”scrapy框架“ 的搜索结果
主要介绍了如何在django中运行scrapy框架,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下
本文我们通过抓取Quotes网站完成了整个Scrapy的简单入门,到此为止我们应该能对Scrapy的基本用法有一个初步的概念了。不过本文内容仅仅是Scrapy所有功能的冰山一角,还有很多内容等待我们去探索,我们后续文章继续...

Scrapy 是一个基于 Twisted 的异步处理框架,是纯 Python 实现的开源爬虫框架,其架构清晰,模块之间的耦合程度低,可扩展性极强,可以灵活完成各种需求。自定义 Item Pipeline 很简单,每个 Item Pipeline 组件都是...
解析Python网络爬虫:核心技术、Scrapy框架、分布式爬虫
最近在各个平台上学习python爬虫技术,林林总总接触到了三大类型的爬虫技术——【1】利用urllib3实现,【2】使用Requests库实现,【3】使用Scrapy框架实现。 虽然是按照以上的顺序进行学习的,但是在学习scrapy的...

主要介绍了Python利用Scrapy框架爬取豆瓣电影,结合实例形式分析了Python使用Scrapy框架爬取豆瓣电影信息的具体操作步骤、实现技巧与相关注意事项,需要的朋友可以参考下
这是一个用python3中的scrapy框架实现爬取京东手机商品信息(手机名称,手机价格,手机图片),存入mysql数据库的案例。
主要介绍了Python爬虫实例——scrapy框架爬取拉勾网招聘信息的相关资料,文中讲解非常细致,代码帮助大家更好的理解和学习,感兴趣的朋友可以了解下
基于python scrapy框架抓取豆瓣影视资料
使用了python非常火的Scrapy框架写的爬虫项目,采用Scrapy自带的异步下载,实现对表情包网站的表情秒下载,相比于我上一个发布的表情包爬虫资源,整整快了100倍
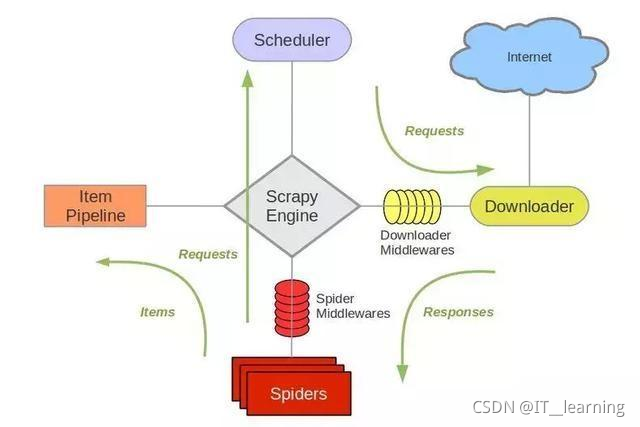
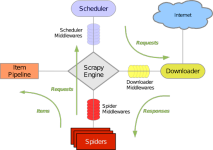
Scrapy框架简介以及构建图 Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。 框架的力量,用户需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容...

