『Python学习笔记』Python实现并发编程(补充joblib和pymysql)_python 完成一个功能后,怎么实现并发和异步-程序员宅基地
技术标签: 并发 python Python学习笔记 pymysql joblib
| Python实现并发编程(补充joblib&pymysql) |
文章目录
- 大神文章:线程与进程,你真得理解了吗
- 大神文章:线程,进程,协程, 并发,并行,同步,异步概念解析
一. 并发编程知识点
1.1. 为什么引入并发编程
- 场景1:一个网络爬虫,按顺序爬取花了1小时,采用并发下载减少到20分钟!
- 场景2:一个APP应用,优化前每次打开页面需要3秒,采用异步并发提升到每次200毫秒;
- 引入并发编程的目的就是为了提升程序的运行速度!

- Python对并发编程的支持
- 多线程:threading,利用CPU和IO可以同时执行的原理,让CPU不会干巴巴等待IO完成
- 多进程:multiprocessing,利用多核CPU的能力,真正的并行执行任务
- 异步IO:asyncio,在单线程利用CPU和IO同时执行的原理,实现函数异步执行
- 使用Lock对资源加锁,防止冲突访问
- 便用Queue实现不同线程/进程之间的数据通信,实现生产者-消费者模式
- 使用线程池Pool/进程池Pool,简化线程/进程的任务提交、等待结東、获取结果
- 使用subprocess启动外部程序的进程,并进行输入输出交互
1.2. 如何选择多线程多进程多协程
- Python并发编程有三种方式:多线程Thread、多进程Process、多协程Coroutine
- 多协程是新出的一个技术,性能会更好,但是要求库支持协程。
1.2.1. 什么是CPU密集型计算、IO密集型计算

1.2.2. 多线程、多进程、多协程的对比

1.2.3. 怎样根据任务选择对应技术?

1.3. Python速度慢的原因
1.3.1. Python慢的原因(动态,GIL)
- 相比
C/C+ +/JAVA,Python确实慢,在一些特殊场景下,Python比C++慢100~200倍- 由于速度慢的原因,很多公司的基础架构代码依然用C/C++开发,比如各大公司阿里/腾讯/快手的推荐引擎、搜索引擎、存储引擎等底层对性能要求高的模块。

1.3.2. 全局解释器锁(Global Interpreter Lock,GIL)

- 由于
GIL的存在,即使电脑有多核CPU,单个时刻也只能使用1个,相比并发加速的C++/JAVA所以慢
- Python这么牛逼的语言,为什么有GIL这个软肋的存在呢?下面解释一下:
- 引入GIL是为了解决多线程之间数据完整性和数据同步的问题,Python中对象的管理是使用引用计数器进行的,引用数为0则释放对象。
- 真实模拟如下,线程A和线程B都引用了对象
obj,obj,ref_num=2,假设某一个时刻线程A和B都想撤销对obj的引用。对于线程A来说,首先执行ref_num--,变成1,可是在操作系统执行的过程中线程可以随时发生切换,假如这个时候发生多线程调度切换,切换到了线程B,B首先将ref_num--,变成0,线程B检测到这个ref_num==0了,释放obj对象。这个时候又发生多线程调度切换,切换到了线程A,这个时候发现ref_num==0,这个时候obj在内存中已经不存在了,这个时候程序会报错。- 在此基础上Python进行了封装,解决了这些问题,这就是为什么GIL的存在了,它简化了Python对共享资源的管理。

1.3.3. 怎样规避GIL带来的限制

二. 并发编程实战
2.1. 多线程加速爬虫
2.1.1. 理解一下多线程(重要)
- 下面的运行时间为什么是0呢? 正常按照我们的理解,两个线程并行它应该是2s呀,是因为我们在运行.py文件的时候,我们这里创建了2个线程thread,还有一个线程就是主线程,虽然两个线程运行起来了,但是在下面脚本中运行了其它代码print(),它在主线程中运行的,所以一共有3个线程,其中有一个
mainThread主线程,线程之间既然可以并行,就意味着程序thread1,thread2开始之后,在sleep之前就主线程仍然可以往下执行print。- 但是主线程执行完之后程序并没有退出,如果主线程退出的话,就不会打印出end了,主线程一旦退出,进程也就退出了,end是执行不到了。

