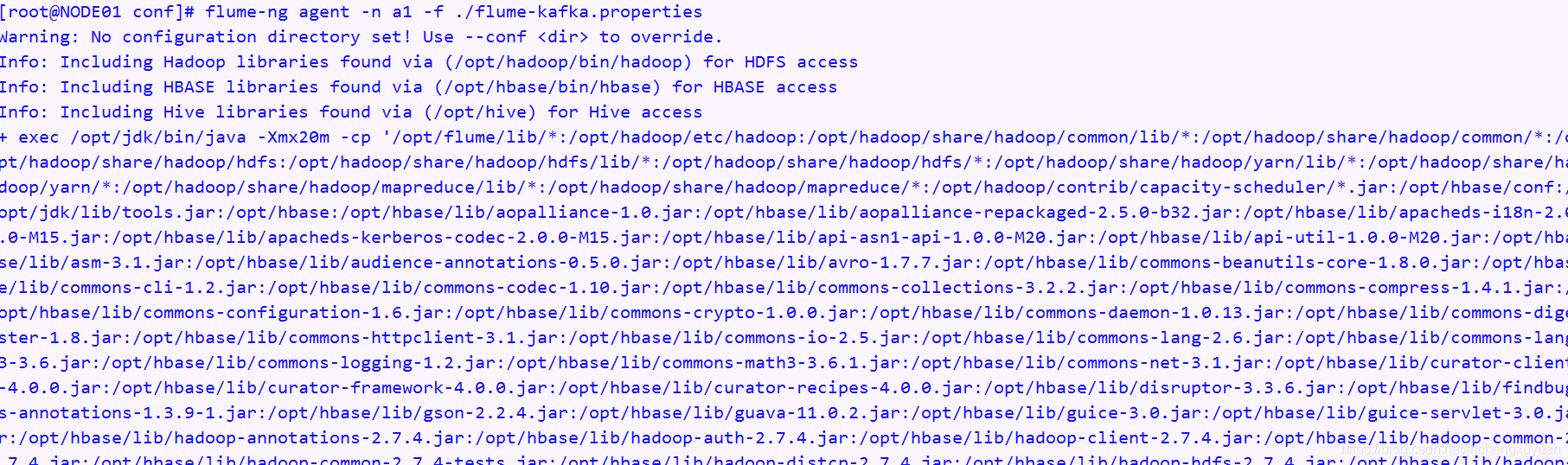
4,开启一个kafka消费的进程
kafka-console-consumer.sh --topic hive --zookeeper NODE01:2181,NODE02:2181 --from-beginning
运行效果


kafka总结
1、Segment的概念:
一个分区被分成相同大小数据条数不相等的Segment,
每个Segment有多个index文件和数据文件组成
2、数据的存储机制(就是面试题中kafka速度为什么如此之快):
首先是Broker接收到数据后,将数据放到操作系统的缓存里(pagecache),
pagecache会尽可能多的使用空闲内存,
使用sendfile技术尽可能多的减少操作系统和应用程序之间进行重复缓存,
写入数据的时候使用顺序写入,写入数据的速度可达600m/s
3、Consumer怎么解决负载均衡?(rebalance)
1)获取Consumer消费的起始分区号
2)计算出Consumer要消费的分区数量
3)用起始分区号的hashCode值模余分区数
4、数据的分发策略?
Kafka默认调用自己分区器(DefaultPartitioner),
也可以自定义分区器,需要实现Partitioner特质,实现partition方法
5、Kafka怎么保证数据不丢失?
Kafka接收数据后会根据创建的topic指定的副本数来存储,
也就是副本机制保证数据的安全性
6、Kafka的应用:
①作为消息队列的应用在传统的业务中使用高吞吐、分布式、使得处理大量业务内容轻松自如。
②作为互联网行业的日志行为实时分析,比如:实时统计用户浏览页面、搜索及其他行为,结合实时处理框架使用实现实时监控,或放到 hadoop/离线数据仓库里处理。
③作为一种为外部的持久性日志的分布式系统提供服务。主要利用节点间备份数据,文件存储、日志压缩等功能。
——————
其他应用场景:
① 企业内部指标
对于某些时效性要求较高的指标,如预警指标等,必须在数据变化时
及时计算并发送信息
② 通信服务运营商
对于用户套餐中的剩余量进行监控,如流量,语音通话,短信
③ 电商行业
对于吞吐量特别大和数据变动频次较高的应用,如电商网站,必须使
用实时计算来捕捉用户偏好
7、Kafka组件:
①每个partition在存储层面是append log文件。新消息都会被直接追加到log文件的尾部,每条消息在log文件中的位置称为offset(偏移量)。
②每条Message包含了以下三个属性:
1° offset 对应类型:long 此消息在一个partition中序号。可以认为offset是partition中Message的id
2° MessageSize 对应类型:int。
3° data 是message的具体内容。
③越多的partitions意味着可以容纳更多的consumer,有效提升并发消费的能力。
④总之:业务区分增加topic、数据量大增加partition (副本数<=broker节点数)。
8、实时流处理框架如Storm, Spark Streaming如何实现实时处理的,底层封装了Kafka Stream。
若是手动实现实时处理的框架,需要自己使用Kafka Stream 库。
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<version>1.0.2</version>
</dependency>
9、维护消息订阅方消费的offset的方式有哪些?
