附源码|paddle paddle实现猫狗识别_paddle 犬只识别-程序员宅基地
技术标签: python 深度学习 paddle paddle
本文是基于paddle paddle采用CNN实现猫狗识别案例。
author:小黄
缓慢而坚定的生长
图像分类是根据图像的语义信息将不同类别图像区分开来,是计算机视觉中重要的基本问题
猫狗分类属于图像分类中的粗粒度分类问题
step1.数据准备
#导入需要的包
import paddle as paddle
import paddle.fluid as fluid
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
import os
(1)数据集介绍
我们使用CIFAR10数据集。CIFAR10数据集包含60,000张32x32的彩色图片,10个类别,每个类包含6,000张。其中50,000张图片作为训练集,10000张作为验证集。这次我们只对其中的猫和狗两类进行预测。
(2)train_reader和test_reader
paddle.dataset.cifar.train10()和test10()分别获取cifar训练集和测试集
paddle.reader.shuffle()表示每次缓存BUF_SIZE个数据项,并进行打乱
paddle.batch()表示每BATCH_SIZE组成一个batch
(3)数据集下载
由于本次实践的数据集稍微比较大,以防出现不好下载的问题,为了提高效率,可以用下面的代码进行数据集的下载。
#!mkdir -p /home/aistudio/.cache/paddle/dataset/cifar/
#!wget “http://ai-atest.bj.bcebos.com/cifar-10-python.tar.gz” -O cifar-10-python.tar.gz
#!mv cifar-10-python.tar.gz /home/aistudio/.cache/paddle/dataset/cifar/
BATCH_SIZE = 128
#用于训练的数据提供器
train_reader = paddle.batch(
paddle.reader.shuffle(paddle.dataset.cifar.train10(),
buf_size=BATCH_SIZE * 100),
batch_size=BATCH_SIZE)
#用于测试的数据提供器
test_reader = paddle.batch(
paddle.dataset.cifar.test10(),
batch_size=BATCH_SIZE)
Step2.网络配置
(1)网络搭建
在CNN模型中,卷积神经网络能够更好的利用图像的结构信息。下面定义了一个较简单的卷积神经网络。显示了其结构:输入的二维图像,先经过两次卷积层到池化层,再经过全连接层,最后使用softmax分类作为输出层。
池化是非线性下采样的一种形式,主要作用是通过减少网络的参数来减小计算量,并且能够在一定程度上控制过拟合。通常在卷积层的后面会加上一个池化层。paddlepaddle池化默认为最大池化。是用不重叠的矩形框将输入层分成不同的区域,对于每个矩形框的数取最大值作为输出
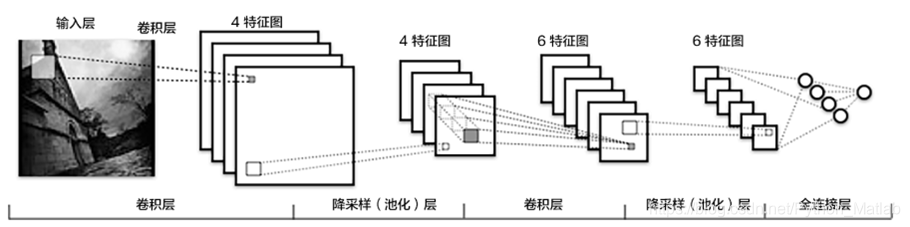
def convolutional_neural_network(img):
# 第一个卷积-池化层
conv_pool_1 = fluid.nets.simple_img_conv_pool(
input=img, # 输入图像
filter_size=5, # 滤波器的大小
num_filters=20, # filter 的数量。它与输出的通道相同
pool_size=2, # 池化核大小2*2
pool_stride=2, # 池化步长
act="relu") # 激活类型
# 第二个卷积-池化层
conv_pool_2 = fluid.nets.simple_img_conv_pool(
input=conv_pool_1,
filter_size=5,
num_filters=50,
pool_size=2,
pool_stride=2,
act="relu")
# 以softmax为激活函数的全连接输出层,10类数据输出10个数字
prediction = fluid.layers.fc(input=conv_pool_2, size=10, act='softmax')
return prediction
(2)定义数据
#定义输入数据
data_shape = [3, 32, 32]
images = fluid.layers.data(name='images', shape=data_shape, dtype='float32')
label = fluid.layers.data(name='label', shape=[1], dtype='int64')
(3)获取分类器
# 获取分类器,用cnn进行分类
predict = convolutional_neural_network(images
(4)定义损失函数和准确率
这次使用的是交叉熵损失函数,该函数在分类任务上比较常用。
定义了一个损失函数之后,还有对它求平均值,因为定义的是一个Batch的损失值。
同时我们还可以定义一个准确率函数,这个可以在我们训练的时候输出分类的准确率。
# 获取损失函数和准确率
cost = fluid.layers.cross_entropy(input=predict, label=label) # 交叉熵
avg_cost = fluid.layers.mean(cost) # 计算cost中所有元素的平均值
acc = fluid.layers.accuracy(input=predict, label=label) #使用输入和标签计算准确率
(5)定义优化方法
这次我们使用的是Adam优化方法,同时指定学习率为0.001
# 定义优化方法
optimizer =fluid.optimizer.Adam(learning_rate=0.001)
optimizer.minimize(avg_cost)
print("完成")
在上述模型配置完毕后,得到两个fluid.Program:fluid.default_startup_program() 与fluid.default_main_program() 配置完毕了。
