Python数据爬取超详细讲解(零基础入门,老年人都看的懂)_python爬取数据-程序员宅基地
技术标签: 爬虫 python 数据分析 大数据 Python
本文已收录至Github,推荐阅读 Java随想录
转载于:https://www.bilibili.com/video/BV12E411A7ZQ?spm_id_from=333.337.search-card.all.click
本文是根据视频教程记录的学习笔记,建议结合视频观看。
先看后赞,养成习惯。
点赞收藏,人生辉煌。

讲解我们的爬虫之前,先概述关于爬虫的简单概念(毕竟是零基础教程)
爬虫
网络爬虫(又被称为网页蜘蛛,网络机器人)就是模拟浏览器发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序。
原则上,只要是浏览器(客户端)能做的事情,爬虫都能够做。
为什么我们要使用爬虫
互联网大数据时代,给予我们的是生活的便利以及海量数据爆炸式的出现在网络中。
过去,我们通过书籍、报纸、电视、广播或许信息,这些信息数量有限,且是经过一定的筛选,信息相对而言比较有效,但是缺点则是信息面太过于狭窄了。不对称的信息传导,以致于我们视野受限,无法了解到更多的信息和知识。
互联网大数据时代,我们突然间,信息获取自由了,我们得到了海量的信息,但是大多数都是无效的垃圾信息。
例如新浪微博,一天产生数亿条的状态更新,而在百度搜索引擎中,随意搜一条——减肥100,000,000条信息。
在如此海量的信息碎片中,我们如何获取对自己有用的信息呢?
答案是筛选!
通过某项技术将相关的内容收集起来,在分析删选才能得到我们真正需要的信息。
这个信息收集分析整合的工作,可应用的范畴非常的广泛,无论是生活服务、出行旅行、金融投资、各类制造业的产品市场需求等等……都能够借助这个技术获取更精准有效的信息加以利用。
网络爬虫技术,虽说有个诡异的名字,让能第一反应是那种软软的蠕动的生物,但它却是一个可以在虚拟世界里,无往不前的利器。
爬虫准备工作
我们平时都说Python爬虫,其实这里可能有个误解,爬虫并不是Python独有的,可以做爬虫的语言有很多例如:PHP,JAVA,C#,C++,Python,选择Python做爬虫是因为Python相对来说比较简单,而且功能比较齐全。
首先我们需要下载python,我下载的是官方最新的版本 3.8.3
其次我们需要一个运行Python的环境,我用的是pychram

也可以从官方下载,
我们还需要一些库来支持爬虫的运行(有些库Python可能自带了)
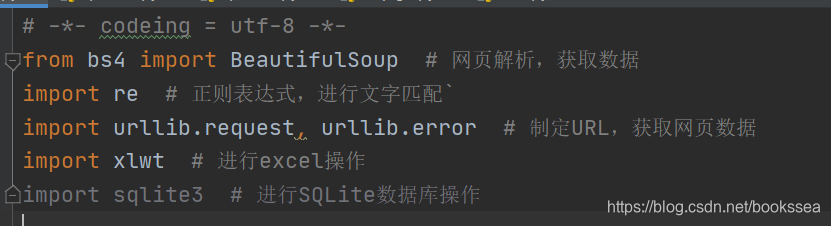
差不多就是这几个库了,良心的我已经在后面写好注释了