import threading
import time
# 比如爬虫,简单写一些
def get_detail_html(url):
""" 模拟获取html,当成网络请求 """
print("get detail html started")
time.sleep(2)
print("get detail html end")
def get_detail_url(url):
""" 模拟获取url"""
print("get detail url started")
time.sleep(2)
print("get detail url end")
if __name__ == '__main__':
thread1 = threading.Thread(target=get_detail_html, args=("",), name="html")
thread2 = threading.Thread(target=get_detail_url, args=("",), name="url")
start_time = time.time()
thread1.start()
thread2.start()
print("last time: {}".format(time.time() - start_time))
# 运行结果:
get detail html startedget detail url started
last time: 0.0003478527069091797
get detail html end
get detail url end
- 为了解决上面主线程和其它线程并行执行了,我们希望在两个线程执行完毕再执行主线程,这个时候只需要在前面加上
thread1.join(), thread2.join(),这样就会在此位置就行阻塞,它等待两个线程完成之后才会执行下面print时间的地方。
2.1.2. Python创建多线程的方法
- 1. 准备一个函数
def my_func(a, b):
do_craw(a, b)
- 2. 怎样创建一个线程
import threading
t = threading.Thread(target=my_func, args(100, 200)) # 创建一个线程对象,args是一个元组
- 3. 启动线程
t.start()
- 4. 等待结束
t.join() # 等到线程结束
2.1.3. 代码实现
- 单线程执行过程中是顺序执行的,多线程执行不是顺序执行的,系统按照自己的规则调度的!
import time
import requests
import threading
import functools
urls = [
f"https://www.cnblogs.com/#{
page}"
for page in range(1, 51)
]
def craw(url):
r = requests.get(url)
# print(url, len(r.text))
# craw(urls[0])
def timer(func):
""" 计时器装饰器 """
@functools.wraps(func)
def wrapper(*args, **kwargs):
start = time.time()
func(*args, **kwargs)
end = time.time()
print("{} takes {} seconds".format(func.__name__, end - start))
return wrapper
@timer
def single_thread():
""" 单线程版本 """
print("single_thread start")
for url in urls:
craw(url)
print("single_thread end")
@timer
def multi_thread():
""" 多线程版本 """
print("multi_thread start")
thread_list = []
# 1. 创建多个线程
for url in urls: # 对于每个url我都启动一个线程
thread_list.append(
threading.Thread(target=craw, args=(url,)) # 元组逗号
)
# 2. 启动线程
for thread in thread_list: # 启动50个线程
thread.start()
# 3. 等待结束
for thread in thread_list: # 等待结束
thread.join()
print("multi_thread end")
if __name__ == '__main__':
single_thread()
multi_thread()
# 执行结果
single_thread start
single_thread end
single_thread takes 5.113051891326904 seconds
multi_thread start
multi_thread end
multi_thread takes 1.73423171043396 seconds
2.2. Python实现生产者消费爬虫
2.2.1 多组件的Pipeline技术架构
- 通常复杂的事情一般都不会一下子做完,而是会分很多中间步骤一步步完成,如下例子:由输入数据得到输出数据中间会经过很多的模块,而且模块之间会通过中间数据进行交互,这些不同的处理模块叫做处理器,比如编号1,编号X,编号N很多个。把一件事分成很多处理模块的架构叫做Pipeline,每个处理模块也有一个名字叫Process。
- 其实生产者消费者就是典型的Pipeline,有2个角色生产者和消费者,生产者生产的结果会通过中间数据交给消费者进行消费。而生产者以数据数据作为原料,消费者以输出作为最终的数据数据。

2.2.2 生产者消费者爬虫的架构
- 里面有2个Processor:
- 第1个Processor生产者获取待爬取的URL进行网页下载,下载好的内容放到网页队列中。
- 第2个Processor消费者从队列中获取数据,进行网页的解析,把结果进行存储,如商品价格、品牌。

