如何设计一个MQ-程序员宅基地
技术标签: spring java 系统 SpringBoot 后端 JAVA后端
一、为什么使用MQ
比较核心的有3个业务场景:解耦、异步、削峰
1.1、消息队列有什么优点和缺点啊?
优点上面已经说了,就是在特殊场景下有其对应的好处,解耦、异步、削峰
缺点呢?显而易⻅的
- 系统可用性降低:
系统引入的外部依赖越多,越容易挂掉,本来你就是A系统调用BCD三个系统的接口就好了,人ABCD四个系统好好的,没啥问题,你偏加个MQ进来,万一MQ挂了咋整?MQ挂了,整套系统崩溃了,你不就完了么。
- 系统复杂性提高:
硬生生加个MQ进来,你怎么保证消息没有重复消费?怎么处理消息丢失的情况?怎么保证消息传递的顺序性?头大头大,问题一大堆,痛苦不已
- 一致性问题:
A系统处理完了直接返回成功了,人都以为你这个请求就成功了;但是问题是,要是BCD三个系统那里,BD两个系统写库成功了,结果C系统写库失败了,咋整?你这数据就不一致了。所以消息队列实际是一种非常复杂的架构,你引入它有很多好处,但是也得针对它带来的坏处做各种额外的技术方案和架构来规避掉,最好之后,你会发现,妈呀,系统复杂度提升了一个数量级,也许是复杂了10倍。但是关键时刻,用,还是得用的。
二、主流的消息队列
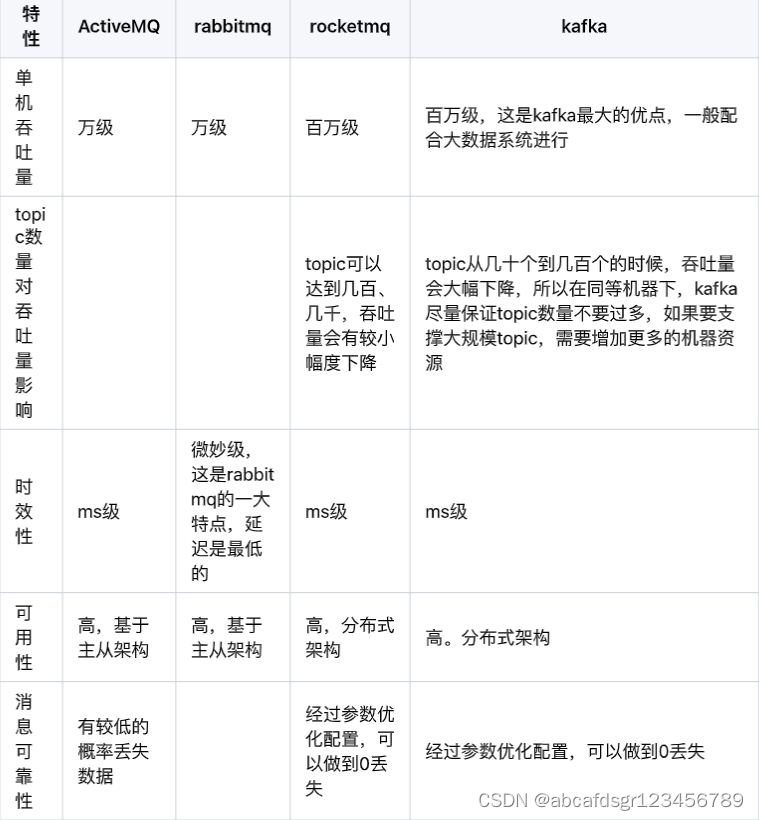
三、计算机构成
CPU、内存、硬盘、网卡
现在CPU都是多核,这就造成数据原子性问题
CPU快,内存慢,CPU需要等到内存(例如存储、拉取)。CPU解决的办法就是缓存。
CPU缓存分为3级:L1;L2;L3作用:进一步提高数据的访问速度,同时降低内存延迟,尤其在大数据量计算时,能显著提升处理器的性能,CPU需要处理数据时,首先会检查一级缓存(L1),如果一级缓存中找不到所需数据,则会查看二级缓存(L2),如果二级缓存中也没有该数据,CPU就会访问三级缓存。如果三级缓存中仍然没有所需数据,CPU最终会从内存中调用这些数据。通过这种方式,三级缓存减少了直接从内存中读取数据的次数,从而提高了程序的运行效率。
机械磁盘影响性能因素:转速(寻址)。固态磁盘与机械磁盘区别https://baijiahao.baidu.com/s?id=1765673312500037801&wfr=spider&for=pc
三、如何设计一款MQ
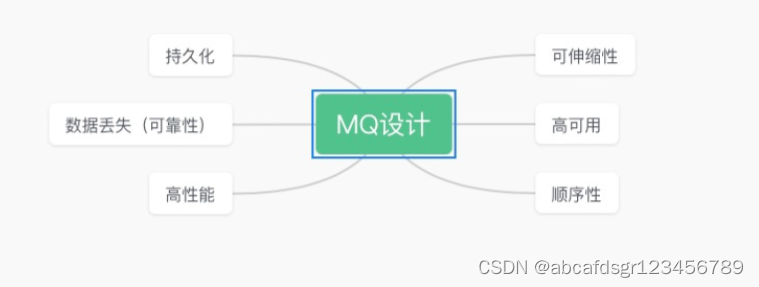
3.1、可伸缩性就是需要的时候快速扩容,就可以增加吞吐量和容量
那怎么搞?设计个分布式的系统呗,参照一下kafka的设计理念,broker->topic->partition,每个partition放一个机器,就存一部分数据。如果现在资源不够了,简单啊,给topic增加partition,然后做数据迁移,增加机器,不就可以存放更多数据,提供更高的吞吐量了3.2高可用集群分布式架构主从
