计算机视觉迎来GPT时刻!UC伯克利三巨头祭出首个纯CV大模型!-程序员宅基地
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
扫码加入CVer知识星球,可以最快学习到最新顶会顶刊上的论文idea和CV从入门到精通资料,以及最前沿项目和应用!发论文,强烈推荐!

在CVer微信公众号后台回复:LVM,即可下载论文pdf和代码链接!快学起来!
转载自:机器之心
仅靠视觉(像素)模型能走多远?UC 伯克利、约翰霍普金斯大学的新论文探讨了这一问题,并展示了大型视觉模型(LVM)在多种 CV 任务上的应用潜力。
最近一段时间以来,GPT 和 LLaMA 等大型语言模型 (LLM) 已经风靡全球。
另一个关注度同样很高的问题是,如果想要构建大型视觉模型 (LVM) ,我们需要的是什么?
LLaVA 等视觉语言模型所提供的思路很有趣,也值得探索,但根据动物界的规律,我们已经知道视觉能力和语言能力二者并不相关。比如许多实验都表明,非人类灵长类动物的视觉世界与人类的视觉世界非常相似,尽管它们和人类的语言体系「两模两样」。
在最近一篇论文中,UC 伯克利和约翰霍普金斯大学的研究者探讨了另一个问题的答案 —— 我们仅靠像素本身能走多远?

论文地址:https://arxiv.org/abs/2312.00785
项目主页:https://yutongbai.com/lvm.html
研究者试图在 LVM 中效仿的 LLM 的关键特征:1)根据数据的规模增长进行扩展,2)通过提示(上下文学习)灵活地指定任务。
他们指定了三个主要组件,即数据、架构和损失函数。
在数据上,研究者想要利用视觉数据中显著的多样性。首先只是未标注的原始图像和视频,然后利用过去几十年产生的各种标注视觉数据源(包括语义分割、深度重建、关键点、多视图 3D 对象等)。他们定义了一种通用格式 —— 「视觉句子」(visual sentence),用它来表征这些不同的注释,而不需要任何像素以外的元知识。训练集的总大小为 16.4 亿图像 / 帧。
在架构上,研究者使用大型 transformer 架构(30 亿参数),在表示为 token 序列的视觉数据上进行训练,并使用学得的 tokenizer 将每个图像映射到 256 个矢量量化的 token 串。
