常用数据结构及算法_java数据结构常见算法-程序员宅基地
翻译来自:https://github.com/kdn251/interviews#live-coding-practice
数据结构
Linked List
- 链表是数据元素的线性集合,称为节点,每个元素通过指针指向下一个节点。 它是由一组节点组成的数据结构,它们一起表示一个序列。
- 单链表 : 其中每个节点指向下一个节点,而最后一个节点指向null。
- 双向链表 : 其中每个节点具有两个指针p,n,使得p指向前一个节点,并且n指向下一个节点; 最后一个节点的n个指针指向null。
- 循环链表 : 其中每个节点指向下一个节点,并且最后一个节点指向第一个节点。
时间复杂度
索引: O(n)
查找: O(n)
插入: O(1)
移除: O(1)
Stack
- 栈是一个元素的集合,有两个主要的操作:push,它添加到集合中,而pop,用于删除最近添加的元素
- Last in, first out data structure (LIFO)后进先出的数据结构
- 时间复杂度:
索引: O(n)
查找: O(n)
插入: O(1)
删除: O(1)
Queue
- 队列是一个元素的集合,支持两个主要的操作:入队,将一个元素插入到队列中,出队,从队列中删除一个元素
- First in, first out data structure (FIFO)先进先出的数据结构
- 时间复杂度:
索引: O(n)
查找: O(n)
插入: O(1)
删除: O(1)
tree
- 树是一个无向,连接的非循环图
Binary Tree
- 二叉树是一个树状数据结构,其中每个节点最多有两个子节点,这被称为左子节点和右子节点
- 满二叉树(Full Tree):每个节点有 0 或者 2 个子节点
- 完美二叉树(Perfect Binary Tree):每个节点有两个子节点,并且所有的叶子节点的深度是一样的。
- 完全二叉树(Complete Tree):除最后一层外其他各层的节点数均达到最大值,最后一层的节点都连续集中在最左边。
Binary Search Tree
- 二叉查找树(BST)是一种二叉树。其任何节点的值都大于等于左子树中的值,小于等于右子树中的值。
- 时间复杂度:
索引: O(log(n))
查找: O(log(n))
插入: O(log(n))
删除: O(log(n))
