Java集合体系-程序员宅基地
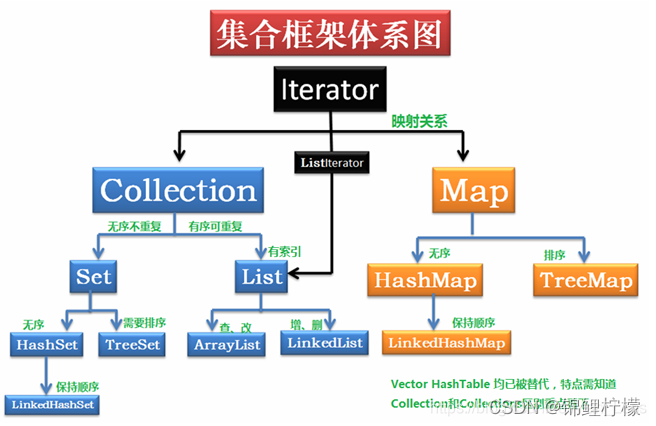
Java集合体系框架


集合与数组的区别
(1)长度区别:集合长度可变,数组长度不可变
(2)内容区别:集合可存储不同类型元素,数组存储只可单一类型元素
(3)元素区别:集合只能存储引用类型元素,数组可存储引用类型,也可存储基本类型
Java 集合类可以用于存储数量不等的多个对象,还可用于保存具有映射关系的关联数组。
在这里主要讲一些我们平常很常用的一些接口和一些实现类。
Java 集合可分为Collection和 Map 两种体系:
Collection接口:单列数据,定义了存取一组对象的方法的集合
- List:元素有序、可重复的集合(动态数组)
- Set:元素无序、不可重复的集合(类似于高中所讲的集合)
Map接口:双列数据,保存具有映射关系“key-value对”的集合(高中时所讲的函数)
Collection接口的使用方法
Collection 接口是 List、Set 和 Queue 接口的父接口,该接口里定义的方法既可用于操作 Set 集合,也可用于操作 List 和 Queue 集合。
JDK不提供此接口的任何直接实现,而是提供更具体的子接口(如:Se和List)实现。
Collection 接口方法:
1、添加
add(Object obj)
addAll(Collection coll) (把另一个集合的所有元素都加到当前集合中)
2、获取有效元素的个数
int size()
3、清空集合
void clear()
4、是否是空集合
boolean isEmpty()
5、是否包含某个元素
boolean contains(Object obj):是通过元素的equals方法来判断是否是同一个对象。
boolean containsAll(Collection c):判断这个集合中的所有元素是否都在我原来的集合中。也是调用元素的equals方法来比较的。拿两个集合的元素挨个比较。
6、删除
boolean remove(Object obj) :通过元素的equals方法判断是否是要删除的那个元素。只会删除找到的第一个元素
boolean removeAll(Collection coll):移除这个集合中与当前集合中共有的元素。
7、取两个集合的交集
boolean retainAll(Collection c):把交集的结果存在当前集合中,不影响 c
8、集合是否相等 (注意当前集合到底是有序的还是无序的,在于你使用的具体是Collection的哪个接口)
boolean equals(Object obj)
9、转成对象数组
Collection coll =new ArrayList();
Object[] array = coll.toArray();
10、遍历
iterator():返回迭代器对象,用于集合遍历
Collection 接口的接口 对象的集合(单列集合)
├——-List 接口:元素按进入先后有序保存,可重复
│—————-├ LinkedList 接口实现类, 链表, 插入删除, 没有同步, 线程不安全
│—————-├ ArrayList 接口实现类, 数组, 随机访问, 没有同步, 线程不安全
│—————-└ Vector 接口实现类 数组, 同步, 线程安全
│ ———————-└ Stack 是Vector类的实现类
└——-Set 接口: 仅接收一次,不可重复,并做内部排序
├—————-└HashSet 使用hash表(数组)存储元素
│————————└ LinkedHashSet 链表维护元素的插入次序
└ —————-TreeSet 底层实现为二叉树,元素排好序
Map 接口 键值对的集合 (双列集合)
├———Hashtable 接口实现类, 同步, 线程安全
├———HashMap 接口实现类 ,没有同步, 线程不安全-
│—————–├ LinkedHashMap 双向链表和哈希表实现
│—————–└ WeakHashMap
├ ——–TreeMap 红黑树对所有的key进行排序
└———IdentifyHashMap
一、Set
Set继承于Collection接口,是一个不允许出现重复元素,并且无序的集合,主要有HashSet和TreeSet两大实现类。在判断重复元素的时候,Set集合会调用hashCode()和equal()方法来实现。
set集合框架结构

与List接口一样,Set接口也提供了集合操作的基本方法。
但与List不同的是,Set还提供了equals(Object o)和hashCode(),供其子类重写,以实现对集合中插入重复元素的处理
HashSet(存储结构:哈希表(数组+链表+红黑树))