(爬虫运行过程中,不一定就只需要上面几个库,看你爬虫的一个具体写法了,反正需要库的话我们可以直接在setting里面安装)
爬虫项目讲解
我们的爬取的内容是:电影详情链接,图片链接,影片中文名,影片外国名,评分,评价数,概况,相关信息。
代码分析
先把代码发放上来,然后我根据代码逐步解析
# -*- codeing = utf-8 -*-
from bs4 import BeautifulSoup # 网页解析,获取数据
import re # 正则表达式,进行文字匹配`
import urllib.request, urllib.error # 制定URL,获取网页数据
import xlwt # 进行excel操作
#import sqlite3 # 进行SQLite数据库操作
findLink = re.compile(r'<a href="(.*?)">') # 创建正则表达式对象,标售规则 影片详情链接的规则
findImgSrc = re.compile(r'<img.*src="(.*?)"', re.S)
findTitle = re.compile(r'<span class="title">(.*)</span>')
findRating = re.compile(r'<span class="rating_num" property="v:average">(.*)</span>')
findJudge = re.compile(r'<span>(\d*)人评价</span>')
findInq = re.compile(r'<span class="inq">(.*)</span>')
findBd = re.compile(r'<p class="">(.*?)</p>', re.S)
def main():
baseurl = "https://movie.douban.com/top250?start=" #要爬取的网页链接
# 1.爬取网页
datalist = getData(baseurl)
savepath = "豆瓣电影Top250.xls" #当前目录新建XLS,存储进去
# dbpath = "movie.db" #当前目录新建数据库,存储进去
# 3.保存数据
saveData(datalist,savepath) #2种存储方式可以只选择一种
# saveData2DB(datalist,dbpath)
# 爬取网页
def getData(baseurl):
datalist = [] #用来存储爬取的网页信息
for i in range(0, 10): # 调用获取页面信息的函数,10次
url = baseurl + str(i * 25)
html = askURL(url) # 保存获取到的网页源码
# 2.逐一解析数据
soup = BeautifulSoup(html, "html.parser")
for item in soup.find_all('div', class_="item"): # 查找符合要求的字符串
data = [] # 保存一部电影所有信息
item = str(item)
link = re.findall(findLink, item)[0] # 通过正则表达式查找
data.append(link)
imgSrc = re.findall(findImgSrc, item)[0]
data.append(imgSrc)
titles = re.findall(findTitle, item)
if (len(titles) == 2):
ctitle = titles[0]
data.append(ctitle)
otitle = titles[1].replace("/", "") #消除转义字符
data.append(otitle)
else:
data.append(titles[0])
data.append(' ')
rating = re.findall(findRating, item)[0]
data.append(rating)
judgeNum = re.findall(findJudge, item)[0]
data.append(judgeNum)
inq = re.findall(findInq, item)
if len(inq) != 0:
inq = inq[0].replace("。", "")
data.append(inq)
else:
data.append(" ")
bd = re.findall(findBd, item)[0]
bd = re.sub('<br(\s+)?/>(\s+)?', "", bd)
bd = re.sub('/', "", bd)
data.append(bd.strip())
datalist.append(data)
return datalist
# 得到指定一个URL的网页内容
def askURL(url):
head = {
# 模拟浏览器头部信息,向豆瓣服务器发送消息
"User-Agent": "Mozilla / 5.0(Windows NT 10.0; Win64; x64) AppleWebKit / 537.36(KHTML, like Gecko) Chrome / 80.0.3987.122 Safari / 537.36"
}
# 用户代理,表示告诉豆瓣服务器,我们是什么类型的机器、浏览器(本质上是告诉浏览器,我们可以接收什么水平的文件内容)
request = urllib.request.Request(url, headers=head)
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html
# 保存数据到表格
def saveData(datalist,savepath):
print("save.......")
book = xlwt.Workbook(encoding="utf-8",style_compression=0) #创建workbook对象
sheet = book.add_sheet('豆瓣电影Top250', cell_overwrite_ok=True) #创建工作表
col = ("电影详情链接","图片链接","影片中文名","影片外国名","评分","评价数","概况","相关信息")
for i in range(0,8):
sheet.write(0,i,col[i]) #列名
for i in range(0,250):
# print("第%d条" %(i+1)) #输出语句,用来测试
data = datalist[i]
for j in range(0,8):
sheet.write(i+1,j,data[j]) #数据
book.save(savepath) #保存
# def saveData2DB(datalist,dbpath):
# init_db(dbpath)
# conn = sqlite3.connect(dbpath)
# cur = conn.cursor()
# for data in datalist:
# for index in range(len(data)):
# if index == 4 or index == 5:
# continue
# data[index] = '"'+data[index]+'"'
# sql = '''
# insert into movie250(
# info_link,pic_link,cname,ename,score,rated,instroduction,info)
# values (%s)'''%",".join(data)
# # print(sql) #输出查询语句,用来测试
# cur.execute(sql)
# conn.commit()
# cur.close
# conn.close()
# def init_db(dbpath):
# sql = '''
# create table movie250(
# id integer primary key autoincrement,
# info_link text,
# pic_link text,
# cname varchar,
# ename varchar ,
# score numeric,
# rated numeric,
# instroduction text,
# info text
# )
#
#
# ''' #创建数据表
# conn = sqlite3.connect(dbpath)
# cursor = conn.cursor()
# cursor.execute(sql)
# conn.commit()
# conn.close()
# 保存数据到数据库
if __name__ == "__main__": # 当程序执行时
# 调用函数
main()
# init_db("movietest.db")
print("爬取完毕!")
下面我根据代码,从下到下给大家讲解分析一遍

