模拟实现std::string类(包含完整、分文件程序)-程序员宅基地
std库中的string是一个类,对string的模拟实现,既可以复习类的特性,也可以加深对std::string的理解。
一、搭建框架
️1.新命名空间
本质上string是一个储存在库std里面的类,现在需要模拟实现一个string类,为了不和std库冲突,因此将我们自己写的string放进一个新的命名空间中,假设命名空间名为tmp:
namespace tmp {
class string {
public:
...
private:
...
};
}
️2.成员变量的设置
思考,用哪些变量可以完整的描述并找到一个字符串:
①找头:指向该字符串的指针——char* _str
②找尾:知道指针指向的这串字符串的有效长度——size_t _size
③前提是有底层空间:字符串不像内置类型,编译器不会主动分配空间,需要我们自己开辟。底层空间大于等于字符串所占用的空间——size_t _capacity
private:
char* _str;
size_t _size;
size_t _capacity;
️3.缺省静态变量
比如常用的缺省值npos,本质上就是一个静态变量。
npos代表整型的最大值,即unsigned int -1,在很多地方都需要用npos充当默认值,表示有多少就取多少,那么npos是怎么声明默认值的呢?
这归功于编译器的特殊处理。
npos是静态成员变量,属于整个类的所有对象,不独属于某一个单独的对象,因此不会走初始化列表,又因为只有初始化列表处才能赋缺省值,因此按道理不可以给静态变量npos赋予缺省值。但由于有特殊需求,编译器就对此做了特殊处理,在前面加上const后,就可以用给静态变量npos赋缺省值了。
注意:该特殊处理只限于整型。
private:
char* _str;
size_t _size;
size_t _capacity;
const static size_t npos = -1;
};
(static和const的前后顺序无要求)
该特殊设计的其他用处:

直接定义一个静态缺省变量,用该变量定义数组。
二、基础操作函数
️1.迭代器和begin、end
(1)迭代器
迭代器本质上是指针,能指向string的迭代器对应字符指针,分为有无const两种:
①const char*:string::const_iterator
②char*:string::iterator
需要在public部分的最上面进行typedef:
namespace tmp {
class string {
public:
typedef char* iterator;
typedef const char* const_iterator;
...
};
}
(2)首尾迭代器函数 begin、end
begin和end的功能是分别是返回指向字符串开头和结尾的迭代器。每一个函数都对应两个重载,分别对应const类型和非const类型的字符串。
iterator begin() {
return _str;
}
iterator end() {
return _str + _size;
}
const_iterator begin() const{
return _str;
}
const_iterator end() const{
return _str + _size;
}
️2.返回字符串指针 c_str
很简单,直接返回成员变量_str:
//返回字符串指针
const char* c_str() const{
return _str;
}
️3.返回字符串大小 size
//计算大小
size_t size() const{
return _size;
}
️4.交换字符串 swap
交换字符串本质上就是进行字符指针、_size、_capzcity3个变量的交换。因此在我们写的swap(tmp::swap)内部要调用3次std::swap函数实现交换,切忌自己调用自己,会无限递归导致栈溢出。
//交换字符串
void swap(string& s) {
//借助std的swap,以防自己调用自己从而栈溢出
std::swap(_str, s._str);
std::swap(_size, s._size);
std::swap(_capacity, s._capacity);
}
三、预留空间 reserve
reserve就是显式地控制底层空间大小,步骤为:申请新的空间,拷贝旧空间的内容,释放旧空间,指针指向新空间:
void reserve(size_t n) {
if (n > _capacity) {
char* tmp = new char[n + 1];
strcpy(tmp, _str);
delete[] _str;
_str = tmp;
//_size不变,光_capacity变
_capacity = n;
}
}
四、构造、拷贝构造、析构
️1.构造函数 string
主要是两种,构造空字符串和非空的。
注意1:选初始化列表?还是函数体?
