微服务架构实战第五节 服务容错、熔断、降级_微服务阻断回退-程序员宅基地
技术标签: 微服务 sentinel 架构 java spring cloud hytrix 教程
12 服务容错:如何理解服务消费者容错思想和模式?
在介绍完 API 网关之后,我们继续讨论微服务架构中的一个核心话题,即服务容错。相较传统单体系统中的函数级调用,跨进程的远程调用要复杂很多,也更容易出错。今天的内容关注服务容错的设计理念和与其相关的架构模式。
为什么要实现服务容错?
我们知道,在微服务架构中,服务之间通过跨进程的远程调用来完成交互。假设系统中存在两个微服务,分别是服务 A 和服务 B,其中服务 B 会调用服务 A,如下图所示:
服务 B 调用服务 A 示意图
现在,系统出现故障了。首先,服务 A 因为某种原因发生了宕机而变得不可用,这是故障的第一阶段。如下图所示:
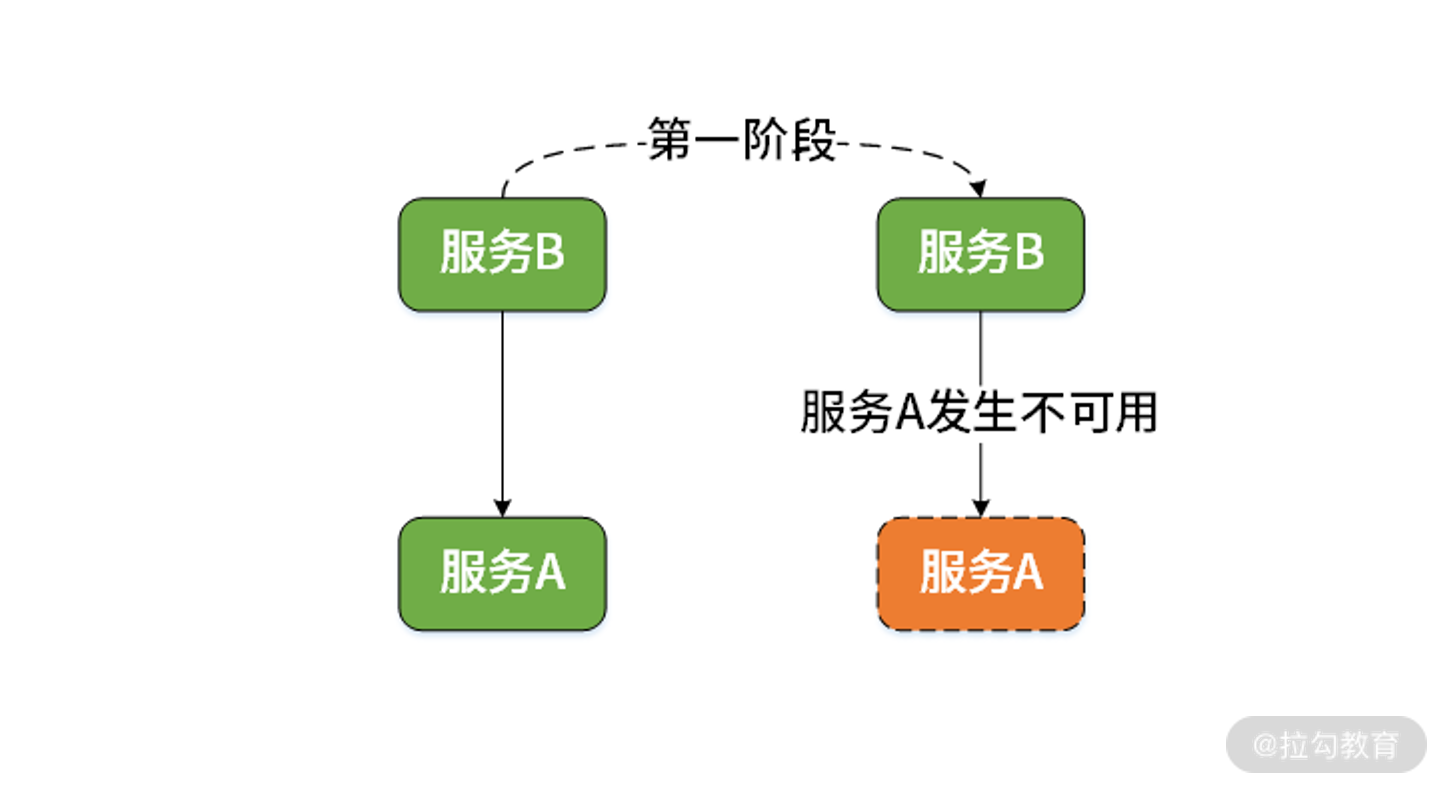
服务 A 变得不可用示意图
服务 A 不可用的原因有很多,包括服务器硬件等环境问题,也包括服务自身存在 Bug 等因素。而当访问服务 A 得不到正常的响应时,服务 B 的常见处理方式是通过重试机制来进一步加大对服务 A 的访问流量。这样,服务 B 每进行一次重试就会启动一批线程。我们知道线程的不断创建是需要消耗系统资源的,一旦系统资源被耗尽,服务 B 本身也将变得不可用,这就是事故的第二个阶段:
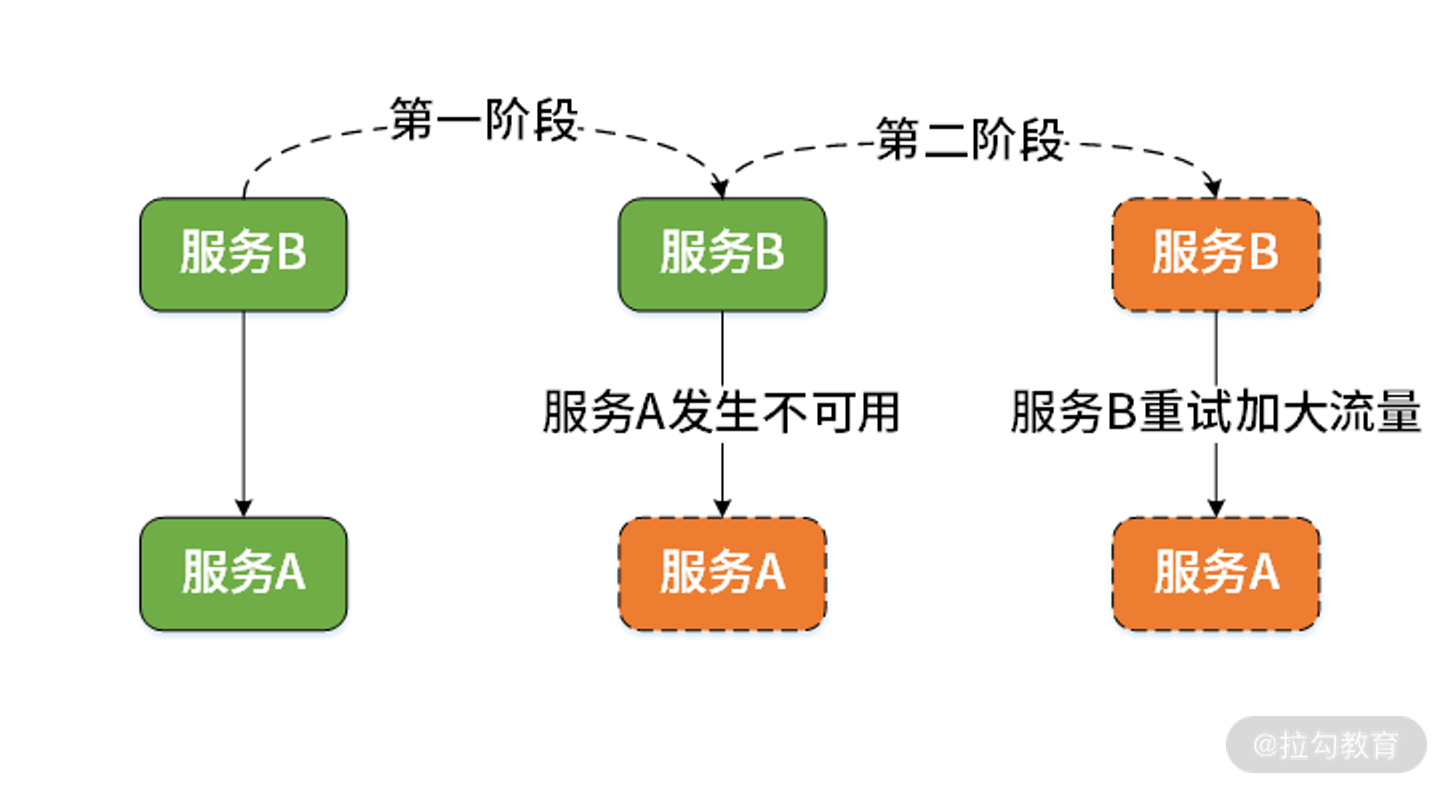
服务 B 变得不可用示意图
我们进一步假设,微服务系统中还存在依赖于服务 B 的服务 C。这样,基于同样的原因,服务 B 的不可用同样会导致服务 C 的不可用。类似的,系统中可能还存在服务 D 等其他服务依赖服务 C......以此类推,最终在以服务 A 为起点的整个调用链路上的所有服务都会变得不可用。这种扩散效应就是所谓的服务雪崩效应。
服务雪崩效应本质上是一种服务依赖失败。服务依赖失败较之服务自身失败而言,影响更大,也更加难以发现和处理。因此,服务依赖失败是我们在设计微服务架构中所需要重点考虑的服务可靠性因素。
显然,应对雪崩效应的切入点不在于服务提供者,而在于服务消费者。我们不能保证所有服务提供者都不会失败,但是我们要想办法确保服务消费者不受已失败的服务提供者的影响,或者说需要将服务消费者所受到的这种影响降到最低,这就是服务消费者容错的需求。而为了应对这个需求,业界也存在一些成熟的模式可以进行应用。
服务容错的模式
消费者容错的常见实现模式包括集群容错、服务隔离、服务熔断和服务回退,如下图所示:
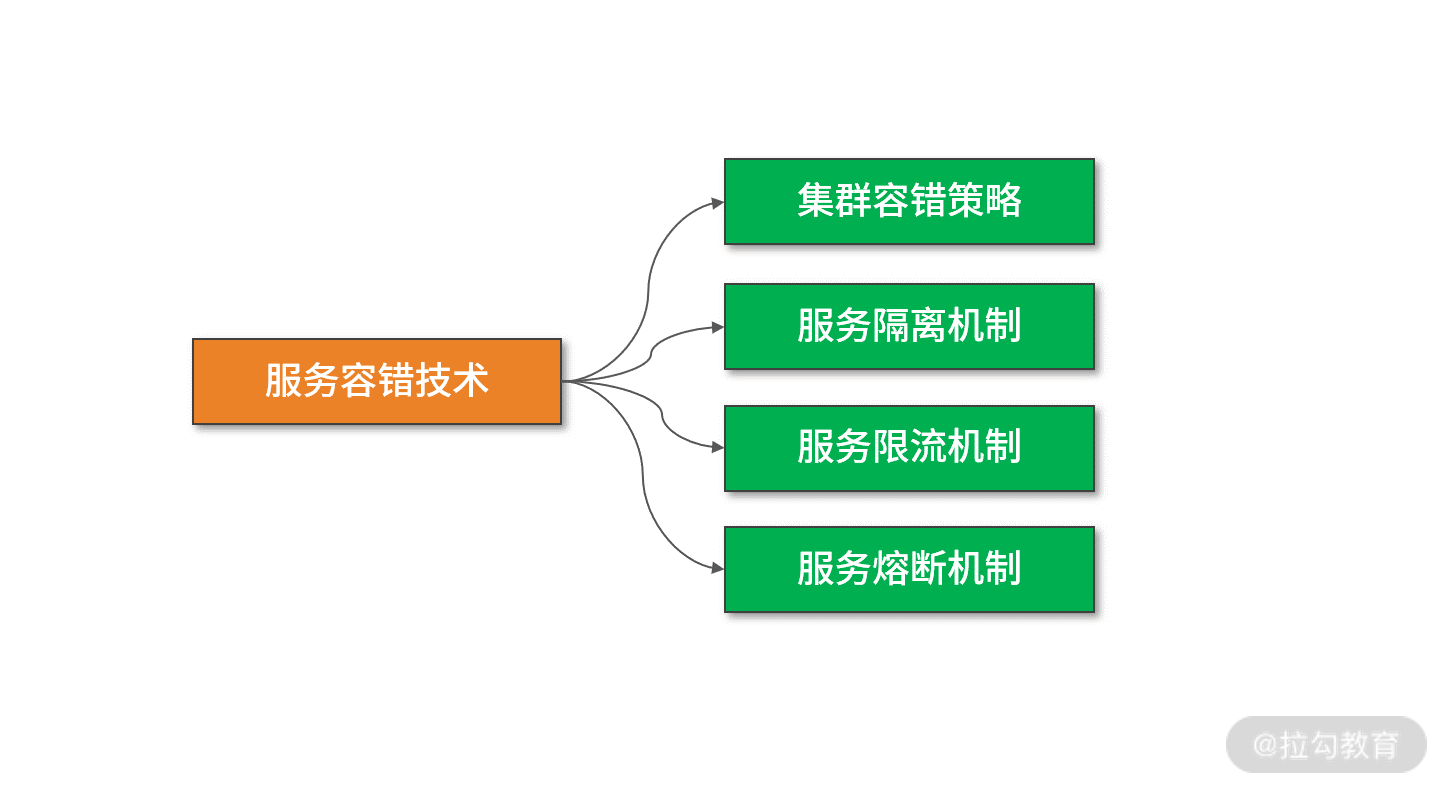
服务容错常见技术
接下来,我们对上图中的四种服务容错模式进行一一展开。
集群容错
在介绍服务治理部分内容时,我们提到了集群和客户端负载均衡。从消费者容错的角度讲,负载均衡不失为一种好的容错策略。从设计思想上讲,容错机制的基本要素就是要做到冗余,即某一个服务应该构建多个实例,这样当一个服务实例出现问题时可以重试其他实例。一个集群中的服务本身就是冗余的。而针对不同的重试方式就诞生了一批集群容错策略,常见的包括 Failover(失效转移)、Failback(失败通知)、Failsafe(失败安全)和 Failfast(快速失败)等。
这里以最常见、最实用的集群容错策略 Failover 为例展开讨论。Failover 即失效转移,当发生服务调用异常时,请求会重新在集群中查找下一个可用的服务提供者实例。如下图所示:
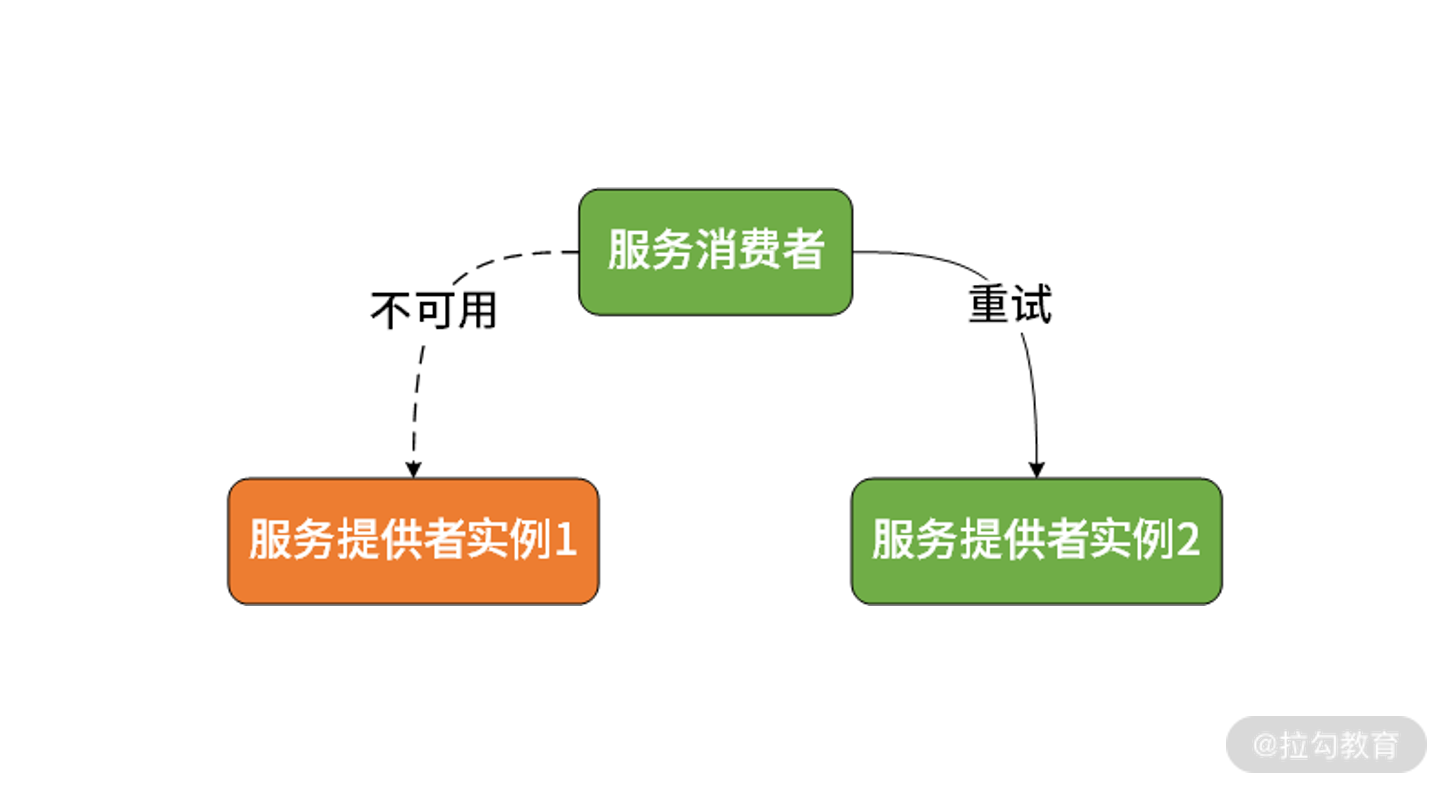
