【计算机网络-网络层】IPv4 和 IPv6_mtu为800,总长度为1580,怎么分片-程序员宅基地
技术标签: NAT # 计算机网络 IP CIDR 计算机网络
文章目录
第一部分:IPv4(IP 协议版本 4)
1 IP 数据报
1.1 IP 数据报格式
IP 数据报的格式如下:
| 首部(发送在前) | 数据部分 |
|---|---|
| 固定部分(20B)+ 可变部分 | 数据信息 |
IP 数据报首部的格式如下:

IP 首部的字段含义如下:
- 版本(4b):IP 协议版本,广泛使用的版本号为 4。
- 首部长度(4b,单位 4B):可表示的最小十进制为 5,最大十进制数为 15,以 4B 为单位,最大值为 60B(15 x 4B),用于指示首部的长度。
| 首部长度字段 | 首部长度 |
|---|---|
| 5 | 20B |
| 6 | 24B |
| 7 | 28B |
| … | … |
| 14 | 56B |
| 15 | 60B |
- 区分服务(DS)(8b):用来获得更好的服务,只有在使用区分服务时才起作用。
- 总长度(16b,单位 1B):首部和数据之和的长度,单位为字节。数据报的最大长度为 216-1 = 65535B,但是一个数据报的长度不能超过以太网帧的最大传送单元(MTU = 1500B),所以还需把数据报分片。
- 标识(16b):一个计数器,每产生一个数据报就加 1,但并不是序号,因为 IP 是无连接服务。
- 标志(3b):只有低两位有意义。
| 0/1 | 无意义(MSB) | DF(Don’t Fragment) | MF(More Fragment)(LSB) |
|---|---|---|---|
| 0 | - | 不能分片 | 若干数据片中的最后一个 |
| 1 | - | 可以分片 | 后面还有数据片 |
- 片偏移(13b,单位 8B):某数据报片相对于数据字段的终点,以 8 个字节为偏移单位。除最后一个数据报片外,其他每个分片的长度一定是 8 字节的整数倍。
- 生存时间(TTL)(8b):标识该数据报在网络中的寿命。路由器在转发数据报前,TTL 减 1。若 TTL 为 0,则该分组丢弃。注意,TTL 不是秒数,而是跳数,意义是数据报能在互联网最多可经过多少个路由器。
- 协议(8b):指出该数据报携带的数据使用何种协议。
| 协议名 | ICMP | TCP | UDP |
|---|---|---|---|
| 协议字段值 | 1 | 6 | 17 |
- 首部校验和(16b):只校验首部,不校验数据部分。
- 源地址(32b):发送 IP 数据报的主机的 IP 地址。
- 目的地址(32b):接收 IP 数据报的主机的 IP 地址。
- 可选字段(0~40B):用来支持排错、测量以及安全等措施,内容丰富。
- 填充:全 0,把首部补充为 4B 的整数倍。
1.2 相关例题
【例 1】原始数据报的总长度为 4000B(首部 20B,数据部分 3980B),标识号为 12345,需要转发到一条 MTU = 1500B 的以太网链路上,则 IP 分片为:
| 数据片报 | 位于原始数据报数据部分的位置 | 数据部分长度 | 总长度 | 标识 | MF | DF | 片偏移 |
|---|---|---|---|---|---|---|---|
| 数据报片 1 | 0B ~ 1479B | 1500B - 20B = 1480B | 1500B | 12345 | 1 | 0 | 0 |
| 数据报片 2 | 1480B ~ 2959B | 2960B - 1480B = 1480B | 1500B | 12345 | 1 | 0 | 1480 / 8 = 185 |
| 数据报片 3 | 2960B ~ 3980B | 3980B - 2960B = 1020B | 1040B | 12345 | 0 | 0 | 2960 / 8 = 370 |
【例 2】原始数据报的总长度为 3820B(首部 20B,数据部分 3800B),标识号为 777,需要转发到一条 MTU = 1420B 的链路上,则 IP 分片为:
| 数据片报 | 位于原始数据报数据部分的位置 | 数据部分长度 | 总长度 | 标识 | MF | DF | 片偏移 |
|---|---|---|---|---|---|---|---|
| 数据报片 1 | 0B ~ 1399B | 1420B - 20B = 1400B | 1420B | 777 | 1 | 0 | 0 |
| 数据报片 2 | 1400B ~ 2799B | 2800B - 1400B = 1400B | 1420B | 777 | 1 | 0 | 1400 / 8 = 175 |
| 数据报片 3 | 2800B ~ 3800B | 3800B - 2800B = 1000B | 1020B | 777 | 0 | 0 | 2800 / 8 = 350 |
【例 3】若路由器向 MTU = 800B 的链路转发一个总长度为 1580B 的 IP 数据报(首部长度为 20B)时,进行了分片,且每个分片尽可能大,则第 2 个分片的总长度字段和 MF 标志位的值分别是( )
A. 796, 0
B. 796, 1
C. 800, 0
D. 800, 1
【解】数据部分大小 = 1580B-20B = 1560B,则每个分片的情况:
| 分片 | 首部 | 数据部分 | MF |
|---|---|---|---|
| 1 | 20B | 780B | 1 |
| 2 | 20B | 780B | 0 |
但是!数据部分的长度必须能被 8 整除,780 不能被 8 整除,所以要将 780 改成最大能被 8 整除的数即 776!
