Netty使用篇:自定义编解码器_netty自定义编码器和解码器-程序员宅基地
我们今天还是继续Netty,Netty的编码器和解码器就是Netty对Handler这个组件的一种使用场景而已,SpringWebFlex就是基于这个Netty来做的,在往上引深一层GateWay服务网关就是SpringWebFlex的实现,所以SpringCloud当中明确说明了:Gateway不能和SpringWebStarter一起使用,引入了Gateway就不能引入后者,因为这是两种实现策略,常见的WebStater是Tomcat+JavaEE这套实现方式实现的。而webflex是基于Netty,不从属于传统JavaEE的这种开发方式。
看了很多Netty为我们提供的编解码器之后,我们如何自定义一个编解码器呢?
自定义编解码之上,能够自定义一套自己的通信协议呢?
制定了自定义协议之后,自定义编解码器必须需要我们自己定义了。
第一章:自定义编解码器的流程
在我们现在的开发来讲呢,我们需要客户端,我们假定客户端开发也是基于Java,我们也会有服务端。客户端和服务器端是需要通信的会有数据的往来,客户端和服务端都基于Java开发的话,我们关注的点是Java的类型,换句话说就是一个一个的Java类。最终,我们的数据也会封装到一个一个的Java类当中,我们跟服务端通信,通信的主旨是什么?就是将客户端封装好的类的对象的数据发送给服务端,服务端处理好之后,将业务数据封装成对象将对象数据发送给客户端。我们不可能在两个虚拟机当中传递我们的Java对象,这个过程当中都是讲Java对象转换为ByteBuf,这是Netty提供的类型,作为Netty将其中的数据取出来转成Byte数组,基于Socket流发送出去,作为服务器端呢,Netty会将Byte数组中的二进制数据转换为ByteBuf,然后将ByteBuf转换为Java类型(业务相关的对象类型)。
以上两个过程中涉及到我们的两部分内容了。一部分内容是Java类型转换为ByteBuf在Nerry体系当中称之为编码,反之ByteBuf转换为Java类型在Netty体系当中称之为Netty的解码。
前边我们讲到的各种的Encoder和Decoder解决的都是这样的问题。剩余的通信问题都是Netty帮我们做了,我们只需要关注于自定义边编解码就可以了。
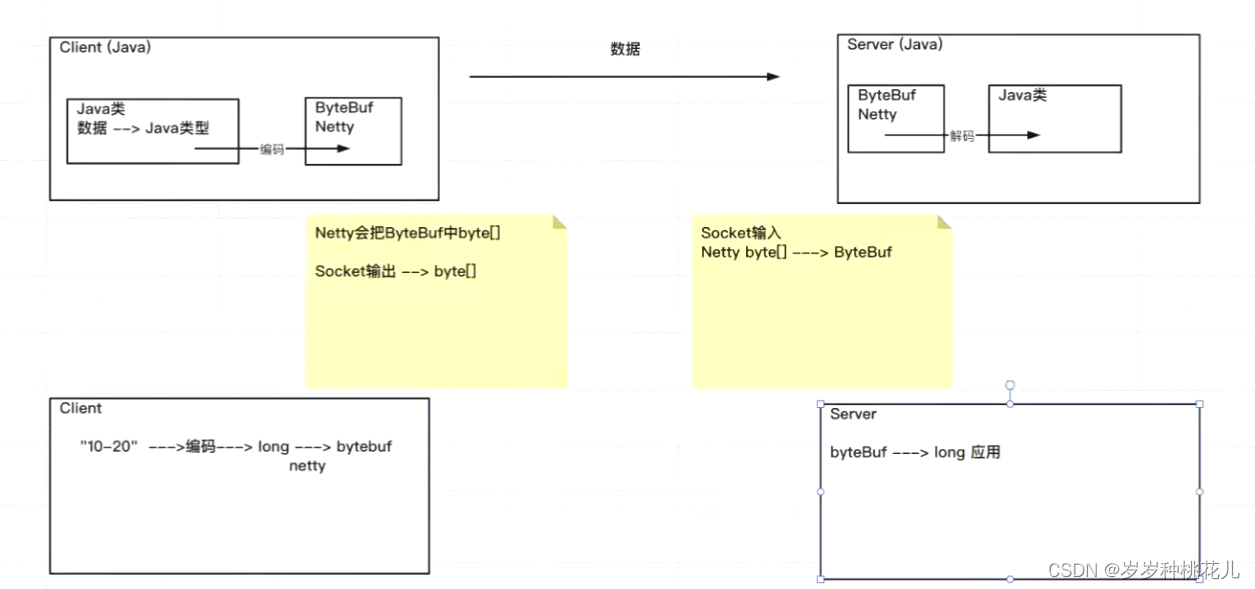
现在假设我们想要将“10-20”这样的数据编码成Long类型的数据,然后通过Netty发送给服务端。站在我们的服务端我们接收过来的数据是ByteBuf我们想要把他解码成Long类型。以上情况就涉及到编解码过程。显然,这个功能Netty是没有给我们提供的,我们基于此开发一个编码器和一个解码器。
我们现在想对任何一个框架进行一下拓展,都需要使用当前框架提供的规范进行开发。这个规范指的就是框架提供各种各种的接口或者父类。我们遵循这些规范即可,框架自身也会遵循这些规范。
作为编码器来讲,他需要继承一个父类:MessageToByteEncoder,解码器需要继承一个父类:ByteToMessageDecoder,最后将我们开发的边解码器假如到客户端或者服务端的pipeLine当中。
我们这里边发送的是要给字符串,创建一个类MyLongToByteEncoder extends MessageToByteEncoder去继承这个类之后,我们实现encoder方法,这个ctx是整个pileLine的上线文,是整个PipeLine的一个核心实现,获得了ctx就等于拿到了这个channel当中的pipeLine中的所有信息。这个ctx当中都有啥,channel和ByteBuf以及各种各样的Handler。msg带表了,客户端client要输出的内容,对于我们这个案例来讲我们在这里输出的就是10-20的数据。第三个参数ByteBufout就代表了就真正的往服务端写数据的ByteBuf,我们转换好的数据好存放到这里边。
我们基于循环的方式将每一个Long类型的数据发送出去。这样我们的客户端就发送出去了。这里有写以为,我们之前不都是使用一个内部类吗?为什么这里不用匿名内部类了。为什么现在不用了,首先从设计的角度来讲,我们要尽可能的少使用这个内部类,因为内部类的重用性很差,所以一个类型要复用话,我们尽量不用内部类,除非这个类的使用范围仅限于本类,这个时候我们才会考虑使用内部类,这是一种变量的封装。最典型的内部类体现封装概念的案例就是Map.Entry<key,value> 实际上做内部类就不是一个地道的方式,后续开发过程中要少用内部类。
服务器端,我们先使用一个LongHandler进行解码,将ByteBuf转换为Long(一个Long在ByteBuf当中占用8个字节)然后添加一个自定义的解码器,将数据存存储到这里边。所以这个List的泛型是Object
客户端代码:
public class MyNettyClient {
public static void main(String[] args) throws InterruptedException{
log.debug("myNettyClientStarter------");
EventLoopGroup eventLoopGroup = new NioEventLoopGroup();
Bootstrap bootstrap = new Bootstrap();