2.2.3 多线程数据通信的queue.Queue
queue.Queue可以 用于多线程之间的、线程安全(线程安全指多个线程并发的访问数据不会出现冲突)的数据通信
# 1. 导入类库
import queue
# 2. 创建Queue
q = queue.Queue()
# 3. 添加元素
q.put(item)
# 4. 获取元素
item = q.get()
# 5. 查询状态
q.qsize() # 元素的大小
q.empty() # 判断是否为空
q.full() # 判断是否已满
2.2.4 代码实现
- 接着上一个例子,也是爬取网页,这里解析出文章的标题。
blog_spider.py如下
import time
import requests
import functools
from bs4 import BeautifulSoup
urls = [
f"https://www.cnblogs.com/#{
page}"
for page in range(1, 51)
]
def craw(url):
""" 爬取网页 """
r = requests.get(url)
return r.text
def parse(html):
""" 解析标题 """
# class="post-item-title"
soup = BeautifulSoup(html, "html.parser")
links = soup.find_all("a", class_="post-item-title")
# 标题和链接元组
return [(link["href"], link.get_text()) for link in links]
def timer(func):
""" 计时器装饰器 """
@functools.wraps(func)
def wrapper(*args, **kwargs):
start = time.time()
func(*args, **kwargs)
end = time.time()
print("{} takes {} seconds".format(func.__name__, end - start))
return wrapper
if __name__ == '__main__':
for result in parse(craw(urls[1])):
print(result)
producer_consumer_spider.py如下
import queue
import threading
import blog_spider
import time
import random
def do_craw(url_queue: queue.Queue, html_queue: queue.Queue):
"""
生产者:这是一个processor,它有两个参数输入队列和输出队列
"""
while True:
url = url_queue.get()
html = blog_spider.craw(url)
html_queue.put(html)
print(threading.currentThread().name, f"craw={
url}",
f"url_queue.size={
url_queue.qsize()}") # 打印一下当前线程的名字
time.sleep(random.randint(1, 2))
def do_parse(html_queue: queue.Queue, fout):
"""
消费者:这是一个processor,两个参数,写入到一个文件中
"""
while True:
html = html_queue.get()
results = blog_spider.parse(html)
for result in results:
fout.write(str(result) + "\n")
print(threading.currentThread().name, f"len(result)={
len(result)}",
f"url_queue.size={
url_queue.qsize()}") # 打印一下当前线程的名字
time.sleep(random.randint(1, 2))
if __name__ == '__main__':
url_queue = queue.Queue()
html_queue = queue.Queue()
for url in blog_spider.urls:
url_queue.put(url)
# 新建3个生产者线程
for idx in range(6):
t = threading.Thread(target=do_craw, args=(url_queue, html_queue), name=f"craw{
idx}")
t.start()
# 新建2个消费者线程
fout = open("o2.data.txt", "w")
for idx in range(2):
t = threading.Thread(target=do_parse, args=(html_queue, fout), name=f"parse{
idx}")
t.start()
- 最后程序卡住了,因为while True一直等待queue中的内容。
craw0 craw=https://www.cnblogs.com/#1 url_queue.size=44
craw1 craw=https://www.cnblogs.com/#2 url_queue.size=44
parse1 len(result)=2 parse0 len(result)=2 url_queue.size=44
url_queue.size=44
craw4 craw=https://www.cnblogs.com/#5 url_queue.size=44
craw2 craw=https://www.cnblogs.com/#3 url_queue.size=44
craw3 craw=https://www.cnblogs.com/#4 url_queue.size=44
craw5 craw=https://www.cnblogs.com/#6 url_queue.size=44
parse1 len(result)=2 url_queue.size=39
craw1 craw=https://www.cnblogs.com/#7 url_queue.size=39
craw2 craw=https://www.cnblogs.com/#9 url_queue.size=39
craw3 craw=https://www.cnblogs.com/#10 url_queue.size=39
craw5 craw=https://www.cnblogs.com/#11 url_queue.size=39
craw4 craw=https://www.cnblogs.com/#8 url_queue.size=39
parse0 len(result)=2 url_queue.size=38
craw0 craw=https://www.cnblogs.com/#12 url_queue.size=38
parse1 len(result)=2 url_queue.size=37
craw1 craw=https://www.cnblogs.com/#13 url_queue.size=34
craw2 craw=https://www.cnblogs.com/#14 url_queue.size=34
craw3 craw=https://www.cnblogs.com/#15 url_queue.size=34
craw5 craw=https://www.cnblogs.com/#16 url_queue.size=34
parse1 len(result)=2 url_queue.size=34
craw1 craw=https://www.cnblogs.com/#17 url_queue.size=31
craw4 craw=https://www.cnblogs.com/#18 url_queue.size=31
craw5 craw=https://www.cnblogs.com/#19 url_queue.size=31
parse0 len(result)=2 url_queue.size=30
craw0 craw=https://www.cnblogs.com/#20 url_queue.size=30
craw2 craw=https://www.cnblogs.com/#21 url_queue.size=28
craw3 craw=https://www.cnblogs.com/#22 url_queue.size=28
parse1 len(result)=2 url_queue.size=27
craw0 craw=https://www.cnblogs.com/#23 url_queue.size=26
craw4 craw=https://www.cnblogs.com/#25 url_queue.size=23
craw1 craw=https://www.cnblogs.com/#24 url_queue.size=23
craw3 craw=https://www.cnblogs.com/#26 url_queue.size=23
craw5 craw=https://www.cnblogs.com/#27 url_queue.size=23
parse0 len(result)=2 url_queue.size=23
parse1 len(result)=2 url_queue.size=23
craw0 craw=https://www.cnblogs.com/#28 url_queue.size=20
craw2 craw=https://www.cnblogs.com/#29 url_queue.size=20
craw1 craw=https://www.cnblogs.com/#31 url_queue.size=18
craw4 craw=https://www.cnblogs.com/#30 url_queue.size=18
craw3 craw=https://www.cnblogs.com/#32 url_queue.size=18
craw0 craw=https://www.cnblogs.com/#33 url_queue.size=15
craw2 craw=https://www.cnblogs.com/#34 url_queue.size=15
craw5 craw=https://www.cnblogs.com/#35 url_queue.size=14
craw4 craw=https://www.cnblogs.com/#36 url_queue.size=13
craw3 craw=https://www.cnblogs.com/#37 url_queue.size=13
parse0 len(result)=2 url_queue.size=13
parse1 len(result)=2 url_queue.size=13
craw0 craw=https://www.cnblogs.com/#38 url_queue.size=10
craw5 craw=https://www.cnblogs.com/#40 url_queue.size=8
craw1 craw=https://www.cnblogs.com/#39 url_queue.size=8
craw3 craw=https://www.cnblogs.com/#42 url_queue.size=8
craw4 craw=https://www.cnblogs.com/#41 url_queue.size=8
parse1 len(result)=2 url_queue.size=8
craw2 craw=https://www.cnblogs.com/#43 url_queue.size=7
craw0 craw=https://www.cnblogs.com/#44 url_queue.size=6
craw1 craw=https://www.cnblogs.com/#45 url_queue.size=4
craw4 craw=https://www.cnblogs.com/#46 url_queue.size=4
parse0 len(result)=2 url_queue.size=4
parse1 len(result)=2 url_queue.size=4
craw5 craw=https://www.cnblogs.com/#47 url_queue.size=3
craw3 craw=https://www.cnblogs.com/#48 url_queue.size=2
craw4 craw=https://www.cnblogs.com/#49 url_queue.size=1
parse0 len(result)=2 url_queue.size=1
parse1 len(result)=2 url_queue.size=1
craw2 craw=https://www.cnblogs.com/#50 url_queue.size=0
parse1 len(result)=2 url_queue.size=0
parse0 len(result)=2 url_queue.size=0
2.3. 线程安全问题与解决
2.3.1. 线程安全介绍
- 线程安全指某个函数、函数库在多线程环境中被调用时,能够正确地处理多个线程之间的共享变量,使程序功能正确完成。
- 由于线程的执行随时会发生切换,就造成了不可预料的结果,出现线程不安全

