第五节“LMDeploy量化部署”笔记-程序员宅基地
技术标签: 笔记 书生·浦语大模型实战营——笔记
一、LMDeploy环境部署
Conda环境配置
Python 3.10环境
LMDeploy安装
pip install lmdeploy[all]==0.3.0
二、模型对话
模型托管与推理引擎
Hugging Face——针对深度学习模型和数据集的在线托管社区——HF格式——国内可以使用阿里巴巴的MindScope社区,或者上海AI Lab搭建的OpenXLab社区
TurboMind——LMDeploy团队开发的一款关于LLM推理的高效推理引擎
主要功能包括:LLaMa 结构模型的支持,continuous batch 推理模式和可扩展的 KV 缓存管理器。
TurboMind推理引擎仅支持推理TurboMind格式的模型。因此,TurboMind在推理HF格式的模型时,会首先自动将HF格式模型转换为TurboMind格式的模型。该过程在新版本的LMDeploy中是自动进行的,无需用户操作。
模型下载
InternLM2-Chat-1.8B的HF模型
使用Transformer库运行模型
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("/root/internlm2-chat-1_8b", trust_remote_code=True)
# Set `torch_dtype=torch.float16` to load model in float16, otherwise it will be loaded as float32 and cause OOM Error.
model = AutoModelForCausalLM.from_pretrained("/root/internlm2-chat-1_8b", torch_dtype=torch.float16, trust_remote_code=True).cuda()
model = model.eval()
inp = "hello"
print("[INPUT]", inp)
response, history = model.chat(tokenizer, inp, history=[])
print("[OUTPUT]", response)
inp = "please provide three suggestions about time management"