| 分片 | 首部 | 数据部分 | MF |
|---|---|---|---|
| 1 | 20B | 776B | 1 |
| 2 | 20B | 776B | 1 |
| 3 | 20B | 8B | 0 |
答案选 B。
2 分类编址(两级结构,网络号定长)
2.1 IP 地址的表示方法
IP 地址指明了连接到某个网络上的一个主机或路由器。
- IP 地址的格式:
IP 地址 ::= {<网络号>, <主机号>} - 点分十进制:每隔 8 位插入一个“.”,把 8 位二进制数转换为十进制数。
【例】
128.14.35.72在计算机中表示为10000000.00001110.00100011.00000111。
2.2 IP 分类编址
- A 类(网络号 1~126,单播地址):
| 0b~7b | 8b~32b |
|---|---|
| 0 网络号 | 主机号 |
- B 类(网络号 128~191,单播地址):
| 0b~15b | 16b~32b |
|---|---|
| 10 网络号 | 主机号 |
- C 类(网络号 192~223,单播地址):
| 0b~23b | 24b~32b |
|---|---|
| 110 网络号 | 主机号 |
- D 类(网络号 224~339,多播地址):
| 0b~32b |
|---|
| 1110 多播地址 |
- E 类(网络号 240~255):
| 0b~32b |
|---|
| 1111 保留为今后使用 |
2.3 IP 地址的特殊用途
(需记忆)有些 IP 地址用作特殊用途,不用做 IP 地址(-1 表示所有位上都是 1):
| 网络号 | 主机号 | 作为源地址 | 作为目的地址 | 例子 | 用途 |
|---|---|---|---|---|---|
| 0 | 0 | √ | x | 0.0.0.0 | 本网络上的本主机 |
| -1 | -1 | x | √ | 255.255.255.255 | 只在本网络上进行广播 |
| net-id | -1 | x | √ | 202.98.174.255 | 对网络号为 net-id 的所有主机进行广播 |
| 0 | host-id | √ | x | 0.0.0.250 | 在本网络上主机号为 host-id 的主机 |
| 127 | 非 0 且非 -1 | √ | √ | 127.0.0.1 | 用于本地软件环回测试 |
(需记忆)A 类、B 类、C 类地址的使用范围:
| 网络类别 | 最大可用网络数 | 每个网络中最大可用主机数 | 可用的网络号 |
|---|---|---|---|
| A | 27-2(减去 0 和 -1 的情况) | 224-2(减去 0 和 -1 的情况) | 1 ~ 126 |
| B | 214 | 216-2(减去 0 和 -1 的情况) | 128.0 ~ 191.255 |
| C | 221 | 28-2(减去 0 和 -1 的情况) | 192.0.0 ~ 223.255.255 |
3 无分类编址 CIDR(两级结构,网络前缀不定长)
3.1 网络前缀和地址块
- CIDR 地址的格式:
IP 地址 ::= {<网络前缀>, <主机号>} - CIDR 记法(斜线记法):
IP 地址/网络前缀所占位数 - CIDR 地址块:把网络前缀都相同的所有连续 IP 地址组成一个 CIDR 地址块。
- 网络前缀越短的地址块所包含的地址数越多。
【例】
128.14.35.72/20,前 20 位是网络前缀:1000 0000. 0000 1110. 0010 0011. 0000 0111该地址块可表示为:
1000 0000. 0000 1110. 0010*或128.14.32/20若不需要指明网络地址时,可表示为:
/20地址块该地址块的最小地址:
1000 0000. 0000 1110. 0010 0000. 0000 0000,即128.14.32.0该地址块的最大地址:
1000 0000. 0000 1110. 0010 1111. 1111 1111,即128.14.47.255该地址块能分配的最大可用主机数 = 212-2
- 特殊用途:
| 网络前缀 | 记法 | 用途 | 说明 |
|---|---|---|---|
| 32b | a.b.c.d/32 | 没有主机号,用于主机路由 | 对特定目的主机的 IP 地址专门指明一个路由,方便管理人员控制和测试网络 |
| 31b | a.b.c.d/31 | 只有两个主机号 0 和 1,用于点对点链路 | |
| 0b | a.b.c.d/0 | 用于默认路由 | 不管分组的目的地址在哪里,都由指定的路由器 R 来处理 |
3.2 地址掩码
- 地址掩码:由一连串的 1 和一连串的 0 组成,1 的个数即为网络前缀的长度。
- 计算得到网络地址:把二进制的 IP 地址和地址掩码进行按位与运算,即可得到网络地址。
- A 类、B 类、C 类地址的地址掩码:
| 网络类别 | 地址掩码 |
|---|---|
| A 类 | 255.0.0.0 |
| B 类 | 255.255.0.0 |
| C 类 | 255.255.255.0 |
- 地址掩码中的二进制和十进制转换:
| 二进制 | 十进制 |
|---|---|
| 1000 0000 | 128 |
| 1100 0000 | 192 |
| 1110 0000 | 224 |
| 1111 0000 | 240 |
| 1111 1000 | 248 |
| 1111 1100 | 252 |
| 1111 1110 | 254 |
| 1111 1111 | 255 |
【例】
128.14.35.72/20,则/20地址块的子网掩码:1111 1111. 1111 1111. 1111 0000. 0000 0000与
128.14.35.72进行按位与运算,得到网络前缀(网络地址):
| 十进制 IP 地址 | 128 | 14 | 35 | 72 |
|---|---|---|---|---|
| 二进制 IP 地址 | 1000 0000 | 0000 1110 | 0010 0011 | 0000 0111 |
| 二进制子网掩码 | 1111 1111 | 1111 1111 | 1111 0000 | 0000 0000 |
