”倒排索引“ 的搜索结果
C++倒排索引
标签: C++ 倒排索引 信息检索
读入文本集,建立倒排索引,内含有的TXT文本可以替换,源代码可以直接运行 读入文本集,建立倒排索引,内含有的TXT文本可以替换,源代码可以直接运行
对所给的Tweets数据集建立倒排索引; 实现Boolean Retrieval Model,使用TREC 2014 test topics进行测试; Boolean Retrieval Model中支持and, or ,not,查询优化可选做;
c++实现倒排索引算法
标签: c++ 索引
c++倒排索引算法
Boolean Retrival(布尔检索) and Posting Lists(倒排索引表)问题描述利用文档和词项的布尔关系建立倒排索引表,根据倒排索引表进行布尔表达式查询.这里只实现AND操作.布尔检索布尔检索模型React了文档和词项集合的...
最简回答:ElasticSearch 的倒排索引是一种将词条和文档ID之间的对应关系反转存储的结构,通过快速定位包含特定词条的文档来提高搜索效率。综上所述,Elasticsearch的倒排索引通过存储词项和文档ID的对应关系以及...
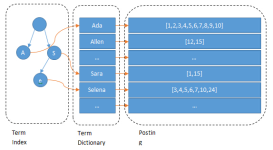
下图是一个相对复杂些的倒排索引,与上图的基本索引系统比,在单词对应的倒排列表中不仅记录了文档编号,还记载了单词频率信息(TF),即这个单词在某个文档中的出现次数,之所以要记录这个信息,是因为词频信息在...

MapReduce操作实例-倒排索引.pdf 学习资料 复习资料 教学资源
在搜索引擎领域,倒排索引是一种核心数据结构,它让搜索引擎能够以极高的效率找到包含用户查询关键词的所有网页。为了理解倒排索引的工作原理,我们可以将其与一种更直观、生活化的例子相比较:书店里的索引卡片系统...
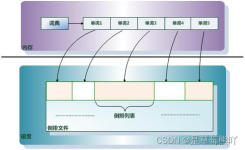
倒排索引主要由两部分组成: 1)单词词典,即每个文档进行分词后的词项在去重后组成的集合; 2)倒排文件是倒排列表持久化存储的结果,通常保存在磁盘等存储设备上。倒排列表记录了词项所在文档的文档列表、单词...
倒排索引还有很多进一步的优化技术,比如索引压缩、布尔匹配排序、聚合查询优化、缓存优化、索引重建优化等,这些技术可以根据实际应用场景的特点进行选择和组合,从而有效提高倒排索引的查询效率和应用效果。...
读取 10 个 .txt 文本构建序列表,排序并输出倒排序列表。 输入两个词,空格隔开,搜索,输出两个词的公有文本。
基于hadoop集群系统(也可以在伪分布式系统上运行)系统使用Java编写的倒排索引实现,具有使用停词表功能,使用正则表达式选择规范的单词。代码重构了setup(),map(),combiner(),partitation()和reducer()函数,...
在信息检索领域中,倒排索引是一种重要的数据结构,被广泛应用于搜索引擎、文本检索系统等场景中。与传统的索引结构不同,倒排索引以词项为单位,记录了每个词项出现在哪些文档中,从而实现了快速的文档检索。...
先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!...
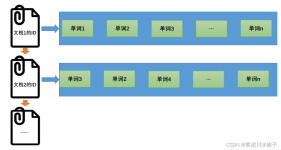
倒排索引 二. 倒排索引原理 1 词语和文档的关系 2 倒排索引的数据结构 3 倒排索引的建立实例 4 倒排索引的更新策略 一. 倒排索引 倒排索引(Inverted Index) 也被称为“反向索引”或“反向文件”,是...
倒排索引 Elasticsearch通过倒排索引的数据结构来实现全文搜索 在关系数据库系统里,索引是检索数据最有效率的方式。但对于搜索引擎,它并不能满足其特殊要求,比如海量数据下比如百度或者谷歌要搜索百亿级的网页,...
大数据实验报告Hadoop编程实现InvertedIndex文档倒排索引程序附源码.doc
需要注意的是,倒排索引的构建和维护是一个相对复杂的过程,涉及到文档的分词、词典的生成、倒排列表的构建以及索引的更新等多个步骤。这个列表包含了所有包含该词项的文档的ID以及词项在文档中的位置信息(如词项...
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对...例如,在数据库系统中,正排索引用于快速访问数据记录,而倒排索引用于实现高效的文本搜索。
基于倒排索引的可验证混淆关键字密文检索方案
什么是倒排索引? 倒排索引(英语:Inverted index),也常被称为反向索引、置入档案或反向档案,是一种索引方法,被用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射。它是文档检索系统中最...

Elasticsearch 中的倒排索引(Inverted Index)是其核心数据结构之一,对实现高效的全文搜索起着关键作用。
过长,效率提高文中提出了一种新的基于倒排索引的多维网络存储模型II-GC(InvertedIndexbasedGraphCube),通过。将图的非线性结构和顶点的多维属性存储在倒排索引列表中的快速查询速度,并在多维网络上进行聚集...
运行说明:在linux终端输入 $ hadoop jar test-1.0-SNAPSHOT.jar WordCount /input/* /MyOutput1/ 后两个参数是hdfs上面【输入】的文本文件目录和【输出】目录。 记得清空输出目录。
推荐文章
- Codeforces-学校排队-程序员宅基地
- 计算机毕业设计ssm基于JAVA的图书馆自习室座位预约系统194fd9 (附源码)轻松不求人_基于ssm的图书馆预约座位-程序员宅基地
- 实值复变函数求导 ——(Wirtinger derivatives)_wirtinger导数-程序员宅基地
- VMWare虚拟机设置固定IP上网方法_vm虚拟机只允许指定ip访问-程序员宅基地
- 深度学习修炼(一)线性分类器 | 权值理解、支撑向量机损失、梯度下降算法通俗理解-程序员宅基地
- 基于SpringBoot的社区团购APP+02043(免费领源码)可做计算机毕业设计JAVA、PHP、爬虫、APP、小程序、C#、C++、python、数据可视化、大数据、全套文案-程序员宅基地
- 如何在无公网IP环境下远程访问Serv-U FTP服务器共享文件-程序员宅基地
- uniapp的navigateTo页面跳转参数传递问题_uni.navigateto刷新携带参数丢失-程序员宅基地
- C++中std::getline()函数的用法-程序员宅基地
- vue 工作中的一些小总结(基础知识供刚入门的小伙伴看 vue+elementUi+vsCode+vue-router+iconfont )_mac+elementui+vscode-程序员宅基地