在损失函数上,研究者从自然语言社区汲取灵感,即掩码 token 建模已经「让位给了」序列自回归预测方法。一旦图像、视频、标注图像都可以表示为序列,则训练的模型可以在预测下一个 token 时最小化交叉熵损失。
通过这一极其简单的设计,研究者展示了如下一些值得注意的行为:
随着模型尺寸和数据大小的增加,模型会出现适当的扩展行为;
现在很多不同的视觉任务可以通过在测试时设计合适的 prompt 来解决。虽然不像定制化、专门训练的模型那样获得高性能的结果, 但单一视觉模型能够解决如此多的任务这一事实非常令人鼓舞;
大量无监督数据对不同标准视觉任务的性能有着显著的助益;
在处理分布外数据和执行新的任务时,出现了通用视觉推理能力存在的迹象,但仍需进一步研究。
论文共同一作、约翰霍普金斯大学 CS 四年级博士生、伯克利访问博士生 Yutong Bai 发推宣传了她们的工作。
图源:https://twitter.com/YutongBAI1002/status/1731512110247473608
在论文作者中,后三位都是 UC 伯克利在 CV 领域的资深学者。Trevor Darrell 教授是伯克利人工智能研究实验室 BAIR 创始联合主任、Jitendra Malik 教授获得过 2019 年 IEEE 计算机先驱奖、 Alexei A. Efros 教授尤以最近邻研究而闻名。

从左到右依次为 Trevor Darrell、Jitendra Malik、Alexei A. Efros。
方法介绍
本文采用两阶段方法:1)训练一个大型视觉 tokenizer(对单个图像进行操作),可以将每个图像转换为一系列视觉 token;2)在视觉句子上训练自回归 transformer 模型,每个句子都表示为一系列 token。方法如图 2 所示:
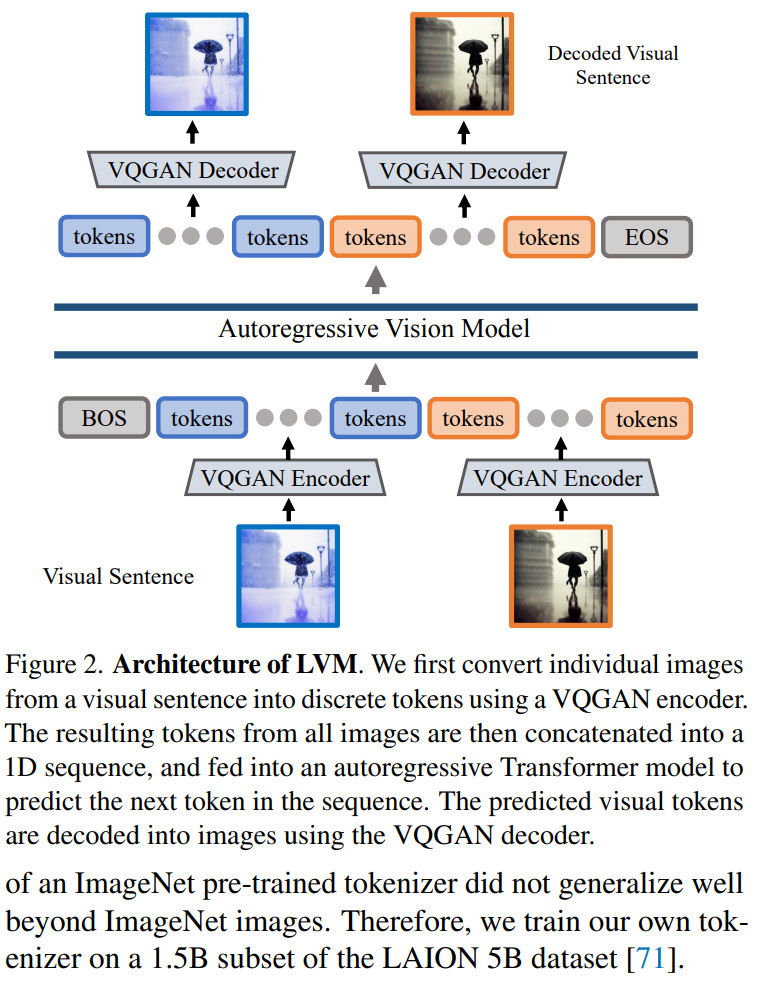
图像 Token 化
为了将 Transformer 模型应用于图像,典型的操作包括:将图像划分为 patch,并将其视为序列;或者使用预训练的图像 tokenizer,例如 VQVAE 或 VQGAN,将图像特征聚集到离散 token 网格中。本文采用后一种方法,即用 VQGAN 模型生成语义 token。