| 按位与运算结果 | 1000 0000 | 0000 1110 | 0010 0000 | 0000 0000 |
| 十进制网络地址 | 128 | 14 | 32 | 0 |
3.3 构造超网和路由聚合
- 构造超网:CIDR 地址块包含了多个 C 类地址,因此 CIDR 编址又称为构成超网。
- 路由聚合:大的 CIDR 地址块中包含很多较小的地址块,我们可以用较大的 CIDR 地址块来代替许多较小的地址块。
- 路由聚合的方法:找共同前缀。
- 注意:地址块的数字越小,地址块越大。比如地址块
/27比地址块/30大。
【例】某路由表中有转发接口相同的 4 条路由表项,其目的网络地址分别为 35.230.32.0/21, 35.230.40.0/21, 35.230.48.0/21 和 35.230.56.0/21,将该 4 条路由聚合后的目的网络地址为( )
A. 35.230.0.0/19
B. 35.230.0.0/20
C. 35.230.32.0/19
D. 35.230.32.0/20
【解】先将四个地址化为二进制,再找出公共前缀,即可得知选 C,如下表所示。
| 地址 | 8b | 8b | 8b | 8b |
|---|---|---|---|---|
| 地址 1 | 35 | 230 | 0010 0000 | 0 |
| 地址 2 | 35 | 230 | 0010 1000 | 0 |
| 地址 3 | 35 | 230 | 0011 0000 | 0 |
| 地址 4 | 35 | 230 | 0011 1000 | 0 |
4 划分子网编址(三级结构,网络号定长)
4.1 子网掩码
- 三级 IP 地址格式:
IP 地址 ::= {<网络号>, <子网号>, <主机号>} - 子网掩码:由一连串的 1 和一连串的 0 组成,1 的个数即为网络号和子网号的长度。
- 计算得到网络地址:把二进制的 IP 地址和子网掩码进行按位与运算,即可得到网络地址。
【注】子网掩码和地址掩码其实是同一个概念,只不过指示的内容不同。
4.2 定长子网掩码(FLSM)划分子网
- 定长子网掩码划分子网:所划分出的每一个子网都使用同一个子网掩码。
- 特点:每个子网所分配的IP地址数量相同,容易造成地址资源的浪费。
例 1:假设申请到的 C 类网络为 218.75.230.0
【例 1】假设申请到的 C 类网络为218.75.230.0,使用定长的子网掩码划分子网来满足需求:网络 1 需要 IP 地址数量为 9,网络 2 需要 IP 地址数量为 28,网络 3 需要 IP 地址数量为 15,网络 4 需要 IP 地址数量为 13,网络 5 需要 IP 地址数量为 4。
【解】因为有 5 个子网,因此可以从主机号借来 3 个比特作为子网号使用,则子网掩码为:11111111.11111111.11111111.1110000 --> 255.255.255.224
该 C 类网的格式如下表所示,子网号一共 3 个比特,可划分 8 个子网;主机号一共 5 个比特,说明每个子网可供 32 个主机使用:
| 网络号 | 子网号 | 主机号 |
|---|---|---|
| 218.75.230. | 000 | 00000 |
| 218.75.230. | 000 | 00001 |
| … | … | … |
| 218.75.230. | 000 | 11110 |
| 218.75.230. | 000 | 11111 |
| 218.75.230. | 001 | 00000 |
| … | … | … |
| 218.75.230. | 111 | 11110 |
| 218.75.230. | 111 | 11111 |
所以一共划分为 8 个子网,可供上述 5 个子网选择使用:
| 子网 | 网络地址 | 该子网的可分配地址 | 广播地址 |
|---|---|---|---|
| 1 | 218.75.230.0 | 218.75.230.1 ~ 218.75.230.30 | 218.75.230.31 |
| 2 | 218.75.230.32 | 218.75.230.33 ~ 218.75.230.62 | 218.75.230.63 |
| 3 | 218.75.230.64 | 218.75.230.65 ~ 218.75.230.94 | 218.75.230.95 |
| 4 | 218.75.230.96 | 218.75.230.97 ~ 218.75.230.126 | 218.75.230.127 |
| 5 | 218.75.230.128 | 218.75.230.129 ~ 218.75.230.158 | 218.75.230.159 |
| 6 | 218.75.230.160 | 218.75.230.161 ~ 218.75.230.190 | 218.75.230.191 |
| 7 | 218.75.230.192 | 218.75.230.193 ~ 218.75.230.222 | 218.75.230.223 |
| 8 | 218.75.230.224 | 218.75.230.225 ~ 218.75.230.254 | 218.75.230.255 |
例 2:假设地址块为 192.168.252.0/24
【例 2】假设地址块为 192.168.252.0/24,使用定长的子网掩码划分子网来满足需求:网络 1 需要 IP 地址数量为 63,网络 2 需要 IP 地址数量为 23,网络 3 需要 IP 地址数量为 13,网络 4 需要 IP 地址数量为 4。
【解】因为有 4 个子网,因此可以从主机号借来 2 个比特作为子网号使用,则子网掩码为:11111111.11111111.11111111.11000000 --> 255.255.255.192
该地址块的格式如下表所示,子网号一共 2 个比特,可划分 4 个子网;主机号一共 6 个比特,说明每个子网可供 64 个主机使用:
| 网络号 | 子网号 | 主机号 |
|---|---|---|
| 218.75.230. | 00 | 000000 |
| 218.75.230. | 00 | 000001 |
| … | … | … |
| 218.75.230. | 00 | 111110 |