如果用初始化列表,则需格外注意成员变量的顺序和初始化的先后顺序匹配,一旦不匹配就会出错。
对于内置类型的成员变量,则只能通过初始化列表初始化,而string的三个成员变量都不是内置类型(char*类、size_t类)。
综上权衡,使用函数体的方式更好。
注意2:合适的初始化顺序可以提高效率
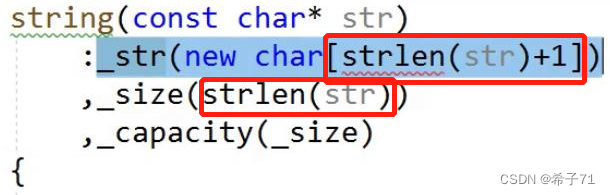
比如上图,调用了两次strlen函数,属于对效率的浪费,如果最先算_size,后面的_capacity和new的空间大小都用_size算出的值,才算最高的效率。
(当然,上图是初始化列表,对初始化顺序严格要求,才有出现了这种低效率现象,也进一步说明了能不用初始化列表就不用)
注意3:不可以用空指针构造空字符串
构造空字符串时,不可以将空字符串的指针看作空指针,因为空指针不可以被解引用,算不出空指针的大小和容量;空字符串可能后序会被插入进字符串,插入肯定要解引用字符串指针,然而访问空指针程序会直接崩溃。比如下面的错误写法:

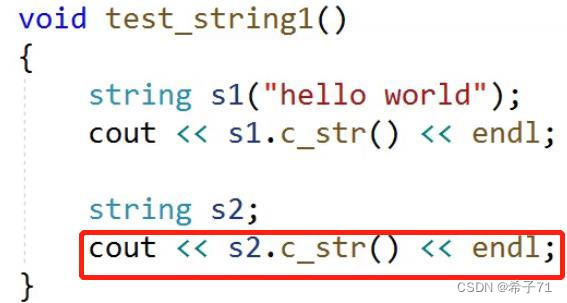
访问了空指针,程序崩溃。
注意4:实际容量要比实际大小至少多1
实际大小即_size是字符串有效长度,然而字符串必须有结尾标志’\0’,这个字符不属于有效字符,但底层空间却一定不可以少了这个字符,这就意味着实际的底层容量还要再增加一个位置存放字符’\0’,即reserve的时候要比实际传来的参数多reserve1个空间,new的时候要比_size多1。
对于空字符串,正确做法是开辟一个大小为1的空间,内部唯一储存的字符是’\0’,这样既不会出现访问空指针的问题,还保证了字符串的有效长度为0。
法1:两个重载,分别针对空字符串和非空
string() {
_size = 0;
_capacity = 0;
_str = new char[1];
_str[0] = '\0';
}
string(char* str) {
_size = strlen(str);
_capacity = _size;
_str = new char[_size + 1];
strcpy(_str, str);
_str[_size] = '\0';
}
法2:利用缺省参数,将两个重载合并成一个函数
string(const char* str = "") {
_size = strlen(str);
_capacity = _size;
_str = new char[_capacity + 1];
strcpy(_str, str);
_str[_size] = '\0';
}
注意是字符串形式的"\0",而不是字符形式的’\0’,因为只有字符串才可以充当指针,从而与参数类型const char*匹配。并且\0可以不写,因为默认常量字符串以\0结尾。
️2.拷贝构造
注意:
- 拷贝构造函数不是必须的,即使不显式写,编译器也会自动生成拷贝构造函数,但这个函数只能浅拷贝(值拷贝)。
- 当成员变量中有指针类型时,必须要显式地写出拷贝构造函数,否则在传值传参或传值返回等需要拷贝构造临时或局部对象时,容易因重复释放同一空间而出现程序崩溃。
- 当成员变量中有自定义类型,且该自定义类型的成员变量中有指针类型时,和2同理,也必须要显式地写出拷贝构造函数。
(1)法1:(传统方法)开新空间释放旧空间
string(const string& s) {
_str = new char[s._capacity + 1];
strcpy(_str, s._str);
_size = s._size;
_capacity = s._capacity;
}
(2)法2:巧用swap
先用一个局部对象tmp将字符串s中的、除指针以外的内容全盘接收,在交换this和局部对象,就完成了用字符串s拷贝构造this的任务。tmp就是一个棋子,调用完毕tmp就被销毁,因此不用管swap之后tmp中储存的值。
string(const string& s) {
string tmp(s._str);
swap(tmp);
}
️3.析构函数 ~string
会自动调用,无需显式调用
~string() {
delete[] _str;
_size = 0;
_capacity = 0;
}
五、操作符重载
️1.下标访问 operator[]
两个重载,一个是可读可写,可借此修改字符;另一个是只能读不可写,针对被const修饰的字符串:
//可读可写版本
char& operator[](size_t pos) {
assert(pos < _size);
return _str[pos];
}
//只可读不可写版本
const char& operator[](size_t pos)const {
assert(pos < _size);
return _str[pos];
}
注意:
- assert可以检验出越界访问。
- operator[]一定要用引用返回,不是为了减少拷贝次数,而是为了让返回值可以被更改。传值返回无法让值变化。
️2.赋值 operator=
思考:赋值重载函数的参数是什么?