Trie
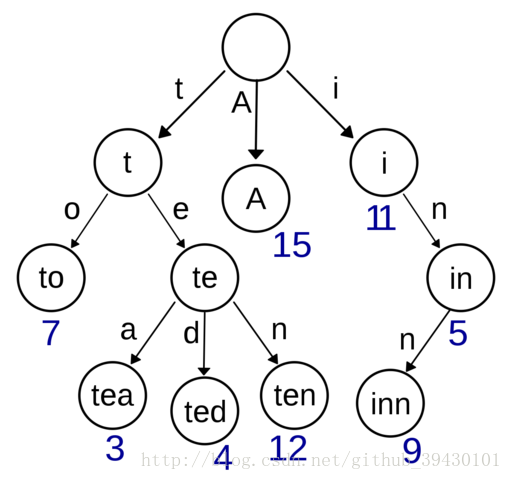
- 字典树,又称为基数树或前缀树,用于存储键值为字符串的动态集合或关联数组的查找树。树中的节点并不直接存储关联键值,而是该节点在树中的位置决定了其关联键值。一个节点的所有子节点都有相同的前缀,根节点则是空字符串。
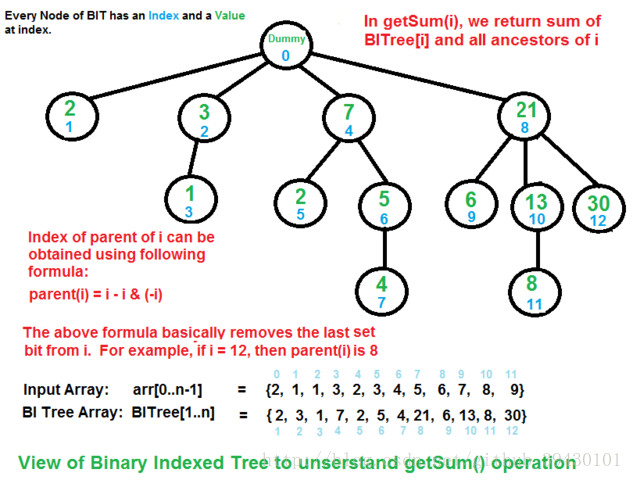
Fenwick Tree
- 树状数组,又称为二进制索引树(Binary Indexed Tree,BIT),其概念上是树,但以数组实现。数组中的下标代表树中的节点,每个节点的父节点或子节点的下标可以通过位运算获得。数组中的每个元素都包含了预计算的区间值之和,在整个树更新的过程中,这些计算的值也同样会被更新。
- 时间复杂度:
区间求和: O(log(n))
跟新: O(log(n))
Segment Tree
- 线段树是用于存储区间和线段的树形数据结构。它允许查找一个节点在若干条线段中出现的次数。
- 时间复杂度:
Range Query: O(log(n))
Update: O(log(n))
Heap
- 堆是一种基于树的满足某些特性的数据结构:整个堆中的所有父子节点的键值都满足相同的排序条件。堆分为最大堆和最小堆。在最大堆中,父节点的键值永远大于等于所有子节点的键值,根节点的键值是最大的。最小堆中,父节点的键值永远小于等于所有子节点的键值,根节点的键值是最小的。
- 时间复杂度
Access: O(log(n))
Search: O(log(n))
Insert: O(log(n))
Remove: O(log(n))
Remove Max / Min: O(1)
Hashing
- 哈希用于将任意长度的数据映射到固定长度的数据。哈希函数的返回值被称为哈希值、哈希码或者哈希。如果不同的主键得到相同的哈希值,则发生了冲突。
- Hash Map:hash map 是一个存储键值间关系的数据结构。HashMap 通过哈希函数将键转化为桶或者槽中的下标,从而便于指定值的查找。
冲突解决:
链地址法(Separate Chaining):在链地址法中,每个桶(bucket)是相互独立的,每一个索引对应一个元素列表。处理HashMap 的时间就是查找桶的时间(常量)与遍历列表元素的时间之和。开放地址法(Open Addressing):在开放地址方法中,当插入新值时,会判断该值对应的哈希桶是否存在,如果存在则根据某种算法依次选择下一个可能的位置,直到找到一个未被占用的地址。开放地址即某个元素的位置并不永远由其哈希值决定。