| 218.75.230. | 00 | 111111 |
| 218.75.230. | 01 | 000000 |
| … | … | … |
| 218.75.230. | 11 | 111110 |
| 218.75.230. | 11 | 111111 |
所以一共划分为 4 个子网,可供上述 4 个子网选择使用:
| 子网 | 网络地址 | 该子网的可分配地址 | 广播地址 |
|---|---|---|---|
| 1 | 218.75.230.0 | 218.75.230.1 ~ 218.75.230.62 | 218.75.230.63 |
| 2 | 218.75.230.64 | 218.75.230.65 ~ 218.75.230.126 | 218.75.230.127 |
| 3 | 218.75.230.128 | 218.75.230.129 ~ 218.75.230.190 | 218.75.230.191 |
| 4 | 218.75.230.192 | 218.75.230.193 ~ 218.75.230.254 | 218.75.230.255 |
4.3 变长子网掩码(VLSM)划分子网
- 变长子网掩码划分子网:所划分出的每一个子网可以使用不同的子网掩码。
- 特点:每个子网所分配的IP地址数量可以不同,尽可能减少对地址资源的浪费。
- 在地址块中选取子块的原则:每个子块的起点位置不能随便选取,只能选取主机号部分是块大小整数倍的地址作为起点。建议先为大的子块选取。
例 1:假设申请到的地址块为 218.75.230.0/24
【例 1】假设申请到的地址块为218.75.230.0/24,使用变长的子网掩码划分子网来满足需求:网络 1 需要 IP 地址数量为 9,网络 2 需要 IP 地址数量为 28,网络 3 需要 IP 地址数量为 15,网络 4 需要 IP 地址数量为 13,网络 5 需要 IP 地址数量为 4。
【解】各网络的情况如下表所示:
| 网络序号 | 需要 IP 地址数量 | 主机号位数 | 网络前缀位数 | 地址块 | 可使用的地址数量 |
|---|---|---|---|---|---|
| 1 | 9 | 4 (24=16) | 32-4=28 | /28 | 16 |
| 2 | 28 | 5 (25=32) | 32-5=27 | /27 | 32 |
| 3 | 15 | 4 (24=16) | 32-4=28 | /28 | 16 |
| 4 | 13 | 4 (24=16) | 32-4=28 | /28 | 16 |
| 5 | 4 | 2 (22=4) | 32-2=30 | /30 | 4 |
从地址块 218.75.230.0/24 中取出 5 个地址块(/30,/28,/28,/28,/27):
| IP 地址 | 用途 |
|---|---|
| 218.75.230.0 ~ 218.75.230.31 | 供网络 2 使用,拥有 32 个地址,主机号为 0 |
| 218.75.230.32 ~ 218.75.230.47 | 供网络 1 使用,拥有 16 个地址,主机号为 32 |
| 218.75.230.48 ~ 218.75.230.63 | 供网络 3 使用,拥有 16 个地址,主机号为 48 |
| 218.75.230.64 ~ 218.75.230.79 | 供网络 4 使用,拥有 16 个地址,主机号为 64 |
| 218.75.230.80 ~ 218.75.230.83 | 供网络 5 使用,拥有 4 个地址,主机号为 80 |
| 218.75.230.84 ~ 218.75.230.255 | 剩余待分配 |
例 2:假设地址块为 192.168.252.0/24
【例 2】假设地址块为 192.168.252.0/24,使用变长的子网掩码划分子网来满足需求:网络 1 需要 IP 地址数量为 63,网络 2 需要 IP 地址数量为 23,网络 3 需要 IP 地址数量为 13,网络 4 需要 IP 地址数量为 4。
【解】各网络的情况如下表所示:
| 网络序号 | 需要 IP 地址数量 | 主机号位数 | 网络前缀位数 | 地址块 | 可使用的地址数量 |
|---|---|---|---|---|---|
| 1 | 63 | 6 (26=64) | 32-6=26 | /26 | 64 |
| 2 | 23 | 5 (25=32) | 32-5=27 | /27 | 32 |
| 3 | 13 | 4 (24=16) | 32-4=28 | /28 | 16 |
| 4 | 4 | 2 (22=4) | 32-2=30 | /30 | 4 |
从地址块 192.168.252.0/24 中取出 5 个地址块(/30,/28,/27,/26):
| IP 地址 | 用途 |
|---|---|
| 192.168.252.0 ~ 192.168.252.63 | 供网络 1 使用,拥有 64 个地址,主机号为 0 |
| 192.168.252.64 ~ 192.168.252.95 | 供网络 2 使用,拥有 32 个地址,主机号为 64 |
| 192.168.252.96 ~ 192.168.252.111 | 供网络 3 使用,拥有 16 个地址,主机号为 96 |
| 192.168.252.112 ~ 192.168.252.115 | 供网络 4 使用,拥有 4 个地址,主机号为 112 |
| 192.168.252.116 ~ 192.168.252.255 | 剩余待分配 |
【注】若还要继续分配网络,则不能在 192.168.252.116 处开始分配,因为 116 不能被 4、8、16、32、64、… 整除,所以该地址不能分配大小为 4、8、16、32、64、… 的地址块。那么应该从哪里开始分配地址呢?见下表:
| 分配的地址块大小 | 起始地址 |
|---|---|
| 4 | 192.168.252.120 |
| 8 | 192.168.252.120 |
| 16 | 192.168.252.128 |
| 32 | 192.168.252.128 |
| 64 | 192.168.252.128 |
| 128 | 192.168.252.128 |
| … | … |