Failover 集群容错策略示意图
为了防止无限重试,如果采用 Failover 机制,通常会对失败重试最大次数进行限制。
服务隔离
所谓隔离,就是指对资源进行有效的管理,从而避免因为资源不可用、发生失败等情况导致系统中的其他资源也变得不可用。在设计思想上,我们希望在系统发生故障时能够对该故障的传播和影响范围做出有效的控制。服务隔离包括一些常见的隔离思路,以及特定的隔离实现技术框架。在日常开发过程中,我们主要的处理对象还是线程级别的隔离。
要实现线程隔离,简单而主流的做法是使用线程池(Thread Pool)。针对不同的业务场景,我们可以设计不同的线程池。因为不同的线程池之间线程是不共享的,所以某个线程池因为业务异常导致资源消耗时,不会将这种资源消耗扩散到其他线程池,从而保证其他服务持续可用。
服务隔离的概念比较抽象,接下来我们通过一个实例来进一步介绍它的工作场景。我们知道在 SpringHealth 案例中存在 user-service、device-service 和 intevention-service 这三个微服务。从资源的角度讲,假设这 3 个服务一共能够使用的线程数是 300 个,其他服务调用这三个服务时会共享这 300 个线程,如下图所示:
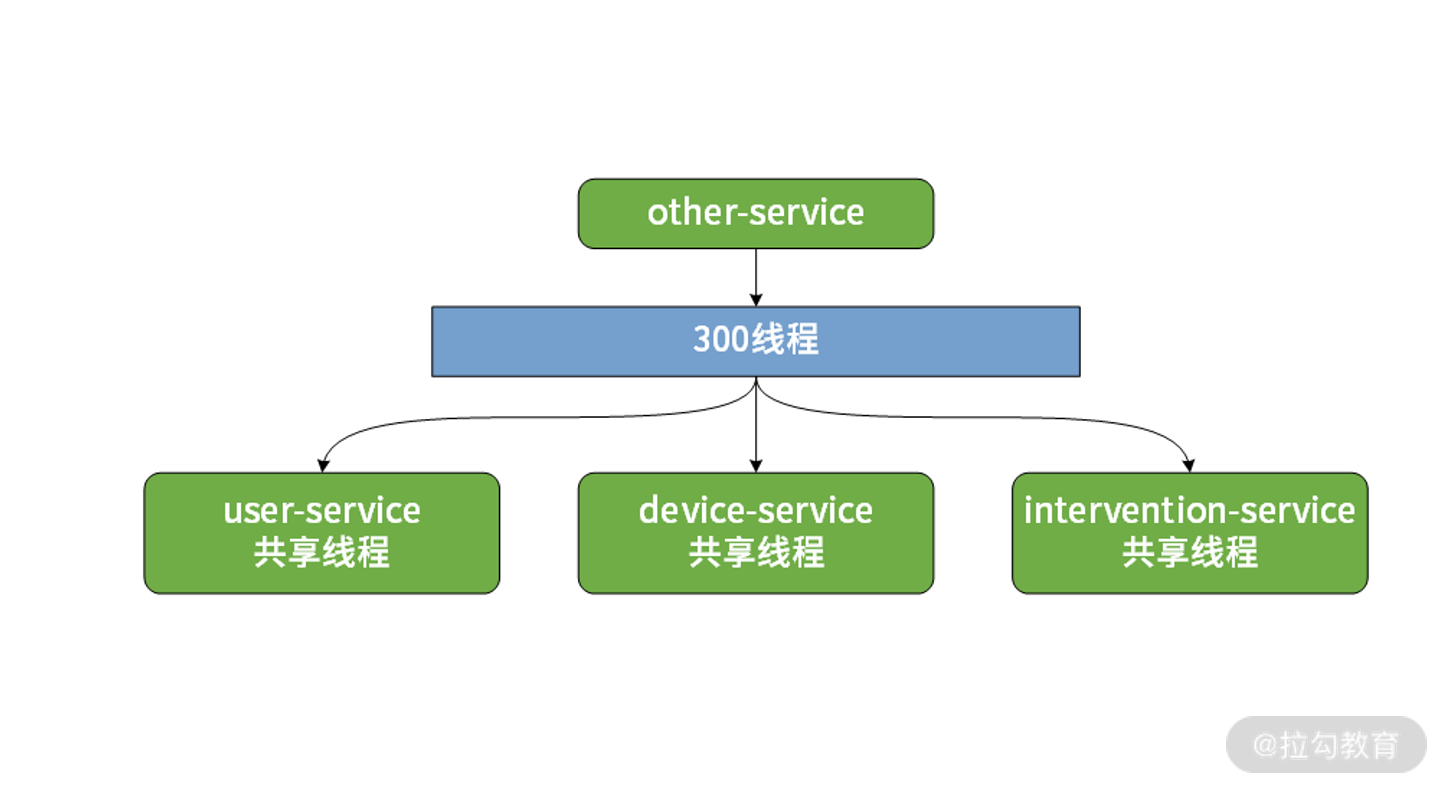
三个微服务共享线程池的场景示意图
在上图中,如果其中的 user-service 不可用, 就会出现线程池里所有线程被这个服务消耗殆尽 从而造成服务雪崩,如下图所示:
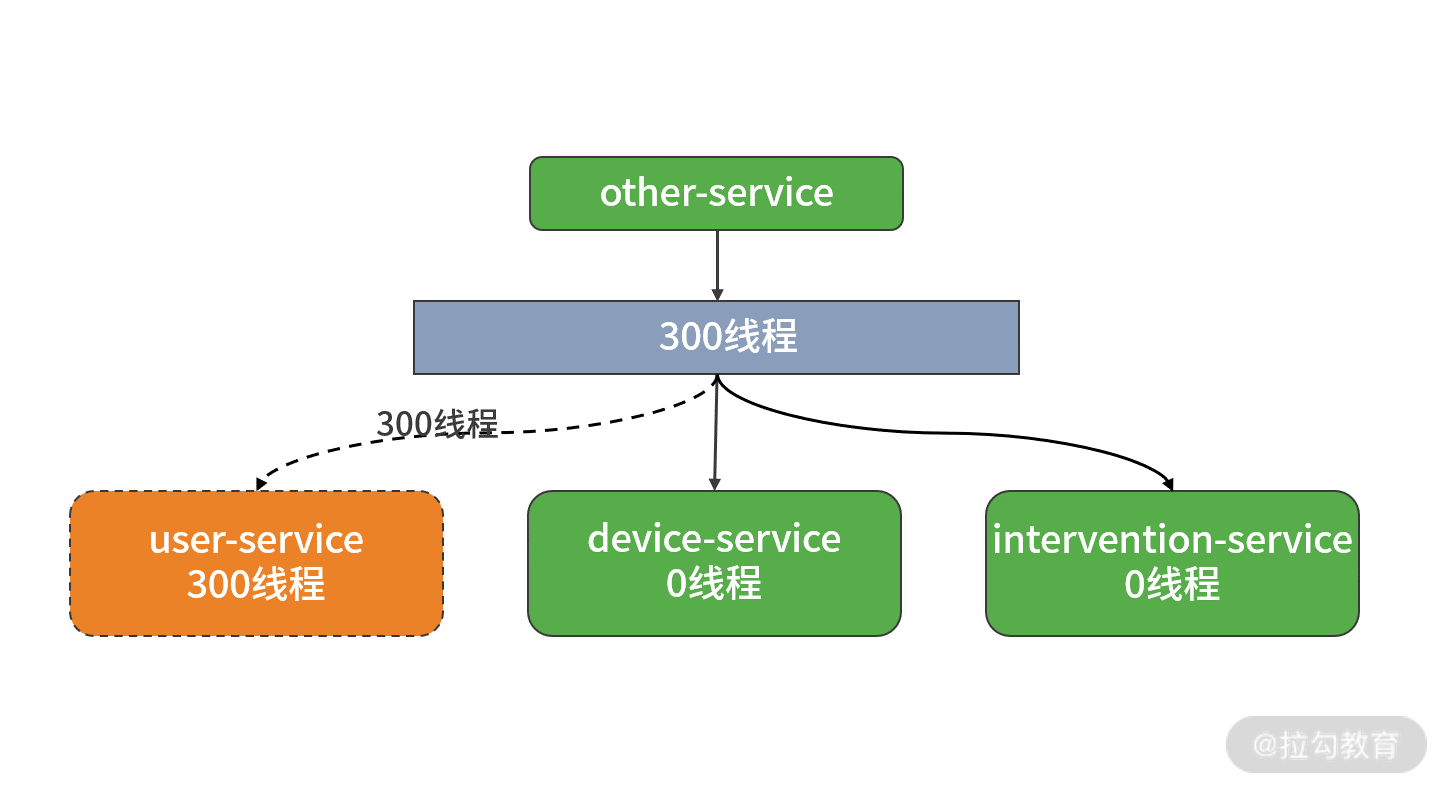
没有使用线程池隔离造成的服务雪崩场景示意图
现在,系统中的 300 个线程都被 user-service 所占用,device-service 和 intevention-service 已经分不到任何线程来响应请求。
线程隔离机制的实现方法也很简单,就是为每个服务分配独立的线程池以实现资源隔离,例如我们可以为 3 个服务平均分配 100 个线程,见下图:
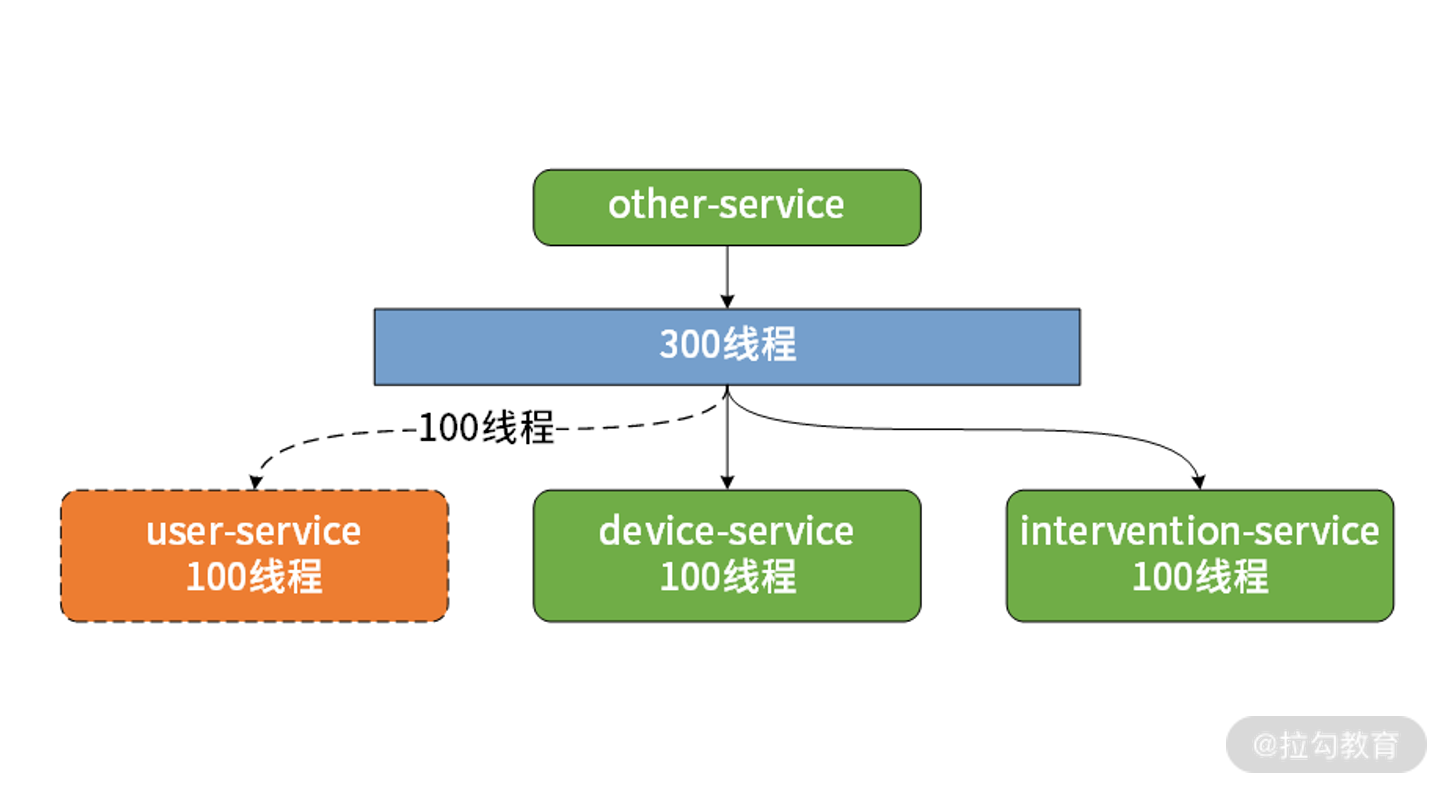
使用线程池隔离的场景示意图
在上图中, 当 user-service 不可用时, 最差的情况也就是消耗分配给它的 100 个线程,而其他的线程都还是属于各个微服务中,不会受它的影响。
从服务隔离的角度讲,线程隔离是一种比较细粒度的处理机制。而 Spring Cloud Circuit Breaker 同样对服务隔离提供了不同维度和粒度的支持。
服务熔断
讲完服务隔离,接下来我们来看服务熔断。服务熔断的概念来源于日常生活中的电路系统,在电路系统中存在一种熔断器(Circuit Breaker),它的作用就是在电流过大时自动切断电路。在微服务架构中,也存在类似的“熔断器”:当系统中出现某一个异常情况时,能够直接熔断整个服务的请求处理过程。这样可以避免一直等到请求处理完毕或超时,从而避免浪费。
从设计理念上讲,服务熔断也是快速失败的一种具体表现。当服务消费者向服务提供者发起远程调用时,服务熔断器会监控该次调用,如果调用的响应时间过长,服务熔断器就会中断本次调用并直接返回。请注意服务熔断器判断本次调用是否应该快速失败是有状态的,也就是说服务熔断器会把所有的调用结果都记录下来,如果发生异常的调用次数达到一定的阈值,那么服务熔断机制才会被触发,快速失败就会生效;反之,将按照正常的流程执行远程调用。
我们对以上过程进行抽象和提炼,可以得到服务熔断器的基本结构,如下图所示:
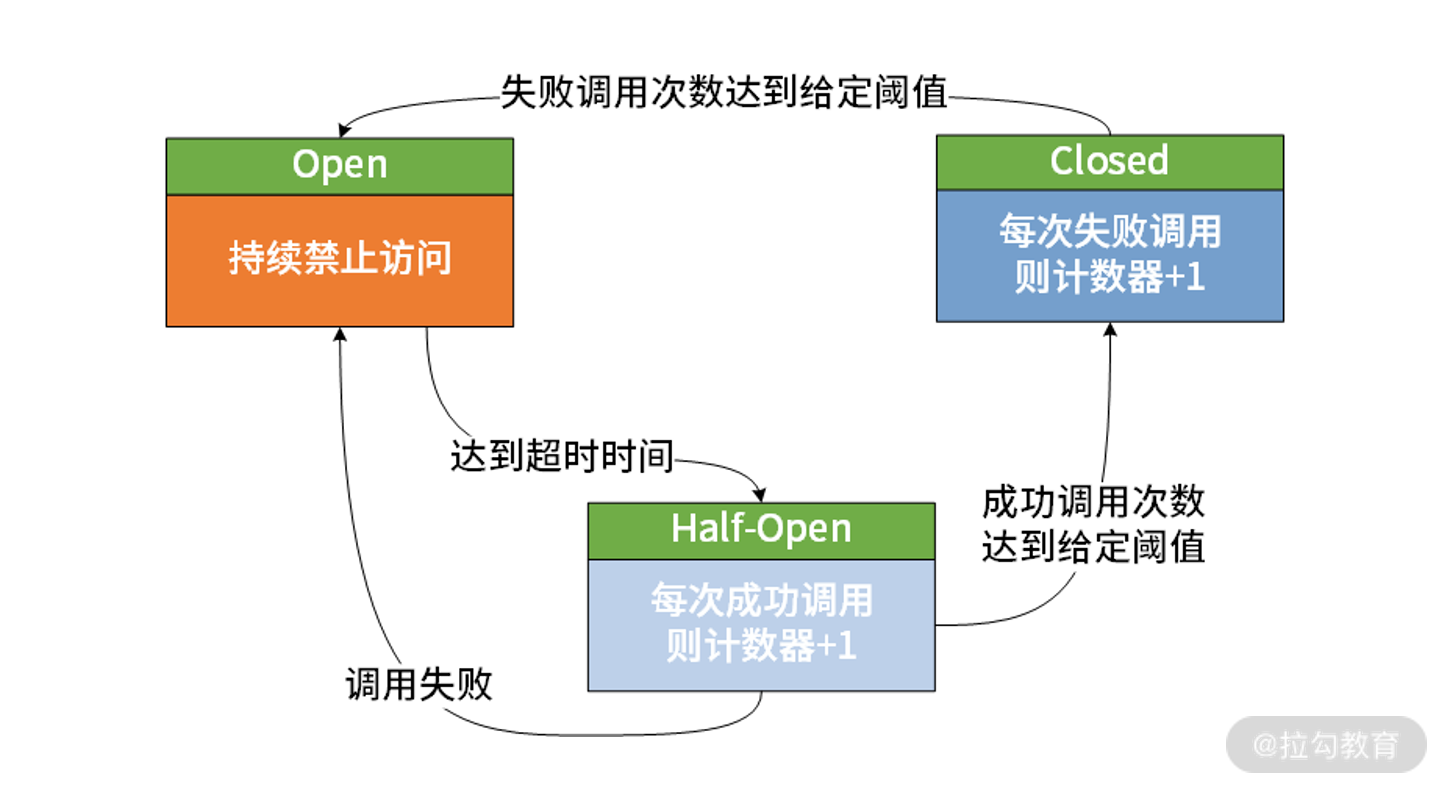
服务熔断器结构示意图