赋值有两种,一种是用字符串本身赋值,此时参数为string类型(或string&);另一种是用指针指向的字符串赋值,此时参数为char类型。按道理,应该有两个函数重载分别对应这两个参数类型,但是char类型可以隐式转换成string类型(本质上是用字符串构造一个临时对象),即参数为char时也可以调用operator=(string& s)函数,但反过来,string类型不可以隐式转换成char类型,即char*类型时无法传string类型的参数。
因此:只将string(或string&)作为参数类型即可,无需有其他重载。
法1:引用传参,开新空间释放旧空间
string& operator=(const string& s) {
if (this != &s) {
//比较两个对象的地址是否相等,相等就没必要赋值了
char* tmp = new char[s._capacity + 1];
strcpy(tmp, s._str);
delete[] _str;
_str = tmp;
_size = s._size;
_capacity = s._capacity;
}
return *this;
}
注意:

此处比较的是两个对象的地址,而不是两个对象内部存储的值,一旦两个对象的地址相同了,就说明他们是同一个对象,就没必要进行下面的赋值工作了。
法2:引用传参,构造临时对象再swap
string& operator=(string& s) {
if (this != &s) {
string tmp(s);
swap(s);
}
return *this;
}
法3:传值传参,直接swap
string& operator=(string s) {
swap(s);
return *this;
}
为何传参一定要传值而不是传引用?
当使用传值传参方式时,实际上是用原对象拷贝构造了一个局部对象,该局部对象只在该函数中存在,后序的swap也是将this和局部对象交换,与等号右边的对象没关系。函数运行结束后局部对象就会被销毁,这样既达到了给this赋值,又不会影响等号右边的那个字符串。一旦传了引用,则等号右边的对象的值就被等号左边偷走了。
六、插入
️1.尾插一个字符 push_back
步骤:判断容量够不够,不够扩容->_size位置放入字符->_size加1->最后放入标志性字符’\0’。
void push_back(char ch) {
if (_size == _capacity) {
int newCapacity = _capacity == 0 ? 4 : 2 * _capacity;
reserve(newCapacity);
}
_str[_size] = ch;
_size++;
_str[_size] = '\0';
}
️2.尾插一串字符串append
思考:赋值重载函数的参数是什么?
和operator=那里的分析思路相同,结论是:参数采用string&。
步骤:判断容量够不够,不够扩容->从_size位置开始往后,放入字符串->_size加插入的字符串的长度->最后在_size位置放入标志性字符’\0\
void append(const string& s) {
if (s._size + _size > _capacity) {
reserve(s._size + _size);
}
strcpy(_str + _size, s._str);
_size += s._size;
}
️3.尾插字符或字符串 +=
有两个重载,功能分别为尾插字符和尾插字符串。可以直接用push_back和append函数。
string& operator+=(char ch) {
//直接复用push_back函数
push_back(ch);
return *this;
}
string& operator+=(const string& s) {
//或者直接复用append函数
append(s);
return *this;
}
️4.内部插入 insert
重载1:内部插入一个字符
void insert(size_t pos, char ch) {
assert(pos <= _size);
//当pos=_size时,就相当于在原字符串的末尾插入一个字符ch
if (_size + 1 > _capacity) {
reserve(_size + 1);
}
//为防止挪动覆盖原数据,从后往前,将该位置的值放到下一个位置上
int end = _size;
while (end >= (int)pos) {
_str[end + 1] = _str[end];
end--;
}
_str[pos] = ch;
_size++;
}
普通注意点:
- 需要一个一个地移动字符:整体向后移动的话,该整体内部的字符需从后往前进行操作;整体向前移动的话,该整体内部的字符需从前往后进行操作。
- 标志字符’\0’也需要被移动,即挪动前下标为_size的位置的字符’\0’,最终被挪动到下标为_size+len的位置。
超级注意点:end需要是int类型,pos也要强制转化为int
- while内部的end一定要强制转换成int,即while (end >= pos&&end > 0),否则程序会因为死循环崩溃。
- 原因分析:当pos为0时,仍会进入循环,但由于end的数据类型为size_t,end减一变成了无符号-1,即整型最大值,不会变成负数,永远满足end>=pos的条件,循环永远不结束,最终程序崩溃。
- end是int类型呀,为什么程序还是会挂?因为符号左右两边类型不同时(左边的end类型为int,右边的pos类型为size_t),小范围的会整型提升成大范围的size_t,即end还是会整型提升为无符号类型。