参数初始化操作会被写入fluid.default_startup_program()
fluid.default_main_program()用于获取默认或全局main program(主程序)。该主程序用于训练和测试模型。fluid.layers 中的所有layer函数可以向 default_main_program 中添加算子和变量。default_main_program 是fluid的许多编程接口(API)的Program参数的缺省值。例如,当用户program没有传入的时候, Executor.run() 会默认执行 default_main_program 。
Step3.模型训练 and Step4.模型评估
(1)创建Executor
首先定义运算场所 fluid.CPUPlace()和 fluid.CUDAPlace(0)分别表示运算场所为CPU和GPU
Executor:接收传入的program,通过run()方法运行program。
place = fluid.CPUPlace()
exe = fluid.Executor(place)
exe.run(fluid.default_startup_program())
(2)定义数据映射器
DataFeeder 负责将reader(读取器)返回的数据转成一种特殊的数据结构,使它们可以输入到 Executor
feeder = fluid.DataFeeder( feed_list=[images, label],place=place)
(3)定义绘制训练过程的损失值和准确率变化趋势的方法draw_train_process
iter=0
iters=[]
train_costs=[]
train_accs=[]
def draw_train_process(iters, train_costs, train_accs):
title="training costs/training accs"
plt.title(title, fontsize=24)
plt.xlabel("iter", fontsize=14)
plt.ylabel("cost/acc", fontsize=14)
plt.plot(iters, train_costs, color='red', label='training costs')
plt.plot(iters, train_accs, color='green', label='training accs')
plt.legend()
plt.grid()
plt.show()
(3)训练并保存模型
Executor接收传入的program,并根据feed map(输入映射表)和fetch_list(结果获取表) 向program中添加feed operators(数据输入算子)和fetch operators(结果获取算子)。 feed map为该program提供输入数据。fetch_list提供program训练结束后用户预期的变量。
每一个Pass训练结束之后,再使用验证集进行验证,并打印出相应的损失值cost和准确率acc。
EPOCH_NUM = 3
model_save_dir = "/home/aistudio/data/catdog.inference.model"
for pass_id in range(EPOCH_NUM):
# 开始训练
train_cost = 0
for batch_id, data in enumerate(train_reader()): #遍历train_reader的迭代器,并为数据加上索引batch_id
train_cost,train_acc = exe.run(program=fluid.default_main_program(),#运行主程序
feed=feeder.feed(data), #喂入一个batch的数据
fetch_list=[avg_cost, acc]) #fetch均方误差和准确率
if batch_id % 100 == 0: #每100次batch打印一次训练、进行一次测试
print('Pass:%d, Batch:%d, Cost:%0.5f, Accuracy:%0.5f' %
(pass_id, batch_id, train_cost[0], train_acc[0]))
iter=iter+BATCH_SIZE
iters.append(iter)
train_costs.append(train_cost[0])
train_accs.append(train_acc[0])
# 开始测试
test_costs = [] #测试的损失值
test_accs = [] #测试的准确率
for batch_id, data in enumerate(test_reader()):
test_cost, test_acc = exe.run(program=fluid.default_main_program(), #运行测试程序
feed=feeder.feed(data), #喂入一个batch的数据
fetch_list=[avg_cost, acc]) #fetch均方误差、准确率
test_costs.append(test_cost[0]) #记录每个batch的误差
test_accs.append(test_acc[0]) #记录每个batch的准确率
test_cost = (sum(test_costs) / len(test_costs)) #计算误差平均值(误差和/误差的个数)
test_acc = (sum(test_accs) / len(test_accs)) #计算准确率平均值( 准确率的和/准确率的个数)
print('Test:%d, Cost:%0.5f, ACC:%0.5f' % (pass_id, test_cost, test_acc))
#保存模型
if not os.path.exists(model_save_dir):
os.makedirs(model_save_dir)
fluid.io.save_inference_model(model_save_dir,
['images'],
[predict],
exe)
print('训练模型保存完成!')