LVM 框架包括编码和解码机制,还具有量化层,其中编码器和解码器是用卷积层构建的。编码器配备了多个下采样模块来收缩输入的空间维度,而解码器配备了一系列等效的上采样模块以将图像恢复到其初始大小。对于给定的图像,VQGAN tokenizer 会生成 256 个离散 token。
实现细节。本文采用 Chang 等人提出的 VQGAN 架构,并遵循 Chang 等人使用的设置,在此设置下,下采样因子 f=16,码本大小 8192。这意味着对于大小为 256 × 256 的图像,VQGAN tokenizer 会生成 16 × 16 = 256 个 token,其中每个 token 可以采用 8192 个不同的值。此外,本文在 LAION 5B 数据集的 1.5B 子集上训练 tokenizer。
视觉句子序列建模
使用 VQGAN 将图像转换为离散 token 后,本文通过将多个图像中的离散 token 连接成一维序列,并将视觉句子视为统一序列。重要的是,所有视觉句子都没有进行特殊处理 —— 即不使用任何特殊的 token 来指示特定的任务或格式。
视觉句子允许将不同的视觉数据格式化成统一的图像序列结构。
实现细节。在将视觉句子中的每个图像 token 化为 256 个 token 后,本文将它们连接起来形成一个 1D token 序列。在视觉 token 序列上,本文的 Transformer 模型实际上与自回归语言模型相同,因此他们采用 LLaMA 的 Transformer 架构。
本文使用的上下文长度为 4096 个 token,与语言模型类似,本文在每个视觉句子的开头添加一个 [BOS](begin of sentence)token,在末尾添加一个 [EOS](end of sentence)token,并在训练期间使用序列拼接提高效率。
本文在整个 UVDv1 数据集(4200 亿个 token)上训练模型,总共训练了 4 个具有不同参数数量的模型:3 亿、6 亿、10 亿和 30 亿。
实验结果
该研究进行实验评估了模型的扩展能力,以及理解和回答各种任务的能力。
扩展
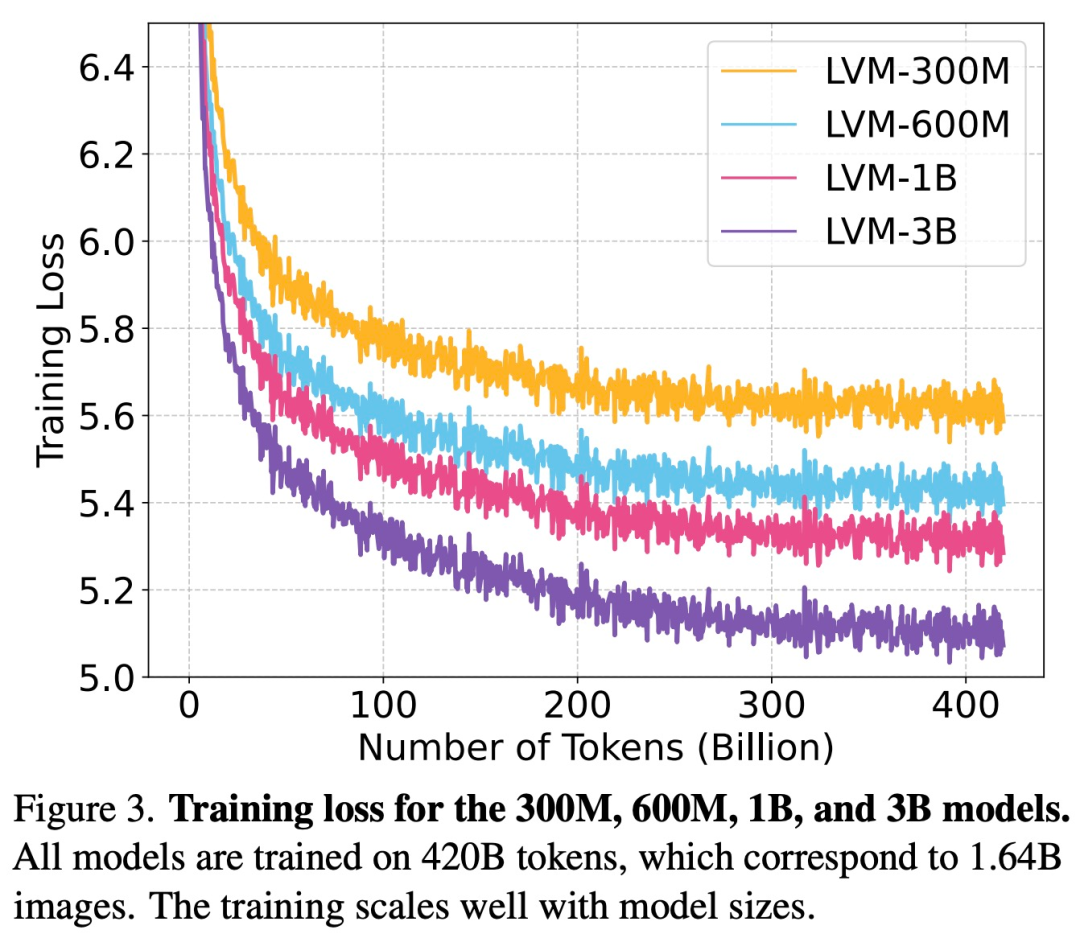