- 只能首先声明end为int类型的变量,再将pos强制转换为int类型,end的值才可能是-1,循环才会结束。
另一种可行的办法:

重载2:内部插入一串字符串
为了一举两得地函数适用于字符串和字符串指针,字符串的参数类型为string&,而不是char*。
写法1:用循环控制字符的移动
void insert(size_t pos, const string& s) {
assert(pos <= _size);
reserve(_size + s._size);
int end = _size;
size_t len = s._size;
while (end >= (int)pos) {
_str[end + len] = _str[end];
end--;
}
strncpy(_str + pos, s._str, len);
_size += len;
}
其实写法一就是模拟了一下strncpy函数,当然可以直接用strncpy函数本身,即写法2。
写法2:用strncpy函数控制字符的移动
void insert(size_t pos, const string& s) {
assert(pos <= _size);
reserve(_size + s._size);
strncpy(_str + pos + s._size, _str + pos, s._size);
strncpy(_str + pos, s._str, s._size);
_size += s._size;
_capacity += s._capacity;
}
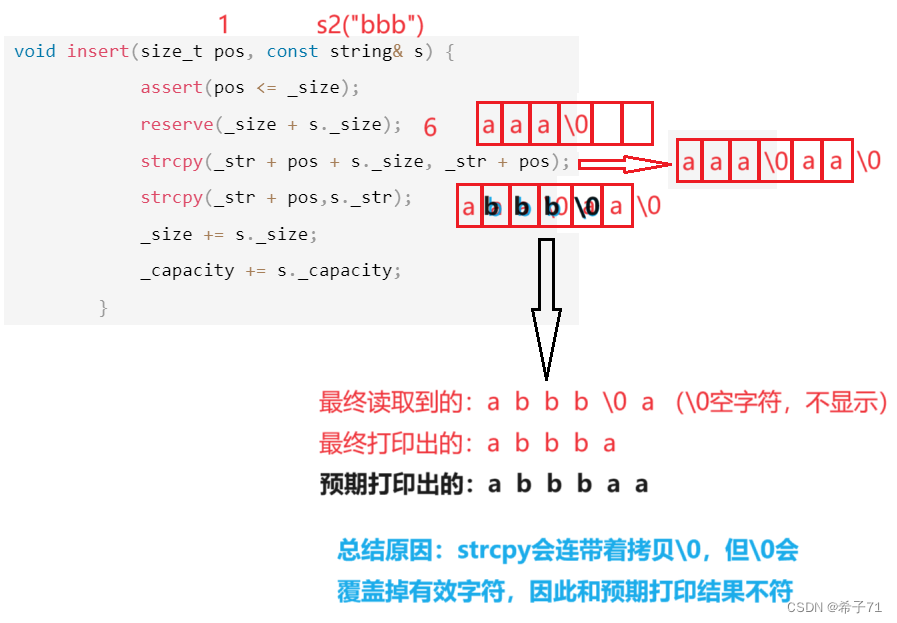
超级注意点:谨慎使用strcpy
万万不可把strncpy函数写成strcpy。
下面是使用strcpy导致打印不符合预期的例子:
string()...
~string()...
void insert(size_t pos, const string& s) {
assert(pos <= _size);
reserve(_size + s._size);
strcpy(_str + pos + s._size, _str + pos);
strcpy(_str + pos,s._str);
_size += s._size;
_capacity += s._capacity;
}
void TestInsert() {
string s1 = "aaa";
string s2 = "bbb";
s1.insert(1, s2);
std::cout << s1;
}
int main() {
tmp::TestInsert();
}
预期输出:abbbaa
实际输出:abbba
原因分析:
七、删除
️1.尾删一个字符pop_back
void pop_back() {
if (_size!=0) {
_str[_size - 1] = '\0';
_size--;
}
}
️2.删除一长串内容 erase
删除从pos位置开始,长度为len个字符:
情况一:当pos+len代表的位置超出或等于字符串的长度,表示删除从pos位置开始后面的所有数据,只需要将_size等于pos,表示pos位置已经是删除后的字符串的末尾了,给_size位置放上结束字符’\0’。
情况二:删除原字符串中间的部分内容,用strcpy函数将pos+len位置以后的数据拷贝到pos位置,_size-=len,最后_size位置放上结束符’\0’。
void erase(size_t pos, size_t len = npos) {
assert(pos <= _size);
if (len == npos || pos + len >= _size) {
_str[pos] = '\0';
_size = pos;
}
else {
strcpy(_str + pos, _str + pos + len);
_size -= len;
}
}
这里用strcpy函数很合适,正好可以连带着把’\0’符号也移动了。
️3.清空所有内容 clear
void clear() {
_size = 0;
_str[0] = '\0';
}
八、寻找某个位置 find
️1.找某个字符出现的位置
size_t find(const char ch, size_t pos=0) {
assert(pos < _size);
for (int i = pos;i < _size;i++) {
if (_str[i] == ch) {
return i;
}
}
return npos;
}
pos有缺省值1,默认从0位置开始寻找。注意,此时是半缺省函数,缺省参数只能写在右边部分,并且连续,不可以跳跃设置缺省参数。
️2.找某串子字符串出现的位置
法1:指针先停在可能位置,再进一步判断是否是该位置
bool isSame(const string& s, size_t pos=0) {
for (int i = 0;i < s._size;i++) {
if (!*(_str + pos) == *(s._str + i))
return false;
pos++;
}
return true;
}
size_t find(const string& s ,size_t pos=0) {
assert(pos < _size);
if (pos + s._size <= _size)
return npos;
for (int i = pos;i < _size;i++) {
if (_str[i] == s._str[0] && isSame(i, s))