draw_train_process(iters, train_costs,train_accs)
Step5.模型预测
(1)创建预测用的Executor
infer_exe = fluid.Executor(place)
inference_scope = fluid.core.Scope()
(2)图片预处理
在预测之前,要对图像进行预处理。
首先将图片大小调整为32*32,接着将图像转换成一维向量,最后再对一维向量进行归一化处理。
def load_image(file):
#打开图片
im = Image.open(file)
im = im.convert('RGB')
#将图片调整为跟训练数据一样的大小 32*32, 设定ANTIALIAS,即抗锯齿.resize是缩放
im = im.resize((32, 32), Image.ANTIALIAS)
#建立图片矩阵 类型为float32
im = np.array(im).astype(np.float32)
#矩阵转置
im = im.transpose((2, 0, 1))
#将像素值从【0-255】转换为【0-1】
im = im / 255.0
#print(im)
im = np.expand_dims(im, axis=0)
# 保持和之前输入image维度一致
print('im_shape的维度:',im.shape)
return im
(3)开始预测
通过fluid.io.load_inference_model,预测器会从params_dirname中读取已经训练好的模型,来对从未遇见过的数据进行预测。
with fluid.scope_guard(inference_scope):
#从指定目录中加载 推理model(inference model)
[inference_program, # 预测用的program
feed_target_names, # 是一个str列表,它包含需要在推理 Program 中提供数据的变量的名称。
fetch_targets] = fluid.io.load_inference_model(model_save_dir,#fetch_targets:是一个 Variable 列表,从中我们可以得到推断结果。
infer_exe) #infer_exe: 运行 inference model的 executor
infer_path='/home/aistudio/data/dog.png'
img = Image.open(infer_path)
plt.imshow(img)
plt.show()
img = load_image(infer_path)
results = infer_exe.run(inference_program, #运行预测程序
feed={
feed_target_names[0]: img}, #喂入要预测的img
fetch_list=fetch_targets) #得到推测结果
print('results',results)
label_list = [
"airplane", "automobile", "bird", "cat", "deer", "dog", "frog", "horse",
"ship", "truck"
]
print("infer results: %s" % label_list[np.argmax(results[0])])
智能推荐
Mathorcup数学建模竞赛第五届-【妈妈杯】A题:基于群智能算法的改进 Webster 交通信号配时优化模型(附一等奖获奖论文和matlab代码实现)_交通配时代码-程序员宅基地
文章浏览阅读1.9k次。随着我国城市化速度的加快以及城市规模的不断扩大,交通供需矛盾日益突出,在城市交通网络中产生的交通拥堵现象日趋严重,严重影响了社会经济的发展和人民生活水平的提高。为了提高城市道路交通管理水平,改善城市交通秩序,保障公路交通的畅通与安全,当今世界各国普遍使用智能交通系统。在该系统中,核心的问题是交通信号智能控制。平面交叉口是道路交通的主要冲突点,不仅机动车数量多,而且行人和非机动车也在同一平面通过。目前在我国的大、中型城市交通管理中,普遍采用的是单点定时交通信号灯控制。_交通配时代码
SSL/TLS协议信息泄露漏洞(CVE-2016-2183)【原理扫描】远程桌面 3389 Windows 2016-程序员宅基地
文章浏览阅读2.1w次,点赞2次,收藏28次。前言 为了提高远程桌面的安全级别,保证数据不被***窃取,在Windows2003的最新补丁包SP1中添加了一个安全认证方式的远程桌面功能。通过这个功能我们可以使用SSL加密信息来传输控制远程服务器的数据,从而弥补了远程桌面功能本来的安全缺陷。2.问题描述在Windows server 2003和Windows server 2008,远程桌面服务SSL加密默认是关闭的,需要配置才可以使用;但 Windows server 2012默认是开启的,且有默认的CA证书。由于SSL/ TLS自身存在漏洞缺陷_ssl/tls协议信息泄露漏洞(cve-2016-2183)【原理扫描】
联通SGIP错误码-程序员宅基地
文章浏览阅读514次。错误码描述0无错误,命令正确接收1非法登录,如登录名、口令出错、登录名与口令不符等。2重复登录,如在同一TCP/IP连接中连续两次以上请求登录。3连接过多,指单个节点要求同时建立的连接数过多。4登录类型错,指bind命令中的logintype字段出错。 5 参数格式错,指命令中参数值与参数类型不符或与协议规定的范围不符。 6 非法手机号码,协议中所有手机..._sgip api接口响应 非法登录
