
”mapreduce做单词统计“ 的搜索结果

大数据小型项目源码之mapreduce英语单词频次统计,附带所需全部jar包,欢迎下载学习。
单词统计的MapReduce源码,统计多个文本数据集,最终输出每个单词的出现次数,可帮功能扩展修改 Map阶段 采集数据 Combiner阶段 合并数据 Reduce阶段 最终处理,进行排序等自定义操作 每个阶段都会打印对应的数据...
文章目录一、准备数据二、MR的编程规范 一、准备数据 注意:准备的数据的格式必须是文本 编码必须是utf-8无bom! 二、MR的编程规范 MR的编程只需要将自定义的组件和系统默认组件进行组合,组合之后运行即可!...

统计单词个数 创建项目 按下图所示在resources目录下创建文件夹input,在其中提供文件wc.txt: 注意:不要创建output目录,系统会自动创建。否则会报目录已存在的错。wc.txt文件的内容: hello hadoop and hello ...

mapreduce 单词统计 案例 一、Hadoop MapReduce 构思体现在如下的三个方面: 1.如何对付大数据处理:分而治之 2.构建抽象模型:Map 和 Reduce Map: 对一组数据元素进行某种重复式的处理; Reduce: 对 Map 的...
给定一个文本文档,使用MapReduce思想统计出出现频率最高的前三个单词
MapReduce实现单词统计。
理解MapReduce在Hadoop体系结构中的角色,通过该实验后,能设计开发简单的MapReduce程序。 二、实验设备 计算机:CPU四核i7 6700处理器;内存8G; SATA硬盘2TB硬盘; Intel芯片主板;集成声卡、千兆网卡、显卡; 20...
使用的环境如下: VMware虚拟机下CentOS7 hadoop-3.2.0 jdk1.8.0_221 完成hadoop的伪分布式搭建后,就可以执行hadoop自带的WordCount程序来入门了。 先启动hadoop,不然程序时不会成功运行的。...
要求:给定一个文件,统计文本中单词出现的次数 用户编写的程序分为三个部分:Mapper、Reduce和Driver· 1、Mapper阶段 package cn.kgc.map; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop....
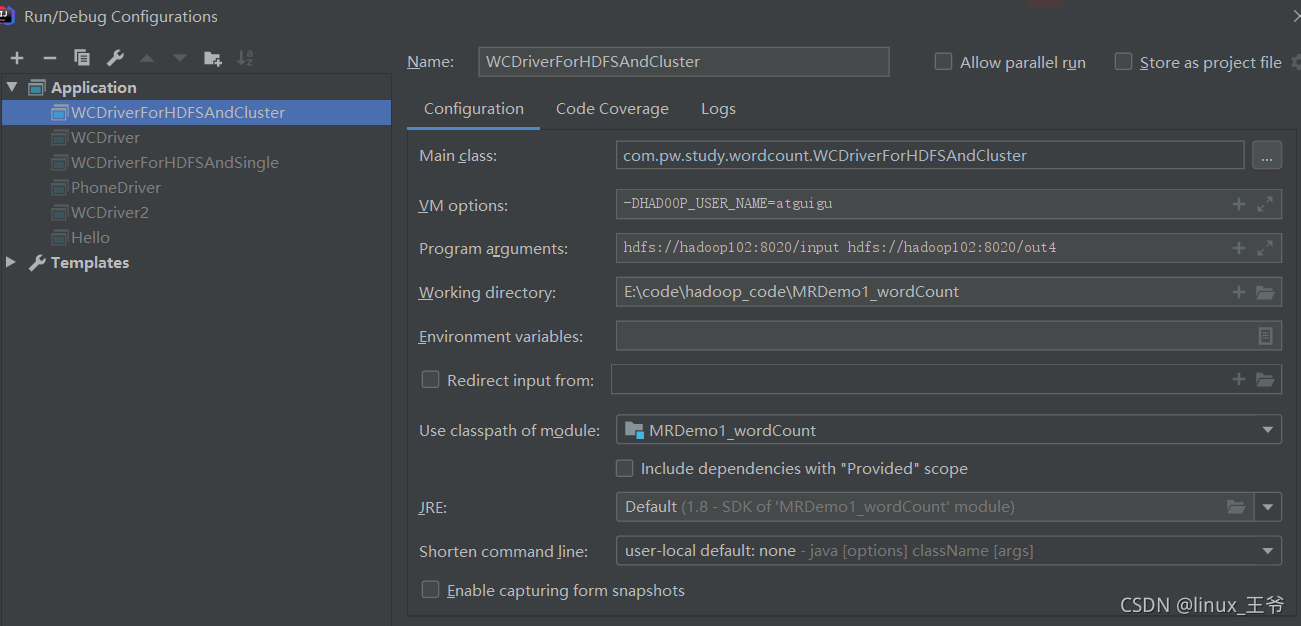
1、统计文件准备1.1 创建需要统计单词的文件1.2 上传到hdfs文件系统上2、创建java项目2.1 配置文件2.2 java代码2.2.1 WordCountMapper 类2.2.2WordCountReducer 类2.2.3 MainClass 类3、参数设置4、运行结果 ...
1、Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster 2、expected org.apache.hadoop.io.Text,recieved org.apache.hadoop.io.LongWritable
Hadoop MapReduce实现单词统计——Wordcount环境:Centos 7系统+IDEA本程序是利用IDEA中的Maven来实现的,主要是因为Maven省去了在本地搭建Hadoop环境的麻烦,只需要在配置文件中进行相应的配置即可。如果你还没有...