return i;
}
return npos;
}
法2:直接用strstr函数
其实法1是对strstr函数的模拟,当然也可以直接用strstr函数:
size_t find(const string& s, size_t pos=0) {
assert(pos < _size);
const char* ptr = strstr(_str + pos, s._str);
if (ptr == nullptr) {
return npos;
}
else {
return ptr - _str;
}
}
九、用子字符串构造新字符串 substr
从pos位置开始,将这之后的len个位置的所有字符组成一个新的字符串。
情况一:pos+len<_size。子字符串就是从pos到pos+len。
情况二:pos+len>=_size。则只能取到size位置,end位置就是_size的值。
情况三:len==npos,和情况二处理方法相同。
string& substr(size_t pos=0, size_t len=npos) {
assert(pos < _size);
size_t end = pos + len;
if (len == npos || pos + len >= _size) {
end = _size;
}
string ret;
for (int i = pos;i < end;i++) {
//注意:i不需要等于end,下标为end的地方是空字符'\0'
//不需要我们放置,尾插会帮我们放置。
ret.push_back(_str[i]);
}
return ret;
}
十、(非成员函数)流操作符重载
注意:如果是成员函数,则默认第一个参数是this,这样写出来的插入和提取不符合可读性,只能把流插入提取函数写成非成员函数。
️1.流插入(<<)重载
思路:将已存在的字符串一个字符一个字符地存进out这个ostream类型的对象中,out再把值放到控制台上。
ostream& operator<<(ostream& out, const string& s) {
for (auto ch : s) {
out << ch;
}
return out;
}
️2.流提取(>>)重载
思路:将控制台输入的字符一个一个地读取进in这个std::istream类型的对象中,in再将这些字符放进提前声明好的字符串中。
错误1:in接收输入的内容,导致无限循环。
std::istream& operator>>(std::istream& in, string& s) {
char ch;
in >> ch;
while (ch != ' ' && ch != '\n') {
s += ch;
in >> ch;
}
return in;
}
错误原因:因为istream类型的对象的设计是这样的:识别到空格符’ ‘或换行符’\n’时,会自动略过寻找下一个有效字符,也就是说永远不会把空格符或换行符存储进自身。对于本程序而言,while中的条件永远符合,永远不会停止输入。
如何解决?找到一个能读取到空格符和换行符的方法,即get函数。get函数可以读取并存储空格符和换行符。通过get函数将读到的所有字符都存入ch变量中,ch再判断是否是空格符或换行符,一旦是就停止。
解决错误1:用get函数接收输入的内容。
std::istream& operator>>(std::istream& in, string& s) {
char ch = in.get();
while (ch != ' ' && ch != '\n') {
s += ch;
ch = in.get();
}
return in;
}
补充:有关缓冲区的知识
如果输入的内容中有空格,空格后的内容会先存进缓冲区,如果此时后面的程序中有其他对象的流提取的语句,则会将缓冲区的内容存储到其他对象中。
void TestInOut() {
string s1;
std::cin >> s1;
std::cout << s1 << std::endl;
string s2;
std::cin >> s2;
std::cout << s2 << std::endl;
string s3;
std::cin >> s3;
std::cout << s3 << std::endl;
}
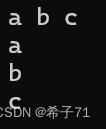
- 第一次输入和输出:
string s1;
std::cin >> s1;——>输入了a b c
std::cout << s1 << std::endl;——>打印出a
(问:为何只打印了一个字符?答:因为每次读取只能读取到第一个空格前面的内容,遇到空格或换行会停止读取)
(问:那剩下的内容去了哪里?答:停留在缓冲区中,后续其他对象打印的内容直接从缓冲区上获得) - 第二次输入输出:
string s2;
std::cin >> s2;——>因为缓冲区有东西,所以无需再输入
std::cout << s2 << std::endl;——>打印出b
(同样的道理,缓冲区有b c,只能读取到第一个空格前的内容,即b) - 第三次输入输出:
string s3;
std::cin >> s3;——>因为缓冲区有东西,所以无需再输入
std::cout << s3 << std::endl;——>打印出c - 如果还有第四次输入输出呢?答:到第四次时,缓冲区就没有东西了,执行输入语句时就需要自己输入了。
错误2:同一个对象,前面输入的内容影响了后面输入的内容
问题:先后两次对同一个对象进行输入,前面的内容会影响后面吗?