HashSet实现Set接口,HashSet底层由HashMap实现,为哈希表结构,插入的元素被当做是HashMap的key,根据hashCode值来确定集合中的位置,由于Set集合中并没有角标的概念,所以并没有像List一样提供get()方法,HashSet相当于一个阉割版的HashMap。当获取HashSet中某个元素时,只能通过遍历集合的方式进行equals()比较来实现。添加元素时,底层HashSet调用了HashMap的put(K key, V value)方法,当有元素插入的时候在向HashMap中添加元素时,先判断key的hashCode值是否相同,如果相同,则调用equals()、==进行判断,若相同则覆盖原有元素;如果不同,则直接向Map中添加元素;
它继承于AbstractSet,实现了Set, Cloneable, Serializable接口。
(1)HashSet继承AbstractSet类,获得了Set接口大部分的实现,减少了实现此接口所需的工作,实际上是又继承了AbstractCollection类;
(2)HashSet实现了Set接口,获取Set接口的方法,可以自定义具体实现,也可以继承AbstractSet类中的实现;
(3)HashSet实现Cloneable,得到了clone()方法,可以实现克隆功能;
(4)HashSet实现Serializable,表示可以被序列化,通过序列化去传输,典型的应用就是hessian协议。
存储过程(重复依据)
- 根据hashCode计算保存的位置,如果位置为空,直接保存,若不为空,进行第二步
- 再执行equals方法,如果equals为true,则认为是重复,否则形成链表
存储过程:
- 基于HashCode计算元素存放位置
- 利用31这个质数,减少散列冲突
- 31提高执行效率
31 * i = (i << 5) - i转为移位操作
- 31提高执行效率
- 当存入元素的哈希码相同时,会调用equals进行确认,如果结果为true,则拒绝后者存入
- 利用31这个质数,减少散列冲突
新建集合 HashSet<String> hashSet = new HashSet<String>();
添加元素 hashSet.add( );
删除元素 hashSet.remove( );
遍历操作
1. 增强for for( type type : hashSet)
2. 迭代器 Iterator<String> it = hashSet.iterator( );
判断 hashSet.contains( ); hashSet.isEmpty();
特点:
-
不允许出现重复因素;
-
允许插入Null值;
-
元素无序(添加顺序和遍历顺序不一致);
-
线程不安全,若2个线程同时操作HashSet,必须通过代码实现同步;
TreeSet(存储结构:红黑树)
此集合的实现和树结构有关。与HashSet集合类似,TreeSet也是基于Map来实现,具体实现TreeMap,其底层结构为红黑树(特殊的二叉查找树);
与HashSet不同的是,TreeSet具有排序功能,分为自然排序(123456)和自定义排序两类,默认是自然排序;在程序中,我们可以按照任意顺序将元素插入到集合中,等到遍历时TreeSet会按照一定顺序输出--倒序或者升序;
它继承AbstractSet,实现NavigableSet, Cloneable, Serializable接口。
(1)与HashSet同理,TreeSet继承AbstractSet类,获得了Set集合基础实现操作;
(2)TreeSet实现NavigableSet接口,而NavigableSet又扩展了SortedSet接口。这两个接口主要定义了搜索元素的能力,例如给定某个元素,查找该集合中比给定元素大于、小于、等于的元素集合,或者比给定元素大于、小于、等于的元素个数;简单地说,实现NavigableSet接口使得TreeSet具备了元素搜索功能;
(3)TreeSet实现Cloneable接口,意味着它也可以被克隆;
(4)TreeSet实现了Serializable接口,可以被序列化,可以使用hessian协议来传输;
创建集合 TreeSet<String> treeSet = new TreeSet<>()
添加元素 treeSet.add();
删除元素 treeSet.remove();
遍历 1. 增强for 2. 迭代器
判断 treeSet.contains();
补充:TreeSet集合的使用
Comparator 实现定制比较(比较器)
Comparable 可比较的
特点
- 基于排列顺序实现元素不重复
- 实现SortedSet接口,对集合元素自动排序,是一个有序的集合
- 元素对象的类型必须实现Comparable接口,指定排序规则
- 通过CompareTo方法确定是否为重复元素
- 允许插入Null值
- 线程不安全
在TreeSet调用add方法时,会调用到底层TreeMap的put方法,在put方法中会调用到compare(key, key)方法,进行key大小的比较;