例 3:若将 101.200.16.0/20 划分为 5 个子网
【例 3】若将 101.200.16.0/20 划分为 5 个子网,则可能的最小子网的可分配 IP 地址数是( )
A. 126
B. 254
C. 510
D. 1022
【解】地址块 101.200.16.0/20 主机号位数为 32-20=12,即 101. 200. 0001 0000. 0000 0000,包含地址数量为 212=4096 个。
若要求最小子网,则不能采用均匀分配,要采用不均匀的子网划分,因此采用哈夫曼编码的方式确定子网号。
- 子网 1:101. 200. 0001 0000. 0000 0000,子网号为 1 位,IP 地址数为 2048 个
- 子网 2:101. 200. 0001 1000. 0000 0000,子网号为 2 位,IP 地址数为 1024 个
- 子网 3:101. 200. 0001 1100. 0000 0000,子网号为 3 位,IP 地址数为 512 个
- 子网 4:101. 200. 0001 1110. 0000 0000,子网号为 4 位,IP 地址数为 256 个
- 子网 5:101. 200. 0001 1111. 0000 0000,子网号为 4 位,IP 地址数为 256 个
去掉网络地址和广播地址,可分配 IP 地址数为 254 个,选 B。
(请参考《(考研复习)子网划分小题解析》)
5 IP 层转发分组的过程
5.1 IP 地址与 MAC 地址
数据报传送过程中 IP 地址(逻辑地址)与 MAC 地址(硬件地址)的变化情况:

- 在数据包的传送过程中,数据包的源 IP 地址和目的 IP 地址保持不变。
- 在数据包的传送过程中,数据包的源 MAC 地址和目的 MAC 地址逐链路(或逐网络)改变。
- 若仅使用 MAC 地址进行通信:包含海量 MAC 地址的路由信息需要路由器具备极大的存储空间,并且会给分组的查表转发带来非常大的时延。
【例 1】下图中各主机和路由器各接口的 MAC 地址和所配置的 IP 地址都已标注在它们的旁边,假设主机 H1 要给 H2 发送一个 IP 数据报,该 IP 数据报会被封装成以太网帧进行发送,则当 H2 收到该帧时,其首部中的源 MAC 地址以及所封装的 IP 数据报首部中的源 IP 地址分别是( )
A. 00-a1-b2-c3-d4-61,192.168.1.254
B. 00-a1-b2-c3-d4-61,192.168.0.1
C. 00-a1-b2-c3-d4-51,192.168.0.1
D. 00-a1-b2-c3-d4-51,192.168.1.254
【解】答案为选项 B,见下表:
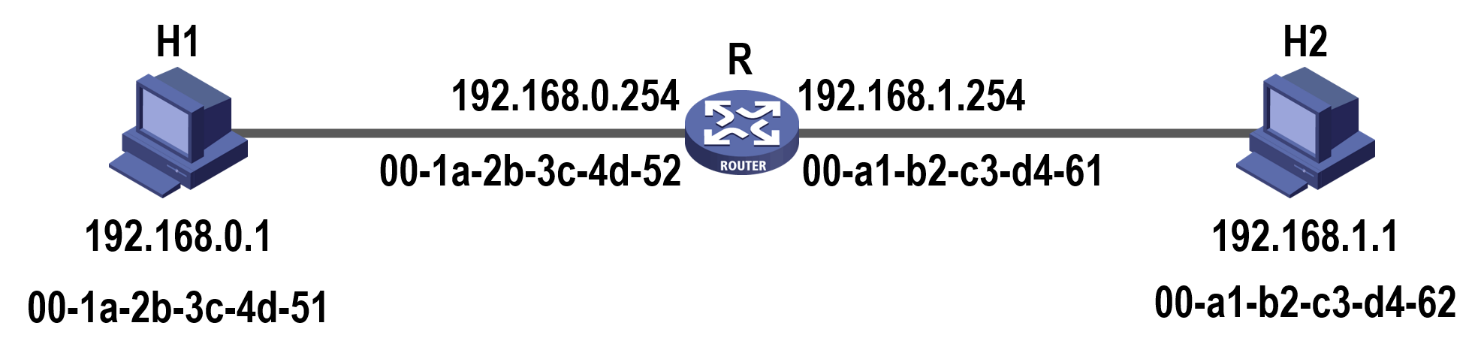
| 传输区间 | 网络层 IP 数据报首部的源 IP 地址 | 网络层 IP 数据报首部的目的 IP 地址 | 数据链路层帧首部的源 MAC 地址 | 数据链路层帧首部的目的 MAC 地址 |
|---|---|---|---|---|
| H1 --> R | 192.168.0.1 | 192.168.1.1 | 00-a1-b2-c3-d4-51 | 00-a1-b2-c3-d4-52 |
| R --> H2 | 192.168.0.1 | 192.168.1.1 | 00-a1-b2-c3-d4-61 | 00-a1-b2-c3-d4-62 |
【例 2】路由器 R 通过以太网交换机 S1 和 S2 连接两个网络,R 的接口、主机 H1 和 H2 的 IP 地址与 MAC 地址如下图所示。若 H1 向 H2 发送一个 IP 分组 P,则 H1 发出的封装 P 的以太网帧的目的 MAC 地址、H2 收到的封装 P 的以太网帧的源 MAC 地址分别是( )
A. 00-a1-b2-c3-d4-62,00-1a-2b-3c-4d-52
B. 00-a1-b2-c3-d4-62,00-1a-2b-3c-4d-61
C. 00-1a-2b-3c-4d-51,00-1a-2b-3c-4d-52
D. 00-1a-2b-3c-4d-51,00-a1-b2-c3-d4-61
【解】答案为选项 D,见下表:

| 传输区间 | 网络层 IP 数据报首部的源 IP 地址 | 网络层 IP 数据报首部的目的 IP 地址 | 数据链路层帧首部的源 MAC 地址 | 数据链路层帧首部的目的 MAC 地址 |
|---|---|---|---|---|
| H1 --> R | 192.168.3.2 | 192.168.4.2 | 00-a1-b2-c3-d4-52 | 00-a1-b2-c3-d4-51 |
| R --> H2 | 192.168.3.2 | 192.168.4.2 | 00-a1-b2-c3-d4-61 | 00-a1-b2-c3-d4-62 |
【注】查表转发的结果可以指明IP数据报的下一跳路由器的 IP 地址,但无法指明该 IP 地址所对应的 MAC 地址。因此,在数据链路层封装该 IP 数据报成为帧时,帧首部中的目的 MAC 地址字段就无法填写,该问题需要使用网际层中的地址解析协议 ARP 来解决。
5.2 IP 数据报的发送和转发过程

- 目的地址与路由器 R 的路由表第一行的地址掩码进行按位与运算,运算结果与目的网络不匹配。
- 目的地址与路由器 R 的路由表第二行的地址掩码进行按位与运算,运算结果与目的网络匹配。
- 若目的地址是
192.168.0.127或255.255.255.255(本网络的广播地址),则路由器不转发广播 IP 数据报(路由器 R 会隔离广播域)。如果因特网中数量巨大的路由器收到广播 IP 数据报后都进行转发,则会造成巨大的广播风暴,严重浪费因特网资源。
【注】默认网关和默认路由的区别:
- 默认网关:是一个 IP 地址;是与主机直接相连的路由器端口。
- 默认路由:是路由表中的一项,一般通往互联网的方向。
【例】某网络拓扑如下图所示,其中 R 为路由器,主机 H1~H4 的 IP 地址配置以及 R 的各接口 IP 地址配置如图中所示。现有若干台以太网交换机(无 VLAN 功能)和路由器两类网络互连设备可供选择。

请回答以下问题:
(1)设备 1、设备 2 和设备 3 分别应选择什么类型网络设备?
