springboot集成kafka,@KafkaListener重复消费问题
”kafka“ 的搜索结果
Apache Kafka是一个开源的流式平台,用于处理实时数据流。它可以用于各种用途,包括日志聚合、事件处理、监控等。本文将向您展示如何在Windows操作系统上安装和配置Apache Kafka。
ISR 机制的另外一个相关参数是, 可以在 broker 或者主题级别进行配置,代表 ISR 列表中至少要有几个可用副本。这里假设设置为 2,那么当可用副本数量小于该值时,就认为整个分区处于不可用状态。...
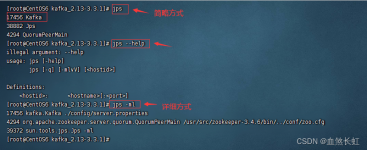
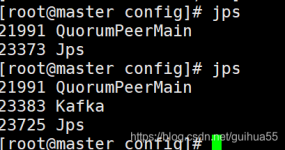
文章目录一、安装 JDK二、安装 zookeeper三、安装 kafka 一、安装 JDK rpm -qa | grep java rpm -qa | grep jdk rpm -qa | grep gcj rpm -qa | grep java | xargs rpm -e --nodeps #卸载老版本 yum list java-1.8*...
支持Oracle、DB2、SQL Server、MySQL、达梦等交易数据库实时数据捕获(日志解析),支持SAP Hana、GreenPlum、...支持实时捕获业务系统变化数据并将其发步到Kafka,也支持从Kafka订阅实时数据并写入数仓或大数据平台。
Kafka消费者组 什么是kafka消费者组消费者组的特性为什么出现消费者组针对Consumer Group,Kafka如何管理位移(offset)?kafka的Rebalance(重平衡)定义触发条件问题 什么是kafka消费者组 kafka消费者组...
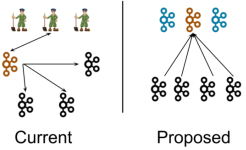
kafka是没有tag等功能的,所以过滤只能在消费端实现。下面直接上代码 代码 配置文件 spring: kafka: bootstrap-servers: 127.0.0.1:9092 # kafka连接接地址 # client-id: # 发送请求时传给服务器的id consumer: ...
kafka操作命令-主题管理
标签: kafka
kafka操作命令-主题管理
kafka是分布式的、基于发布/订阅模式的消息队列。本文使用docker安装 kafka集群

目录 背景 介绍 运行机制 参数 保留参数 log.retention.bytes log.retention.hours log.retention.minutes ...因为在windows环境运行,遭遇了文件重写异常,于是研究了一下kafka的消息保留...
docker安装kafka
场景:kafka发送消息,并且根据消息发送到不同的渠道类型(例如发送到WX,DingDing,邮箱),采取不同的线程池处理 1.引入依赖 <dependency> <groupId>org.springframework.kafka</groupId> ...
kafka发送和接收数据。

centos部署kafka_exporter
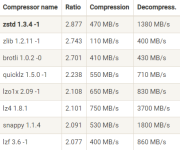
-- kafka--> <dependency> <groupId>org.springframework.kafka</groupId> <artifactId>spring-kafka</artifactId> <version>2.2.14.RELEASE</version>
@KafkaListener(id = "layer_test_consumer", topics = {"${kafka.consumer.topic.layerTestConfig}"}, groupId = "${kafka.consumer.group-id.layerTestConfig}", containerFactory = "batchContainerFactory", ...
kafka,分布式集群架构下,高性能的流式事件数据(主要是消息)集成、发布(生产)和订阅(分发、消费)组件(中间件)。 kafka依赖zooeeper(数据后端),这里有Windows下安装配置启动zookeeper的 文章(1): ...
磁盘爆满后,cd /data/kafka_log/ du -sh *|grep 'G'查看发现dbaudit的topic占用很多,所以通过以下命令进行数据清理。 # 设置删除超过24小时数据清除 ./bin/kafka-configs.sh --zookeeper 10.35.16.252:2181 --...
推荐文章
- NSFuzz:TowardsEfficient and State-Aware Network Service Fuzzing-程序员宅基地
- 刘睿民畅谈大数据:政府应紧急设立首席数据官-程序员宅基地
- nginx 编译安装依赖包_nginx编译怎么添加新的依赖库-程序员宅基地
- Python+OpenCV+Tesseract实现OCR字符识别_python + opencv + tesseract-程序员宅基地
- 微型计算机主板上的主要部件,微型计算机主板上安装的主要部件-程序员宅基地
- 推荐一款可匹敌国际大厂的国产企业级低无代码平台_国产私有化 无代码-程序员宅基地
- UE4 蓝图 实现 数组的边遍历边删除_ue4 数组删不掉-程序员宅基地
- python爬虫之bs4解析和xpath解析_from bs4 import beautifulsoup xpath-程序员宅基地
- MySQL配置环境变量-程序员宅基地
- VGG16进行微调,训练mnist数据集_vgg16 tensorflow 2 mnist-程序员宅基地