由于我们模拟的是std库中的string,不妨先看看库里是如何处置的:
void TestInOut() {
std::string s1;
std::cin >> s1;
std::cout << s1 << std::endl;
std::cin >> s1;
std::cout << s1 << std::endl;
}
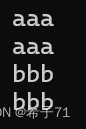
可看出,对于std库中的string,先后对同一个对象(s1)输入,上一次输入的不会影响下一次的内容。
反观我们写的函数的运行结果:
std::istream& operator>>(std::istream& in, string& s) {
char ch = in.get();
while (ch != ' ' && ch != '\n') {
s += ch;
ch = in.get();
}
return in;
}
void TestInOut() {
std::string s1;
std::cin >> s1;
std::cout << s1 << std::endl;
std::cin >> s1;
std::cout << s1 << std::endl;
}
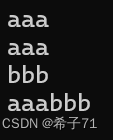
连带着上一次输入的内容也打印出来了。
解决错误2:
在流提取函数的最开始加上个clear函数就可以了:
std::istream& operator>>(std::istream& in, string& s) {
s.clear();
char ch = in.get();
while (ch != ' ' && ch != '\n') {
s += ch;
ch = in.get();
}
return in;
}
需要改进的地方:频繁尾插拉低效率
流提取本质就是通过循环,读取输入的字符,再将字符尾插到字符串中,但频繁的尾插需要频繁reserve,因此借用内存池的思想,提前开好一大块空间,将读取到的字符先放入空间中,一旦读取结束或空间被放满了,在整体尾插进字符串。
最优版本的流提取:
设置容量为128的字符数组buff,先将读取到的字符插入到数组中,最后在将数组整体尾插进字符串。
istream& operator>>(istream& in, string& s) {
char buff[128];//设置一个大一点的数组,就不用频繁reserve了
char ch = in.get();
int i = 0;
while (ch != '\0' && ch != '\n') {
buff[i++] = ch;
if (i == 127) {
buff[i] = '\0';
s += buff;
i = 0;
}
ch = in.get();
}
if (i > 0) {
buff[i] = '\0';
s += buff;
}
return in;
}
十一、分文件的string模拟实现(完整程序)
以下是模拟实现string程序的分文件模式,分成string.h、string.cpp、test.cpp三个文件(test.cpp中无实际测试程序,走个形式。但函数经过了测试可运行)
️分文件的注意事项
- .h的头文件不会被编译,只会在.c和.cpp文件中被替换展开。
- 头文件的包含不能重复。
比如:一个.cpp文件包含了string.h和tmp.h,但tmp.h文件中也包含了一个string.h。 - 包含头文件时,就假象头文件和该文件写在一起,一定要上下对应,下面出现的函数要在上面的头文件中找到对应的声明,否则就会报错。
- 缺省值只能在声明给,不可声明定义同时给。即.cpp文件中不可以出现缺省参数,否则编译不通过。
- .h文件中有命名空间、类名、内联函数;.cpp文件中只有命名空间,且函数去前面都要加上域名。
️string.h
#pragma once
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
#include<assert.h>
namespace tmp {
class string {
public:
//迭代器
typedef char* iterator;
typedef const char* const_iterator;
iterator begin() {
return _str;
}
iterator end() {
return _str + _size;
}
const_iterator begin() const {
return _str;
}
const_iterator end() const {
return _str + _size;
}
//返回字符串指针
const char* c_str() const {
return _str;
}
//计算大小
size_t size() const {
return _size;
}
//交换字符串
void swap(string& s);
//开n个空间
void reserve(size_t n);
//构造函数
string(const char* str = "");
//拷贝构造
string(const string& s);
//析构
~string();
//赋值重载
string& operator=(string s);
//下标访问重载
char& operator[](size_t pos);
const char& operator[](size_t pos)const;
//(插入)尾插一个字符
void push_back(char ch);
//(插入)尾插一串字符
void append(const string& s);
//(插入)+= 各种尾插(字符、字符串)
string& operator+=(char ch);
string& operator+=(const string& s);
//(插入)insert 内部插入(字符、字符串)
void insert(size_t pos, char ch);
void insert(size_t pos, const string& s);
//(删除)尾删
void pop_back();
//部分删除
void erase(size_t pos, size_t len = npos);
//清空内容
void clear();
//找字符位置
size_t find(const char ch, size_t pos = 0);
//找字符串位置
size_t find(const string& s, size_t pos=0);
//子字符串
string& substr(size_t pos = 0, size_t len = npos);
private:
char* _str;
size_t _size;
size_t _capacity;
const static size_t npos = -1;
};
//流操作符重载
std::ostream& operator<<(std::ostream& out, const string& s);
std::istream& operator>>(std::istream& in, string& s);
}
️string.cpp
#include"string.h"