Graph
- 图是G =(V,E)的有序对,其包括顶点或节点的集合 V 以及边或弧的集合E,其中E包括了两个来自V的元素(即边与两个顶点相关联 ,并且该关联为这两个顶点的无序对)。
- 无向图:图的邻接矩阵是对称的,因此如果存在节点 u 到节点 v 的边,那节点 v 到节点 u 的边也一定存在。
- 有向图:图的邻接矩阵不是对称的。因此如果存在节点 u 到节点 v 的边并不意味着一定存在节点 v 到节点 u 的边。

算法
排序
快速排序
- 稳定 否
- 时间复杂度
最优: O(nlog(n))
最差: O(n^2)
平均: O(nlog(n))

合并排序
- 合并排序是一种分治算法。这个算法不断地将一个数组分为两部分,分别对左子数组和右子数组排序,然后将两个数组合并为新的有序数组。
- 稳定: 是
时间复杂度:
最优:O(nlog(n))
最差:O(nlog(n))
平均:O(nlog(n))

桶排序
- 桶排序是一种将元素分到一定数量的桶中的排序算法。每个桶内部采用其他算法排序,或递归调用桶排序。
- 时间复杂度 :
最优: Ω(n + k)
最差: O(n^2)
平均:Θ(n + k)
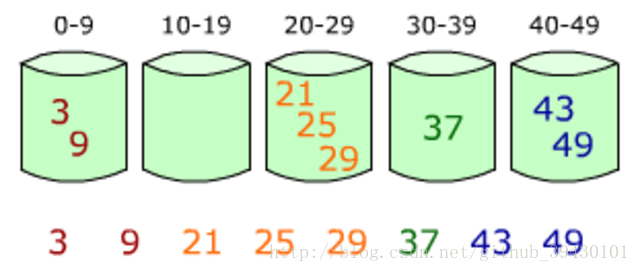
基数排序
- 基数排序类似于桶排序,将元素分发到一定数目的桶中。不同的是,基数排序在分割元素之后没有让每个桶单独进行排序,而是直接做了合并操作。
- 时间复杂度:
Best Case: Ω(nk)
Worst Case: O(nk)
Average Case: Θ(nk)
图算法
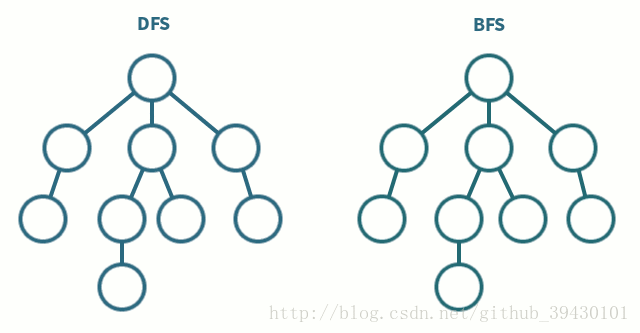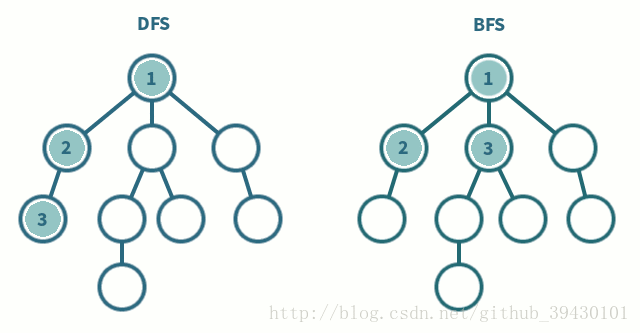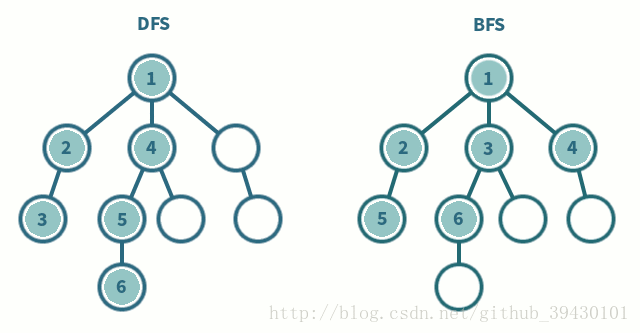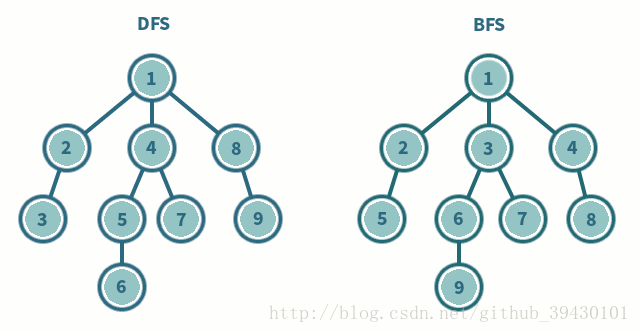
深度优先搜索
- 深度优先搜索是一种先遍历子节点而不回溯的图遍历算法。
- 时间复杂度:O(|V| + |E|)