bootstrap.channel(NioSocketChannel.class);
Bootstrap group = bootstrap.group(eventLoopGroup);
bootstrap.handler(new ChannelInitializer<NioSocketChannel>() {
@Override
protected void initChannel(NioSocketChannel ch) throws Exception {
ch.pipeline().addLast(new LoggingHandler());
//自定义编码器
//Encoderxxx
ch.pipeline().addLast(new MyLongToByteEncoder());
//编解码器 或者 handler 匿名的内部类 重用性差
//内部类 ---> 使用范围 仅限于本类 (封装) Map Map.Entry(key -- value)
}
});
Channel channel = bootstrap.connect(new InetSocketAddress(8000)).sync().channel();
channel.writeAndFlush("10-20");
}
}
public class MyLongToByteEncoder extends MessageToByteEncoder<String>{
private static final Logger log = LoggerFactory.getLogger(MyLongToByteEncoder.class);
@Override
//获得了ctx等于拿到了这个channel相关的pipeline中的所有信息
//1. channel
//2. ByteBuf
// String msg 编码器接受的 client输出的内容
//ByteBuf out 真正往服务端写的ByteBuf的数据,细节 xxx
protected void encode(ChannelHandlerContext ctx, String msg, ByteBuf out) throws Exception {
log.debug("encode method invoke ");
String[] messges = msg.split("-");
for (String messge : messges) {
long resultLong = Long.parseLong(messge);
//每一个long类型的数据,在bytebuf中占用8个字节
out.writeLong(resultLong);
}
}
}
客户端日志:
2022-11-24 22:24:46.048 [nioEventLoopGroup-2-1] DEBUG io.netty.buffer.AbstractByteBuf - -Dio.netty.buffer.checkBounds: true
2022-11-24 22:24:46.049 [nioEventLoopGroup-2-1] DEBUG io.netty.util.ResourceLeakDetectorFactory - Loaded default ResourceLeakDetector: io.netty.util.ResourceLeakDetector@2ac301e9
2022-11-24 22:24:46.052 [nioEventLoopGroup-2-1] DEBUG com.suns.netty10.MyLongToByteEncoder - encode method invoke
2022-11-24 22:24:46.054 [nioEventLoopGroup-2-1] DEBUG io.netty.handler.logging.LoggingHandler - [id: 0x3c44ede1, L:/192.168.1.4:53328 - R:0.0.0.0/0.0.0.0:8000] WRITE: 16B
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 00 00 00 00 00 00 00 0a 00 00 00 00 00 00 00 14 |................|
+--------+-------------------------------------------------+----------------+
2022-11-24 22:24:46.054 [nioEventLoopGroup-2-1] DEBUG io.netty.handler.logging.LoggingHandler - [id: 0x3c44ede1, L:/192.168.1.4:53328 - R:0.0.0.0/0.0.0.0:8000] FLUSH
服务端代码:
public class MyNettyServer {
public static void main(String[] args) {
ServerBootstrap serverBootstrap = new ServerBootstrap();
serverBootstrap.channel(NioServerSocketChannel.class);
serverBootstrap.group(new NioEventLoopGroup());