namespace tmp {
//开n个空间
void string::reserve(size_t n) {
if (n > _capacity) {
char* tmp = new char[n + 1];
strcpy(tmp, _str);
delete[] _str;
_str = tmp;
//_size不变,光_capacity变
_capacity = n;
}
}
//交换字符串
void string::swap(string& s) {
//借助std的swap,以防自己调用自己从而栈溢出
std::swap(_str, s._str);
std::swap(_size, s._size);
std::swap(_capacity, s._capacity);
}
//构造函数
string::string(const char* str) {
//str = ""
_size = strlen(str);
_capacity = _size;
_str = new char[_capacity + 1];
strcpy(_str, str);
_str[_size] = '\0';
}
//拷贝构造
string::string(const string& s) {
string tmp(s._str);
swap(tmp);
}
//析构
string::~string() {
delete[] _str;
_size = 0;
_capacity = 0;
}
//赋值重载
string& string::operator=(string s) {
swap(s);
return *this;
}
//下标访问重载
char& string::operator[](size_t pos) {
//可读可写版本
assert(pos < _size);
return _str[pos];
}
const char& string::operator[](size_t pos)const {
//只可读不可写版本
assert(pos < _size);
return _str[pos];
}
//(插入)尾插一个字符
void string::push_back(char ch) {
if (_size == _capacity) {
int newCapacity = _capacity == 0 ? 4 : 2 * _capacity;
reserve(newCapacity);
}
_str[_size] = ch;
_size++;
_str[_size] = '\0';
}
//(插入)尾插一串字符
void string::append(const string& s) {
if (s._size + _size > _capacity) {
reserve(s._size + _size);
}
strcpy(_str + _size, s._str);
_size += s._size;
}
//(插入)+= 各种尾插(字符、字符串)
string& string::operator+=(char ch) {
push_back(ch);
return *this;
}
string& string::operator+=(const string& s) {
append(s);
return *this;
}
//(插入)insert 内部插入(字符、字符串)
void string::insert(size_t pos, char ch) {
assert(pos <= _size);
//当pos=_size时,就相当于在原字符串的末尾插入一个字符ch
if (_size + 1 > _capacity) {
reserve(_size + 1);
}
int end = _size;
while (end >= (int)pos) {
_str[end + 1] = _str[end];
end--;
}
_str[pos] = ch;
_size++;
}
void string::insert(size_t pos, const string& s) {
assert(pos <= _size);
reserve(_size + s._size);
strncpy(_str + pos + s._size, _str + pos, s._size);
strncpy(_str + pos, s._str, s._size);
_size += s._size;
_capacity += s._capacity;
}
//(删除)尾删
void string::pop_back() {
if (_size != 0) {
_str[_size - 1] = '\0';
_size--;
}
}
//部分删除
void string::erase(size_t pos, size_t len) {
//len=npos
assert(pos <= _size);
if (len == npos || pos + len >= _size) {
_str[pos] = '\0';
_size = pos;
}
else {
strcpy(_str + pos, _str + pos + len);
_size -= len;
}
}
//清空内容
void string::clear() {
_size = 0;
_str[0] = '\0';
}
//找字符位置
size_t string::find(const char ch, size_t pos) {
//pos=0
assert(pos < _size);
for (int i = pos;i < _size;i++) {
if (_str[i] == ch) {
return i;
}
}
return npos;
}
//找字符串位置
size_t string::find(const string& s, size_t pos) {
//pos=0
assert(pos < _size);
const char* ptr = strstr(_str + pos, s._str);
if (ptr == nullptr) {
return npos;
}
else {
return ptr - _str;
}
}
//子字符串
string& string::substr(size_t pos, size_t len) {
//pos=0 len=npos
assert(pos < _size);
size_t end = pos + len;
if (len == npos || pos + len > _size) {
end = _size;
}
string ret;
for (int i = pos;i < end;i++) {
//注意:i不可以等于end,会越界。
//假设pos=0,len=10,_size=10,最终子字符串的下标是从0到9,下标不可能取到10
ret.push_back(_str[i]);
}
return ret;
}
//流操作符重载
std::ostream& operator<<(std::ostream& out, const string& s) {
for (auto ch : s) {
out << ch;
}
return out;
}