2.3.2. Lock用于解决线程安全问题

2.3.2. 代码实现
- 运行结果:有时候执行成功,有时候执行失败,如果在下面加一句sleep它会一直出问题,因为sleep语句一定会导致当前线程的阻塞,进行线程的切换。
import threading
import time
class Account:
""" 银行账户 """
def __init__(self, balance):
self.balance = balance
def draw(account: Account, amount):
""" 取钱 """
if account.balance > amount:
time.sleep(0.1)
print(threading.currentThread().name, "取钱成功")
account.balance -= amount
print(threading.currentThread().name, "余额", account.balance)
else:
print(threading.currentThread().name, "取钱失败, 余额不足")
if __name__ == '__main__':
account = Account(1000)
ta = threading.Thread(target=draw, args=(account, 800), name="ta")
tb = threading.Thread(target=draw, args=(account, 800), name="tb")
ta.start()
tb.start()
ta.join()
tb.join()
- 增加锁lock
import threading
import time
lock = threading.Lock()
class Account:
""" 银行账户 """
def __init__(self, balance):
self.balance = balance
def draw(account: Account, amount):
""" 取钱 """
with lock:
if account.balance > amount:
time.sleep(0.1)
print(threading.currentThread().name, "取钱成功")
account.balance -= amount
print(threading.currentThread().name, "余额", account.balance)
else:
print(threading.currentThread().name, "取钱失败, 余额不足")
if __name__ == '__main__':
account = Account(1000)
ta = threading.Thread(target=draw, args=(account, 800), name="ta")
tb = threading.Thread(target=draw, args=(account, 800), name="tb")
ta.start()
tb.start()
ta.join()
tb.join()
2.4. 好用的线程池
2.3.1. 线程池原理
- 新建线程系统需要分配资源、终止线程 系统需要回收资源,

- 如果可以重用线程,则可以减去新建/终止的开销(减少时间开销)。
- 线程池的原理本身就是基于重用线程这个原理来减少时间开销,具体如何流转的呢?
- 线程池由两部分组成:提前建立好的线程,这些线程会被重复地使用,同时还有一个 任务队列 的概念! 当新来一个任务,首先不是一个一个的创建线程,而是先放进一个任务队列,咱们创建好的线程挨着取出任务进行依次的执行,执行好这个任务之后,它会取下一个任务进行执行。

2.3.2. 使用线程池的好处

2.3.3. ThreadPoolExecutor的使用语法

2.3.4. 使用线程池改造爬虫代码
import concurrent.futures
import blog_spider
# craw
with concurrent.futures.ThreadPoolExecutor() as pool:
""" 用法1:map方式, 很简单"""
htmls = pool.map(blog_spider.craw, blog_spider.urls)
htmls = list(zip(blog_spider.urls, htmls))
for url, html in htmls:
print(url, len(html))
print("craw over")
# parse
with concurrent.futures.ThreadPoolExecutor() as pool:
""" 用法1:feature方式,更强大"""
features = dict()
for url, html in htmls:
feature = pool.submit(blog_spider.parse, html) # 它是一个一个提交的
features[feature] = url
# for feature, url in features.items(): # 方式1:输出有顺序
# print(url, feature.result())
for feature in concurrent.futures.as_completed(features): # 方式2:输出无顺序
url = features[feature]
print(url, feature.result())
print("parse over")
2.5. 多进程multiprocessing加速(重要)
2.5.1. 有了多线程threading,为什么还要用多进程mutiprocessing?
- 全局解释器锁GIL是计算机程序设计语言解释器用于同步线程的一种机制,它使得 任何时刻仅有一个线程在执行即便在多核心处理器上,使用 GIL 的解释器也只允许同一时间执行一个线程。所以对于CPU密集型计算,多线程反而会降低执行速度!

