flink生产环境参数配置
标签: flink
1.flink生产环境目前的配置 jobmanager.rpc.address dqapp121076 io.tmp.dirs /data12/tmp web.tmpdir /data12/tmp fs.hdfs.hadoopconf /etc/hadoop/conf web.upload.dir /data12/tmp/upload ...
标签: flink
1.flink生产环境目前的配置 jobmanager.rpc.address dqapp121076 io.tmp.dirs /data12/tmp web.tmpdir /data12/tmp fs.hdfs.hadoopconf /etc/hadoop/conf web.upload.dir /data12/tmp/upload ...
目录flink的三种运行模式单机模式分布式on yarn环境准备下载flinkflink配置启动测试 flink的三种运行模式 单机模式 分布式 on yarn 环境准备 下载flink 下载地址:...
为提供 Java/Scala 的自定义函数,你首先需要实现和编译函数类,该函数继承自 ScalarFunction、 AggregateFunction 或 TableFunction(19、Flink 的table api与sql之内置函数: Table API 和 SQL 中的内置函数一个或...

本文详细的介绍了flink的Standalone独立集群模式和Standalone HA集群模式的部署、提交任务与验证,同时介绍了Flink on yarn的两种运行模式。在部署该集群前,zookeeper集群已经部署好了,其三台服务器为server1、...
运行模式是 flink-on-yarn per-job模式,每个任务有独立的yarn session,启动任务的方式是CLI方式。所以我们任务启动命令像是这样:flink run -ynm your_jobName -yn 7 -ys 2 -p 14 -ytm 2048m -yjm 2048m -m yarn-...

根据下列文章,即可成功启动,这里偷懒直接参考下面这篇就好 https://blog.csdn.net/xinxin6193/article/details/112347736
akka.ask.timeout:用于异步futures和阻塞调用Akka的超时,如果flink因为超时而失败,则可以尝试增加此值,超时可能是由于机器速度慢或网络拥挤造成的。超时值需要时间单位说明符(ms/s/min/h/d)。源码默认值:10s...
很多时候,我们在IDE中编写Flink代码,我们希望能够查看到Web UI,从而来了解Flink程序的运行情况。按照以下步骤操作即可,亲测有效。...flink-runtime-web_2.11</artifactId> <version>1.9.0&...
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: ...
Flink KafkaSource常用调优 1、Kafka动态分区发现 该参数表示间隔多久检测一次是否有新创建的 partition。默认值是Long的最小值,表示不开启,大于0表示开启。 properties.setProperty(FlinkKafkaConsumerBase.KEY_...
RocksDB是Flink中用于持久化状态的默认后端,它提供了高性能和可靠的状态存储。然而,当处理大型状态并频繁读写时,可能会导致背压问题,因为RocksDB需要从磁盘读取和写入数据,而这可能成为瓶颈。
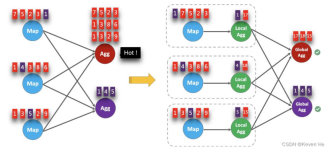
KafkaSource调优 动态发现分区 当 FlinkKafkaConsumer 初始化时,每个 subtask 会订阅一批 partition,但是当 Flink 任务运行过程中,如果被订阅的 topic 创建了新的 partition,FlinkKafkaConsumer 如何实现动态...

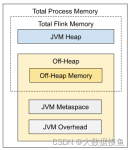
jvm设置 ...堆设置 -Xms :初始堆大小 ...如:为3,表示年轻代与年老代比值为1:3,年轻代占整个年轻代年老代和的1/4 -XX:SurvivorRatio=n :年轻代中Eden区与两个Survivor区的比值。注意Survivor区有两个。如:3,表
Postgres的CDC源表(即Postgres的流式源表)用于依次读取PostgreSQL数据库全量快照数据和变更数据,保证不多读也不少读一条数据。即使发生故障,也能采用ExactlyOnce方式处理。idINT,PRIMARYKEY(`id`)NOTENFORCED--...
本部分介绍Flink的部署、配置相关基础内容。2、Flink基础系列 本部分介绍Flink 的基础部分,比如术语、架构、编程模型、编程指南、基本的datastream api用法、四大基石等内容。3、Flik Table API和SQL基础系列 本...
1. 前言Flink是批流一体化的数据处理框架,性能卓越,诸多大厂都在使用。由于时间原因,本篇文章只简单了解一下,后续会深入分析,以及经典case分享。2. 安装pyflink安装虚拟环境和pyflink$ conda create -n py36 ...
常见错误集 1.Checkpoint失败:Checkpoint expired before completing env.enableCheckpointing(1000L) val checkpointConf = env.getCheckpointConfig checkpointConf.setMinPauseBetweenCheckp...
Flink 中的每个方法或算子都能够是有状态的(Flink(八)Flink四大基石之State概念、使用场景、持久化、批处理的详解与keyed state和operator state、broadcast state使用和详细示例了解更多)。状态化的方法在处理...
1. Flink类加载机制 Flink采用不同于Java默认的类加载机制,而是采用两个类加载器的层级结构 Java应用程序加载器 AppClassLoader,加载类路径中包含的所有类 用户代码类加载器 FlinkUserCodeClassLoader,用于...
flink的23种算子,window join ,interval join,数据倾斜,数据分区

几乎所有的 Flink 应用程序,包括批处理和流处理,都依赖于外部配置参数,这些参数被用来指定输入和输出源(如路径或者地址),系统参数(并发数,运行时配置)和应用程序的可配参数(通常用在自定义函数中)。 Flink ...
Flink CDC有两种实现方式,一种是DataStream,另一种是FlinkSQL方式。 DataStream方式:优点是可以应用于多库多表,缺点是需要自定义反序列化器(灵活) FlinkSQL方式:优点是不需要自定义反序列化器,缺点是只能...