如下图 3 所示,该研究首先检查了不同大小的 LVM 的训练损失。
如下图 4 所示,较大的模型在所有任务中复杂度都是较低的,这表明模型的整体性能可以迁移到一系列下游任务上。
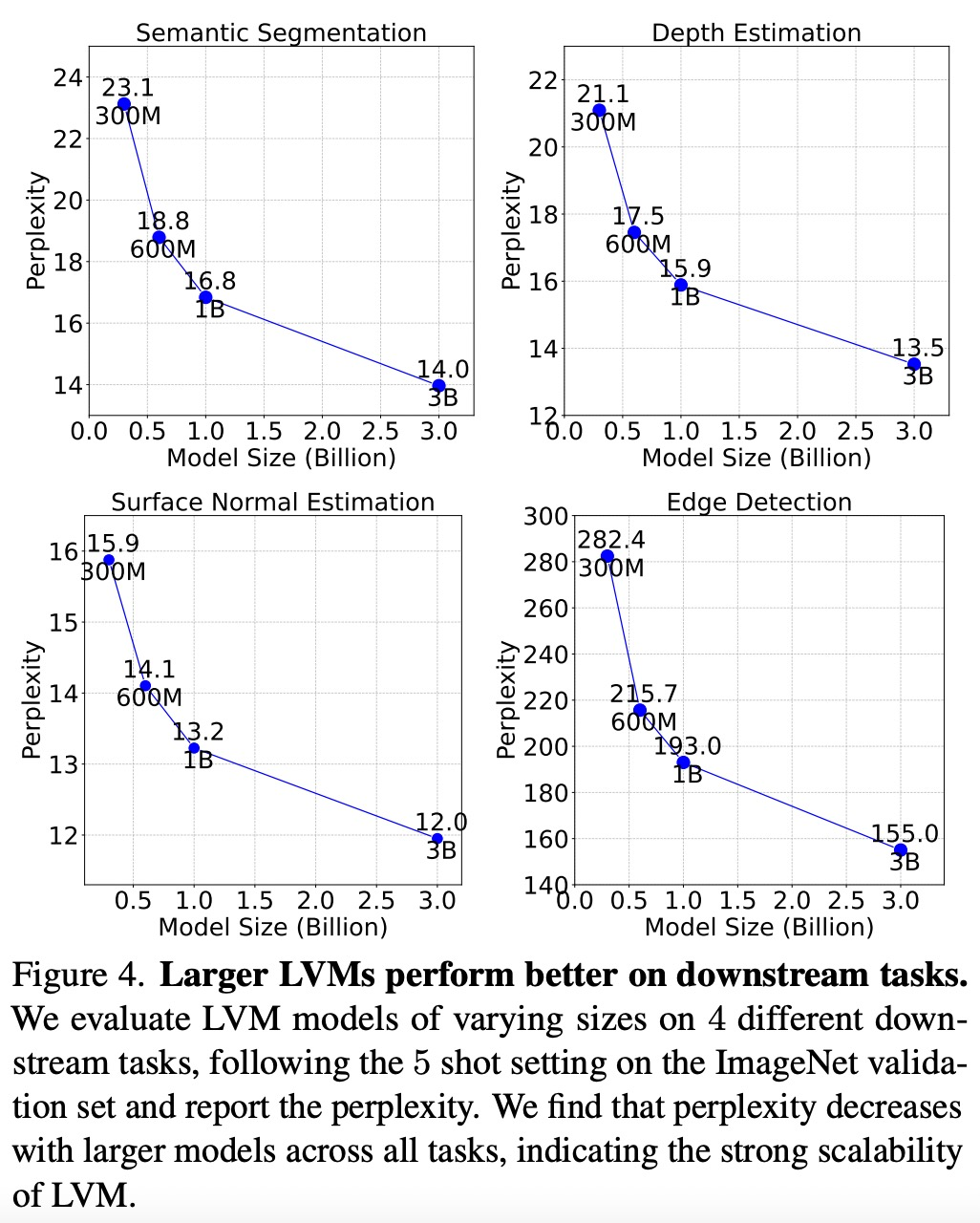
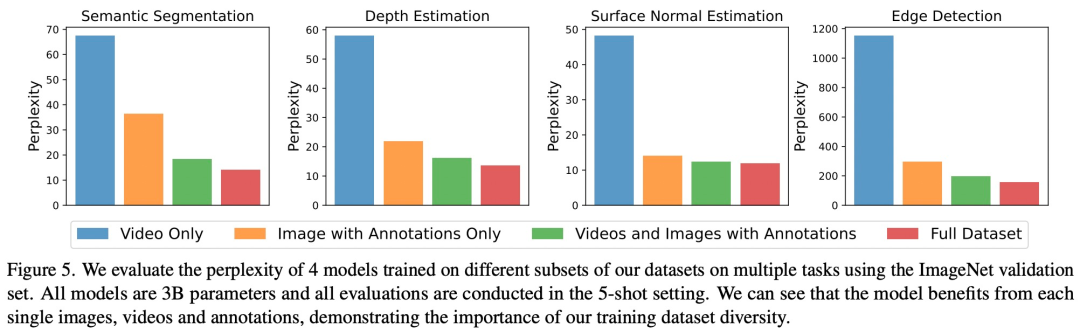
如下图 5 所示,每个数据组件对下游任务都有重要作用。LVM 不仅会受益于更大的数据,而且还随着数据集的多样性而改进。
序列 prompt
为了测试 LVM 对各种 prompt 的理解能力,该研究首先在序列推理任务上对 LVM 进行评估实验。其中,prompt 非常简单:向模型提供 7 张图像的序列,要求它预测下一张图像,实验结果如下图 6 所示:

该研究还将给定类别的项目列表视为一个序列,让 LVM 预测同一类的图像,实验结果如下图 15 所示:

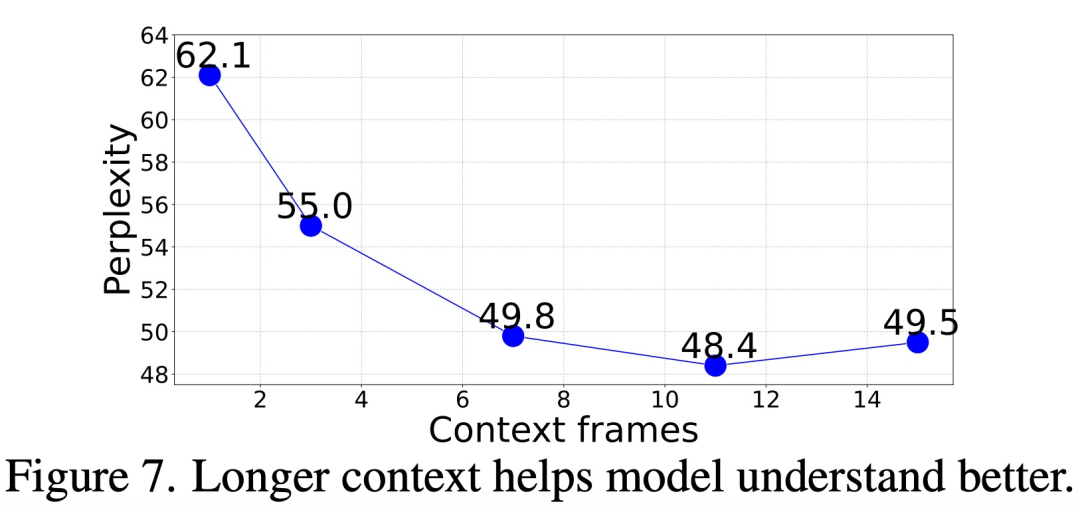
那么,需要多少上下文(context)才能准确预测后续帧?
该研究在给出不同长度(1 到 15 帧)的上下文 prompt 情况下,评估了模型的帧生成困惑度,结果如下图 7 所示,困惑度从 1 帧到 11 帧有明显改善,之后趋于稳定(62.1 → 48.4)。
Analogy Prompt
该研究还评估了更复杂的 prompt 结构 ——Analogy Prompt,来测试 LVM 的高级解释能力。
下图 8 显示了对许多任务进行 Analogy Prompt 的定性结果:

与视觉 Prompting 的比较如下所示, 序列 LVM 在几乎所有任务上都优于以前的方法。

合成任务。图 9 展示了使用单个 prompt 组合多个任务的结果。

其他 prompt
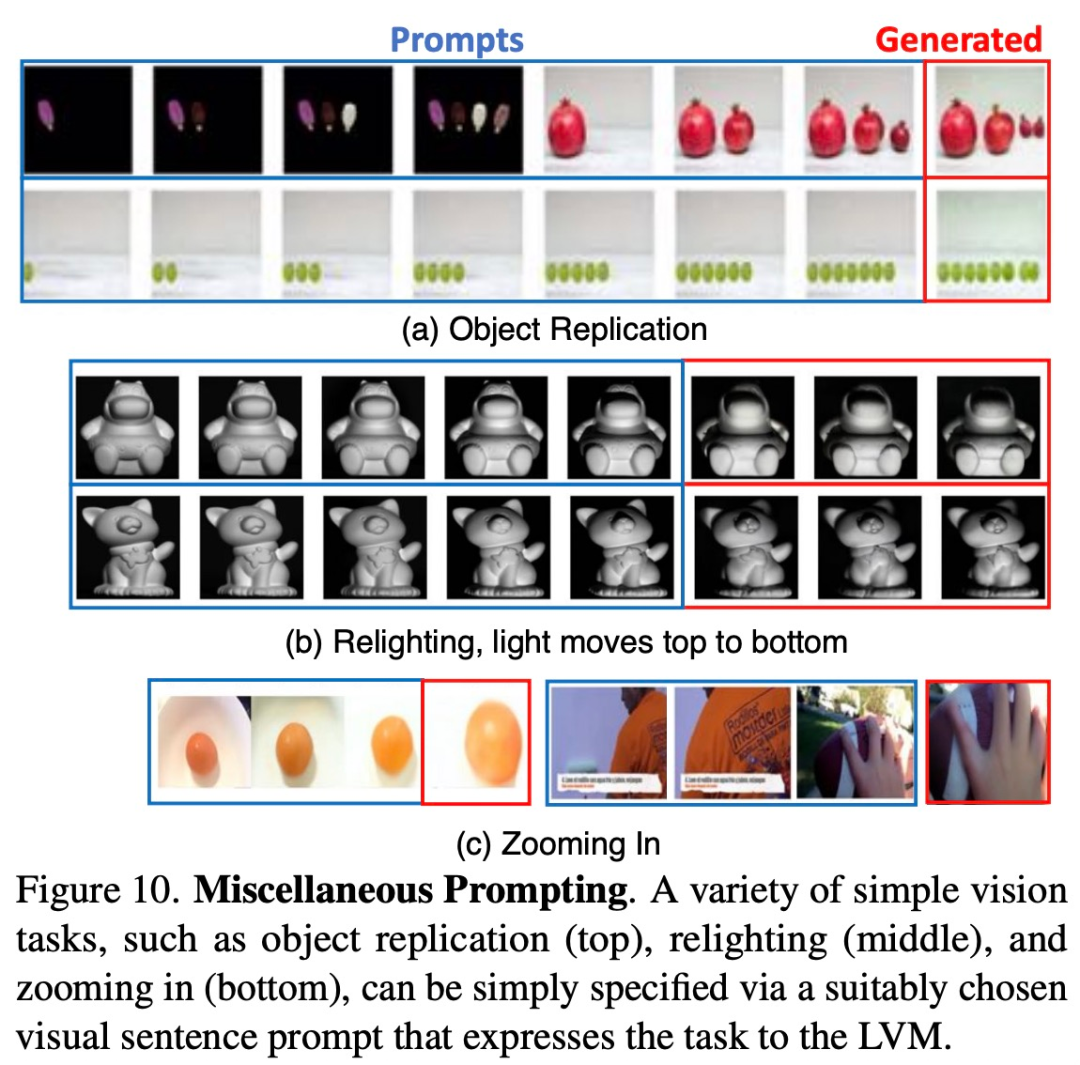
研究者试图通过向模型提供它以往未见过的各种 prompt,来观察模型的扩展能力到底怎样。下图 10 展示了一些运行良好的此类 prompt。
下图 11 展示了一些用文字难以描述的 prompt,这些任务上 LVM 最终可能会胜过 LLM。
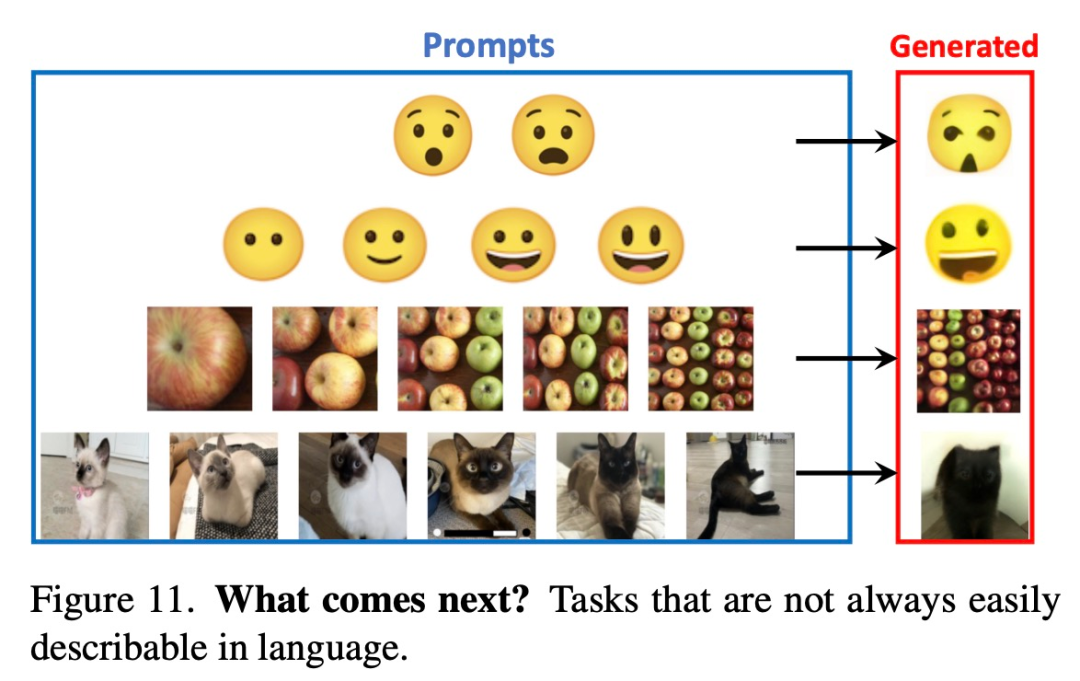