3.2.1、rabbitmq高可用
rabbitmq有三种模式:单机模式,普通集群模式,镜像集群模式
3.2.1.1、单机模式
就是demo级别的,一般就是你本地启动了玩玩儿的,没人生产用单机模式
3.2.1.2、普通集群模式
就是在多台机器上启动多个rabbitmq实例,每个机器启动一个。但是你创建的queue,只会放在一个rabbtimq实例上,但是每个实例都同步queue的元数据。完了你消费的时候,实际上如果连接到了另外一个实例,那么那个实例会从queue所在实例上拉取数据过来。
这种方式确实很麻烦,也不怎么好,没做到所谓的分布式,就是个普通集群。因为这导致你要么消费者每次随机连接一个实例然后拉取数据,要么固定连接那个queue所在实例消费数据,前者有数据拉取的开销,后者导致单实例性能瓶颈。
而且如果那个放queue的实例宕机了,会导致接下来其他实例就无法从那个实例拉取,如果你开启了消息持久化,让rabbitmq落地存储消息的话,消息不一定会丢,得等这个实例恢复了,然后才可以继续从这个queue拉取数据。
所以这个事儿就比较尴尬了,这就没有什么所谓的高可用性可言了,这方案主要是提高吞吐量的,就是说让集群中多个节点来服务某个queue的读写操作。
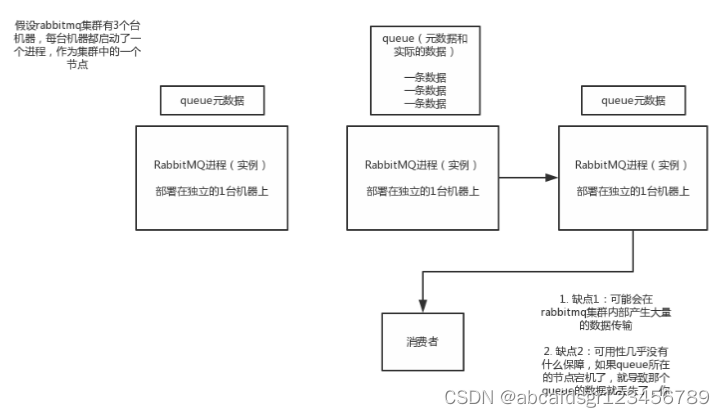
3.2.1.3、镜像集群模式
这种模式,才是所谓的rabbitmq的高可用模式,跟普通集群模式不一样的是,你创建的queue,无论元数据还是queue里的消息都会存在于多个实例上,然后每次你写消息到queue的时候,都会自动把消息到多个实例的queue里进行消息同步。
这样的话,好处在于,你任何一个机器宕机了,没事儿,别的机器都可以用。坏处在于,第一,这个性能开销也太大了吧,消息同步所有机器,导致网络带宽压力和消耗很重!第二,这么玩儿,就没有扩展性可言了,如果某个queue负载很重,你加机器,新增的机器也包含了这个queue的所有数据,并没有办法线性扩展你的queue
那么怎么开启这个镜像集群模式呢?我这里简单说一下,避免面试人家问你你不知道,其实很简单rabbitmq有很好的管理控制台,就是在后台新增一个策略,这个策略是镜像集群模式的策略,指定的时候可以要求数据同步到所有节点的,也可以要求就同步到指定数量的节点,然后你再次创建queue的时候,应用这个策略,就会自动将数据同步到其他的节点上去了。
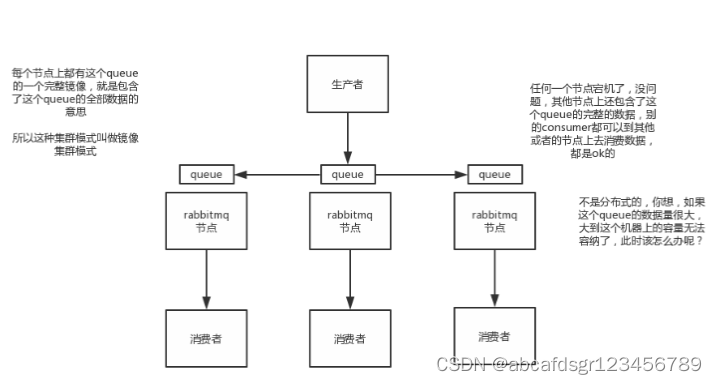
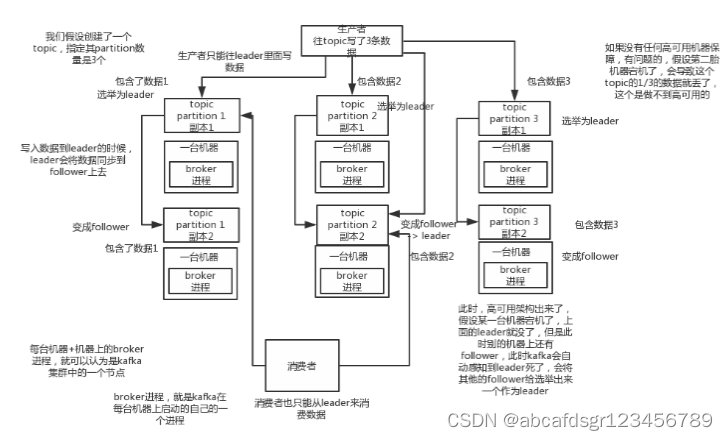
3.2.2、kafka高可用kafka
一个最基本的架构认识:多个broker组成,每个broker是一个节点;你创建一个topic,这个topic可以划分为多个partition,每个partition可以存在于不同的broker上,每个partition就放一部分数据。
