”hive使用“ 的搜索结果
1.Hive如何显示当前数据库 2.根据需求设置是否需要执行MR 3.如何正确启动Hive
目录 1 Hive 概念与连接使用: 2 2 Hive支持的数据类型: 2 2.1原子数据类型: 2 2.2复杂数据类型: 2 2.3 Hive类型转换: 3 3 Hive创建/删除数据库 3 3.1创建数据库: 3 ...12 Hive使用注意点: 6 13 Hive优化 9
Hive基础和使用详解

Hive详细介绍及简单应用
标签: hive
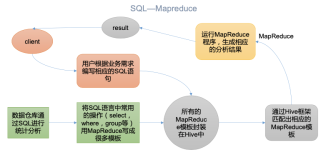
1.1.2为什么使用Hive 1.)直接使用hadoop所面临的问题 人员学习成本太高 项目周期要求太短 MapReduce实现复杂查询逻辑开发难度太大 2.) 操作接口采用类SQL语法,提供快速开发的能力。 避免了去写MapReduce,...
这也是在Hadoop上使用诸如Hive之类的工具构建数据库会成为一个功能强大的解决方案的原因。如果一家公司没有资源构建一个复杂的大数据分析平台,该怎么办?当业务智能(BI)、数据仓库和分析工具无法连接到ApacheHadoop...
Hive是一个基于Apache Hadoop的数据仓库。对于数据存储与处理,Hadoop提供了主要的扩展和容错能力。 Hive设计的初衷是:对于大量的数据,使得数据汇总,查询和分析更加简单。它提供了SQL,允许用户更加简单地进行...
在大数据的发展当中,大数据技术生态的组件,也在不断地拓展开来,而其中的Hive组件,作为Hadoop的数据仓库工具,可以实现对Hadoop集群当中的大规模数据进行相应的数据处理。今天我们的大数据入门分享,就主要来讲讲...
使用方式共三种 第一种交互方式:Hive交互...//在设置hive全局环境变量之后可以在任何目录使用hive 查看所有的数据库 hive (default)> show databases; 创建数据库 hive (default)> create database myh...
使用spark引擎查询hive有以下几种方式: 1>使用spark-sql(spark sql cli) 2>使用spark-thrift提交查询sql 3>使用hive on spark(即hive本身设置执行引擎为spark) 针对第一种情况: 1>ambari 已经支持,不...
在使用HDP Hadoop版本时,Ambari界面允许选择Hive执行引擎是MapReduce还是TEZ,如下图所示 使用TEZ作为Hive执行引擎来替代MapReduce,可以在很多场景上实现更好的效率提高,然后使用TEZ作为默认引擎也会导致一些...
创建一个map类型字段 create table test3(field2 map<string,string>) row format delimited fields terminated by ',' collection items terminated by "|" map keys terminated by ":";...
可知date在SQL语言中为关键字,用为字段名时,无法直接使用,需要加上倒引号,才可识别,在建表时也需加倒引号进行使用。
hive的使用及基本操作完整版
标签: hive
安装mysql、hive步骤 一、什么是hive Hive是基于Hadoop的一个数据仓库工具(离线),可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。 操作接口采用类SQL语法,提供快速开发的能力, 避免了去写...
往hive分区表中插入数据时,如果需要创建的分区很多,比如以表中某个字段进行分区存储,则需要复制粘贴修改很多sql去执行,效率低。因为hive是批处理系统,所以hive提供了一个动态分区功能,其可以基于查询参数的...
问题如下,进入hive之后使用show databases报错 hive> show databases; FAILED: SemanticException org.apache.hadoop.hive.ql.metadata.HiveException: java.lang.RuntimeException: Unable to instantiate org....
【hive创建动态分区】hive使用动态分区插入数据详解 往hive分区表中插入数据时,如果需要创建的分区很多,比如以表中某个字段进行分区存储,则需要复制粘贴修改很多sql去执行,效率低。因为hive是批处理系统,所以...
The Apache Hive ™ data warehouse software facilitates reading, writing, and managing large datasets residing in distributed storage using SQL. Structure can be projected onto data already in storage....
hive使用本地模式
zeppelin环境搭建及连接hive使用一、准备工作1.zepeelin简介2.安装包下载3.环境要求二、解压安装三、修改配置文件1.修改配置文件zeppelin-site.xml2.修改zeppelin的环境文件四、启动zepeelin五、配置hive解释器1....
hive 也是支持jdbc 连接的这样操作起来就会方便很多 毕竟可以在客户端直接些sql 不多说 首先 需要启动hive server 的server2 服务 bin/hive --service hiveserver2 &amp; 下面就是编写客户端了 提供pom 依赖 &...
使用beeline连接hive两种方式 1、启动hiveserver2 #进入hive安装目录 cd /usr/local/hive目录 #启动hive2目录 bin/hive --service hiveserver2 2、克隆会话启动beeline #进入hive安装目录 cd /usr/local/hive...
解决:一般存在MapJoin,设置参数set hive.auto.convert.join = false转成reduce端的Common Join。 shuffle阶段 解决:减少每个reduce处理的数据量,调整参数:hive.exec.reducers.bytes.per.reducer,默认300000000...

hive是基于Hadoop构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop分布式文件系统中的数据:可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能;可以将SQL语句转换为...
在Hive中使用变量 调用shell变量 # 在shell中定义变量 tablename="student" varsubject="Math" # 使用 hive -e 调用变量 hive -e "SELECT * FROM ${tablename} WHERE subjects = ${varsubject};" 调用Hive配置...
-- 假设给定的时间戳是UTC并转换为给定的时区(从Hive 0.8.0开始)UTC 默认时区 转为 GMT+8 上海时区 SELECT from_utc_timestamp(CURRENT_TIMESTAMP,'GMT+8') from_utc -- 假设给定时间戳在给定时区内并转换为UTC...
推荐文章
- NSFuzz:TowardsEfficient and State-Aware Network Service Fuzzing-程序员宅基地
- 刘睿民畅谈大数据:政府应紧急设立首席数据官-程序员宅基地
- nginx 编译安装依赖包_nginx编译怎么添加新的依赖库-程序员宅基地
- Python+OpenCV+Tesseract实现OCR字符识别_python + opencv + tesseract-程序员宅基地
- 微型计算机主板上的主要部件,微型计算机主板上安装的主要部件-程序员宅基地
- 推荐一款可匹敌国际大厂的国产企业级低无代码平台_国产私有化 无代码-程序员宅基地
- UE4 蓝图 实现 数组的边遍历边删除_ue4 数组删不掉-程序员宅基地
- python爬虫之bs4解析和xpath解析_from bs4 import beautifulsoup xpath-程序员宅基地
- MySQL配置环境变量-程序员宅基地
- VGG16进行微调,训练mnist数据集_vgg16 tensorflow 2 mnist-程序员宅基地