2.5.2. 多进程multiprocessing知识梳理
- multiprocessing模块就是python为了解决GIL缺陷引入的一个模块,原理是用多进程在多CPU上并行执行

2.5.3. 代码实战(单线程vs多线程vs多进程对比CPU密集型速度)

import time
import math
import functools
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor
import multiprocessing
PRIMES = [1, 2, 4, 5, 6, 112272535095293] * 5
def timer(func):
""" 计时器装饰器 """
@functools.wraps(func)
def wrapper(*args, **kwargs):
start = time.time()
func(*args, **kwargs)
end = time.time()
print("{} takes {} seconds".format(func.__name__, end - start))
return wrapper
def is_prime(num):
""" 判断一个数是否为素数 """
if num == 1:
return False
# 循环需要判断的次数
for i in range(2, int(math.sqrt(num) + 1)):
if num % i == 0:
return False
return True
@timer
def single_thread():
""" 单线程 """
for num in PRIMES:
is_prime(num)
@timer
def multi_thread():
""" 多线程 """
with ThreadPoolExecutor() as pool:
pool.map(is_prime, PRIMES)
@timer
def multi_process1():
""" 多进程 """
with ProcessPoolExecutor() as pool:
results = pool.map(is_prime, PRIMES)
print(list(results))
@timer
def multi_process2():
pool = multiprocessing.Pool()
results = pool.map(is_prime, PRIMES)
print(list(results))
pool.close()
@timer
def multi_process3():
pool = multiprocessing.Pool()
results = []
for num in PRIMES:
# pool.apply_async(is_prime, (num,))
results.append(pool.apply_async(is_prime, (num,)))
print([result.get() for result in results])
# print(list(results))
if __name__ == '__main__':
single_thread()
multi_thread()
multi_process1()
multi_process2()
multi_process3()
# 运行结果
single_thread takes 7.030707120895386 seconds
multi_thread takes 6.476134300231934 seconds
[False, True, False, True, False, True, False, True, False, True, False, True, False, True, False, True, False, True, False, True, False, True, False, True, False, True, False, True, False, True]
multi_process1 takes 2.2322838306427 seconds
[False, True, False, True, False, True, False, True, False, True, False, True, False, True, False, True, False, True, False, True, False, True, False, True, False, True, False, True, False, True]
multi_process2 takes 2.474424123764038 seconds
[False, True, False, True, False, True, False, True, False, True, False, True, False, True, False, True, False, True, False, True, False, True, False, True, False, True, False, True, False, True]
multi_process3 takes 2.73321795463562 seconds
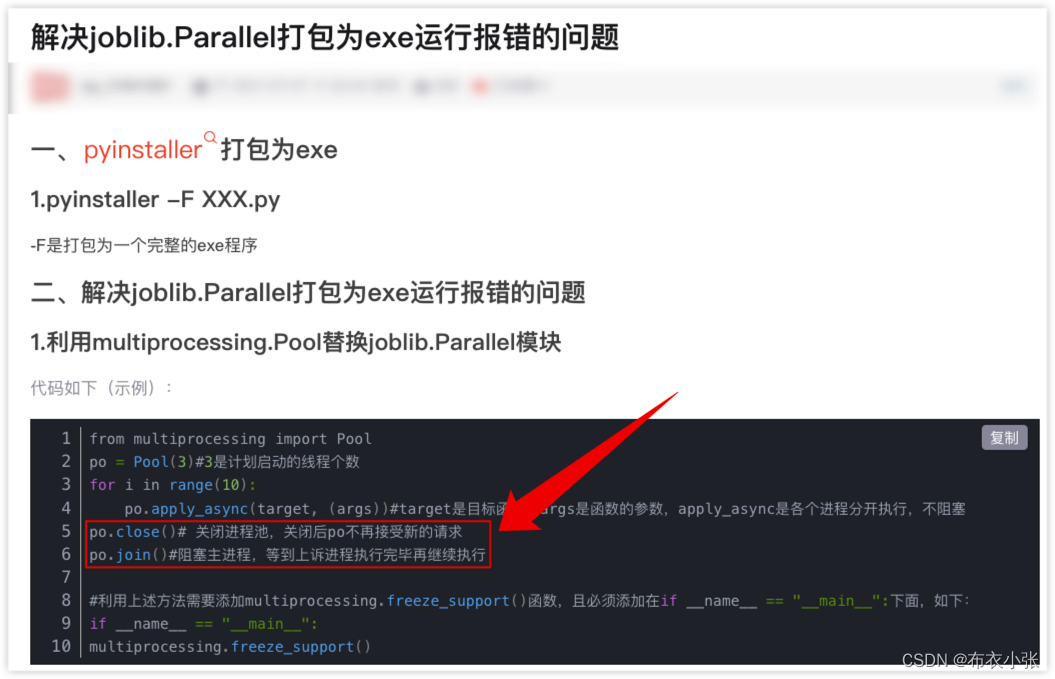
# 方案1:在用Pyinstaller打包的时候会报错,如果打包的话建议用方案2。
# n_jobs=-3表示使用比全部cpu少2个, 提供的有multiprocessing, threading, 一般而言,直接采用默认方式 loky 就好
# with parallel_backend('threading', n_jobs=4):
# Parallel()(delayed(qg_extract)(num, f_n_type, output) for num, f_n_type in
# enumerate(file_name_type_list))
# 方案2: apply_async是各个进程分开执行,不阻塞
pool = mp.Pool(8 if mp.cpu_count() > 10 else 4)
for num, file_name_type in enumerate(file_name_type_list):
pool.apply_async(qg_extract, (num, file_name_type, output,))
pool.close()
pool.join()

2.5.4. 多进程加进度条bar
- Python多进程打印进度条:https://cloud.tencent.com/developer/article/1617778