这就是天然的分布式消息队列,就是说一个topic的数据,是分散放在多个机器上的,每个机器就放一部分数据。实际上rabbitmq之类的,并不是分布式消息队列,他就是传统的消息队列,只不过提供了一些集群、HA的机制而已,因为无论怎么玩儿,rabbitmq一个queue的数据都是放在一个节点里的,镜像集群下,也是每个节点都放这个queue的完整数据。
kafka0.8以前,是没有HA机制的,就是任何一个broker宕机了,那个broker上的partition就废了,没法写也没法读,没有什么高可用性可言。
kafka0.8以后,提供了HA机制,就是replica副本机制。每个partition的数据都会同步到吉他机器上,形成自己的多个replica副本。然后所有replica会选举一个leader出来,那么生产和消费都跟这个leader打交道,然后其他replica就是follower。写的时候,leader会负责把数据同步到所有follower上去,读的时候就直接读leader上数据即可。只能读写leader?很简单,要是你可以随意读写每个follower,那么就要care数据一致性的问题,系统复杂度太高,很容易出问题。kafka会均匀的将一个partition的所有replica分布在不同的机器上,这样才可以提高容错性。
这么搞,就有所谓的高可用性了,因为如果某个broker宕机了,没事儿,那个broker上面的partition在其他机器上都有副本的,如果这上面有某个partition的leader,那么此时会重新选举一个新的leader出来,大家继续读写那个新的leader即可。这就有所谓的高可用性了。
写数据的时候,生产者就写leader,然后leader将数据落地写本地磁盘,接着其他follower自己主动从leader来pull数据。一旦所有follower同步好数据了,就会发送ack给leader,leader收到所有follower的ack之后,就会返回写成功的消息给生产者。
(当然,这只是其中一种模式,还可以适当调整这个行为)消费的时候,只会从leader去读,但是只有一个消息已经被所有follower都同步成功返回ack的时候,这个消息才会被消费者读到。
3.3、顺序性
文本追加
时序数据库
1个消费者
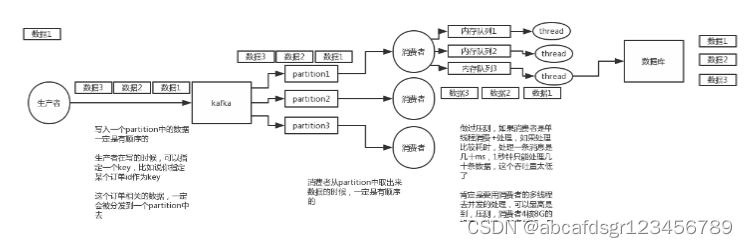
你在mysql里增删改一条数据,对应出来了增删改3条binlog,接着这三条binlog发送到MQ里面,到消费出来依次执行,起码得保证人家是按照顺序来的吧?不然本来是:增加、修改、删除;你楞是换了顺序给执行成删除、修改、增加,不全错了么。
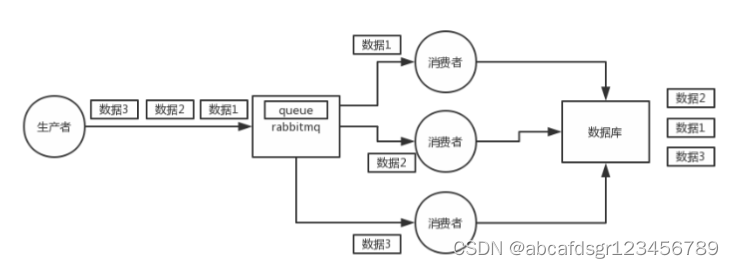
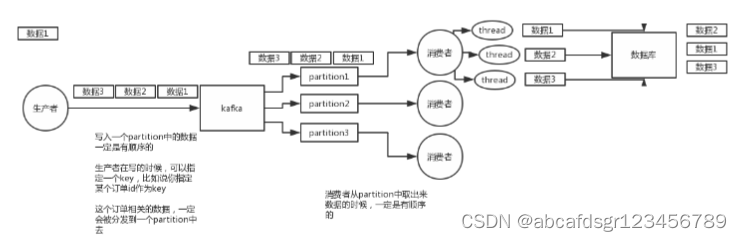
先看看顺序会错乱的俩场景
