pytorch进行fashion mnist数据集分类_fmnist-程序员宅基地
技术标签: 图像分类 深度学习 fashion mnist pytorch mnist
1.数据集介绍
最近在撸pytorch框架,这里参考深度学习经典数据集mnist的“升级版”fashion mnist,来做图像分类,主要目的是熟悉pytorch框架,代码中包含了大量的pytorch使用相关的注释。
(1)MNIST
MNIST是深度学习最基本的数据集之一,由CNN鼻祖yann lecun建立的一个手写字符数据集,包含60000张训练图像和10000张测试图像,包含数字0-9共10个类别.

(2)FASHION MNIST
由于MNIST数据集太简单,简单的网络就可以达到99%以上的top one准确率,也就是说在这个数据集上表现较好的网络,在别的任务上表现不一定好。因此zalando research的工作人员建立了fashion mnist数据集,该数据集由衣服、鞋子等服饰组成,包含70000张图像,其中60000张训练图像加10000张测试图像,图像大小为28x28,单通道,共分10个类,如下图,每3行表示一个类。

数据集信息如下:
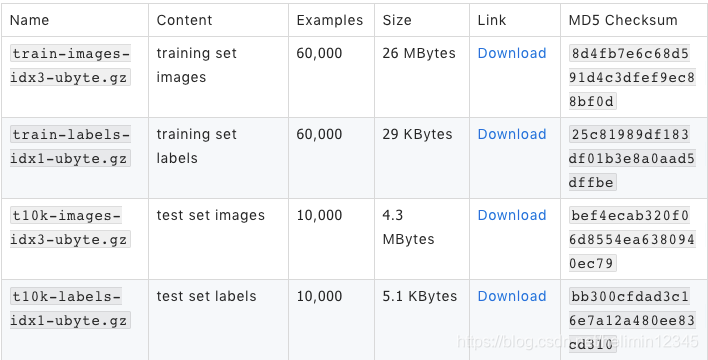
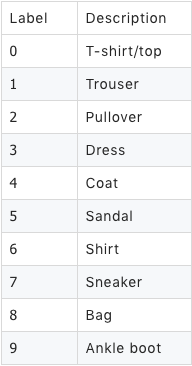
数据集共分10个类,类别描述如下:
标题2. pytorch进行分类
pytorch中提供了这个数据集的下载接口,下面分别使用全连接网络和CNN网络来进行分类
(1)FC网络
输入图像大小为28x28,设计如下全连接网络,代码命名为02_fashion_mnist_fc.py
FC1(784) + Relu(1000) + FC2(500) + Relu + FC3(200) + Relu3 + FC4(10) + log_softmax
from __future__ import print_function # 从future版本导入print函数功能
import argparse # 加载处理命令行参数的库
import torch # 引入相关的包
import torch.nn as nn # 指定torch.nn别名nn
import torch.nn.functional as F # 引用神经网络常用函数包,不具有可学习的参数
import torch.optim as optim
from torchvision import datasets, transforms # 加载pytorch官方提供的dataset
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(784, 1000) # 784表示输入神经元数量,1000表示输出神经元数量
self.fc2 = nn.Linear(1000, 500)
self.fc3 = nn.Linear(500, 200)
self.fc4 = nn.Linear(200, 10)
def forward(self, x):
x = x.view(-1, 28*28)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = F.relu(self.fc3(x))
x = self.fc4(x)
return F.log_softmax(x, dim=1) #Applies a softmax followed by a logarithm, output batch * classes tensor
def train(args, model, device, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target) # negative log likelihood loss(nll_loss), sum up batch cross entropy
loss.backward()
optimizer.step() # 根据parameter的梯度更新parameter的值
#print(epoch, batch_idx, type(batch_idx))
if batch_idx % args.log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
def test(args, model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad(): #无需计算梯度
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.nll_loss(output, target, reduction='sum').item() # sum up batch loss
pred = output.argmax(dim=1, keepdim=True) # get the index of the max log-probability
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
def main():
# Training settings
parser = argparse.ArgumentParser(description='PyTorch MNIST Example')