图 13 显示了在非语言人类 IQ 测试中发现的典型视觉推理问题的初步定性结果。

阅读原文,了解更多细节。
在CVer微信公众号后台回复:LVM,即可下载论文pdf和代码链接!快学起来!
CVPR / ICCV 2023论文和代码下载
后台回复:CVPR2023,即可下载CVPR 2023论文和代码开源的论文合集
后台回复:ICCV2023,即可下载ICCV 2023论文和代码开源的论文合集计算机视觉和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer444,即可添加CVer小助手微信,便可申请加入CVer-计算机视觉或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群▲扫码或加微信号: CVer444,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集近万人!
▲扫码加入星球学习▲点击上方卡片,关注CVer公众号智能推荐
EasyDarwin开源流媒体云平台之EasyRMS录播服务器功能设计_开源录播系统-程序员宅基地
文章浏览阅读3.6k次。需求背景EasyDarwin开发团队维护EasyDarwin开源流媒体服务器也已经很多年了,之前也陆陆续续尝试过很多种服务端录像的方案,有:在EasyDarwin中直接解析收到的RTP包,重新组包录像;也有:在EasyDarwin中新增一个RecordModule,再以RTSPClient的方式请求127.0.0.1自己的直播流录像,但这些始终都没有成气候;我们的想法是能够让整套EasyDarwin_开源录播系统
oracle Plsql 执行update或者delete时卡死问题解决办法_oracle delete update 锁表问题-程序员宅基地
文章浏览阅读1.1w次。今天碰到一个执行语句等了半天没有执行:delete table XXX where ......,但是在select 的时候没问题。后来发现是在执行select * from XXX for update 的时候没有commit,oracle将该记录锁住了。可以通过以下办法解决: 先查询锁定记录 Sql代码 SELECT s.sid, s.seri_oracle delete update 锁表问题