可以看到,这个结构给出了熔断器在实现上需要考虑的三个状态机。在上图中,我们使用不同的颜色标明了执行熔断的程度:
-
Closed: 对于熔断器而言,Closed 状态代表熔断器不进行任何的熔断处理。尽管这个时候人们感觉不到熔断器的存在,但它在背后会对调用失败次数进行积累,到达一定阈值或比例时则自动启动熔断机制。
-
Open: 一旦对服务的调用失败次数达到一定阈值时,熔断器就会打开,这时候对服务的调用将直接返回一个预定的错误,而不执行真正的网络调用。同时,熔断器内置了一个时间间隔,当处理请求达到这个时间间隔时会进入半熔断状态。
-
Half-Open: 在半开状态下,熔断器会对通过它的部分请求进行处理,如果对这些请求的成功处理数量达到一定比例则认为服务已恢复正常,就会关闭熔断器,反之就会打开熔断器。
Spring Cloud Circuit Breaker 中同样实现了服务熔断器组件,具备与上图类似的结构和功能。
服务回退
服务回退(Fallback)的概念类似一种被动的、临时的处理机制。当远程调用发生异常时,服务回退并不是直接抛出异常,而是产生一个另外的处理机制来应对该异常。这相当于执行了另一条路径上的代码或返回一个默认处理结果。而这条路径上的代码或这个默认处理结果并一定满足业务逻辑的实现需求,只是告知服务的消费者当前调用中所存在的问题。显然,服务回退不能解决由异常引起的实际问题,而是一种权宜之计。这种权宜之计在处理因为服务依赖而导致的异常时也是一种有效的容错机制。
在现实环境中,服务回退的实现方式可以很简单,原则上只需要保证异常被捕获并返回一个处理结果即可。但在有些场景下,回退的策略则可以非常复杂,我们可能会从其他服务或数据中获取相应的处理结果,需要具体问题具体分析。
Spring Cloud Circuit Breaker 支持服务回退,开发人员只需要提供一个自定义回退方法(Fallback Method),就可以非常简单地使用这一机制来支持服务回退。
Spring Cloud 中的服务容错解决方案
在前面的内容中,我们已经知道 Spring Cloud 中专门用于提供服务容错功能的 Spring Cloud Circuit Breaker 框架。从命名上看,Spring Cloud Circuit Breaker 是对熔断器的一种抽象,支持不同的熔断器实现方案。在 Spring Cloud Circuit Breaker 中,内置了四种熔断器,如下所示:
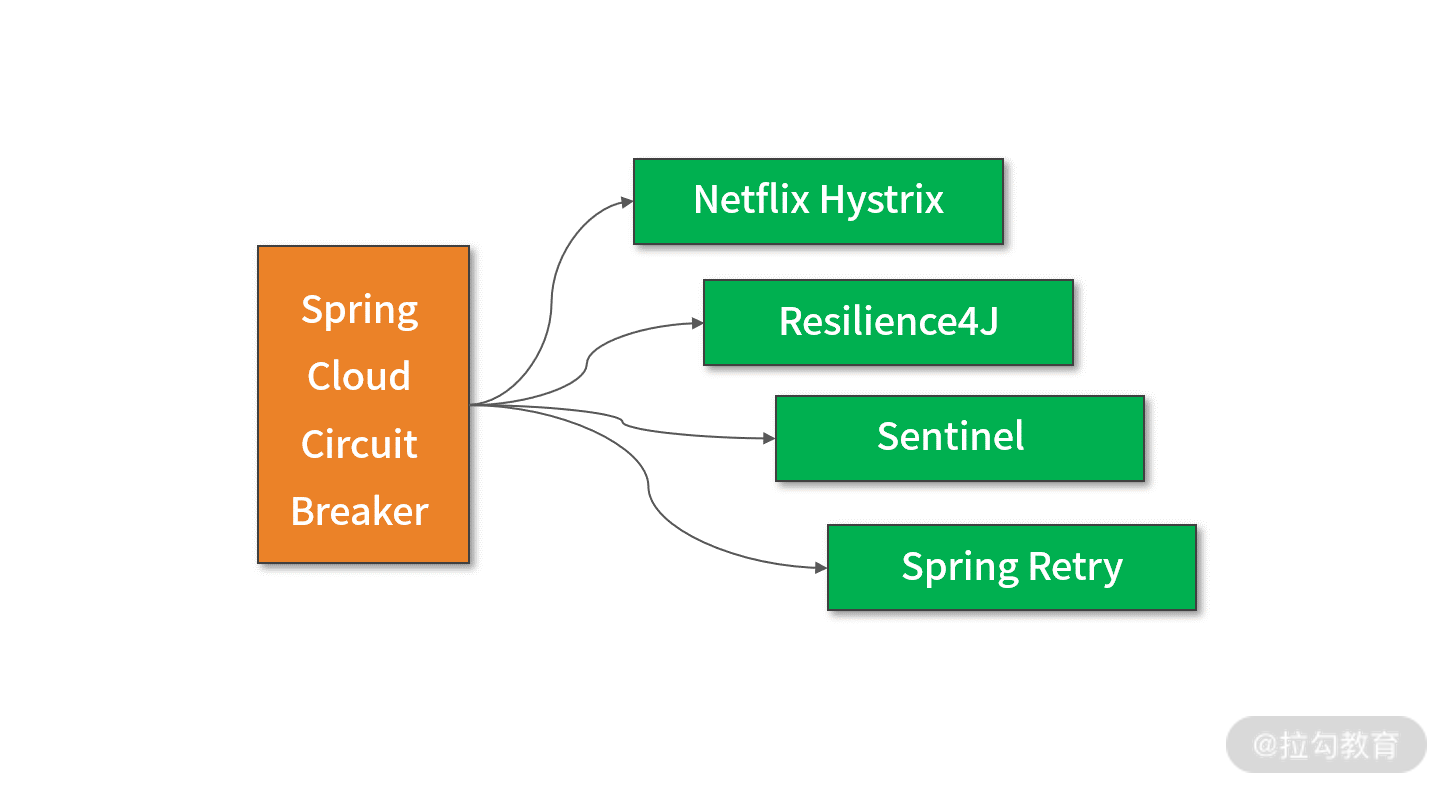
Spring Cloud Circuit Breaker 中的四种熔断器实现机制
针对以上四种熔断器,Spring Cloud Circuit Breaker 提供了统一的 API。其中 Netflix Hystrix 显然来自 Netflix OSS;Resilience4j 是受 Hystrix 项目启发所诞生的一款新型的容错库;Sentinel 从定位上讲是一款包含了熔断降级功能的高可用流量防护组件;而最后的 Spring Retry 是 Spring 自研的重试和熔断框架。
小结与预告
服务容错是微服务架构中值得深入探讨的一个核心话题,本节的内容关注服务容错的一些理论知识,包括服务容错的设计思想,以及相关的实现模式。今天,我们详细探讨了四种服务容错的实现模式,并结合 Spring Cloud 中的 Spring Cloud Circuit Breaker 框架给出了对应的解决方案。
这里给你留一道思考题:在 Spring Cloud Circuit Breaker 中,分别提供了哪些可以用于实现服务容错的实现技术?