-- codeing = utf-8 --,开头的这个是设置编码为utf-8 ,写在开头,防止乱码。
然后下面 import就是导入一些库,做做准备工作,(sqlite3这库我并没有用到所以我注释起来了)。
下面一些find开头的是正则表达式,是用来我们筛选信息的。
(正则表达式用到 re 库,也可以不用正则表达式,不是必须的。)
大体流程分三步走:
1. 爬取网页
2.逐一解析数据
3. 保存网页
先分析流程1,爬取网页,baseurl 就是我们要爬虫的网页网址,往下走,调用了 getData(baseurl) ,
我们来看 getData方法
for i in range(0, 10): # 调用获取页面信息的函数,10次
url = baseurl + str(i * 25)
这段大家可能看不懂,其实是这样的:
因为电影评分Top250,每个页面只显示25个,所以我们需要访问页面10次,25*10=250。
baseurl = "https://movie.douban.com/top250?start="
我们只要在baseurl后面加上数字就会跳到相应页面,比如i=1时
https://movie.douban.com/top250?start=25
我放上超链接,大家可以点击看看会跳到哪个页面,毕竟实践出真知。

然后又调用了askURL来请求网页,这个方法是请求网页的主体方法,
怕大家翻页麻烦,我再把代码复制一遍,让大家有个直观感受
def askURL(url):
head = {
# 模拟浏览器头部信息,向豆瓣服务器发送消息
"User-Agent": "Mozilla / 5.0(Windows NT 10.0; Win64; x64) AppleWebKit / 537.36(KHTML, like Gecko) Chrome / 80.0.3987.122 Safari / 537.36"
}
# 用户代理,表示告诉豆瓣服务器,我们是什么类型的机器、浏览器(本质上是告诉浏览器,我们可以接收什么水平的文件内容)
request = urllib.request.Request(url, headers=head)
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html
这个askURL就是用来向网页发送请求用的,那么这里就有老铁问了,为什么这里要写个head呢?

这是因为我们要是不写的话,访问某些网站的时候会被认出来爬虫,显示错误,错误代码
418
这是一个梗大家可以百度下,
418 I’m a teapot
The HTTP 418 I’m a teapot client error response code indicates that
the server refuses to brew coffee because it is a teapot. This error
is a reference to Hyper Text Coffee Pot Control Protocol which was an
April Fools’ joke in 1998.
我是一个茶壶

