什么是Spark,spark Core,Spark SQL,Scala概述,Scala运算符,程序流程控制,Scala循环,Scala集合,集合中常用元素操作,Scala模式匹配,Scala进阶-程序员宅基地
目录
Linux 上安装 Scala(实验环境为centos7):
章节一 Spark简介
在Spark基础-实验列表下,单击Spark基础课程实验一:Spark简介右侧的【开始实验】按钮,具体如下图红色圈出部分:

自动登录到私有云集群操作环境下,具体如下图所示:

Apache Spark 是开源码的集群运算框架,由加州大学伯克利分校的AMPLab开发。Spark 是一个弹性的运算框架,适合进行Spark Streaming 数据流处理、Spark SQL互动分析、MLlib 机器学习等应用,因此Spark 可作为一个用途广泛的大数据运算平台。Spark 允许用户将数据加载到cluster 集群的内存中存储,并多次重复运算,非常适合用于机器学习的算法。
-
Spark RDD in-memory 的计算框架
Spark 的核心是RDD(Resilient Distributed Dataset)弹性分布式数据集,是由AMPlab实验室提出的概念,属于一种分布式的内容。Spark 主要的优势来自于RDD 本身的特性,RDD能与其他系统兼容,可以导入外部存储系统的数据集,例如HDFS、HBase或其他Hadoop数据源。
Spark在运算时,将中间生产的数据暂存在内存中,因此可以加快运行速度。需要反复操作的次数越多,所需读取的数据量越大,Spark的性能凸显越明显。Spark在内存中运行程序,命令运行周期比Hadoop MapReduce的命令运行周期快100倍,即便是运行于硬盘上时Spark的速度也能快上10倍。
-
Spark 的发展历史
| 项目 |
所需数目 |
| 2009 |
Spark 在2009年由Matei Zaharia 在加州大学柏克利分校的AMPLab 开发 |
| 2010 |
2010年通过BSD授权条款发布开放源码 |
| 2013 |
该项目被捐赠给Apache软件基金会 |
| 2014/2 |
Spark 成为Apache的顶级项目 |
| 2014/11 |
Databricks 团队使用Spark 刷新数据库排序的世界纪录 |
| 2015/3 |
Spark 1.3.0发布,开始加入 DataFrame 与Spark ML |
| 2016/7 |
Spark 2.0.0 版发布,该版本主要更新APIs,支持SQL 2003,支持R UDF ,增强其性能。300个开发者贡献了2500补丁程序。 |
| 2016/12 |
Spark 2.1.0发布。这是 2.x 版本线的第二个发行版。此发行版在为Structured Streaming进入生产环境做出了重大突破,Structured Streaming现在支持了event time watermarks了,并且支持Kafka 0.10。此外,此版本更侧重于可用性,稳定性和优雅(polish),并解决了1200多个tickets |
| 2017/7 |
Spark 2.2.0发布。这也是 2.x 系列的第三个版本。此版本移除了 Structured Streaming 的实验标记(experimental tag),意味着已可以放心在线上使用。该版本的主要更新内容主要针对的是系统的可用性、稳定性以及代码润色。包括:
|
| 2018/2 |
Spark 2.3.0发布。这也是 2.x 系列中的第四个版本。此版本增加了对 Structured Streaming 中的 Continuous Processing 以及全新的 Kubernetes Scheduler 后端的支持。其他主要更新包括新的 DataSource 和 Structured Streaming v2 API,以及一些 PySpark 性能增强。此外,此版本继续针对项目的可用性、稳定性进行改进,并持续润色代码。 |
| 2018/11 |
Spark 2.4.0发布。这也是 2.x 系列中的最新版本。 |
-
Spark 的主要功能
Spark SQL:可以使用熟知的SQL查询语言来运行数据分析
Data Frame:具有Schema ,可以使用类SQL方法,比如select(),使用上比RDD更方便。
Spark Streaming: 可实现实时的数据串流的处理,具有大数据量、容错性、可扩充性等特点。
GraphX:是Spark撒花姑娘的分布式图形处理架构,可用图表计算。
Spark MLlib:是一个可扩充的Spark机器学习库,可使用许多常见的机器学习算法,简化大规模机器学习的时间。算法包括分类与回归、支持向量机、回归、线性回归、决策树、朴素贝叶斯、聚类分析、协同过滤等。
Spark ML Pipeline:将机器学习的每一个阶段建立成Pipeline 流程,可减轻数据分析师程序设计的负担。
-
-
Spark 生态圈
-
Spark 生态系统以Spark Core 为核心,能够读取传统文件(如文本文件)、HDFS、Amazon S3、Alluxio 和NoSQL 等数据源,利用Standalone、YARN 和Mesos 等资源调度管理,完成应用程序分析与处理。这些应用程序来自Spark 的不同组件,如Spark Shell 或Spark Submit 交互式批处理方式、Spark Streaming 的实时流处理应用、Spark SQL 的即席查询、采样近似查询引擎BlinkDB 的权衡查询、MLbase/MLlib 的机器学习、GraphX 的图处理和SparkR 的数学计算等,如下图所示,正是这个生态系统实现了“One Stack to Rule Them All”目标。 (在这里只介绍Spark Core、Spark SQL以及Spark Streaming)

Spark Core 是整个Spark生态系统的核心组件,是一个分布式大数据处理框架。Spark Core提供了多种资源调度管理,通过内存计算、有向无环图(DAG)等机制保证分布式计算的快速,并引入了RDD 的抽象保证数据的高容错性,其重要特性描述如下:
提供了有向无环图(DAG)的分布式并行计算框架,并提供内存机制来支持多次迭代计算或者数据共享,大大减少迭代计算之间读取数据局的开销,这对于需要进行多次迭代的数据挖掘和分析性能有很大提升 。另外在任务处理过程中移动计算而非移动数据(数据本地性),RDDPartition 可以就近读取分布式文件系统中的数据块到各个节点内存中进行计算。
- 在Spark中引入了RDD (Resilient Distributed Dataset) 的抽象,它是分布在一组节点中的只读对象集合,这些集合是弹性的,如果数据集一部分丢失,则可以根据血统对它们进行重建,保证了数据的高容错性;
- 移动计算而非移动数据,RDD Partition可以就近读取分布式文件系统中的数据块到各个节点内存中进行计算
- 使用多线程池模型来减少task启动开稍
- 采用容错的、高可伸缩性的akka作为通讯框架
- SparkStreaming是一个对实时数据流进行高通量、容错处理的流式处理系统,可以对多种数据源(如Kafka、Flume、Twitter、Zero和TCP 套接字)进行类似Map、Reduce和Join等复杂操作,并将结果保存到外部文件系统、数据库或应用到实时仪表盘。

Spark Streaming构架 :
- 计算流程:Spark Streaming是将流式计算分解成一系列短小的批处理作业。这里的批处理引擎是Spark Core,也就是把Spark Streaming的输入数据按照batch size(如1秒)分成一段一段的数据(Discretized Stream),每一段数据都转换成Spark中的RDD(Resilient Distributed Dataset),然后将Spark Streaming中对DStream的Transformation操作变为针对Spark中对RDD的Transformation操作,将RDD经过操作变成中间结果保存在内存中。整个流式计算根据业务的需求可以对中间的结果进行叠加或者存储到外部设备。下图显示了Spark Streaming的整个流程。

- 容错性:对于流式计算来说,容错性至关重要。首先我们要明确一下Spark中RDD的容错机制。每一个RDD都是一个不可变的分布式可重算的数据集,其记录着确定性的操作继承关系(lineage),所以只要输入数据是可容错的,那么任意一个RDD的分区(Partition)出错或不可用,都是可以利用原始输入数据通过转换操作而重新算出的。
对于Spark Streaming来说,其RDD的传承关系如下图所示,图中的每一个椭圆形表示一个RDD,椭圆形中的每个圆形代表一个RDD中的一个Partition,图中的每一列的多个RDD表示一个DStream(图中有三个DStream),而每一行最后一个RDD则表示每一个Batch Size所产生的中间结果RDD。我们可以看到图中的每一个RDD都是通过lineage相连接的,由于Spark Streaming输入数据可以来自于磁盘,例如HDFS(多份拷贝)或是来自于网络的数据流(Spark Streaming会将网络输入数据的每一个数据流拷贝两份到其他的机器)都能保证容错性,所以RDD中任意的Partition出错,都可以并行地在其他机器上将缺失的Partition计算出来。这个容错恢复方式比连续计算模型(如Storm)的效率更高。
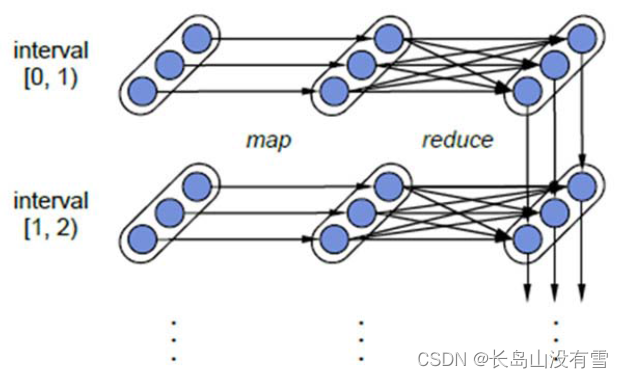
Spark Streaming中RDD的lineage关系图
- 实时性:对于实时性的讨论,会牵涉到流式处理框架的应用场景。Spark Streaming将流式计算分解成多个Spark Job,对于每一段数据的处理都会经过Spark DAG图分解以及Spark的任务集的调度过程。对于目前版本的Spark Streaming而言,其最小的Batch Size的选取在0.5~2秒钟之间(Storm目前最小的延迟是100ms左右),所以Spark Streaming能够满足除对实时性要求非常高(如高频实时交易)之外的所有流式准实时计算场景。
- 扩展性与吞吐量:Spark目前在EC2上已能够线性扩展到100个节点(每个节点4Core),可以以数秒的延迟处理6GB/s的数据量(60M records/s),其吞吐量也比流行的Storm高2~5倍,图4是Berkeley利用WordCount和Grep两个用例所做的测试,在Grep这个测试中,Spark Streaming中的每个节点的吞吐量是670k records/s,而Storm是115k records/s。
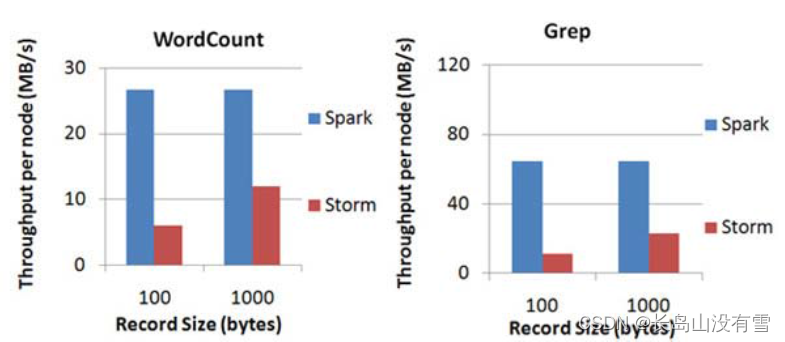
Spark Streaming与Storm吞吐量比较图
Shark是SparkSQL的前身,它发布于3年前,那个时候Hive可以说是SQL on Hadoop的唯一选择,负责将SQL编译成可扩展的MapReduce作业,鉴于Hive的性能以及与Spark的兼容,Shark项目由此而生。
Shark即Hive on Spark,本质上是通过Hive的HQL解析,把HQL翻译成Spark上的RDD操作,然后通过Hive的metadata获取数据库里的表信息,实际HDFS上的数据和文件,会由Shark获取并放到Spark上运算。Shark的最大特性就是快和与Hive的完全兼容,且可以在shell模式下使用rdd2sql()这样的API,把HQL得到的结果集,继续在scala环境下运算,支持自己编写简单的机器学习或简单分析处理函数,对HQL结果进一步分析计算。
在2014年7月1日的Spark Summit上,Databricks宣布终止对Shark的开发,将重点放到Spark SQL上。Databricks表示,Spark SQL将涵盖Shark的所有特性,用户可以从Shark 0.9进行无缝的升级。在会议上,Databricks表示,Shark更多是对Hive的改造,替换了Hive的物理执行引擎,因此会有一个很快的速度。然而,不容忽视的是,Shark继承了大量的Hive代码,因此给优化和维护带来了大量的麻烦。随着性能优化和先进分析整合的进一步加深,基于MapReduce设计的部分无疑成为了整个项目的瓶颈。因此,为了更好的发展,给用户提供一个更好的体验,Databricks宣布终止Shark项目,从而将更多的精力放到Spark SQL上。
Spark SQL允许开发人员直接处理RDD,同时也可查询例如在 Apache Hive上存在的外部数据。Spark SQL的一个重要特点是其能够统一处理关系表和RDD,使得开发人员可以轻松地使用SQL命令进行外部查询,同时进行更复杂的数据分析。除了Spark SQL外,Michael还谈到Catalyst优化框架,它允许Spark SQL自动修改查询方案,使SQL更有效地执行。
-
Spark SQL的特点:
- 引入了新的RDD类型SchemaRDD,可以象传统数据库定义表一样来定义SchemaRDD,SchemaRDD由定义了列数据类型的行对象构成。SchemaRDD可以从RDD转换过来,也可以从Parquet文件读入,也可以使用HiveQL从Hive中获取。
- 内嵌了Catalyst查询优化框架,在把SQL解析成逻辑执行计划之后,利用Catalyst包里的一些类和接口,执行了一些简单的执行计划优化,最后变成RDD的计算
- 在应用程序中可以混合使用不同来源的数据,如可以将来自HiveQL的数据和来自SQL的数据进行Join操作。

