关于自编码器(AE,DAE,CAE,SAE等)_深度自编码器-程序员宅基地
技术标签: 人工智能-神经网络
最近在做关于无监督学习的模型,偶尔又拾起了关于自编码器(AE,autoencoder)的知识,现在做一个系统梳理。
其实关于这一方面,还有一个更加吸引人的升级版VAE,变分自编码器,这个是GAN,生成式对抗网络的孪生兄弟。可以参见我单独后续的博客。
一、什么是自编码器(Autoencoder)
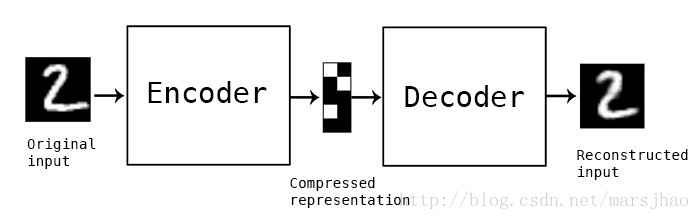
自动编码器是一种数据的压缩算法,其中数据的压缩和解压缩函数是数据相关的、有损的、从样本中自动学习的。在大部分提到自动编码器的场合,压缩和解压缩的函数是通过神经网络实现的。
1)自动编码器是数据相关的(data-specific 或 data-dependent),这意味着自动编码器只能压缩那些与训练数据类似的数据。比如,使用人脸训练出来的自动编码器在压缩别的图片,比如树木时性能很差,因为它学习到的特征是与人脸相关的。
2)自动编码器是有损的,意思是解压缩的输出与原来的输入相比是退化的,MP3,JPEG等压缩算法也是如此(突然想说,神奇的微信图片压缩算法哈哈哈)。这与无损压缩算法不同。
3)自动编码器是从数据样本中自动学习的,这意味着很容易对指定类的输入训练出一种特定的编码器,而不需要完成任何新工作。
搭建一个自动编码器需要完成下面三样工作:搭建编码器,搭建解码器,设定一个损失函数,用以衡量由于压缩而损失掉的信息。编码器和解码器一般都是参数化的方程,并关于损失函数可导,典型情况是使用神经网络。编码器和解码器的参数可以通过最小化损失函数而优化,例如SGD。
自编码器是一个自监督的算法,并不是一个无监督算法。自监督学习是监督学习的一个实例,其标签产生自输入数据。要获得一个自监督的模型,你需要一个靠谱的目标跟一个损失函数,仅仅把目标设定为重构输入可能不是正确的选项。基本上,要求模型在像素级上精确重构输入不是机器学习的兴趣所在,学习到高级的抽象特征才是。事实上,当主要任务是分类、定位之类的任务时,那些对这类任务而言的最好的特征基本上都是重构输入时的最差的那种特征。
目前自编码器的应用主要有两个方面,第一是数据去噪,第二是为进行可视化而降维。配合适当的维度和稀疏约束,自编码器可以学习到比PCA等技术更有意思的数据投影。
对于2D的数据可视化,t-SNE(读作tee-snee)或许是目前最好的算法,但通常还是需要原数据的维度相对低一些。所以,可视化高维数据的一个好办法是首先使用自编码器将维度降低到较低的水平(如32维),然后再使用t-SNE将其投影在2D平面上。
二、几种自编码器
自编码器(autoencoder)是神经网络的一种,经过训练后能尝试将输入复制到输出。自编码器()autoencoder)内部有一个隐藏层 h,可以产生编码(code)表示输入。该网络可以看作由两部分组成:一个由函数 h = f(x) 表示的编码器和一个生成重构的解码器 r = g(h)。如果一个自编码器只是简单地学会将处处设置为 g(f(x)) = x,那么这个自编码器就没什么特别的用处。相反,我们不应该将自编码器设计成输入到输出完全相等。这通常需要向自编码器强加一些约束,使它只能近似地复制,并只能复制与训练数据相似的输入。这些约束强制模型考虑输入数据的哪些部分需要被优先复制,因此它往往能学习到数据的有用特性。
1. 欠完备自编码器(一般常见的自编码器AE)
从自编码器获得有用特征的一种方法是限制 h的维度比 x 小,这种编码维度小于输入维度的自编码器称为欠完备(undercomplete)自编码器。学习欠完备的表示将强制自编码器捕捉训练数据中最显著的特征。
学习过程可以简单地描述为最小化一个损失函数L(x,g(f(x))),其中 L 是一个损失函数,惩罚g(f(x)) 与 x 的差异,如均方误差。当解码器是线性的且 L 是均方误差,欠完备的自编码器会学习出与 PCA 相同的生成子空间。这种情况下,自编码器在训练来执行复制任务的同时学到了训据的主元子空间。如果编码器和解码器被赋予过大的容量,自编码器会执行复制任务而捕捉不到任何有关数据分布的有用信息。
2. 正则自编码器
正则自编码器使用的损失函数可以鼓励模型学习其他特性(除了将输入复制到输出),而不必限制使用浅层的编码器和解码器以及小的编码维数来限制模型的容量。这些特性包括稀疏表示、表示的小导数、以及对噪声或输入缺失的鲁棒性。即使模型容量大到足以学习一个无意义的恒等函数,非线性且过完备的正则自编码器仍然能够从数据中学到一些关于数据分布的有用信息。
2.1 稀疏自编码器(SAE)