print("[INPUT]", inp)
response, history = model.chat(tokenizer, inp, history=history)
print("[OUTPUT]", response)
运行:python /root/pipeline_transformer.py
运行结果:
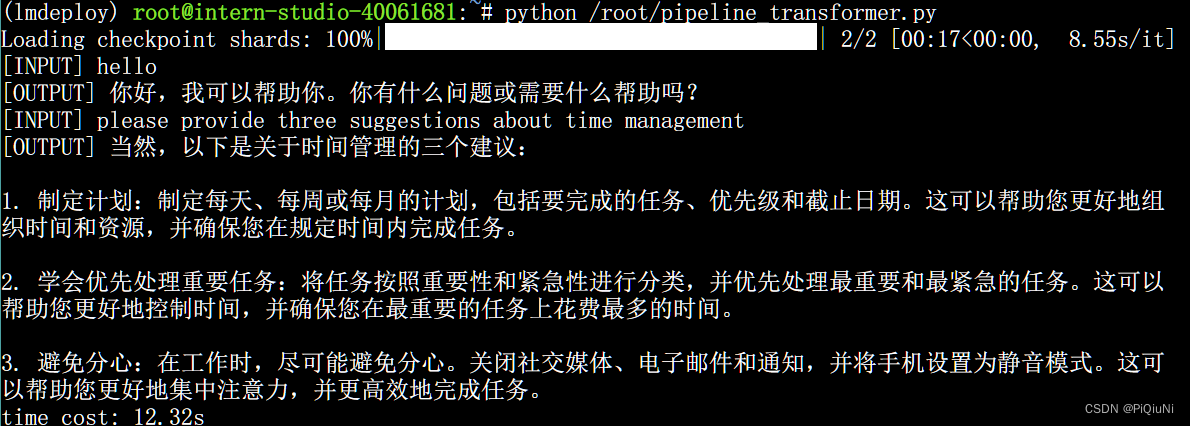
运行时间:12.32s
LMDeploy对话
lmdeploy chat /root/internlm2-chat-1_8b
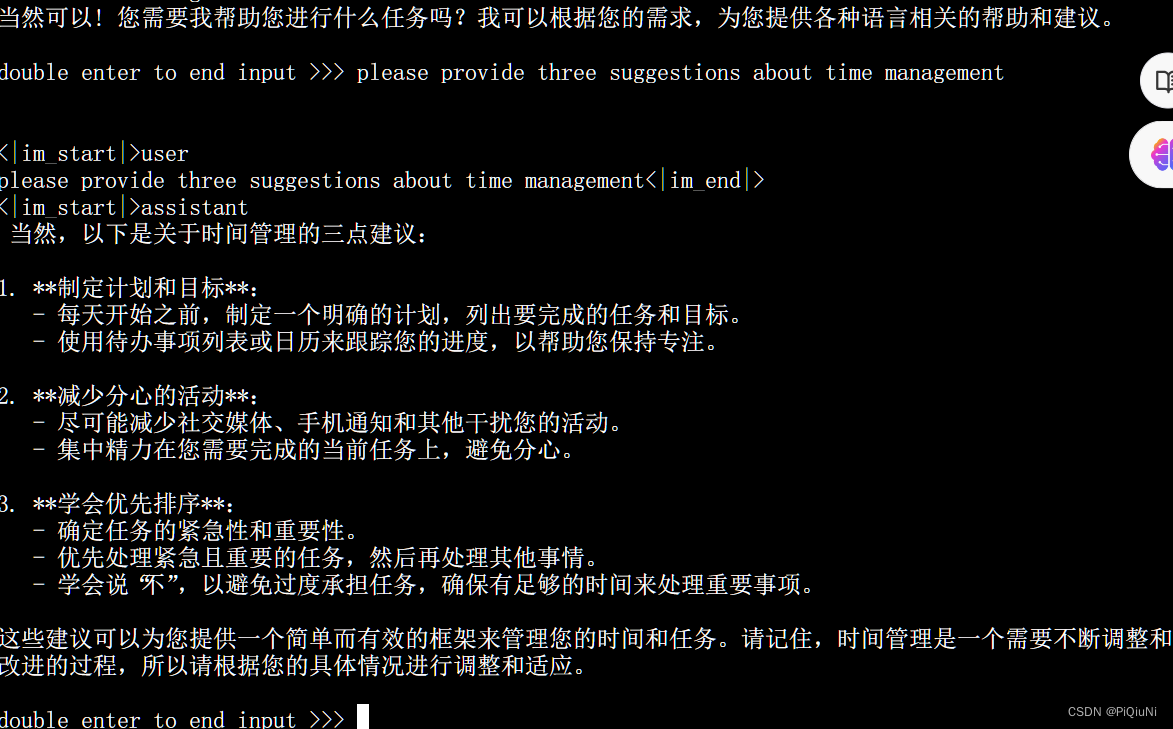
连续推理测试:
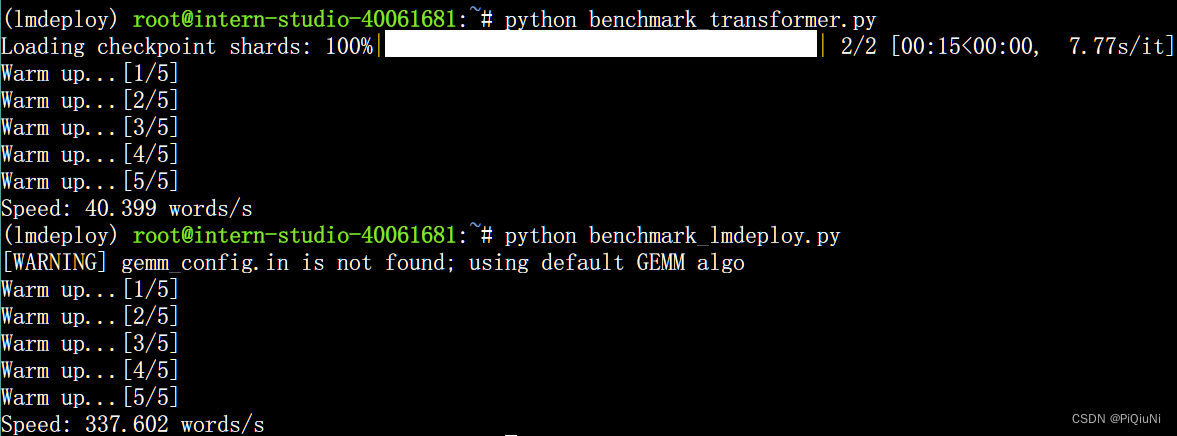
LMDeploy的推理速度约为337.6 words/s,是Transformer库的8倍。
三、模型量化
量化是一种以参数或计算中间结果精度下降换空间节省(以及同时带来的性能提升)的策略。
先介绍两个概念:
- 计算密集(compute-bound): 指推理过程中,绝大部分时间消耗在数值计算上;针对计算密集型场景,可以通过使用更快的硬件计算单元来提升计算速。
- 访存密集(memory-bound): 指推理过程中,绝大部分时间消耗在数据读取上;针对访存密集型场景,一般通过减少访存次数、提高计算访存比或降低访存量来优化。
常见的 LLM 模型由于 Decoder Only 架构的特性,实际推理时大多数的时间都消耗在了逐 Token 生成阶段(Decoding 阶段),是典型的访存密集型场景。
KV8量化是指将逐 Token(Decoding)生成过程中的上下文 K 和 V 中间结果进行 INT8 量化(计算时再反量化),以降低生成过程中的显存占用。
W4A16 量化,将 FP16 的模型权重量化为 INT4,Kernel 计算时,访存量直接降为 FP16 模型的 1/4,大幅降低了访存成本。Weight Only 是指仅量化权重,数值计算依然采用 FP16(需要将 INT4 权重反量化)。
设置最大KV Cache缓存大小
KV Cache是一种缓存技术,通过存储键值对的形式来复用计算结果,以达到提高性能和降低内存消耗的目的。
在大规模训练和推理中,KV Cache可以显著减少重复计算量,从而提升模型的推理速度。理想情况下,KV Cache全部存储于显存,以加快访存速度。当显存空间不足时,也可以将KV Cache放在内存,通过缓存管理器控制将当前需要使用的数据放入显存。
