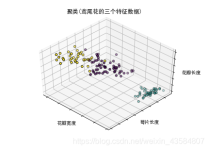
”聚类“ 的搜索结果
聚类
标签: JupyterNotebook
聚类 在这里,我使用python代码来展示各种聚类算法如何工作,并将其应用于数据集。
(一)何谓聚类 还是那句“物以类聚、人以群分”,如果预先知道人群的标签(如文艺、普通、2B),那么根据监督学习的分类算法可将一个人明确的划分到某一类;如果预先不知道人群的标签,那就只有根据人的特征(如...
聚类分析一、聚类的关键:距离二、K-means聚类算法三、聚类的注意事项聚类好坏的评估方法1、技术上的方法2、业务上的方法连续型数据标准化分类型数据标准化 一、聚类的关键:距离 二、K-means聚类算法 三、聚类的...
MYDBSCAN:基于密度的聚类DBSCAN(Density-Based Spatial Clustering of Applications with Noise)算法的底层实现 MYAP:基于划分的聚类AP(Affinity Propagation Clustering Algorithm )算法的底层实现--近邻传播...
【代码】PhaGCN2:病毒聚类。
探索 Awesome Deep Graph Clustering: 深度图聚类的新境界 项目地址:https://gitcode.com/yueliu1999/Awesome-Deep-Graph-Clustering 在这个数据驱动的世界里,Awesome Deep Graph Clustering 是一个令人兴奋的开源...
代码 复杂网络的聚类系数算法代码代码 复杂网络的聚类系数算法代码代码 复杂网络的聚类系数算法代码代码 复杂网络的聚类系数算法代码代码 复杂网络的聚类系数算法代码代码 复杂网络的聚类系数算法代码代码 复杂网络...
利用MATLAB做模糊聚类,并且画出系谱图
ai ai_机器学习算法实现之KMeans聚类
通过密度聚类算法的应用,可以有效地削减风电和电负荷数据中的异常点,从而提取出更具代表性的场景模型。这种方法不仅能够提高场景模型的准确性,还能够更好地反映出风电和电负荷之间的关联关系,为电网的运行和调度...

在本教程中,您发现了如何在 python 中安装和使用顶级聚类算法。具体来说,你学到了:聚类是在特征空间输入数据中发现自然组的无监督问题。有许多不同的聚类算法,对于所有数据集没有单一的最佳方法。在 scikit-...
本文件为常见聚类算法测试数据集 ,UCI上常用的聚类算法数据集
经典层次聚类算法DIANA,MATLAB编程,简单易懂,可以运行
Python HDBSCAN是一款基于密度的层次聚类算法库,能够有效处理数据中的离群点和噪声,是数据挖掘和机器学习领域常用的工具之一。本文将介绍HDBSCAN库的安装、特性、基本功能、高级功能、实际应用场景等方面。
特征波长筛选算法有CARS,SPA,GA,MCUVE,光谱数据降维算法以及数据聚类算法PCA,KPCA,KNN,HC层次聚类降维,以及SOM数据聚类算法,都是直接替换数据就可以用,程序内有注释,直接替换光谱数据,以及实测值,就...

在数据挖掘算法中,K均值聚类算法是一种比较常见的无监督学习方法,簇间数据对象越相异,簇内数据对象越相似,说明该聚类效果越好。然而,簇个数的选取通常是由有经验的用户预先进行设定的参数。本文提出了一种能够...
python 文本聚类分析案例说明摘要1、结巴分词2、去除停用词3、生成tfidf矩阵4、K-means聚类5、获取主题词 / 主题词团 说明 实验要求:对若干条文本进行聚类分析,最终得到几个主题词团。 实验思路:将数据进行预处理...
手写K均值K_means和模糊C均值FCM算法对Iris鸢尾花数据集聚类以及图像聚类分割 数据集:Iris Requirement pandas numpy cv2 matplotlib

聚类分析,基于kmeans聚类分析并输出收敛图,matlab2021a仿真,输出聚类点,聚类收敛图。
聚类分析,kmeans聚类分析,输出聚类坐标点。matlab2021a测试仿真。
python 聚类 效果图利用DBSCAN方法对用户的使用时间进行聚类,利用python的matplotlib库进行了作图绘制,将用户基于一天24小时进行分类处理得到了几类用户并进行了作图分析
在单链接聚类中,两个聚类之间的链接距离是两个聚类中最接近的两个点的距离。在方阵中,行和列都代表城市,对角线上的元素是城市与自己之间的距离,非对角线上的元素是城市之间的距离。‘average’(平均链接):...
基本的层次聚类算法matlab实现 简单明了 是我以前上课时记下的笔记内容 代码在15b上实验证实可用
K-means 对 iris 数据进行聚类并显示聚类中心,聚类结果等,附注释
推荐文章
- NSFuzz:TowardsEfficient and State-Aware Network Service Fuzzing-程序员宅基地
- 刘睿民畅谈大数据:政府应紧急设立首席数据官-程序员宅基地
- nginx 编译安装依赖包_nginx编译怎么添加新的依赖库-程序员宅基地
- Python+OpenCV+Tesseract实现OCR字符识别_python + opencv + tesseract-程序员宅基地
- 微型计算机主板上的主要部件,微型计算机主板上安装的主要部件-程序员宅基地
- 推荐一款可匹敌国际大厂的国产企业级低无代码平台_国产私有化 无代码-程序员宅基地
- UE4 蓝图 实现 数组的边遍历边删除_ue4 数组删不掉-程序员宅基地
- python爬虫之bs4解析和xpath解析_from bs4 import beautifulsoup xpath-程序员宅基地
- MySQL配置环境变量-程序员宅基地
- VGG16进行微调,训练mnist数据集_vgg16 tensorflow 2 mnist-程序员宅基地