
”对比学习“ 的搜索结果
对比学习是一种学习方法,侧重于通过对比正反两方面的实例来提取有意义的表征。它利用的假设是,在学习到的嵌入空间中,相似的实例应靠得更近,而不相似的实例应离得更远。通过将学习作为一项辨别任务,对比学习允许...
SupContrast:有监督的对比学习本文档以CIFAR为例说明了PyTorch中以下论文的参考实现:(1)有监督的对比学习。 论文(2)一个简单的Fr SupContrast:有监督的对比学习本文档以CIFAR为例说明了PyTorch中以下论文的...
在深度学习中, 如何利用大量、易获取的无标注数据增强神经网络模型的特征表达能力, 是一个具有重要意义的研究问题, 而对比学习是解决该问题的有效方法之一, 近年来得到了学术界的广泛关注, 涌现出一大批新的研究方法...
图像和文本对的对比学习表示ConVIRT论文中描述的体系结构的Pytorch实现:从成对的图像和文本中进行医学视觉表示的对比学习张宇豪,江航,三浦康秀,克里斯托弗·曼宁,柯蒂斯·P·朗格兹Eduardo Reis的非官方开源...
下面这张画详细解释了该模型原理,假设我们的batch-size为256,这样我们就有256张图片数据,通过数据增强操作我们得到256张增强图片,对于图片x1来说x1’为正样本,剩下的图片都是负样本(包括原始的图片以及数据...
作者做了超级多的实验,看李沐老师和朱老师的视频讲解也算是一次知识蒸馏([by Hinton)了通过大量的图像-文本对进行训练,CLIP的核心思想是通过对比学习来训练模型。它将图像与文本配对,并尝试将它们映射到相同的...

对比学习文献介绍,包含TS2vec、Subseries Consistency、TLoss/ Subseries Consistency、TNC/ Temporal consistency等文献,以及其他对比学习文件

对比学习 ——simsiam 代码解析。.doc
对比学习可以通过自我监督的方式捕捉时间序列数据中的时间依赖性和动态变化,这使得它特别适合处理时间序列数据,因为时间序列的本质特征就在于其随时间的演变和变化。因此,相较于传统的时序,能够适应更广泛、更...
对比学习最近在 3D 场景理解任务中展示了无监督预训练的巨大潜力。然而,大多数现有工作在建立对比度时随机选择点特征作为锚点,导致明显偏向通常在 3D 场景中占主导地位的背景点。此外,对象意识和前景到背景的辨别...
SSL 中使用的最古老和最受欢迎的技术之一是对比学习,它使用“正”和“负”样本来指导深度学习模型。此后,对比学习得到了进一步发展,现在被用于完全监督和半监督的环境中,并提高了现有技术水平的性能。现在让我们...
大家好,本文同步发布在公众号。
PyContrast此repo列出了最新的对比学习论文,并包括其中许多代码。论文清单找到很棒的对比学习。 PyTorch代码有关SoTA方法的参考实现(例如InstDis,CMC,MoCo等),请参见 。预训练模型提供了一组ImageNet无监督的...
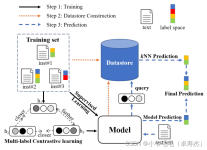
对比学习的核心思想是在无监督的情况下,学习出能够区分正例和负例的特征表示。对于一个给定的数据样本,正例是来自与该样本相似的其他样本,而负例是与该样本不相似的样本。通过最大化正例之间的相似度,同时最小化...

为了解决这一挑战,我们提出了一种新的基于图对比学习的对抗性自监督图神经网络(GNN),称为A-GCL,用于使用功能磁共振成像(fMRI)诊断神经发育障碍。利用GNN在fMRI诊断精神疾病中的成功应用,我们提出的A-GCL模型...