在引入了 Spring Cloud Circuit Breaker 框架之后,下一课时我们先来关注第一种服务容错实现框架,即 Netflix 中的 Hystrix。
13 熔断之器:如何使用 Spring Cloud Circuit Breaker 实现服务容错?(上)
在上一课时中,我们全面梳理了在微服务架构中实现服务容错的设计思想和实现方案,也引出了 Spring Cloud 中专门用于实现服务容错的 Spring Cloud Circuit Breaker 框架。我们知道 Spring Cloud Circuit Breaker 是一个集成性的框架,内部整合了 Netflix Hystrix、Resilience4j、Sentinel 和 Spring Retry 这四款独立的熔断器组件。由于课时有限,我们无意对这四款组件都进行详细的展开,而是更多关注于 Netflix 旗下的 Hystrix,以及受 Hystrix 启发而诞生的 Resilience4j。在今天的课时中,我们先来讨论 Netflix Hystrix。
引入 Hystrix
要想在微服务中添加对 Netflix Hystrix 的支持,我们首先需要在 Maven 中添加对 spring-cloud-starter-netflix-hystrix 的依赖。过程如下所示:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
</dependency>
另一方面,通过上一课时的介绍,我们也明确了在微服务架构中,服务调用之间势必需要引入熔断器机制,确保服务容错。所以,Spring Cloud 推出了一个全新的注解,@SpringCloudApplication 注解。该注解用来集成服务治理和服务熔断方面的核心功能。@SpringCloudApplication 注解定义如下所示。
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
@SpringBootApplication
@EnableDiscoveryClient
@EnableCircuitBreaker
public @interface SpringCloudApplication {
}
可以看到 @SpringCloudApplication 是一个组合注解,整合了 @SpringBootApplication、@EnableDiscoveryClient 和 @EnableCircuitBreaker 这三个微服务所需的核心注解。我们可以直接使用该注解来简化代码。因此,从今天开始,在所有的业务服务中,我们都将使用这个新的 @SpringCloudApplication 注解。以 intervention-service 为例,现在的 Bootstrap 类的定义如下所示:
@SpringCloudApplication
public class InterventionApplication
在 Hystrix 中,最核心的莫过于HystrixCommand 类。HystrixCommand 是一个抽象类,只包含了一个抽象方法,即如下所示的 run 方法:
protected abstract R run() throws Exception;
显然,这个方法是让开发人员实现服务容错所需要处理的业务逻辑。在微服务架构中,我们通常在这个 run 方法中添加对远程服务的访问代码。
同时我们在 HystrixCommand 类中还发现了另一个很有用的方法 getFallback。这个方法用于在 HystrixCommand 子类中设置服务回退函数的具体实现,如下所示:
protected R getFallback() {
throw new UnsupportedOperationException("No fallback available.");
}
Hystrix 是一个非常经典而完善的服务容错开发框架,同时支持了上一课时中所提到的服务隔离、服务熔断和服务回退机制。下面的内容,就让我们逐一了解一下这些功能吧。
使用 Hystrix 实现服务隔离
基于前面对 HystrixCommand 抽象类的理解,我们就可以提供一个该类的子类来实现服务隔离。针对服务隔离,Hystrix 组件在提供了线程池隔离机制的同时,还实现了信号量隔离。这里,我们基于最常用的线程池隔离来进行介绍。典型的 HystrixCommand 子类代码风格如下所示:
public class GetUserCommand extends HystrixCommand<UserMapper> {
//远程调用 user-service 的客户端工具类
private UserServiceClient userServiceClient;
protected GetUserCommand(String name) {
super(Setter.withGroupKey(
//设置命令组
HystrixCommandGroupKey.Factory.asKey(“springHealthGroup”))
//设置命令键
.andCommandKey(HystrixCommandKey.Factory.asKey(“interventionKey”))
//设置线程池键
.andThreadPoolKey(HystrixThreadPoolKey.Factory.asKey(name))
//设置命令属性
.andCommandPropertiesDefaults(
HystrixCommandProperties.Setter()
.withExecutionTimeoutInMilliseconds(5000))
//设置线程池属性
.andThreadPoolPropertiesDefaults(
HystrixThreadPoolProperties.Setter()
.withMaxQueueSize(10)
.withCoreSize(2))
);
}
protected UserMapper run() throws Exception {
return userServiceClient.getUserByUserName(“springhealth_user1”);
}
protected UserMapper getFallback() {
return new UserMapper(1L,“user1”,“springhealth_user1”);
}
}
上述代码中使用了 Hystrix 中的很多常见的配置项,这些配置项大多数也涉及线程池隔离的相关概念。在 Hystrix 中,从控制粒度上讲,开发人员可以从服务分组和服务本身这两个维度出发,对线程隔离机制进行配置。也就是说我们既可以把一批服务都划分到一个线程池中,也可以把单个服务划分到一个线程池中。上述代码中的 HystrixCommandGroupKey 和 HystrixCommandKey 分别用来配置服务分组名称和服务名称,然后 HystrixThreadPoolKey 用来配置线程池的名称。
当我们根据需要设置了分组、服务以及线程池名称后,接下来就需要指定与线程池相关的各个属性。这些属性都包含在 HystrixThreadPoolProperties 中。例如,在上述代码中,我们使用 maxQueueSize 配置线程池队列的最大值,使用 coreSize 配置核心线程池的最大值等。同时,我们也注意到可以使用 withExecutionTimeoutInMilliseconds 配置项来指定请求的超时时间。
虽然,上述代码有助于我们更好的理解 Hystrix 中线程池隔离实现机制,但在日常开发过程中,一般不建议你通过创建一个 HystrixCommand 子类的方式来实现服务隔离,而是推荐你使用更为简单的 @HystrixCommand 注解。@HystrixCommand 是 Hystrix 为简化开发过程而专门提供的一个注解,定义如下:
public @interface HystrixCommand {
String groupKey() default “”;
String commandKey() default “”;
String threadPoolKey() default “”;
String fallbackMethod() default “”;
HystrixProperty[] commandProperties() default {};
HystrixProperty[] threadPoolProperties() default {};
Class<? extends Throwable>[] ignoreExceptions() default {};
ObservableExecutionMode observableExecutionMode() default ObservableExecutionMode.EAGER;
HystrixException[] raiseHystrixExceptions() default {};
String defaultFallback() default “”;
}
在上述定义中,我们看到了用于设置分组、服务与线程池名称相关的 groupKey、commandKey 和 threadPoolKey方法,以及与线程池属性相关的 threadPoolProperties 对象。让我们回到案例,并使用 @HystrixCommand 注解进行重构,效果如下:
@HystrixCommand
private UserMapper getUser(String userName) {
return userClient.getUserByUserName(userName);
}
可以看到这里只使用了 @HystrixCommand 这个注解就完成 HystrixCommand 的创建。当然,我们也可以进一步使用 @HystrixProperty 注解来设置所需的各项属性,如下所示:
@HystrixCommand(threadPoolKey = "springHealthGroup",
threadPoolProperties =
{
@HystrixProperty(name="coreSize",value="2"),
@HystrixProperty(name="maxQueueSize",value="10")
}
)
private UserMapper getUser(String userName) {
return userClient.getUserByUserName(userName);
}
同样可以看到,我们为该 HystrixCommand 设置了 threadPoolKey,也提供了 threadPoolProperties 来设置 coreSize 和 maxQueueSize。
使用 Hystrix 实现服务熔断
在上一课时中,我们知道熔断器有三个状态,其中打开和半打开状态会导致触发熔断机制。针对服务熔断,我们同样来考虑案例系统中一个服务依赖调用的具体场景,这个场景是对前面介绍的服务隔离的衍生。在 SpringHealth 案例中,我们知道 intervention-service 需要调用 user-service 和 device-service 来生成健康干预记录,该操作的代码流程如下所示:
public Intervention generateIntervention(String userName, String deviceCode) {
logger.debug("Generate intervention record with user: {} from device: {}", userName, deviceCode);
Intervention intervention = new Intervention();
//获取远程 User 信息
UserMapper user = getUser(userName);
if (user == null) {
return intervention;
}
logger.debug(“Get remote user: {} is successful”, userName);
//获取远程 Device 信息
DeviceMapper device = getDevice(deviceCode);
if (device == null) {
return intervention;
}
logger.debug(“Get remote device: {} is successful”, deviceCode);
//创建并保存 Intervention 信息
intervention.setUserId(user.getId());
intervention.setDeviceId(device.getId());
intervention.setHealthData(device.getHealthData());
intervention.setIntervention(“InterventionForDemo”);
intervention.setCreateTime(new Date());
interventionRepository.save(intervention);
return intervention;
}
显然,上述代码中 getUser() 方法和 getDevice() 方法都会涉及微服务之间的相互依赖和调用,示例代码如下所示:
@Autowired
private UserServiceClient userClient;
@Autowired
private DeviceServiceClient deviceClient;
@HystrixCommand
private UserMapper getUser(String userName) {
return userClient.getUserByUserName(userName);
}
@HystrixCommand
private DeviceMapper getDevice(String deviceCode) {
return deviceClient.getDevice(deviceCode);
}
这里通过注入 UserServiceClient 和 DeviceServiceClient 两个工具类来实现远程调用,这两个工具类都使用了 Ribbon 和 RestTemplate 来实现调用过程的客户端负载均衡,关于客户端负载均衡相关内容我们在《负载均衡:如何使用 Ribbon 实现客户端负载均衡?》中已经进行了介绍。
在微服务环境下,使用 UserServiceClient 和 DeviceServiceClient 的调用过程可能会出现响应超时等问题,这个时候 intervention-service 作为服务消费者需要做到服务容错。要嵌入 Hystrix 提供的熔断机制,我们只需要在这两个方法上添加 @HystrixCommand 注解即可。在前面的代码我已经做了相应的示例。
现在我们来模拟一下远程调用超时的场景,调整 getDevice() 方法的代码,通过 Thread.sleep(2000) 来模拟响应时间过长的场景,如下所示。
@HystrixCommand
private DeviceMapper getDevice(String deviceCode) {
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
return deviceClient.getDevice(deviceCode);
}
现在我们创建一个端点,如下所示:
@RestController
@RequestMapping(value="interventions")
public class InterventionController {
@Autowired
private InterventionService interventionService;
public Intervention generateIntervention( String userName,
String deviceCode) {
Intervention intervention = interventionService.generateIntervention(userName, deviceCode);
return intervention;
}
}
显然,这个端点是用来访问 InterventionService 并生成 Intervention 记录的。现在,让我们访问这个端点:
http://localhost:8083/interventionss/springhealth_user1/device_blood
首先,我们在 intervention-service 的控制台中会看到“java.lang.InterruptedException: sleep interrupted”异常地抛出,而抛出该异常的来源正是 Hystrix。
然后,我们来查看端点调用的返回值,如下所示:
{
"timestamp":"1601881721343",
"status":500,
"error":"Internal Server Error",
"exception":"com.netflix.hystrix.exception.HystrixRuntimeException",
"message":"generate Intervention time-out and fallback failed.",
"path":"/interventions/springhealth_user1/device_blood"
}
在这里,我们发现 HTTP 响应状态为 500,而抛出的异常为 HystrixRuntimeException,从异常信息上可以看出引起该异常的原因是超时。事实上,默认情况下,添加了 @HystrixCommand 注解的方法调用超过了 1000 毫秒就会触发超时异常,显然上例中设置的 2000 毫秒满足触发条件。
和设置线程池属性一样,在 HystrixCommand 中我们也可以对熔断的超时时间、失败率等各项阈值进行设置。例如我们可以在 getDevice() 方法上添加如下配置项以改变 Hystrix 的默认行为:
@HystrixCommand(commandProperties = {
@HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds", value = "3000")
})
private DeviceMapper getDevice(String deviceCode)
上面示例中的 execution.isolation.thread.timeoutInMilliseconds 配置项就是用来设置 Hystrix 的超时时间,现在我们把它设置成 3000 毫秒。这时,我们再次访问 http://localhost:8083/interventions/springhealth_user1/device_blood端点,就会发现请求会正常返回。当然,Hystrix 还提供了一系列的配置项来细化对熔断器的控制。常见的配置项如下所示:
@HystrixCommand(commandProperties = {
@HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds", value = "12000"),
//一个滑动窗口内最小的请求数
@HystrixProperty(name = "circuitBreaker.requestVolumeThreshold", value = "10"),
//错误比率阈值
@HystrixProperty(name = "circuitBreaker.errorThresholdPercentage", value = "75"),
//触发熔断的时间值
@HystrixProperty(name = "circuitBreaker.sleepWindowInMilliseconds", value = "7000"),
//一个滑动窗口的时间长度
@HystrixProperty(name = "metrics.rollingStats.timeInMilliseconds", value = "15000"),
//一个滑动窗口被划分的数量
@HystrixProperty(name = "metrics.rollingStats.numBuckets", value = "5") })
我们在后续介绍 Hystrix 熔断器实现原理和滑动窗口机制时会对这些配置项的作用做进一步展开。
使用 Hystrix 实现服务回退
Hystrix 在服务调用失败时都可以执行服务回退逻辑。在开发过程上,我们只需要提供一个 Fallback 方法实现并进行配置即可。例如,在 SpringHealth 案例系统中,对于 intervention-service 中访问 user-service 和 device-service 这两个远程调用场景,我们都可以实现 Fallback 方法。回退方法的实现也非常方便,唯一需要注意的就是 Fallback 方法的参数和返回值必须与真实的方法完全一致。如下所示的就是 Fallback 方法的一个示例:
private UserMapper getUserFallback(String userName) {
UserMapper fallbackUser = new UserMapper(0L,"no_user","not_existed_user");
return fallbackUser;
}
我们通过构建一个不存在的 User 信息来返回 Fallback 结果。有了这个 Fallback 方法,剩下来要做的就是在 @HystrixCommand 注解中设置“fallbackMethod”配置项。重构后的 getUser 方法如下所示:
@HystrixCommand(threadPoolKey = "springHealthGroup",
threadPoolProperties =
{
@HystrixProperty(name="coreSize",value="2"),
@HystrixProperty(name="maxQueueSize",value="10")
},
fallbackMethod = "getUserFallback"
)
private UserMapper getUser(String userName) {
return userClient.getUserByUserName(userName);
}
现在你可以模拟远程方法调用的各种异常情况,并观察这个 Fallback 是否已经生效了。
小结与预告
本课时对 Hystrix 这款服务容错实现框架进行了详细了讨论,并结合 SpringHealth 案例系统给出了使用该框架的示例代码。Hystrix 是服务容错领域的代表性框架,包含了服务隔离、服务容错和服务回退功能,值得你进行深入的理解并掌握运用。为了帮助你更好的学习 Hystrix 框架,我们在后续课时中还会专门从源码级别分析他的实现原理。
这里给你留一道思考题:你能说出 Hystrix 中有哪些常见的配置项吗?