MapReduce分布式计算包含两个阶段:Mapper和Reduce。一个完整的MapReduce程序在分布式计算时包括三类实例进程: MrAppMaster:负责整个程序的过程调度及状态协调; MapTask:负责Map阶段整个数据处理流程; ...


或直接将下文的xml的“dependency”中的“version”改为自己的hadoop版本。上传jar文件和input文件夹至liunx的/data/temp。2. 如有/output文件夹,删除。此处以hadoop3.3.4为例。上传input至hdfs。...
单词计数是MapReduce的入门程序,跟编程语言当中的“Hello world”一样。
一、实例描述计算出文件中各个单词的频数,要求输出结果按照单词出现的频数进行降序。 比如,输入文件 file1.txt,其内容如下: hello word bye world file2.txt,其内容如下: hello hadoop goodbye hadoop ...
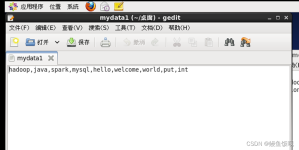
*导入文件count.txt内容为: hadoop,hive,hbase hive,storm hive,hbase,kafka spark,flume,kafka,storm hbase,hadoop,hbase hive,spark,storm 同样代码分为Mapper,Reducer,和运行的Runner Mapper: ...
英语单词频次统计 Map类 package WordCount_01; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; public ...
推荐文章
- Response使用 application/octet-stream 响应到前端_application/octet-stream;charset=utf-8-程序员宅基地
- 利用MultipartFile实现文件上传_实现了multipartfile file上传文件时要选择一个栏目,传给后端一个栏目id,如何实现-程序员宅基地
- muduo之Singleton_muduo singleton-程序员宅基地
- html5 动态存储 localStorage.name 和localStorage.setItem()的差别_localstorage.setitem('aa')和localstorage.aa一样吗-程序员宅基地
- 02.loadrunner之http接口脚本编写_http脚本-程序员宅基地
- The server time zone value ‘�й���ʱ��‘ is unrecognized or represents more than one time zone.-程序员宅基地
- 如何打造企业短视频账号的人设?_做的比较有人格化的公司短视频账号-程序员宅基地
- 一个会做饭的程序员如何每天给女朋友带不同的便当?-程序员宅基地
- PendingIntent重定向:一种针对安卓系统和流行App的通用提权方法——BlackHat EU 2021议题详解 (下)_getrunningservicecontrolpanel-程序员宅基地
- python 之 面向对象(反射、__str__、__del__)-程序员宅基地