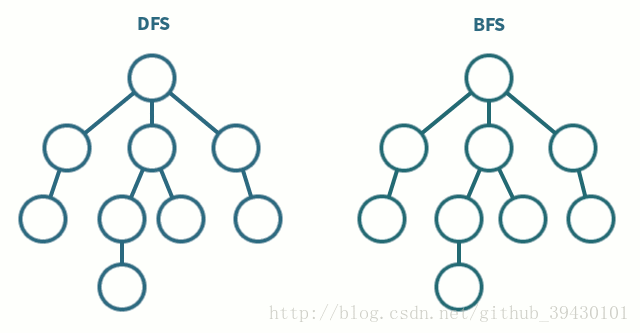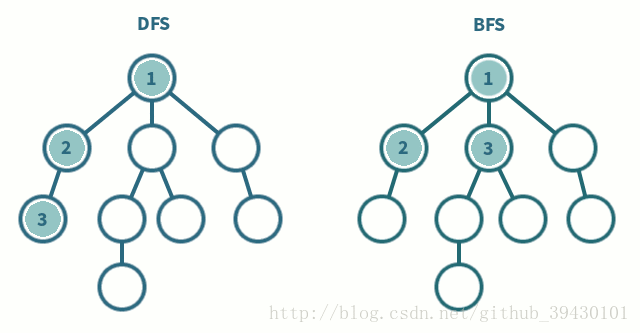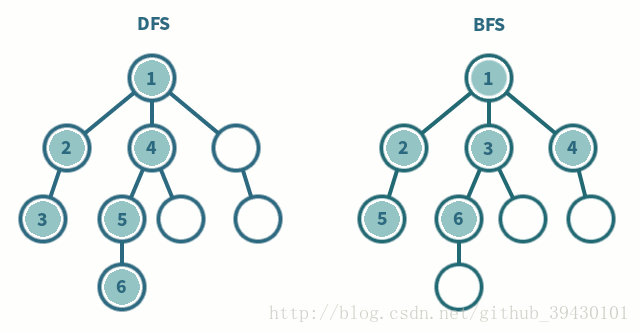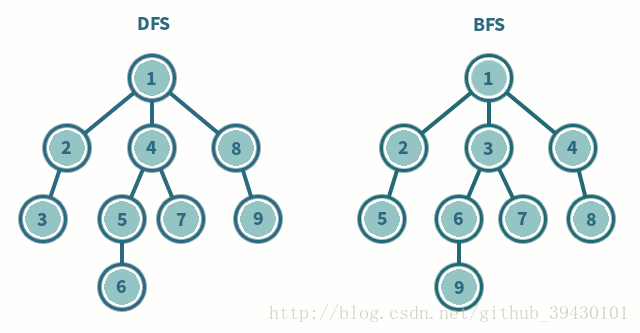
广度优先搜索
- 广度优先搜索是一种先遍历邻居节点而不是子节点的图遍历算法。
- 时间复杂度:O(|V| + |E|)
拓扑排序
- 拓扑排序是有向图节点的线性排序。对于任何一条节点 u 到节点 v 的边,u 的下标先于 v。
- 时间复杂度:O(|V| + |E|)
Dijkstra算法
- Dijkstra 算法是一种在有向图中查找单源最短路径的算法
- 时间复杂度:O(|V|^2)

Bellman-Ford算法
- Bellman-Ford 是一种在带权图中查找单一源点到其他节点最短路径的算法。
- 虽然时间复杂度大于 Dijkstra 算法,但它可以处理包含了负值边的图
时间复杂度:
最优:O(|E|)
最差:O(|V||E|)

Floyd-Warshall 算法
- Floyd-Warshall 算法是一种在无环带权图中寻找任意节点间最短路径的算法。
- 该算法执行一次即可找到所有节点间的最短路径(路径权重和)。
- 时间复杂度 :
Best Case: O(|V|^3)
Worst Case: O(|V|^3)
Average Case: O(|V|^3)
最小生成树算法
- 最小生成树算法是一种在无向带权图中查找最小生成树的贪心算法。换言之,最小生成树算法能在一个图中找到连接所有节点的边的最小子集
- 时间复杂度 :
O(|V|^2)
Kruskal’s 算法
- Kruskal 算法也是一个计算最小生成树的贪心算法,但在 Kruskal 算法中,图不一定是连通的
- 时间复杂度 :O(|E|log|V|)

贪心算法
- 贪心算法总是做出在当前看来最优的选择,并希望最后整体也是最优的
使用贪心算法可以解决的问题必须具有如下两种特性:
最优子结构
问题的最优解包含其子问题的最优解。
贪心选择
每一步的贪心选择可以得到问题的整体最优解。实例-硬币选择问题
- 给定期望的硬币总和为 V 分,以及 n 种硬币,即类型是 i 的硬币共有 coinValue[i] 分,i的范围是 [0…n – 1]。假设每种类型的硬币都有无限个,求解为使和为 V 分最少需要多少硬币?