讲完 Hystrix,我们将进一步讲解 Spring Cloud Circuit Breaker 框架。我们知道 Spring Cloud Circuit Breaker 中集成了多种服务容错框架,其中包括 Hystrix 却也不仅包括 Hystrix。下一课时,我们将首先探讨 Spring Cloud Circuit Breaker 中对服务容错的抽象机制,并完成对 Hystrix 使用方式的重构,以及介绍另一款主流的服务熔断工具 Resilience4j。
14 熔断之器:如何使用 Spring Cloud Circuit Breaker 实现服务容错?(下)
在上一课时中,我们系统介绍了 Hystrix 所提供了服务隔离、服务容错和服务回退功能。我们发现这个框架确实非常强大,能够灵活处理服务容错的各种场景。事实上,业界也存在一批类似 Hystrix 的框架。Spring Cloud 基于这些框架的共性,专门抽象并开发了一个 Spring Cloud Circuit Breaker 框架。在今天的课程中,我们将引入 Spring Cloud Circuit Breaker 框架,并给出使用这个框架来满足各种服务容错需求的实现方法。
理解 Spring Cloud Circuit Breaker 中的熔断器抽象
从命名上看,Spring Cloud Circuit Breaker 是对熔断器抽象,内部集成了多款不同的熔断器实现工具,并基于这些工具提取了统一的 API 供应用程序进行调用。
为了在应用程序中创建一个熔断器,我们可以使用 Spring Cloud Circuit Breaker 中的工厂类 CircuitBreakerFactory,该工厂类的定义如下所示:
public abstract class CircuitBreakerFactory<CONF, CONFB extends ConfigBuilder<CONF>> extends AbstractCircuitBreakerFactory<CONF, CONFB> {
public abstract CircuitBreaker create(String id);
}
可以看到这是一个抽象类,只有一个 create 方法用来创建一个 CircuitBreaker。CircuitBreaker 是一个接口,约定了熔断器应该具有的功能,该接口定义如下所示:
public interface CircuitBreaker {
default <T> T run(Supplier<T> toRun) {
return run(toRun, throwable -> {
throw new NoFallbackAvailableException("No fallback available.", throwable);
});
};
<T> T run(Supplier<T> toRun, Function<Throwable, T> fallback);
}
这里用到了函数式编程的一些语法,但我们从方法定义上还是可以明显看出包含了 run() 方法和 fallback() 方法。其中的 Supplier 包含了你希望运行在熔断器中的业务代码,而 Function 则代表着回退方法。对比上一课时中介绍的 HystrixCommand,我们发现两者之间存在明显的对应关系。
在 Spring Cloud Circuit Breaker 中,分别针对 Hystrix、Resilience4j、Sentinel 和 Spring Retry 这四款框架提供了 CircuitBreakerFactory 抽象类的子类。如果我们想要在应用程序中使用这些工具,首先需要引入相关的 Maven 依赖。以 Resilience4j 为例,对应的 Maven 依赖如下所示:
<dependency>
<groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-circuitbreaker-resilience4j</artifactId>
</dependency>
不过有一点需要注意,Hystrix 对应的 Maven 依赖名称并不是像其他三个框架一样是在“spring-cloud-starter-circuitbreaker-”之后添加具体的框架名称,而是使用如下所示的依赖关系:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
</dependency>
一旦在代码工程的类路径中添加了 starter,系统就会自动创建 CircuitBreaker。也就是说 CircuitBreakerFactory.create 方法会实例化对应框架的一个 CircuitBreaker 实例。
在引入具体的开发框架之后,下一步工作就是对它们进行配置。在 CircuitBreakerFactory 的父类 AbstractCircuitBreakerFactory 中,我们发现了如下两个抽象方法:
//针对某一个 id 创建配置构造器
protected abstract CONFB configBuilder(String id);
//为熔断器配置默认属性
public abstract void configureDefault(Function<String, CONF> defaultConfiguration);
这里用到了大量的泛型定义,我们可以猜想,在这两个抽象方法的背后,Spring Cloud Circuit Breaker 会针对不同的第三方框架提供了不同的配置实现过程。我们在后续内容中会基于具体的框架对这一过程做展开讨论,首当其冲的就是 Hystrix 框架。
使用 Spring Cloud Circuit Breaker 集成 Hystrix
让我们回到 Hystrix,来看看在 Spring Cloud Circuit Breaker 中是如何使用统一编程模式集成 Hystrix。
理解 HystrixCircuitBreakerFactory 和 HystrixCircuitBreaker
我们首先关注实现了 CircuitBreaker 接口的 HystrixCircuitBreaker 类,如下所示:
public class HystrixCircuitBreaker implements CircuitBreaker {
private HystrixCommand.Setter setter;
public HystrixCircuitBreaker(HystrixCommand.Setter setter) {
this.setter = setter;
}
@Override
public <T> T run(Supplier<T> toRun, Function<Throwable, T> fallback) {
HystrixCommand<T> command = new HystrixCommand<T>(setter) {
@Override
protected T run() throws Exception {
return toRun.get();
}
@Override
protected T getFallback() {
return fallback.apply(getExecutionException());
}
};
return command.execute();
}
}
不难想象,这里应该构建了一个 HystrixCommand 对象,并在该对象原有的 run 和 getFallback 方法中封装了 CircuitBreaker 中的统一方法调用,而最终实现熔断操作的还是 Hystrix 原生的 HystrixCommand。
然后,我们接着来看 HystrixCircuitBreakerFactory,这个类的实现过程也简洁明了,如下所示:
public class HystrixCircuitBreakerFactory extends
CircuitBreakerFactory<HystrixCommand.Setter, HystrixCircuitBreakerFactory.HystrixConfigBuilder> {
//实现默认配置
private Function<String, HystrixCommand.Setter> defaultConfiguration = id -> HystrixCommand.Setter
.withGroupKey(
HystrixCommandGroupKey.Factory.asKey(getClass().getSimpleName()))
.andCommandKey(HystrixCommandKey.Factory.asKey(id));
public void configureDefault(
Function<String, HystrixCommand.Setter> defaultConfiguration) {
this.defaultConfiguration = defaultConfiguration;
}
public HystrixConfigBuilder configBuilder(String id) {
return new HystrixConfigBuilder(id);
}
//创建熔断器
public HystrixCircuitBreaker create(String id) {
Assert.hasText(id, "A CircuitBreaker must have an id.");
HystrixCommand.Setter setter = getConfigurations().computeIfAbsent(id,
defaultConfiguration);
return new HystrixCircuitBreaker(setter);
}
//
public static class HystrixConfigBuilder
extends AbstractHystrixConfigBuilder<HystrixCommand.Setter> {
public HystrixConfigBuilder(String id) {
super(id);
}
@Override
public HystrixCommand.Setter build() {
return HystrixCommand.Setter.withGroupKey(getGroupKey())
.andCommandKey(getCommandKey())
.andCommandPropertiesDefaults(getCommandPropertiesSetter());
}
}
}
上述代码基本就是对原有 HystrixCommand 中关于服务分组等属性的简单封装,你可以结合上一课时的内容做一些回顾。
使用 HystrixCircuitBreakerFactory 设置默认属性
在应用程序中为熔断器创建默认配置,我们可以使用 Spring Cloud Circuit Breaker 提供的 Customizer工具类。通过传入一个 HystrixCircuitBreakerFactory 对象,然后调用它的 configureDefault 方法就可以构建一个 Customizer 实例。示例代码如下所示:
Bean
public Customizer<HystrixCircuitBreakerFactory> defaultConfig() {
return factory -> factory.configureDefault(id -> HystrixCommand.Setter
.withGroupKey(HystrixCommandGroupKey.Factory.asKey(id))
.andCommandPropertiesDefaults(HystrixCommandProperties.Setter().withExecutionTimeoutInMilliseconds(3000)));
}
这段代码比较容易理解,我们看到了熟悉的服务分组键 GroupKey,以及 Hystrix 命令属性 CommandProperties。这里同样通过 HystrixCommandProperties 的 withExecutionTimeoutInMilliseconds 方法将默认超时时间设置为 3000 毫秒。
以上方法一般推荐放置在 Spring Boot 的启动类中,这样相当于对 HystrixCircuitBreakerFactory 进行了初始化,接下来就可以使用它来完成服务熔断操作了。
使用 Hystrix 实现服务熔断
使用 HystrixCircuitBreakerFactory 实现服务熔断的开发流程比较固化。首先,我们需要通过 HystrixCircuitBreakerFactory 创建一个runCircuitBreaker 实例,然后实现具体的业务逻辑并提供一个回退函数,最后执行 CircuitBreaker 的 run 方法。示例代码如下:
//创建 CircuitBreaker
CircuitBreaker hystrixCircuitBreaker = circuitBreakerFactory.create("springhealth");
//封装业务逻辑
Supplier<UserMapper> supplier = () -> {
return userClient.getUserByUserName(userName);
};
//初始化回退函数
Function<Throwable, UserMapper> fallback = t -> {
UserMapper fallbackUser = new UserMapper(0L,“no_user”,“not_existed_user”);
return fallbackUser;
};
//执行业务逻辑
hystrixCircuitBreaker.run(supplier, fallback);
我们可以把上述示例代码进行调整并嵌入到各种业务场景中。
使用 Spring Cloud Circuit Breaker 集成 Resilience4j
介绍完 Hystrix,我们接下来再来看另一个非常主流的熔断器实现工具 Resilience4j。
Resilience4j 基础
Resilience4j 是一款轻量级的服务容错库,其设计灵感正是来自 Hystrix,我们先来看一下 Resilience4j 中定义的几个核心组件。
当使用 Resilience4j 时,同样需要对熔断器进行配置。而这样配置信息同样分为两部分,一部分是默认配置,一部分是专属于某一个服务的特定配置。典型的 Resilience4j 配置项如下所示:
resilience4j:
circuitbreaker:
configs:
default:
ringBufferSizeInClosedState: 5 # 熔断器关闭时的缓冲区大小
ringBufferSizeInHalfOpenState: 2 # 熔断器半开时的缓冲区大小
waitDurationInOpenState: 10000 # 熔断器从打开到半开需要的时间
failureRateThreshold: 60 # 熔断器打开的失败阈值
eventConsumerBufferSize: 10 # 事件缓冲区大小
recordExceptions: # 记录的异常
- com.example.resilience4j.exceptions.BusinessBException
- com.example.resilience4j.exceptions.BusinessAException
ignoreExceptions: # 忽略的异常
- com.example.resilience4j.exceptions.BusinessAException
instances:
userCircuitBreaker:
baseConfig: default
deviceCircuitBreaker:
baseConfig: default
waitDurationInOpenState: 5000
failureRateThreshold: 20
可以看到这里,我们先对全局熔断器设置好一系列的默认配置。针对不同的业务服务,我们可以配置多个熔断器实例,并对这些实例使用不同的配置或者直接覆盖默认配置。在上述配置项中,我们初始化了两个服务级的 Circuit Breaker 实例 userCircuitBreaker 和 deviceCircuitBreaker,分别作用于 user-service 和 device-service。其中,userCircuitBreaker 完全使用的是默认配置,而 deviceCircuitBreaker 对 waitDurationInOpenState 和 failureRateThreshold 这两个配置项做了覆盖。
在 Resilience4j 中,存在一个熔断器注册器 CircuitBreakerRegistry。上述配置项会帮我们把 userCircuitBreaker 和 deviceCircuitBreaker 自动注册到这个 CircuitBreakerRegistry 中。而在应用程序中,通过指定熔断器名称就可以从 CircuitBreakerRegistry 中获取熔断器,如下所示:
CircuitBreaker circuitBreaker = circuitBreakerRegistry.circuitBreaker("userCircuitBreaker");
一旦获取了 CircuitBreaker 对象,接下来就是通过该对象所提供的 executeSupplier 方法或 executeCheckedSupplier 方法来执行业务代码,如下所示:
circuitBreaker.executeCheckedSupplier(userClient::getUser);
如果需要对业务代码执行回退,在 Resilience4j 中的实现过程会相对复杂一点。我们需要使用包装器方法 decorateCheckedSupplier,然后再使用 Try.of().recover() 方法进行降级处理,代码示例如下所示:
CircuitBreaker circuitBreaker = circuitBreakerRegistry.circuitBreaker("userCircuitBreaker");
CheckedFunction0<UserMapper> checkedSupplier = CircuitBreaker.
decorateCheckedSupplier(circuitBreaker, userClient::getUser);
Try<UserMapper> result = Try.of(checkedSupplier).
.recover(throwable -> {
UserMapper fallbackUser = new UserMapper(0L,"no_user","not_existed_user");
return fallbackUser;
});
return result.get();
至此我们演示了基于 Java 代码的方式来使用 Resilience4j,但 Resilience4j 也提供了 @CircuitBreaker 注解。该注解类似 Hystrix 中的 @HystrixCommand 注解。使用方式上也比较类似,一般只需要指定熔断器的名称以及回退方法即可,如下所示:
@CircuitBreaker(name = "userCircuitBreaker", fallbackMethod = "getUserFallback")
使用 Resilience4j 实现服务熔断
现在,让我们回到 Spring Cloud Circuit Breaker,看看该框架如何对 Resilience4j 的使用过程进行封装和集成。
首先,我们同样需要构建一个 Customizer 实例,来初始化对 Resilience4j 的配置,如下所示:
@Bean
public Customizer<Resilience4JCircuitBreakerFactory> defaultCustomizer() {
return factory -> factory.configureDefault(id -> new Resilience4JConfigBuilder(id)
.circuitBreakerConfig(CircuitBreakerConfig.ofDefaults())
.build());
}
上述代码似曾相识,但这里的 Customizer 中包装的是 Resilience4JCircuitBreakerFactory 工厂类。同时,这里也构建了一个 Resilience4JConfigBuilder 用来完成与 Resilience4j 相关配置的构建工作。
而针对 Resilience4JCircuitBreakerFactory 的使用方法,我们会发现与 HystrixCircuitBreakerFactory 是完全一致的。我们也是先通过 Resilience4JCircuitBreakerFactory 创建 CircuitBreaker,然后封装业务逻辑并初始化回调函数,最后通过 CircuitBreaker 的 run 方法执行业务逻辑。相关代码不再重复展开,这种实现方式也是 Spring Cloud Circuit Breaker 作为一个平台化框架提供统一 API 的价值所在。
服务容错集成 API 网关
最后,我们还是有必要提在 API 网关中集成服务容错机制的实现方法。我们在前面几个课时中系统介绍了 Netflix Zuul 和 Spring Cloud Gateway 这两款 API 网关实现工具,它们都可以完成与 Hystrix 的无缝集成。
事实上,Hystrix 集成 API 网关唯一所要做的事情就是在网关的配置文件中添加与 Hystrix 相关的配置项即可。这里以常见的设置服务访问超时时间的场景为例,给出 Hystrix 配置项,如下所示:
hystrix:
command:
default:
execution:
isolation:
thread:
timeoutInMilliseconds: 5000
显然,上述配置信息的效果就是覆写 Hystrix 的默认超时时间为 5000 毫秒。请注意,以上配置项对经由 API 网关中的所有服务均生效。如果我们想要设置具体某一个服务(例如 userservice)的 Hystrix 超时时间,把“hystrix.command.default”段改为“hystrix.command.userservice”即可。
对于 API 而言,无论是 Netflix Zuul 还是 Spring Cloud Gateway,上述配置项都是一样的。你可以自己进行尝试使用。
小结与预告
本课时对 Spring Cloud Circuit Breaker 框架进行了展开,并基于该框架重构了上一课时中针对 Hystrix 的使用方法。然后,我们引入了另一个主流的熔断器框架 Resilience4j,并同样基于 Spring Cloud Circuit Breaker 所提供的统一 API 完成了熔断器实现。同时,在结尾部分,我们还给出了 Hystrix 集成 API 网关的配置方法。作为对主流几款熔断器实现技术的统一抽象和封装,Spring Cloud Circuit Breaker 的设计和实现过程值得我们借鉴。
这里给你留一道思考题:Spring Cloud Circuit Breaker 是如何对各种不同的 Circuit Breaker 的使用方法进行统一抽象的?
讲完 Spring Cloud Circuit Breaker 的使用方法,我们有必要对熔断器的实现原理做一定的展开。作为一款强大而完善的熔断器工具,Hystrix 内部使用了滑动窗口机制来对运行时度量数据进行采集和计算,从而实现自动熔断。下一课时,就让我们继续围绕 Hystrix 的内部结构和实现机制展开深入分析。
15 熔断原理:如何正确理解 HytrixCircuitBreaker 的底层实现机制?
