损失函数——交叉熵损失函数_bp神经网络交叉熵loss曲线图-程序员宅基地
交叉熵代价函数(Cross-entropy cost function)是用来衡量人工神经网络(ANN)的预测值与实际值的一种方式。与二次代价函数相比,它能更有效地促进ANN的训练。在介绍交叉熵代价函数之前,本文先简要介绍二次代价函数,以及其存在的不足。
一、二次代价函数的不足
ANN的设计目的之一是为了使机器可以像人一样学习知识。人在学习分析新事物时,当发现自己犯的错误越大时,改正的力度就越大。比如投篮:当运动员发现自己的投篮方向离正确方向越远,那么他调整的投篮角度就应该越大,篮球就更容易投进篮筐。同理,我们希望:ANN在训练时,如果预测值与实际值的误差越大,那么在反向传播训练的过程中,各种参数调整的幅度就要更大,从而使训练更快收敛。然而,如果使用二次代价函数训练ANN,看到的实际效果是,如果误差越大,参数调整的幅度可能更小,训练更缓慢。
以一个神经元的二类分类训练为例,进行两次实验(ANN常用的激活函数为sigmoid函数,该实验也采用该函数):输入一个相同的样本数据x=1.0(该样本对应的实际分类y=0);两次实验各自随机初始化参数,从而在各自的第一次前向传播后得到不同的输出值,形成不同的代价(误差):
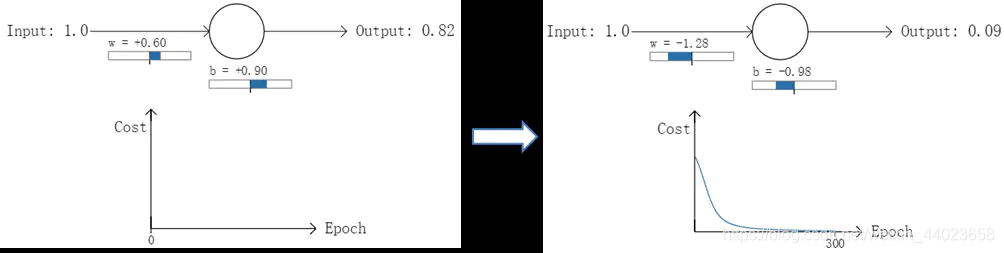
实验1:第一次输出值为0.82

实验2:第一次输出值为0.98
在实验1中,随机初始化参数,使得第一次输出值为0.82(该样本对应的实际值为0);经过300次迭代训练后,输出值由0.82降到0.09,逼近实际值。而在实验2中,第一次输出值为0.98,同样经过300迭代训练,输出值只降到了0.20。
从两次实验的代价曲线中可以看出:实验1的代价随着训练次数增加而快速降低,但实验2的代价在一开始下降得非常缓慢;直观上看,初始的误差越大,收敛得越缓慢。
其实,误差大导致训练缓慢的原因在于使用了二次代价函数。二次代价函数的公式如下:
C = 1 2 n ∑ x ∥ y ( x ) − a L ( x ) ∥ 2 C=\frac{1}{2 n} \sum_{x}\left\|y(x)-a^{L}(x)\right\|^{2} C=2n1x∑∥∥y(x)−aL(x)∥∥2
其中,C表示代价,x表示样本,y表示实际值,a表示输出值,n表示样本的总数。为简单起见,同样一 个样本为例进行说明,此时二次代价函数为:
C = ( y − a ) 2 2 C=\frac{(y-a)^{2}}{2} C=2(y−a)2
目前训练ANN最有效的算法是反向传播算法。简而言之,训练ANN就是通过反向传播代价,以减少代价为导向,调整参数。参数主要有:神经元之间的连接权重w,以及每个神经元本身的偏置b。调参的方式 是采用梯度下降算法 ( Gradient descent ),沿着梯度方向调整参数大小。W和b的梯度推导如下:
∂ C ∂ w = ( a − y ) σ ′ ( z ) x ∂ C ∂ b = ( a − y ) σ ′ ( z ) \begin{array}{l} \frac{\partial C}{\partial w}=(a-y) \sigma^{\prime}(z) x \\ \frac{\partial C}{\partial b}=(a-y) \sigma^{\prime}(z) \end{array} ∂w∂C=(a−y)σ′(z)x∂b∂C=(a−y)σ′(z)
其中,Z表示神经元的输入, の表示激活函数。从以上公式可以看出,W和b的梯度跟激活函数的梯度成正比,激活函数的梯度越大,w和b的大小调整得越快,训练收合得就越快。而神经网络常用的激活函数为sigmoid函数,该函数的曲线如下所示:
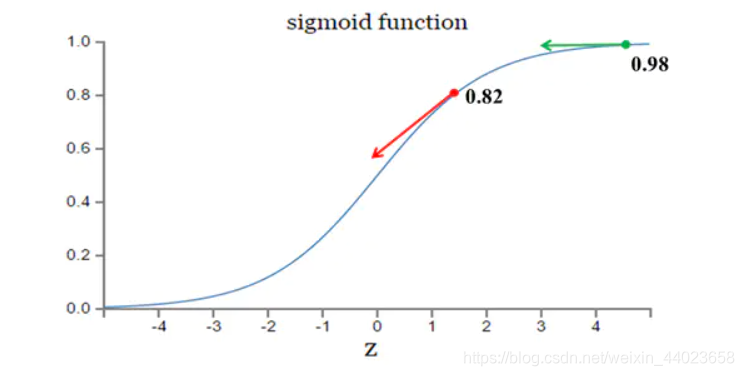
如图所示,实验2的初始输出值(0.98)对应的梯度明显小于实验1的输出值(0.82),因此实验2的参数梯度下降得比实验1慢。这就是初始的代价(误差)越大,导致训练越慢的原因。与我们的期望不符,即:不能像人一样,错误越大,改正的幅度越大,从而学习得越快。
可能有人会说,那就选择一个梯度不变化或变化不明显的激活函数不就解决问题了吗?图样图森破,那样虽然简单粗暴地解决了这个问题,但可能会引起其他更多更麻烦的问题。而且,类似sigmoid这样的函数(比如tanh函数)有很多优点,非常适合用来做激活函数,具体请自行google之
交叉熵代价函数的定义
那么我们如何解决这个问题呢?研究表明, 我们可以通过使用交叉嫡函数来替换二次代价函数。为 了理解什么是交叉嫡, 我们稍微改变一下之前的简单例子。假设, 我们现在要训练一个包含若干输
入变量的的神经元, x 1 , x 2 , … x_{1}, x_{2}, \ldots x1,x2,… 对应的权重为 w 1 , w 2 , … w_{1}, w_{2}, \ldots w1,w2,… 和偏置 b b b :
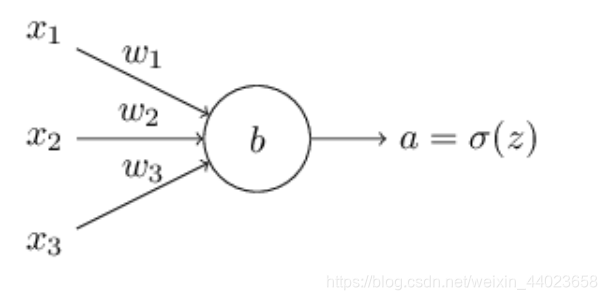
神经元的输出就是 a = σ ( z ) , a=\sigma(z), a=σ(z), 其中 z = ∑ j w j x j + b z=\sum_{j} w_{j} x_{j}+b_{\text { } \text { }} z=∑jwjxj+b 是输入的带权和。我们如下定义这个神经元的交叉嫡代价函数:
C = − 1 n ∑ x [ y ln a + ( 1 − y ) ln ( 1 − a ) ] C=-\frac{1}{n} \sum_{x}[y \ln a+(1-y) \ln (1-a)] C=−n1x∑[ylna+(1−y)ln(1−a)]
其中 n n n 是训练数据的总数,求和是在所有的训练输入 x x x 上进行的, y y y 是对应的目标输出。
对于交叉嫡代价函数, 针对一个训练样本 x x x 的输出误差 δ L \delta^{L} δL 为
δ L = a L − y \delta^{L}=a^{L}-y δL=aL−y
关于输出层的权重的偏导数为
∂ C ∂ w j k L = 1 n ∑ x a k L − 1 ( a j L − y j ) \frac{\partial C}{\partial w_{j k}^{L}}=\frac{1}{n} \sum_{x} a_{k}^{L-1}\left(a_{j}^{L}-y_{j}\right) ∂wjkL∂C=n1x∑akL−1(ajL−yj)
这里 σ ′ ( z j L ) \sigma^{\prime}\left(z_{j}^{L}\right) σ′(zjL) 就消失了,所以交叉嫡避免了学习缓慢的问题。
那么我们应该在什么时候用交叉熵来替换二次代价函数?实际上,如果在输出神经元是 S S S时,交叉熵一般都是更好的选择。为什么?考虑一下我们初始化网络的权重和偏置的时候通常使用某种随机方法。可能会发生这样的情况,这些初始选择会对某些训练输入误差相当明显,比如说,目标输出是 1 1 1 ,而实际值是 0 0 0,或者完全反过来。如果我们使用二次代价函数,那么这就会导致学习速度的下降。它并不会完全终止学习的过程,因为这些权重会持续从其他的样本中进行学习,但是显然这不是我们想要的效果。
交叉熵在分类问题中的应用
交叉熵损失函数应用在分类问题中时,不管是单分类还是多分类,类别的标签都只能是 0 或者 1。
交叉熵在单分类问题中的应用
这里的单类别是指,每一张图像样本只能有一个类别,比如只能是狗或只能是猫。交叉熵在单分类问题上基本是标配的方法
los s = − ∑ i = 1 n y i log ( y ^ i ) \operatorname{los} s=-\sum_{i=1}^{n} y_{i} \log \left(\hat{y}_{i}\right) loss=−i=1∑nyilog(y^i)
上式为一张样本的 loss 计算方法。式中 n n n 代表着 n n n 种类别。举例如下
∗ 猫 青蛙 老鼠 Label 0 1 0 Pred 0.3 0.6 0.1 \begin{array}{|l|l|l|l|} \hline * & \text { 猫 } & \text { 青蛙 } & \text { 老鼠 } \\ \hline \text { Label } & 0 & 1 & 0 \\ \hline \text { Pred } & 0.3 & 0.6 & 0.1 \\ \hline \end{array} ∗ Label Pred 猫 00.3 青蛙 10.6 老鼠 00.1
那么
los s = − ( 0 × log ( 0.3 ) + 1 × log ( 0.6 ) + 0 × log ( 0.1 ) = − log ( 0.6 ) \begin{aligned} \operatorname{los} s &=-(0 \times \log (0.3)+1 \times \log (0.6)+0 \times \log (0.1)\\ &=-\log (0.6) \end{aligned} loss=−(0×log(0.3)+1×log(0.6)+0×log(0.1)=−log(0.6)
对应一个batch的loss就是
los s = − 1 m ∑ j = 1 m ∑ i = 1 n y j i log ( y ^ j i ) \operatorname{los} s=-\frac{1}{m} \sum_{j=1}^{m} \sum_{i=1}^{n} y_{j i} \log \left(\hat{y}_{j i}\right) loss=−m1j=1∑mi=1∑nyjilog(y^ji)
m为当前batch的样本数
交叉熵在多标签问题中的应用
这里的多类别是指,每一张图像样本可以有多个类别,比如同时包含一只猫和一只狗和单分类问题的标签不同,多分类的标签是n-hot。
∗ 猫 青蛙 老鼠 Label 0 1 1 Pred 0.1 0.7 0.8 \begin{array}{|l|l|l|l|} \hline * & \text { 猫 } & \text { 青蛙 } & \text { 老鼠 } \\ \hline \text { Label } & 0 & 1 & 1 \\ \hline \text { Pred } & 0.1 & 0.7 & 0.8 \\ \hline \end{array} ∗ Label Pred 猫 00.1 青蛙 10.7 老鼠 10.8