(2)设备 1、设备 2 和设备 3 中,哪几个设备的接口需要配置 IP 地址?并为对应的接口配置正确的 IP 地址。
(4)若主机 H3 发送一个目的地址为 192.168.1.127 的 IP 数据报,网络中哪几个主机会收到该数据报?
【解】(1)H1 和 H2 的网络前缀相同,因此设备 1 是交换机;同理,H3 和 H4 的网络前缀相同,因此设备 2 也是交换机。由于 H1 和 H3 的网络前缀不相同,因此设备 3 是路由器。
(2)路由器 IF1 = 192.168.1.254/30,IF2 = 192.168.1.1,IF3 = 192.168.1.65。
(4)192.168.1.127 为 H3 所在网络的广播地址,因此主机 H3 和 H4 都能收到该数据报。
5.3 分组转发算法
- 基于终点的转发:分组在互联网上传送和转发是基于分组首部的目的地址。
- 分组转发算法(前缀已按长短顺序排列):
- 从收到的 IP 分组的首部提取目的主机的 IP 地址 D。
- 用本网络的子网掩码和 D 进行按位与运算,若运算结果与网络地址匹配,则把分组直接交付,若不匹配则进行下一步。
- 若路由表中有特定地址为 D 的特定主机路由,则把分组传送给路由表中所指的下一跳路由器,否则执行下一步。
- 对路由表中的每一行,用子网掩码与 D 进行按位与运算,其结果为 N。若 N 与该行的目的网络地址匹配,则把分组传送给该行指明的下一跳路由器。否则执行下一步。
- 若路由表中有一个默认路由,则把分组传送给所指明的默认路由器。否则执行下一步。
- 报告转发分组出错。
【例】如图所示有三个子网,两个路由器,以及路由器 1 的部分路由表。现在源主机 H1 向目的主机 H2 发送分组。试着讨论 R1 收到 H1 向 H2 发送的分组后查找路由表的过程。(来源《使用子网时的分组转发算法》)
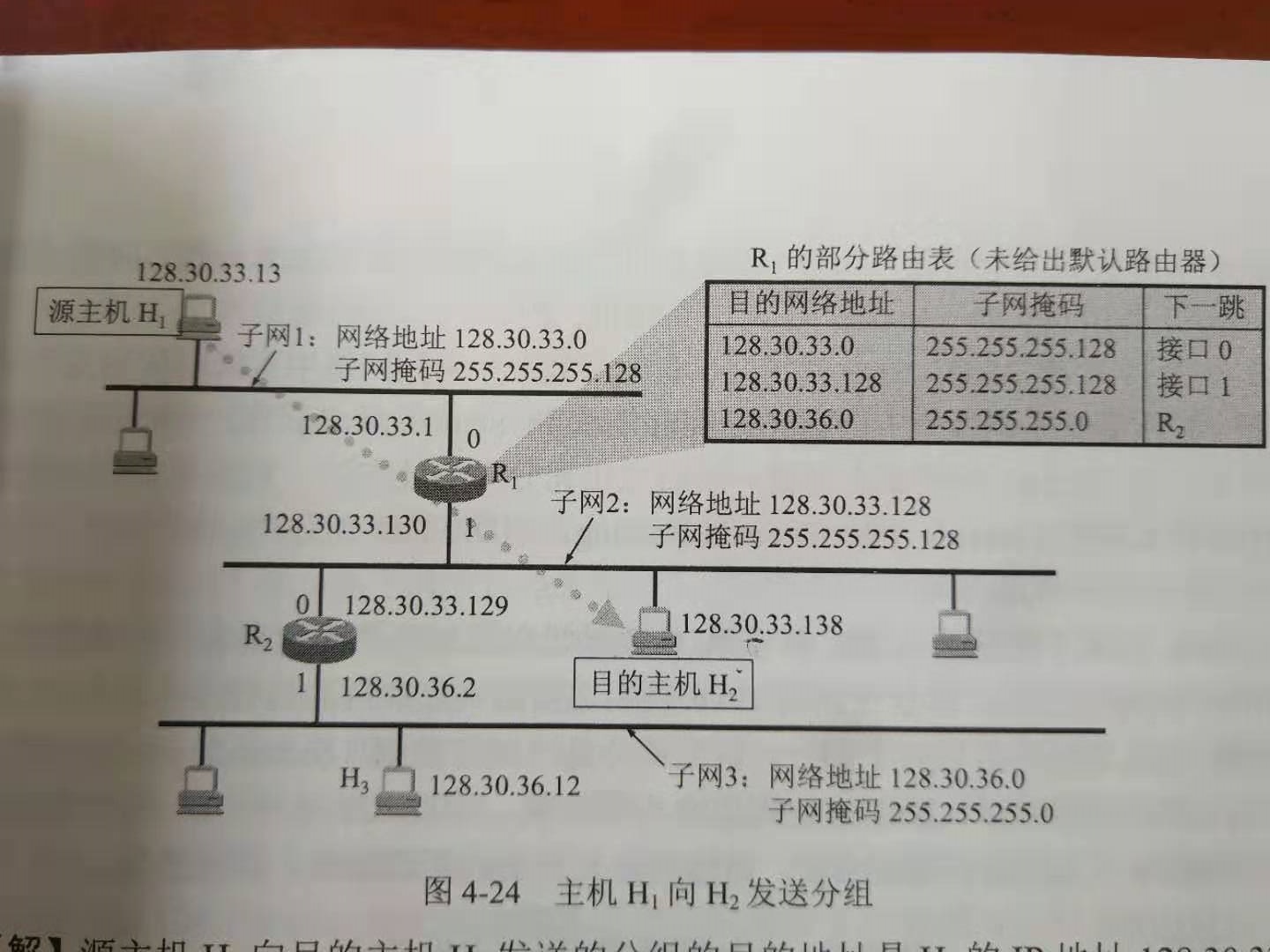
【解】源主机 H1 首先判断目的主机 H2 是否在本网络上:
| 十进制目的主机 IP 地址 | 128 | 30 | 33 | 138 |
|---|---|---|---|---|
| 二进制目的主机 IP 地址 | 128 | 30 | 33 | 1000 1010 |
| 二进制本网络的子网掩码 | 255 | 255 | 255 | 1000 0000 |
| 按位与运算结果 | 128 | 30 | 33 | 1000 0000 |
| 十进制网络地址 | 128 | 30 | 33 | 128 |
因此得出的网络地址与本网络的网络地址不匹配,说明 H2 不在 H1 所在的网络中,必须把分组交给路由器 R1,让 R1 根据转发表来处理这个分组。
用 H2 的 IP 地址(128.30.33.138)与转发表每一行的子网掩码进行按位与运算,看是否匹配目的地址:
| 目的网络 | 子网掩码 | 下一跳 | 子网掩码与 H2 的 IP 地址的按位与运算 | 是否匹配 |
|---|---|---|---|---|
| 128.30.33.0/25 | 255.255.255.128 | 接口 0 | 128.30.33.128 | x |
| 128.30.33.128/25 | 255.255.255.128 | 接口 1 | 128.30.33.128 | √(此时不再往下匹配) |
| 128.30.36.0/24 | 255.255.255.0 | R2 |
于是 R1 把分组从接口 1 交付给 H2。
5.4 最长前缀匹配
- 最长前缀匹配:使用 CIDR 查找路由表时可能会得到不止一个匹配结果,此时应当从匹配结果中选择具有最长网络前缀的路由。
- 网络前缀越长,其地址块就越小,路由越具体。
- 当使用 CIDR 后,由于不知道目的网络的前缀,使得转发表的查找过程更复杂了,因此采用二叉线索查找转发表。
- 分组转发算法(最长前缀匹配):
- 从收到的 IP 分组的首部提取目的主机的 IP 地址 D。
- 用本网络的子网掩码和 D 进行按位与运算,若运算结果与网络地址匹配,则把分组直接交付,若不匹配则进行下一步。
- 若路由表中有特定地址为 D 的特定主机路由,则把分组传送给路由表中所指的下一跳路由器,否则执行下一步。
- 对路由表中的每一行,用子网掩码与 D 进行按位与运算,其结果为 N。若 N 与该行的目的网络地址多个匹配,则取前缀最长的目的网络,把分组传送给该行指明的下一跳路由器。否则执行下一步。
- 若路由表中有一个默认路由,则把分组传送给所指明的默认路由器。否则执行下一步。
- 报告转发分组出错。
【例】路由器 R0 的路由表见下表,若进入路由器 R0 的分组的目的地址为 132.19.237.5,该分组应该被转发到( )下一跳路由器。
| 目的网络 | 下一跳 |
|---|---|
| 132.0.0.0/8 | R1 |
| 132.0.0.0/11 | R2 |
| 132.19.232.0/22 | R3 |
| 0.0.0.0/0 | R4 |
A. R1
B. R2
C. R3
D. R4
【解】见下表:
| 目的网络 | 子网掩码 | 下一跳 | 子网掩码与目的地址的按位与运算 | 是否匹配 |
|---|---|---|---|---|
| 132.0.0.0/8 | 255.0.0.0 | R1 | 132.0.0.0 | √ |
| 132.0.0.0/11 | 255.224.0.0 | R2 | 132.0.0.0 | √ |
| 132.19.232.0/22 | 255.255.252.0 | R3 | 132.19.236.0 | x |
| 0.0.0.0/0 | 0.0.0.0 | R4 | 0.0.0.0 | √ |
0.0.0.0/0 为默认路由,只有路由表中的所有网络都不能和分组的目的网络匹配时才使用。有三个目的网络均匹配,则选择前缀最长的路由,所以答案为选项 B。
5.5 网络地址转换 NAT
- 网络地址转换(NAT):通过将专用网络地址转换为公用地址,从而对外隐藏内部管理的 IP 地址。
- 私有 IP 地址:只用于 LAN,不用于 WAN,允许私有 IP 地址被 LAN重复使用。
- 私有 IP 地址网段:
| 网络类别 | 地址范围 | 网段个数 |
|---|---|---|
| A | 10.0.0.0 ~ 10.255.255.255 | 1 个 A 类网段 |