serverBootstrap.childHandler(new ChannelInitializer<NioSocketChannel>() {
@Override
//
protected void initChannel(NioSocketChannel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
pipeline.addLast(new LoggingHandler());
//ByteBuf --- Long
//解码过程
pipeline.addLast(new MyByteToLongDecoder());
//pipeline.addLast(new MyLongCodec());
pipeline.addLast(new ChannelInboundHandlerAdapter(){
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
log.debug("recive date in handler ...");
if(msg instanceof Long){
Long result = (Long) msg;
log.debug("my handler data is {} ",result);
}
}
});
}
});
//
serverBootstrap.bind(8000);
}
}
public class MyByteToLongDecoder extends ByteToMessageDecoder {
@Override
//获得了ctx等于拿到了这个channel相关的pipeline中的所有信息
//1. channel
//2. ByteBuf
//ByteBuf in client提交上来的数据
// decode方法处理的过程中,如果bytebuf没有处理完,那么他会重复调用decode方法
protected void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception {
log.debug("decode method invoke ...");//ssss
if (in.readableBytes() >= 8) {
in.markReaderIndex();
long reciveLong = in.readLong();
out.add(reciveLong);
}
System.out.println(ByteBufUtil.prettyHexDump(in));
}
}
服务端日志:
2022-11-24 22:24:46.064 [nioEventLoopGroup-2-2] DEBUG io.netty.util.ResourceLeakDetectorFactory - Loaded default ResourceLeakDetector: io.netty.util.ResourceLeakDetector@53fb3f15
2022-11-24 22:24:46.067 [nioEventLoopGroup-2-2] DEBUG io.netty.handler.logging.LoggingHandler - [id: 0x57544fbc, L:/192.168.1.4:8000 - R:/192.168.1.4:53328] READ: 16B
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 00 00 00 00 00 00 00 0a 00 00 00 00 00 00 00 14 |................|
+--------+-------------------------------------------------+----------------+
2022-11-24 22:24:46.073 [nioEventLoopGroup-2-2] DEBUG com.suns.netty10.MyByteToLongDecoder - decode method invoke ...
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 00 00 00 00 00 00 00 14 |........ |
+--------+-------------------------------------------------+----------------+
2022-11-24 22:24:46.074 [nioEventLoopGroup-2-2] DEBUG com.suns.netty10.MyNettyServer - recive date in handler ...
2022-11-24 22:24:46.074 [nioEventLoopGroup-2-2] DEBUG com.suns.netty10.MyNettyServer - my handler data is 10
2022-11-24 22:24:46.074 [nioEventLoopGroup-2-2] DEBUG com.suns.netty10.MyByteToLongDecoder - decode method invoke ...