2.6. Flask服务中使用进程池
- 当你定义这个pool的时候,它所依赖的这些函数必须都已经声明完了,所以
process_pool = ProcessPoolExecutor()必须放在最下面,所有函数都声明完,才能正常使用。同时还要定义在if __name__ == '__main__':函数中。
import math
import json
import flask
from concurrent.futures import ProcessPoolExecutor
app = flask.Flask(__name__)
def is_prime(num):
""" 判断一个数是否为素数 """
if num == 1:
return False
# 循环需要判断的次数
for i in range(2, int(math.sqrt(num) + 1)):
if num % i == 0:
return False
return True
@app.route("/is_prime/<numbers>")
def api_is_prime(numbers):
number_list = [int(x) for x in numbers.split(",")] # 这是cpu密集型计算,多进程加速
results = process_pool.map(is_prime, number_list)
return json.dumps(dict(zip(number_list, results)))
if __name__ == '__main__':
process_pool = ProcessPoolExecutor()
app.run()

- 注意:对于多线程的使用其实非常灵活,你定义在哪里都可以,比较灵活,因为它共享当前进程的所有环境。但是在多进程在使用的过程中就遇到一些问题。而flask框架中使用多进程的方式在main函数里面,在app.run()之前初始化进程池,然后在所有的函数里就可以使用这个pool.map。
2.7. 异步IO实现并发爬虫(新知识asyncio)
- 单线程爬虫的执行路径

- 其中
超级循环不会一直等待,而是会执行下一个任务。

import time
import asyncio
import aiohttp
import blog_spider
# 1. 定义协程,注意异步的实现前面都加上了async
async def async_craw(url):
print("cral url: ", url)
async with aiohttp.ClientSession as session: # 定义一个异步对象
async with session.get(url) as response:
result = await response.text() # 获取内容,刚才提到await时候,超级循环不会一直等待,而会执行下一个任务
print(f"craw url: {
url}, {
len(result)})") # 这样的话携程就开发完了,协程就是在异步io中执行该函数
# 2. 获取事件循环
loop = asyncio.get_event_loop()
# 3. 创建task列表
tasks = [
loop.create_task(async_craw(url)) # 对每个url创建一个task
for url in blog_spider.urls
]
start = time.time()
loop.run_until_complete(asyncio.wait(tasks))
print("cost time is: ", time.time() - start)
2.8. 异步IO使用信号量爬虫并发度

import time
import asyncio
import aiohttp
import blog_spider
semaphore = asyncio.Semaphore(10) ####### 信号量,并发度设置10
# 1. 定义协程,注意异步的实现前面都加上了async
async def async_craw(url):
async with semaphore: #######
print("cral url: ", url)
async with aiohttp.ClientSession as session: # 定义一个异步对象
async with session.get(url) as response:
result = await response.text() # 获取内容,刚才提到await时候,超级循环不会一直等待,而会执行下一个任务
await asyncio.sleep(5)
print(f"craw url: {
url}, {
len(result)})") # 这样的话携程就开发完了,协程就是在异步io中执行该函数
# 2. 获取事件循环
loop = asyncio.get_event_loop()
# 3. 创建task列表
tasks = [
loop.create_task(async_craw(url)) # 对每个url创建一个task
for url in blog_spider.urls
]
start = time.time()
loop.run_until_complete(asyncio.wait(tasks))
print("cost time is: ", time.time() - start)
三. 并发编程(基于joblib包)
- Python的并行远不如Matlab好用。比如Matlab里面并行就直接把for改成parfor就行(当然还要注意迭代时下标的格式),而Python查 一查并行,各种乱七八糟的方法一大堆,而且最不爽的一点就是只能对函数进行并行。
- 大名鼎鼎的sklearn里面集成了很方便的并行计算,仔细查看其代码发现就是用 joblib实现 的,并且用法还挺巧
# !/usr/bin/env python
# -*- encoding: utf-8 -*-
import time
import numpy as np
from numba import jit
from joblib import Parallel, delayed
# @jit(nopython=True) # jit,numba装饰器中的一种
def test_mvar(a, b):
a = np.random.rand(10, 10)
b = np.random.rand(10, 10)
return np.matmul(a, b)
start = time.time()
maxlen = 100000
# 指定5个CPU(默认是分配给不同的CPU), 一般而言,直接采用默认方式loky就好。
parallel = Parallel(n_jobs=5, backend='multiprocessing') # 提供的有 multiprocessing, threading, finally
# delayed(sqrt)表示要用的函数是sqrt,这里这种用法就非常类似C++里面的委托(delegate)。
out = parallel(
delayed(test_mvar)(i, j) for i, j in zip(np.random.rand(maxlen), np.random.rand(maxlen))
)
# print(out)
print(time.time() - start)
# multiprocessing耗时: 3.5902414321899414
# loky耗时: 10.363945722579956
- numba支持的东西很有限,意义不大。