稀疏自编码器简单地在训练时结合编码层的稀疏惩罚 Ω(h) 和重构误差:L(x,g(f(x))) + Ω(h),其中 g(h) 是解码器的输出,通常 h 是编码器的输出,即 h = f(x)。稀疏自编码器一般用来学习特征,以便用于像分类这样的任务。稀疏正则化的自编码器必须反映训练数据集的独特统计特征,而不是简单地充当恒等函数。以这种方式训练,执行附带稀疏惩罚的复制任务可以得到能学习有用特征的模型。
2.2 去噪自编码器(DAE)
去噪自编码器(denoisingautoencoder, DAE)最小化L(x,g(f(˜ x))),其中 ˜ x 是被某种噪声损坏的 x 的副本。因此去噪自编码器必须撤消这些损坏,而不是简单地复制输入。
2.3 收缩自编码器(CAE)
另一正则化自编码器的策略是使用一个类似稀疏自编码器中的惩罚项 Ω,
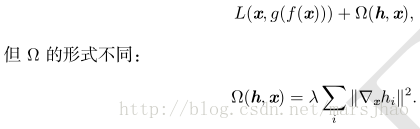
这迫使模型学习一个在 x 变化小时目标也没有太大变化的函数。因为这个惩罚只对训练数据适用,它迫使自编码器学习可以反映训练数据分布信息的特征。这样正则化的自编码器被称为收缩自编码器(contractive autoencoder, CAE)。这种方法与去噪自编码器、流形学习和概率模型存在一定理论联系。
3. 表示能力、层的大小和深度
万能近似定理保证至少有一层隐藏层且隐藏单元足够多的前馈神经网络能以任意精度近似任意函数(在很大范围里),这是非平凡深度(至少有一层隐藏层)的一个主要优点。这意味着具有单隐藏层的自编码器在数据域内能表示任意近似数据的恒等函数。但是,从输入到编码的映射是浅层的。这意味这我们不能任意添加约束,比如约束编码稀疏。深度自编码器(编码器至少包含一层额外隐藏层)在给定足够多的隐藏单元的情况下,能以任意精度近似任何从输入到编码的映射。
深度可以指数地降低表示某些函数的计算成本。深度也能指数地减少学习一些函数所需的训练数据量。实验中,深度自编码器能比相应的浅层或线性自编码器产生更好的压缩效率。
训练深度自编码器的普遍策略是训练一堆浅层的自编码器来贪心地预训练相应的深度架构。所以即使最终目标是训练深度自编码器,我们也经常会遇到浅层自编码器。
4. 去噪自编码器
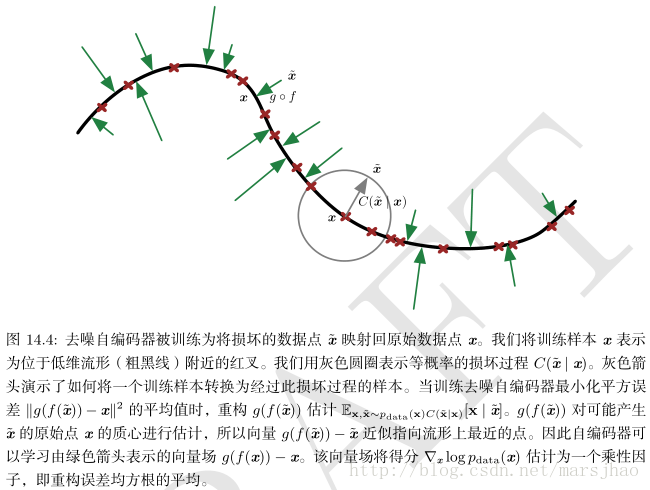
去噪自编码器(denoisingautoencoder, DAE)是一类接受损坏数据作为输入,并训练来预测原始未被损坏数据作为输出的自编码器。
DAE 的训练准则(条件高斯p(x | h))能让自编码器学到能估计数据分布得分的向量场 (g(f(x)) − x) ,这是 DAE 的一个重要特性。
5. 收缩自编码器
收缩自编码器 (Rifai et al.,2011a,b) 在编码 h = f(x) 的基础上添加了显式的正则项,鼓励 f 的导数尽可能小:
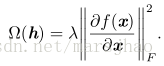
惩罚项 Ω(h) 为平方 Frobenius范数(元素平方之和),作用于与编码器的函数相关偏导数的 Jacobian 矩阵。
收缩(contractive)源于 CAE 弯曲空间的方式。具体来说,由于 CAE 训练为抵抗输入扰动,鼓励将输入点邻域映射到输出点处更小的邻域。我们能认为这是将输入的邻域收缩到更小的输出邻域。
三、使用Keras建立简单的自编码器
1. 单隐含层自编码器
建立一个全连接的编码器和解码器。也可以单独使用编码器和解码器,在此使用Keras的函数式模型API即Model可以灵活地构建自编码器。
50个epoch后,看起来我们的自编码器优化的不错了,损失val_loss: 0.1037。
from keras.layers import Input, Dense
from keras.models import Model
from keras.datasets import mnist
import numpy as np
import matplotlib.pyplot as plt
(x_train, _), (x_test, _) = mnist.load_data()
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
x_train = x_train.reshape((len(x_train), np.prod(x_train.shape[1:])))
x_test = x_test.reshape((len(x_test), np.prod(x_test.shape[1:])))
print(x_train.shape)
print(x_test.shape)
encoding_dim = 32
input_img = Input(shape=(784,))
encoded = Dense(encoding_dim, activation='relu')(input_img)
decoded = Dense(784, activation='sigmoid')(encoded)