2022-11-24 22:24:46.074 [nioEventLoopGroup-2-2] DEBUG com.suns.netty10.MyNettyServer - recive date in handler ...
2022-11-24 22:24:46.074 [nioEventLoopGroup-2-2] DEBUG com.suns.netty10.MyNettyServer - my handler data is 20
站在客户端角度来讲,客户端是使用一次给我们发送过来的,16个字节一次给发过来的。但是为什么站在服务端解码的时候要调用两个decode方法,产生了两个Message。(整个PipeLine的调用次数是按照Message个数定义的)但是消息我认可是两个,但是为啥要decode方法两次呢?这个是在Netty体系当中一个很大的坑,如果在Netty当中的ByteBuf当中如果一次性没处理完。他就会再次调用decode方法。再次交给你处理,恰好此时我们的数据时候16个字节,我们这就取了8个字节,这个时候我们的就调用了两次,如果是20个字节,我们的decode方法被调用了三次,这个是以处理完没处理完ByteBuf当中的数据当做一回事的。readLong读了8个字节,后边还有8个字节。
decode方法外部包了一层循环,只要是我们的ByteBuf当中还有数据没有读完。就会重复的调用decode方法,接着去处理。
智能推荐
什么是内部类?成员内部类、静态内部类、局部内部类和匿名内部类的区别及作用?_成员内部类和局部内部类的区别-程序员宅基地
文章浏览阅读3.4k次,点赞8次,收藏42次。一、什么是内部类?or 内部类的概念内部类是定义在另一个类中的类;下面类TestB是类TestA的内部类。即内部类对象引用了实例化该内部对象的外围类对象。public class TestA{ class TestB {}}二、 为什么需要内部类?or 内部类有什么作用?1、 内部类方法可以访问该类定义所在的作用域中的数据,包括私有数据。2、内部类可以对同一个包中的其他类隐藏起来。3、 当想要定义一个回调函数且不想编写大量代码时,使用匿名内部类比较便捷。三、 内部类的分类成员内部_成员内部类和局部内部类的区别
分布式系统_分布式系统运维工具-程序员宅基地
文章浏览阅读118次。分布式系统要求拆分分布式思想的实质搭配要求分布式系统要求按照某些特定的规则将项目进行拆分。如果将一个项目的所有模板功能都写到一起,当某个模块出现问题时将直接导致整个服务器出现问题。拆分按照业务拆分为不同的服务器,有效的降低系统架构的耦合性在业务拆分的基础上可按照代码层级进行拆分(view、controller、service、pojo)分布式思想的实质分布式思想的实质是为了系统的..._分布式系统运维工具
用Exce分析l数据极简入门_exce l趋势分析数据量-程序员宅基地
文章浏览阅读174次。1.数据源准备2.数据处理step1:数据表处理应用函数:①VLOOKUP函数; ② CONCATENATE函数终表:step2:数据透视表统计分析(1) 透视表汇总不同渠道用户数, 金额(2)透视表汇总不同日期购买用户数,金额(3)透视表汇总不同用户购买订单数,金额step3:讲第二步结果可视化, 比如, 柱形图(1)不同渠道用户数, 金额(2)不同日期..._exce l趋势分析数据量
宁盾堡垒机双因素认证方案_horizon宁盾双因素配置-程序员宅基地
文章浏览阅读3.3k次。堡垒机可以为企业实现服务器、网络设备、数据库、安全设备等的集中管控和安全可靠运行,帮助IT运维人员提高工作效率。通俗来说,就是用来控制哪些人可以登录哪些资产(事先防范和事中控制),以及录像记录登录资产后做了什么事情(事后溯源)。由于堡垒机内部保存着企业所有的设备资产和权限关系,是企业内部信息安全的重要一环。但目前出现的以下问题产生了很大安全隐患:密码设置过于简单,容易被暴力破解;为方便记忆,设置统一的密码,一旦单点被破,极易引发全面危机。在单一的静态密码验证机制下,登录密码是堡垒机安全的唯一_horizon宁盾双因素配置
谷歌浏览器安装(Win、Linux、离线安装)_chrome linux debian离线安装依赖-程序员宅基地
文章浏览阅读7.7k次,点赞4次,收藏16次。Chrome作为一款挺不错的浏览器,其有着诸多的优良特性,并且支持跨平台。其支持(Windows、Linux、Mac OS X、BSD、Android),在绝大多数情况下,其的安装都很简单,但有时会由于网络原因,无法安装,所以在这里总结下Chrome的安装。Windows下的安装:在线安装:离线安装:Linux下的安装:在线安装:离线安装:..._chrome linux debian离线安装依赖
烤仔TVの尚书房 | 逃离北上广?不如押宝越南“北上广”-程序员宅基地
文章浏览阅读153次。中国发达城市榜单每天都在刷新,但无非是北上广轮流坐庄。北京拥有最顶尖的文化资源,上海是“摩登”的国际化大都市,广州是活力四射的千年商都。GDP和发展潜力是衡量城市的数字指...