parser.add_argument('--batch-size', type=int, default=64, metavar='N',
help='input batch size for training (default: 64)')
parser.add_argument('--test-batch-size', type=int, default=1000, metavar='N',
help='input batch size for testing (default: 1000)')
parser.add_argument('--epochs', type=int, default=10, metavar='N',
help='number of epochs to train (default: 10)')
parser.add_argument('--lr', type=float, default=0.01, metavar='LR',
help='learning rate (default: 0.01)')
parser.add_argument('--momentum', type=float, default=0.5, metavar='M',
help='SGD momentum (default: 0.5)')
parser.add_argument('--no-cuda', action='store_true', default=False,
help='disables CUDA training')
parser.add_argument('--seed', type=int, default=1, metavar='S',
help='random seed (default: 1)')
parser.add_argument('--log-interval', type=int, default=10, metavar='N',
help='how many batches to wait before logging training status')
parser.add_argument('--save-model', action='store_true', default=True,
help='For Saving the current Model')
args = parser.parse_args()
use_cuda = not args.no_cuda and torch.cuda.is_available()
torch.manual_seed(args.seed)
device = torch.device("cuda" if use_cuda else "cpu")
kwargs = {'num_workers': 1, 'pin_memory': True} if use_cuda else {}
train_loader = torch.utils.data.DataLoader(
datasets.FashionMNIST('./fashionmnist_data/', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=args.batch_size, shuffle=True, **kwargs)
test_loader = torch.utils.data.DataLoader(
datasets.FashionMNIST('./fashionmnist_data/', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=args.test_batch_size, shuffle=True, **kwargs)
model = Net().to(device)
optimizer = optim.SGD(model.parameters(), lr=args.lr, momentum=args.momentum) #optimizer存储了所有parameters的引用,每个parameter都包含gradient
scheduler = optim.lr_scheduler.MultiStepLR(optimizer, milestones=[12, 24], gamma=0.1) #学习率按区间更新
for epoch in range(1, args.epochs + 1):
train(args, model, device, train_loader, optimizer, epoch)
test(args, model, device, test_loader)
if (args.save_model):
torch.save(model.state_dict(), "mnist_fc.pt")
# 当.py文件直接运行时,该语句及以下的代码被执行,当.py被调用时,该语句及以下的代码不被执行
if __name__ == '__main__':
main()
python 02_fashion_mnist_fc.py --epochs=36
备注:
数据集下载比较慢,第一次训练时,train_loader中download设置为True,后面再训练时改为False
F.log_softmax只是对输出结果做softmax后再取log
optimizer存储了所有parameters的引用,每个parameter都包含gradient
