手头有个python项目,该项目是一个数据库中间件,用于集中处理各个业务系统对Oracle数据库的增删改查操作。
项目采用gevent的WSGISever启动:
application = tornado.wsgi.WSGIApplication([
(r"/healthcheck", HealthCheck)])
...
server = gevent.wsgi.WSGIServer(('', args.port), application, log=None)
server.serve_forever()该项目自我接手以来,一直在找系统性能瓶颈,经过长时间的测试、调查,发现,cx_Oracle的OCI不支持异步,导致gevent在协程处理请求时,如果数据库长时间不返回,系统就会被阻塞,从而使后续请求得不到处理,最终系统崩溃。
关于cx_Oracle的OCI不支持异步,请参考:
https://bitbucket.org/anthony_tuininga/cx_oracle/issues/8/gevent-eventlet-support
IMO, it is impossible with cx_Oracle.
Psycopg2 uses libpq (PostgreSQL client library), which provides asynchronous functions. Psycopg2 supports async I/O calls with the aid of the asynchronous functions. (Well, I have not confirmed it... I'm not a python user.)
On the other hand, cx_Oracle uses OCI(Oracle Call Interface), which doesn't provide asynchronous functions. Strictly speaking it provides an asynchronous function which makes a connection non-blocking. But there is no way to detect the status of the connection: whether it is readable or so. If OCI provided a function which exposed underneath TCP/IP sockets, pipe descriptors (local connections on Unix) or named pipe handles (local connections on Windows) to caller such as cx_Oracle, Gevent/Eventlet might use the sockets/descriptors/handles to support async I/O calls. However OCI doesn't provide such functions as mentioned.
所以为了解决阻塞的问题,我在访问数据库的地方开辟线程去访问数据库,代码如下:
class BaseServices:
def __init__(self, db_pool, wap_db_pool):
self.wap_db_pool = wap_db_pool
self._db_pool = db_pool
self._db_handle_pool = ThreadPool(1000)
self._logger = logging.getLogger('default')
self.db_ops = {}
Logger.debug(self._logger, 'BaseDataQueryService created')
def do_db_operation(self, op_id, conn, c, procedure_name, procedure_params):
self._logger.debug('inside, parent thread is %s ,thread is %s' % (op_id, thread.get_ident()))
try:
p = c.callproc(procedure_name, procedure_params)
self._logger.debug('inside after, parent thread is %s ,thread is %s, p is %s, db_pool_maxsize is %s, db_pool_size is %s'
% (op_id, thread.get_ident(), str(p), conn._pool._maxconnections, conn._pool._connections))
except Exception as ex:
self._logger.error(ex)
msg = traceback.format_exc()
self._logger.error('\n' + 'inside exception, parent thread is %s ,thread is %s'
% (op_id, thread.get_ident()) + ' ' + msg)
self._logger.debug('inside end ,parent thread is %s , thread is %s, thread_pool_maxsize is %s, thread_pool_size is %s'
% (op_id, thread.get_ident(), str(self._db_handle_pool._get_maxsize()),
str(self._db_handle_pool._get_size())))
# self.db_ops.get(op_id).set(p)
return p
def query_force_db(self, data):
"""
强查数据库
:param data: post报文
:return:
"""
...
try:
....
conn, c = None, None
try:
conn = self._db_pool.connection()
c = conn.cursor()
procedure_result_list = []
self._logger.debug('before, thread is %s , thread_pool_maxsize is %s, thread_pool_size is %s'% (thread.get_ident(), str(self._db_handle_pool._get_maxsize()),
str(self._db_handle_pool._get_size())))
self._logger.debug('before, thread is %s, db_pool_maxsize is %s, db_pool_size is %s'% (thread.get_ident(), conn._pool._maxconnections, conn._pool._connections))
# 调用存储过程 参数使用 procedure_name和procedure_params return p
# 改进后采用线程访问数据库
p = self._db_handle_pool.apply(self.do_db_operation, (str(thread.get_ident()),conn,c, procedure_name, procedure_params))
# 改进前直接访问数据库,会阻塞
# p = c.callproc(procedure_name, procedure_params)
...
self._logger.debug('after, p = %s ,thread = %s, thread_pool_maxsize is %s, thread_pool_size is %s'% (p, thread.get_ident(), str(self._db_handle_pool._get_maxsize()),
str(self._db_handle_pool._get_size())))
self._logger.debug('after, thread = %s, db_pool_maxsize is %s, db_pool_size is %s'% (thread.get_ident(), conn._pool._maxconnections, conn._pool._connections))
for out_value in p[len(procedure_in_params):]:
...
except Exception as ex:
self._logger.error(ex)
msg = traceback.format_exc()
self._logger.error('\n' + msg)
...
finally:
if conn is not None:
conn.close()
self._logger.debug('finally, thread = %s, db_pool_maxsize is %s, db_pool_size is %s'
% (thread.get_ident(), conn._pool._maxconnections, conn._pool._connections))
...
except Exception as ex:
self._logger.error(ex)
msg = traceback.format_exc()
self._logger.error('\n' + msg)
...