Windows环境下安装Ruby教程_ruby.exe-程序员宅基地
文章浏览阅读6.7k次,点赞7次,收藏14次。安装背景:SASS是一种CSS的开发工具,提供了许多便利的写法,大大节省了设计者的时间,使得CSS的开发,变得简单和可维护。SASS是Ruby语言写的,但是两者的语法没有关系。不懂Ruby,照样使用。只是必须先安装Ruby,然后再安装SASS。然后我就安装了Ruby过程如下:首先打开Ruby的下载地址https://rubyinstaller.org/downloads/如果您不知道要安装..._ruby.exe
Integer和int的运算_integer加减乘除-程序员宅基地
文章浏览阅读2.4w次,点赞9次,收藏15次。自动包装&自动拆包Integer 是包装类,与int不是一种数据类型,本不能一起做运算,但是java设计了一种功能叫做自动包装。从java5.0版本以后开始提供了自动包装功能,可以简化编码简单理解就是包装类型和基本类型之间可以自动转换类型赋值。自动包装:将基本类型自动包装为包装类型;自动拆包:将包装类型自动转化为基本类型。举个例子:自动包装int m = 2;Inte..._integer加减乘除
HTML5中的video插件_html5 前端 video 兼容 格式转换插件-程序员宅基地
文章浏览阅读3.5k次,点赞2次,收藏2次。在HTML5中,新增了两个元素---video元素与audio元素。video元素专门用来播放网络上的视频或电影,而audio元素专门用来播放网络上的音频数据。使用这两个元素,就不在需要使用其他插件了,只需要支持HTML5的浏览器即可。今天,我们在这里就详细的说说video元素它(video)的作用是用于播放视频。它所主要支持的文件格式有webm、ogg、MP4、MP3、WAVE。它的用法..._html5 前端 video 兼容 格式转换插件
随便推点
树莓派C++开发机器人智能小车(11)超声波传感器连线和编程_超声波传感器避障算法 c++-程序员宅基地
文章浏览阅读717次。edu.51cto.com/sd/4920aHC-SR04传感器引脚由4个:VCC,GND,发射,echo, RPi和超声波传感器这样连接:连接传感器VCC引脚到引脚4 连接传感器GND引脚到引脚9 连接传感器Trig引脚到wiringPi引脚12传感器echo引脚经过分压器后连接到wiringPi引脚13。分压器电路的两个电阻分别是1KΩ和2KΩ。分压器电路用于把输入的5V信号降低到3.3V,避免烧坏主板,它是从echo引脚到RPi如下图:用于把输入电压转为3.3V的公式:._超声波传感器避障算法 c++
adb安装apk程序_adb install 安装apk-程序员宅基地
文章浏览阅读2.3k次。7.执行安装,如提示success即安装成功。其它错误请拍照发给我看。5.在最后输入adb所在完整路径,前面加上分好;_adb install 安装apk
十三个经典算法研究与总结、目录+索引-程序员宅基地
文章浏览阅读10w+次,点赞167次,收藏1.5k次。十三个经典算法研究与总结、目录+索引「后续更新为十五个」 (PDF下载地址:http://download.csdn.net/detail/v_july_v/4478027)作者:July。时间:二零一零年十二月末-二零一一年四月初。出处:http://blog.csdn.net/v_JULY_v。声明:版权所有,侵权定究。------------------------------_经典算法
myeclipse工作目录上的.metadata文件夹可以删除_metadata可以删除吗-程序员宅基地
文章浏览阅读3.3k次。不能删除。看看文件夹下的内容就知道:1、me_tcat:是MyEclipse记录的当前工作空间中的配置,比如当前工作空间中有哪些工程,打开了哪些文件java类,编辑了哪些文件和Java类,MyEclipse会在启动时加载这个文件夹下的内容。如果删除了,再次打开MyEclipse会发现工作空间是空的,需要重新导入工程。2、plugins:当前工作空间用到了哪些IDE插件,和程程序无关_metadata可以删除吗
SeetaFace2 Android 平台编译_seetafacerecognizer2.0.ats-程序员宅基地
文章浏览阅读4.1k次。SeetaFace2 Android 平台编译项目地址:https://github.com/seetafaceengine/SeetaFace2SeetaFace2 人脸识别引擎包括了搭建一套全自动人脸识别系统所需的三个核心模块,即:人脸检测模块 FaceDetector、面部关键点定位模块 FaceLandmarker 以及人脸特征提取与比对模块 FaceRecognizer。面部关键点定位支持 5 点 和 81 点定位,两个辅助模块 FaceTracker 和 QualityAssessor 用_seetafacerecognizer2.0.ats
Oracle删除约束和主键的语句_oracle删除主键的sql语句-程序员宅基地
文章浏览阅读3.2w次,点赞4次,收藏34次。1.删除约束语句:alter table 表名 drop constraint 约束名;alter table mz_sf4 drop constraint pk_id1;2.删除主键语句:alter table 表名 drop primary key;alter table mz_sf3 drop primary key;如果出错:ORA-02273:此唯一主键已_oracle删除主键的sql语句