本系统采用Scrapy爬虫框架来开发,使用Xpath网页提取技术对下载网页进行内容解析,使用Redis做分布式,使用MongoDB对提取的数据进行存储,使用Django开发可视化界面对爬取的结果进行友好展示,设计并实现了针对链家...
”python—scrapy框架爬虫—链家二手房数据_m0_50360098的博客-程序员宅基地“ 的搜索结果

Scrapy犹如一个爬虫流水线,Item Pipeline是流水线的最后一道工序,但它是可选的,默认关闭,使用时需要将它激活。如果需要,可以定义多个Item Pipeline组件,数据会依次访问每个组件,执行相应的数据处理功
scrapy抓取链家网二手房成交数据
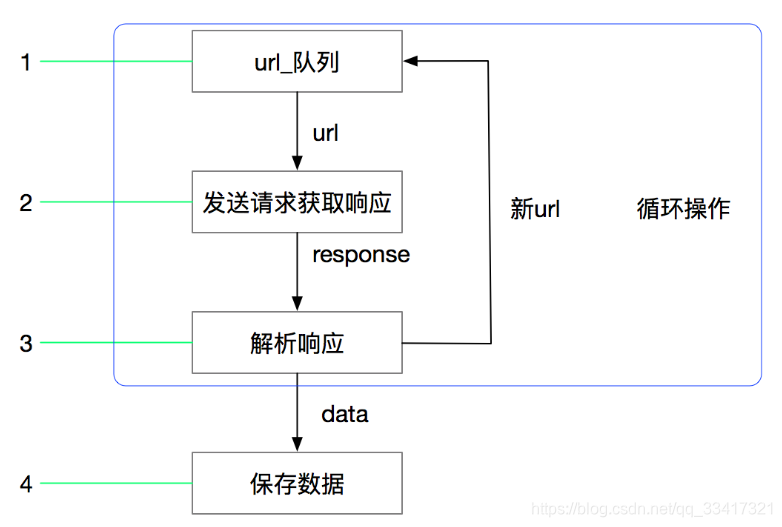


基于Python的scrapy爬虫框架实现爬取招聘网站的信息到数据库
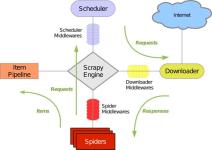
python爬虫 python爬虫_爬虫项目实战之Scrapy抓手机今日头条App数据并存入MongoDB
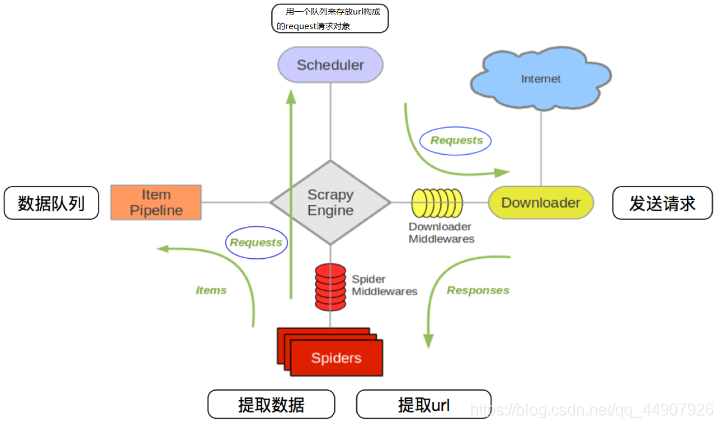
Scrapy 是用 Python 实现的一个为了采集网站数据、提取结构性数据而编写的应用框架。常应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。通常我们可以很简单的通过 Scrapy 框架实现一个爬虫,抓取指定...
BXG-2018-5 8.95GB 高清视频第 一 章:解析python网络爬虫:核心技术、Scrapy框架、分布式爬虫1-1 初识爬虫1-1-1 1.1-爬虫产生背景1-1-2 1.2-什么是网络爬虫1-1-3 1.3-爬虫的用途1-1-4 1.4-爬虫分类1-2 爬虫的实现...
Scrapy 爬虫的数据类型 数据流的出入口(2)1. 实现Python爬虫重要技术路线2. 可用性都好,文档丰富,入门简单3.两者都没有处理js、提交表单、应对验证码等功能(可扩展)(1)进入命令行窗体,在D盘中 建立一个...

Python爬虫之Scrapy框架系列(23)——分布式爬虫scrapy_redis浅实战【XXTop250部分爬取】
之前用过selenium和request爬取数据,但是感觉速度慢,然后看了下scrapy教程,准备用这个框架爬取试一下。 1、目的:通过爬取成都链家的二手房信息,主要包含小区名,小区周边环境,小区楼层以及价格等信息。并且把...
并爬取第1~5页数据中第2条。



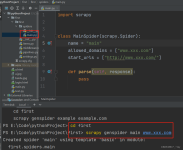

本项目是python课程的期末练手项目,在简要学习完python和爬虫相关的Scrapy框架后,基于这两者的运用最终完成了对于链家网站二手房页面的信息进行爬取,并将爬取的数据存放于MongoDB之中,使用Studio 3T进行查看。...

文章目录Scrapy 框架一、 简介1、 介绍2、 环境配置3、 常用命令4、 运行原理4.1 流程图4.2 部件简介4.3 运行流程二、 创建项目1、 修改配置2、 创建一个项目3、 定义数据4、 编写并提取数据5、 存储数据6、 运行...
Python开源爬虫框架:Scrapy架构分析-为程序员服务[定义].pdf
推荐文章
- python读取raw数据文件_numpy – 使用python打开.raw图像数据-程序员宅基地
- Splunk分布式部署简介_splunk部署-程序员宅基地
- 基于鲸鱼优化算法WOA,哈里斯鹰算法HHO,灰狼算法WOA,算术优化算法AOA实现13类工程优化工程问题求解附matlab代码_aoa-hho算法-程序员宅基地
- FreeMarker(三)简单使用-程序员宅基地
- Qt + Opencv 实现的一个简单文字识别的demo_qt opencv字符识别-程序员宅基地
- CMakeLists.txt demo-程序员宅基地
- docker启动容器报错 Unknown runtime specified nvidia._docker: error response from daemon: unknown runtim-程序员宅基地
- spring cloud feign组件简单使用_"@feignclient(name = \"user-provider\",fallback = -程序员宅基地
- Android心得4.3--SQLite数据库--execSQL()和rawQuery()方法_android sqlite rawquery-程序员宅基地
- Spring MVC 学习笔记 第四章 Spring MVC 模型数据解析_spring mvc模型数据解析笔记-程序员宅基地