- Python之并行–基于joblib:https://blog.csdn.net/cauchy7203/article/details/107545490
- numba,让python速度提升百倍:https://zhuanlan.zhihu.com/p/78882641
- 使用joblib库,通过并发提升pandas计算效率
- Documentation:https://joblib.readthedocs.io/en/latest/index.html
- Joblib 基本使用方法简介:https://blog.csdn.net/sinat_39434559/article/details/125965767
四. Python连接Mysql数据库
- Python连接Mysql数据库:https://blog.csdn.net/Kqs19513500676/article/details/123750419
- 【Python之pymysql库学习】4.数据表插入多条数据(保姆级图文+实现代码):https://blog.csdn.net/u011027547/article/details/122520776
# !/usr/bin/env python
# -*- encoding: utf-8 -*-
"""====================================
@Project: wuhan
@Author : kaifang zhang
@Date : 2022/11/21 15:06
@Contact: [email protected]
====================================="""
import pymysql
import datetime
import pandas as pd
chinese2englist = {
'合江门': 'yibin', '白沙湾': 'jiangan', '泸州站': 'luzhou', '朱沱站': 'zhutuo', '寸滩站': 'cuntan',
'长寿站': 'changshou', '涪陵站': 'fuling', '万州站': 'wanzhou', '奉节站': 'fengjie', '秭归': 'zigui',
'宜昌': 'yichang', '李家渡': 'zhijiang', '沙市(杨陵矶)': 'shashi', '郝穴': 'zhougongdi', '监利': 'jianli',
'城陵矶': 'chenglingji', '莫家河': 'mojiahe', '汉口': 'hankou', '黄石': 'huangshi', '九江': 'jiujiang',
'安庆': 'anqing', '铜陵': 'tongling', '芜湖': 'wuhu', '南京': 'nanjing', '镇江': 'zhenjiang'
}
# 打开数据库连接
db = pymysql.connect(host='192.168.90.202',
port=3306,
user='root',
passwd='root@1298',
db='waterPredict',
charset='utf8'
)
# 使用cursor()方法获取操作游标
cursor = db.cursor()
def select_data(start, end):
""" 查询指定日期的数据 """
sql = '''
select * from bas_water_level_copy1
where measure_time between '{}' and '{}'
'''.format(start, end)
try:
cursor.execute(sql) # 执行SQL语句
results = cursor.fetchall() # 获取所有记录列表
for row in results:
print(row)
except pymysql.MySQLError as e:
print(f"查询数据失败,{
e}")
def delete_data(start, end):
""" 删除指定当天的数据 """
sql = '''
delete from bas_water_level_copy1
where measure_time between '{}' and '{}'
'''.format(start, end)
try:
cursor.execute(sql) # 执行sql语句
db.commit() # 提交事务
print('删除数据成功')
except pymysql.MySQLError as e:
db.rollback()
print(f'删除数据失败,{
e}')
def insert_data(data):
""" 批量添加数据到mysql数据库中 """
sql = '''
insert into bas_water_level_copy1 (site_name,measure_time,measure_water_85,site_name_en)
value (%s,%s,%s,%s)
'''
try:
cursor.executemany(sql, data) # 执行sql语句
db.commit() # 提交到数据库执行
print('插入多条数据成功')
except pymysql.MySQLError as e:
db.rollback() # 如果发生错误则回滚
print(f'插入多条数据失败,{
e}')
def read_xlsx(filepath):
""" 读取当天水位数据 """
today_data = pd.read_excel(filepath)[['站点名称', '测量时间', '输出水位85']]
today_data = [row + [chinese2englist[row[0]]] for row in today_data.values.tolist()]
return today_data
def main():
# ------ 获取当前的时间
now = datetime.datetime.now()
today = now.strftime("%F %T")[:10]
yesterday = (now - datetime.timedelta(days=1)).strftime("%F %T")[:10]
filepath = "final_" + today + ".xlsx" # 文件路径
start = yesterday + " 09:00:00" # 开始日期
end = today + " 09:00:00" # 结束日期
# ------ 读取数据
data_list = read_xlsx(filepath)
# ------ 查询数据
select_data(start, end)
# ------ 删除数据
delete_data(start, end)
# # ------ 插入数据
insert_data(data_list)
db.close() # 关闭数据库连接
if __name__ == '__main__':
main()
智能推荐
Linux 下清空Oracle监听日志_linux清理oracle监听日志-程序员宅基地