autoencoder = Model(inputs=input_img, outputs=decoded)
encoder = Model(inputs=input_img, outputs=encoded)
encoded_input = Input(shape=(encoding_dim,))
decoder_layer = autoencoder.layers[-1]
decoder = Model(inputs=encoded_input, outputs=decoder_layer(encoded_input))
autoencoder.compile(optimizer='adadelta', loss='binary_crossentropy')
autoencoder.fit(x_train, x_train, epochs=50, batch_size=256,
shuffle=True, validation_data=(x_test, x_test))
encoded_imgs = encoder.predict(x_test)
decoded_imgs = decoder.predict(encoded_imgs)
n = 10 # how many digits we will display
plt.figure(figsize=(20, 4))
for i in range(n):
ax = plt.subplot(2, n, i + 1)
plt.imshow(x_test[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
ax = plt.subplot(2, n, i + 1 + n)
plt.imshow(decoded_imgs[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
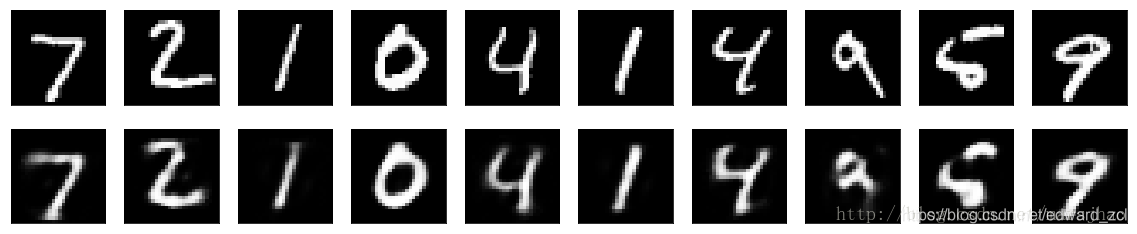
2. 稀疏自编码器、深层自编码器(栈式自编码器SAE)
为码字加上稀疏性约束。如果我们对隐层单元施加稀疏性约束的话,会得到更为紧凑的表达,只有一小部分神经元会被激活。在Keras中,我们可以通过添加一个activity_regularizer达到对某层激活值进行约束的目的。
encoded = Dense(encoding_dim, activation='relu',activity_regularizer=regularizers.activity_l1(10e-5))(input_img)
把多个自编码器叠起来即加深自编码器的深度,50个epoch后,损失val_loss:0.0926,比1个隐含层的自编码器要好一些。
input_img = Input(shape=(784,))
encoded = Dense(128, activation='relu')(input_img)
encoded = Dense(64, activation='relu')(encoded)
decoded_input = Dense(32, activation='relu')(encoded)
decoded = Dense(64, activation='relu')(decoded_input)
decoded = Dense(128, activation='relu')(decoded)
decoded = Dense(784, activation='sigmoid')(encoded)
autoencoder = Model(inputs=input_img, outputs=decoded)
encoder = Model(inputs=input_img, outputs=decoded_input)
autoencoder.compile(optimizer='adadelta', loss='binary_crossentropy')
autoencoder.fit(x_train, x_train, epochs=50, batch_size=256,
shuffle=True, validation_data=(x_test, x_test))
encoded_imgs = encoder.predict(x_test)
decoded_imgs = autoencoder.predict(x_test)
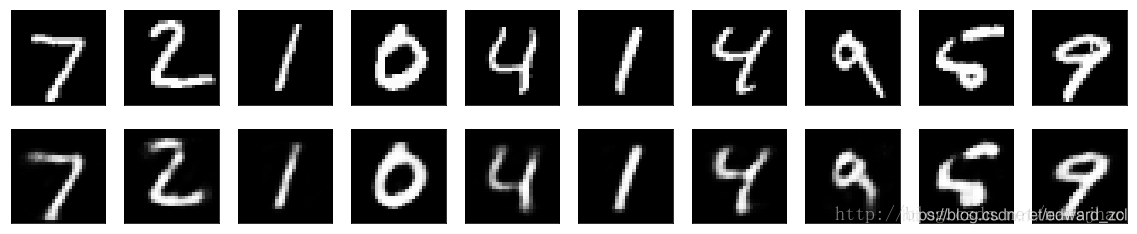
稀疏自编码器的损失函数可以是L1或者L2,或者是KL散度,参考:
https://blog.csdn.net/wblgers1234/article/details/81545079
http://ufldl.stanford.edu/wiki/index.php/稀疏编码