模型在运行时,占用的显存可大致分为三部分:模型参数本身占用的显存、KV Cache占用的显存,以及中间运算结果占用的显存。LMDeploy的KV Cache管理器可以通过设置–cache-max-entry-count参数,控制KV缓存占用剩余显存的最大比例。默认的比例为0.8。
默认参数0.8
lmdeploy chat /root/internlm2-chat-1_8b
对话显存占用:

降低为0.4
lmdeploy chat /root/internlm2-chat-1_8b --cache-max-entry-count 0.4
对话显存占用:

禁止KV Cache缓存
lmdeploy chat /root/internlm2-chat-1_8b --cache-max-entry-count 0.01
对话显存占用:

W4A16量化
LMDeploy使用AWQ算法,实现模型4bit权重量化。推理引擎TurboMind提供了非常高效的4bit推理cuda kernel,性能是FP16的2.4倍以上。
lmdeploy lite auto_awq \
/root/internlm2-chat-1_8b \
--calib-dataset 'ptb' \
--calib-samples 128 \
--calib-seqlen 1024 \
--w-bits 4 \
--w-group-size 128 \
--work-dir /root/internlm2-chat-1_8b-4bit
运行
lmdeploy chat /root/internlm2-chat-1_8b-4bit --model-format awq
显存占用

对比:
lmdeploy chat /root/internlm2-chat-1_8b-4bit --model-format awq --cache-max-entry-count 0.01

四、模型服务
封装为API:
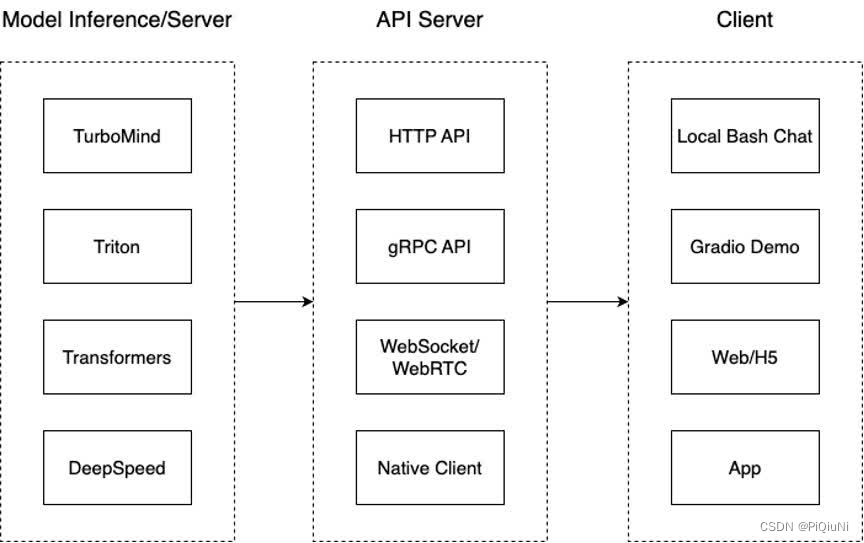
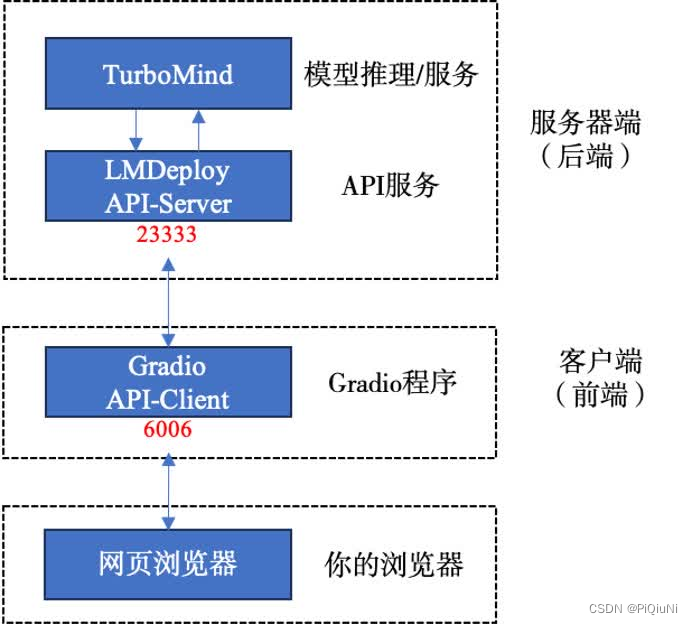
我们把从架构上把整个服务流程分成下面几个模块。
- 模型推理/服务。主要提供模型本身的推理,一般来说可以和具体业务解耦,专注模型推理本身性能的优化。可以以模块、API等多种方式提供。
- API Server。中间协议层,把后端推理/服务通过HTTP,gRPC或其他形式的接口,供前端调用。