scheduler根据设置的epoch区间来调整学习率大小,调整率为gamma
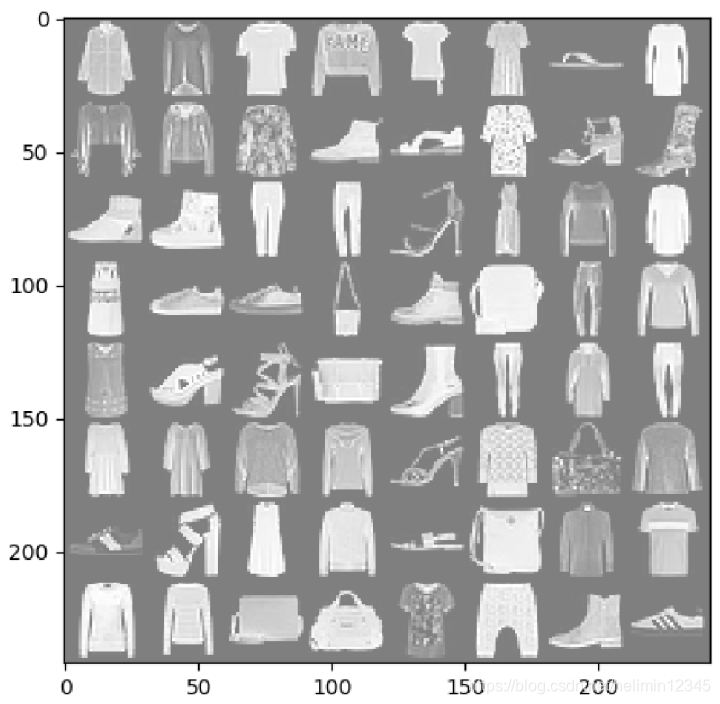
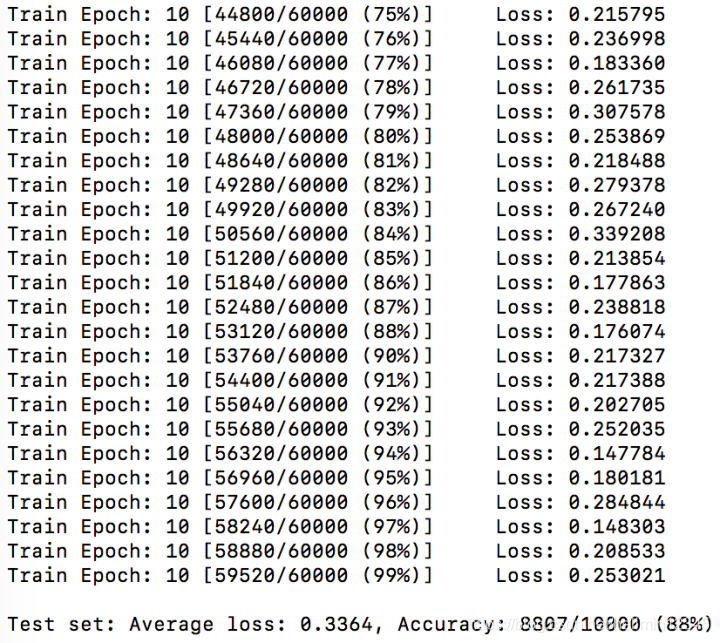
训练过程中,随机选择1个batch的数据显示,如下:
训练结果如下,top1准确率为88%,网络参数大小为5.1M
2.2 CNN网络
FC网络参数量太大,而CNN网络考虑到图像的局部关联特性,使用卷积网络,参数量大小减小,设计如下CNN,代码全名为02_fashion_mnist_cnn.py
conv(1, 20, 5) + Relu + conv(20, 50, 5) + flatten + Relu + FC(10) + log_softmax
from __future__ import print_function # 从future版本导入print函数功能
import argparse # 加载处理命令行参数的库
import torch # 引入相关的包
import torch.nn as nn # 指定torch.nn别名nn
import torch.nn.functional as F # 引用神经网络常用函数包,不具有可学习的参数
import torch.optim as optim
from torchvision import datasets, transforms # 加载pytorch官方提供的dataset
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 20, 5, 1) # 1表示输入通道,20表示输出通道,5表示conv核大小,1表示conv步长
self.conv2 = nn.Conv2d(20, 50, 5, 1)
self.fc1 = nn.Linear(4 * 4 * 50, 500)
self.fc2 = nn.Linear(500, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.max_pool2d(x, 2, 2)
x = F.relu(self.conv2(x))
x = F.max_pool2d(x, 2, 2)
x = x.view(-1, 4 * 4 * 50)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return F.log_softmax(x, dim=1)
def train(args, model, device, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % args.log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
def test(args, model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.nll_loss(output, target, reduction='sum').item() # sum up batch loss
pred = output.argmax(dim=1, keepdim=True) # get the index of the max log-probability
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
def main():
# Training settings
parser = argparse.ArgumentParser(description='PyTorch MNIST Example')
parser.add_argument('--batch-size', type=int, default=64, metavar='N',
help='input batch size for training (default: 64)')
parser.add_argument('--test-batch-size', type=int, default=1000, metavar='N',
help='input batch size for testing (default: 1000)')
parser.add_argument('--epochs', type=int, default=10, metavar='N',
help='number of epochs to train (default: 10)')
parser.add_argument('--lr', type=float, default=0.01, metavar='LR',
help='learning rate (default: 0.01)')
parser.add_argument('--momentum', type=float, default=0.5, metavar='M',
help='SGD momentum (default: 0.5)')
parser.add_argument('--no-cuda', action='store_true', default=False,
help='disables CUDA training')
parser.add_argument('--seed', type=int, default=1, metavar='S',
