目录1 Job执行三原则1.1 原则一 充分利用集群资源1.2 原则二 ReduceTask并发调整1.3 原则三 Task执行时间要合理2 Shuffle调优2.1 Map阶段2.2 Copy阶段2.3 Reduce阶段3 Job调优 1 Job执行三原则 充分利用集群资源 ...
”hadoop调优“ 的搜索结果
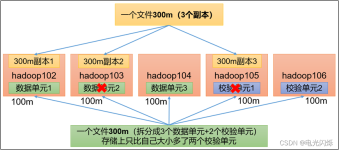
TIPS:设置HDFS的文件副本数,默认为3,当许多任务同时读取一个文件时,读取可能会造成瓶颈,增大副本数可以有效缓解,但也会造成大量的磁盘空间占用,这时可以只修改Hadoop客户端的配置,从Hadoop客户端上传的文件的...
hadoop调优参数列表
以下修改的配置文件均在目录下一、Hadoop入门 1 、常用端口号hadoop3.xHDFS NameNode 内部通常端口:8020/9000/9820HDFS NameNode 对用户的查询端口:9870Yarn查看任务运行情况的:8088历史服务器:19888hadoop2.x...
hadoop调优参数列表.
标签: hadoop
hadoop调优参数列表.hadoop调优参数列表.hadoop调优参数列表.


Hadoop 常用调优手段
前言 本文隶属于专栏《1000个问题搞定大数据技术体系》,该专栏为笔者原创,引用请...下表给出了在 Hadoop 生产集群中推荐使用的 Linux 内核参数配置。 Linux 内核参数配置 参数说明 fs.file-mx=6815744 文件描
Hadoop调优之操作系统调优与JVM 调优.pdf

hadoop调优指南
hadoop调优及常用调优参数 MapReduce跑的慢的原因 MapReduce程序效率的瓶颈在于两点: 1.计算机性能 cpu,内存,磁盘健康,网络 2.I/O操作优化 数据倾斜 Map和Reduce数设置不合理 Map运行时间过长,导致Reduce等待过久 ...


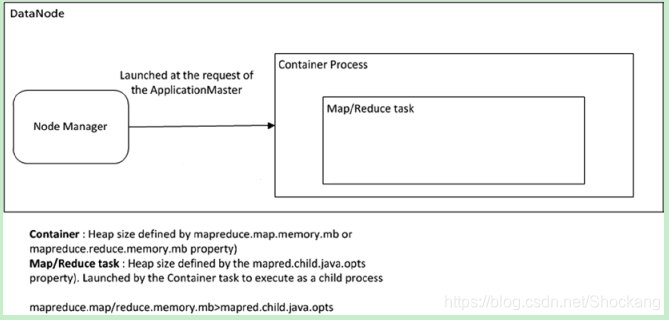
Hadoop调优之调度算法详解一,大数据开发的基本语法在这里。
Hadoop调优策略
标签: Hadoop调优策略
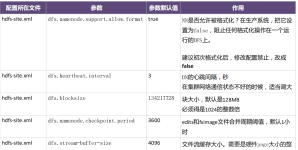
4.小文件归档 * HDFS存储小文件的弊端 每个文件均按块存储,每个块的元数据存储在 NameNode 的内存中,因此 HDFS 存储小文件会非常低效。因为大量的小文件会占用 NameNode 中的大部分内存。但注意,存储小文件所需要...

Hadoop综合调优
标签: hadoop
Hadoop 小文件优化方法 Hadoop小文件弊端 HDFS 上每个文件都要在 NameNode 上创建对应的元数据,这个元数据的大小约为150byte,这样当小文件比较多的时候,就会产生很多的元数据文件,一方面会大量占用NameNode 的...
Hadoop 调优之 Linux 操作系统调优篇 Hadoop 调优之 MapReduce 调优篇 Hadoop 调优之 YARN 调优篇 Hive 如何进行企业级调优? 正文 1. hdfs-site.xml <propertv> <name>dfs.block.si
Hadoop 调优之 Linux 操作系统调优篇 Hadoop 调优之 HDFS 调优篇 Hadoop 调优之 YARN 调优篇 Hive 如何进行企业级调优? 正文 使用 Hadoop 进行大数据运算,当数据量极大时,那么对 MapReduce 性能的调优重要性...
Hadoop调优 mapred.tasktracker.map.tasks.maximum 官方解释:The maximum number of map tasks that will be runsimultaneously by a task tracker. 我的理解:一个tasktracker最多可以同时运行的map任务...
hadoop调优 MR优化 数据输入 合并小文件 除了CombinTextInputFormat还有什么方法合并? 使用CombinTextInputFormat合并小文件 Map阶段 减少溢写(spill)次数 减少合并(merge)次数 不影响业务需求下,使用...
Hadoop参数调优 性能调优涉及4个方面:CPU利用率、内存占用情况、磁盘I/O和网络流量。 有很多因素会对HadoopMapReduce性能产生影响。一般说来,与工作负载相关的Hadoop性能优化需要关注以下3个主要方面:系统硬件...
推荐文章
- SMT的基本知识介绍_smt行业基础知识-程序员宅基地
- 43.基于SSM的口腔护理网站|基于SSM框架+ Mysql+Java设计与实现(可运行源码+数据库+lw)-程序员宅基地
- HTML中Table表格的使用与漂亮的表格模板_html table 样式-程序员宅基地
- Linkage Mapper中的局部和全局地图比较实践指南(含实例分析)-程序员宅基地
- 线性筛求欧拉函数-程序员宅基地
- 初中几何题_初中几何题解-程序员宅基地
- jQuery 放大镜效果_jquery放大效果-程序员宅基地
- Python构建快速高效的中文文字识别OCR_中文ocr python-程序员宅基地
- SQL语句用case when实现if-else条件逻辑_case when里面可以加if else吗-程序员宅基地
- 数据结构实验课程设计报告求工程的最短完成时间_(1)用字符文件提供数据建立aoe网络邻接表存储结构; (2)编写程序,实现图中顶点的-程序员宅基地