std::istream& operator>>(std::istream& in, string& s) {
char buff[128];//设置一个大一点的数组,就不用频繁reserve了
char ch = in.get();
int i = 0;
while (ch != ' ' && ch != '\n') {
buff[i++] = ch;
if (i == 127) {
buff[i] = '\0';
s += buff;
i = 0;
}
ch = in.get();
}
if (i > 0) {
buff[i] = '\0';
s += buff;
}
return in;
}
}
️Test.cpp
注意包含头文件。
#include"string.h"
using namespace tmp;
int main() {
}
智能推荐
while循环&CPU占用率高问题深入分析与解决方案_main函数使用while(1)循环cpu占用99-程序员宅基地
文章浏览阅读3.8k次,点赞9次,收藏28次。直接上一个工作中碰到的问题,另外一个系统开启多线程调用我这边的接口,然后我这边会开启多线程批量查询第三方接口并且返回给调用方。使用的是两三年前别人遗留下来的方法,放到线上后发现确实是可以正常取到结果,但是一旦调用,CPU占用就直接100%(部署环境是win server服务器)。因此查看了下相关的老代码并使用JProfiler查看发现是在某个while循环的时候有问题。具体项目代码就不贴了,类似于下面这段代码。while(flag) {//your code;}这里的flag._main函数使用while(1)循环cpu占用99
【无标题】jetbrains idea shift f6不生效_idea shift +f6快捷键不生效-程序员宅基地
文章浏览阅读347次。idea shift f6 快捷键无效_idea shift +f6快捷键不生效
node.js学习笔记之Node中的核心模块_node模块中有很多核心模块,以下不属于核心模块,使用时需下载的是-程序员宅基地
文章浏览阅读135次。Ecmacript 中没有DOM 和 BOM核心模块Node为JavaScript提供了很多服务器级别,这些API绝大多数都被包装到了一个具名和核心模块中了,例如文件操作的 fs 核心模块 ,http服务构建的http 模块 path 路径操作模块 os 操作系统信息模块// 用来获取机器信息的var os = require('os')// 用来操作路径的var path = require('path')// 获取当前机器的 CPU 信息console.log(os.cpus._node模块中有很多核心模块,以下不属于核心模块,使用时需下载的是
数学建模【SPSS 下载-安装、方差分析与回归分析的SPSS实现(软件概述、方差分析、回归分析)】_化工数学模型数据回归软件-程序员宅基地
文章浏览阅读10w+次,点赞435次,收藏3.4k次。SPSS 22 下载安装过程7.6 方差分析与回归分析的SPSS实现7.6.1 SPSS软件概述1 SPSS版本与安装2 SPSS界面3 SPSS特点4 SPSS数据7.6.2 SPSS与方差分析1 单因素方差分析2 双因素方差分析7.6.3 SPSS与回归分析SPSS回归分析过程牙膏价格问题的回归分析_化工数学模型数据回归软件
利用hutool实现邮件发送功能_hutool发送邮件-程序员宅基地
文章浏览阅读7.5k次。如何利用hutool工具包实现邮件发送功能呢?1、首先引入hutool依赖<dependency> <groupId>cn.hutool</groupId> <artifactId>hutool-all</artifactId> <version>5.7.19</version></dependency>2、编写邮件发送工具类package com.pc.c..._hutool发送邮件
docker安装elasticsearch,elasticsearch-head,kibana,ik分词器_docker安装kibana连接elasticsearch并且elasticsearch有密码-程序员宅基地
文章浏览阅读867次,点赞2次,收藏2次。docker安装elasticsearch,elasticsearch-head,kibana,ik分词器安装方式基本有两种,一种是pull的方式,一种是Dockerfile的方式,由于pull的方式pull下来后还需配置许多东西且不便于复用,个人比较喜欢使用Dockerfile的方式所有docker支持的镜像基本都在https://hub.docker.com/docker的官网上能找到合..._docker安装kibana连接elasticsearch并且elasticsearch有密码
随便推点
Python 攻克移动开发失败!_beeware-程序员宅基地
文章浏览阅读1.3w次,点赞57次,收藏92次。整理 | 郑丽媛出品 | CSDN(ID:CSDNnews)近年来,随着机器学习的兴起,有一门编程语言逐渐变得火热——Python。得益于其针对机器学习提供了大量开源框架和第三方模块,内置..._beeware
Swift4.0_Timer 的基本使用_swift timer 暂停-程序员宅基地
文章浏览阅读7.9k次。//// ViewController.swift// Day_10_Timer//// Created by dongqiangfei on 2018/10/15.// Copyright 2018年 飞飞. All rights reserved.//import UIKitclass ViewController: UIViewController { ..._swift timer 暂停
元素三大等待-程序员宅基地
文章浏览阅读986次,点赞2次,收藏2次。1.硬性等待让当前线程暂停执行,应用场景:代码执行速度太快了,但是UI元素没有立马加载出来,造成两者不同步,这时候就可以让代码等待一下,再去执行找元素的动作线程休眠,强制等待 Thread.sleep(long mills)package com.example.demo;import org.junit.jupiter.api.Test;import org.openqa.selenium.By;import org.openqa.selenium.firefox.Firefox.._元素三大等待
Java软件工程师职位分析_java岗位分析-程序员宅基地
文章浏览阅读3k次,点赞4次,收藏14次。Java软件工程师职位分析_java岗位分析
Java:Unreachable code的解决方法_java unreachable code-程序员宅基地
文章浏览阅读2k次。Java:Unreachable code的解决方法_java unreachable code
标签data-*自定义属性值和根据data属性值查找对应标签_如何根据data-*属性获取对应的标签对象-程序员宅基地
文章浏览阅读1w次。1、html中设置标签data-*的值 标题 11111 222222、点击获取当前标签的data-url的值$('dd').on('click', function() { var urlVal = $(this).data('ur_如何根据data-*属性获取对应的标签对象