文章浏览阅读3.5k次。Linux 下清空Oracle监听日志_linux清理oracle监听日志
R语言RCurl爬虫(多线程爬虫)-高评分豆瓣图书_rcurl 批量获取url-程序员宅基地
文章浏览阅读2.6k次,点赞4次,收藏22次。R语言爬虫-高评分图书(豆瓣)# R语言爬虫-高评分图书(豆瓣)本篇文章依然延续之前的爬虫类型文章,多次实操有助于对于代码的理解和技术的提升。此次爬取的是豆瓣上高评分的图书,每一次爬取都会给大家提供一份有价值、有意义的东西,每一次都有所提升,我是ERIC,希望喜欢这方面技术的或者对于发表的内容感兴趣都可以相互交流,共同提升。 (此篇爬虫数据采集后只进行了简单的可视化分析,未进..._rcurl 批量获取url
去掉txt文件内的换行符-程序员宅基地
文章浏览阅读5.8k次。在txt文件内,直接用^p来搜索换行符并不行,所以有时候面对很多行数字(如手机号)的时候,如果想去掉换行符,我就粘贴到word里,再替换。但是这样效率很慢,粘一万条手机号都要等很久,后来通过搜索找到一个好办法,把txt文件另存为html文件,里边的换行符就会删除掉,变成了空格,这时候我们只要把html文件里内容重新粘回txt文档,把空格替换掉就可以了,速度很快。转载于:https..._txt里有怎么消除
SpotMicro 12自由度四足机器人制作(两套方案)-程序员宅基地
文章浏览阅读4k次,点赞8次,收藏56次。提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档文章目录前言一、方案确立二、使用步骤1.引入库2.读入数据总结前言老板想做个大号的四足,让我先做个小的练练手,两套方案均基于树莓派。一、方案确立大致情况如下方链接所示。前面的动态图是基于ROS-kinectic系统,后面的图是树莓派原生系统。二、使用步骤1.引入库代码如下(示例):import numpy as npimport pandas as pdimport matplotlib.pyplot as plti_spotmicro
【愚公系列】2023年07月 Python自动化办公之win32com操作excel-程序员宅基地
文章浏览阅读6k次。python中能操作Excel的库主要有以下9种:本文主要针对win32com读取 写入 修改 操作Excel进行详细介绍win32com是Python的一个模块,它提供了访问Windows平台上的COM组件和Microsoft Office应用程序的能力。通过该模块,Python程序可以与Windows平台上的其他应用程序交互,例如实现自动化任务、自动化报告生成等功能。_win32com
sql审核工具 oracle,Oracle SQL Developer工具-程序员宅基地
文章浏览阅读326次。Oracle SQL Developer工具下载解压了Oracle SQL Developer工具,运行时,启动不了,报错信息如下:---------------------------Unable to create an instance of the Java Virtual MachineLocated at path:\jdk\jre\bin\client\jvm.dll--------..._开源oracle sql审核工具
随便推点
Hack the BTRSys1(Boot2Root Challenge)【VulnHub靶场】渗透测试实战系列1_welcome to the boot2root ctf, morpheus:1. you play-程序员宅基地
文章浏览阅读1.2k次。靶场下载地址:BTRSys: v1下载完毕之后直接导入到VMWare,看下设置了DHCP,那就在内网网段~~接着就打开内网的另外一台攻击机器Kali,首先搜集一下信息,Zenmap开始扫描,其实也就是nmap包装了一个UI界面。Okay,扫描结果出来了,看下图:主要提供了下面三个服务端口:vsftd,这个应该版本有点老,可以exploit一下,小本本记下来 ss..._welcome to the boot2root ctf, morpheus:1. you play trinity, trying to invest
antd date-picker 默认时间设置问题_a-date-picker 默认值-程序员宅基地
文章浏览阅读1.3w次,点赞7次,收藏8次。一.官网给出的例子<template> <div> <a-date-picker :default-value="moment('2015/01/01', dateFormat)" :format="dateFormat"/> <br /> <a-date-picker :default-value="moment('01/01/2015', dateFormatList[0])" :format="dateFormatList"/_a-date-picker 默认值
python已知两边求第三边_已知两边求第三边公式-程序员宅基地
文章浏览阅读2.4k次。各位家长好,我是家长无忧(jiazhang51.cn)专栏作者,七玥老师全文共计549字,建议阅读2分钟如果是三角形是直角三角形,了解两侧,可以用勾股定理求出第三边。如果是三角形是一般三角形(钝角、钝角三角形),那这一标准下只有求出第三边的范畴:两边之和超过第三边,两侧之差低于第三边。求边公式计算只了解两侧相同假如一个是底部一个是腰得话,这个是正三角形,第三边就等于腰。假如只了解等腰三角形腰长,那..._输入两边长度自动得出第三边长度 并排序
达梦数据库--学习总结-程序员宅基地
文章浏览阅读697次。达梦概述:1. 达梦:达梦数据库管理系统是达梦公司推出的具有完全自主知识产权的高性能数据库管理系统,简称DM。2. 2019年新一代达梦数据库管理系DM8发布。(二)特点:1. 通用性:达梦数据库管理系统兼容多种硬件体系,可运行于X86、X64、SPARC、POWER等硬件体系之上。2. 高性能:支持列存储、数据压缩、物化视图等面向联机事务分析场景的优化选项。3. 高可用:可配置数据守护系统(主备),自动快速故障恢复,具有强大的容灾处理能力。_达梦数据库
神经网络(优化算法)_nnet-程序员宅基地
文章浏览阅读1.2w次。神经网络(优化算法)人工神经网络(ANN),简称神经网络,是一种模仿生物神经网络的结构和功能的数学模型或计算模型。神经网络由大量的人工神经元联结进行计算。大多数情况下人工神经网络能在外界信息的基础上改变内部结构,是一种自适应系统。现代神经网络是一种非线性统计性数据建模工具,常用来对输入和输出间复杂的关系进行建模,或用来探索数据的模式。人工神经网络从以下四个方面去模拟人的智能行为:_nnet
<video>标签及属性说明_video标签-程序员宅基地
文章浏览阅读5.5w次,点赞56次,收藏300次。实例HTML <video> 标签一段简单的 HTML5 视频:<video src="video.mp4" controls="controls">您的浏览器不支持 video 标签。</video>属性性 值 描述 autoplay autoplay 如果出现该属性,则视频在就绪后马上播放。 controls controls 如果出现该属性,则向用户显示控件,比如播放按钮。 height_video标签