- 硬币:便士(1美分),镍(5美分),一角(10美分),四分之一(25美分)
假设总和 V 为41,。我们可以使用贪心算法查找小于或者等于 V 的面值最大的硬币,然后从 V 中减掉该硬币的值,如此重复进行。
V = 41 | 使用了0个硬币
V = 16 | 使用了1个硬币(41 – 25 = 16)
V = 6 | 使用了2个硬币(16 – 10 = 6)
V = 1 | 使用了3个硬币(6 – 5 = 1)
V = 0 | 使用了4个硬币(1 – 1 = 0)
位运算
- 位运算即在比特级别进行操作的技术。使用位运算技术可以带来更快的运行速度与更小的内存使用。
- 测试第 k 位:s & (1 << k);
- 设置第k位:s |= (1 << k);
- 关闭第k位:s &= ~(1 << k);
- 切换第k位:s ^= (1 << k);
- 乘以2n:s << n;
- 除以2n:s >> n;
- 交集:s & t;
- 并集:s | t;
- 减法:s & ~t;
- 提取最小非0位:s & (-s);
- 提取最小0位:~s & (s + 1);
- 交换值:x ^= y; y ^= x; x ^= y;
运行时分析
大 O 表示
- 大 O 表示用于表示某个算法的上界,用于描述最坏的情况。
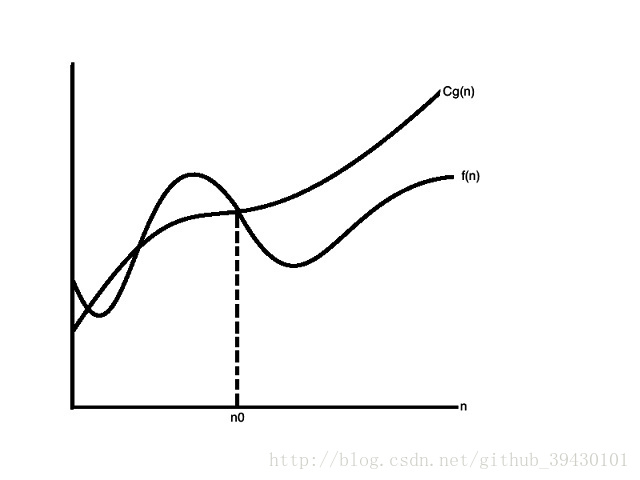
小O表示
- 小 O 表示用于描述某个算法的渐进上界,二者逐渐趋近
大 Ω 表示
- 大 Ω 表示用于描述某个算法的渐进下界。
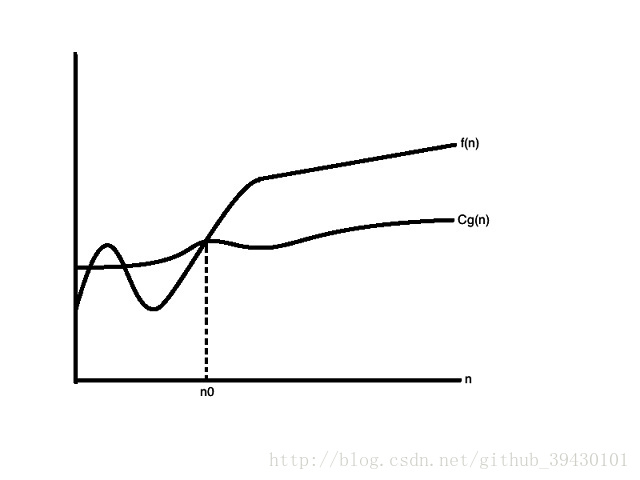
小 ω 表示
- 小 ω 表示用于描述某个算法的渐进下界,二者逐渐趋近。
Theta Θ 表示
- Theta Θ 表示用于描述某个算法的确界,包括最小上界和最大下界。

.