值得注意的是,这里的Pred采用的是sigmoid函数计算。将每一个节点的输出归一化到[0,1]之间。所有Pred值的和也不再为1。换句话说,就是每一个Label都是独立分布的,相互之间没有影响。所以交叉熵在这里是单独对每一个节点进行计算,每一个节点只有两种可能值,所以是一个二项分布。对于二项分布这种特殊的分布,熵的计算可以进行简化。
同样的,交叉熵的计算也可以简化,即
loss = − y log ( y ^ ) − ( 1 − y ) log ( 1 − y ^ ) \operatorname{loss}=-y \log (\hat{y})-(1-y) \log (1-\hat{y}) loss=−ylog(y^)−(1−y)log(1−y^)
注意,上式只是针对一个节点的计算公式。这一点一定要和单分类Ioss区分开来。
例子中可以计算为:
los s 猫 = − 0 × log ( 0.1 ) − ( 1 − 0 ) log ( 1 − 0.1 ) = − log ( 0.9 ) los s 蛙 = − 1 × log ( 0.7 ) − ( 1 − 1 ) log ( 1 − 0.7 ) = − log ( 0.7 ) los s 鼠 = − 1 × log ( 0.8 ) − ( 1 − 1 ) log ( 1 − 0.8 ) = − log ( 0.8 ) \begin{array}{l} \operatorname{los} s_{\text {猫 }}=-0 \times \log (0.1)-(1-0) \log (1-0.1)=-\log (0.9) \\ \operatorname{los} s_{\text {蛙 }}=-1 \times \log (0.7)-(1-1) \log (1-0.7)=-\log (0.7) \\ \operatorname{los} s_{\text {鼠 }}=-1 \times \log (0.8)-(1-1) \log (1-0.8)=-\log (0.8) \end{array} loss猫 =−0×log(0.1)−(1−0)log(1−0.1)=−log(0.9)loss蛙 =−1×log(0.7)−(1−1)log(1−0.7)=−log(0.7)loss鼠 =−1×log(0.8)−(1−1)log(1−0.8)=−log(0.8)
单张样本的loss即为loss = l o s s 猫 + loss 娃 + loss 氏 =l o s s_{\text {猫 }}+\operatorname{loss} _{\text {娃 }}+\operatorname{loss} _{\text {氏 }} =loss猫 +loss娃 +loss氏 每一个batch的loss就是:
loss = ∑ j = 1 m ∑ i = 1 n − y j i log ( y ^ j i ) − ( 1 − y j i ) log ( 1 − y ^ j i ) \operatorname{loss}=\sum_{j=1}^{m} \sum_{i=1}^{n}-y_{j i} \log \left(\hat{y}_{j i}\right)-\left(1-y_{j i}\right) \log \left(1-\hat{y}_{j i}\right) loss=j=1∑mi=1∑n−yjilog(y^ji)−(1−yji)log(1−y^ji)
式中m为当前batch中的样本量,n为类别数。
交叉熵代价函数对权重求导的证明
交叉熵代价函数的定义:
C = − 1 n ∑ x [ y ln a + ( 1 − y ) ln ( 1 − a ) ] C=-\frac{1}{n} \sum_{x}[y \ln a+(1-y) \ln (1-a)] C=−n1x∑[ylna+(1−y)ln(1−a)]
代价函数 C C C 对 w j k L w_{j k}^{L} wjkL 求偏导
∂ C ∂ w j k L = − 1 n ∑ x ( y j L σ ( z j L ) − ( 1 − y j L ) 1 − σ ( z j L ) ) ∂ σ ( z j L ) ∂ w j k L = − 1 n ∑ x ( y j L σ ( z j L ) − ( 1 − y j L ) 1 − σ ( z j L ) ) σ ′ ( z j L ) a k L − 1 = 1 n ∑ x σ ′ ( z j L ) a k L − 1 σ ( z j L ) ( 1 − σ ( z j L ) ) ( σ ( z j L ) − y j ) \begin{aligned} \frac{\partial C}{\partial w_{j k}^{L}} &=-\frac{1}{n} \sum_{x}\left(\frac{y_{j}^{L}}{\sigma\left(z_{j}^{L}\right)}-\frac{\left(1-y_{j}^{L}\right)}{1-\sigma\left(z_{j}^{L}\right)}\right) \frac{\partial \sigma\left(z_{j}^{L}\right)}{\partial w_{j k}^{L}} \\ &=-\frac{1}{n} \sum_{x}\left(\frac{y_{j}^{L}}{\sigma\left(z_{j}^{L}\right)}-\frac{\left(1-y_{j}^{L}\right)}{1-\sigma\left(z_{j}^{L}\right)}\right) \sigma^{\prime}\left(z_{j}^{L}\right) a_{k}^{L-1} \\ &=\frac{1}{n} \sum_{x} \frac{\sigma^{\prime}\left(z_{j}^{L}\right) a_{k}^{L-1}}{\sigma\left(z_{j}^{L}\right)\left(1-\sigma\left(z_{j}^{L}\right)\right)}\left(\sigma\left(z_{j}^{L}\right)-y_{j}\right) \end{aligned} ∂wjkL∂C=−n1x∑(σ(zjL)yjL−1−σ(zjL)(1−yjL))∂wjkL∂σ(zjL)=−n1x∑(σ(zjL)yjL−1−σ(zjL)(1−yjL))σ′(zjL)akL−1=n1x∑σ(zjL)(1−σ(zjL))σ′(zjL)akL−1(σ(zjL)−yj)
其中 ∂ z j l ∂ w j k l = a k l − 1 \frac{\partial z_{j}^{l}}{\partial w_{j k}^{l}}=a_{k}^{l-1} ∂wjkl∂zjl=akl−1 来自, 根据 z j l z_{j}^{l} zjl 定义
z j l = ∑ k w j k l a k l − 1 + b j l z_{j}^{l}=\sum_{k} w_{j k}^{l} a_{k}^{l-1}+b_{j}^{l} zjl=k∑wjklakl−1+bjl
所以
∂ z j l ∂ w j k l = a k l − 1 \frac{\partial z_{j}^{l}}{\partial w_{j k}^{l}}=a_{k}^{l-1} ∂wjkl∂zjl=akl−1
根据 σ ( z ) = 1 / ( 1 + e − z ) \sigma(z)=1 /\left(1+e^{-z}\right) σ(z)=1/(1+e−z) 的定义
σ ′ ( z ) = ( 1 1 + e − z ) ′ = e − z ( 1 + e − z ) 2 = 1 + e − z − 1 ( 1 + e − z ) 2 = 1 ( 1 + e − z ) ( 1 − 1 ( 1 + e − z ) ) = σ ( z ) ( 1 − σ ( z ) ) \begin{aligned} \sigma^{\prime}(z) &=\left(\frac{1}{1+e^{-z}}\right)^{\prime} \\ &=\frac{e^{-z}}{\left(1+e^{-z}\right)^{2}} \\ &=\frac{1+e^{-z}-1}{\left(1+e^{-z}\right)^{2}} \\ &=\frac{1}{\left(1+e^{-z}\right)}\left(1-\frac{1}{\left(1+e^{-z}\right)}\right) \\ &=\sigma(z)(1-\sigma(z)) \end{aligned} σ′(z)=(1+e−z1)′=(1+e−z)2e−z=(1+e−z)21+e−z−1=(1+e−z)1(1−(1+e−z)1)=σ(z)(1−σ(z))
把 σ ′ ( z ) \sigma^{\prime}(z) σ′(z) 带入 ∂ C ∂ w j \frac{\partial C}{\partial w_{j}} ∂wj∂C 可街
∂ C ∂ w j k L = 1 n ∑ x a k L − 1 ( a j L − y j ) \frac{\partial C}{\partial w_{j k}^{L}}=\frac{1}{n} \sum_{x} a_{k}^{L-1}\left(a_{j}^{L}-y_{j}\right) ∂wjkL∂C=n1x∑akL−1(ajL−yj)
其向量形式是
∂ C ∂ w L = 1 n ∑ x a j L − 1 ( σ ( z L ) − y ) \frac{\partial C}{\partial w^{L}}=\frac{1}{n} \sum_{x} a_{j}^{L-1}\left(\sigma\left(z^{L}\right)-y\right) ∂wL∂C=n1x∑ajL−1(σ(zL)−y)
对偏置用同样的方法可得
∂ C ∂ b j L = 1 n ∑ x ( a j L − y j ) \frac{\partial C}{\partial b_{j}^{L}}=\frac{1}{n} \sum_{x}\left(a_{j}^{L}-y_{j}\right) ∂bjL∂C=n1x∑(ajL−yj)
交叉熵的含义和来源
我们对于交叉熵的讨论聚焦在代数分析和代码实现。这虽然很有用,但是也留下了一个未能回答的更加宽泛的概念上的问题,如:交叉熵究竟表示什么?存在一些直觉上的思考交叉熵的方法吗?我们如何想到这个概念?