随便推点
java spark的使用和配置_使用java调用spark注册进去的程序-程序员宅基地
文章浏览阅读3.3k次。前言spark在java使用比较少,多是scala的用法,我这里介绍一下我在项目中使用的代码配置详细算法的使用请点击我主页列表查看版本jar版本说明spark3.0.1scala2.12这个版本注意和spark版本对应,只是为了引jar包springboot版本2.3.2.RELEASEmaven<!-- spark --> <dependency> <gro_使用java调用spark注册进去的程序
汽车零部件开发工具巨头V公司全套bootloader中UDS协议栈源代码,自己完成底层外设驱动开发后,集成即可使用_uds协议栈 源代码-程序员宅基地
文章浏览阅读4.8k次。汽车零部件开发工具巨头V公司全套bootloader中UDS协议栈源代码,自己完成底层外设驱动开发后,集成即可使用,代码精简高效,大厂出品有量产保证。:139800617636213023darcy169_uds协议栈 源代码
AUTOSAR基础篇之OS(下)_autosar 定义了 5 种多核支持类型-程序员宅基地
文章浏览阅读4.6k次,点赞20次,收藏148次。AUTOSAR基础篇之OS(下)前言首先,请问大家几个小小的问题,你清楚:你知道多核OS在什么场景下使用吗?多核系统OS又是如何协同启动或者关闭的呢?AUTOSAR OS存在哪些功能安全等方面的要求呢?多核OS之间的启动关闭与单核相比又存在哪些异同呢?。。。。。。今天,我们来一起探索并回答这些问题。为了便于大家理解,以下是本文的主题大纲:[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JCXrdI0k-1636287756923)(https://gite_autosar 定义了 5 种多核支持类型
VS报错无法打开自己写的头文件_vs2013打不开自己定义的头文件-程序员宅基地
文章浏览阅读2.2k次,点赞6次,收藏14次。原因:自己写的头文件没有被加入到方案的包含目录中去,无法被检索到,也就无法打开。将自己写的头文件都放入header files。然后在VS界面上,右键方案名,点击属性。将自己头文件夹的目录添加进去。_vs2013打不开自己定义的头文件
【Redis】Redis基础命令集详解_redis命令-程序员宅基地
文章浏览阅读3.3w次,点赞80次,收藏342次。此时,可以将系统中所有用户的 Session 数据全部保存到 Redis 中,用户在提交新的请求后,系统先从Redis 中查找相应的Session 数据,如果存在,则再进行相关操作,否则跳转到登录页面。此时,可以将系统中所有用户的 Session 数据全部保存到 Redis 中,用户在提交新的请求后,系统先从Redis 中查找相应的Session 数据,如果存在,则再进行相关操作,否则跳转到登录页面。当数据量很大时,count 的数量的指定可能会不起作用,Redis 会自动调整每次的遍历数目。_redis命令
URP渲染管线简介-程序员宅基地
文章浏览阅读449次,点赞3次,收藏3次。URP的设计目标是在保持高性能的同时,提供更多的渲染功能和自定义选项。与普通项目相比,会多出Presets文件夹,里面包含着一些设置,包括本色,声音,法线,贴图等设置。全局只有主光源和附加光源,主光源只支持平行光,附加光源数量有限制,主光源和附加光源在一次Pass中可以一起着色。URP:全局只有主光源和附加光源,主光源只支持平行光,附加光源数量有限制,一次Pass可以计算多个光源。可编程渲染管线:渲染策略是可以供程序员定制的,可以定制的有:光照计算和光源,深度测试,摄像机光照烘焙,后期处理策略等等。_urp渲染管线