rabbitmq:一个queue,多个consumer,这不明显乱了
kafka:一个topic,一个partition,一个consumer,内部多线程,这不也明显乱了
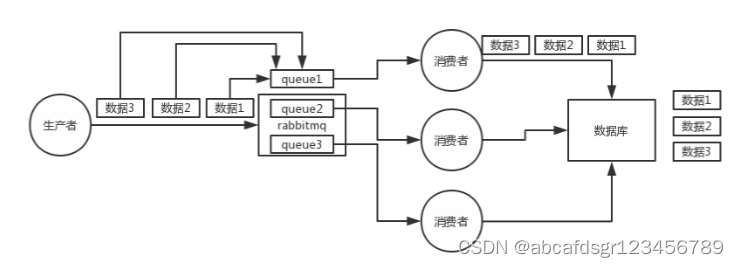
那如何保证消息的顺序性呢
rabbitmq:拆分多个queue,每个queue一个consumer,就是多一些queue而已,确实是麻烦点;或者就一个queue但是对应一个consumer,然后这个consumer内部用内存队列做排队,然后分发给底层不同的worker来处理
kafka:一个topic,一个partition,一个consumer,内部单线程消费,写N个内存queue,然后N个线程分别消费一个内存queue即可
3.4、可靠性可靠性:如何防止数据丢失,重复、幂等
持久化
应答
消息ID
生成者,在哪些情况下会丢失数据?如何防止?
消费者,在哪些情况下会丢失数据?如何防止?
3.6、高性能(吞吐量)持久化顺序读写内存存储零拷⻉
智能推荐
Python3 socket BlockingIOError: [Errno 11] Resource temporarily unavailable解决方案-程序员宅基地
文章浏览阅读8.9k次。在实用python3进行socket做图传时产生BlockingIOError: [Errno 11]先给出解决方案:报错部分来自与socket的client.recv(buf_size)部分;在接收的处理部分添加try: #client.recv(buf_size)的整个处理部分 不用担心会丢失数据except BlockingIOError: co...
TX2 摄像头CSI(一)_工业相机 连接tx2-程序员宅基地
文章浏览阅读1.9k次。最近发现不少Jetson TX2用户都在考虑如何选择相机,尤其是关于CSI相机。Lady我在网上找到一篇不错的文章,来自于一位软件工程师,分享给大家https://cloud.tencent.com/developer/article/1151984在本文里,他将重点告诉大家:为什么用CSI相机如果您希望获得最佳性能(根据FPS,分辨率和CPU使用情况),或者需要对摄像机进行底层控制,并且您愿意支付一台摄像机,CSI摄像机应该是您的摄像机的主要选择这些功能的优质。我个人使用CSI相机,因为我需要高_工业相机 连接tx2
线程变量ThreadLocal的使用和分析_线程对象如何引用threadlocal变量-程序员宅基地
文章浏览阅读169次。一、ThreadLocal的基本使用 // 创建一个ThreadLocal对象 final static ThreadLocal<String> mThreadLocal = new ThreadLocal<>(); @Test public void myThread() { new Thread() { @Override public void run() { _线程对象如何引用threadlocal变量