在比较的时候,会将传入的key进行类型强转,所以当我们自定义的类进行比较的时候,自然就会抛出异常,因为该类并没有实现Comparable接口;因此需要将自定义类实现Comparable接口,再做比较
二、Map

Map集合的特点:
(1)Map集合是一个双列集合,一个元素包含两个值,一个key,一个value。
(2)Map集合中的元素,key和value的数据类型可以相同,也可以不同。
(3)Map集合中的元素,key是不允许重复的,value是可以重复的。
(4)Map集合中的元素,key和value是一一对应的。
Map集合中的方法:
1.public V put (K key,V value) 把指定的键和值添加到Map集合中,返回值是V
如果要存储的键值对,key不重复返回值V是null
如果要存储的键值对,key重复返回值V是被替换的value值
2. public V remove(Object key)把指定键所对应的键值对元素,在Map集合中删除,返回被删除的元素的值。 返回值:V 。如果key存在,返回被删除的值,如果key不存在,返回null
3.public V get(Object key):根据指定的键,在Map集合中获取对应的值
如果key存在,返回对应的value值,如果key不存在,返回null
4.boolean containsKey( Object key)判判断集合中是否包含指定的键
遍历Map集合方式:
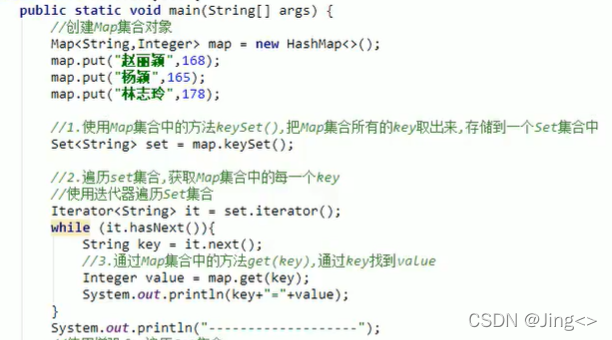
1.通过键找值的方法(keySet)
使用了keySet方法,将Map集合中的key值,存储到Set集合,用迭代器或foreach循环遍历Set集合来获取Map集合的每一个key,并使用get(key)方法来获取value值


2.使用Entry对象遍历
Map.Entry<K,V>,在Map接口中有一个内部接口Entry(内部类)
作用:当集合一创建,就会在Map集合中创建一个Entry对象,用来记录键与值(键值对对象,键值的映射关系)
有了Entry对象就可以使用Map中的entrySet方法,把Map集合中的多个Entry对象存入一个Set集合来遍历Set集合,获取Set集合中每一个Entry对象,然后可以使用Entry中的两个方法getKey和getValue来分别获取键和值。



3.entrySet
entrySet是 java中 键-值 对的集合,Set里面的类型是Map.Entry,一般可以通过map.entrySet()得到。
- entrySet实现了Set接口,里面存放的是键值对。一个K对应一个V。

四种遍历map方式
public static void main(String[] args) {
Map<String, String> map = new HashMap<String, String>();
map.put("1", "value1");
map.put("2", "value2");
map.put("3", "value3");
//第一种:普遍使用,二次取值
System.out.println("通过Map.keySet遍历key和value:");
for (String key : map.keySet()) {
System.out.println("key= "+ key + " and value= " + map.get(key));
}
//第二种
System.out.println("通过Map.entrySet使用iterator遍历key和value:");
Iterator<Map.Entry<String, String>> it = map.entrySet().iterator();
while (it.hasNext()) {
Map.Entry<String, String> entry = it.next();
System.out.println("key= " + entry.getKey() + " and value= " + entry.getValue());
}
//第三种:推荐,尤其是容量大时
System.out.println("通过Map.entrySet遍历key和value");
for (Map.Entry<String, String> entry : map.entrySet()) {
System.out.println("key= " + entry.getKey() + " and value= " + entry.getValue());
}
//第四种
System.out.println("通过Map.values()遍历所有的value,但不能遍历key");
for (String v : map.values()) {
System.out.println("value= " + v);
}
HashMap(存储结构:哈希表(数组+单向链表/红黑树))
特点:
1.HashMap底是哈希表,查询速度非常快(jdk1.8之前是数组+单向链表,1.8之后是数组+单向链表/红黑树 ,链表长度超过8时,换成红黑树)
2. HashMap是无序的集合,存储元素和取出元素的顺序有可能不一致
3.集合是不同步的,也就是说是多线程的,速度快
HashMap存储自定义类型键值,Map集合保证key是唯一的:作为key的元素,必须重写hashCode方法和equals方法,以保证key唯一
LinkedHashMap
HashMap有子类LinkedHashMap:LinkedHashMap <K,V> extends HashMap <K,V>
是Map接口的哈希表和链表的实现,具有可预知的迭代顺序(有序)
底层原理:哈希表+链表(记录元素顺序)
特点:1.LinkedHashMap底层是哈希表+链表(保证迭代的顺序)
2.LinkedHashMap是一个有序的集合,存储元素和取出元素的顺序一致
改进之处就是:元素存储有序了
HashTable
Hashtable<K,V> implements Map<K,V>
Hashtable:底层也是哈希表,是同步的,是一个单线程结合,是线程安全的集合,速度慢
HashMap:底层也是哈希表,但是线程不安全的集合,是多线程集合,速度快
HashMap(还有之前学的所有集合):都可以存储null键,null值
Hashtable:不能存储null键,null值
TreeMap(存储结构:红黑树)
- TreeMap存储K-V键值对,通过红黑树(R-B tree)实现;
- TreeMap继承了NavigableMap接口,NavigableMap接口继承了SortedMap接口,可支持一系列的导航定位以及导航操作的方法,当然只是提供了接口,需要TreeMap自己去实现;
- TreeMap实现了Cloneable接口,可被克隆,实现了Serializable接口,可序列化;
- TreeMap因为是通过红黑树实现,红黑树结构天然支持排序,默认情况下通过Key值的自然顺序进行排序;
- TreeMap的基本操作 containsKey、get、put 和 remove 的时间复杂度是 log(n) 。
另外,TreeMap是非同步的。 它的iterator 方法返回的迭代器是fail-fastl的。
三、List

在Collection中,List集合是有序的,Developer可对其中每个元素的插入位置进行精确地控制,可以通过索引来访问元素,遍历元素。
在List集合中,我们常用到ArrayList和LinkedList这两个类。
其中,ArrayList底层通过数组实现,随着元素的增加而动态扩容。而LinkedList底层通过链表来实现,随着元素的增加不断向链表的后端增加节点。
List包括List接口以及List接口的所有实现类。因为List接口实现了Collection接口,所以List接口拥有Collection接口提供的所有常用方法,又因为List是列表类型,所以List接口还提供了一些适合于自身的常用方法,如图所示

ArrayList (底层:数组)
ArrayList是Java集合框架中使用最多的一个类,是一个数组队列,线程不安全集合。
它继承于AbstractList,实现了List, RandomAccess, Cloneable, Serializable接口。
(1)ArrayList实现List,得到了List集合框架基础功能;
(2)ArrayList实现RandomAccess,获得了快速随机访问存储元素的功能,RandomAccess是一个标记接口,没有任何方法;
(3)ArrayList实现Cloneable,得到了clone()方法,可以实现克隆功能;
(4)ArrayList实现Serializable,表示可以被序列化,通过序列化去传输,典型的应用就是hessian协议。
它具有如下特点:
- 容量不固定,随着容量的增加而动态扩容(阈值基本不会达到)
- 有序集合(插入的顺序==输出的顺序)
- 插入的元素可以为null
- 增删改查效率更高(相对于LinkedList来说)
- 线程不安全
LinkedList(底层:链表)
LinkedList是一个双向链表,每一个节点都拥有指向前后节点的引用。相比于ArrayList来说,LinkedList的随机访问效率更低。
它继承AbstractSequentialList,实现了List, Deque, Cloneable, Serializable接口。
(1)LinkedList实现List,得到了List集合框架基础功能;
(2)LinkedList实现Deque,Deque 是一个双向队列,也就是既可以先入先出,又可以先入后出,说简单些就是既可以在头部添加元素,也可以在尾部添加元素;
(3)LinkedList实现Cloneable,得到了clone()方法,可以实现克隆功能;