- Client。可以理解为前端,与用户交互的地方。通过通过网页端/命令行去调用API接口,获取模型推理/服务。
值得说明的是,以上的划分是一个相对完整的模型,但在实际中这并不是绝对的。比如可以把“模型推理”和“API Server”合并,有的甚至是三个流程打包在一起提供服务。
启动API服务器
lmdeploy serve api_server \
/root/internlm2-chat-1_8b \
--model-format hf \
--quant-policy 0 \
--server-name 0.0.0.0 \
--server-port 23333 \
--tp 1
其中,model-format、quant-policy这些参数是与第三章中量化推理模型一致的;server-name和server-port表示API服务器的服务IP与服务端口;tp参数表示并行数量(GPU数量)。
ssh连接,查看接口说明
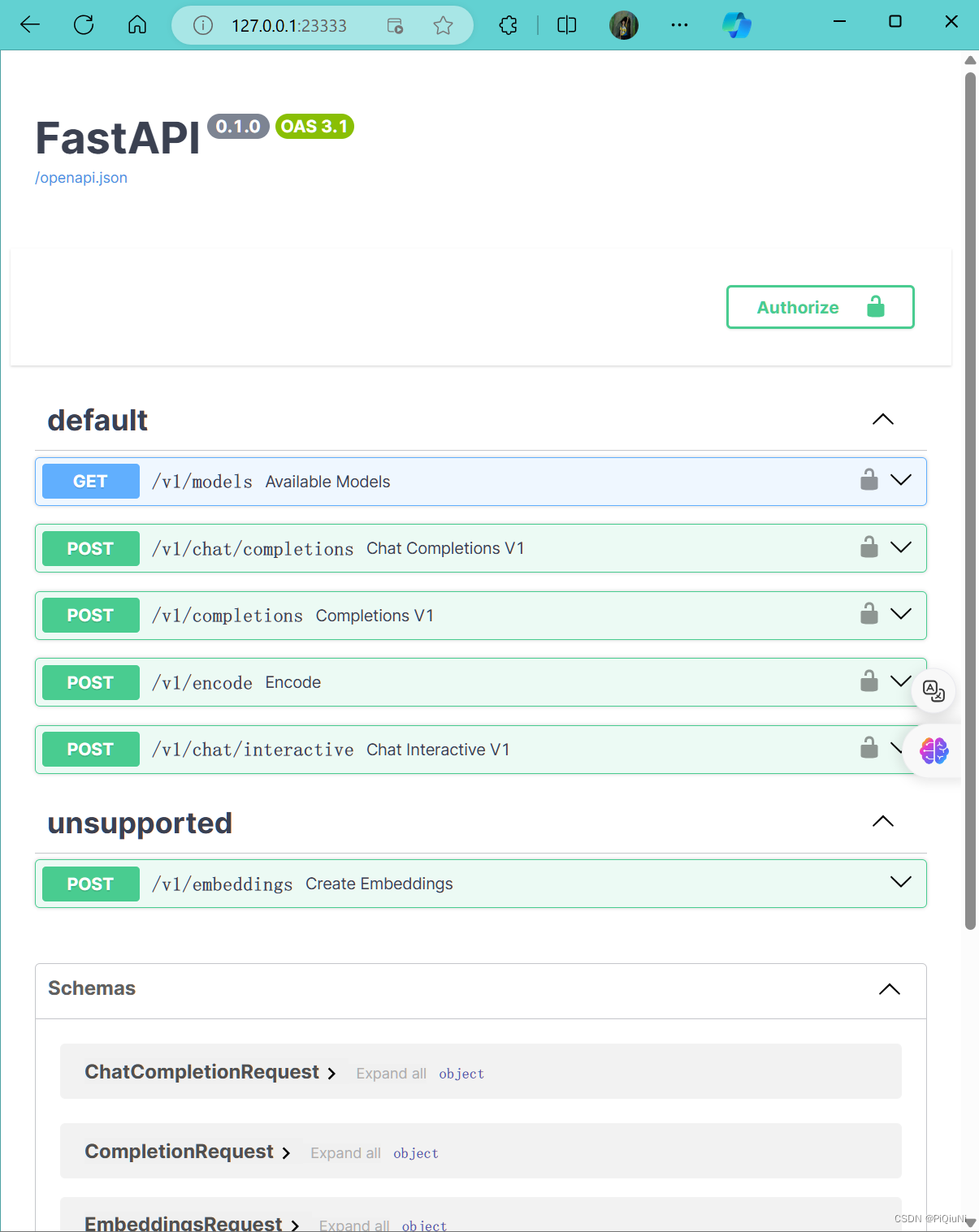
命令行客户端连接API服务器
lmdeploy serve api_client http://localhost:23333

连接架构:
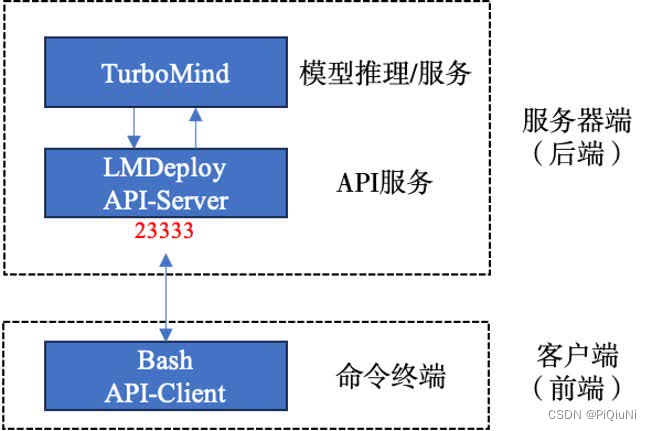
网页客户端连接API服务器
lmdeploy serve gradio http://localhost:23333 \ --server-name 0.0.0.0 \ --server-port 6006
访问 http://127.0.0.1:6006
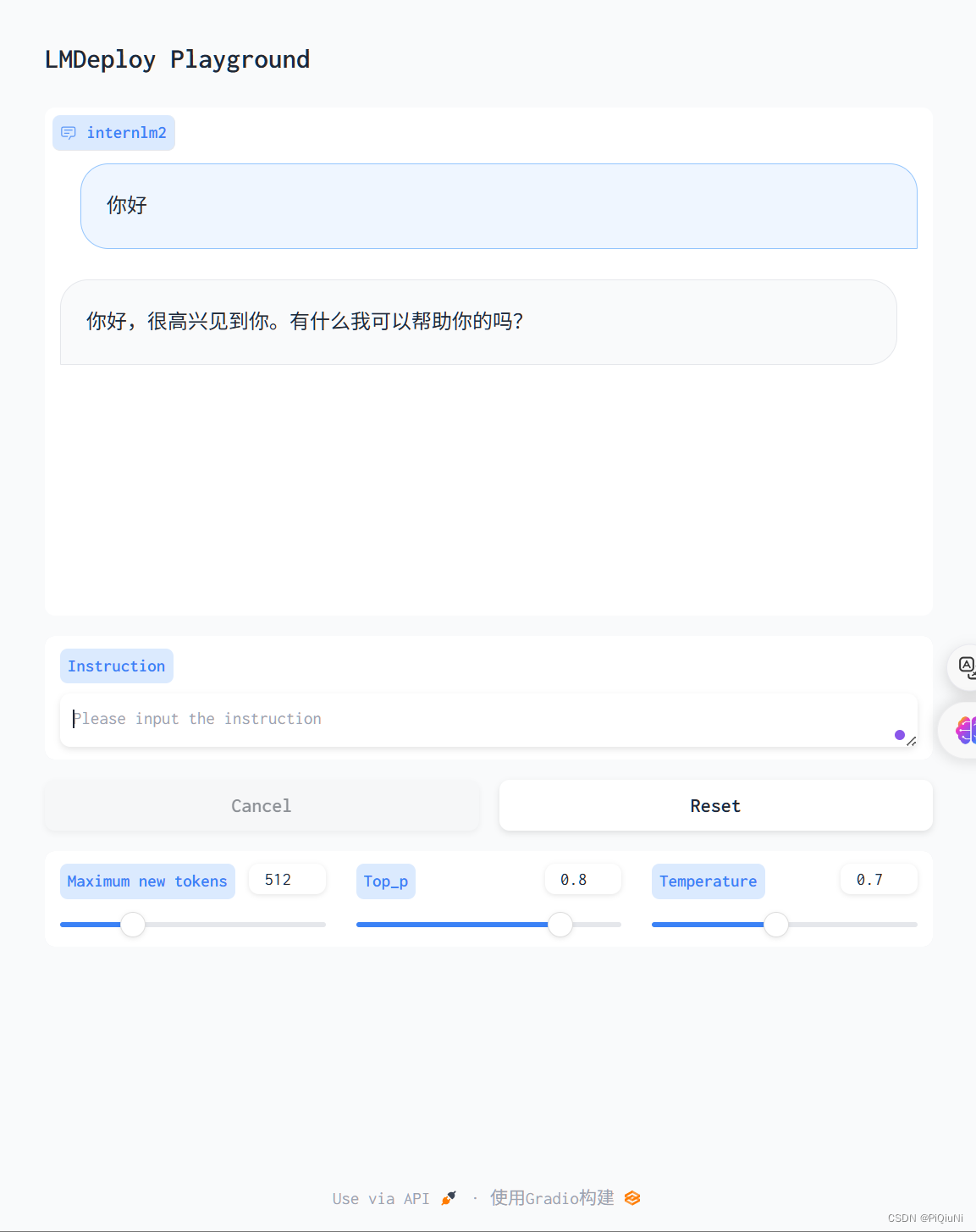
架构:
五、Python代码集成
Python代码集成运行1.8B模型
将大模型推理集成到Python代码里面
from lmdeploy import pipeline
pipe = pipeline('/root/internlm2-chat-1_8b')
response = pipe(['Hi, pls intro yourself', '上海是'])
print(response)
向TurboMind后端传递参数
from lmdeploy import pipeline, TurbomindEngineConfig