代码实现 https://github.com/kdn251/interviews#live-coding-practice 目录如下
├── Array
│ ├── bestTimeToBuyAndSellStock.java
│ ├── findTheCelebrity.java
│ ├── gameOfLife.java
│ ├── increasingTripletSubsequence.java
│ ├── insertInterval.java
│ ├── longestConsecutiveSequence.java
│ ├── maximumProductSubarray.java
│ ├── maximumSubarray.java
│ ├── mergeIntervals.java
│ ├── missingRanges.java
│ ├── productOfArrayExceptSelf.java
│ ├── rotateImage.java
│ ├── searchInRotatedSortedArray.java
│ ├── spiralMatrixII.java
│ ├── subsetsII.java
│ ├── subsets.java
│ ├── summaryRanges.java
│ ├── wiggleSort.java
│ └── wordSearch.java
├── Backtracking
│ ├── androidUnlockPatterns.java
│ ├── generalizedAbbreviation.java
│ └── letterCombinationsOfAPhoneNumber.java
├── BinarySearch
│ ├── closestBinarySearchTreeValue.java
│ ├── firstBadVersion.java
│ ├── guessNumberHigherOrLower.java
│ ├── pow(x,n).java
│ └── sqrt(x).java
├── BitManipulation
│ ├── binaryWatch.java
│ ├── countingBits.java
│ ├── hammingDistance.java
│ ├── maximumProductOfWordLengths.java
│ ├── numberOf1Bits.java
│ ├── sumOfTwoIntegers.java
│ └── utf-8Validation.java
├── BreadthFirstSearch
│ ├── binaryTreeLevelOrderTraversal.java
│ ├── cloneGraph.java
│ ├── pacificAtlanticWaterFlow.java
│ ├── removeInvalidParentheses.java
│ ├── shortestDistanceFromAllBuildings.java
│ ├── symmetricTree.java
│ └── wallsAndGates.java
├── DepthFirstSearch
│ ├── balancedBinaryTree.java
│ ├── battleshipsInABoard.java
│ ├── convertSortedArrayToBinarySearchTree.java
│ ├── maximumDepthOfABinaryTree.java
│ ├── numberOfIslands.java
│ ├── populatingNextRightPointersInEachNode.java
│ └── sameTree.java
├── Design
│ └── zigzagIterator.java
├── DivideAndConquer
│ ├── expressionAddOperators.java
│ └── kthLargestElementInAnArray.java
├── DynamicProgramming
│ ├── bombEnemy.java
│ ├── climbingStairs.java
│ ├── combinationSumIV.java
│ ├── countingBits.java
│ ├── editDistance.java
│ ├── houseRobber.java
│ ├── paintFence.java
│ ├── paintHouseII.java
│ ├── regularExpressionMatching.java
│ ├── sentenceScreenFitting.java
│ ├── uniqueBinarySearchTrees.java
│ └── wordBreak.java
├── HashTable
│ ├── binaryTreeVerticalOrderTraversal.java
│ ├── findTheDifference.java
│ ├── groupAnagrams.java
│ ├── groupShiftedStrings.java
│ ├── islandPerimeter.java
│ ├── loggerRateLimiter.java
│ ├── maximumSizeSubarraySumEqualsK.java
│ ├── minimumWindowSubstring.java
│ ├── sparseMatrixMultiplication.java
│ ├── strobogrammaticNumber.java
│ ├── twoSum.java
│ └── uniqueWordAbbreviation.java
├── LinkedList
│ ├── addTwoNumbers.java
│ ├── deleteNodeInALinkedList.java
│ ├── mergeKSortedLists.java
│ ├── palindromeLinkedList.java