请确保前文所讲的代理池、Cookies池已经实现并可以正常运行,安装Scrapy、PyMongo库。首先我们要实现用户的大规模爬取。这里采用的爬取方式是,以微博的几个大V为起始点,爬取他们各自的粉丝和关注列表,然后获取...
简书简介小甲鱼B站教学视频
通过Scrapy,我们可以轻松地完成一个站点爬虫的编写。但如果抓取的站点量非常大,比如爬取各大媒体的新闻信息,多个Spider则可能包含很多重复代码。如果我们将各个站点的Spider的公共部分保留下来,不同的部分提取...
引言:使用pip install 来安装scrapy需要安装大量的依赖库,这里我使用了Anaconda来安装scrapy,安装时只需要一条语句:conda install scrapy即可 步骤1:安装Anaconda,在cmd窗口输入:conda install scrapy ,输入...
主要介绍了python Scrapy框架的相关资料,帮助大家开始学习python 爬虫,感兴趣的朋友可以了解下
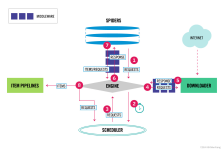
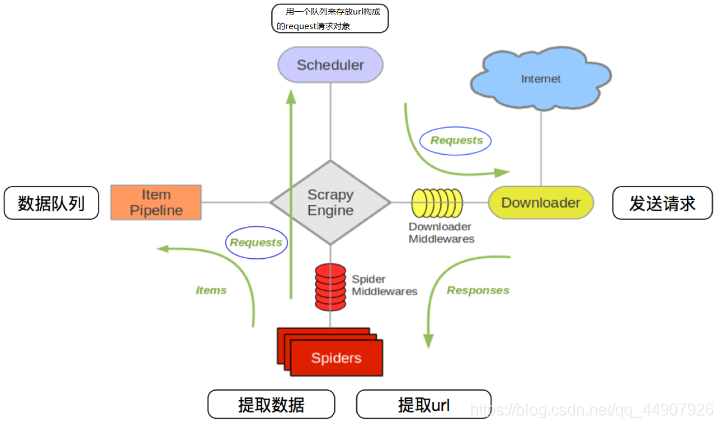
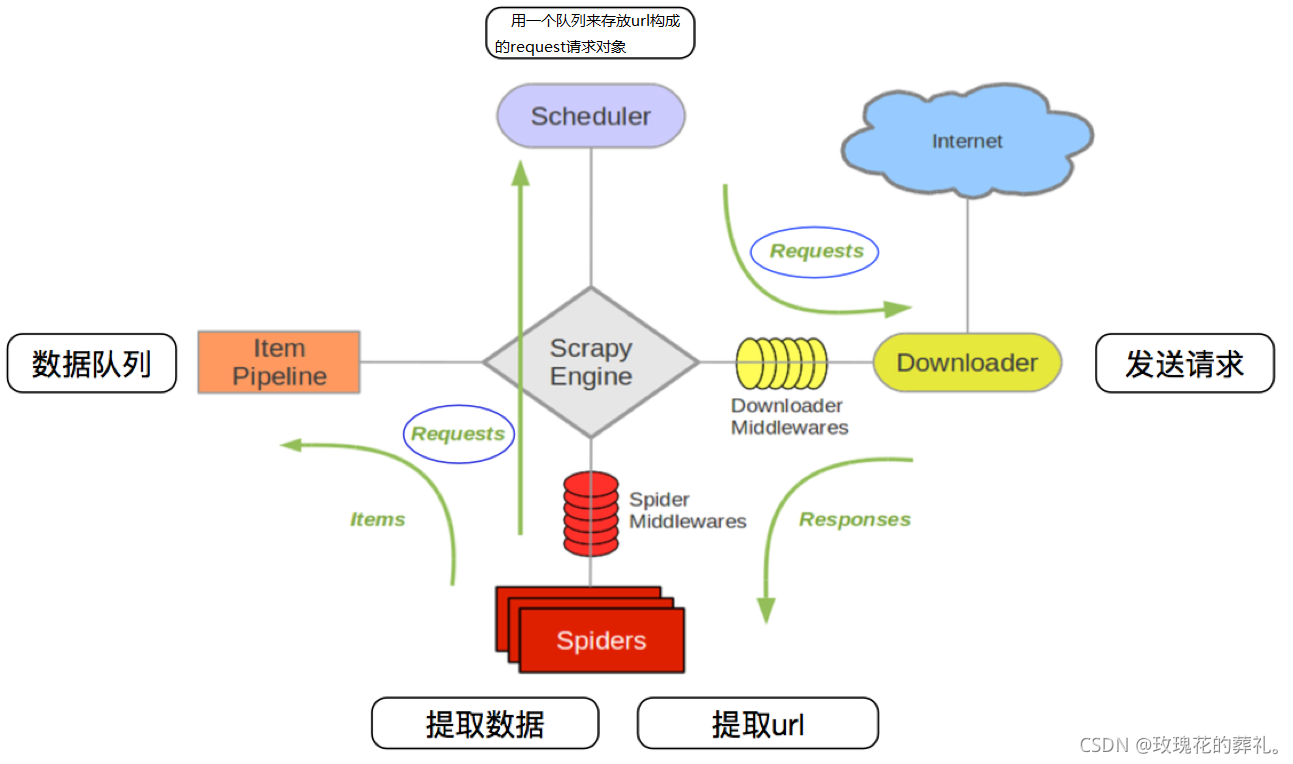
文章目录Scrapy 框架一、 简介1、 介绍2、 环境配置3、 常用命令4、 运行原理4.1 流程图4.2 部件简介4.3 运行流程二、 创建项目1、 修改配置2、 创建一个项目3、 定义数据4、 编写并提取数据5、 存储数据6、 运行...
在本篇内容中我们给大家整理了关于python安装Scrapy框架的图文详细步骤,需要的朋友们跟着学习下。
第一部分爬虫架构介绍 1.Spiders(自己书写的爬虫逻辑,处理url及网页等【spider genspider -t 指定模板 爬虫文件名 域名】),返回Requests给engine——> 2.engine拿到requests返回给scheduler(什么也没做)——> ...
推荐文章
- Codeforces-学校排队-程序员宅基地
- 计算机毕业设计ssm基于JAVA的图书馆自习室座位预约系统194fd9 (附源码)轻松不求人_基于ssm的图书馆预约座位-程序员宅基地
- 实值复变函数求导 ——(Wirtinger derivatives)_wirtinger导数-程序员宅基地
- VMWare虚拟机设置固定IP上网方法_vm虚拟机只允许指定ip访问-程序员宅基地
- 深度学习修炼(一)线性分类器 | 权值理解、支撑向量机损失、梯度下降算法通俗理解-程序员宅基地
- 基于SpringBoot的社区团购APP+02043(免费领源码)可做计算机毕业设计JAVA、PHP、爬虫、APP、小程序、C#、C++、python、数据可视化、大数据、全套文案-程序员宅基地
- 如何在无公网IP环境下远程访问Serv-U FTP服务器共享文件-程序员宅基地
- uniapp的navigateTo页面跳转参数传递问题_uni.navigateto刷新携带参数丢失-程序员宅基地
- C++中std::getline()函数的用法-程序员宅基地
- vue 工作中的一些小总结(基础知识供刚入门的小伙伴看 vue+elementUi+vsCode+vue-router+iconfont )_mac+elementui+vscode-程序员宅基地