help='random seed (default: 1)')
parser.add_argument('--log-interval', type=int, default=10, metavar='N',
help='how many batches to wait before logging training status')
parser.add_argument('--save-model', action='store_true', default=False,
help='For Saving the current Model')
args = parser.parse_args()
use_cuda = not args.no_cuda and torch.cuda.is_available()
torch.manual_seed(args.seed)
device = torch.device("cuda" if use_cuda else "cpu")
kwargs = {'num_workers': 1, 'pin_memory': True} if use_cuda else {}
train_loader = torch.utils.data.DataLoader(
datasets.FashionMNIST('./fashionmnist_data/', train=True, download=False,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=args.batch_size, shuffle=True, **kwargs)
test_loader = torch.utils.data.DataLoader(
datasets.FashionMNIST('./fashionmnist_data/', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=args.test_batch_size, shuffle=True, **kwargs)
model = Net().to(device)
optimizer = optim.SGD(model.parameters(), lr=args.lr, momentum=args.momentum)
scheduler = optim.lr_scheduler.MultiStepLR(optimizer, milestones=[12, 24], gamma=0.1)
for epoch in range(1, args.epochs + 1):
train(args, model, device, train_loader, optimizer, epoch)
test(args, model, device, test_loader)
if (args.save_model):
torch.save(model.state_dict(), "mnist_cnn.pt")
# 当.py文件直接运行时,该语句及以下的代码被执行,当.py被调用时,该语句及以下的代码不被执行
if __name__ == '__main__':
main()
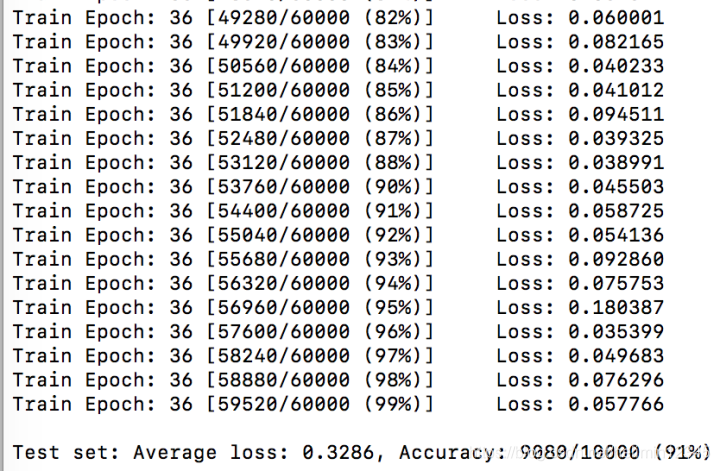
python 02_fashion_mnist_cnn.py --epochs=36
训练结果如下,top1准确率为91%。
标题3. references
[1] https://github.com/zalandoresearch/fashion-mnist
[2] https://pytorch.org/docs/stable/_modules/torch/optim/lr_scheduler.html
[3] https://github.com/zalandoresearch/fashion-mnist
智能推荐
MultipartFile的属性 file.getOriginalFilename()与file.getName()的区别 MultipartFile与File互转_multipartfile属性-程序员宅基地
文章浏览阅读1.9k次,点赞3次,收藏5次。MultipartFile为org.springframework.web.mutipart包下的一个类,也就是说如果想使用MultipartFile这个类就必须引入spring框架,换句话说,如果想在项目中使用MultipartFile这个类,那么项目必须要使用spring框架才可以,否则无法引入这个类。以下基于spring-web.5.2.9.RELEASE源码了解一下MultipartFileMultipartFile注释说明第一句:一种可以接收使用多种请求方式来进行上传文件的代表形式。_multipartfile属性
english-程序员宅基地
文章浏览阅读1.8k次。关于音标: 1.http://blog.hjenglish.com/melodious/category/2060.html(美音听力及发音小技巧) 2.http://det.tjfsu.edu.cn/learning/oral.htm(英语口语学习资源) 3.http://203.68.17.29/mis/mono/kevin/EteachWeb/KK%AD%B5%BC%D0/kk.htm