让我们从最后一个问题开始回答:什么能够激发我们想到交叉熵?假设我们发现学习速度下降了,并理解其原因是因为对于二次代价函数,输出层的权重的偏导数为
∂ C ∂ w j k L = 1 n ∑ x a k L − 1 ( a j L − y j ) σ ′ ( z j L ) \frac{\partial C}{\partial w_{j k}^{L}}=\frac{1}{n} \sum_{x} a_{k}^{L-1}\left(a_{j}^{L}-y_{j}\right) \sigma^{\prime}\left(z_{j}^{L}\right) ∂wjkL∂C=n1x∑akL−1(ajL−yj)σ′(zjL)
项 σ ′ ( z j L ) \sigma^{\prime}\left(z_{j}^{L}\right) σ′(zjL) 会在一个输出神经元困在错误值时导致学习速度的下降。在研究了这些公式后, 我们 可能就会想到选择一个不包含 σ ′ ( z ) \sigma^{\prime}(z) σ′(z) 的代价函数。所以, 这时候对一个训练样本 x x x, 其代价 C = C x C=C_{x} C=Cx 满足:
∂ C ∂ w j = a j L − 1 ( a j L − y ) ∂ C ∂ b = ( a − y ) \begin{array}{c} \frac{\partial C}{\partial w_{j}}=a_{j}^{L-1}\left(a_{j}^{L}-y\right) \\ \frac{\partial C}{\partial b}=(a-y) \end{array} ∂wj∂C=ajL−1(ajL−y)∂b∂C=(a−y)
如果我们选择的损失函数满足这些条件,那么它们就能以简单的方式呈现这样的特性:初始误差越大,神经元学习得越快。这也能够解决学习速度下降的问题。实际上,从这些公式开始,现在我们就看看凭着我们数学的直觉推导出交叉熵的形式是可行的。我们来推一下,由链式法则,我们有
∂ C ∂ b = ∂ C ∂ a σ ′ ( z ) \frac{\partial C}{\partial b}=\frac{\partial C}{\partial a} \sigma^{\prime}(z) ∂b∂C=∂a∂Cσ′(z)
使用 σ ′ ( z ) = σ ( z ) ( 1 − σ ( z ) ) = a ( 1 − a ) , \sigma^{\prime}(z)=\sigma(z)(1-\sigma(z))=a(1-a), σ′(z)=σ(z)(1−σ(z))=a(1−a), 上个等式就变成
∂ C ∂ b = ∂ C ∂ a a ( 1 − a ) \frac{\partial C}{\partial b}=\frac{\partial C}{\partial a} a(1-a) ∂b∂C=∂a∂Ca(1−a)
对比等式, 我们有
∂ C ∂ a = a − y a ( 1 − a ) \frac{\partial C}{\partial a}=\frac{a-y}{a(1-a)} ∂a∂C=a(1−a)a−y
对此方程关于 a a a 进行积分, 得到
C = − [ y ln a + ( 1 − y ) ln ( 1 − a ) ] + constant C=-[y \ln a+(1-y) \ln (1-a)]+\text { constant } C=−[ylna+(1−y)ln(1−a)]+ constant
其中 constant 是积分常量。这是一个单独的训练样本 x x x 对损失函数的贡献。为了得到整个的损失 函数, 我们需要对所有的训练样本进行平均, 得到了
C = − 1 n ∑ x [ y ln a + ( 1 − y ) ln ( 1 − a ) ] + constant C=-\frac{1}{n} \sum_{x}[y \ln a+(1-y) \ln (1-a)]+\text { constant } C=−n1x∑[ylna+(1−y)ln(1−a)]+ constant
而这里的常量就是所有单独的常量的平均。所以我们看到方程
∂ C ∂ w j = a j L − 1 ( a j L − y ) ∂ C ∂ b = ( a − y ) \begin{array}{c} \frac{\partial C}{\partial w_{j}}=a_{j}^{L-1}\left(a_{j}^{L}-y\right) \\ \frac{\partial C}{\partial b}=(a-y) \end{array} ∂wj∂C=ajL−1(ajL−y)∂b∂C=(a−y)
唯一确定了交叉嫡的形式,并加上了一个常量的项。这个交叉嫡并不是凭空产生的。而是一种我们以自然和简单的方法获得的结果。那么交叉嫡直觉含义又是什么?我们如何看待它?深入解释这一点会将我们带到一个不大愿意讨论的领域。然而,还是值得提一下,有一种源自信息论的解释交叉嫡的标准方式。粗略地说,交叉嫡 是"不确定性"的一种度量。特别地, 我们的神经元想要计算函数 x → y = y ( x ) x\rightarrow y=y(x) x→y=y(x) 。但是, 它用函 数 x → a = a ( x ) x \rightarrow a=a(x) x→a=a(x) 进行了替换。假设我们将 a a a 想象成我们神经元估计为 y = 1 y=1 y=1 的概率, 而 1 − a 1-a 1−a 则是 y = 0 y=0 y=0 的概率。那么交叉嫡衡量我们学习到 y y y的正确值的平均起来的不确定性。 如 果输出我们期望的结果,不确定性就会小一点; 反之,不确定性就大一些。
当然,我这里没有严格地给出"不确定性"到底意味着什么,所以看起来像在夸夸其谈。但是实际上,在信息论中有一种准确的方式来定义不确定性究竟是什么。详细内容请看交叉嫡(cross-entropy)的数学历史。
交叉熵(cross-entropy)的数学历史
通用的说,熵(Entropy)被用于描述一个系统中的不确定性(the uncertainty of a system)。在不同领域熵有不同的解释,比如热力学的定义和信息论也不大相同。
先给出一个"不严谨"的概念表述:
熵:可以表示一个事件A的自信息量,也就是A包含多少信息。
KL散度:可以用来表示从事件A的角度来看,事件B有多大不同。
交叉熵:可以用来表示从事件A的角度来看,如何描述事件B。
一句话总结的话:KL散度可以被用于计算代价,而在特定情况下最小化KL散度等价于最小化交叉熵。而交叉熵的运算更简单,所以用交叉熵来当做代价。
信息量
首先是信息量。假设我们听到了两件事,分别如下:
事件A:巴西队进入了2018世界杯决赛圈。
事件B:中国队进入了2018世界杯决赛圈。
仅凭直觉来说,显而易见事件B的信息量比事件A的信息量要大。究其原因,是因为事件A发生的概率很大,事件B发生的概率很小。所以当越不可能的事件发生了,我们获取到的信息量就越大。越可能发生的事件发生了,我们获取到的信息量就越小。那么信息量应该和事件发生的概率有关。
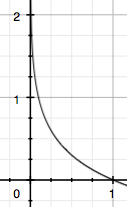
假设 X X X 是一个离散型随机变量, 其取值集合为 χ \chi χ,概率分布函数 p ( x ) = Pr ( X = x ) , x ∈ χ p(x)=\operatorname{Pr}(X=x), x \in \chi p(x)=Pr(X=x),x∈χ 则定义事件 X = x 0 X=x_{0} X=x0 的信息量为:
I ( x 0 ) = − log ( p ( x 0 ) ) I\left(x_{0}\right)=-\log \left(p\left(x_{0}\right)\right) I(x0)=−log(p(x0))
由于是概率所以 p ( x 0 ) p\left(x_{0}\right) p(x0) 的取值范围是[0, 1], 绘制为图形如下:
什么是熵(Entropy)?