①zookeeper ,参数:--zookeeper
②kafka集群来维护,参数:--bootstrap-server
主题名:__consumer_offsets, 默认: 50个分区; 默认的副本数是:1
若是达到默认的主题__consumer_offsets的分区的ha (高容错),需要在server.properties文件中定制默认的副本数:
default.replication.factor=3
③手动维护偏移量 (一般使用redis存储偏移量)
10,几个问题:
①每次启动一个消费者进程(kafka-console-consumer.sh),是一个单独的进程
②手动书写的消费者,可以通过参数来定制是从头开始消费,还是接力消费。需要指定flg (main: args[])
③kafka-console-consumer.sh,每次开启一个消费者进程,有一个默认的消费者组。命名方式是:console-consumer-64328
④查看消费者组的信息,详见: 4_笔记\查看消费者组.png
⑤PachCache, SendFile

能。
——————
其他应用场景:
① 企业内部指标
对于某些时效性要求较高的指标,如预警指标等,必须在数据变化时
及时计算并发送信息
② 通信服务运营商
对于用户套餐中的剩余量进行监控,如流量,语音通话,短信
③ 电商行业
对于吞吐量特别大和数据变动频次较高的应用,如电商网站,必须使
用实时计算来捕捉用户偏好
7、Kafka组件:
①每个partition在存储层面是append log文件。新消息都会被直接追加到log文件的尾部,每条消息在log文件中的位置称为offset(偏移量)。
②每条Message包含了以下三个属性:
1° offset 对应类型:long 此消息在一个partition中序号。可以认为offset是partition中Message的id
2° MessageSize 对应类型:int。
3° data 是message的具体内容。
③越多的partitions意味着可以容纳更多的consumer,有效提升并发消费的能力。
④总之:业务区分增加topic、数据量大增加partition (副本数<=broker节点数)。
8、实时流处理框架如Storm, Spark Streaming如何实现实时处理的,底层封装了Kafka Stream。
若是手动实现实时处理的框架,需要自己使用Kafka Stream 库。
org.apache.kafka
kafka-streams
1.0.2
9、维护消息订阅方消费的offset的方式有哪些?
①zookeeper ,参数:–zookeeper
②kafka集群来维护,参数:–bootstrap-server
主题名:__consumer_offsets, 默认: 50个分区; 默认的副本数是:1
若是达到默认的主题__consumer_offsets的分区的ha (高容错),需要在server.properties文件中定制默认的副本数:
default.replication.factor=3
③手动维护偏移量 (一般使用redis存储偏移量)
10,几个问题:
①每次启动一个消费者进程(kafka-console-consumer.sh),是一个单独的进程
②手动书写的消费者,可以通过参数来定制是从头开始消费,还是接力消费。需要指定flg (main: args[])
③kafka-console-consumer.sh,每次开启一个消费者进程,有一个默认的消费者组。命名方式是:console-consumer-64328
④查看消费者组的信息,详见: 4_笔记\查看消费者组.png
⑤PachCache, SendFile


智能推荐
【史上最易懂】马尔科夫链-蒙特卡洛方法:基于马尔科夫链的采样方法,从概率分布中随机抽取样本,从而得到分布的近似_马尔科夫链期望怎么求-程序员宅基地
文章浏览阅读1.3k次,点赞40次,收藏19次。虽然你不能直接计算每个房间的人数,但通过马尔科夫链的蒙特卡洛方法,你可以从任意状态(房间)开始采样,并最终收敛到目标分布(人数分布)。然后,根据一个规则(假设转移概率是基于房间的人数,人数较多的房间具有较高的转移概率),你随机选择一个相邻的房间作为下一个状态。比如在巨大城堡,里面有很多房间,找到每个房间里的人数分布情况(每个房间被访问的次数),但是你不能一次进入所有的房间并计数。但是,当你重复这个过程很多次时,你会发现你更有可能停留在人数更多的房间,而在人数较少的房间停留的次数较少。_马尔科夫链期望怎么求
linux以root登陆命令,su命令和sudo命令,以及限制root用户登录-程序员宅基地
文章浏览阅读3.9k次。一、su命令su命令用于切换当前用户身份到其他用户身份,变更时须输入所要变更的用户帐号与密码。命令su的格式为:su [-] username1、后面可以跟 ‘-‘ 也可以不跟,普通用户su不加username时就是切换到root用户,当然root用户同样可以su到普通用户。 ‘-‘ 这个字符的作用是,加上后会初始化当前用户的各种环境变量。下面看下加‘-’和不加‘-’的区别:root用户切换到普通..._限制su root登陆
精通VC与Matlab联合编程(六)_精通vc和matlab联合编程 六-程序员宅基地