【转载】mybatis 解决 java.lang.Integer cannot be cast to java.lang.String_mybatis升级后 jdbctype=integer无法支持string了-程序员宅基地
文章浏览阅读1.1k次。转载于:https://www.cnblogs.com/chongyou/p/9052834.html1.在执行代码打印map的value时,提示错误java.lang.Integer cannot be cast to java.lang.String,这个错误很明显是类型转换错误查看表字段的数据解决方案:?12345671 .直接使用tosting的方式//方法二:Integer类的成员方法toString()String str = entry.value().toS_mybatis升级后 jdbctype=integer无法支持string了
electron-vue打包借助Inno Setup打包成可执行文件_win-unpacked 打安装包-程序员宅基地
文章浏览阅读827次。1.使用yarn build将程序打包成安装包形式在程序文件中的build文件夹中的win-unpacked中2.下载工具下载软件Inno Setup,这是官网https://jrsoftware.org/isdl.php安装好了之后打开软件,点击取消点击文件–>新建,点击下一步输入程序名称、版本、发布者下一步默认,不需要修改选择文件和安装包文件夹下一步默认选项下一步没有许可证文件跳过,直接下一步默认选项选择安装时支持的语言_win-unpacked 打安装包
vmware虚拟机安装gho版本系统_虚拟机安装本机的gho-程序员宅基地
文章浏览阅读4.6k次。首先下载winpe选择第二个进入pe接着选择分区工具选择快速分区选择4K的扇区分好之后就是2个,并关机开始映射到本地,加载win7Gho文件,去掉只读开始——运行,输入:gpedit.msc回车,双击本地计算机策略的【windows设置】——安全设置——本地策略——安全选项–双击【用户账户控制:以管理员批准模式运行所有管理员】,点击禁用,重启..._虚拟机安装本机的gho
随便推点
css简洁的table样式_CSS3简洁整洁的标头部分-程序员宅基地
文章浏览阅读515次。css简洁的table样式Neat and modern header section with CSS3 Have you thought about remaking your website header section? As you know – this is the most important section of any website. First of all, all vi..._css table