放在信息论的语境里面来说,就是一个事件所包含的信息量。我们现在有了信息量的定义,而熵用来表示所有信息量的期望,即:
因此嫡被定义为 S ( x ) = − ∑ i P ( x i ) log b P ( x i ) \text { 因此嫡被定义为 } S(x)=-\sum_{i} P\left(x_{i}\right) \log _{b} P\left(x_{i}\right) 因此嫡被定义为 S(x)=−i∑P(xi)logbP(xi)
如何衡量两个事件/分布之间的不同:KL散度
我们上面说的是对于一个随机变量x的事件A的自信息量,如果我们有另一个独立的随机变量x相关的事件B,该怎么计算它们之间的区别?
此处我们介绍默认的计算方法:KL散度,有时候也叫KL距离,一般被用于计算两个分布之间的不同。看名字似乎跟计算两个点之间的距离也很像,但实则不然,因为KL散度不具备有对称性。在距离上的对称性指的是A到B的距离等于B到A的距离。
KL散度的数学定义:
相对熵又称KL散度,如果我们对于同一个随机变量 x 有两个单独的概率分布 P(x) 和 Q(x),我们可以使用 KL 散度(Kullback-Leibler (KL) divergence)来衡量这两个分布的差异
维基百科对相对熵的定义
In the context of machine learning, DKL(P‖Q) is often called the information gain achieved if P is used instead of Q.
对于离散事件我们可以定义事件A和B的差别为:
D K L ( A ∣ ∣ B ) = ∑ i P A ( x i ) log ( P A ( x i ) P B ( x i ) ) = ∑ i P A ( x i ) log ( P A ( x i ) ) − P A ( x i ) log ( P B ( x i ) ) D_{K L}(A|| B)=\sum_{i} P_{A}\left(x_{i}\right) \log \left(\frac{P_{A}\left(x_{i}\right)}{P_{B}\left(x_{i}\right)}\right)=\sum_{i} P_{A}\left(x_{i}\right) \log \left(P_{A}\left(x_{i}\right)\right)-P_{A}\left(x_{i}\right) \log \left(P_{B}\left(x_{i}\right)\right) DKL(A∣∣B)=i∑PA(xi)log(PB(xi)PA(xi))=i∑PA(xi)log(PA(xi))−PA(xi)log(PB(xi))
对于连续事件,那么我们只是把求和改为求积分而已。
D K L ( A ∥ B ) = ∫ a ( x ) log ( a ( x ) b ( x ) ) D_{K L}(A \| B)=\int a(x) \log \left(\frac{a(x)}{b(x)}\right) DKL(A∥B)=∫a(x)log(b(x)a(x))
从公式中可以看出:
- 如果 P A = P B P_{A}=P_{B} PA=PB, 即两个事件分布完全相同,那么KL散度等于0。
- 观察公式, 可以发现减号左边的就是事件A的嫡,请记住这个发现。
- 如果颠倒一下顺序求 D K L ( B ∣ ∣ A ) , D_{K L}(B|| A), DKL(B∣∣A), 那么就需要使用B的嫡,答案就不一样了。所以KL散度 来计算两个分布A与B的时候是不是对称的,有"坐标系"的问题** D K L ( A ∣ ∣ B ) ≠ D K L ( B ∣ ∣ A ) D_{K L}(A|| B) \neq D_{K L}(B|| A) DKL(A∣∣B)=DKL(B∣∣A)
换句话说,KL散度由A自己的熵与B在A上的期望共同决定。当使用KL散度来衡量两个事件(连续或离散),上面的公式意义就是求 A与B之间的对数差 在 A上的期望值。
KL散度 = 交叉熵 - 熵?
如果我们默认了用KL散度来计算两个分布间的不同,那还要交叉熵做什么?