# 调低 k/v cache内存占比调整为总显存的 20%
backend_config = TurbomindEngineConfig(cache_max_entry_count=0.2)
pipe = pipeline('/root/internlm2-chat-1_8b',
backend_config=backend_config)
response = pipe(['Hi, pls intro yourself', '上海是'])
print(response)
六、拓展
使用LMDeploy运行视觉多模态大模型llava
本地运行
pipeline_llava.py
from lmdeploy.vl import load_image
from lmdeploy import pipeline, TurbomindEngineConfig
backend_config = TurbomindEngineConfig(session_len=8192) # 图片分辨率较高时请调高session_len
# pipe = pipeline('liuhaotian/llava-v1.6-vicuna-7b', backend_config=backend_config) 非开发机运行此命令
pipe = pipeline('/share/new_models/liuhaotian/llava-v1.6-vicuna-7b', backend_config=backend_config)
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg')
response = pipe(('describe this image', image))
print(response)
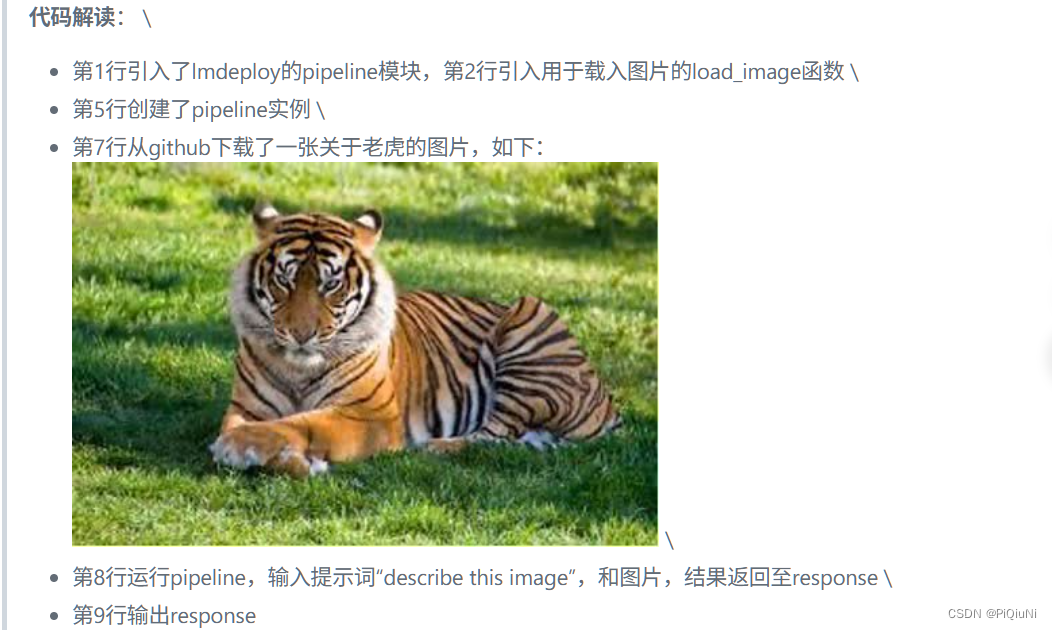
运行结果:
gradio_llava.py
import gradio as gr
from lmdeploy import pipeline, TurbomindEngineConfig
backend_config = TurbomindEngineConfig(session_len=8192) # 图片分辨率较高时请调高session_len
# pipe = pipeline('liuhaotian/llava-v1.6-vicuna-7b', backend_config=backend_config) 非开发机运行此命令
pipe = pipeline('/share/new_models/liuhaotian/llava-v1.6-vicuna-7b', backend_config=backend_config)