plsql查看数据库服务器信息,plsql服务器查询数据库连接-程序员宅基地
文章浏览阅读2.6k次。plsql服务器查询数据库连接 内容精选换一换CDM目前支持迁移以下关系型数据库:数据仓库服务(DWS)云数据库 MySQL云数据库 PostgreSQL云数据库 SQL ServerMySQLPostgreSQLMicrosoft SQL ServerOracleIBM Db2FusionInsight LibrASAP HANAMYCAT达梦数据库 DM已参考管理驱动上传对应的驱待审计的数据库..._plsql查看数据库连接信息
斯威夫特山地车_斯威夫特枚举-程序员宅基地
文章浏览阅读334次。斯威夫特山地车In this tutorial, we’ll be discussing the basics of Swift enum. You must be familiar with Enumerations if you have a previous programming background. Enumerations in Swift are really powerful a..._山地车 swift
U-Net网络-程序员宅基地
文章浏览阅读1.1w次,点赞11次,收藏60次。U-Net在架构设计和其他利用卷积神经网络基于像素的图像分割方面更成功,对有限数据集的图像更有效。此次项目中,去除池化层和增加跳跃连接是一个很好的选择。池化层会丢失图像信息和降低图像分辨率且是不可逆的操作,对图像分割任务有一些影响。..._u-net
iOS关于键盘弹出后tableview的滑动问题-程序员宅基地
文章浏览阅读870次。在键盘处理的过程中,最容易出现问题的就是,在键盘监听事件中,tableView的frame的修改,网上分享的大部分都是修改frame,这样会导致tableView的cell被遮挡,可能引起获取不到cell的indexPath,导致无法滚动到指定位置还有一点就是UITableViewController的使用,如果直接使用UITableViewController,键盘弹出事件是不用我们开发..._ios开发 键盘弹出时tableview跳动
Python 编程语言,Python综合面试-程序员宅基地
文章浏览阅读1.1k次,点赞8次,收藏20次。不知道你们用的什么环境,我一般都是用的Python3.6环境和pycharm解释器,没有软件,或者没有资料,没人解答问题,都可以免费领取(包括今天的代码),过几天我还会做个视频教程出来,有需要也可以领取~给大家准备的学习资料包括但不限于:Python 环境、pycharm编辑器/永久激活/翻译插件python 零基础视频教程Python 界面开发实战教程Python 爬虫实战教程Python 数据分析实战教程python 游戏开发实战教程Python 电子书100本。