介绍完 Spring Cloud 中针对服务容错机制的 Spring Cloud Circuit Breaker 组件之后,今天我们还是探讨其中的 Hystrix 组件。Hystrix 作为最为经典的服务容错实现框架,我们有必须要对它的底层实现机制有一定的了解。
HystrixCircuitBreaker
通过前面两个课时的介绍,我们知道在日常开发中,使用 Hystrix 熔断器的最简单方法就是在 Spring Boot 应用程序中添加 @EnableCircuitBreaker 注解。让我们先来分析一下这个注解背后的实现原理。
@EnableCircuitBreaker 注解
@EnableCircuitBreaker 注解的作用就是告诉 Spring Cloud 在该服务中启用 Hystrix,其效果就相当于在应用程序中自动注入了熔断器。与介绍负载均衡时提到的 LoadBalancerClient 接口一样,Spring Cloud 也把 @EnableCircuitBreaker 注解作为一种公共组件放在 spring-cloud-commons 工程中,其定义如下所示:
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
@Import(EnableCircuitBreakerImportSelector.class)
public @interface EnableCircuitBreaker {
}
可以看到,这里通过 @Import 注解引入了 EnableCircuitBreakerImportSelector 类,该类定义如下:
public class EnableCircuitBreakerImportSelector extends
SpringFactoryImportSelector<EnableCircuitBreaker> {
@Override
protected boolean isEnabled() {
return getEnvironment().getProperty(
"spring.cloud.circuit.breaker.enabled", Boolean.class, Boolean.TRUE);
}
}
关于 Spring Boot 中各种 ImportSelector 类的工作原理,其作用类似于 JDK 中的 SPI,它会在代码工程中的 META-INF/spring.factories 文件夹下寻找相应的配置项。上述的 EnableCircuitBreakerImportSelector 类会加载 spring.factories 中标明为 EnableCircuitBreaker 的配置类,如下所示:
org.springframework.cloud.client.circuitbreaker.EnableCircuitBreaker=\
org.springframework.cloud.netflix.hystrix.HystrixCircuitBreakerConfiguration
可以看到这里指向了 HystrixCircuitBreakerConfiguration 这个配置类,注意该类位于 spring-cloud-netflix-core 工程中。Hystrix 在整个 Spring Cloud Netflix 框架中的地位很高,这点从它所处的工程位置就可见一斑。框架的设计者认为服务容错是最核心的机制,是所有服务都应该具备的基础功能,所以没有单独创建以 Hystrix 命名的工程,而是将其直接放在了 spring-cloud-netflix-core 工程中。实际上,该工程也只包含了 Hystrix 相关的类。
HystrixCircuitBreakerConfiguration 配置类内部构造了一个切面,即 HystrixCommandAspect。从命名上看,HystrixCommandAspect 是一个用于拦截 HystrixCommand 的切面,这个切面对应的pointcut如下:
@Pointcut("@annotation(com.netflix.hystrix.contrib.javanica.annotation.HystrixCommand)")
public void hystrixCommandAnnotationPointcut() {
}
@Pointcut("@annotation(com.netflix.hystrix.contrib.javanica.annotation.HystrixCollapser)")
public void hystrixCollapserAnnotationPointcut() {
}
@Around("hystrixCommandAnnotationPointcut() || hystrixCollapserAnnotationPointcut()")
public Object methodsAnnotatedWithHystrixCommand(final ProceedingJoinPoint joinPoint) throws Throwable {
}
可以看到使用 @HystrixCommand 注解和 @HystrixCollapser 注解修饰的方法都会被这个切面进行拦截,该切面的处理流程如下所示,为了演示简单,部分内容我做了裁剪:
//从切点获取所调用方法的相关信息
Method method = getMethodFromTarget(joinPoint);
MetaHolderFactory metaHolderFactory = META_HOLDER_FACTORY_MAP.get(HystrixPointcutType.of(method));
//创建一个用于封装元数据的 MetaHolder,这些元数据包括方法中与 Hystrix 相关的信息
MetaHolder metaHolder = metaHolderFactory.create(joinPoint);
//根据 MetaHolder 创建出一个 ystrixInvokable 接口,而 HystrixCommand 就是 HystrixInvokable 的实现类
HystrixInvokable invokable = HystrixCommandFactory.getInstance().create(metaHolder);
//得到执行类型,包括同步、异步和响应式三种
ExecutionType executionType = metaHolder.isCollapserAnnotationPresent() ?
metaHolder.getCollapserExecutionType() : metaHolder.getExecutionType();
Object result;
try {
if (!metaHolder.isObservable()) {
result = CommandExecutor.execute(invokable, executionType, metaHolder);
} else {
result = executeObservable(invokable, executionType, metaHolder);
}
} catch (HystrixBadRequestException e) {
throw e.getCause();
} catch (HystrixRuntimeException e) {
throw hystrixRuntimeExceptionToThrowable(metaHolder, e);
}
return result;
从这个处理流程中引出了 HystrixInvokable 接口,我们发现它实际上只是一个空接口。在 Hystrix中,存在一批以“-able”结尾的接口定义。例如,HystrixExecutable 和 HystrixObservable 接口就继承了 HystrixInvokable 接口,而这些接口最终都由各种以“-Command”结尾的类来负责实现。HystrixInvokable 接口以及相关的 Command 类的类层关系比较复杂,整体类层结构关系如下所示。
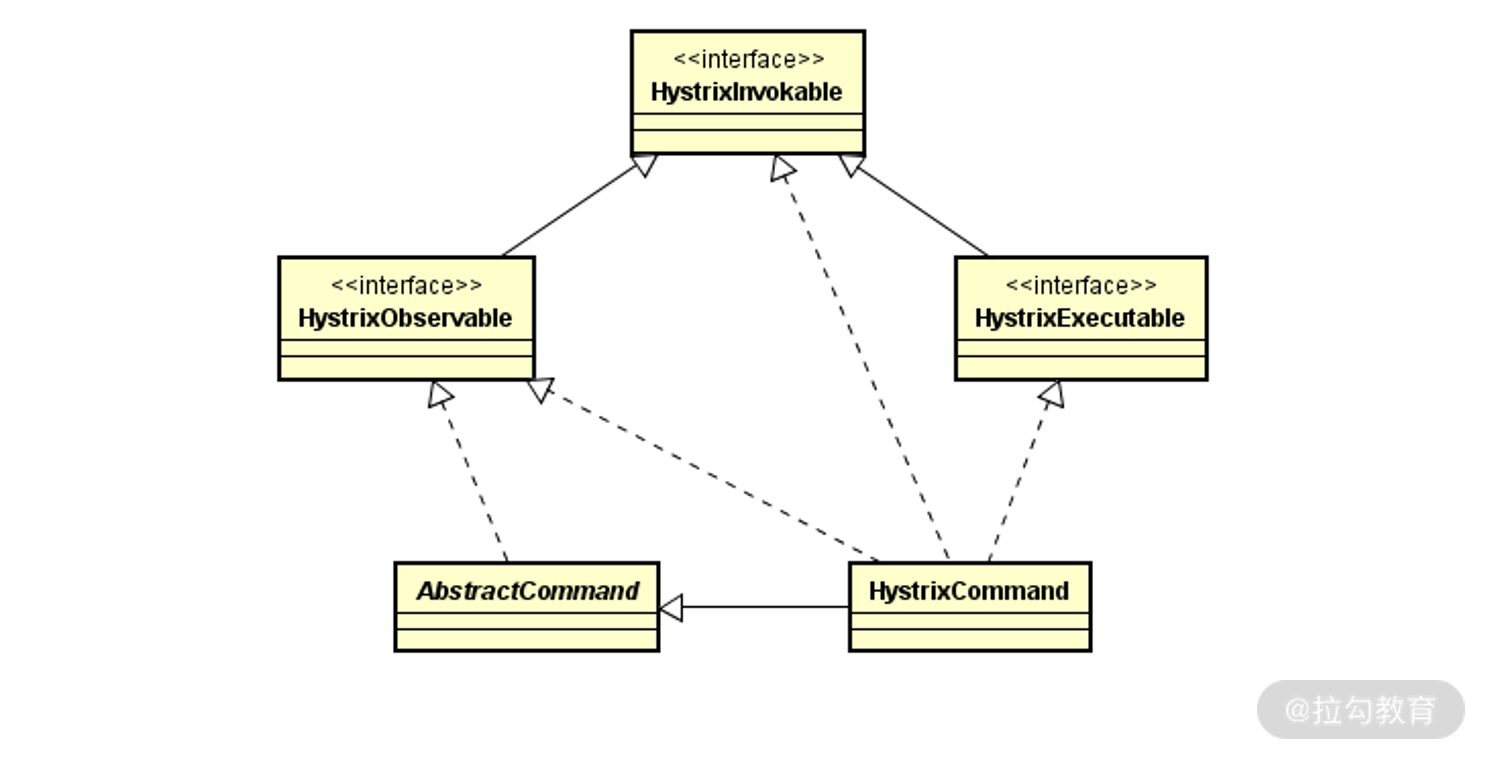
HystrixInvokable 接口的类层关系图
HystrixCircuitBreaker 实现原理
我们无意对上图中的所有内容做详细展开,本课时的目的还是梳理整个熔断器的处理流程。所以,我们快速浏览这些类中的参数和代码结构,发现在 AbstractCommand 类中存在一个类型为 HystrixCircuitBreaker 接口的变量,同时在构造函数中给出了它的初始化方法,如下所示:
protected final HystrixCircuitBreaker circuitBreaker;
private static HystrixCircuitBreaker initCircuitBreaker(boolean enabled, HystrixCircuitBreaker fromConstructor,
HystrixCommandGroupKey groupKey, HystrixCommandKey commandKey,
HystrixCommandProperties properties, HystrixCommandMetrics metrics) {
if (enabled) {
if (fromConstructor == null) {
//通过工厂类获取 HystrixCircuitBreaker 的默认实现
return HystrixCircuitBreaker.Factory.getInstance(commandKey, groupKey, properties, metrics);
} else {
return fromConstructor;
}
} else {
return new NoOpCircuitBreaker();
}
}
注意:这里的 enabled 标志位就是前面介绍的 @EnableCircuitBreaker 注解中,通过 EnableCircuitBreakerImportSelector 的 isEnabled() 方法获取的配置,相当于是一个控制是否启用熔断器的开关。如果该标志位为 true,则会创建一个 HystrixCircuitBreaker 实例,反之则返回一个什么都不做的 NoOpCircuitBreaker。
让我们来看一下 HystrixCircuitBreaker 接口的定义,如下所示:
public interface HystrixCircuitBreaker {
<span class="hljs-comment">//请求是否可被执行</span>
<span class="hljs-function"><span class="hljs-keyword">public</span> <span class="hljs-keyword">boolean</span> <span class="hljs-title">allowRequest</span><span class="hljs-params">()</span></span>;
<span class="hljs-comment">//返回当前熔断器是否打开</span>
<span class="hljs-function"><span class="hljs-keyword">public</span> <span class="hljs-keyword">boolean</span> <span class="hljs-title">isOpen</span><span class="hljs-params">()</span></span>;
<span class="hljs-comment">//关闭熔断器</span>
<span class="hljs-function"><span class="hljs-keyword">void</span> <span class="hljs-title">markSuccess</span><span class="hljs-params">()</span></span>;
}
可以看到 HystrixCircuitBreaker 接口只有三个方法,它的实现类为 HystrixCircuitBreakerImpl,该实现类通过一个 Factory 工厂类进行创建。我们先来看这个工厂类如何创建一个 HystrixCircuitBreaker 实例,也算是对工厂模式的回顾。
public static class Factory {
private static ConcurrentHashMap<String, HystrixCircuitBreaker> circuitBreakersByCommand = new ConcurrentHashMap<String, HystrixCircuitBreaker>();