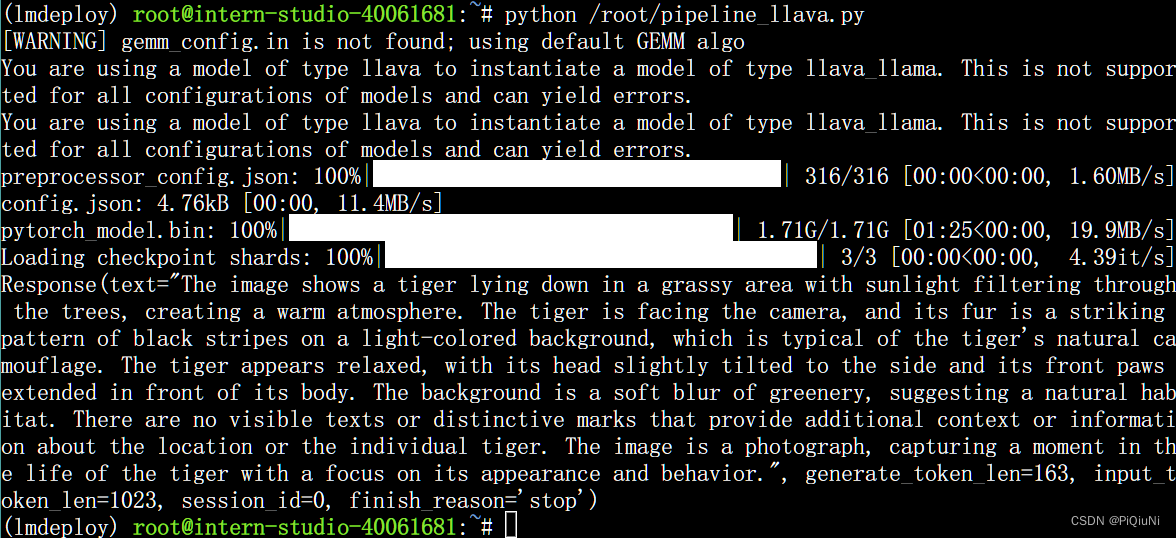
def model(image, text):
if image is None:
return [(text, "请上传一张图片。")]
else:
response = pipe((text, image)).text
return [(text, response)]
demo = gr.Interface(fn=model, inputs=[gr.Image(type="pil"), gr.Textbox()], outputs=gr.Chatbot())
demo.launch()
运行,端口转发后,浏览器访问:http://127.0.0.1:7860
运行结果:
使用LMDeploy运行第三方大模型
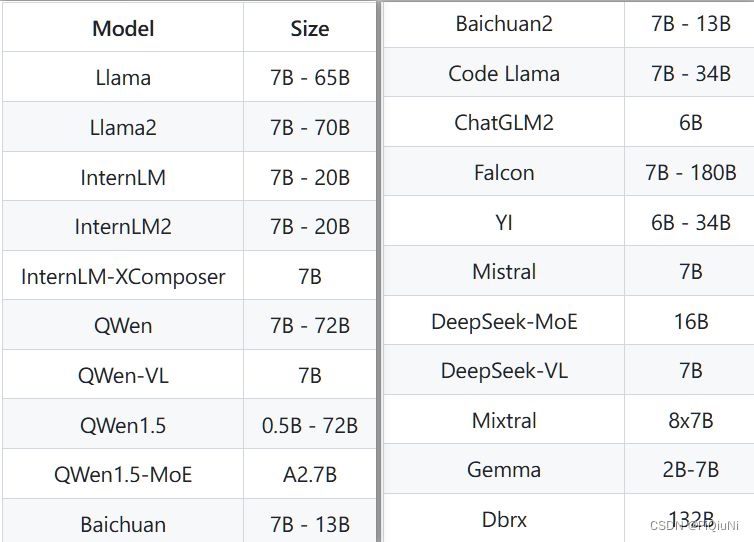
支持的模型:
定量比较LMDeploy与Transformer库的推理速度差异
参见上文
智能推荐
c# 调用c++ lib静态库_c#调用lib-程序员宅基地
文章浏览阅读2w次,点赞7次,收藏51次。四个步骤1.创建C++ Win32项目动态库dll 2.在Win32项目动态库中添加 外部依赖项 lib头文件和lib库3.导出C接口4.c#调用c++动态库开始你的表演...①创建一个空白的解决方案,在解决方案中添加 Visual C++ , Win32 项目空白解决方案的创建:添加Visual C++ , Win32 项目这......_c#调用lib
deepin/ubuntu安装苹方字体-程序员宅基地
文章浏览阅读4.6k次。苹方字体是苹果系统上的黑体,挺好看的。注重颜值的网站都会使用,例如知乎:font-family: -apple-system, BlinkMacSystemFont, Helvetica Neue, PingFang SC, Microsoft YaHei, Source Han Sans SC, Noto Sans CJK SC, W..._ubuntu pingfang
html表单常见操作汇总_html表单的处理程序有那些-程序员宅基地