│ ├── plusOneLinkedList.java
│ ├── README.md
│ └── reverseLinkedList.java
├── Queue
│ └── movingAverageFromDataStream.java
├── README.md
├── Sort
│ ├── meetingRoomsII.java
│ └── meetingRooms.java
├── Stack
│ ├── binarySearchTreeIterator.java
│ ├── decodeString.java
│ ├── flattenNestedListIterator.java
│ └── trappingRainWater.java
├── String
│ ├── addBinary.java
│ ├── countAndSay.java
│ ├── decodeWays.java
│ ├── editDistance.java
│ ├── integerToEnglishWords.java
│ ├── longestPalindrome.java
│ ├── longestSubstringWithAtMostKDistinctCharacters.java
│ ├── minimumWindowSubstring.java
│ ├── multiplyString.java
│ ├── oneEditDistance.java
│ ├── palindromePermutation.java
│ ├── README.md
│ ├── reverseVowelsOfAString.java
│ ├── romanToInteger.java
│ ├── validPalindrome.java
│ └── validParentheses.java
├── Tree
│ ├── binaryTreeMaximumPathSum.java
│ ├── binaryTreePaths.java
│ ├── inorderSuccessorInBST.java
│ ├── invertBinaryTree.java
│ ├── lowestCommonAncestorOfABinaryTree.java
│ ├── sumOfLeftLeaves.java
│ └── validateBinarySearchTree.java
├── Trie
│ ├── addAndSearchWordDataStructureDesign.java
│ ├── implementTrie.java
│ └── wordSquares.java
└── TwoPointers
├── 3Sum.java
├── 3SumSmaller.java
├── mergeSortedArray.java
├── minimumSizeSubarraySum.java
├── moveZeros.java
├── removeDuplicatesFromSortedArray.java
├── reverseString.java
└── sortColors.java
智能推荐
017、Python+fastapi,第一个Python项目走向第17步:ubuntu24.04 无界面服务器版下安装nvidia显卡驱动
新的ubuntu24.04正式版发布了,前段时间玩了下桌面版,感觉还行,先安装一个服务器无界面版本吧安装时有一个openssh选择安装,要不然就不能ssh远程,我就是没选,后来重新安装ssh。另外一个就是安装过程中静态ip设置下在etc/netplan 文件夹下,有一个yaml文件,我的是50-cloud-init.yaml,先用ip a看看network:ethernets:enp3s0:routes:version: 2。
不是阿里P8级大佬,岂能错过这篇MySQL运维内参?啃透涨薪so easy-程序员宅基地
文章浏览阅读176次。写在前面MySQL被设计为一个可移植的数据库,几乎在当前所有系统上都能运行,如Linux、Solaris、 FreeBSD、 Mac和Windows。尽管各平台在底层(如线程)实现方面都各有不同,但是MySQL基本上能保证在各平台上的物理体系结构的一致性。因此,用户应该能很好地理解MySQL数据库在所有这些平台上是如何运作的。由于工作的缘故,笔者的大部分时间需要与开发人员进行数据库方面的沟通,并对他们进行培训。不论他们是DBA,还是开发人员,似乎都对MySQL的体系结构了解得不够透彻。很多人喜欢把M_mysql运维内参
百度正用谷歌AlphaGo,解决一个比围棋更难的问题 | 300块GPU在燃烧-程序员宅基地
文章浏览阅读382次。晓查 发自 凹非寺量子位 报道 | 公众号 QbitAI9102年,人类依然不断回想起围棋技艺被AlphaGo所碾压的恐怖。却也有不以为然的声音:只会下棋的AI,再厉害..._alpha go训练用了多少个gpu
docker 容器 设置网络代理_docker export http_proxy-程序员宅基地
文章浏览阅读3.3k次。docker 容器 设置网络代理以/bin/bash 形式进入容器:【设置http 及https代理】,如下:export http_proxy=http://172.16.0.20:3128export https_proxy=https://172.16.0.20:3128要取消该设置:unsethttp_proxyunset https_proxy..._docker export http_proxy
linux之笔记_linux 0775十六進制-程序员宅基地
文章浏览阅读263次。授课环境: 结束程序运行: ctrl + c 共享目录(工作目录): /kyo /Videos 访问共享目录流程: 是否能连通服务器 ping 3.3.3.9 是否服务器开启共享 showmount -e 3.3.3.9 挂载共享目录到本地: _linux 0775十六進制
普通屏幕已过时?裸眼3D屏幕显示效果更胜一筹!