finally:
pass
return res_model
改进后的代码,解决了阻塞的问题,当一个请求在数据库里长时间不能返回时,别的请求依然能正常被处理。本以为如此就解决了该系统性能不高的问题,结果压测的时候发现并不然,该系统的性能依然不高。
数据库连接池大小是1000:
db_pool = PooledDB(cx_Oracle, threaded=True, user=xx,password=xx,dsn='dsn'
mincached=1, maxcached=1, maxconnections=1000)线程池大小是1000,代码如上述BaseService里所示。
采用siege压测5分钟,并发量是600:
$siege/bin/siege -c 600 -t 5M -f url.txt
压测结果:
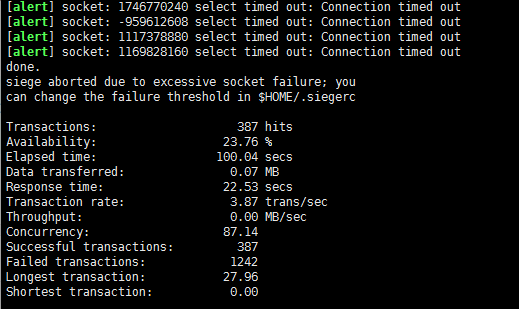
很明显,这个结果很不理想。按理说,数据库连接池1000,线程池1000,每个请求在数据库里的执行时间1秒(实际上,压测的URL最终都是在数据库里sleep了1秒然后返回'success'),那么并发量应该在1000左右时能表现良好,命中率令人满意才对。但是,理想是美好的,现实是骨感的,600的并发量的命中率只有23.76% 。进一步压测,并发量为400时的命中率也只有46.77%。
为了追踪内部运行情况,加了一些跟线程池、数据库连接池相关的log,如上述代码。发现,数据库连接池基本是正常的,1000的连接池,能用到300+ ,而线程池,不对劲,1000的线程池,只用到23,通篇日志文件里,线程池的只能到23,感觉如同到此为止了样。
日志文件里主要有以下问题:
2种错误输出
[2016-09-09 17:50:35,766] DEBUG::(1676 46912773723152)::BaseServices[line:126] - before, thread is 46912773723152
[2016-09-09 17:50:35,766] DEBUG::(1676 46912773723792)::BaseServices[line:34] - inside, parent thread is 46912773723152 ,thread is 46912773723792
[2016-09-09 17:50:40,854] DEBUG::(1676 46912773723152)::BaseServices[line:133] - after, p = None ,thread = 46912773723152
[2016-09-09 17:50:40,854] ERROR::(1676 46912773723152)::BaseServices[line:151] - 'NoneType' object has no attribute '__getitem__'
[2016-09-09 17:50:40,854] ERROR::(1676 46912773723152)::BaseServices[line:153] -
Traceback (most recent call last):
File "/home/was/python_apps/lcy_test/AsyncQueryProject/Services/BaseServices.py", line 134, in query_force_db
for out_value in p[len(procedure_in_params):]:
TypeError: 'NoneType' object has no attribute '__getitem__'
[2016-09-09 17:50:33,476] DEBUG::(1676 46912773633360)::BaseServices[line:126] - before, thread is 46912773633360
[2016-09-09 17:50:36,296] DEBUG::(1676 46912773633360)::BaseServices[line:133] - after, p = None ,thread = 46912773633360
[2016-09-09 17:50:36,296] ERROR::(1676 46912773633360)::BaseServices[line:151] - 'NoneType' object has no attribute '__getitem__'
[2016-09-09 17:50:36,297] ERROR::(1676 46912773633360)::BaseServices[line:153] -
Traceback (most recent call last):
File "/home/was/python_apps/lcy_test/AsyncQueryProject/Services/BaseServices.py", line 134, in query_force_db
for out_value in p[len(procedure_in_params):]:
TypeError: 'NoneType' object has no attribute '__getitem__'这个,主要是数据库返回结果变量p为空导致,至于为啥它会为空,我也没搞明白,分析日志文件,貌似:
1. 数据库没返回结果,导致主线程对空p进行处理;
2. 子线程没有进入,导致主线程“跳过”子线程直接对空p进行处理。
but,为什么会这样呢?有大神能指导一下么
[2016-09-14 15:33:42,970] ERROR::(12505 46912619885904)::BaseServices[line:41] - This operation would block forever
[2016-09-14 15:33:42,971] ERROR::(12505 46912619885904)::BaseServices[line:44] -
inside exception, parent thread is 46912622501712 ,thread is 46912619885904 Traceback (most recent call last):
File "/home/was/python_apps/lcy_test/AsyncQueryProject/Services/BaseServices.py", line 38, in do_db_operation
% (op_id, thread.get_ident(), str(p), conn._pool._maxconnections, conn._pool._connections))
File "/home/was/software/python2.7.8/lib/python2.7/logging/__init__.py", line 1148, in debug
self._log(DEBUG, msg, args, **kwargs)
File "/home/was/software/python2.7.8/lib/python2.7/logging/__init__.py", line 1279, in _log
self.handle(record)
File "/home/was/software/python2.7.8/lib/python2.7/logging/__init__.py", line 1289, in handle
self.callHandlers(record)
File "/home/was/software/python2.7.8/lib/python2.7/logging/__init__.py", line 1329, in callHandlers
hdlr.handle(record)
File "/home/was/software/python2.7.8/lib/python2.7/logging/__init__.py", line 755, in handle
self.acquire()
File "/home/was/software/python2.7.8/lib/python2.7/logging/__init__.py", line 706, in acquire
self.lock.acquire()
File "/home/was/software/python2.7.8/lib/python2.7/threading.py", line 173, in acquire
rc = self.__block.acquire(blocking)
File "_semaphore.pyx", line 112, in gevent._semaphore.Semaphore.acquire (gevent/gevent._semaphore.c:3004)
File "/home/was/software/python2.7.8/lib/python2.7/site-packages/gevent-1.0.1-py2.7-linux-x86_64.egg/gevent/hub.py", line 331, in switch
return greenlet.switch(self)
LoopExit: This operation would block forever我在网上看了很多这个错误的分析,没得到什么有用的启示。我狠郁闷。究竟为什么会block forever,在什么情况下如此,这个异常是不是就是我的系统性能上不去的原因?各位走过路过的大神,谁能指点一下我