文章浏览阅读159次。表单表单概述表单标签表单域按钮控件demo表单标签表单标签基本语法结构<form action="处理数据程序的url地址“ method=”get|post“ name="表单名称”></form><!--action,当提交表单时,向何处发送表单中的数据,地址可以是相对地址也可以是绝对地址--><!--method将表单中的数据传送给服务器处理,get方式直接显示在url地址中,数据可以被缓存,且长度有限制;而post方式数据隐藏传输,_html表单的处理程序有那些
PHP设置谷歌验证器(Google Authenticator)实现操作二步验证_php otp 验证器-程序员宅基地
文章浏览阅读1.2k次。使用说明:开启Google的登陆二步验证(即Google Authenticator服务)后用户登陆时需要输入额外由手机客户端生成的一次性密码。实现Google Authenticator功能需要服务器端和客户端的支持。服务器端负责密钥的生成、验证一次性密码是否正确。客户端记录密钥后生成一次性密码。下载谷歌验证类库文件放到项目合适位置(我这边放在项目Vender下面)https://github.com/PHPGangsta/GoogleAuthenticatorPHP代码示例://引入谷_php otp 验证器
【Python】matplotlib.plot画图横坐标混乱及间隔处理_matplotlib更改横轴间距-程序员宅基地
文章浏览阅读4.3k次,点赞5次,收藏11次。matplotlib.plot画图横坐标混乱及间隔处理_matplotlib更改横轴间距
docker — 容器存储_docker 保存容器-程序员宅基地
文章浏览阅读2.2k次。①Storage driver 处理各镜像层及容器层的处理细节,实现了多层数据的堆叠,为用户 提供了多层数据合并后的统一视图②所有 Storage driver 都使用可堆叠图像层和写时复制(CoW)策略③docker info 命令可查看当系统上的 storage driver主要用于测试目的,不建议用于生成环境。_docker 保存容器
随便推点
网络拓扑结构_网络拓扑csdn-程序员宅基地
文章浏览阅读834次,点赞27次,收藏13次。网络拓扑结构是指计算机网络中各组件(如计算机、服务器、打印机、路由器、交换机等设备)及其连接线路在物理布局或逻辑构型上的排列形式。这种布局不仅描述了设备间的实际物理连接方式,也决定了数据在网络中流动的路径和方式。不同的网络拓扑结构影响着网络的性能、可靠性、可扩展性及管理维护的难易程度。_网络拓扑csdn