事实上交叉嫡和KL散度的公式非常相近, 其实就是KL散度的后半部分(公式2.1):A和B的交叉嫡 A与B的KL散度 - A的嫡。 D K L ( A ∥ B ) = − S ( A ) + H ( A , B ) D_{K L}(A \| B)=-S(A)+H(A, B) DKL(A∥B)=−S(A)+H(A,B)
对比一下这是KL散度的公式:
D K L ( A ∣ ∣ B ) = ∑ i P A ( x i ) log ( P A ( x i ) P B ( x i ) ) = ∑ i P A ( x i ) log ( P A ( x i ) ) − P A ( x i ) log ( P B ( x i ) ) D_{K L}(A|| B)=\sum_{i} P_{A}\left(x_{i}\right) \log \left(\frac{P_{A}\left(x_{i}\right)}{P_{B}\left(x_{i}\right)}\right)=\sum_{i} P_{A}\left(x_{i}\right) \log \left(P_{A}\left(x_{i}\right)\right)-P_{A}\left(x_{i}\right) \log \left(P_{B}\left(x_{i}\right)\right) DKL(A∣∣B)=i∑PA(xi)log(PB(xi)PA(xi))=i∑PA(xi)log(PA(xi))−PA(xi)log(PB(xi))
这是嫡的公式:
S ( A ) = − ∑ i P A ( x i ) log P A ( x i ) S(A)=-\sum_{i} P_{A}\left(x_{i}\right) \log P_{A}\left(x_{i}\right) S(A)=−i∑PA(xi)logPA(xi)
这是交叉嫡公式:
H ( A , B ) = − ∑ i P A ( x i ) log ( P B ( x i ) ) H(A, B)=-\sum_{i} P_{A}\left(x_{i}\right) \log \left(P_{B}\left(x_{i}\right)\right) H(A,B)=−i∑PA(xi)log(PB(xi))
此处最重要的观察是, 如果 S ( A ) S(A) S(A) 是一个常量, 那么 D K L ( A ∥ B ) = H ( A , B ) D_{K L}(A \| B)=H(A, B) DKL(A∥B)=H(A,B), 也就是说 KL散度和交叉嫡在特定条件下等价。。
为什么交叉嫡可以用作代价?
接着上一点说,最小化模型分布 P ( m o d e l ) P(\bmod e l) P(model) 与 训练数据上的分布 P ( training ) P(\text {training}) P(training) 的差异 等价 于 最小化这两个分布间的KL散度, 也就是最小化 K L ( P ( t r a i n i n g ) ∥ P ( m o d e l ) ) K L(P(t r a i n i n g) \| P(m o d e l)) KL(P(training)∥P(model))
比照第四部分的公式:
- 此处的A就是数据的真实分布: P ( training ) \quad P(\text { training }) P( training )
- 此处的B就是模型从训练数据上学到的分布: P ( model ) \quad P(\text { model }) P( model )
巧的是,训练数据的分布A是给定的。那么根据我们在第四部分说的,因为A固定不变,那么求 D K L ( A ∣ ∣ B ) D_{K L}(A|| B) DKL(A∣∣B) 等价于求 H ( A , B ) , H(A, B), H(A,B), 也就是A与B的交叉嫡。得证, 交叉嫡可以用于计算"学习 模型的分布"与"训练数据分布"之间的不同。当交叉嫡最低时(等于训练数据分布的嫡),我们学到了 '最好的模型"。
但是,完美的学到了训练数据分布往往意味着过拟合,因为训练数据不等于真实数据,我们只是假设它们是相似的,而一般还要假设存在一个高斯分布的误差,是模型的泛化误差下线。
因此在评价机器学习模型时,我们往往不能只看训练数据上的误分率和交叉熵,还是要关注测试数据上的表现。如果在测试集上的表现也不错,才能保证这不是一个过拟合或者欠拟合的模型。交叉熵比照误分率还有更多的优势,因为它可以和很多概率模型完美的结合。
所以逻辑思路是,为了让学到的模型分布更贴近真实数据分布,我们最小化 模型数据分布 与 训练数据之间的KL散度,而因为训练数据的分布是固定的,因此最小化KL散度等价于最小化交叉熵。
因为等价,而且交叉熵更简单更好计算,当然用它。
参考自:望江小汽车
智能推荐
matplotlib画饼状图时,数据重叠避免方法_python matplotlib 绘制的饼状图,有的数据很小全部挤在一起影响效果图-程序员宅基地
文章浏览阅读1.1w次,点赞3次,收藏10次。项目开发的报表展示模块,需要展示具体的数据库中的内容。遇到一个问题,就是画饼状图的时候,存在数据堆叠的情况。废话少说,首先看个例子:但是我想要的是这种情况:于是我就找方法,找到了一种方法是生成html文件格式的情况:参考https://blog.csdn.net/qq_42467563/article/details/82812340这种方法是使用pyecharts。所..._python matplotlib 绘制的饼状图,有的数据很小全部挤在一起影响效果图
再谈Thunderbird(雷鸟)的地址簿与Microsoft 活动目录(AD)关联_thunderbird 添加ldap通讯录-程序员宅基地
文章浏览阅读606次。最近将工作用的操作系统换成了深度Linux,邮件使用Thunderbird(雷鸟),但是公司的内部地址簿是在Microsoft 活动目录(AD)中保存和维护的,这样就涉及到如何将Microsoft 活动目录(AD)和Thunderbird(雷鸟)地址簿关联的问题,网上有很多的文章介绍,但是对于“基准标示名”和“使用用户名和密码登录”没有说的很清楚,在此补充下。1、首先在主页面的上方打开“通讯录”2、点击“编辑”,选择“首选项”菜单3、选择“目录服务器”旁的“编辑目录”按钮4、在弹_thunderbird 添加ldap通讯录