(4)LinkedList实现Serializable,表示可以被序列化,通过序列化去传输,典型的应用就是hessian协议。
ArrayList与LinkedList比较
ArrayList底层是数组实现,能够动态扩容
由于LinkedList是链表结构,没有角标的概念,没有实现RandomAccess接口,不具备随机元素访问功能,所以在get方面表现的差强人意,ArrayList再一次完胜。
ArrayList在随机访问方面表现的十分优秀,比LinkedList强了很多。
LinkedList为什么这么慢呢?这主要是LinkedList的代码实现所致,每一次获取都是从头开始遍历,一个个节点去查找,每查找一次就遍历一次,所以性能自然得不到提升。
由于ArrayList实现了RandomAccess,所以具备了随机访问特性,调用elementData()可以获取到对应元素的值
四、List,Set,Map理解与区别
1.List和Set是存储单列数据的集合,Map是存储键值对这样的双列数据的集合。
2.List,Set和Map的区别:
List:中存储的数据是有顺序的,并且值是允许重复的。
Set:中存储的数据是无序的,并且值是不允许重复的,但是元素在集合中的位置是由hashcode 决定的,即存进去的位置是固定的。
Map:中存储的数据是无序的,它的键是不允许 重复的,它的值允许重复。
3.List的接口有三个实现类:
(1).LinkedList:基于链表实现的,链表内存是散列的,增删快,查询慢。
(2).ArrayList:基于数组实现的,非线程安全的,效率高,增删慢,查询快。
(3).Vector:基于数组实现 的,线程安全的,效率低,增删慢,查找快。
4.Set接口有两个实现类:
(1).hashSet:底层是由HashMap实现的,不允许集合中有重复的值,使用该集合时需要重
写equals()和hashcode()方法。
(2).LinkedHashSet:继承与HashSet,同时又基于LinkedHashMap来进行实现,底层使用的
是LinkedHashMap。
5.Map接口有四个实现类:
(1).HashMap:基于hash表的Map接口实现,非线程安全,高效,支持null值和null键。
(2).HashTable:线程安全,低效,不支持null值和null键。
(3).LinkedHashMap:是Hash的一个子类,保存了记录的插入顺序。
(4).TreeMap:基于二叉树实现,能够把它保存的记录根据键排序,默认是键值的升序排序。
6.ArrayList和LinkedList的区别:
ArrayList:
(1).底层是由数组实现的,非线程安全的,建议单线程时使用,多线程中可以选择Vector。
(2).对于随机访问get和set,ArrayList通过数组下标快速查找,效率高。
(3). 对于增加和删除时,因为是数组的数据结构,要移动数组里的元素,效率低;查询修改效率高。
LinkedList:
(1).底层是由双向链表实现的,线程安全的。
(2).对于随机访问get和set,LinkedList要移动指针,从前往后找,效率低。
(3).对于增加和删除时,效率高,查询修改效率低。
7.hashMap的底层理解:
(1). 存储结构为:数组+链表+红黑树(jdk1.8以后有的),添加红黑树的目的是提高效率。
(2).hashMap是非线程安全的,只是用于单线程环境下,多线程环境下可以采用concurrent并发包下的concurrentHashMap。
(3).HashMap的特性: 存储方式是键值对,实现快速存取数据;允许null键/值;非同步;不保证有序(比如插入的顺序)。实现map接口
智能推荐
centos/ubuntu—yum/apt-get软件安装_yum安装apt-get-程序员宅基地
文章浏览阅读6.7k次。这里注意,info后面必须是软件完整名称,例如查询mysql-connector-java.noarch,名称应该是mysql-connector-java,写mysql会报错。或者写作mysql*,查询所有含有mysql名称的软件包参考centos-vault | 镜像站使用帮助 | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror鸟哥私房菜 - 第二十二章、软件安装 RPM, SRPM 与 YUM (vbird.org)/var/l_yum安装apt-get
BatteryProperty上报流程_power_supply_changed-程序员宅基地
文章浏览阅读2.1k次,点赞2次,收藏19次。本流程主要涉及文件: kernel层:qpnp-smbcharger.c qpnp-fg.c dwc3-msm.c power_supply_core.c power_supply_sysfs.c文件路径:kernel\drivers\power\ system/core/healthd层:healthd.cpp BatteryMonitor.cpp、Batt..._power_supply_changed