Xcode Undefined symbols 错误_xcode undefined symbols:-程序员宅基地
文章浏览阅读3.4k次。报错信息error:Undefined symbol: typeinfo for sdk::IConfigUndefined symbol: vtable for sdk::IConfig具体信息:Undefined symbols for architecture x86_64: "typeinfo for sdk::IConfig", referenced from: typeinfo for sdk::ConfigImpl in sdk.a(config_impl.o) _xcode undefined symbols:
项目05(Mysql升级07Mysql5.7.32升级到Mysql8.0.22)_mysql8.0.26 升级32-程序员宅基地
文章浏览阅读249次。背景《承接上文,项目05(Mysql升级06Mysql5.6.51升级到Mysql5.7.32)》,写在前面需要(考虑)检查和测试的层面很多,不限于以下内容。参考文档https://dev.mysql.com/doc/refman/8.0/en/upgrade-prerequisites.htmllink推荐阅读以上链接,因为对应以下问题,有详细的建议。官方文档:不得存在以下问题:0.不得有使用过时数据类型或功能的表。不支持就地升级到MySQL 8.0,如果表包含在预5.6.4格_mysql8.0.26 升级32
高通编译8155源码环境搭建_高通8155 qnx 源码-程序员宅基地
文章浏览阅读3.7k次。一.安装基本环境工具:1.安装git工具sudo apt install wget g++ git2.检查并安装java等环境工具2.1、执行下面安装命令#!/bin/bashsudoapt-get-yinstall--upgraderarunrarsudoapt-get-yinstall--upgradepython-pippython3-pip#aliyunsudoapt-get-yinstall--upgradeopenjdk..._高通8155 qnx 源码
