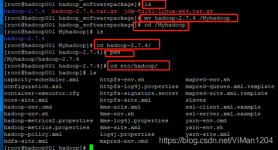
先说点小知识 hadoop fs 使用面最广,可以操作任何文件系统 hadoop dfs和hdfs dfs只能操作HDFS相关的 在上一篇博客中,我们已经...root@guo:/opt/Hadoop/hadoop-2.7.2# hdfs dfs -mkdir /data/input root@guo:/opt/Hado
”hadoop测试wordcount出现的问题_zxc843231635的博客-程序员宅基地“ 的搜索结果
一、结论 先说结论。最后问题解决了。终于能在windows的eclipse上通过执行wordcount类,然后将某个文档内容处理后,将结果传到远程服务器的hadoop的...而且已经在linux服务器上测试过hadoop2.8自带的wordcount的jar

#!/usr/bin/env bash # Licensed to the Apache Software Foundation (ASF) under one or more # contributor license agreements. See the NOTICE file distributed with # this work for additional information
hadoop jar命令调用的java类地址 #hadoop jar 短命令格式 hadoop jar 要执行的jar包 要执行的任务名 输入目录 输出...hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar
hadoop的安装文件,linux下使用
Hadoop_MapReduce_Shuffle工作原理 Shuffle 是连接 Mapper 和 Reducer 之间的桥梁,Mapper的输出结果必须经过Shuffle环节才能传递给Reducer Shuffle分为Map阶段的数据准备和Reducer阶段的数据拷贝。 Shuffle核心机制...
项目场景: 环境:Ubuntu 20.04.1 ...其次确认Hadoop中的/usr/local/hadoop/etc/hadoop/hadoop-env.sh 文件中Java环境变量是否与系统中的Java环境变量相同 按E,进入编辑模式 果然与问题所致的路径相同,问题所
大数据_05 【hadoop HDFS】01 Hadoop组成02 Hadoop的文件系统介绍03 HDFS分块存储05 HDFS副本机制 01 Hadoop组成 Hadoop HDFS:一个高可靠、高吞吐量的分布式文件系统,对海量数据的存储。 Hadoop MapReduce:一个...
主体转自:http://blog.sina.com.cn/s/blog_3d9e90ad0102wqrp.html (未亲测,我的getconf LONG_BIT返回32,且file libhadoop.so.1.0.0返回64,与之相反)Hadoop的本地库(Native Libraries)介绍Hadoop是使用Java...
1、WordCount代码 package com.test; import java.io.IOException; import java.net.URI; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs....
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试。其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式。至于为什么先写单机的搭建,是因为作为个人...
四、WordCount.java测试1、测试准备wordcount.java程序是用来统计词频的,因此这里需要先建好输入文件。/test/input/ 但是发现从eclipse上传到hdfs中的文件大小始终都为0尝试使用hadoop shell的方式来创建文件。 ...
下面介绍一下mapred-site.xml配置文件的配置过程: 增加mapreduce配置(使用yarn框架、jobhistory使用地址以及web地址) <configuration> <property> <name>mapreduce.framework.name<...
首先要说明的是运行Hadoop需要jdk1.6或以上版本,如果你还没有搭建好Hadoop集群,请参考我的另一篇文章:
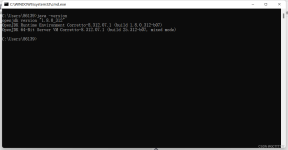
Please update F:\hadoop\conf\hadoop-env.cmd错误如下图 如果你的JAVA_HOME环境变量配置也没问题,在控制台中输入java -version得到如下输出则说明没问题: 打开E:\hadoop-2.7.3\etc\h
在你解压的hadoop文件中的sbin文件中 vi进去并编辑start-dfs.sh与stop-dfs.sh HDFS_DATANODE_USER=root HADOOP_SECURE_DN_USER=hdfs HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root vi进去并编辑start...



本文介绍hadoop HA环境部署。本文分为三部分,即HA集群规划、HA集群部署和HA集群验证前提依赖:1、前提是zookeeper已经部署好,其服务器部署在server1、server2、server3上,且能正常运行2、ssh免登录已完成配置,且...
今天跑了一下hadoop自带的wordcount 遇到了如下问题 我的配置是 VMware上hadoop的伪分布式安装 也就是map0%,reduce0%问题,网上的博客都翻了个遍,几乎都是修改yarn-site.xmal文件的各种配置,说是内存不足,资源...
Please set $HADOOP_COMMON_HOME to the root of your Hadoop installation. 根据错误提示缺少的hadoop安装路径配置,需修改sqoop配置文件。 解决: 1.进入sqoop下的conf配置文件目录, 复制 sqoo...
编写实际生产用的hadoop mapreduce程序的时候,通常都会引用第三方库,也就会碰到ClassPath的问题,主要是两种情况: 找不到类ClassNotFound 库的加载顺序不对,就是第三库引用了一个比较通用的库,比如jackson-core...
推荐文章
- vuex中state对象会数组中的值更新后getters没有监听到state数据的改变的问题state数据跟新页面不刷新问题_vue对象数组改变元素没有getter-程序员宅基地
- 《Centos7——手动部署prometheus》_prometheus centos7-程序员宅基地
- iOS 数据保存几种方式总结_苹果ld都会保留那些数据-程序员宅基地
- quartus生成qdb文件_quartus 生成qxp和vqm文件的方法-程序员宅基地
- Servlet学习笔记3,及回忆。_attributeadded(servletrequestattributeevent ev)方法的-程序员宅基地
- cv::putText详解-程序员宅基地
- tomcat优化_tomcat ajp端口干嘛用的 关闭会怎么样-程序员宅基地
- (UVA)11916 Emoogle Grid-程序员宅基地
- 指针_定义一个指针变量他的值是多少-程序员宅基地
- 《Java基础——异常的捕获与抛出》_java捕获异常和抛出异常-程序员宅基地