正则化的目的在于提高模型在未知测试数据上的泛化力,避免参数过拟合。...以我们之前在线性回归器一节中介绍过的最小二乘优化目标为例,如果加入对模型的L1范数正则化,那么新的线性回归目标如下...
”Python机器学习及实践——进阶篇4(模型正则化之L1正则“ 的搜索结果
Python机器学习及实践——进阶篇:模型实用技巧(模型正则化) 任何机器学习模型在训练集上的性能表现,都不能作为其对未知测试数据预测能力的评估。 1. 欠拟合与过拟合 所谓拟合,是指机器学习模型在训练的过程...
一、L2范数正则化 二、L1范数正则化 三、L0范数正则化 四、dropout正则化 五、Early stopping 六、数据扩增
机器学习和深度学习进阶之路 机器学习 分类 随机森林 Logistic回归 AdaBoost 回归 树回归 SVR 聚类 Apriori FP-growth 降维 SVD(奇异值分解) 深度学习 神经网络 卷积神经网络实现 循环神经网络实现 常用Trick L1...
python机器学习——正则化
标签: 机器学习
范数正则化理论及具体案例操作1、正则化(1)什么是正则化(2)为什么要进行正则化(3)正则化原理2、范数(1)L0 范数(2)L1 范数参考文献 1、正则化 (1)什么是正则化 正则化( Regularization )就是对最小化...
《机器学习:公式推导与代码实践》鲁伟著读书笔记。 回归模型拓展 对于回归模型来说,目标变量有许多影响因素。但是这么多影响因素之中,总有少数关键因素对目标变量的变化起着重要的影响。面对过多影响因素的回归...
网络正则化权重衰减提前停止 高神经网络的泛化能力反而成为影响模型能力的最 关键因素. 参见第2.8.1节. ...(Over-Parameterization)时,ℓ1 和ℓ2 正则化的效果往往不如浅层机器学习模型 中显著. 过度参
回归模型一般分为:①线性回归——就是线性方程,类似为一元一次方程(y=wx+b),比如你的年龄; ②逻辑回归(类似为曲线方程) 线性回归 先来详细的学习下线性回归,线性回归就是回归模型中最简单的,就像一元...
它通过最小化误差的平方和寻找数据的最佳函数匹配。利用最小二乘法可以简便地求得未知的数据,并使得这些求得的数据与实际数据之间误差的平方和为最小。最小二乘法还可用于曲线拟合,其他一些优化问题也可通过最小化...

正则化(Regularization)是机器学习中一种常用的技术,其主要目的是控制模型复杂度,减小过拟合。 最基本的正则化方法是在原目标(代价)函数 中添加惩罚项,对复杂度高的模型进行“惩罚”。 数学表达式: 式中 、...
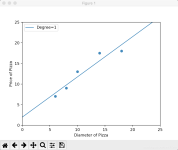
(1)L1 范数正则化—— Lasso 模型在 4 次多项式特征上的拟合表现 # 输入训练样本的特征以及目标值,分别存储在变量 X_train 与 y_train 之中 X_train = [[6], [8], [10], [14], [18]] y_train = [[7], [9], [13], ...
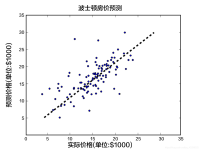
2.1.1 分类学习 2.1.1.1 线性分类器(Linear Classifier) 数据下载:导入pandas,numpy包,创建特征列表,使用pandas.read_csv读取数据 #数据描述:原始数据样本由699条样本,每个样本有11列不同的数值,1列用于...


本文主要向大家介绍了机器学习入门之机器学习之路: python线性回归 过拟合 L1与L2正则化,通过具体的内容向大家展现,希望对大家学习机器学习入门有所帮助。正则化:提高模型在未知数据上的泛化能力避免参数过拟合...
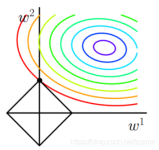
经验风险和结构风险在机器学习任务中,常用损失函数(loss function)来衡量模型输出值和真实值Y之间的差异,如下面定义的损失函数:若数据是服从联合分布,则其损失函数的期望值为,也称为模型的真实风险,记作。...
模型正则化(Regularization),对学习算法的修改,限制参数的大小,减少泛化误差而不是训练误差。 在使用比较复杂的模型,去拟合数据时,很容易出现过拟合现象(训练集表现很好,测试集表现较差),这...
同时,正则化方法可以有效减少模型复杂程度,避免过拟合的情况,提高模型的泛化能力。在机器学习中,无论是线性模型还是非线性模型,我们需要选择合适的优化方法以获得最优的模型参数。常用的梯度下降法是优化模型...
正则化技术,让你的模型不再“任性”过拟合!

和岭回归一样,套索回归也会将系数限制在非常接近0的范围内,但是它限制的方式稍微有些不同,我们称之为L1正则化。与L2正则化不同的是,L1正则化会导致在使用套索回归的时候,有一部分特征的系数会正好等于0.也就是...
使用机器学习方法解决实际问题时,我们通常要用L1或L2范数做正则化(regularization),从而限制权值大小,减少过拟合风险,故其又称为权重衰减。特别是在使用梯度下降来做目标函数优化时。 L1和L2的区别 在机器...

文章目录正则化1、过拟合问题2、正则化2.1正则化原理2.2L2正则化线性回归2.3L2正则化逻辑回归3、sklearn实现L2正则化 正则化 1、过拟合问题 什么是过拟合?顾名思义,过度拟合,对训练集的学习过于充分,以至于一些...
推荐文章
- ps play服务器没有响应mac,【攻略技巧】人在外心在家 教你用PC/MAC远程打PS4-程序员宅基地
- PHP实现在数据库百万条数据中随机获取几条记录的方法_海量数据随机查询-程序员宅基地
- 基于CC2530的停车场系统_基于cc2530课程设计项目免费-程序员宅基地
- oracle求非偶非素数的和,每个大于的2偶数都是2个素数之和,(无素数定理)-程序员宅基地
- 有了它们,我把所有截图、录 GIF、录屏软件都卸了-程序员宅基地
- 170402网摘题目-程序员宅基地
- 安装paddlespeech报错ERROR: Could not build wheels for webrtcvad_could not build wheels for webrtcvad, which is req-程序员宅基地
- C# 将多个图片合并成TIFF文件的两种方法-程序员宅基地
- 基于springboot+vue.js的中山社区医疗综合服务平台附带文章和源代码设计说明文档ppt-程序员宅基地
- 【代码超详解 · 附参考模板】洛谷 P1226 【模板】快速幂||取余运算_洛谷批改代码系统如何实现-程序员宅基地