JS重写Date函数,兼容IOS系统_date.prototype 将所有 ios-程序员宅基地
文章浏览阅读1.8k次,点赞5次,收藏8次。IOS系统Date的坑要创建一个指定时间的new Date对象时,通常的做法是:new Date("2020-09-21 11:11:00")这行代码在 PC 端和安卓端都是正常的,而在 iOS 端则会提示 Invalid Date 无效日期。在IOS年月日中间的横岗许换成斜杠,也就是new Date("2020/09/21 11:11:00")通常为了兼容IOS的这个坑,需要做一些额外的特殊处理,笔者在开发的时候经常会忘了兼容IOS系统。所以就想试着重写Date函数,一劳永逸,避免每次ne_date.prototype 将所有 ios
如何将EXCEL表导入plsql数据库中-程序员宅基地
文章浏览阅读5.3k次。方法一:用PLSQL Developer工具。 1 在PLSQL Developer的sql window里输入select * from test for update; 2 按F8执行 3 打开锁, 再按一下加号. 鼠标点到第一列的列头,使全列成选中状态,然后粘贴,最后commit提交即可。(前提..._excel导入pl/sql
Git常用命令速查手册-程序员宅基地
文章浏览阅读83次。Git常用命令速查手册1、初始化仓库git init2、将文件添加到仓库git add 文件名 # 将工作区的某个文件添加到暂存区 git add -u # 添加所有被tracked文件中被修改或删除的文件信息到暂存区,不处理untracked的文件git add -A # 添加所有被tracked文件中被修改或删除的文件信息到暂存区,包括untracked的文件...
分享119个ASP.NET源码总有一个是你想要的_千博二手车源码v2023 build 1120-程序员宅基地
文章浏览阅读202次。分享119个ASP.NET源码总有一个是你想要的_千博二手车源码v2023 build 1120
【C++缺省函数】 空类默认产生的6个类成员函数_空类默认产生哪些类成员函数-程序员宅基地
文章浏览阅读1.8k次。版权声明:转载请注明出处 http://blog.csdn.net/irean_lau。目录(?)[+]1、缺省构造函数。2、缺省拷贝构造函数。3、 缺省析构函数。4、缺省赋值运算符。5、缺省取址运算符。6、 缺省取址运算符 const。[cpp] view plain copy_空类默认产生哪些类成员函数