C语言程序设计 最简单的C程序设计——顺序程序设计_c语言实验报告顺序结构程序设计-程序员宅基地
文章浏览阅读2.7k次。1 算法是程序的灵魂1.1 什么是算法程序包括两个方面的内容:(1)对数据的描述。在程序中要指定数据的类型和数据的组织形式,即数据结构。(2)对操作的描述。即操作步骤,也就是算法。数据结构+算法=程序设计一个程序需要运用算法、数据结构、程序设计方法和语言。算法是灵魂,数据结构是加工对象,语言是工具,编程需要采用适合的方法。计算机算法分两大类:数值运算算法和非数值运算算法。算法是解决“做什么”和”怎么做“的问题。”做什么“就是目的,效果。”怎么做“就是做哪些事情才能达到解决问题的目的;二_c语言实验报告顺序结构程序设计
Mybatis实现分页查询之PageHelper的使用及参数说明_分页查询page参数介绍-程序员宅基地
文章浏览阅读2.1k次。pom.xml配置<!-- pagehelper --><!-- 版本使用参考MVNrepository --><dependency> <groupId>com.github.pagehelper</groupId> <artifactId>pagehelper</artifactId> <version>最新版本</version></dependency&g_分页查询page参数介绍
python环境搭建-程序员宅基地
文章浏览阅读1.2w次,点赞40次,收藏77次。python安装步骤详细教程,看完不会来砍我,谢谢支持_python环境搭建
使用grep搜索多个文件夹下文件内容的脚本_grep几个文件夹下的所有文件-程序员宅基地
文章浏览阅读9.3k次。#!/bin/bashfor i in 01 02 03 04dogrep -r KEYWORD /home/201807$i/FILENAME > 201807$i.txtdone _grep几个文件夹下的所有文件
随便推点
pandas 筛选出某列的元素是否在一个集合中 然后保存到一个新的Excel表中_pandas 是否在某个组合-程序员宅基地
文章浏览阅读2.3k次。// An highlighted blockdata_only_flu_people = pd.read_excel('./Data/newData/1.xlsx')# print (data_only_flu_people.head())set_544 = set(data_only_flu_people['zjhm'])#集合的大小#print (len(set_544))da..._pandas 是否在某个组合
[Orangepi 3 LTS]学习记录(二)_nmcli 扫描wifi-程序员宅基地
文章浏览阅读1k次。接[Orangepi 3 LTS]学习记录(一) 一、设置Linux系统终端自动登录 二、网络连接 三、SSH远程登陆开发板_nmcli 扫描wifi
node中后台安全的防护-程序员宅基地
文章浏览阅读510次,点赞22次,收藏8次。本人分享一下这次字节跳动、美团、头条等大厂的面试真题涉及到的知识点,以及我个人的学习方法、学习路线等,当然也整理了一些学习文档资料出来是附赠给大家的。知识点涉及比较全面,包括但不限于前端基础,HTML,CSS,JavaScript,Vue,ES6,HTTP,浏览器,算法等等详细大厂面试题答案、学习笔记、学习视频等资料领取,点击资料领取直通车免费领取!ttps://bbs.csdn.net/topics/618191877)免费领取!
【php基础】 函数(方法)、日期函数、static关键字-程序员宅基地
文章浏览阅读562次,点赞3次,收藏2次。【代码】php 函数(方法)、日期函数。
[深入研究4G/5G/6G专题-56]: L3信令控制-5-无线承载DRB管理_基站配置drb-程序员宅基地
文章浏览阅读642次。Radio Bearer (RB)是基站为UE分配空口不同层协议实体及配置的总称,包括PDCP协议实体、RLC协议实体、MAC协议实体和PHY分配的一系列资源等。它包含一组Qos和无线资源描述的参数。_基站配置drb
FFMPEG推流到RTMP服务器命令_ffmpeg推流rtmp命令-程序员宅基地
文章浏览阅读3.2k次。7、将当前摄像头以及扬声器通过DSHOW采集,使用H.264/AAC压缩后推送到RTMP服务器。4、将其中一个直播流中的视频改用H.264压缩,音频改用aac压缩,推送到另外一个直播服务器。3、将其中一个直播流中的视频改用H.264压缩,音频不变,推送到另外一个直播服务器。5、将其中一个直播流中的视频不变,音频改用aac压缩,推送到另外一个直播服务器。6、将一个高清流复制为几个不同清晰度的流重新发布,其中音频不变。10、将AAC文件转化为flv文件,编码格式采用AAC。1、将文件当作源推送到。_ffmpeg推流rtmp命令