| B | 172.16.0.0 ~ 172.31.255.255 | 16 个 B 类网段 |
| C | 192.168.0.0 ~ 192.168.255.255 | 256 个 C 类网段 |
- 专用互联网(本地互联网):采用私有 IP 地址的互联网络
- NAT 路由器:在连接专用网和因特网的路由器上安装了 NAT 软件
- NAT 转换表:存放了
{本地 IP 地址: 端口}到{全球IP 地址: 端口}的映射,将多个私有 IP 地址映射到一个全球 IP 地址
【注】将 NAT 和运输层端口号结合使用,称为网络地址与端口号转换(Network Address and Port Translation,NAPT),但一般又称为 NAT。
例 1:分析 NAT 路由器的工作流程
【例 1】假设主机 A 端口号为 30000,主机 B 端口号为 80,(1)用户主机 A 向目的主机 B 发送分组,(2)用户主机 B 向目的主机 A 发送响应分组,请分析 NAT 路由器的工作流程。

【解】(1)用户主机 A 向目的主机 B 发送分组的过程如下。
- 在网络层(IP 层)的数据报:
| IP 首部 | 运输层首部 | 应用层报文 |
|---|---|---|
| 源 IP:192.168.0.3;目的 IP:213.18.2.4 | 源端口:30000;目的端口:80 | xxx |
- NAT 路由器收到 IP 数据报后,为该数据报生成一个新端口号 40001,在 NAT 转换表中新增一个表项:
| WAN 端(外网) | LAN 端(内网) |
|---|---|
| 172.38.1.5: 40001 | 192.168.0.3: 30000 |
- 通过 NAT 转换表,改写数据报,转发到主机 B:
| IP 首部 | 运输层首部 | 应用层报文 |
|---|---|---|
| 源 IP:172.38.1.5;目的 IP:213.18.2.4 | 源端口:40001;目的端口:80 | xxx |
(2)用户主机 B 向目的主机 A 发送响应分组的过程如下。
- 在网络层(IP 层)的数据报:
| IP 首部 | 运输层首部 | 应用层报文 |
|---|---|---|
| 源 IP:213.18.2.4;目的 IP:172.38.1.5 | 源端口:80;目的端口:40001 | xxx |
- NAT 路由器收到 IP 数据报后,通过 NAT 转换表,改写数据报,转发到主机 A:
| IP 首部 | 运输层首部 | 应用层报文 |
|---|---|---|
| 源 IP:213.18.2.4;目的 IP:192.168.0.3 | 源端口:80;目的端口:30000 | xxx |
例 2:假定一个 NAT 路由器的公网地址为 205.56.79.35
【例 2】假定一个 NAT 路由器的公网地址为 205.56.79.35,并且有如下表项:
| 转换端口 | 源 IP 地址 | 源端口 |
|---|---|---|
| 2056 | 192.168.32.56 | 21 |
| 2057 | 192.168.32.56 | 20 |
| 1892 | 192.168.48.26 | 80 |
| 2256 | 192.168.55.106 | 80 |
它收到一个源 IP 地址为 192.168.32.56,源端口为 80 的分组,其动作是( )。
A. 转换地址,将源 IP 变为 205.56.79.35,端口变为 2056,然后发送到公网
B. 添加一个新的条目,转换 IP 地址以及端口然后发送到公网
C. 不转发,丢弃该分组
D. 直接将分组转发到公网上
【解】NAT 的表项需要管理员添加,这样可以控制一个内网到外网的网络连接。题目中主机发送的分组在 NAT 表项中找不到(端口 80 是从源端口找,而不是转换端口),所以服务器就不转发该分组。选 C。
第二部分:IPv6(IP 协议版本 6)
1 IPv6 的特点
- 更大的地址空间:IPv6 将 IPv4 的 32 比特地址空间增大到了 128 比特,在采用合理编址方法的情况下,在可预见的未来是不会用完的。
- 扩展的地址层次结构
- 灵活的首部格式
- 改进的选项
- 允许协议继续扩充
- 支持即插即用(即自动配置)
- 支持资源的预分配
2 IPv6 数据报
与 IPv4 相比,IPv6 数据报首部的某些字段作了以下更改:
- 取消首部长度字段,因为首部长度已被固定为 40B
- 取消服务类型字段
- 取消总长度字段
- 取消标识、标志、片偏移字段
- 将 TTL 字段改为跳数限制字段
- 取消协议字段
- 取消校验和字段
- 取消选项字段
3 IPv6 地址
- 三种类型:单播、多播、任播
- 冒号十六进制记法:
68E6:8C64:FFFF:FFFF:0:1180:960A:FFFF - 零压缩(只能使用一次):
- 连续零:
68E6:0:0:0:0:0:0:FFFF–>68E6::FFFF - 左侧零:
0:0:0:0:0:0:128.10.2.1–>::128.10.2.1 - 左侧零:
0:0:0:0:0:0:0:FFFF–>::FFFF - 左侧零:
0:0:0:0:0:0:0:0–>::
- 连续零:
4 IPv4 向 IPv6 过渡的策略
- 双协议栈技术
- 隧道技术
智能推荐
源码阅读笔记 - 2 std::vector (1)-程序员宅基地
文章浏览阅读362次。vector的源码真是太长了,今天用了一个下午和一个晚上看和注释了前面的一千行左右p.s.博客园的代码高亮真是太垃圾, 如果想要阅读带注释的源码,推荐粘贴到VS2015里,然后按ctrl+z取消自动格式化,用我格式化好的样子,并在最前面#include <vector>和using namespace std,这样就能带高亮的看我加了注释的代码了花了不短的时间弄明白了..._2std
利用python实现对连续特征的分箱操作(数据离散化)_连续性数据分箱方法-程序员宅基地
文章浏览阅读5.7k次。1. 数据分箱1.1 等区间分箱将连续变量的值进行获取,然后利用pandas的cut函数进行等区间分箱。如下代码,获取值A2_values ,并等数值区间分为6类为[0,1,2,3,4,5];(cut在操作时,统计了一维数组的最小、最大值,得到一个区间长度,因为需要划分6个区间)1.2 等频分箱将连续变量在[min,max]区间内,等数量地进行分箱。1.3 卡方分箱法(ChiMe..._连续性数据分箱方法
