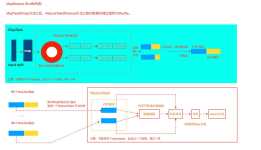
shuffle的机制
标签: shuffle
这里详细的分析了hadoop的shuffle机制,具体步骤等等。
标签: shuffle
这里详细的分析了hadoop的shuffle机制,具体步骤等等。
1、在 Spark 中,不同stage、不同节点上的task 进行数据传递的过程通常称为 Shuffle 机制。Shuffle 解决的是如何将数据进行重新组织,使其能够在上游和下游 task 间进行
标签: spark
Shuffle简介 Shuffle描述着数据从map task输出到reduce task输入的这段过程。shuffle是连接Map和Reduce之间的桥梁,Map的输出要用到Reduce中必须经过shuffle这个环节,shuffle的性能高低直接影响了整个程序的...
将map输出作为输入传递给reducer的过程称为shuffle。 shuffle存在于map和reduce阶段。 map阶段大致过程为: 写数据,分区,排序,将属于同一分区的输出合并一起写在磁盘上。 每个map任务都有一个...
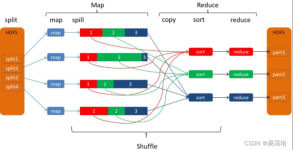
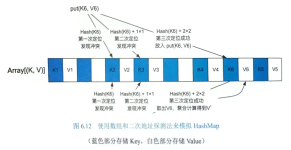

介绍Spark Shuffle机制


带你揭开 Spark shuffle 机制迷雾!
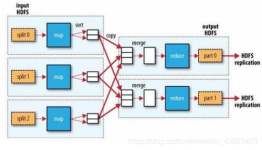
MapReduce 的 Shuffle 机制1、概述2、主要流程3、详细流程4、流程图5、MapReduce 超详细执行流程解读 1、概述 1、MapReduce 中,mapper 阶段处理的数据如何传递给 reducer 阶段,是 MapReduce 框架中最关键的一个...
简述Spark的Shuffle机制----HashShuffle和SortShuffle。
Hadoop生态系统中,Shuffle是MapReduce的核心机制,它肩负了从Map到Reduce的底层过程。 一个切片input split对应一个mapper,mapper将数据写入到环形缓冲区; 这个环形缓冲区默认是100M,当它达到默认阀值80%的时候...
hashshuffle 中的 ...sortshuffle 中的 bypass机制 :https://blog.csdn.net/qichangjian/article/details/88039576 本质上都是为了减少shuffle过程中的性能开销:不排序?减少小文件的个数?减少磁盘IO? ...

1.1 MapReduce的shuffle机制 1.1.1 概述: mapreduce中,map阶段处理的数据如何传递给reduce阶段,是mapreduce框架中最关键的一个流程,这个流程就叫shuffle; shuffle: 洗牌、发牌——(核心机制:数据分区,...
MR中shuffle机制 概述 ●mapreduce中,map阶段处理的数据如何传递给reduce阶段,是mapreduce框架中最关键的一个流程,这个流程就叫shuffle; ●shuffle: 洗牌、发牌——(核心机制:数据分区,排序,缓存) ●具体...
因此少量的最终磁盘文件,也让该机制相对未经优化的HashShuffleManager来说,shuffle read的性能更好。ShuffleManager随着Spark的发展有两种实现的方式,分别为HashShuffleManager和SortShuffleManager,因此spark的...
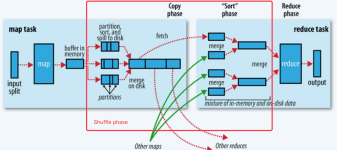
(1)如果 Reduce Task的数量> getPartition的结果数,则会多产生几个空的输出文件part-r-000Xx (2)如果1< ReduceT


标签: 大数据
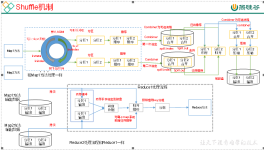
MR之shuffle机制~分区 一、shuffle阶段划分 Map方法之后,Reduce方法之前的处理过程就是shuffle阶段.(sort-copy-sort) 二、shuffle阶段流程分析 相关基础:
在Spark计算平台中,数据倾斜...提出了广播机制避免Shuffle过程数据倾斜的方法,分析了广播变量分发逻辑过程,给出广播变量性能优势分析和该方法的算法实现.通过Broadcast Join实验验证了该方法在性能上有稳定的提升.