public static HystrixCircuitBreaker getInstance(HystrixCommandKey key, HystrixCommandGroupKey group, HystrixCommandProperties properties, HystrixCommandMetrics metrics) {
HystrixCircuitBreaker previouslyCached = circuitBreakersByCommand.get(key.name());
if (previouslyCached != null) {
return previouslyCached;
}
HystrixCircuitBreaker cbForCommand = circuitBreakersByCommand.putIfAbsent(key.name(), new HystrixCircuitBreakerImpl(key, group, properties, metrics));
if (cbForCommand == null) {
return circuitBreakersByCommand.get(key.name());
} else {
return cbForCommand;
}
}
public static HystrixCircuitBreaker getInstance(HystrixCommandKey key) {
return circuitBreakersByCommand.get(key.name());
}
static void reset() {
circuitBreakersByCommand.clear();
}
}
这段代码很明显采用了基于 Key-Value 对的缓存设计思想,其中 Key 为 HystrixCommandKey 的 name,Value 为一个 HystrixCircuitBreakerImpl 实例。如果缓存中能够获取已有 Key 对应的 HystrixCircuitBreakerImpl 实例则直接返回,如果没有则创建一个新的实例并放入缓存。现在已经获取了一个 HystrixCircuitBreakerImpl 实例,让我们看看它如何实现 HystrixCircuitBreaker 的三个方法。
-
allowRequest()
当请求到来时,HystrixCommand 会首先调用 HystrixCircuitBreaker 中的 allowRequest 方法判断服务是否已经熔断了,而该判断取决于服务访问的失败率。allowRequest 方法首先会判断熔断器是否被强制打开或关闭。如果是强制打开,则直接拒绝请求;如果为强制关闭,则会调用下面要介绍的 isOpen() 方法来判断当前熔断器是否需要打开。如下所示:
public boolean allowRequest() {
if (properties.circuitBreakerForceOpen().get()) {
return false;
}
if (properties.circuitBreakerForceClosed().get()) {
isOpen();
return true;
}
return !isOpen() || allowSingleTest();
}
-
isOpen()
该方法返回当前熔断器是否打开的状态。如果熔断器为 Open 状态,则直接返回 true。如果不是,则会从度量指标中获取请求健康信息并根据熔断阈值判断熔断结果,如下所示:
public boolean isOpen() {
if (circuitOpen.get()) {
return true;
}
HealthCounts health = metrics.getHealthCounts();
// 检查是否达到最小请求数,如果未达到的话即使请求全部失败也不会熔断
if (health.getTotalRequests() < properties.circuitBreakerRequestVolumeThreshold().get()) {
return false;
}
// 检查错误百分比是否达到设定的阈值,如果未达到的话也不会熔断
if (health.getErrorPercentage() < properties.circuitBreakerErrorThresholdPercentage().get()) {
return false;
} else {
// 如果错误率过高,则进行熔断,并记录下熔断时间
if (circuitOpen.compareAndSet(false, true)) {
circuitOpenedOrLastTestedTime.set(System.currentTimeMillis());
return true;
} else {
return true;
}
}
}
-
markSuccess()
HystrixCircuitBreaker 中的最后一个 markSuccess 方法用于关闭熔断器。在 HystrixCmmand 执行成功的情况下,通过调用该方法可以将打开的熔断器关闭,并重置度量指标对象,如下所示:
public void markSuccess() {
if (circuitOpen.get()) {
if (circuitOpen.compareAndSet(true, false)) {
//重置度量指标对象
metrics.resetStream();
}
}
}
这三个方法的执行逻辑实际上都不复杂,HystrixCircuitBreaker 通过一个 circuitOpen 状态位控制着整个熔断判断流程,而这个状态位本身的状态值则取决于系统目前的执行数据和健康指标。我们在这三个方法中看到的 HealthCounts 和 HystrixCommandMetrics 都是这些指标的具体体现。而针对这些指标的采集和处理过程,Hystrix 提供了一套值得我们学习和借鉴的设计思想和实现机制,这就是滑动窗口(Rolling Window)机制。
Hystrix 滑动窗口机制
首先,来看一下在 HystrixCircuitBreaker 的 isOpen() 中使用到的 HealthCounts 类,我们关注它所包含的变量以及这些变量的计算方法,如下所示:
public static class HealthCounts {
private final long totalCount;
private final long errorCount;
private final int errorPercentage;
public HealthCounts plus(long[] eventTypeCounts) {
long updatedTotalCount = totalCount;
long updatedErrorCount = errorCount;
long successCount = eventTypeCounts[HystrixEventType.SUCCESS.ordinal()];
long failureCount = eventTypeCounts[HystrixEventType.FAILURE.ordinal()];
long timeoutCount = eventTypeCounts[HystrixEventType.TIMEOUT.ordinal()];
long threadPoolRejectedCount = eventTypeCounts[HystrixEventType.THREAD_POOL_REJECTED.ordinal()];
long semaphoreRejectedCount = eventTypeCounts[HystrixEventType.SEMAPHORE_REJECTED.ordinal()];
updatedTotalCount += (successCount + failureCount + timeoutCount + threadPoolRejectedCount + semaphoreRejectedCount);
updatedErrorCount += (failureCount + timeoutCount + threadPoolRejectedCount + semaphoreRejectedCount);
return new HealthCounts(updatedTotalCount, updatedErrorCount);
}
}
可以看到这个 plus() 方法比较复杂,我们需要明确所传入的 eventTypeCounts 数组的数据来源,这就要引出 Hystrix 中非常核心的一个类 HealthCountsStream。这个核心类在设计上采用了一种特定的机制,也就是所谓的滑动窗口机制。而 Hystrix 在实现这一机制时采用了数据流处理和响应式编程方面的技术和框架。作为知识储备,我们首先需要对这些机制和技术的原理做一定介绍,以便大家更好的理解实现一个熔断器所需要的考虑的各个方面。
滑动窗口和数据流处理
通常,我们想要对一些数据做分析和统计时,会首先采集一定的样本,然后进行一定的分组。在采集策略上可以使用时间维度或数量维度。滑动窗口显然属于时间维度的采集方式,即采集过程基于一定的时间窗口,而这个时间窗口随着时间的演进而逐步向前滑动。
在 Hystrix 中,采用滑动窗口来采集的系统运行时健康数据包括成功请求数量、失败请求数、超时请求数、被拒绝的请求数等。然后每次取最近 10 秒的数据来进行计算,如果这 10 秒中请求的失败率计算下来超过了 50%,就会触发熔断器的熔断机制。这里的 10 秒就是一个滑动窗口,参考其官网的一幅图:
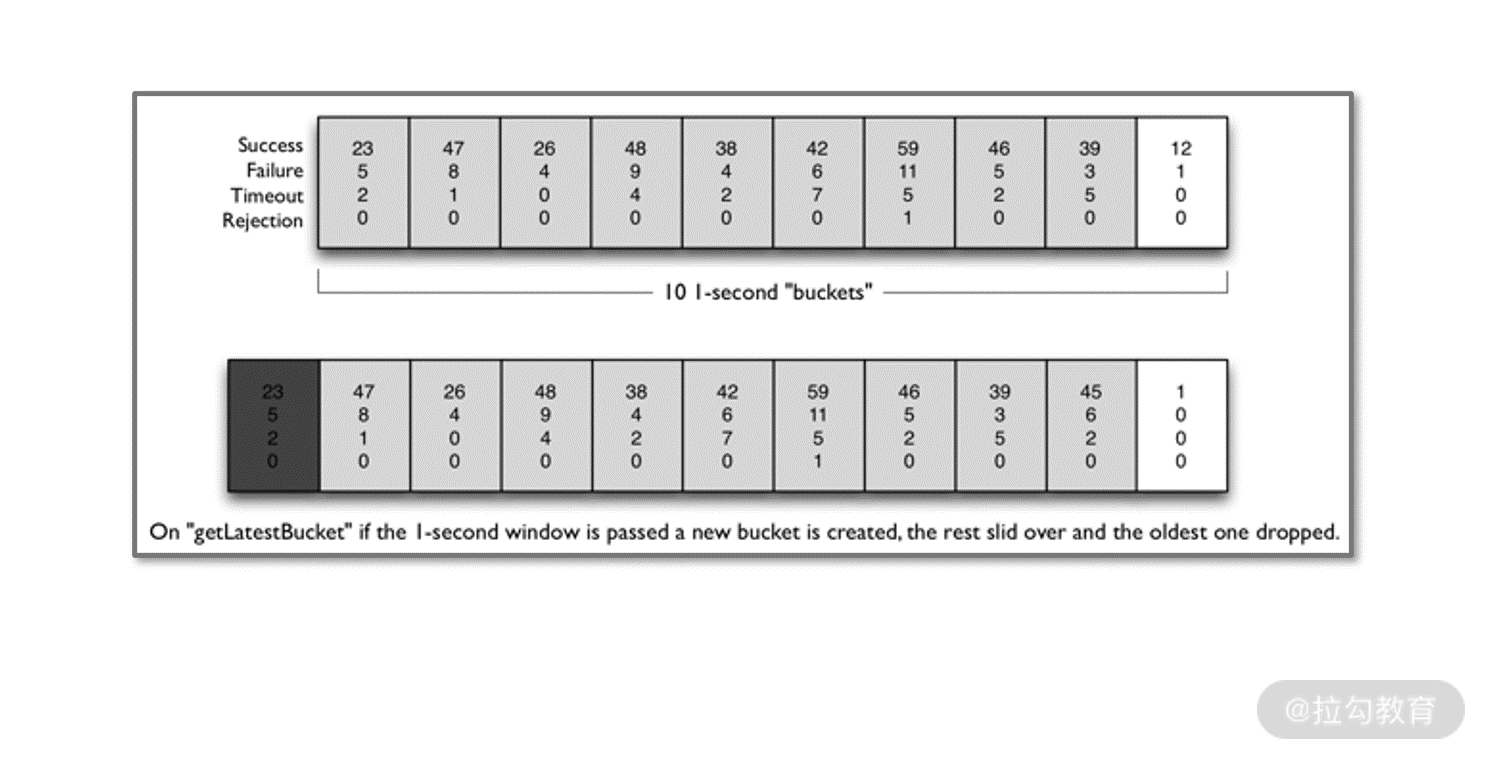
滑动窗口示意图(来自 Hystrix 官网)
在上图中,每一个格子就是一个时间间隔,格子中的数据就是这个时间间隔内所处理的请求数量。通常我们把这种格子称为一个桶(Bucket)。然后每当收集好一个新桶之后,就会丢弃掉最旧的一个桶,这样时间窗口就能持续向前滑动。
那么如何来实现这个滑动窗口呢?我们转换思路,可以把系统运行时所产生的所有数据都视为一个个的事件,这样滑动窗口中每个桶的数据都来自源源不断的事件,因此滑动窗口非常适合用观察者模式来实现。同时,对于这些生成的事件,我们通常需要对其进行转换以便执行后续的操作。这两点构成了实现滑动窗口的设计目标和方法。
响应式编程和 RxJava 基础
在技术选型上,Hystrix 采用了响应式编程框架 RxJava。如果大家想要完全掌握 Hystrix 中的源码实现过程,还是需要对响应式编程和 RxJava 框架有一定的了解。在响应式编程中,我们把源源不断的事件看成是一个流(Stream),业界也存在一个响应式流(Reactive Stream)规范,该规范中的流是一个发布和订阅的过程。关于响应式流以及响应式编程的核心概念以及 RxJava、Project Reactor 等框架,可参考《RxJava反应式编程》和《Spring响应式编程》进行学习。在本课时中,我们无意对 RxJava 做全面而详细的介绍,这里仅仅给出理解 Hystrix 滑动窗口实现过程中所需要的必备知识。
与其他响应式编程框架一样,RxJava 同样实现了响应式流规范。使用 RxJava 实现有一大好处是可以通过 RxJava 的一系列操作符来实现滑动窗口,从而可以依赖 RxJava 的线程模型来确保数据写入和聚合的线程安全。RxJava 中用于健康信息采集的操作符包括 window、flatMap 和 reduce 等。
-
window 操作符。
window 操作符用于开窗操作,也就是把当前流中的元素采集并合并到另外的流中,该操作符示意图如下图所示:
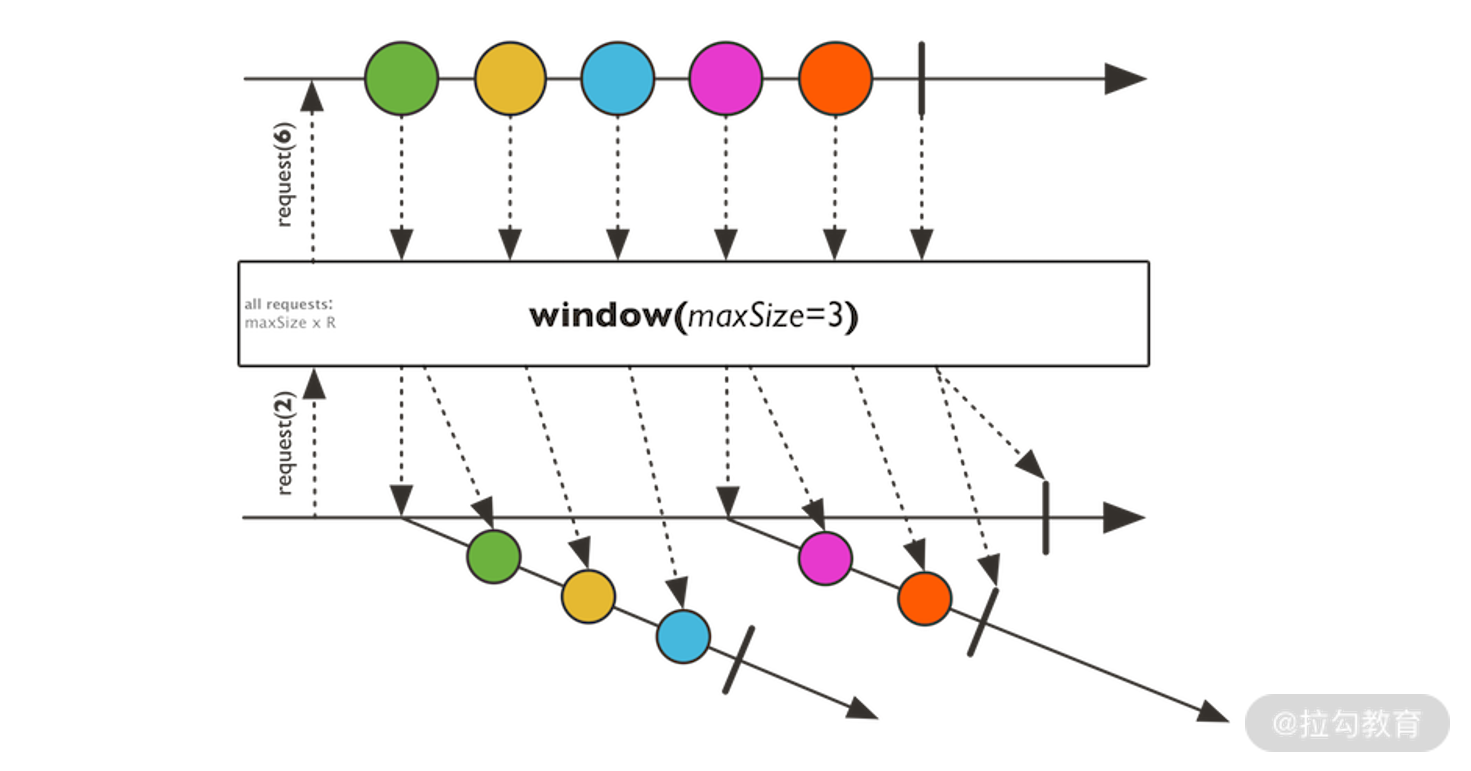
window 操作符示意图(来自 Reactor 官网)
以上图为例,我们看到有 5 个元素从流中输入,然后我们对其进行开窗操作(窗口大小为 3),这样输入流就变成了两个输出流。
-
flatMap 操作符。
flatMap,也就是拉平并转化。与常见的 map 不同,flatMap 操作符把输入流中的每个元素转换成另一个流,再把这些转换之后得到的流元素进行合并。flapMap 操作符示意图如下图所示:
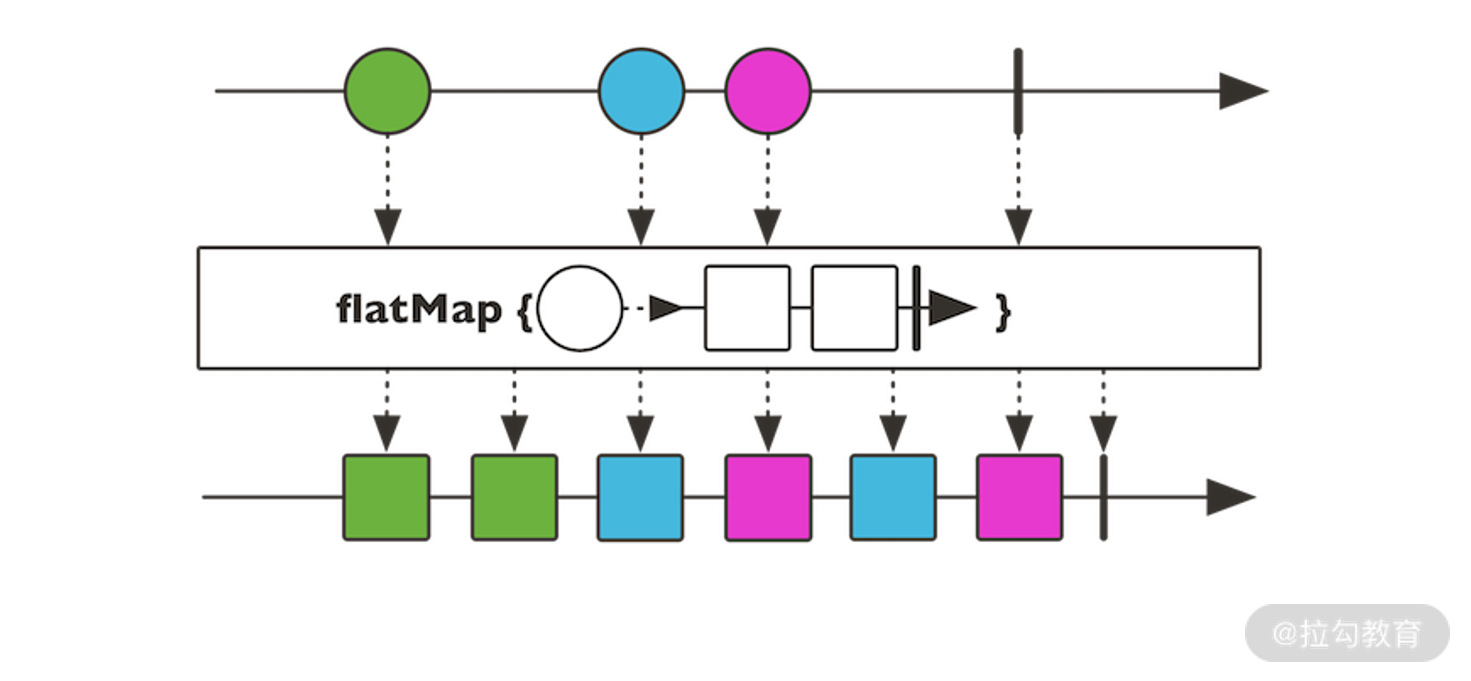
flapMap 操作符示意图(来自 Reactor 官网)
例如,我们对 1 和 5 使用 flatMap 操作,转换的逻辑是返回它们的平方值并进行合并,这样通过 flatMap 操作符之后这两个元素就变成了 1 和 25。
-
reduce 操作符。
reduce 操作符对流中包含的所有元素进行累积计算,该操作符示意图见下图所示:
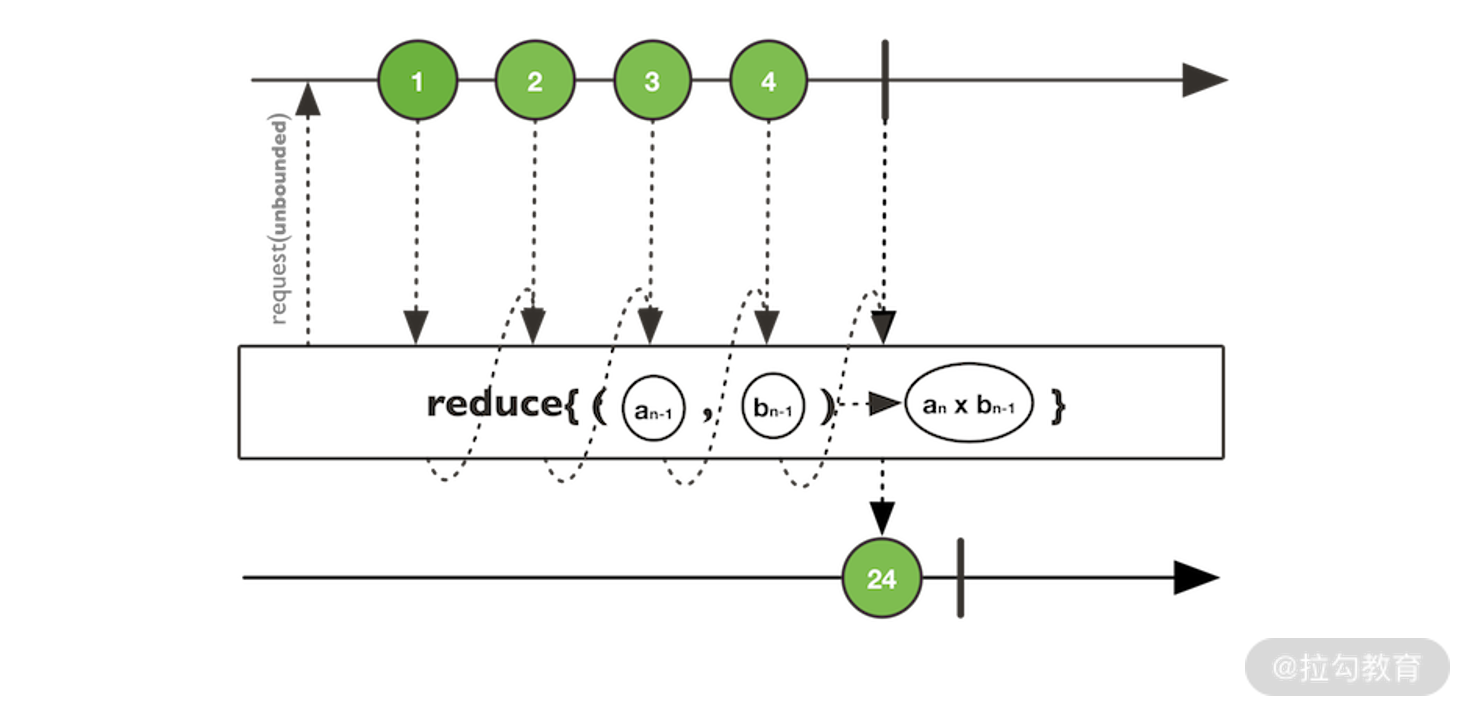
