遗传算法(Genetic Algorithm,GA)最早是由美国的 John holland于20世纪70年代提出,该算法是根据大自然中生物体进化规律而设计提出的。是模拟。
”无监督学习“ 的搜索结果
2.Unsupervised Learning — 无监督学习 3.Reinforcement Learning — 强化学习 1.监督学习 监督学习,就是人们常说的分类,通过已有的训练样本(即已知数据以及其对应的输出)去训练得到一个最优模型...
无监督学习与推荐系统:创新思路 推荐系统是现代信息处理的重要组成部分,它通过对用户的行为、兴趣和喜好进行分析,为用户提供个性化的信息、产品和服务。随着数据量的增加,传统的推荐系统已经不能满足现实中复杂...
随着数据的爆炸增长,无监督学习成为了人工智能领域的重要研究方向之一。无监督学习通过对无标签数据进行处理,可以帮助我们发现数据中的模式和结构。神经网络是机器学习的核心技术之一,它在各种应用领域取得了显著...
无监督学习是当今计算机视觉领域最困难的挑战之一。这项任务在人工智能和新兴技术中有着巨大的实用价值,因为可以用相对较低的成本收集大量未标注的视频。——————01 概述——...
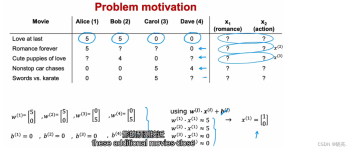
无监督学习是一种机器学习方法,它不依赖于标签或标注的数据集。相反,它从未标记的数据中自动发现模式和结构。无监督学习可以应用于许多领域,包括图像处理、文本挖掘、数据压缩和聚类等。在大数据时代,无监督学习...
无监督学习在自然语言生成中的应用
标签: 学习
在自然语言生成任务中,无监督学习是一种重要的方法,它可以帮助我们在没有明确标签或标注的情况下,从大量的文本数据中学习语言模式和结构。 无监督学习是一种机器学习方法,它不需要预先标记的数据来训练模型。...
本文仅对常见的无监督学习算法进行了简单讲述,其他的如自动编码器,受限玻尔兹曼机用于无监督学习,神经网络用于无监督学习等未包括。同时虽然整体上分为了聚类和降维两大类,但实际上这两类并非完全正交,很多地方...
机器学习五大分类: 1.监督学习: 从给定的训练集中学习一个函数,当新数据到来时,可以根据这个... 无监督学习与监督学习相比,训练集没有人为标注的结果(有些数据难以人工标注分类或标注分类成本太高)。...
无监督学习是一种机器学习方法,它不依赖于标签或者已知的输出数据来训练模型。相反,它通过分析输入数据的结构和模式来自动发现模式和规律。无监督学习通常用于处理未知或不可描述的数据,例如图像、文本、音频等。...
无监督学习是一种机器学习方法,它不需要预先标记的数据来训练模型。相反,它通过分析未标记的数据来发现数据中的模式和结构。在医学图像分析领域,无监督学习已经被广泛应用于许多任务,例如疾病诊断、病理诊断、...
有监督学习分类器:朴素贝叶斯,决策树,k-近邻,神经网络,支持向量机,随机森林,逻辑回归,最小二乘法,...无监督学习分类器:k-means(k-均值),DBSCAN,主成分分析,差异值分解,聚类算法,独立成分分析。 ...
在Deeplearning4j 1.0.0-beta5的版本中NLP模块开始支持FastText模型。在这之前的版本中,已经支持的embedding算法有Word2Vec、Glove、Doc2Vec以及Graph Embedding。这些模块的使用在我的GitChat CSDN达人课中有详细...
无监督学习是一种通过分析数据中的模式和结构来自动发现隐含结构的学习方法。它主要应用于数据竞争中,通过对数据的分类、聚类、降维等方式来提取数据中的知识。高斯混合模型(Gaussian Mixture Model, GMM)是一种...
无监督学习在文本情感分析中的应用
标签: 学习
1.背景介绍 文本情感分析是一种自然语言处理任务,旨在根据给定的文本内容判断其情感倾向。随着互联网的普及和社交媒体的兴起,文本情感分析的应用场景不断...无监督学习是一种机器学习方法,不需要预先标注的数据...