firebase 与谷歌_Firebase的好与不好-程序员宅基地
文章浏览阅读461次。firebase 与谷歌 大多数开发人员都听说过Google的Firebase产品。 这就是Google所说的“ 移动平台,可帮助您快速开发高质量的应用程序并发展业务。 ”。 它基本上是大多数开发人员在构建应用程序时所需的一组工具。 在本文中,我将介绍这些工具,并指出您选择使用Firebase时需要了解的所有内容。 在开始之前,我需要说的是,我不会详细介绍Firebase提供的所有工具。 我..._firsebase 与 google
随便推点
k8s挂载目录_kubernetes(k8s)的pod使用统一的配置文件configmap挂载-程序员宅基地
文章浏览阅读1.2k次。在容器化应用中,每个环境都要独立的打一个镜像再给镜像一个特有的tag,这很麻烦,这就要用到k8s原生的配置中心configMap就是用解决这个问题的。使用configMap部署应用。这里使用nginx来做示例,简单粗暴。直接用vim常见nginx的配置文件,用命令导入进去kubectl create cm nginx.conf --from-file=/home/nginx.conf然后查看kub..._pod mount目录会自动创建吗
java计算机毕业设计springcloud+vue基于微服务的分布式新生报到系统_关于spring cloud的参考文献有啥-程序员宅基地
文章浏览阅读169次。随着互联网技术的发发展,计算机技术广泛应用在人们的生活中,逐渐成为日常工作、生活不可或缺的工具,高校各种管理系统层出不穷。高校作为学习知识和技术的高等学府,信息技术更加的成熟,为新生报到管理开发必要的系统,能够有效的提升管理效率。一直以来,新生报到一直没有进行系统化的管理,学生无法准确查询学院信息,高校也无法记录新生报名情况,由此提出开发基于微服务的分布式新生报到系统,管理报名信息,学生可以在线查询报名状态,节省时间,提高效率。_关于spring cloud的参考文献有啥
VB.net学习笔记(十五)继承与多接口练习_vb.net 继承多个接口-程序员宅基地