UE4不使用屏幕后处理实现人物外轮廓描边效果_ue4 不是后处理的描边方案-程序员宅基地
文章浏览阅读3.3k次,点赞4次,收藏30次。UE4不使用屏幕后处理实现人物外轮廓描边效果项目涉及卡通渲染风格,需要人物描边效果,之前在网上有大量的通过post process volume来实现的描边效果,但是问题在于屏幕后处理无法控制只对特定对象生效。post process volume的机制是:通过框调整作用范围,当相机进入范围内显示后处理效果(这种效果还是全屏的,只是进入范围内才生效)因此放弃后处理,改为在人物材质上直接描边。..._ue4 不是后处理的描边方案
uni开发手写板功能 弹框 完整代码 舒适应用!!!_uniapp手写板-程序员宅基地
文章浏览阅读519次。成品展示如上图所示首先在项目的componts文件夹里引入cc-signature.vue```javascript<template> <view v-if="canvasVisiable"> <view class="canvas-container"> <canvas canvas-id="canvas" id="canvas" :disable-scroll="true" style="width: 100%; height: 200p._uniapp手写板
Apache Tomcat 8.0.9下载、安装、配置和部署(不是最新版本)_tomcat8.0.9安装-程序员宅基地
文章浏览阅读8.1k次。Apache Tomcat 8.0.8下载、安装、配置和部署_tomcat8.0.9安装
10大最受欢迎的国外业务流程管理(BPM)软件_bpm业务流程管理软件-程序员宅基地
文章浏览阅读1w次。最好的BPM软件是最重要的大型业务解决方案,因为业务竞争力取决于流程管理。业务流程管理(BPM)是使组织的工作流程更加高效,有效并适应业务环境变化的系统化过程。业务流程是为达到特定组织目的和价值目标而由不同的人分别共同完成的一系列活动。活动之间不仅有严格的先后顺序限定,而且活动的内容、方式、责任等也都必须有明确的安排和界定,以使不同活动在不同岗位角色之间进行转手交接成为可能。活动与活动之间在时间和..._bpm业务流程管理软件
随便推点
即插即用 | 5行代码实现NAM注意力机制让ResNet、MobileNet轻松涨点(超越CBAM)-程序员宅基地
文章浏览阅读3k次,点赞4次,收藏54次。点击上方“小白学视觉”,选择加"星标"或“置顶”重磅干货,第一时间送达识别不显著特征是模型压缩的关键。然而,这一点在注意力机制中却没有得到研究。在这项工作中提出了一种新的基于规范化的注意力模块(NAM),它抑制了较少显著性的权值。它对注意力模块应用一个权重稀疏惩罚,因此,在保持类似性能的同时,使它们更有效地计算。通过与ResNet和MobileNet上其他三种注意力机制的..._nam注意力机制
uniapp添加顶部导航栏颜色渐变_uniapp navigationbarbackgroundcolor 颜色渐变-程序员宅基地
文章浏览阅读1.5w次,点赞2次,收藏12次。在uniapp文件夹的pages.json文件中添加如下代码即可实现"backgroundImage":"linear-gradient(to right, #FFDE28,#FF3228)"{ "path": "pages/mySuccessOrder/mySuccessOrder", "style": { "navigationBarTitleText": "支付", "app-plus": { "titleNView": { _uniapp navigationbarbackgroundcolor 颜色渐变
数据存储之SQLCipher数据库解密访问踩坑:net.sqlcipher.database.SQLiteException: file is not a databaseAndroid-程序员宅基地
文章浏览阅读5.1k次。Android解密db文件失败_net.sqlcipher.database.sqliteexception: file is not a database: , while comp
SNORT3规则编写_snort规则编写-程序员宅基地
文章浏览阅读8.6k次,点赞6次,收藏12次。Snort3 IPS规则编写1.规则基础Snort规则被分为两个逻辑部分,规则头和规则选项。规则头包含规则的操作、协议、源和目标IP地址,以及源和目标端口信息。规则选项部分包含警报消息和应该检查数据包的哪些部分的信息,以确定是否应该采取规则操作。规则举例:注:第一个括号之前的文本是规则标题,括号中包含的部分包含规则选项。规则选项部分中冒号前的单词称为选项关键字。选项部分关键字可选。2.规则头规则头包含规则的操作、协议、源和目标IP地址和网掩码,以及源和.._snort规则编写
soap和wsdd的理解_wsdda-程序员宅基地
文章浏览阅读1.5k次。soap的理解概念soap就是简单对象访问协议,是基于 XML 的用于访问网络服务的协议。soap的传输方式SOAP的传输协议使用的就是HTTP协议,HTTP传输的内容是HTML文本,而soap传输内容就是soap消息。soap请求其实就是http请求,请求消息中包含SOAPAction字段,则说明是soap消息。POST /WebServices/WeatherWebService.a..._wsdda
爬虫基础知识点_爬虫知识-程序员宅基地
文章浏览阅读2.7k次,点赞4次,收藏11次。1.爬虫的概念模拟浏览器,发送请求,获取响应。2.爬虫的作用数据采集软件测试抢票网站上的投票网络安全3.爬虫的分类爬虫根据数量:分为通用爬虫、聚焦爬虫聚焦爬虫根据是否获取数据:分为:功能性爬虫(不读取数据,只为实现某一功能)、数据增量爬虫(获取数据,用于后续分析)数据增量爬虫根据url与数据的关系:分为url与数据同时变化、url不变数据变化。4.爬虫的流程url或url_list(网址或网址列表)发请求,获取响应解析5.http、https_爬虫知识