目录评估无监督学习算法代码 评估无监督学习算法 无监督学习算法不做出预测,也不存在 y 值,因此无法直接根据模型预测的准确率进行评估。以聚类算法为例,我们虽然可以目测“肘部”,但还是需要一个统计量。轮廓...

无监督学习是一种通过从数据中发现隐含的结构和模式,而不需要人类干预的学习方法。在本文中,我们将探讨无监督学习在时间序列分析中的作用,并讨论其主要算法和应用。 2.核心概念与联系 无监督学习是一种通过从...
1.背景介绍 生成对抗网络(Generative Adversarial Networks,GANs)是一种深度学习算法,它由两个相互对抗的神经网络组成:生成器...这种对抗学习框架使得GANs能够学习到数据的复杂结构,并在图像生成、图像...
如今,ImageNet上图像识别精度的性能提升通常一次只有零点几个百分点,而来自谷歌研究人员的最新研究,如图灵奖获得者杰弗里·辛顿(Geoffrey Hinton)已经将无监督学习的指数提高了7-10%,甚至可以与有监督学习的...
无监督学习(unsupervised learning):训练样本的标记信息未知,目标是通过对无标记训练样本的学习来揭示数据的内在性质及规律,为进一步的数据分析提供基础,此类学习任务中研究最多、应用最广的是"聚类" ...
在机器学习(Machine learning)领域。主要有三类不同的学习方法:监督学习(Supervised learning)、非监督学习(Unsupervised learning)、半监督学习(Semi-supervised learning)。 监督学习:通过已有的一部分输
而我们需要做的“无监督学习”算法,难度则要大不少。对于我们这种算法小白,虽然理解了有监督和无监督的区别,对于无监督到底是怎么学习的还是有点云里雾里。 直到前几天看到一张算法学习的图,才略有点明白。挺...
监督学习(Supervised learning)、 非监督学习(Unsupervised learning)、 半监督学习(Semi-supervised learning), 监督学习:通过已有的一部分输入数据与输出数据之间的对应关系,生成一个函数,将输入映射...
监督学习 训练集的数据都是有标签的数据,在输入数据时,我们知道这个数据对应的输出,模型不断的建模数据输入和输出之间的关系。 不断的调整模型,缩小与真实输出的loss,直到输入输出一致。比如已知一些图片是猫...
自监督方法在深度学习中将取代当前占主导地位监督方法的预言已经存在了很长时间。 如今,自监督方法在Pascal VOC检测方面已经超过了监督方法(2019年何恺明提出的MoCo方法),并且在许多其他任务上也显示出了出色的...
任务 * 了解以下概念: &...从高层次上区分,有两种类型的建模技术:监督学习和无监督学习。 ▲ 基本流程:准备原料--> 模型学习 --> 模型评价 构建模型之后,使用标准指标...
机器学习分为:监督学习、无监督学习、强化学习 监督学习 监督学习是输入 ** 数据和标签** 进行训练学习,数据分为训练集和测试集。训练集用于训练模型,测试集用于验证模型的好坏。监督学习就像学生在学习时已知...
无监督学习 半监督学习 强化学习 1 监督学习 定义: 输入数据是由输入特征值和目标值所组成。 - 函数的输出可以是一个连续的值(称为回归) - 或是输出是有限个离散值(称作分类) 1.1 回归问题 例如:预测房价,...
推荐文章
- NSFuzz:TowardsEfficient and State-Aware Network Service Fuzzing-程序员宅基地
- 刘睿民畅谈大数据:政府应紧急设立首席数据官-程序员宅基地
- nginx 编译安装依赖包_nginx编译怎么添加新的依赖库-程序员宅基地
- Python+OpenCV+Tesseract实现OCR字符识别_python + opencv + tesseract-程序员宅基地
- 微型计算机主板上的主要部件,微型计算机主板上安装的主要部件-程序员宅基地
- 推荐一款可匹敌国际大厂的国产企业级低无代码平台_国产私有化 无代码-程序员宅基地
- UE4 蓝图 实现 数组的边遍历边删除_ue4 数组删不掉-程序员宅基地
- python爬虫之bs4解析和xpath解析_from bs4 import beautifulsoup xpath-程序员宅基地
- MySQL配置环境变量-程序员宅基地
- VGG16进行微调,训练mnist数据集_vgg16 tensorflow 2 mnist-程序员宅基地