Android studio升级3.0 carry2 出现问题Gradle sync failed: Connection timed out: connect解决办法_gradle sync failed: read timed out consult ide log-程序员宅基地
文章浏览阅读3.7w次,点赞3次,收藏14次。android studio 3.0升级后报错的解决_gradle sync failed: read timed out consult ide log for more details (help
IText5 PDF合并并且添加书签_itextsharp 添加页签-程序员宅基地
文章浏览阅读290次。多个PDF合并,添加书签,更好的多每个PDF进行定位查看,书签定位带每个PDF的第一页。_itextsharp 添加页签
Qt5 的connect新语法中 lambda表达式的引用传递问题_lambda qt connect 传参-程序员宅基地
文章浏览阅读1.7k次。介绍 Qt5 的 connect 新式语法的文章很多,关于其使用 lambda 表达式的语法也很容易搜到,今天我来一点不一样的干货也可以说是bug,由于个人能力原因,无法深究真正的原因,望神通广大的网友能告知一下,不尽感激。/* * 使用Qt 5.15.0 创建一个新的GUI程序,基类选择QWidget * 同时取消创建 ui界面,在 widget.cpp 中写上下面的代码 * 然后编译执行,在弹出的窗口中,点击QPushButton即可验证*/#include "widget.h"#incl_lambda qt connect 传参
【转】GitLab 7.2.1 升级到 7.14.3 过程中遇到的坑_gitlab gc-程序员宅基地
文章浏览阅读281次。转自:http://dockone.io/article/8413GitLab 7.2.1 升级到 7.14.3 过程中遇到的坑【背景】在此次升级之前,我们线上的 GitLab 7.2.1 版本已经跑了3年之久,其中结合我们自己的 CI/CD 流程添加了一些自定义的 feature,整个 CI/CD 流程运行的也十分顺畅。不过随着微服务、Docker、Kubernetes、Servic..._gitlab gc
随便推点
CSS3做出条纹大背景-程序员宅基地
文章浏览阅读168次。㈠实现不等宽背景条纹实现如上图所示的效果,代码如下: 1 <!DOCTYPE html> 2 <html lang="en"> 3 <head> 4 <meta charset="UTF-8"> 5 <style type="text/css"> 6 .con..._css3 条纹背景
IT项目实施流程及每个阶段输出的文档_项目管理各个阶段输出文档-程序员宅基地
文章浏览阅读3.3k次,点赞2次,收藏12次。IT项目实施流程及每个阶段输出的文档_项目管理各个阶段输出文档
【瑞萨RA_FSP】SCL UART 串口通信_sci和uart-程序员宅基地
文章浏览阅读1.6k次,点赞3次,收藏11次。串口通讯(Serial Communication)是一种设备间非常常用的串行通讯方式,因为它简单便捷,因此大部分电子设备都支持该通讯方式,电子工程师在调试设备时也经常使用该通讯方式输出调试信息。在计算机科学里,大部分复杂的问题都可以通过分层来简化。如芯片被分为内核层和片上外设。对于通讯协议, 我们也以分层的方式来理解,最基本的是把它分为物理层和协议层。物理层规定通讯系统中具有机械、电子功能部分的特性,确保原始数据在物理媒体的传输。协议层主要规定通讯逻辑,统一收发双方的数据打包、解包标准。_sci和uart
生成模型在知识图谱构建中的应用:如何提高知识抽取和整合能力-程序员宅基地
文章浏览阅读737次,点赞20次,收藏5次。1.背景介绍知识图谱(Knowledge Graph, KG)是一种表示实体、关系和实例的数据结构,它可以帮助计算机理解和推理人类语言中的信息。知识图谱已经成为人工智能和大数据领域的重要技术,它在自然语言处理、推荐系统、问答系统等方面发挥着重要作用。然而,知识图谱的构建是一个非常挑战性的任务,因为它需要从大量的文本数据中自动抽取和整合知识。生成模型(Generative Model)是一类...
我的心得:数据中心运维&管理(二)-程序员宅基地
文章浏览阅读2.9k次。续接:《我的心得:数据中心运维&管理(一)》5:追其根源,防患未然:5Why 分析法在数据中心的应用;如何有效的解决问题,首先需要了解产生此问题的因素和最根本因素;如何寻找根本原因?需要更加有效合理的工具方法,下面给大家介绍一下典型的 5-Why 分析法:什么是 5-Why5-why 的关键在于鼓励解决问题的人要努力避开主观或自负的假设和逻辑陷阱,从结果着手,沿着因果关系链条,顺藤摸瓜,直至找出原_数据中心运维汇报案例
粒子群优化算法(PSO)-程序员宅基地
文章浏览阅读1.9w次,点赞34次,收藏307次。先简单介绍一下粒子群优化算法(Particle Swarm Optimization),后边会介绍一些改进的粒子群算法。1.背景知识受到鸟群觅食行为的启发(鸟群觅食,通过信息共享使种群找到最优的觅食点),由社会心理学家JamesKennedy和电气工程师RussellEberhart于1995年提出,用于解决科学工程领域的非线性,非凸性,组合优化问题;在函数优化,图像处理也有广泛的应用。粒子群优化算法是一种基于数值的优化算法,粒子群优化算法的基础是“信息共享”。具..._粒子群优化算法