文章浏览阅读3.2k次。Public MustInherit Class Contact '只能作基类且不能实例化 Private mID As Guid = Guid.NewGuid Private mName As String Public Property ID() As Guid Get Return mID End Get_vb.net 继承多个接口
【Nexus3】使用-Nexus3批量上传jar包 artifact upload_nexus3 批量上传jar包 java代码-程序员宅基地
文章浏览阅读1.7k次。1.美图# 2.概述因为要上传我的所有仓库的包,希望nexus中已有的包,我不覆盖,没有的添加。所以想批量上传jar。3.方案1-脚本批量上传PS:nexus3.x版本只能通过脚本上传3.1 批量放入jar在mac目录下,新建一个文件夹repo,批量放入我们需要的本地库文件夹,并对文件夹授权(base) lcc@lcc nexus-3.22.0-02$ mkdir repo2..._nexus3 批量上传jar包 java代码
关于去隔行的一些概念_mipi去隔行-程序员宅基地
文章浏览阅读6.6k次,点赞6次,收藏30次。本文转自http://blog.csdn.net/charleslei/article/details/486519531、什么是场在介绍Deinterlacer去隔行处理的方法之前,我们有必要提一下关于交错场和去隔行处理的基本知识。那么什么是场呢,场存在于隔行扫描记录的视频中,隔行扫描视频的每帧画面均包含两个场,每一个场又分别含有该帧画面的奇数行扫描线或偶数行扫描线信息,_mipi去隔行
ABAP自定义Search help_abap 自定义 search help-程序员宅基地
文章浏览阅读1.7k次。DATA L_ENDDA TYPE SY-DATUM. IF P_DATE IS INITIAL. CONCATENATE SY-DATUM(4) '1231' INTO L_ENDDA. ELSE. CONCATENATE P_DATE(4) '1231' INTO L_ENDDA. ENDIF. DATA: LV_RESET(1) TY_abap 自定义 search help