https://www.cnblogs.com/tornadomeet/archive/2013/04/13/3018393.html
关于激活值正则与权重正则是非常常见的。
栈式自编码器可进一步参考:
https://blog.csdn.net/wblgers1234/article/details/81545079
3. 卷积自编码器(CAE):用卷积层构建自编码器
当输入是图像时,使用卷积神经网络是更好的。卷积自编码器的编码器部分由卷积层和MaxPooling层构成,MaxPooling负责空域下采样。而解码器由卷积层和上采样层构成。50个epoch后,损失val_loss: 0.1018。
input_img = Input(shape=(28, 28, 1))
x = Convolution2D(16, (3, 3), activation='relu', padding='same')(input_img)
x = MaxPooling2D((2, 2), padding='same')(x)
x = Convolution2D(8, (3, 3), activation='relu', padding='same')(x)
x = MaxPooling2D((2, 2), padding='same')(x)
x = Convolution2D(8, (3, 3), activation='relu', padding='same')(x)
encoded = MaxPooling2D((2, 2), padding='same')(x)
x = Convolution2D(8, (3, 3), activation='relu', padding='same')(encoded)
x = UpSampling2D((2, 2))(x)
x = Convolution2D(8, (3, 3), activation='relu', padding='same')(x)
x = UpSampling2D((2, 2))(x)
x = Convolution2D(16, (3, 3), activation='relu')(x)
x = UpSampling2D((2, 2))(x)
decoded = Convolution2D(1, (3, 3), activation='sigmoid', padding='same')(x)
autoencoder = Model(inputs=input_img, outputs=decoded)
autoencoder.compile(optimizer='adadelta', loss='binary_crossentropy')
#打开一个终端并启动TensorBoard,终端中输入 tensorboard --logdir=/autoencoder
autoencoder.fit(x_train, x_train, epochs=50, batch_size=256,
shuffle=True, validation_data=(x_test, x_test),
callbacks=[TensorBoard(log_dir='autoencoder')])
decoded_imgs = autoencoder.predict(x_test)
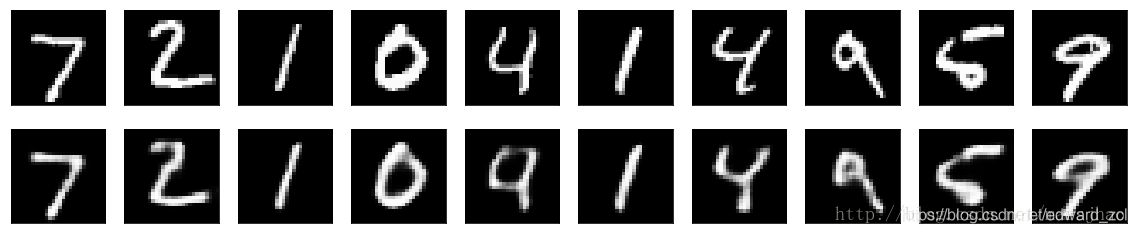
4. 使用自动编码器进行图像去噪
我们把训练样本用噪声污染,然后使解码器解码出干净的照片,以获得去噪自动编码器。首先我们把原图片加入高斯噪声,然后把像素值clip到0~1。
from keras.layers import Input, Convolution2D, MaxPooling2D, UpSampling2D
from keras.models import Model
from keras.datasets import mnist
import numpy as np
import matplotlib.pyplot as plt
from keras.callbacks import TensorBoard
(x_train, _), (x_test, _) = mnist.load_data()
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
x_train = np.reshape(x_train, (len(x_train), 28, 28, 1))
x_test = np.reshape(x_test, (len(x_test), 28, 28, 1))
noise_factor = 0.5
x_train_noisy = x_train + noise_factor * np.random.normal(loc=0.0, scale=1.0, size=x_train.shape)