与普通屏幕中播放的视频相对,裸眼3D屏幕需要先将裸眼3D视频分成两部分,分别呈现在左右两个视窗上,因此后者需要更高的分辨率,以及更精细的图像处理能力,以此使裸眼3D屏幕的画面展示效果更加细腻,进而加深每个物体和场景的深度感和空间感,让每个驻足于此的观众惊叹于裸眼3D屏幕的震撼视觉效果。另外,裸眼3D屏幕的色彩表现,也比大多的普通屏幕更加丰富和鲜艳,能够展现出电影级别的画面质量,总而言之,裸眼3D屏幕比之普通屏幕的显示效果,有着巨大的优势,这也是使裸眼3D成为重要显示技术的重要原因!
随便推点
OpenHarmony语言基础类库【@ohos.util.List (线性容器List)】
而网上有关鸿蒙的开发资料非常的少,假如你想学好鸿蒙的应用开发与系统底层开发。你可以参考这份资料,少走很多弯路,节省没必要的麻烦。由两位前阿里高级研发工程师联合打造的《鸿蒙NEXT星河版OpenHarmony开发文档》里面内容包含了(ArkTS、ArkUI开发组件、Stage模型、多端部署、分布式应用开发、音频、视频、WebGL、OpenHarmony多媒体技术、Napi组件、OpenHarmony内核、Harmony南向开发、鸿蒙项目实战等等)鸿蒙(Harmony NEXT)技术知识点。
[自学笔记] ESP32-C3 Micropython初次配置
2、本次测试了两款IDE,分别是"thonny-4.1.4.exe"和"uPyCraft-v1.0.exe"。Thonny支持中文及多语言。而uPyCraft-v1.0只支持英文语言。因此入门时选用了Thonny作为IDE。(注:1、测试过程中IDE正常连接ESP32C3简约版的虚拟串口。不受简约版无串口芯片的影响。
初识Electron,创建桌面应用
古有匈奴犯汉,晋室不纲,铁木夺宋,虏清入关,神舟陆沉二百年有余,中国之见灭于满清初非满人能灭之,能有之也因有汉奸以作虎怅,残同胞媚异种,始有吴三桂洪承畴,继有曾国藩袁世凯以为厉。今率堂堂之师,征讨汉贼袁氏筑共和之体,或免于我子子孙孙被异族奴役。---- 《讨汉贼袁世凯檄文》- DOMContentLoaded事件:此时浏览器已经完全加载了HTML文件,并且DOM树已经生成好了。- Load事件:此时浏览器已经将所有的资源都加载完毕,可以正确读取页面中的资源。补充知识:Electron 生命周期。
Xcode 15构建问题
将ENABLE_USER_SCRIPT_SANDBOXING设为“no”即可!
OpenVINO应用案例:部署YOLO模型到边缘计算摄像头_openvino yolo-程序员宅基地
文章浏览阅读2.8k次,点赞3次,收藏23次。一、实现路径通过OpenVINO部署YOLO模型到边缘计算摄像头,其实现路径为:训练(YOLO)->转换(OpenVINO)->部署运行(OpenNCC)。二、具体步骤1、训练YOLO模型1.1 安装环境依赖有关安装详情请参阅 https://github.com/AlexeyAB/darknet#requirements-for-windows-linux-and-macos 。1.2 编译训练工具git clone https://github.com/AlexeyAB/da_openvino yolo
数据污染对大型语言模型的潜在影响
总之,数据污染在LLMs中构成一个潜在的重要问题,可能影响它们在各种任务中的性能。它可能导致结果偏倚并削弱LLMs的真实有效性。通过识别和减轻数据污染,我们可以确保LLMs运行良好并产生准确的结果。现在是技术社区优先考虑数据完整性在LLMs的开发和利用中的时候了。通过这样做,我们可以确保LLMs产生无偏见且可靠的结果,这对于新技术和人工智能的发展至关重要。