时序动作检测SSAD《Single Shot Temporal Action Detection》-程序员宅基地
文章浏览阅读6k次,点赞2次,收藏29次。温馨提示:本文仅供自己参考(勿捧杀),如有理解错误,有时间再改!时序动作分类:识别一段视频中的动作类别时序动作检测:识别一段视频中的动作类别以及动作的开始和结束时间时空动作检测:识别一段视频中的动作类别、动作的开始和结束时间,以及动作发生的空间位置(如投篮人所在的bbox)时序动作检测可以被看做是时序版本的图像目标检测,因为两者都是需要检测目标的类别,并且都需要确定目标的准确边界位置。detect by classifying时序动作检测方法:先使..._时序动作检测
经典算法之——解决全排列问题以及详解_排列问题的过程-程序员宅基地
文章浏览阅读3.4k次,点赞18次,收藏81次。回溯”指的是“状态重置”,可以理解为“恢复现场”,是在编码的过程中,是为了节约空间而使用的,而在递归或者深度优先中根据需要的场合来配合回溯法可以进一步对自己的代码进行优化。, n-1, n},方向都为向左。邻位对换法是全排列生成算法中的其中一种,它的换位是双向的,通过保存数字的“方向性”来快速得到下一个排列。最后以 3 开头的全排列为[3, 1, 2], [3, 2, 1];以 1 开头的全排列为[1, 2, 3], [1, 3, 2];以 2 开头的全排列为[2, 1, 3], [2, 3, 1];_排列问题的过程
强化学习(一)模型基础_强化学习模型介导系统总体结构-程序员宅基地
文章浏览阅读1.3k次。 从今天开始整理强化学习领域的知识,主要参考的资料是Sutton的强化学习书和UCL强化学习的课程。这个系列大概准备写10到20篇,希望写完后自己的强化学习碎片化知识可以得到融会贯通,也希望可以帮到更多的人,毕竟目前系统的讲解强化学习的中文资料不太多。 第一篇会从强化学习的基本概念讲起,对应Sutton书的第一章和UCL课程的第一讲。1. 强化学习在机器学习中的位置 强化..._强化学习模型介导系统总体结构
MyBatis整合Spring中间jar包 mybatis-spring-1.3.1.jar的官方下载(免费)_mybatis-spring-1.3.1.jar下载-程序员宅基地
文章浏览阅读1.8w次,点赞15次,收藏11次。官方网站:http://mvnrepository.com/artifact/org.mybatis/mybatis-spring/1.3.1官方下载的步骤: 1.点击上面的链接进入官方网站; 2.按照下面的步骤: 3.这是1.3.1的下载方式,其它类似..._mybatis-spring-1.3.1.jar下载
随便推点
linux 编译 内核模块 头文件,linux/module.h: No such file or directory 内核模块编译过程...-程序员宅基地
文章浏览阅读1.7k次。1、缺少Linux kernel头文件To install just the headers in Ubuntu:sudo apt-get install linux-headers-$(uname -r)To install the entire Linux kernel source in Ubuntu:sudo apt-get install linux-sourceNote that yo..._linux/init.h: no such file or directory
R语言之决策树CART、C4.5算法_c4.5的决策树是怎么画的-程序员宅基地
文章浏览阅读1.6w次,点赞19次,收藏100次。决策树是以树的结构将决策或者分类过程展现出来,其目的是根据若干输入变量的值构造出一个相适应的模型,来预测输出变量的值。预测变量为离散型时,为分类树;连续型时,为回归树。R语言的调用函数rpart(),J48(),prune()_c4.5的决策树是怎么画的
从Java String实例来理解ANSI、Unicode、BMP、UTF等编码概念-程序员宅基地
文章浏览阅读159次。一、前言一切的谜都解开了!在写这篇随笔之前,我的心情只能用金田一每次破案后的这句台词来表达。其实从开始写Java代码以来,遇到过无数次乱码与转码问题,比如从文本文件读入到..._java解析ansi
图片无损放大怎么做?这几种无损放大方法很简单_博客中图片放大怎么做-程序员宅基地
文章浏览阅读173次。无损放大图片还可以帮助我们在数码摄影中获得更好的结果,因为它可以增加图像的细节和清晰度,从而使得图像在观看时更加逼真和生动。给大家分享几种图片无损放大的方法,一起来学习下吧。这是一个专业的图片编辑工具,里面拥有非常全面的图片编辑功能,我们日常的图片编辑需求基本都可以在其中得以解决。3、此外,对于放大镜的形状、大小和颜色都是可以设置的,最后设置好后将图片给保存下来就可以啦,是不是非常简单方便呢。2、图片添加进来后,可以在右上角选择放大的倍数,也可以自定义倍数来设置,大家根据自己的实际需求选择就可以了。_博客中图片放大怎么做
大数据、AI“武装”企业服务:风控、检索、安全-程序员宅基地
文章浏览阅读329次。 大数据、AI“武装”企业服务:风控、检索、安全小饭桌创业课堂2017-05-06 15:26:42阅读(127)评论(0) +- 文|吴杨可月 -- 小饭桌创业研究院出品 - 两件秘闻,将美国大数据公司Palantir从幕后推向前台—— 一是,Palantir的旗下产品在整合40年的记录及海量数据并充分挖掘之后,找到了前纳斯达克主席麦道夫“庞氏骗局”的大量确凿..._企业服务+ai
Java泛型的学习和使用_java泛型需要学吗-程序员宅基地
文章浏览阅读283次。前面,由于对泛型擦除的思考,引出了对Java-Type体系的学习。本篇,就让我们继续对“泛型”进行研究:JDK1.5中引入了对Java语言的多种扩展,泛型(generics)即其中之一。1. 什么是泛型?泛型,即“参数化类型”,就跟在方法或构造函数中普通的参数一样,当一个方法被调用时,实参替换形参,方法体被执行。当一个泛型声明被调用,实际类型参数取代形式类型参数。 ..._java泛型需要学吗