Shark的出现使得SQL-on-Hadoop的性能比Hive有了8-100倍的提高, 那么,摆脱了Hive的限制,SparkSQL的性能又有怎么样的表现呢?虽然没有Shark相对于Hive那样瞩目地性能提升,但也表现得非常优异,如下图所示:

为什么sparkSQL的性能会得到怎么大的提升呢?主要sparkSQL在下面几点做了优化:
1. 内存列存储(In-Memory Columnar Storage) sparkSQL的表数据在内存中存储不是采用原生态的JVM对象存储方式,而是采用内存列存储;
2. 字节码生成技术(Bytecode Generation) Spark1.1.0在Catalyst模块的expressions增加了codegen模块,使用动态字节码生成技术,对匹配的表达式采用特定的代码动态编译。另外对SQL表达式都作了CG优化, CG优化的实现主要还是依靠Scala2.10的运行时放射机制(runtime reflection);
3. Scala代码优化 SparkSQL在使用Scala编写代码的时候,尽量避免低效的、容易GC的代码;尽管增加了编写代码的难度,但对于用户来说接口统一。
BlinkDB 是一个用于在海量数据上运行交互式 SQL 查询的大规模并行查询引擎,它允许用户通过权衡数据精度来提升查询响应时间,其数据的精度被控制在允许的误差范围内。为了达到这个目标,BlinkDB 使用两个核心思想:
- 一个自适应优化框架,从原始数据随着时间的推移建立并维护一组多维样本;
- 一个动态样本选择策略,选择一个适当大小的示例基于查询的准确性和(或)响应时间需求。
和传统关系型数据库不同,BlinkDB是一个很有意思的交互式查询系统,就像一个跷跷板,用户需要在查询精度和查询时间上做一权衡;如果用户想更快地获取查询结果,那么将牺牲查询结果的精度;同样的,用户如果想获取更高精度的查询结果,就需要牺牲查询响应时间。用户可以在查询的时候定义一个失误边界。

MLBase是Spark生态圈的一部分专注于机器学习,让机器学习的门槛更低,让一些可能并不了解机器学习的用户也能方便地使用MLbase。MLBase分为四部分:MLlib、MLI、ML Optimizer和MLRuntime。
- ML Optimizer会选择它认为最适合的已经在内部实现好了的机器学习算法和相关参数,来处理用户输入的数据,并返回模型或别的帮助分析的结果;
- MLI 是一个进行特征抽取和高级ML编程抽象的算法实现的API或平台;
- MLlib是Spark实现一些常见的机器学习算法和实用程序,包括分类、回归、聚类、协同过滤、降维以及底层优化,该算法可以进行可扩充; MLRuntime 基于Spark计算框架,将Spark的分布式计算应用到机器学习领域。

总的来说,MLBase的核心是他的优化器,把声明式的Task转化成复杂的学习计划,产出最优的模型和计算结果。与其他机器学习Weka和Mahout不同的是:
- MLBase是分布式的,Weka是一个单机的系统;
- MLBase是自动化的,Weka和Mahout都需要使用者具备机器学习技能,来选择自己想要的算法和参数来做处理;
- MLBase提供了不同抽象程度的接口,让算法可以扩充
- MLBase基于Spark这个平台
GraphX是Spark中用于图(e.g., Web-Graphs and Social Networks)和图并行计算(e.g., PageRank and Collaborative Filtering)的API,可以认为是GraphLab(C++)和Pregel(C++)在Spark(Scala)上的重写及优化,跟其他分布式图计算框架相比,GraphX最大的贡献是,在Spark之上提供一栈式数据解决方案,可以方便且高效地完成图计算的一整套流水作业。GraphX最先是伯克利AMPLAB的一个分布式图计算框架项目,后来整合到Spark中成为一个核心组件。
GraphX的核心抽象是Resilient Distributed Property Graph,一种点和边都带属性的有向多重图。它扩展了Spark RDD的抽象,有Table和Graph两种视图,而只需要一份物理存储。两种视图都有自己独有的操作符,从而获得了灵活操作和执行效率。如同Spark,GraphX的代码非常简洁。GraphX的核心代码只有3千多行,而在此之上实现的Pregel模型,只要短短的20多行。GraphX的代码结构整体下图所示,其中大部分的实现,都是围绕Partition的优化进行的。这在某种程度上说明了点分割的存储和相应的计算优化的确是图计算框架的重点和难点。

GraphX的底层设计有以下几个关键点。
1. 对Graph视图的所有操作,最终都会转换成其关联的Table视图的RDD操作来完成。这样对一个图的计算,最终在逻辑上,等价于一系列RDD的转换过程。因此,Graph最终具备了RDD的3个关键特性:Immutable、Distributed和Fault-Tolerant。其中最关键的是Immutable(不变性)。逻辑上,所有图的转换和操作都产生了一个新图;物理上,GraphX会有一定程度的不变顶点和边的复用优化,对用户透明。
2. 两种视图底层共用的物理数据,由RDD[Vertex-Partition]和RDD[EdgePartition]这两个RDD组成。点和边实际都不是以表Collection[tuple]的形式存储的,而是由VertexPartition/EdgePartition在内部存储一个带索引结构的分片数据块,以加速不同视图下的遍历速度。不变的索引结构在RDD转换过程中是共用的,降低了计算和存储开销。
3. 图的分布式存储采用点分割模式,而且使用partitionBy方法,由用户指定不同的划分策略(PartitionStrategy)。划分策略会将边分配到各个EdgePartition,顶点Master分配到各个VertexPartition,EdgePartition也会缓存本地边关联点的Ghost副本。划分策略的不同会影响到所需要缓存的Ghost副本数量,以及每个EdgePartition分配的边的均衡程度,需要根据图的结构特征选取最佳策略。目前有EdgePartition2d、EdgePartition1d、RandomVertexCut和CanonicalRandomVertexCut这四种策略。在淘宝大部分场景下,EdgePartition2d效果最好。
-
-
Spark 的特点
-
- 运行速度快
Spark 拥有 DAG 执行引擎,支持在内存中对数据进行迭代计算。官方提供的数据表明,如果数据由磁盘读取,速度是 Hadoop MapReduce 的 10 倍以上,如果数据从内存中读取,速度可以高达 100 多倍。

Hadoop和Spark中的逻辑回归速度对比
- 易用性好
Spark不仅支持Scala编写应用程序,而且支持Java和Python等语言进行编写,特别是Scala是一种高效、可拓展的语言,能够用简洁的代码处理较为复杂的处理工作。
df = spark.read.json("logs.json")df.where("age > 21") .select("name.first").show()
Spark的Python DataFrame API 使用自动模式推断读取JSON文件
- 通用性强
Spark生态圈即BDAS(伯克利数据分析栈)包含了Spark Core、Spark SQL、Spark Streaming、MLLib和GraphX等组件,这些组件分别处理Spark Core提供内存计算框架、SparkStreaming的实时处理应用、Spark SQL的即席查询、MLlib或MLbase的机器学习和GraphX的图处理,它们都是由AMP实验室提供,能够无缝的集成并提供一站式解决平台。

- 随处运行
Spark具有很强的适应性,能够读取HDFS、Cassandra、HBase、S3和Techyon为持久层读写原生数据,能够以Mesos、YARN和自身携带的Standalone作为资源管理器调度job,来完成Spark应用程序的计算。

-
-
Spark 2.0的介绍
-
- 提升执行性能
- Spark SQL在Spark2.0 可以执行所有99 TPC-DS 查询,能够执行SQL:2003标准的新功能,支持子查询。
- SparkSession:新增SparkSession,同时具备了SQLContext与HiveContext功能。不过为了向后兼容,我们仍可以使用SQLContext 与HiveContext。
- Spark ML pipeline 机器学习程序包
- 以DataFrame为基础的机器学习程序包Spark MLpipeline 将成为主要的机器学习架构。过去Spark MLlib 程序包任然可以继续受用,未来的开发会以SparkMLpipeline为主。
- Spark MLpipeline 程序包可以存储、加载训练完成的模型。
- DataSet API
- 过去的DataFrames API 只能执行具有类型的方法,而RDD只能执行不具有类型的方法(如map、filter、groupByKey)。有了Dataset API之后,就可以同时执行具有类型的方法与不具有类型的方法。不过因为编译时类型安全(compile-time、type-safety)并不是Python和R的语言特性,所以Python和R不提供Datasets API。
- Structured Streaming APIs
- Spark2.0的Structured Streaming APIs 是新的结构化数据流处理方式。他可以使用DataFrame/Dataset API,以Catalyst优化提升性能,并且整合了Streaming数据流处理、interactive 互动查询与batch queries 批次查询。
- 其他新增功能
- R语言的分布式算法,增加了Generalized Linerar Models(GLM)、Naïve Bayes、Surival Regression 与K-Means 等算法。更简单、更高性能的Accumulator API,拥有更简洁的类型结构,而且支持基本类型。
-
Spark 成功的案例
-
目前大数据在互联网公司主要应用在广告、报表、推荐系统等业务上。在广告业务方面需要大数据做应用分析、效果分析、定向优化等,在推荐系统方面则需要大数据优化相关排名、个性化推荐以及热点点击分析等。这些应用场景的普遍特点是计算量大、效率要求高。Spark恰恰满足了这些要求,该项目一经推出便受到开源社区的广泛关注和好评。并在近两年内发展成为大数据处理领域最炙手可热的开源项目。
- 腾讯
广点通是最早使用Spark的应用之一。腾讯大数据精准推荐借助Spark快速迭代的优势,围绕“数据+算法+系统”这套技术方案,实现了在“数据实时采集、算法实时训练、系统实时预测”的全流程实时并行高维算法,最终成功应用于广点通pCTR投放系统上,支持每天上百亿的请求量。 基于日志数据的快速查询系统业务构建于Spark之上的Shark,利用其快速查询以及内存表等优势,承担了日志数据的即席查询工作。在性能方面,普遍比Hive高2-10倍,如果使用内存表的功能,性能将会比Hive快百倍。
- Yahoo
Yahoo将Spark用在Audience Expansion中的应用。Audience Expansion是广告中寻找目标用户的一种方法:首先广告者提供一些观看了广告并且购买产品的样本客户,据此进行学习,寻找更多可能转化的用户,对他们定向广告。Yahoo采用的算法是logistic regression。同时由于有些SQL负载需要更高的服务质量,又加入了专门跑Shark的大内存集群,用于取代商业BI/OLAP工具,承担报表/仪表盘和交互式/即席查询,同时与桌面BI工具对接。目前在Yahoo部署的Spark集群有112台节点,9.2TB内存。
- 淘宝
阿里搜索和广告业务,最初使用Mahout或者自己写的MR来解决复杂的机器学习,导致效率低而且代码不易维护。淘宝技术团队使用了Spark来解决多次迭代的机器学习算法、高计算复杂度的算法等。将Spark运用于淘宝的推荐相关算法上,同时还利用Graphx解决了许多生产问题,包括以下计算场景:基于度分布的中枢节点发现、基于最大连通图的社区发现、基于三角形计数的关系衡量、基于随机游走的用户属性传播等。
- 优酷土豆
优酷土豆在使用Hadoop集群的突出问题主要包括:第一是商业智能BI方面,分析师提交任务之后需要等待很久才得到结果;第二就是大数据量计算,比如进行一些模拟广告投放之时,计算量非常大的同时对效率要求也比较高,最后就是机器学习和图计算的迭代运算也是需要耗费大量资源且速度很慢。 最终发现这些应用场景并不适合在MapReduce里面去处理。通过对比,发现Spark性能比MapReduce提升很多。首先,交互查询响应快,性能比Hadoop提高若干倍;模拟广告投放计算效率高、延迟小(同hadoop比延迟至少降低一个数量级);机器学习、图计算等迭代计算,大大减少了网络传输、数据落地等,极大的提高的计算性能。目前Spark已经广泛使用在优酷土豆的视频推荐(图计算)、广告业务等。
章节二:Scala概述
Scala 是一门类 Java 的编程语言,它结合了面向对象编程和函数式编程。Scala 是纯面向对象的,每个值都是一个对象,对象的类型和行为由类定义,不同的类可以通过混入(mixin)的方式组合在一起。Scala 的设计目的是要和两种主流面向对象编程语言Java 和 C#实现无缝互操作,这两种主流语言都非纯面向对象。
Scala 也是一门函数式变成语言,每个函数都是一个值,原生支持嵌套函数定义和高阶函数。Scala 也支持一种通用形式的模式匹配,模式匹配用来操作代数式类型,在很多函数式语言中都有实现。
Scala 被设计用来和 Java 无缝互操作(另一个修改的 Scala 实现可以工作在.NET上)。Scala 类可以调用 Java 方法,创建 Java 对象,继承 Java 类和实现 Java 接口。这些都不需要额外的接口定义或者胶合代码。
学习Scala必要性:Spark是新一代内存级大数据计算框架,是大数据的重要内容。Spark就是使用Scala编写的。因此为了更好的学习Spark, 需要掌握Scala这门语言。Scala 是 Scalable Language 的简写,是一门多范式(范式/编程方式[面向对象/函数式编程])的编程语言 ,Spark的兴起,带动Scala语言的发展!虽然Spark支持Scala,Java,Python和R四种编程语言,但由于Spark是使用Scala编写的,不懂Scala就看不懂Spark源码,是不太可能很好的学好Spark的。
Windows下搭建Scala开发环境:
- 安装jdk(推荐jdk1.8)
- 在官网http://www.scala-lang.org/ 下载Scala程序安装包,本次教程安装的版本为Scala2.11.8(地址:https://downloads.lightbend.com/scala/2.11.8/scala-2.11.8.msi)。实验数据中已经提供。双击运行一直单击下一步完成安装。
- 设置 SCALA_HOME 变量:单击新建,在变量名栏输入:SCALA_HOME: 变量值一栏输入:D:\Program Files(x86)\scala (你的Scala 的安装目录)。
- 将Scala安装目录下的bin目录加入到PATH环境变量在PATH变量中添加:%SCALA_HOME%\bin。
- 运行CMD,输入Scala,输出如下内容则安装成功:

Linux 上安装 Scala(实验环境为centos7):
- 安装jdk(推荐jdk1.8)
- 在官网http://www.scala-lang.org/ 下载Scala程序安装包,本次教程安装的版本为Scala2.11.8(地址:https://downloads.lightbend.com/scala/2.11.8/scala-2.11.8.tgz)。实验数据中已经提供。

- 上传至Linux系统,通过tar -zxvf scala-2.11.8.tgz完成解压。
- 配置环境变量。运行vim ~/.bash_profile,在.bash_profile中输入如下内容:
export SCALA_HOME=/home/yjc/app/scala-2.11.8(Scala解压路径)
export PATH=$SCALA_HOME/bin:$PATH
- 运行source ~/.bash_profile,然后运行echo $SCALA_HOME,可以看到输出Scala安装路径(注意:打开新的窗口需要重新运行source ~/.bash_profile)。
- 输入Scala,回车,打开交互式窗口说明安装成功:
实验三:Scala基础
如果你学过 Java ,了解 Java 语言的基础知识,那么你能很快学会 Scala 的基础语法。Scala 与 Java 的最大区别是:Scala 语句末尾的分号 ; 是可选的。
你可以在cmd或者Linux终端进行交互式编程,输入scala,回车,即可开始编程:
2.1 Scala支持的数据类型

案列如下:

注意,var与val的区别为:val为常量,值不可变(可视为特定的值);var为变量,值可变。
Scala定义变量时可以不指定数据类型和类,当然你也可以手动写上:

Scala中的关键字(定义变量不可用):

2.2 使用IDEA开发Scala
2.2.1 安装Scala插件
单击IDEA左上角File->Settings:

选择Plugins->Marketplace->搜索Scala->安装Scala插件:

2.2.2 创建项目
点击IDEA右上角File-》New-》Project:
选择左边的Maven,勾选“Create from archetype”,选择scala-archetype-simple,然后单击“Next”:

输入GroupId:com.qingtai.scala
输入ArtifactId:HelloWorld
单击“Next”:

继续单击“Next”(可通过勾选右边的“Override”选择自己安装的Maven,也可使用IDEA自带的直接单击“Next”下一步即可):

单击“Finish”,完成项目的创建:

如果弹出如下窗口,单击“Enable Auto-Import”完成自动导包:

导入架包,本次实验使用Scala版本为2.11.8,在pom.xml中写入以下内容:
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.11.8</version>
</dependency>
有的同学的pom.xml文件可能报plugin插件错误,是因为导入了eclipse插件,直接删除对应插件即可,另外如果IDEA自动生成App类,删除即可,我们使用自己创建的Scala程序。
新建Scala Object,在com.qingtai.scala包下右键-》New-》ScalaClass:

输入Name:HelloWorld,下方的类型选择“Object”,然后单击“OK”:

HelloWorld代码:
package com.qingtai.scala
object HelloWorld {
def main(args: Array[String]): Unit = {
println("Hello World!")
println("Hello Scala!")
}
}
右键运行Scala程序:

可以看到控制台的输出:

2.3 Scala运算符
2.3.1 算术运算符
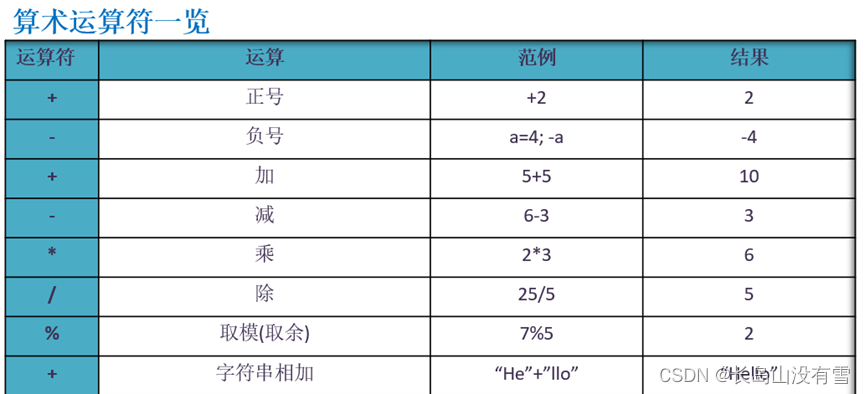
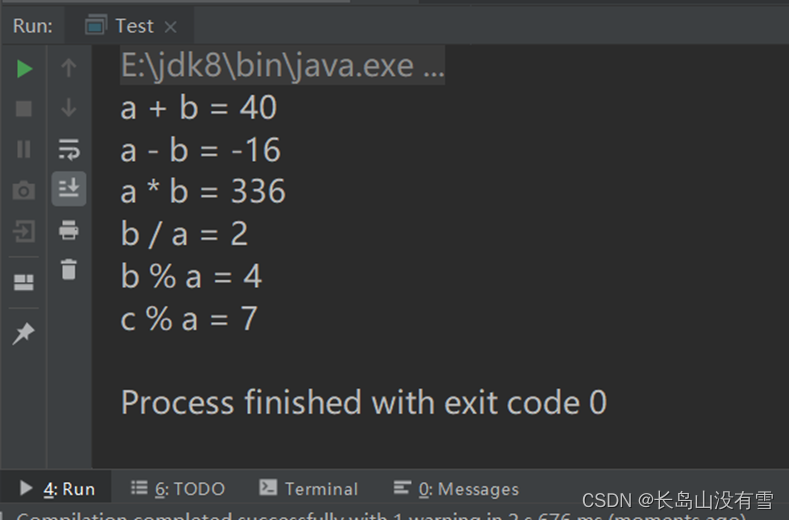
运行如下代码:
package com.qingtai.scala
object Test {
def main(args: Array[String]): Unit = {
val a: Int = 12
val b: Int = 28
val c: Int = 55
val d: Int = 15
println("a + b = " + (a + b))
println("a - b = " + (a - b))
println("a * b = " + (a * b))
println("b / a = " + (b / a))
println("b % a = " + (b % a))
println("c % a = " + (c % a))
}
}
控制台输出结果:
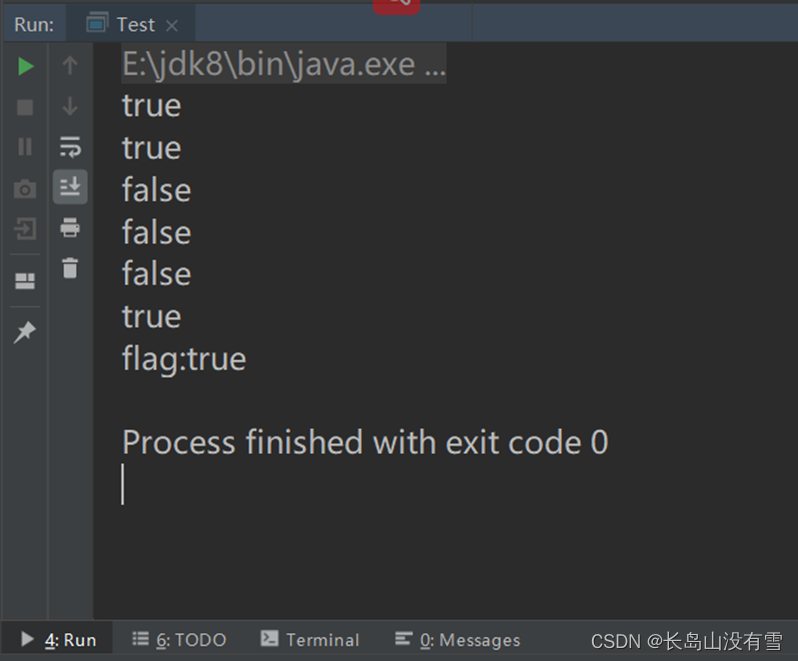
2.3.2 关系运算符

运行如下代码:
package com.qingtai.scala
object Test {
def main(args: Array[String]): Unit = {
val a = 12
val b = 6
println(a>b)
println(a>=b)
println(a<=b)
println(a<b)
println(a==b)
println(a!=b)
val flag : Boolean = a>b
println("flag:"+flag)
}
}
控制台运行结果:
2.3.3 逻辑运算符
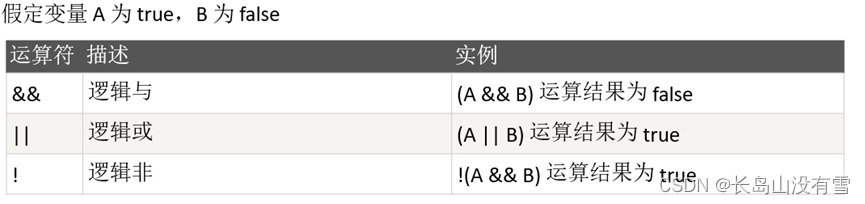
运行如下代码:
package com.qingtai.scala
object Test {
def main(args: Array[String]): Unit = {
val a: Boolean = true
val b: Boolean = false
println("a && b = " + (a && b))
println("a || b = " + (a || b))
println("!a = " + !a)
}
}
控制台运行结果:

2.3.4赋值运算符

2.4 程序流程控制
2.4.1 if...else
案列代码:
package com.qingtai.scala
object Test {
def main(args: Array[String]): Unit = {
val x: Int = 12
if (x < 20) println("x 小于 20")
else println("x 大于 20")
}
}
控制台运行结果:

if...else if...else 语句,if...else 嵌套语句与Java一样,不再举例。
2.5 Scala循环
2.5.1 while循环
案列代码:
package com.qingtai.scala
object Test {
def main(args: Array[String]): Unit = {
var a = 1
while( a < 5 ){
println( "a: " + a )
a = a + 1
}
}
}
控制台运行结果:
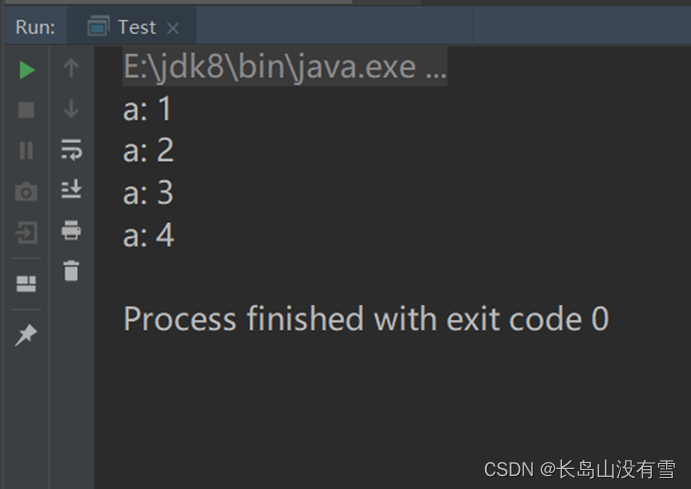
2.5.2 do...while循环
案列代码:
package com.qingtai.scala
object Test {
def main(args: Array[String]): Unit = {
var a: Int = 10
do {
println("Value of a: " + a)
a = a + 1
} while (a < 16)
}
}
控制台运行结果:

2.5.3 for循环
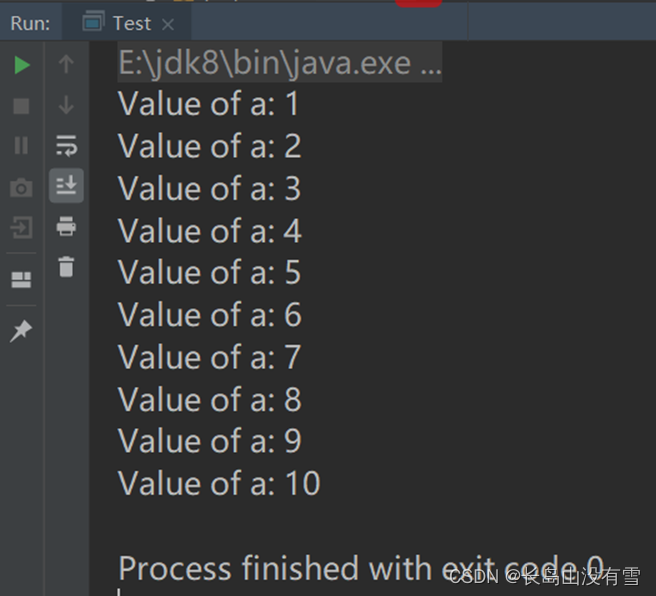
案列代码:
package com.qingtai.scala
object Test {
def main(args: Array[String]): Unit = {
for( a <- 1 to 10){
println( "Value of a: " + a )
}
}
}
控制台运行结果:
2.5.3 break和continue
Scala里面没有break和contine关键字,Scala里面推荐使用函数式的风格解决break和contine的功能,而不是一个关键字。导入如下包:
import util.control.Breaks._
案列代码:
package com.qingtai.scala
import scala.util.control.Breaks._
object Test {
def main(args: Array[String]): Unit = {
println("-------------------break-------------------")
breakable(
for (i <- 1 to 10){
println(i)
if(i == 5){
break()
}
}
)
println("-------------------continue-------------------")
for (i <- 1 to 10){
breakable {
if (i == 5) {
break()
}
println(i)
}
}
}
}
控制台运行结果:

先导入Breaks的包,break的语法是break(...),省略号中写入代码,用break()跳出。continue的语法是{...},其他和break语法一样,注意这里要用{},不然会报错。
2.6 Scala函数/方法
Scala有方法与函数,二者在语义上的区别很小。Scala 方法是类的一部分,而函数是一个对象可以赋值给一个变量。换句话来说在类中定义的函数即是方法。大家不必刻意去区分,认为它们是一样的就可以了。
函数的定义:

- 函数声明关键字为def (definition)
- [参数名: 参数类型], ...:表示函数的输入(就是参数列表), 可以没有。 如果有,多个参数使用逗号间隔
- 函数内部表示为了实现某一功能代码块
- 函数可以有返回值,也可以没有
- Return关键字可以不写 ,默认以最后一行的结果作为返回值
函数案列代码:
package com.qingtai.scala
object Test {
def main(args: Array[String]): Unit = {
sayHello()
println(getHello())
add(3, 5)
println(getSum(4, 8))
}
//无参无返回值函数案例
def sayHello(): Unit = {
println("Hello World!")
}
//无参有返回值函数案例
def getHello(): String = {
"Hello"
}
//有参无返回值函数案例
def add(a: Int, b: Int): Unit = {
val sum: Int = a + b
println(a + "+" + b + "=" + sum)
}
//有参有返回值函数案例
def getSum(a: Int, b: Int): Int = {
a + b
}
}
控制台运行结果:

2.7 Scala数组
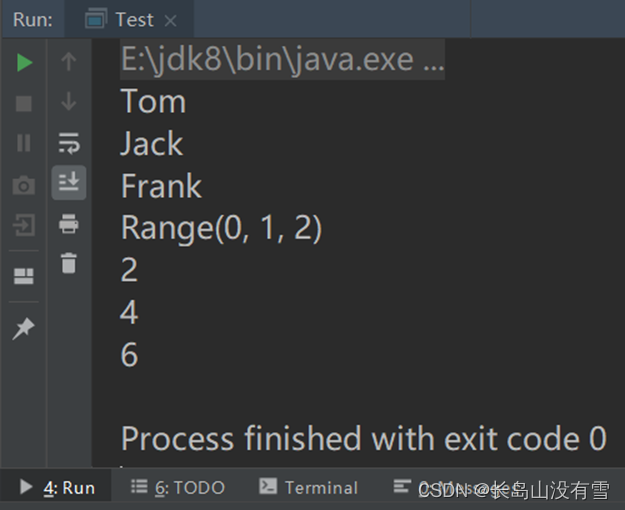
案列代码:
package com.qingtai.scala
object Test {
def main(args: Array[String]): Unit = {
//单个赋值
val names: Array[String] = new Array[String](3)
names(0) = "Tom"
names(1) = "Jack"
names(2) = "Frank"
//等同于Java中的for(String name:names){}
for (name <- names) {
println(name)
}
//直接赋值
val ints: Array[Int] = Array(1, 2, 3)
//0 to 2 等于(0,1,2)
println(0 to 2)
//等同于Java中的for(int i=0;i<3;i++){}
for (i <- 0 to 2) {
println(ints(i) * 2)
}
}
}
控制台运行结果:
数组常用方法,使用前需要导入import Array._ 包:
| 1 |
def apply( x: T, xs: T* ): Array[T] 创建指定对象 T 的数组, T 的值可以是 Unit, Double, Float, Long, Int, Char, Short, Byte, Boolean。 |
| 2 |
def concat[T]( xss: Array[T]* ): Array[T] 合并数组 |
| 3 |
def copy( src: AnyRef, srcPos: Int, dest: AnyRef, destPos: Int, length: Int ): Unit 复制一个数组到另一个数组上。相等于 Java's System.arraycopy(src, srcPos, dest, destPos, length)。 |
| 4 |
def empty[T]: Array[T] 返回长度为 0 的数组 |
| 5 |
def iterate[T]( start: T, len: Int )( f: (T) => T ): Array[T] 返回指定长度数组,每个数组元素为指定函数的返回值。 以上实例数组初始值为 0,长度为 3,计算函数为a=>a+1: scala> Array.iterate(0,3)(a=>a+1)
res1: Array[Int] = Array(0, 1, 2)
|
| 6 |
def fill[T]( n: Int )(elem: => T): Array[T] 返回数组,长度为第一个参数指定,同时每个元素使用第二个参数进行填充。 |
| 7 |
def fill[T]( n1: Int, n2: Int )( elem: => T ): Array[Array[T]] 返回二数组,长度为第一个参数指定,同时每个元素使用第二个参数进行填充。 |
| 8 |
def ofDim[T]( n1: Int ): Array[T] 创建指定长度的数组 |
| 9 |
def ofDim[T]( n1: Int, n2: Int ): Array[Array[T]] 创建二维数组 |
| 10 |
def ofDim[T]( n1: Int, n2: Int, n3: Int ): Array[Array[Array[T]]] 创建三维数组 |
| 11 |
def range( start: Int, end: Int, step: Int ): Array[Int] 创建指定区间内的数组,step 为每个元素间的步长 |
| 12 |
def range( start: Int, end: Int ): Array[Int] 创建指定区间内的数组 |
| 13 |
def tabulate[T]( n: Int )(f: (Int)=> T): Array[T] 返回指定长度数组,每个数组元素为指定函数的返回值,默认从 0 开始。 以上实例返回 3 个元素: scala> Array.tabulate(3)(a => a + 5)
res0: Array[Int] = Array(5, 6, 7)
|
| 14 |
def tabulate[T]( n1: Int, n2: Int )( f: (Int, Int ) => T): Array[Array[T]] 返回指定长度的二维数组,每个数组元素为指定函数的返回值,默认从 0 开始。 |
2.8 Scala字符串常用方法
| 1 |
char charAt(int index) 返回指定位置的字符 |
| 2 |
int compareTo(Object o) 比较字符串与对象 |
| 3 |
int compareTo(String anotherString) 按字典顺序比较两个字符串 |
| 4 |
int compareToIgnoreCase(String str) 按字典顺序比较两个字符串,不考虑大小写 |
| 5 |
String concat(String str) 将指定字符串连接到此字符串的结尾 |
| 6 |
boolean contentEquals(StringBuffer sb) 将此字符串与指定的 StringBuffer 比较。 |
| 7 |
static String copyValueOf(char[] data) 返回指定数组中表示该字符序列的 String |
| 8 |
static String copyValueOf(char[] data, int offset, int count) 返回指定数组中表示该字符序列的 String |
| 9 |
boolean endsWith(String suffix) 测试此字符串是否以指定的后缀结束 |
| 10 |
boolean equals(Object anObject) 将此字符串与指定的对象比较 |
| 11 |
boolean equalsIgnoreCase(String anotherString) 将此 String 与另一个 String 比较,不考虑大小写 |
| 12 |
byte getBytes() 使用平台的默认字符集将此 String 编码为 byte 序列,并将结果存储到一个新的 byte 数组中 |
| 13 |
byte[] getBytes(String charsetName 使用指定的字符集将此 String 编码为 byte 序列,并将结果存储到一个新的 byte 数组中 |
| 14 |
void getChars(int srcBegin, int srcEnd, char[] dst, int dstBegin) 将字符从此字符串复制到目标字符数组 |
| 15 |
int hashCode() 返回此字符串的哈希码 |
| 16 |
int indexOf(int ch) 返回指定字符在此字符串中第一次出现处的索引 |
| 17 |
int indexOf(int ch, int fromIndex) 返回在此字符串中第一次出现指定字符处的索引,从指定的索引开始搜索 |
| 18 |
int indexOf(String str) 返回指定子字符串在此字符串中第一次出现处的索引 |
| 19 |
int indexOf(String str, int fromIndex) 返回指定子字符串在此字符串中第一次出现处的索引,从指定的索引开始 |
| 20 |
String intern() 返回字符串对象的规范化表示形式 |
| 21 |
int lastIndexOf(int ch) 返回指定字符在此字符串中最后一次出现处的索引 |
| 22 |
int lastIndexOf(int ch, int fromIndex) 返回指定字符在此字符串中最后一次出现处的索引,从指定的索引处开始进行反向搜索 |
| 23 |
int lastIndexOf(String str) 返回指定子字符串在此字符串中最右边出现处的索引 |
| 24 |
int lastIndexOf(String str, int fromIndex) 返回指定子字符串在此字符串中最后一次出现处的索引,从指定的索引开始反向搜索 |
| 25 |
int length() 返回此字符串的长度 |
| 26 |
boolean matches(String regex) 告知此字符串是否匹配给定的正则表达式 |
| 27 |
boolean regionMatches(boolean ignoreCase, int toffset, String other, int ooffset, int len) 测试两个字符串区域是否相等 |
| 28 |
boolean regionMatches(int toffset, String other, int ooffset, int len) 测试两个字符串区域是否相等 |
| 29 |
String replace(char oldChar, char newChar) 返回一个新的字符串,它是通过用 newChar 替换此字符串中出现的所有 oldChar 得到的 |
| 30 |
String replaceAll(String regex, String replacement 使用给定的 replacement 替换此字符串所有匹配给定的正则表达式的子字符串 |
| 31 |
String replaceFirst(String regex, String replacement) 使用给定的 replacement 替换此字符串匹配给定的正则表达式的第一个子字符串 |
| 32 |
String[] split(String regex) 根据给定正则表达式的匹配拆分此字符串 |
| 33 |
String[] split(String regex, int limit) 根据匹配给定的正则表达式来拆分此字符串 |
| 34 |
boolean startsWith(String prefix) 测试此字符串是否以指定的前缀开始 |
| 35 |
boolean startsWith(String prefix, int toffset) 测试此字符串从指定索引开始的子字符串是否以指定前缀开始。 |
| 36 |
CharSequence subSequence(int beginIndex, int endIndex) 返回一个新的字符序列,它是此序列的一个子序列 |
| 37 |
String substring(int beginIndex) 返回一个新的字符串,它是此字符串的一个子字符串 |
| 38 |
String substring(int beginIndex, int endIndex) 返回一个新字符串,它是此字符串的一个子字符串 |
| 39 |
char[] toCharArray() 将此字符串转换为一个新的字符数组 |
| 40 |
String toLowerCase() 使用默认语言环境的规则将此 String 中的所有字符都转换为小写 |
| 41 |
String toLowerCase(Locale locale) 使用给定 Locale 的规则将此 String 中的所有字符都转换为小写 |
| 42 |
String toString() 返回此对象本身(它已经是一个字符串!) |
| 43 |
String toUpperCase() 使用默认语言环境的规则将此 String 中的所有字符都转换为大写 |
| 44 |
String toUpperCase(Locale locale) 使用给定 Locale 的规则将此 String 中的所有字符都转换为大写 |
| 45 |
String trim() 删除指定字符串的首尾空白符 |
| 46 |
static String valueOf(primitive data type x) 返回指定类型参数的字符串表示形式 |
2.9 Scala集合
Scala同时支持不可变集合和可变集合,不可变集合可以安全的并发访问
- 不可变集合:scala.collection.immutable
- 可变集合: scala.collection.mutable
2.9.1 Scala List(列表)
List称为列表。
Scala中的List 和Java List 不一样,在Java中List是一个接口,真正存放数据是ArrayList,而Scala的List可以直接存放数据,就是一个object,默认情况下Scala的List是不可变的。
可通过如下方法建立List:
// 字符串列表
val site: List[String] = List("Runoob", "Google", "Baidu")
// 整型列表
val nums: List[Int] = List(1, 2, 3, 4)
// 空列表
val empty: List[Nothing] = List()
// 二维列表
val dim: List[List[Int]] =
List(
List(1, 0, 0),
List(0, 1, 0),
List(0, 0, 1)
)
构造列表的两个基本单位是 Nil 和 ::
Nil 也可以表示为一个空列表。
::可以看成是往List中添加元素或新的List。
如下:
// 字符串列表
val site = "Runoob" :: ("Google" :: ("Baidu" :: Nil))
// 整型列表
val nums = 1 :: (2 :: (3 :: (4 :: Nil)))
// 空列表
val empty = Nil
// 二维列表
val dim = (1 :: (0 :: (0 :: Nil))) ::
(0 :: (1 :: (0 :: Nil))) ::
(0 :: (0 :: (1 :: Nil))) :: Nil
Scala列表有三个基本操作:
- head 返回列表第一个元素
- tail 返回一个列表,包含除了第一元素之外的其他元素
- isEmpty 在列表为空时返回true
案例代码:
package com.qingtai.scala
object Test {
def main(args: Array[String]): Unit = {
val student = "Robort" :: ("Mark" :: ("John" :: Nil))
val nums = Nil
println("第一个同学是 : " + student.head)
println("最后一位同学是 : " + student.tail)
println("查看student列表是否为空 : " + student.isEmpty)
println("查看 nums是否为空 : " + nums.isEmpty)
}
}
控制台运行结果:

你可以使用 ::: 运算符或 List.:::() 方法或 List.concat() 方法来连接两个或多个列表。实例如下:
package com.qingtai.scala
object Test {
def main(args: Array[String]): Unit = {
val site1 = "Runoob" :: ("Google" :: ("Baidu" :: Nil))
val site2 = "Facebook" :: ("Taobao" :: Nil)
// 使用 ::: 运算符
var fruit = site1 ::: site2
println("site1 ::: site2 : " + fruit)
// 使用 List.:::() 方法
fruit = site1.:::(site2)
println("site1.:::(site2) : " + fruit)
// 使用 concat 方法
fruit = List.concat(site1, site2)
println("List.concat(site1, site2) : " + fruit)
}
}
Scala List 常用的方法:
| 1 |
def +:(elem: A): List[A] 为列表预添加元素 scala> val x = List(1)
x: List[Int] = List(1)
scala> val y = 2 +: x
y: List[Int] = List(2, 1)
scala> println(x)
List(1)
|
| 2 |
def ::(x: A): List[A] 在列表开头添加元素 |
| 3 |
def :::(prefix: List[A]): List[A] 在列表开头添加指定列表的元素 |
| 4 |
def :+(elem: A): List[A] 复制添加元素后列表。 scala> val a = List(1)
a: List[Int] = List(1)
scala> val b = a :+ 2
b: List[Int] = List(1, 2)
scala> println(a)
List(1)
|
| 5 |
def addString(b: StringBuilder): StringBuilder 将列表的所有元素添加到 StringBuilder |
| 6 |
def addString(b: StringBuilder, sep: String): StringBuilder 将列表的所有元素添加到 StringBuilder,并指定分隔符 |
| 7 |
def apply(n: Int): A 通过列表索引获取元素 |
| 8 |
def contains(elem: Any): Boolean 检测列表中是否包含指定的元素 |
| 9 |
def copyToArray(xs: Array[A], start: Int, len: Int): Unit 将列表的元素复制到数组中。 |
| 10 |
def distinct: List[A] 去除列表的重复元素,并返回新列表 |
| 11 |
def drop(n: Int): List[A] 丢弃前n个元素,并返回新列表 |
| 12 |
def dropRight(n: Int): List[A] 丢弃最后n个元素,并返回新列表 |
| 13 |
def dropWhile(p: (A) => Boolean): List[A] 从左向右丢弃元素,直到条件p不成立 |
| 14 |
def endsWith[B](that: Seq[B]): Boolean 检测列表是否以指定序列结尾 |
| 15 |
def equals(that: Any): Boolean 判断是否相等 |
| 16 |
def exists(p: (A) => Boolean): Boolean 判断列表中指定条件的元素是否存在。 判断l是否存在某个元素: scala> l.exists(s => s == "Hah")
res7: Boolean = true
|
| 17 |
def filter(p: (A) => Boolean): List[A] 输出符号指定条件的所有元素。 过滤出长度为3的元素: scala> l.filter(s => s.length == 3)
res8: List[String] = List(Hah, WOW)
|
| 18 |
def forall(p: (A) => Boolean): Boolean 检测所有元素。 例如:判断所有元素是否以"H"开头: scala> l.forall(s => s.startsWith("H")) res10: Boolean = false |
| 19 |
def foreach(f: (A) => Unit): Unit 将函数应用到列表的所有元素 |
| 20 |
def head: A 获取列表的第一个元素 |
| 21 |
def indexOf(elem: A, from: Int): Int 从指定位置 from 开始查找元素第一次出现的位置 |
| 22 |
def init: List[A] 返回所有元素,除了最后一个 |
| 23 |
def intersect(that: Seq[A]): List[A] 计算多个集合的交集 |
| 24 |
def isEmpty: Boolean 检测列表是否为空 |
| 25 |
def iterator: Iterator[A] 创建一个新的迭代器来迭代元素 |
| 26 |
def last: A 返回最后一个元素 |
| 27 |
def lastIndexOf(elem: A, end: Int): Int 在指定的位置 end 开始查找元素最后出现的位置 |
| 28 |
def length: Int 返回列表长度 |
| 29 |
def map[B](f: (A) => B): List[B] 通过给定的方法将所有元素重新计算 |
| 30 |
def max: A 查找最大元素 |
| 31 |
def min: A 查找最小元素 |
| 32 |
def mkString: String 列表所有元素作为字符串显示 |
| 33 |
def mkString(sep: String): String 使用分隔符将列表所有元素作为字符串显示 |
| 34 |
def reverse: List[A] 列表反转 |
| 35 |
def sorted[B >: A]: List[A] 列表排序 |
| 36 |
def startsWith[B](that: Seq[B], offset: Int): Boolean 检测列表在指定位置是否包含指定序列 |
| 37 |
def sum: A 计算集合元素之和 |
| 38 |
def tail: List[A] 返回所有元素,除了第一个 |
| 39 |
def take(n: Int): List[A] 提取列表的前n个元素 |
| 40 |
def takeRight(n: Int): List[A] 提取列表的后n个元素 |
| 41 |
def toArray: Array[A] 列表转换为数组 |
| 42 |
def toBuffer[B >: A]: Buffer[B] 返回缓冲区,包含了列表的所有元素 |
| 43 |
def toMap[T, U]: Map[T, U] List 转换为 Map |
| 44 |
def toSeq: Seq[A] List 转换为 Seq |
| 45 |
def toSet[B >: A]: Set[B] List 转换为 Set |
| 46 |
def toString(): String 列表转换为字符串 |
ListBuffer是可变的list集合,可以添加,删除元素,ListBuffer属于序列。
案例如下:
package com.qingtai.scala
import scala.collection.mutable.ListBuffer
object Test {
def main(args: Array[String]): Unit = {
val lb0 = ListBuffer[Int](1, 2, 3)
//输出lb0(1)=2
println("lb0(1)=" + lb0(1))
//输出ListBuffer(1, 2, 3)
println(lb0)
val lb1 = new ListBuffer[Int]
lb1 += 4
lb1.append(5)
//输出ListBuffer(4, 5)
println(lb1)
val lb2 = lb0 ++ lb1
//输出ListBuffer(1, 2, 3, 4, 5)
println(lb2)
val lb3 = lb0 :+ 5
//输出ListBuffer(1, 2, 3, 5)
println(lb3)
println("=====删除=====")
//输出lb1=ListBuffer(4, 5)
println("lb1=" + lb1)
lb1.remove(1)
//输出lb1=ListBuffer(4)
println("lb1=" + lb1)
}
}
控制台输出结果:

2.9.2 Scala Set(集合)
Scala Set(集合)是没有重复的对象集合,所有的元素都是唯一的。Scala 集合分为可变的和不可变的集合。默认情况下,Scala 使用的是不可变集合,如果你想使用可变集合,需要引用 scala.collection.mutable.Set 包。默认引用 scala.collection.immutable.Set。
注意: 虽然可变Set和不可变Set都有添加或删除元素的操作,但是有一个非常大的差别。对不可变Set进行操作,会产生一个新的set,原来的set并没有改变,这与List一样。 而对可变Set进行操作,改变的是该Set本身,与ListBuffer类似。
不可变集合创建:
val set = Set(1, 2, 3) //不可变
println(set)
可变集合创建:
import scala.collection.mutable.Set
val mutableSet = Set(1, 2, 3) //可变
案例代码:
package com.qingtai.scala
import scala.collection.mutable
object Test {
def main(args: Array[String]): Unit = {
val set1 = Set(1, 2, 4, "abc")
println(set1)
val set2 = mutable.Set(1, 2, 4, "abc")
println(set2)
}
}
控制台输出结果:

Scala集合有三个基本操作:
- head 返回集合第一个元素
- tail 返回一个集合,包含除了第一元素之外的其他元素
- isEmpty 在集合为空时返回true
案例代码:
package com.qingtai.scala
object Test {
def main(args: Array[String]): Unit = {
val student = Set("Robort", "Mark", "John")
val nums = Set()
println("第一个同学是 : " + student.head)
println("最后一位同学是 : " + student.tail)
println("查看student列表是否为空 : " + student.isEmpty)
println("查看 nums是否为空 : " + nums.isEmpty)
}
}
控制台输出结果:

集合Set的添加和删除:
案例代码:
package com.qingtai.scala
import scala.collection.mutable.Set
object Test {
def main(args: Array[String]): Unit = {
val student = Set("Robort", "Mark", "John")
println("第一个同学是 : " + student.head)
println("最后一位同学是 : " + student.tail)
println(student)
//添加元素
student.add("Frank")
student.+=("Lucy")
student += ("XiaoMing")
println(student)
//删除元素
student.remove("Lucy")
student.-=("Mark")
//如果删除的对象不存在,则不生效,也不会报错
student -= ("Jhon")
println(student)
}
}
控制台输出结果:

常用方法:
| 序号 |
方法 |
描述 |
| 1 |
def +(elem: A): Set[A] |
为集合添加新元素,并创建一个新的集合,除非元素已存在 |
| 2 |
def -(elem: A): Set[A] |
移除集合中的元素,并创建一个新的集合 |
| 3 |
def contains(elem: A): Boolean |
如果元素在集合中存在,返回 true,否则返回 false。 |
| 4 |
def &(that: Set[A]): Set[A] |
返回两个集合的交集 |
| 5 |
def &~(that: Set[A]): Set[A] |
返回两个集合的差集 |
| 6 |
def ++(elems: A): Set[A] |
合并两个集合 |
| 7 |
def drop(n: Int): Set[A]] |
返回丢弃前n个元素新集合 |
| 8 |
def dropRight(n: Int): Set[A] |
返回丢弃最后n个元素新集合 |
| 9 |
def dropWhile(p: (A) => Boolean): Set[A] |
从左向右丢弃元素,直到条件p不成立 |
| 10 |
def max: A //演示下 |
查找最大元素 |
| 11 |
def min: A //演示下 |
查找最小元素 |
| 12 |
def take(n: Int): Set[A] |
返回前 n 个元素 |
2.9.3 Scala Map(映射)
Map(映射)是一种可迭代的键值对(key/value)结构。所有的值都可以通过键来获取。Map 中的键都是唯一的。Map 也叫哈希表(Hash tables)。Map 有两种类型,可变与不可变,区别在于可变对象可以修改它,而不可变对象不可以。Scala中不可变的Map是有序的,可变的Map是无序的。默认情况下 Scala 使用不可变 Map。如果你需要使用可变集合,你需要显式的引入 import scala.collection.mutable.Map 类。
创建Map案列:
package com.qingtai.scala
object Test {
def main(args: Array[String]): Unit = {
val map1 = Map("Alice" -> 10, "Bob" -> 20, "Kotlin" -> "北京")
println(map1)
val map2 = scala.collection.mutable.Map("Alice" -> 10, "Bob" -> 20, "Kotlin" -> 30)
println(map2)
map2+=("XiaoMing"->16)
map2-=("Bob")
println(map2)
}
}
控制台输出结果:

Scala Map 有三个基本操作:
| keys |
返回 Map 所有的键(key) |
| values |
返回 Map 所有的值(value) |
| isEmpty |
在 Map 为空时返回true |
案例代码(遍历):
package com.qingtai.scala
object Test {
def main(args: Array[String]): Unit = {
val nums: Map[Int, Int] = Map()
println( "检测 nums 是否为空 : " + nums.isEmpty )
val colors = Map("red" -> "#FF0000",
"azure" -> "#F0FFFF",
"peru" -> "#CD853F")
println( "检测 colors 是否为空 : " + colors.isEmpty )
println( "colors 中的键为 : " + colors.keys )
for(key <- colors.keys){
println(key + colors.get(key))
}
println( "colors 中的值为 : " + colors.values )
for(value <- colors.values){
println(value)
}
}
}
控制台输出结果:

常用方法:
| 1 |
def ++(xs: Map[(A, B)]): Map[A, B] 返回一个新的 Map,新的 Map xs 组成 |
| 2 |
def -(elem1: A, elem2: A, elems: A*): Map[A, B] 返回一个新的 Map, 移除 key 为 elem1, elem2 或其他 elems。 |
| 3 |
def --(xs: GTO[A]): Map[A, B] 返回一个新的 Map, 移除 xs 对象中对应的 key |
| 4 |
def get(key: A): Option[B] 返回指定 key 的值 |
| 5 |
def iterator: Iterator[(A, B)] 创建新的迭代器,并输出 key/value 对 |
| 6 |
def addString(b: StringBuilder): StringBuilder 将 Map 中的所有元素附加到StringBuilder,可加入分隔符 |
| 7 |
def addString(b: StringBuilder, sep: String): StringBuilder 将 Map 中的所有元素附加到StringBuilder,可加入分隔符 |
| 8 |
def apply(key: A): B 返回指定键的值,如果不存在返回 Map 的默认方法 |
| 9 |
def clear(): Unit 清空 Map |
| 10 |
def clone(): Map[A, B] 从一个 Map 复制到另一个 Map |
| 11 |
def contains(key: A): Boolean 如果 Map 中存在指定 key,返回 true,否则返回 false。 |
| 12 |
def copyToArray(xs: Array[(A, B)]): Unit 复制集合到数组 |
| 13 |
def count(p: ((A, B)) => Boolean): Int 计算满足指定条件的集合元素数量 |
| 14 |
def default(key: A): B 定义 Map 的默认值,在 key 不存在时返回。 |
| 15 |
def drop(n: Int): Map[A, B] 返回丢弃前n个元素新集合 |
| 16 |
def dropRight(n: Int): Map[A, B] 返回丢弃最后n个元素新集合 |
| 17 |
def dropWhile(p: ((A, B)) => Boolean): Map[A, B] 从左向右丢弃元素,直到条件p不成立 |
| 18 |
def empty: Map[A, B] 返回相同类型的空 Map |
| 19 |
def equals(that: Any): Boolean 如果两个 Map 相等(key/value 均相等),返回true,否则返回false |
| 20 |
def exists(p: ((A, B)) => Boolean): Boolean 判断集合中指定条件的元素是否存在 |
| 21 |
def filter(p: ((A, B))=> Boolean): Map[A, B] 返回满足指定条件的所有集合 |
| 22 |
def filterKeys(p: (A) => Boolean): Map[A, B] 返回符合指定条件的不可变 Map |
| 23 |
def find(p: ((A, B)) => Boolean): Option[(A, B)] 查找集合中满足指定条件的第一个元素 |
| 24 |
def foreach(f: ((A, B)) => Unit): Unit 将函数应用到集合的所有元素 |
| 25 |
def init: Map[A, B] 返回所有元素,除了最后一个 |
| 26 |
def isEmpty: Boolean 检测 Map 是否为空 |
| 27 |
def keys: Iterable[A] 返回所有的key/p> |
| 28 |
def last: (A, B) 返回最后一个元素 |
| 29 |
def max: (A, B) 查找最大元素 |
| 30 |
def min: (A, B) 查找最小元素 |
| 31 |
def mkString: String 集合所有元素作为字符串显示 |
| 32 |
def product: (A, B) 返回集合中数字元素的积。 |
| 33 |
def remove(key: A): Option[B] 移除指定 key |
| 34 |
def retain(p: (A, B) => Boolean): Map.this.type 如果符合满足条件的返回 true |
| 35 |
def size: Int 返回 Map 元素的个数 |
| 36 |
def sum: (A, B) 返回集合中所有数字元素之和 |
| 37 |
def tail: Map[A, B] 返回一个集合中除了第一元素之外的其他元素 |
| 38 |
def take(n: Int): Map[A, B] 返回前 n 个元素 |
| 39 |
def takeRight(n: Int): Map[A, B] 返回后 n 个元素 |
| 40 |
def takeWhile(p: ((A, B)) => Boolean): Map[A, B] 返回满足指定条件的元素 |
| 41 |
def toArray: Array[(A, B)] 集合转数组 |
| 42 |
def toBuffer[B >: A]: Buffer[B] 返回缓冲区,包含了 Map 的所有元素 |
| 43 |
def toList: List[A] 返回 List,包含了 Map 的所有元素 |
| 44 |
def toSeq: Seq[A] 返回 Seq,包含了 Map 的所有元素 |
| 45 |
def toSet: Set[A] 返回 Set,包含了 Map 的所有元素 |
| 46 |
def toString(): String 返回字符串对象 |
2.9.4 Scala Tuple(元组)
元组也是可以理解为一个容器,可以存放各种相同或不同类型的数据。元组的值是通过将单个的值包含在圆括号中构成的。元组中最大只能有22个元素 即 Tuple1...Tuple22。
创建Tuple案例:
package com.qingtai.scala
object Test {
def main(args: Array[String]): Unit = {
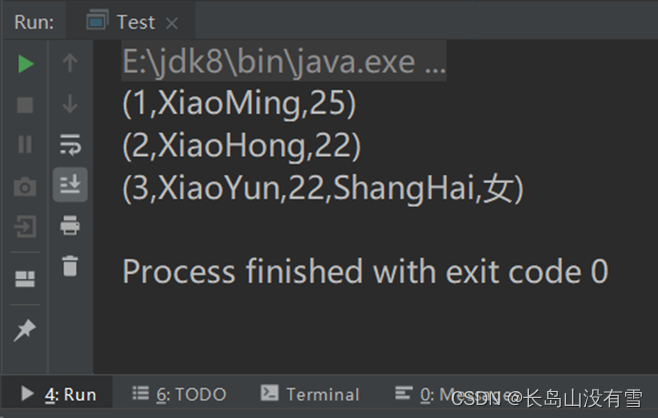
val t1 = (1, "XiaoMing", 25)
println(t1)
//元组中最大只能有22个元素 即 Tuple1...Tuple22
val t2 = new Tuple3(2, "XiaoHong", 22)
println(t2)
val t3 = new Tuple5(3, "XiaoYun", 22, "ShangHai", "女")
println(t3)
}
}
控制台输出结果:
- 访问元组中的数据,可以采用顺序号(_顺序号),也可以通过索引(productElement)访问
- Tuple是一个整体,遍历需要调其迭代器Tuple.productIterator()
案例代码:
package com.qingtai.scala
object Test {
def main(args: Array[String]): Unit = {
val t = (1, "XiaoMing", 23, "男", "程序员")
println(t._1)
println(t.productElement(2))
t.productIterator.foreach {
i => println("Value = " + i)
}
println(t)
}
}
控制台输出结果:

2.9.5 Scala Option(选项)
Scala Option(选项)类型用来表示一个值是可选的(有值或无值)。Option[T] 是一个类型为 T 的可选值的容器:如果值存在,Option[T] 就是一个 Some[T] ,如果不存在,Option[T] 就是对象 None 。
案例如下:
package com.qingtai.scala
object Test {
def main(args: Array[String]): Unit = {
val map: Map[String, String] = Map("k1" -> "v1")
val v1: Option[String] = map.get("k1")
val v2: Option[String] = map.get("k2")
println(v1) // Some(v1)
println(v2) // None
}
}
控制台输出结果:

getOrElse()方法:
如果Option中有值则输出对应的值,如果没有则输出默认值。如下:
package com.qingtai.scala
object Test {
def main(args: Array[String]): Unit = {
val a = Some("Hello Scala!")
val b = None
println(a.getOrElse("Hello World!") )
println(b.getOrElse("Hello World!") )
}
}
控制台输出结果:

Scala Option 常用方法:
| 1 |
def get: A 获取可选值 |
| 2 |
def isEmpty: Boolean 检测可选类型值是否为 None,是的话返回 true,否则返回 false |
| 3 |
def productArity: Int 返回元素个数, A(x_1, ..., x_k), 返回 k |
| 4 |
def productElement(n: Int): Any 获取指定的可选项,以 0 为起始。即 A(x_1, ..., x_k), 返回 x_(n+1) , 0 < n < k. |
| 5 |
def exists(p: (A) => Boolean): Boolean 如果可选项中指定条件的元素存在且不为 None 返回 true,否则返回 false。 |
| 6 |
def filter(p: (A) => Boolean): Option[A] 如果选项包含有值,而且传递给 filter 的条件函数返回 true, filter 会返回 Some 实例。 否则,返回值为 None 。 |
| 7 |
def filterNot(p: (A) => Boolean): Option[A] 如果选项包含有值,而且传递给 filter 的条件函数返回 false, filter 会返回 Some 实例。 否则,返回值为 None 。 |
| 8 |
def flatMap[B](f: (A) => Option[B]): Option[B] 如果选项包含有值,则传递给函数 f 处理后返回,否则返回 None |
| 9 |
def foreach[U](f: (A) => U): Unit 如果选项包含有值,则将每个值传递给函数 f, 否则不处理。 |
| 10 |
def getOrElse[B >: A](default: => B): B 如果选项包含有值,返回选项值,否则返回设定的默认值。 |
| 11 |
def isDefined: Boolean 如果可选值是 Some 的实例返回 true,否则返回 false。 |
| 12 |
def iterator: Iterator[A] 如果选项包含有值,迭代出可选值。如果可选值为空则返回空迭代器。 |
| 13 |
def map[B](f: (A) => B): Option[B] 如果选项包含有值, 返回由函数 f 处理后的 Some,否则返回 None |
| 14 |
def orElse[B >: A](alternative: => Option[B]): Option[B] 如果一个 Option 是 None , orElse 方法会返回传名参数的值,否则,就直接返回这个 Option。 |
| 15 |
def orNull 如果选项包含有值返回选项值,否则返回 null。 |
2.9.6 集合中常用元素操作
map操作
现提出如下问题:请将List(4,8,9,13,15) 中的所有元素都 * 2 ,将其结果放到一个新的集合中返回,即返回一个新的List, 请编写程序实现。
传统的解决方案是取出list中的每一个值乘以2,然后保存到新的List中,案例代码如下:
package com.qingtai.scala
object Test {
def main(args: Array[String]): Unit = {
val list1: List[Int] = List(4, 8, 9, 13, 15)
//传统方法
var list2: List[Int] = List()
for (ele <- list1) {
list2 = list2 :+ ele * 2
}
println(list2)
//使用map操作
//实现原理跟传统方法一样,都是从集合中取出元素分别乘以2,返回新的集合
//list1.map(_ * 2)中的"_"代表集合中的元素
val list3: List[Int] = list1.map(_ * 2)
println(list3)
}
}
控制台输出结果:

在此案例中,使用map方法操作明显比使用传统方法简洁了很多,代码量少了很多。
filter:过滤
案例代码:
package com.qingtai.scala
object Test {
def main(args: Array[String]): Unit = {
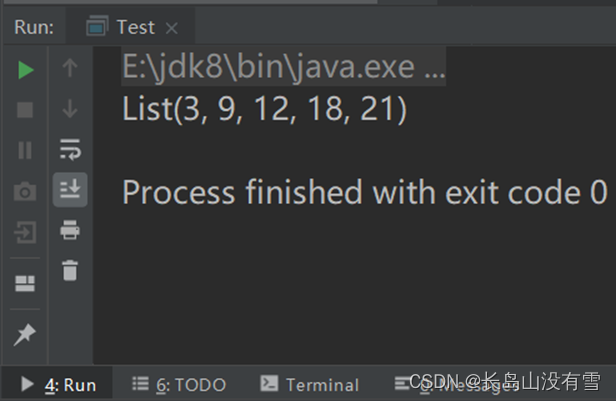
//取出list中所有3的倍数
val list1: List[Int] = List(1,3,5,9,12,16,18,21,22)
val list2: List[Int] = list1.filter(_%3==0)
println(list2)
}
}
控制台输出结果:
reduceLeft与reduceRight
package com.qingtai.scala
object Test {
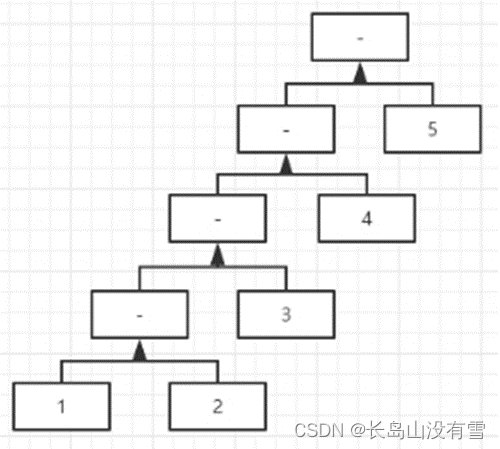
def main(args: Array[String]): Unit = {
val list1: List[Int] = List(1,3,5,9,12)
//求list中所有元素和
//相当于((((1 + 3) + 5) + 9) + 12) = 15
val sum: Int = list1.reduceLeft(_+_)
println(sum)
//求list中所有元素乘积
//相当于((((1 * 3) * 5) * 9) * 12) = 1620
val product: Int = list1.reduceLeft(_*_)
println(product)
}
}
控制台输出结果如下:

原理图如下:
reduceRight(_ + _),reduceRight(_ * _)与之同理,从右向左,同学们可自行测试。
foldLeft与foldRight
原理与reduceLeft与reduceRight相同,只不过可以赋初值。
案例代码如下:
package com.qingtai.scala
object Test {
def main(args: Array[String]): Unit = {
// 折叠
val list = List(1, 2, 3, 4)
def minus(num1: Int, num2: Int): Int = {
num1 - num2
}
//执行原理(((1+2)+3)+4)=10
println(list.reduceLeft(_ + _))
//foldLeft后第一个括号内为初值
//执行原理(((2+1)+2)+3)+4=12
println(list.foldLeft(2)(_ + _))
//执行原理(((5-1)-2)-3)-4=-5
println(list.foldLeft(5)(minus))
//执行原理(1-(2-(3-(4-5))))=3
println(list.foldRight(5)(minus))
}
}
控制台输出结果如下:

flatten和flatMap
现有如下需求:双层列表List(List(1, 2), List(3, 4), List(5, 6, 7))里面的每一个整数乘以2返回一个单层列表List(2, 4, 6, 8, 10, 12, 14)。
案例代码:
package com.qingtai.scala
object Test {
def main(args: Array[String]): Unit = {
val list1: List[List[Int]] = List(List(1, 2), List(3, 4), List(5, 6, 7))
//List(List(2, 4), List(6, 8), List(10, 12, 14))
val list2: List[List[Int]] = list1.map(_.map(_ * 2))
println(list2)
//flatten() 压平,打扁
//List(1, 2, 3, 4, 5, 6, 7)
val list3: List[Int] = list1.flatten
println(list3)
//List(2, 4, 6, 8, 10, 12, 14)
val list4: List[Int] = list1.flatten.map(_ * 2)
println(list4)
//flatMap() 先执行map再执行flatten
//List(2, 4, 6, 8, 10, 12, 14)
val list5: List[Int] = list1.flatMap(_.map(_ * 2))
println(list5)
}
}
控制台输出结果:

2.10 Scala模式匹配
Scala 提供了强大的模式匹配机制,应用也非常广泛。Scala中的模式匹配类似于Java中的switch语法,但是更加强大。一个模式匹配包含了一系列备选项,每个都开始于关键字 case。每个备选项都包含了一个模式及一到多个表达式。箭头符号 => 隔开了模式和表达式。模式匹配语法中,采用match关键字声明,每个分支采用case关键字进行声明,当需要匹配时,会从第一个case分支开始,如果匹配成功,那么执行对应的逻辑代码,如果匹配不成功,继续执行下一个分支进行判断。如果所有case都不匹配,那么会执行case _ 分支,类似于Java中default语句。
简单案例代码:
package com.qingtai.scala
object Test {
def main(args: Array[String]): Unit = {
judgeGrade('A')
judgeGrade('C')
judgeGrade('E')
judgeGrade('D')
judgeGrade('B')
}
def judgeGrade(grade: Char): Unit = {
grade match {
case 'A' => println("你非常优秀!!!")
case 'B' => println("做的很好,继续加油!")
case 'C' => println("成绩尚且可以,你可以做的更好!")
case 'D' => println("成绩不太理想,别放弃,你可以!")
case _ => println("你是一个好孩子,但学习很重要。。。")
}
}
}
控制台输出结果:

2.10.1 类型匹配
案例代码:
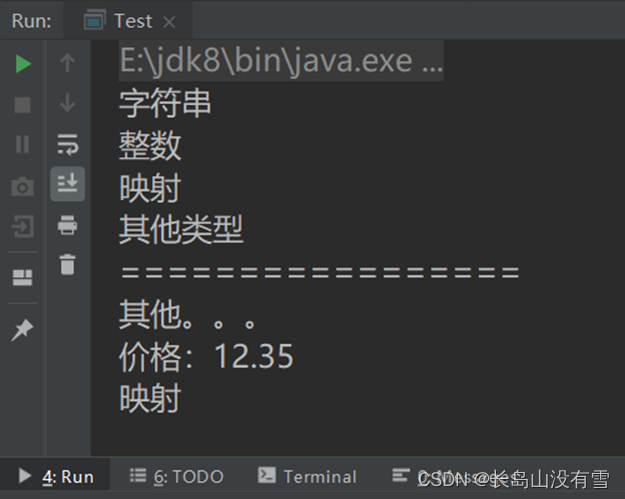
package com.qingtai.scala
object Test {
def main(args: Array[String]): Unit = {
matchType1("Hello Scala!")
matchType1(12)
matchType1(Map("XiaoMing" -> 18))
matchType1('C')
println("=================")
matchType2('A')
matchType2(12.35)
matchType2(Map("XiaoMing" -> 18))
}
def matchType1(any: Any): Unit = {
any match {
case x: Int => println("整数")
case y: String => println("字符串")
case array: Array[_] => println("数组")
case map: Map[_, _] => println("映射")
case _ => println("其他类型")
}
}
def matchType2(any: Any): Unit = {
any match {
case 1 => println("one")
case 12.35 => println("价格:12.35")
case str: String => println("字符串")
case map: Map[_, _] => println("映射")
case _ => println("其他。。。")
}
}
}
控制台输出结果:
2.10.2 样例类匹配
使用了case关键字的类定义就是就是样例类(case classes),样例类是种特殊的类,经过优化以用于模式匹配。使用样例类可以不用使用new关键字创建,直接使用即可。
案例代码:
package com.qingtai.scala
object Test {
def main(args: Array[String]): Unit = {
val alice = new Person("Alice", 25)
val bob = new Person("Bob", 32)
val charlie = new Person("Charlie", 32)
for (person <- List(alice, bob, charlie)) {
person match {
case Person("Alice", 25) => println("Hi Alice!")
case Person("Bob", 32) => println("Hi Bob!")
case Person(name, age) =>
println("Age: " + age + " year, name: " + name + "?")
}
}
}
case class Person(name: String, age: Int)
}
控制台输出结果:

2.11 异常处理
Scala 的异常处理和其它语言比如 Java 类似。Scala 抛出异常的方法和 Java一样,使用 throw 方法,例如,抛出一个新的算术异常:
throw new ArithmeticException
案例代码:
package com.qingtai.scala
object Test {
def main(args: Array[String]): Unit = {
try {
val i = 1 / 0
println(i)
} catch {
case exception: ArithmeticException => {
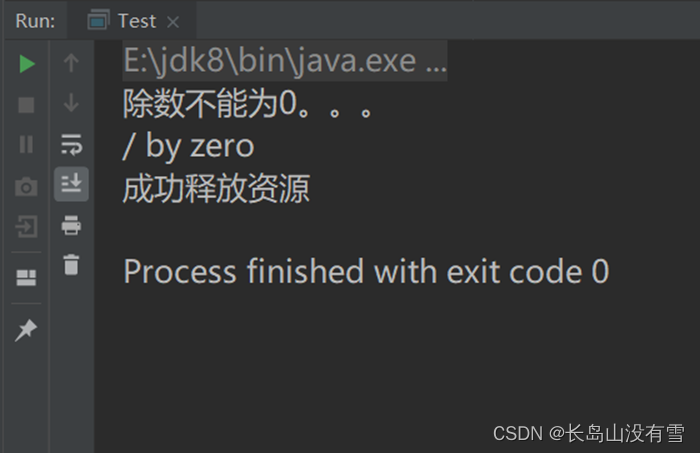
println("除数不能为0。。。")
println(exception.getMessage)
}
} finally {
//最终执行的代码,一般为释放资源
println("成功释放资源")
}
}
}
控制台输出结果:
实验四:Scala进阶
3.1 类和对象
Scala语言是面向对象的。Java是面向对象的编程语言,由于历史原因,Java中还存在着非面向对象的内容:基本类型 ,null,静态方法等。Scala语言来自于Java,所以天生就是面向对象的语言,而且Scala是纯粹的面向对象的语言,即在Scala中,一切皆为对象。类是对象的抽象,而对象是类的具体实例。类是抽象的,不占用内存,而对象是具体的,占用存储空间。类是用于创建对象的蓝图,它是一个定义包括在特定类型的对象中的方法和变量的软件模板。我们可以使用 new 关键字来创建类的对象。scala语法中,类并不声明为public,所有这些类都具有公有可见性(即默认就是public)。
构造器分主构造器和辅助构造器,主构造器的声明直接放置于类名之后,如果主构造器无参数,小括号可省略,构建对象时调用的构造方法的小括号也可以省略。辅助构造器无论是直接或间接,最终都一定要调用主构造器,执行主构造器的逻辑,而且需要放在辅助构造器的第一行。
案例代码:
package com.qingtai.scala
object Test {
def main(args: Array[String]): Unit = {
val p1: Person = new Person()
val p2: Person = new Person("XiaoMing", 16)
println(p1)
p1.work()
println(p2)
p2.work
}
}
class Person() {
//主构造器
//_为占位符
var name: String = _
var age: Int = _
//辅助构造器
def this(pname: String, page: Int) {
this() //务必调用主构造器
this.name = pname
this.age = page
}
def work(): Unit = {
println(name + "正在工作")
}
//重写方法使用override关键字
override def toString(): String = {
s"Person($name, $age)"
}
}
控制台输出结果:

3.2 Scala 继承
Scala继承一个基类跟Java很相似, 但我们需要注意以下几点:
- 重写一个非抽象方法必须使用override修饰符。
- 只有主构造函数才可以往基类的构造函数里写参数。
- 在子类中重写超类的抽象方法时,你不需要使用override关键字。
- Scala 使用 extends 关键字来继承一个类。
案例如下:
package com.qingtai.scala
object Test {
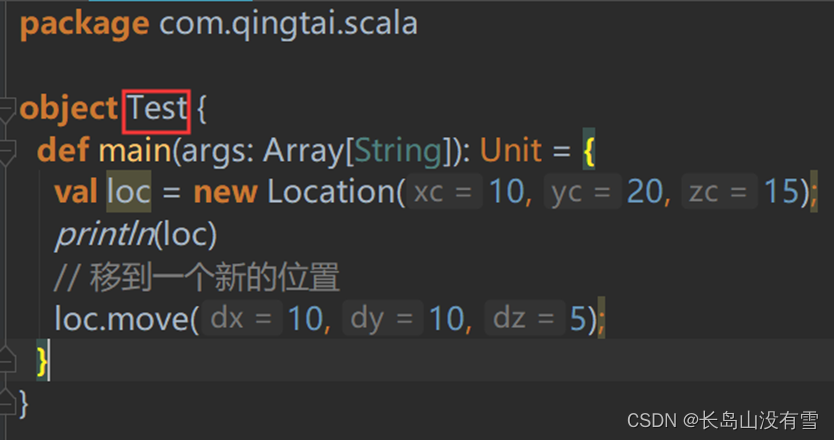
def main(args: Array[String]): Unit = {
val loc = new Location(10, 20, 15);
println(loc)
// 移到一个新的位置
loc.move(10, 10, 5);
}
}
class Point(val xc: Int, val yc: Int) {
var x: Int = xc
var y: Int = yc
def move(dx: Int, dy: Int) {
x = x + dx
y = y + dy
println("x 的坐标点 : " + x);
println("y 的坐标点 : " + y);
}
}
class Location(override val xc: Int, override val yc: Int,
val zc: Int) extends Point(xc, yc) {
var z: Int = zc
def move(dx: Int, dy: Int, dz: Int) {
x = x + dx
y = y + dy
z = z + dz
println("x 的坐标点 : " + x);
println("y 的坐标点 : " + y);
println("z 的坐标点 : " + z);
}
override def toString = s"Location($xc, $yc, $zc)"
}
控制台输出结果:

实例中 Location 类继承了 Point 类。Point 称为父类(基类),Location 称为子类。override val xc 为重写了父类的字段。继承会继承父类的所有属性和方法,Scala 只允许继承一个父类。
3.3 Scala 单例对象
在 Scala 中,是没有 static 这个东西的,但是它也为我们提供了单例模式的实现方法,那就是使用关键字 object。Scala 中使用单例模式时,除了定义的类之外,还要定义一个同名的 object 对象,它和类的区别是,object对象不能带参数。当单例对象与某个类共享同一个名称时,他被称作是这个类的伴生对象:companion object。你必须在同一个源文件里定义类和它的伴生对象。类被称为是这个单例对象的伴生类:companion class。类和它的伴生对象可以互相访问其私有成员。
我们之前一直使用的object Test{}中的Test就是Test类的伴生对象:
Scala中的apply方法:
apply方法通常是在伴生对象中实现的,其目的是,通过伴生类的构造函数功能,来实现伴生对象的构造函数功能;通常我们会在类的伴生对象中定义apply方法,当遇到类名(参数1,…参数n)时apply方法会被调用;在创建伴生对象或伴生类的对象时,通常不会使用new class/class() 的方式,而是直接使用 class(),隐式的调用伴生对象的 apply 方法,这样会让对象创建的更加简洁。
新建Scala Class,在com.qingtai.scala包下右键-》New-》ScalaClass:
输入Name:HelloTest,下方的类型选择“Class”,然后单击“OK”:
案例代码:
package com.qingtai.scala
class HelloTest {
def sayHello(): Unit = {
println("Hello Scala!")
}
}
object HelloTest {
//可以简写为 def apply: HelloTest = new HelloTest()
def apply(): HelloTest = {
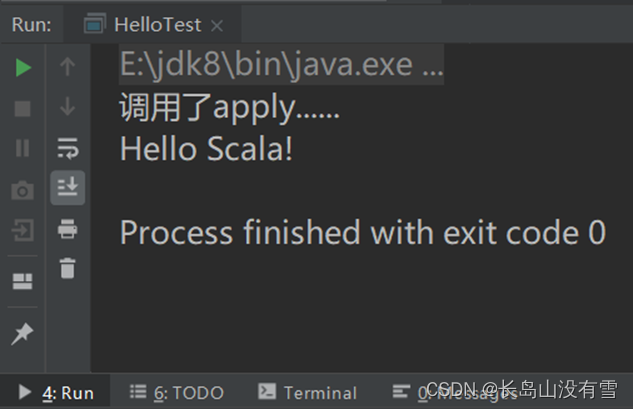
println("调用了apply......")
new HelloTest()
}
def main(args: Array[String]): Unit = {
//自动调用apply方法新建并返回HelloTest对象
val helloTest: HelloTest = HelloTest()
helloTest.sayHello()
}
}
控制台输出结果:
3.4 Scala Trait(特征)
从面向对象来看,接口并不属于面向对象的范畴,Scala是纯面向对象的语言,在Scala中,没有接口。Scala语言中,采用特质trait(特征)来代替接口的概念,也就是说,多个类具有相同的特征(特征)时,就可以将这个特质(特征)独立出来,采用关键字trait声明。一般情况下Scala的类只能够继承单一父类,但是如果是 Trait(特征) 的话就可以继承多个,从结果来看就好像实现了多重继承。
一个类具有某种特质(特征),就意味着这个类满足了这个特质(特征)的所有要素,所以在使用时,也采用了extends关键字,如果有多个特质或存在父类,那么需要采用with关键字连接:

Trait案例:
trait Equal {
def isEqual(x: Any): Boolean
def isNotEqual(x: Any): Boolean = !isEqual(x)
}
以上Trait(特征)由两个方法组成:isEqual 和 isNotEqual。isEqual 方法没有定义方法的实现,isNotEqual定义了方法的实现。子类继承特征可以实现未被实现的方法。
案例如下:
package com.qingtai.scala
object Test {
def main(args: Array[String]): Unit = {
val p1 = new Point(2, 3)
val p2 = new Point(2, 4)
val p3 = new Point(3, 3)
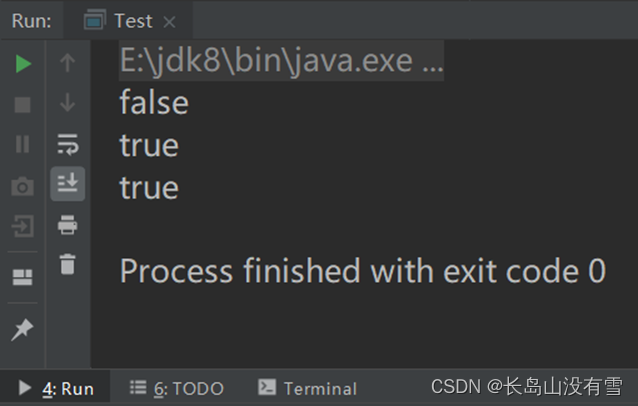
println(p1.isNotEqual(p2))
println(p1.isNotEqual(p3))
println(p1.isNotEqual(2))
}
}
trait Equal {
def isEqual(x: Any): Boolean
def isNotEqual(x: Any): Boolean = !isEqual(x)
}
class Point(xc: Int, yc: Int) extends Equal {
var x: Int = xc
var y: Int = yc
def isEqual(obj: Any) =
obj.isInstanceOf[Point] &&
obj.asInstanceOf[Point].x == x
}
控制台输出结果:
3.5 隐式转换
隐式转换函数是以implicit关键字声明的带有单个参数的函数。这种函数将会自动应用。可以将值从一种类型转换为另一种类型。另外,我们需要某个类中的一个方法,但是这个类没有提供这样的一个方法,所以我们需要隐式转换,转换成提供了这个方法的类,然后再调用这个方法。
案例如下:
package com.qingtai.scala
object Test {
def main(args: Array[String]): Unit = {
val xiaoMing: Man = new Man("XiaoMing")
xiaoMing.run()
//自动进行隐式转换,xiaoMing可以飞了
xiaoMing.fly()
}
//通过隐式转换,将普通人装换成超人,人就可以飞了
implicit def manToSuperman(man: Man): SuperMan = {
new SuperMan(man.name)
}
}
//普通人可以跑,不能飞
class Man(val name: String) {
def run(): Unit = {
println(name + "可以跑")
}
}
//超人可以飞
class SuperMan(val name: String) {
def fly(): Unit = {
println(name + "可以飞")
}
}
控制台输出结果:

3.6 Scala正则表达式
Scala需要使用import scala.util.matching.Regex代码导入Regex类来支持正则表达式。
案例如下:
package com.qingtai.scala
import scala.util.matching.Regex
object Test {
def main(args: Array[String]): Unit = {
//匹配"Scala"
//使用 String 类的 r() 方法构造了一个Regex对象
val r: Regex = "Scala".r
val str: String = "Hello Scala ! Hello Spark ! "
//使用 findFirstIn 方法找到首个匹配项
println(r.findFirstIn(str))
//匹配"Hello"或"hello"
//使用管道(|)来设置不同的模式
val r1: Regex = "(H|h)ello".r
val str1: String = "Hello World ! hello scala"
//使用 findAllIn 方法查看所有的匹配项
//使用 mkString( ) 方法来连接
println(r1.findAllIn(str1).mkString(","))
//替换关键词"nema"替换为"name"
val r2: Regex = "nema".r
val str2: String = "My nema is XiaoMing"
//使用 replaceFirstIn( ) 方法替换第一个匹配项
println(r2.replaceFirstIn(str2, "name"))
}
}
控制台输出结果:

3.7 Scala I/O
可以使用 Scala 的 Source 类及伴生对象来读取文件。Scala 进行文件写操作用的是 java中的I/O类java.io.File。
案例代码:
package com.qingtai.scala
import java.io.{File, PrintWriter}
import scala.io.{BufferedSource, Source}
object Test {
def main(args: Array[String]): Unit = {
//读数据文件
//文件在课程数据文件中,也可以读自己电脑上的文件,注意修改路径
val file: BufferedSource = Source.fromFile("H:\\Scala文件.txt")
file.getLines().foreach(println(_))
file.close()
//写数据文件
val writer: PrintWriter = new PrintWriter(new File("H:\\write.txt"))
writer.write("abcdefg")
writer.close()
}
}
控制台输出结果:

智能推荐
win10安装Ubuntu报错Error code: Wsl/Service/0x8007273d-程序员宅基地
文章浏览阅读4.9k次,点赞6次,收藏7次。下载完成后,启动安装报错,错误代码为0x8007273d。_error code: wsl/service/0x8007273d
Springboot/java/node/python/php基于Springboot的营养配餐评价系统【2024年毕设】-程序员宅基地
文章浏览阅读828次,点赞23次,收藏16次。springboot基于springboot考研资料分享系统。springboot基于springboot的仓储管理系统。开发软件:eclipse/myeclipse/idea。springboot中小型企业物流管理系统的设计与实现。springboot基于云计算的城乡医疗卫生服务系统。springboot消防志愿者服务系统的设计与实现。springboot健身房管理系统的设计与实现。springboot听见你的声音心理咨询网站。springboot数学建模论文阅卷系统。
MinGW-w64安装教程——著名C/C++编译器GCC的Windows版本-程序员宅基地
文章浏览阅读354次。MinGW-w64安装教程——著名C/C++编译器GCC的Windows版本https://www.cnblogs.com/ggg-327931457/p/9694516.html这篇文章解决了我的用“pip install mingw”或者“conda install mingw”无法安装mingw的问题,非常有帮助
[附源码]Python计算机毕业设计高校考研信息共享平台设计与开发_考研择校平台技术上是如何实现的-程序员宅基地
文章浏览阅读276次。项目运行环境配置:Pychram社区版+ python3.7.7 + Mysql5.7 + HBuilderX+list pip+Navicat11+Django+nodejs。项目技术:django + python+ Vue 等等组成,B/S模式 +pychram管理等等。环境需要1.运行环境:最好是python3.7.7,我们在这个版本上开发的。其他版本理论上也可以。2.pycharm环境:pycharm都可以。推荐pycharm社区版;_考研择校平台技术上是如何实现的
chatgpt赋能python:Python敲爱心代码的详细方法和注意事项_python爱心代码需要安装什么库-程序员宅基地
文章浏览阅读239次。您可能已经熟悉了Python中的绘图功能。它可以绘制简单的图形和图表,例如线图,柱状图和散点图。但是,您是否知道还可以在Python中绘制爱心?这是一种非常流行的图形,可以在情人节等浪漫场合使用。本文由chatgpt生成,文章没有在chatgpt生成的基础上进行任何的修改。以上只是chatgpt能力的冰山一角。作为通用的Aigc大模型,只是展现它原本的实力。对于颠覆工作方式的ChatGPT,应该选择拥抱而不是抗拒,未来属于“会用”AI的人。AI职场汇报智能办公文案写作效率提升教程 专注于。_python爱心代码需要安装什么库
chatglm2-6b-int4大语言模型家用电脑部署-程序员宅基地
文章浏览阅读1k次。ChatGLM-6B 是一个开源的、支持中英双语问答的对话语言模型,基于架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。ChatGLM-6B 使用了和ChatGLM相同的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答。_chatglm2-6b-int4
随便推点
sql中的模糊匹配与正则表达式_sql 模糊匹配-程序员宅基地
文章浏览阅读2.4k次。sql中的模糊匹配与正则表达式_sql 模糊匹配
Shp格式详解与在线打开、查看-程序员宅基地
文章浏览阅读7.6k次,点赞33次,收藏36次。使用3D模型在线转换网站进行shp格式在线打开、查看和转换,NSDT 3dconvert支持将shp格式在线转换为glb、gltf、obj、stl、dae、ply、off等格式。_shp
Unity2017 Timeline实例解析:游戏场景中的动画_timeline自定义轨道 2017-程序员宅基地
文章浏览阅读4.2k次。转载注明出处:点击打开链接Unity 2017.1 推出的Timeline功能,不仅可以高效的帮助大家实现游戏场景中的物体动画,还可以制作出更为复杂的过场动画及电影内容。今天这篇文章将由Unity大中华区技术经理成亮,通过实例分析让大家了解Timeline的多轨道,把各类场景中的元素整合实现更为复杂的动画。Timeline简介Timeline 是一套基于时间轴的多轨道动画系统,_timeline自定义轨道 2017
【经典算法题】零钱兑换_java 兑换零钱算法-程序员宅基地
文章浏览阅读2.4k次。【经典算法题】零钱兑换Leetcode 0322 零钱兑换题目描述:Leetcode 0322 零钱兑换分析本题的考点:背包问题。完全背包问题,amout为容量;物品体积为coins[i],价值为1。本题和Leetcode 0279 完全平方数十分类似,可以参考LC279的分析。注意本题和Leetcode 0518 零钱兑换 II的区别,LC518让求得是体积恰好是m的方案数,本题求的是体积恰好是m需要用的最少硬币数。代码C++class Solut_java 兑换零钱算法
精心整理史上最全的数据结构flash演示动画,共5个版本,祝大家考研成功!_数据结构 flash-程序员宅基地
文章浏览阅读1.8k次,点赞2次,收藏4次。精心整理史上最全的数据结构flash演示动画,共5个版本,祝大家考研成功!\数据结构flash演示\版本1\数据结构flash演示\版本2\数据结构flash演示\版本3\数据结构flash演示\版本4\数据结构flash演示\版本5\数据结构flash演示\版本1\1-4 算法和算法分析 冒泡排序.swf\数据结构flash演示\版本1\10-1-1插入排序.swf\数据结构fl..._数据结构 flash
C语言经典算法题_c 语言算法题-程序员宅基地
文章浏览阅读3.5k次,点赞4次,收藏48次。1. 有1、2、3、4个数字,能组成多少个互不相同且无重复的三位数?分别是多少?#include <stdio.h>void main(){ int i,j,k; printf("\n"); for(i=1;i<5;i++){ for(j=1;j<5;j++){ for(k=1;k<5;k++){ if(i!=j&&j!=k&&i!=k){ printf("%d,%d,%d",i,j,k); p_c 语言算法题