x_test_noisy = x_test + noise_factor * np.random.normal(loc=0.0, scale=1.0, size=x_test.shape)
x_train_noisy = np.clip(x_train_noisy, 0., 1.)
x_test_noisy = np.clip(x_test_noisy, 0., 1.)
print(x_train.shape)
print(x_test.shape)
input_img = Input(shape=(28, 28, 1))
x = Convolution2D(32, (3, 3), activation='relu', padding='same')(input_img)
x = MaxPooling2D((2, 2), padding='same')(x)
x = Convolution2D(32, (3, 3), activation='relu', padding='same')(x)
encoded = MaxPooling2D((2, 2), padding='same')(x)
x = Convolution2D(32, (3, 3), activation='relu', padding='same')(encoded)
x = UpSampling2D((2, 2))(x)
x = Convolution2D(32, (3, 3), activation='relu', padding='same')(x)
x = UpSampling2D((2, 2))(x)
decoded = Convolution2D(1, (3, 3), activation='sigmoid', padding='same')(x)
autoencoder = Model(inputs=input_img, outputs=decoded)
autoencoder.compile(optimizer='adadelta', loss='binary_crossentropy')
#打开一个终端并启动TensorBoard,终端中输入 tensorboard --logdir=/autoencoder
autoencoder.fit(x_train_noisy, x_train, epochs=10, batch_size=256,
shuffle=True, validation_data=(x_test_noisy, x_test),
callbacks=[TensorBoard(log_dir='autoencoder', write_graph=False)])
decoded_imgs = autoencoder.predict(x_test_noisy)
n = 10
plt.figure(figsize=(30, 6))
for i in range(n):
ax = plt.subplot(3, n, i + 1)
plt.imshow(x_test[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
ax = plt.subplot(3, n, i + 1 + n)
plt.imshow(x_test_noisy[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
ax = plt.subplot(3, n, i + 1 + 2*n)
plt.imshow(decoded_imgs[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()

以上主要参考:
https://blog.csdn.net/marsjhao/article/details/73480859
想进一步学习可以看下这位公众号博主。。如下:
https://blog.csdn.net/zhq9695/article/details/86558266#5__PSD_72
智能推荐
基于SSM和MySQL的企业人事管理系统的设计与实现_基于ssm的企业人事管理系统的设计与实现参考文献-程序员宅基地
文章浏览阅读484次,点赞2次,收藏2次。管理员进入主界面,软件开始运行,提供用户登录功能,不同的用户登录操作的功 能不同,非管理员用户登录只能查看一些公告信息等,而管理员登录后,可以进行用户 管理丶部门管理、职位管理、员工管理、公告管理等功能。基于其他企业人事管理软件的不足,要求能够制作一个可以方便、快捷的对员工信 息进行添加、修改、删除的操作,为了能够更好的存储职工的信息,可以将职工的信息添 加到 Word 文档,这样,不但便于保存,还可以通过 Word 文档进行打印。员工信息的管理:维护员工的基本信息,用户可以进行员工档案信息的录入及更改,_基于ssm的企业人事管理系统的设计与实现参考文献