文章浏览阅读1.2k次。精通VC与Matlab联合编程(六)作者:邓科下载源代码浅析VC与MATLAB联合编程浅析VC与MATLAB联合编程浅析VC与MATLAB联合编程浅析VC与MATLAB联合编程浅析VC与MATLAB联合编程 Matlab C/C++函数库是Matlab扩展功能重要的组成部分,包含了大量的用C/C++语言重新编写的Matlab函数,主要包括初等数学函数、线形代数函数、矩阵操作函数、数值计算函数_精通vc和matlab联合编程 六
Asp.Net MVC2中扩展ModelMetadata的DescriptionAttribute。-程序员宅基地
文章浏览阅读128次。在MVC2中默认并没有实现DescriptionAttribute(虽然可以找到这个属性,通过阅读MVC源码,发现并没有实现方法),这很不方便,特别是我们使用EditorForModel的时候,我们需要对字段进行简要的介绍,下面来扩展这个属性。新建类 DescriptionMetadataProvider然后重写DataAnnotationsModelMetadataPro..._asp.net mvc 模型description
领域模型架构 eShopOnWeb项目分析 上-程序员宅基地
文章浏览阅读1.3k次。一.概述 本篇继续探讨web应用架构,讲基于DDD风格下最初的领域模型架构,不同于DDD风格下CQRS架构,二者架构主要区别是领域层的变化。 架构的演变是从领域模型到C..._eshoponweb
Springboot中使用kafka_springboot kafka-程序员宅基地
文章浏览阅读2.6w次,点赞23次,收藏85次。首先说明,本人之前没用过zookeeper、kafka等,尚硅谷十几个小时的教程实在没有耐心看,现在我也不知道分区、副本之类的概念。用kafka只是听说他比RabbitMQ快,我也是昨天晚上刚使用,下文中若有讲错的地方或者我的理解与它的本质有偏差的地方请包涵。此文背景的环境是windows,linux流程也差不多。 官网下载kafka,选择Binary downloads Apache Kafka 解压在D盘下或者什么地方,注意不要放在桌面等绝对路径太长的地方 打开conf_springboot kafka
随便推点
VS2008+水晶报表 发布后可能无法打印的解决办法_水晶报表 不能打印-程序员宅基地
文章浏览阅读1k次。编好水晶报表代码,用的是ActiveX模式,在本机运行,第一次运行提示安装ActiveX控件,安装后,一切正常,能正常打印,但发布到网站那边运行,可能是一闪而过,连提示安装ActiveX控件也没有,甚至相关的功能图标都不能正常显示,再点"打印图标"也是没反应解决方法是: 1.先下载"PrintControl.cab" http://support.businessobjects.c_水晶报表 不能打印
一. UC/OS-Ⅱ简介_ucos-程序员宅基地
文章浏览阅读1.3k次。绝大部分UC/OS-II的源码是用移植性很强的ANSI C写的。也就是说某产品可以只使用很少几个UC/OS-II调用,而另一个产品则使用了几乎所有UC/OS-II的功能,这样可以减少产品中的UC/OS-II所需的存储器空间(RAM和ROM)。UC/OS-II是为嵌入式应用而设计的,这就意味着,只要用户有固化手段(C编译、连接、下载和固化), UC/OS-II可以嵌入到用户的产品中成为产品的一部分。1998年uC/OS-II,目前的版本uC/OS -II V2.61,2.72。1.UC/OS-Ⅱ简介。_ucos
python自动化运维要学什么,python自动化运维项目_运维学python该学些什么-程序员宅基地
文章浏览阅读614次,点赞22次,收藏11次。大家好,本文将围绕python自动化运维需要掌握的技能展开说明,python自动化运维从入门到精通是一个很多人都想弄明白的事情,想搞清楚python自动化运维快速入门 pdf需要先了解以下几个事情。这篇文章主要介绍了一个有趣的事情,具有一定借鉴价值,需要的朋友可以参考下。希望大家阅读完这篇文章后大有收获,下面让小编带着大家一起了解一下。_运维学python该学些什么
解决IISASP调用XmlHTTP出现msxml3.dll (0x80070005) 拒绝访问的错误-程序员宅基地
文章浏览阅读524次。2019独角兽企业重金招聘Python工程师标准>>> ..._hotfix for msxml 4.0 service pack 2 - kb832414
python和易语言的脚本哪门更实用?_易语言还是python适合辅助-程序员宅基地
文章浏览阅读546次。python和易语言的脚本哪门更实用?_易语言还是python适合辅助
redis watch使用场景_详解redis中的锁以及使用场景-程序员宅基地
文章浏览阅读134次。详解redis中的锁以及使用场景,指令,事务,分布式,命令,时间详解redis中的锁以及使用场景易采站长站,站长之家为您整理了详解redis中的锁以及使用场景的相关内容。分布式锁什么是分布式锁?分布式锁是控制分布式系统之间同步访问共享资源的一种方式。为什么要使用分布式锁? 为了保证共享资源的数据一致性。什么场景下使用分布式锁? 数据重要且要保证一致性如何实现分布式锁?主要介绍使用redis来实..._redis setnx watch