所以我们需要 “装” ,装成我们就是一个浏览器,这样就不会被认出来,
伪装一个身份。

来,我们继续往下走,
html = response.read().decode("utf-8")
这段就是我们读取网页的内容,设置编码为utf-8,目的就是为了防止乱码。
访问成功后,来到了第二个流程:
2.逐一解析数据
解析数据这里我们用到了 BeautifulSoup(靓汤) 这个库,这个库是几乎是做爬虫必备的库,无论你是什么写法。
下面就开始查找符合我们要求的数据,用BeautifulSoup的方法以及 re 库的
正则表达式去匹配,
findLink = re.compile(r'<a href="(.*?)">') # 创建正则表达式对象,标售规则 影片详情链接的规则
findImgSrc = re.compile(r'<img.*src="(.*?)"', re.S)
findTitle = re.compile(r'<span class="title">(.*)</span>')
findRating = re.compile(r'<span class="rating_num" property="v:average">(.*)</span>')
findJudge = re.compile(r'<span>(\d*)人评价</span>')
findInq = re.compile(r'<span class="inq">(.*)</span>')
findBd = re.compile(r'<p class="">(.*?)</p>', re.S)
匹配到符合我们要求的数据,然后存进 dataList , 所以 dataList 里就存放着我们需要的数据了。
最后一个流程:
3.保存数据
# 3.保存数据
saveData(datalist,savepath) #2种存储方式可以只选择一种
# saveData2DB(datalist,dbpath)
保存数据可以选择保存到 xls 表, 需要(xlwt库支持)
也可以选择保存数据到 sqlite数据库, 需要(sqlite3库支持)
这里我选择保存到 xls 表 ,这也是为什么我注释了一大堆代码,注释的部分就是保存到 sqlite 数据库的代码,二者选一就行
保存到 xls 的主体方法是 saveData (下面的saveData2DB方法是保存到sqlite数据库):
def saveData(datalist,savepath):
print("save.......")
book = xlwt.Workbook(encoding="utf-8",style_compression=0) #创建workbook对象
sheet = book.add_sheet('豆瓣电影Top250', cell_overwrite_ok=True) #创建工作表
col = ("电影详情链接","图片链接","影片中文名","影片外国名","评分","评价数","概况","相关信息")
for i in range(0,8):
sheet.write(0,i,col[i]) #列名
for i in range(0,250):
# print("第%d条" %(i+1)) #输出语句,用来测试
data = datalist[i]
for j in range(0,8):
sheet.write(i+1,j,data[j]) #数据
book.save(savepath) #保存
创建工作表,创列(会在当前目录下创建),
sheet = book.add_sheet('豆瓣电影Top250', cell_overwrite_ok=True) #创建工作表
col = ("电影详情链接","图片链接","影片中文名","影片外国名","评分","评价数","概况","相关信息")
然后把 dataList里的数据一条条存进去就行。
最后运作成功后,会在左侧生成这么一个文件

打开之后看看是不是我们想要的结果
成了,成了!

如果我们需要以数据库方式存储,可以先生成 xls 文件,再把 xls 文件导入数据库中,就可以啦
本篇文章讲解到这里啦,我感觉我讲的还算细致吧,爬虫我也是最近才可以学,对这个比较有兴趣,我肯定有讲的不好的地方,欢迎各位大佬来指正我 。
我也在不断的学习中,学到新东西第一时间会跟大家分享
大家可以动动小手,点波关注不迷路。
如果关于本篇文章有不懂的地方,欢迎大家下面留言,我知道的都会给大家一 一解答。
最后给大家放波福利,博主最近在搞阿里云推广,
活动折扣价:全网最低价87元/年,261元/3年,比学生9.9每月还便宜(只阿里云新用户可用)
新用户可以入手试试,有一台属于自己的服务器,前期用来部署和学习都很方便
阿里云 【点击购买】