reduce 操作符示意图(来自 Reactor 官网)
上图中的具体累积操作通常也是通过一个函数来实现。例如,假如这个函数为一个求和函数,那么对 1 到 10 的数字进行求和时,reduce 操作符的运行结果即为 55。
具备了这些基础知识之后,让我们回到 Hystrix 的 HealthCountsStream 类。
HealthCountsStream
我们首先来看一下 HealthCountsStream 类的类层结构,如下图所示:
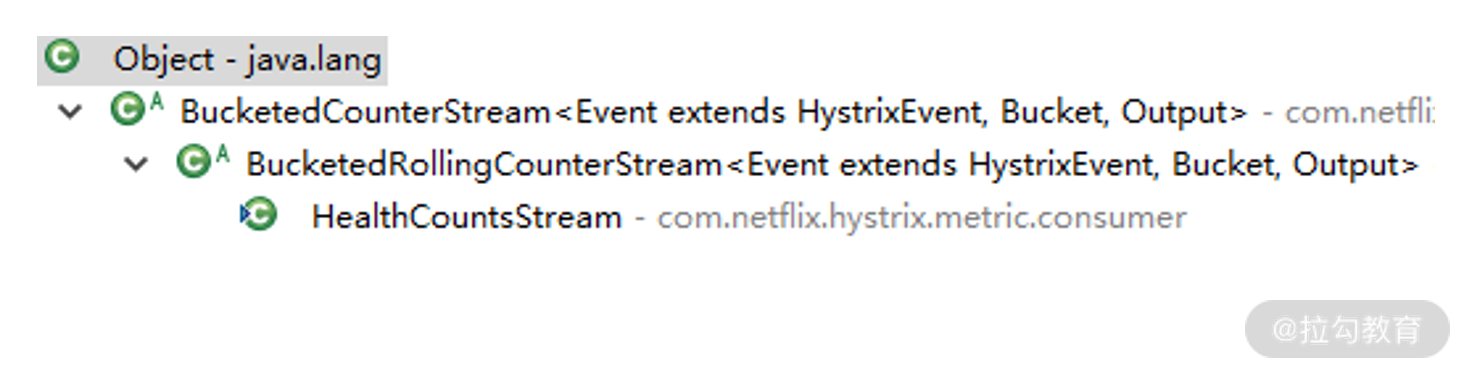
HealthCountsStream 类层结构图
显然,从类的命名上不难看出,BucketedCounterStream 类代表一个窗口类,将基础数据汇总成一个个的桶。它的子类 BucketedRollingCounterStream 在它的基础上添加了滑动窗口处理,将桶汇总成滑动窗口。而 HealthCountsStream 最终表现为一个运行时健康数据流。
在 BucketedCounterStream 类中,通过以下代码把事件流汇总成 Bucket:
this.bucketedStream = Observable.defer(new Func0<Observable<Bucket>>() {
@Override
public Observable<Bucket> call() {
return inputEventStream
.observe()
// 使用 window 操作符收集一个 Bucket 时间内的数据
.window(bucketSizeInMs, TimeUnit.MILLISECONDS)
// 将每个 window 内聚集起来的事件集合汇总成 Bucket
.flatMap(reduceBucketToSummary) .startWith(emptyEventCountsToStart); }
});
可以看到,这里分别使用了前面介绍的 window 和 flatMap 操作符来完成桶的构建。请注意,该方法返回的是一个 Observable<Bucket> 对象。在 RxJava 中,Observable 代表的就是一个无限流对象。
我们再来看 BucketedRollingCounterStream 类,该类的构造函数中同样存在一个类似的方法,如下所示(为了避免过于复杂,裁剪了部分代码):
this.sourceStream = bucketedStream
//将 N 个 Bucket 进行汇总
.window(numBuckets, 1)
//汇总成一个窗口
.flatMap(reduceWindowToSummary)
…
//添加背压控制
.onBackpressureDrop();
上述方法中基于父类 BucketedCounterStream 已经汇总的 bucketedStream 进行开窗处理,从而获取一个 sourceStream,这个 sourceStream 就是滑动窗口的最终形态。最后的 onBackpressureDrop() 语句是 RxJava 中提供的一种背压(Backpressure)机制,代表了一种流量控制策略,当消费者消费速度过慢时就丢弃数据,不进行积压。这里需要展开的是传入到 flatMap 操作符中的 reduceWindowToSummary 对象,该对象实际上是一个方法,用于设置flatMap的具体操作,定义如下:
Func1<Observable<Bucket>, Observable<Output>> reduceWindowToSummary = new Func1<Observable<Bucket>, Observable<Output>>() {
@Override
public Observable<Output> call(Observable<Bucket> window) {
return window.scan(getEmptyOutputValue(), reduceBucket).skip(numBuckets);
}
};
这里使用了 scan + skip 方法组合来完成类似 reduce 操作符的功能。这样做的主要是因为当数据流终结时,位于流末端的最后一个窗口内的数据往往是不完整的。这时候就需要把这些不完整的窗口进行过滤,从而确保数据不缺失。
最后,我们回到 HealthCountsStream。HealthCountsStream 通过调用父类 BucketedRollingCounterStream 的构造函数完成自身流的构建,并在这个过程中使用了 HealthCounts 类的 plus 方法完成健康指标的计算。
作为总结,Hystrix 巧妙地运用了 RxJava 中的 window、flatMap 等操作符来将单位窗口时间内的事件,及一个个窗口大小的桶聚集到一起,形成滑动窗口。并基于滑动窗口,集成指标数据。这个设计思想非常巧妙,值得我们深入研究并对基于流的处理过程中加以尝试和应用。
小结与预告
今天我们继续讨论经典的 Hystrix 框架,但转换了切入点,我们从实现原理出发结合部分源码对该框架的底层实现机制进行了深入的剖析。我们分析了 @EnableCircuitBreaker 和 HystrixCircuitBreaker 的实现原理。更为重要的是,我们介绍了 Hystrix 中所采用的滑动窗口机制,这种机制对于我们理解和掌握流式数据处理有很大的参考价值。
这里给你留一道思考题:你能简要说明 Hystrix 中的滑动窗口机制是如何做到对运行时数据进行采集和计算的吗?
讲完服务容错机制以及 Spring Cloud Circuit Breaker 框架,从下一课时开始,我们将进入一个新的主题的讲解,即配置中心。我们将首先讨论如何设计分布式环境下的配置中心解决方案。
智能推荐
使用nginx解决浏览器跨域问题_nginx不停的xhr-程序员宅基地
文章浏览阅读1k次。通过使用ajax方法跨域请求是浏览器所不允许的,浏览器出于安全考虑是禁止的。警告信息如下:不过jQuery对跨域问题也有解决方案,使用jsonp的方式解决,方法如下:$.ajax({ async:false, url: 'http://www.mysite.com/demo.do', // 跨域URL ty..._nginx不停的xhr
在 Oracle 中配置 extproc 以访问 ST_Geometry-程序员宅基地
文章浏览阅读2k次。关于在 Oracle 中配置 extproc 以访问 ST_Geometry,也就是我们所说的 使用空间SQL 的方法,官方文档链接如下。http://desktop.arcgis.com/zh-cn/arcmap/latest/manage-data/gdbs-in-oracle/configure-oracle-extproc.htm其实简单总结一下,主要就分为以下几个步骤。..._extproc
Linux C++ gbk转为utf-8_linux c++ gbk->utf8-程序员宅基地
文章浏览阅读1.5w次。linux下没有上面的两个函数,需要使用函数 mbstowcs和wcstombsmbstowcs将多字节编码转换为宽字节编码wcstombs将宽字节编码转换为多字节编码这两个函数,转换过程中受到系统编码类型的影响,需要通过设置来设定转换前和转换后的编码类型。通过函数setlocale进行系统编码的设置。linux下输入命名locale -a查看系统支持的编码_linux c++ gbk->utf8
IMP-00009: 导出文件异常结束-程序员宅基地
文章浏览阅读750次。今天准备从生产库向测试库进行数据导入,结果在imp导入的时候遇到“ IMP-00009:导出文件异常结束” 错误,google一下,发现可能有如下原因导致imp的数据太大,没有写buffer和commit两个数据库字符集不同从低版本exp的dmp文件,向高版本imp导出的dmp文件出错传输dmp文件时,文件损坏解决办法:imp时指定..._imp-00009导出文件异常结束
python程序员需要深入掌握的技能_Python用数据说明程序员需要掌握的技能-程序员宅基地
文章浏览阅读143次。当下是一个大数据的时代,各个行业都离不开数据的支持。因此,网络爬虫就应运而生。网络爬虫当下最为火热的是Python,Python开发爬虫相对简单,而且功能库相当完善,力压众多开发语言。本次教程我们爬取前程无忧的招聘信息来分析Python程序员需要掌握那些编程技术。首先在谷歌浏览器打开前程无忧的首页,按F12打开浏览器的开发者工具。浏览器开发者工具是用于捕捉网站的请求信息,通过分析请求信息可以了解请..._初级python程序员能力要求
Spring @Service生成bean名称的规则(当类的名字是以两个或以上的大写字母开头的话,bean的名字会与类名保持一致)_@service beanname-程序员宅基地
文章浏览阅读7.6k次,点赞2次,收藏6次。@Service标注的bean,类名:ABDemoService查看源码后发现,原来是经过一个特殊处理:当类的名字是以两个或以上的大写字母开头的话,bean的名字会与类名保持一致public class AnnotationBeanNameGenerator implements BeanNameGenerator { private static final String C..._@service beanname
随便推点
二叉树的各种创建方法_二叉树的建立-程序员宅基地
文章浏览阅读6.9w次,点赞73次,收藏463次。1.前序创建#include<stdio.h>#include<string.h>#include<stdlib.h>#include<malloc.h>#include<iostream>#include<stack>#include<queue>using namespace std;typed_二叉树的建立
解决asp.net导出excel时中文文件名乱码_asp.net utf8 导出中文字符乱码-程序员宅基地
文章浏览阅读7.1k次。在Asp.net上使用Excel导出功能,如果文件名出现中文,便会以乱码视之。 解决方法: fileName = HttpUtility.UrlEncode(fileName, System.Text.Encoding.UTF8);_asp.net utf8 导出中文字符乱码
笔记-编译原理-实验一-词法分析器设计_对pl/0作以下修改扩充。增加单词-程序员宅基地
文章浏览阅读2.1k次,点赞4次,收藏23次。第一次实验 词法分析实验报告设计思想词法分析的主要任务是根据文法的词汇表以及对应约定的编码进行一定的识别,找出文件中所有的合法的单词,并给出一定的信息作为最后的结果,用于后续语法分析程序的使用;本实验针对 PL/0 语言 的文法、词汇表编写一个词法分析程序,对于每个单词根据词汇表输出: (单词种类, 单词的值) 二元对。词汇表:种别编码单词符号助记符0beginb..._对pl/0作以下修改扩充。增加单词
android adb shell 权限,android adb shell权限被拒绝-程序员宅基地
文章浏览阅读773次。我在使用adb.exe时遇到了麻烦.我想使用与bash相同的adb.exe shell提示符,所以我决定更改默认的bash二进制文件(当然二进制文件是交叉编译的,一切都很完美)更改bash二进制文件遵循以下顺序> adb remount> adb push bash / system / bin /> adb shell> cd / system / bin> chm..._adb shell mv 权限
投影仪-相机标定_相机-投影仪标定-程序员宅基地
文章浏览阅读6.8k次,点赞12次,收藏125次。1. 单目相机标定引言相机标定已经研究多年,标定的算法可以分为基于摄影测量的标定和自标定。其中,应用最为广泛的还是张正友标定法。这是一种简单灵活、高鲁棒性、低成本的相机标定算法。仅需要一台相机和一块平面标定板构建相机标定系统,在标定过程中,相机拍摄多个角度下(至少两个角度,推荐10~20个角度)的标定板图像(相机和标定板都可以移动),即可对相机的内外参数进行标定。下面介绍张氏标定法(以下也这么称呼)的原理。原理相机模型和单应矩阵相机标定,就是对相机的内外参数进行计算的过程,从而得到物体到图像的投影_相机-投影仪标定
Wayland架构、渲染、硬件支持-程序员宅基地
文章浏览阅读2.2k次。文章目录Wayland 架构Wayland 渲染Wayland的 硬件支持简 述: 翻译一篇关于和 wayland 有关的技术文章, 其英文标题为Wayland Architecture .Wayland 架构若是想要更好的理解 Wayland 架构及其与 X (X11 or X Window System) 结构;一种很好的方法是将事件从输入设备就开始跟踪, 查看期间所有的屏幕上出现的变化。这就是我们现在对 X 的理解。 内核是从一个输入设备中获取一个事件,并通过 evdev 输入_wayland