【C语言】手撕二叉树
【C语言】手撕二叉树
Postgresql源码(127)投影ExecProject的表达式执行分析
无论是投影还是别的计算,表达式执行的入口和计算逻辑都是统一的,这里已投影为分析表达式执行的流程。
hive启动beeline报错
出现上面的问题执行以下代码。
【Hadoop】-Hive客户端:HiveServer2 & Beeline 与DataGrip & DBeaver[14]
DataGrip是由JetBrains公司推出的数据库管理软件,DataGrip支持几乎所有主流的关系数据库产品,如DB2、Derby、MySQL、Oracle、SQL Server等,也支持几乎所有主流的大数据生态圈SQL软件,并且提供了简单易用的界面,开发者上手几乎不会遇到任何困难。3、连接成功,在里面我们可以看到我们前面章节所创建的表,这样子就可以在里面操作我们的sql语句的。5、连接成功,在里面我们可以看到我们前面章节所创建的表,这样子就可以在里面操作我们的sql语句的。
java lambda无法使用_java – 为什么不允许lambda函数?-程序员宅基地
文章浏览阅读1.2k次。我一直在Vaadin的GUI中工作,有一些来自我的IT主管的课程.这一切都很棒,但是,今天,我遇到过我不能在addListener方法类型中使用lambda表达式.此方法是自定义的,作为使用它的对象.这是实施:public class ResetButtonForTextField extends AbstractExtension {private final List listeners= n..._java: -source 1.5 中不支持 lambda 表达式
随便推点
FRTC8563时钟芯片的主要特性和应用场景
一款实时时钟(RTC)芯片,它采用SOP-8封装,这种封装形式使得芯片具有较小的体积和良好的引脚连接稳定性,便于集成到各种电子设备中。:该芯片采用低功耗技术,使得在待机状态下功耗极低,有助于延长电池寿命,特别适合用于便携式设备或长时间运行的系统。:FRTC8563基于稳定的晶振工作,能够提供准确的时钟和日历信息,包括年、月、日、星期、小时、分钟和秒等。:芯片支持较宽的电压范围,使其能够适应不同设备的电源需求。提供准确的时间戳和日历信息,支持设备的时间同步和事件记录。:在便携式仪器仪表中,由于其低功耗特性,
wetrtc简介
wetrtc简介
单片机基于ST25DV动态标签的无线通信_st25dv能量采集-程序员宅基地
文章浏览阅读651次。利用I2C有线链路,任何NFC智能手机或NFC/RFID HF专业读卡器以及MCU均可以访问存储在这些标签中的数据,并且支持掉电保存。这些标签的集成度和性价比极高,可提供丰富的功能集,适用于各种应用。此外,开发人员可从评估板、软件工具、移动应用和其他资源构成的完整生态系统中受益,从而加快应用开发速度。在物联网产品的开发过程中,物联网设备非接触式向外界提供可变的交换信息非常有必要,比如路由器向手机提供可配置的WiFi信息,巡检点向手机提供动态的传感器数据等等。_st25dv能量采集
自己搭建 Linux 服务器踩坑记录_建立服务器踩过的坑-程序员宅基地
文章浏览阅读149次。前言妈蛋,自己搭建一个Linux服务器居然能遇到这么多坑。特此整理下,方便下次遇到同样的错误时能够回过头来快速定位问题并解决问题Number 1,服务器重启之后,Xshell 连接不上注:在服务器重启之前,我只安装了 jdk ,配置了 /etc/profile 环境变量,我一直以为是这个原因,后面把jdk 配置注释掉也没用正确的方向应该是先查看 ssh 服务有没有启动键入命令systemctl status sshd.service如果你的显示跟红框一样 【dead..._建立服务器踩过的坑
MT4606-VB_MOSFET产品应用与参数解析-程序员宅基地
文章浏览阅读187次。通过控制20Vgs (±V)的门源电压,可以实现开关管的导通和截止,实现对电流的控制和开关状态的转换。MT4606详细参数说明 - 极性 N+P沟道- 额定电压 ±30V- 额定电流 9A (N沟道), -6A (P沟道)- 导通电阻 15mΩ @ 10V (N沟道), 42mΩ @ 10V (P沟道), 19mΩ @ 4.5V (N沟道), 50mΩ @ 4.5V (P沟道)- 门源电压 20Vgs (±V)- 阈值电压 ±1.65Vth (V)- 封装类型 SOP8。_mt4606
达梦启云平台中,部署使用HIVE笔记_达梦sql中hiveing-程序员宅基地
文章浏览阅读637次。启云平台部署hive_达梦sql中hiveing