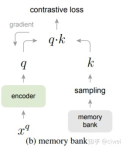
思维导图链接:https://www.processon.com/mindmap/64159f9ff502f062b5d616be是为了让模型更鲁棒,对噪声更加的不敏感。 在实现这一点上,有对抗防御、对抗攻击和对抗训练。 对抗防御是识别出更多的样本 ...
对比学习(Contrastive Learning)是一种自监督学习方法,它的核心目标是学习数据的表示(representation),使得相似的数据点在表示空间中靠近,而不相似的数据点在表示空间中远离。这种方法不依赖于标签数据,而是...
【多模态对比学习】我遇到的坑
标签: 学习
本文是对过去几个月来利用对比学习的思想来优化多模态学习任务的思路的总结,主要包含以下几个方面:为什么要用对比学习、跨模态中对比学习怎么用、对比的过程中负样本是不是越多越好、要不要推远所有的负样本、样本...
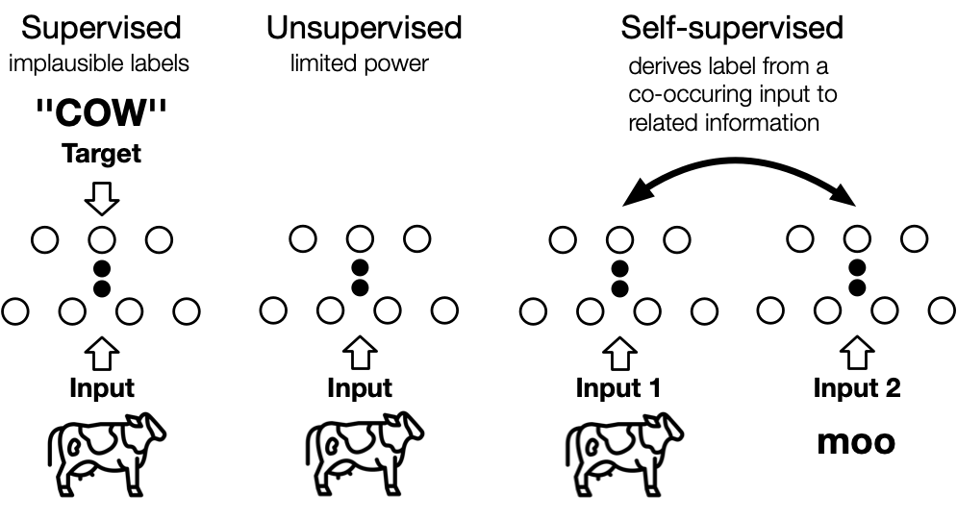
与往年相比,ICML 2020的接收率正逐年走低。本文发现基于对比学习(Contrastive Learning)相关的paper也不少,对比学习、自监督学习等等都是今年比较火的topic,受到了很多人的关注。
对比学习(Contrastive Learning)在自然语言处理(NLP)中具有广泛的应用。对比学习是一种无监督学习方法,旨在将相似样本聚集在一起,并将不相似样本分开。在NLP中,对比学习的目标是学习出具有语义相似性的向量...
汇报PPT,主要介绍了几篇深度学习领域->对比学习方面的论文,对于MOCO,simCLR两种典型的对比学习框架进行了介绍;而后从样例对比学习转到聚类对比学习,再转而介绍了有监督对比学习,总共设计6篇论文。适合于组会...
推荐文章
- Cool Clock - 创意无限的数字时钟-程序员宅基地
- QML之虚拟键盘简单使用_import qtquick.virtualkeyboard import qtquick.virt-程序员宅基地
- layui php cms,GitHub - weinasi/layuiCMS: 基于laravel+layui开发完整cms后台,系统主要是志在更快的开发后台,减少代码冗余,所以本cms基本大部分通...-程序员宅基地
- vue ES6 ArrayList转数组(将类数组对象转换为一个真正的数组) Array.from()_vue+object+转+array+array.from-程序员宅基地
- MATLAB获取轮廓图像的轮廓坐标_matlab图像轮廓坐标-程序员宅基地
- UML类图关系(实例加UML图完整例子)_uml类图示例-程序员宅基地
- vscode vue settings.json 代码格式化配置!自定义设置 VSCode代码颜色设置(霸霸看了都说好)_vxcode settings [vue]-程序员宅基地
- i18n实现SpringBoot后端多语言化(前后端分离)_spring boot 多语言-程序员宅基地
- 智能井盖传感器产品介绍,井盖传感器推荐-程序员宅基地
- MongoDB快速上手_mongodb transformby-程序员宅基地