白嫖不好,创作不易。各位的点赞就是我创作的最大动力,如果我有哪里写的不对,欢迎评论区留言进行指正。
老铁,如果有收获,请点个免费的赞鼓励一下博主呗

智能推荐
Linux环境 docker启动redis命令_linux docker 重启 redis-程序员宅基地
文章浏览阅读1.1k次。docker启动redis命令_linux docker 重启 redis
【总结】插头DP-bzoj1210/2310/2331/2595_dp插头模型-程序员宅基地
文章浏览阅读325次。插头DP小结_dp插头模型
关于测试工作效率低的一些思考和改进方法_测试人员不足与改进-程序员宅基地
文章浏览阅读3.5k次。关于测试工作效率低的一些思考和改进方法引子 汇总统计了一下项目组近期测试项目实际工作量与基线工作量的对比,发现一个严重问题。就是工作效率特别低下。下面简单列举一下几个项目预期工作量和实际工作量以及时间耗费严重的地方、项目简要背景。 1、B版本测试。版本预期工作量15人天,实际耗费工作量在30人天。更为严重的是测试人员并没有因为测试周期延长和工作量投入加大而测试的更轻松,反而是测试期..._测试人员不足与改进
级联样式表_级联样式表| 第三部分-程序员宅基地
文章浏览阅读173次。级联样式表 CSS-难以成熟 (CSS — Difficult to maturation)Unlike software, the CSS specifications are developed by successive versions, which would allow a browser to refer to a particular version. CSS was devel..._级联样式表是哪年产生的
sql server学习笔记——批处理语句、存储过程_sql的批处理-程序员宅基地
文章浏览阅读1.7k次。目录批处理语句1、批处理语句简介示例一:示例二:存储过程一、什么是存储过程1、存储过程的简介2、存储过程包含的内容3、存储过程的优点4、存储过程的分类系统存储过程:用户定义存储过程5、常用的系统储存过程(1)一般常用的存储过程(2)xp_cmdshell二、创建存储过程1、定义存储过程的语法2、不带参数的存储过程3、带参数..._sql的批处理
css代码的定位及浮动
上次,我们解除了css的内外边距、鼠标悬停及其练习。现在我们学习css元素练习和定位。
随便推点
集通字库芯片GT20L16S1Y 读取字体数据-程序员宅基地
文章浏览阅读3.5k次,点赞12次,收藏46次。/** * @brief * @note * @param None * @retval None * @author PWH * @date 2021/4 */int32_t GT20L16S1Y_Get_Addr_Ascii_7x8(char *asciiCode){ if (*asciiCode >= ' ' && *asciiCode <= '~') { return 0x66C0 + (*asciiCode - ._gt20l16s1y
关于ETH的NONCE_ethers获取交易nonce-程序员宅基地
文章浏览阅读1.3k次。最近我的ETH交易里面出现了一种情况,交易虽然返回了hash,但是却迟迟未被确认,连在区块浏览器上也找不到对应的pending交易, 但是通过节点api调用hash获取记忆记录却有数据返回。这种情况问了人也查了资料,最后得出的结果是,交易可能在矿池,但是却没有被矿工打包。于是想到了imtoken钱包的加速交易内容。说到加速交易,不得不说的就是ETH交易内重要的一个内容, nonce。nonc..._ethers获取交易nonce
Flutter Widget显示隐藏_flutter判断控制是否被遮住-程序员宅基地
文章浏览阅读7.6k次。在Android中我们可以用visibility来控制控件的显示和隐藏,那在Flutter中我们怎么控制呢?其实,在Flutter中控制Widget显示和隐藏有3中方法:不过3种方法的核心思想都是根据变量的值去判断的,所以先定义一个变量:bool visible = true;变量的值可以在事件中去控制,比如: onPressed: () { setS..._flutter判断控制是否被遮住
求助生物源排放模型MEGAN_megan v2.04-程序员宅基地
文章浏览阅读673次。有没有师兄师姐有meganv2.04以上的版本小弟只有低版本的 需要高版本运行一下有偿!_megan v2.04
java/jsp/ssm网络文学网站【2024年毕设】-程序员宅基地
文章浏览阅读32次。springboot基于springboot的小型超市库存管理系统。springboot基于SpringBoot的校园失物招领系统。springboot基于springboot的残障人士社交平台。springboot基于springboot的酒店管理系统。springboot基于springboot的电商购物系统。springboot基于微信小程序的Sunmoon口红商城。springboot基于云平台的便民物流速递信息管理系统。springboot基于微服务的固定资产管理系统。
还在用PPT做组织架构图?公司都在用的架构图软件是什么?_书本里印刷的结构图是用什么软件做的-程序员宅基地
文章浏览阅读3.1k次。还在用PPT、Word和Excel画企业组织结构图吗?对于人力资源的同事来说,画组织结构图是一键非常头疼的事情,尤其是对于一些大公司和人员变动较大的公司来说,需要经常更换组织结构图,每次变动都要耗费大量的时间和精力去重新绘图。其实绘制织结构图很简单,之所以难是因为没有找对工具和方法!今天小编就教你如何用亿图图示轻松绘制一个既美观又专业的组织结构图!下图是一个简单的组织结构图例子,小编就以此为例,详细讲解一下好看清晰、实用的公司组织结构图是怎么画出来的。1、新建组织结构图2、创建组织结构_书本里印刷的结构图是用什么软件做的