深度学习-视频检测记录(1)_msra视频检测-程序员宅基地
深度学习-视频检测记录(1)
从MSRA的deep feature flow开始
你好! 从各路大神的思考中收集了一些思路,准备以MSRA的Deep Feature Flow for Video Recognition来作为视频深度学习的入门。
1 论文解读
论文中说image content varies slowly over consecutive video frames, especially the high level semantics,可以用来减少computation cost。
根据Visualizing and Understanding Convolutional Neural Networks的理论,The intermediate convolutional feature maps have the same spatial extent of the input image. They also preserve the spatial correspondences between the low level image content and middle-to-high level semantic concepts. 这就提供了在相邻帧之间廉价传播特征的机会。(对于这个理论的解读,链接: link。此文章通过反卷积可视化中间层特征。可视化工具:toolbox:yosinski/deep-visualization-toolbox)
本文引入了deep feature flow:a fast and accurate approach for video recognition。利用相邻帧之间的一致性,只在关键帧上做图像识别,然后将这些深度特征传播到其他帧上。用flow estimate 和 feature propagation来代替直接convolution。
1.1 模型加速
论文的目的主要是减少video recognition的计算开销。但是前人对于单帧图像识别模型加速的研究已经有很多了,例如低秩约束(link),和权值量化。
如果后续有时间,可以通过link来研究低秩约束的加速理论。下面主要讨论权值量化部分,也是较为常讨论的模型压缩方法之一。
BinaryConnect: Training Deep Neural Networks with binary weights during propagations
1.尽管模型精度降低了非常多,但是在训练效果却不比全精度的网络差,有的时候二值网络的训练效果甚至会超越全精度网络,因为二值化过程给神经网络带来了noise,像dropout一样,反而是一种regularization,可以部分避免网络的overfitting。
2.二值化网络可以把单精度乘法变成位操作,这大大地减少了训练过程中的运算复杂度。这种位运算可以写成gpu kernel, 或者用fpga实现,会给神经网络训练速度带来提升。
3.存储神经网络模型主要是存储weights. 二值化的weight只要一个bit就可以存下来了,相比之前的32bit,模型减小了32倍,那么把训练好的模型放在移动设备,比如手机上面做测试就比较容易了。
XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks
XNOR网络,其中卷积层、全连接层的权重以及网络的输入都进行二值化。 二值化的权重和二值化的输入可以有效地实现卷积运算。如果卷积运算的所有操作数都是二值(1和-1)的,那么可以通过XNOR(异或非门)和位计数操作来估计卷积。XNOR-Nets可以精确地近似CNN,同时在CPU中提高58倍计算速度。
1.2 光流
optical flow(光流):即相邻帧之间像素运动的瞬时速率。它是空间运动物体在观察成像平面上的像素运动的瞬时速度,是利用图像序列中像素在时间域上的变化以及相邻帧之间的相关性来找到上一帧跟当前帧之间存在的对应关系,从而计算出相邻帧之间物体的运动信息的一种方法。光流法有两个假设,1)同一物体在不同帧之间运动时,像素亮度不会发生改变。2)相邻帧之间同一目标位移较小,时间变化不会引起目标的剧烈变化。
Lucas-Kanade(LK)光流法
LK算法的约束条件即:小速度,亮度不变以及区域一致性都是较强的假设,并不很容易得到满足。如当物体运动速度较快时,假设不成立,那么后续的假设就会有较大的偏差,使得最终求出的光流值有较大的误差。图像金字塔可以解决这个问题。
考虑物体的运动速度较大时,算法会出现较大的误差。那么就希望能减少图像中物体的运动速度。一个直观的方法就是,缩小图像的尺寸。假设当图像为400×400时,物体速度为[16 16],那么图像缩小为200×200时,速度变为[8,8]。缩小为100*100时,速度减少到[4,4]。所以在源图像缩放了很多以后,原算法又变得适用了。所以光流可以通过生成 原图像的金字塔图像,逐层求解,不断精确来求得。简单来说上层金字塔(低分辨率)中的一个像素可以代表下层的四个。
求导计算公式可参考link。
1.3 Temporal Dimension in Video Recognition
将视频中的时间信息代入图像检测中,以增加检测的准确性。例如可以将检测结果应用于相邻帧,减少错误的检测和漏测。因为由于运动造成的遮挡或者大姿态,非常容易造成在该帧中检测不出来。
下图为T-CNN的框架结构。
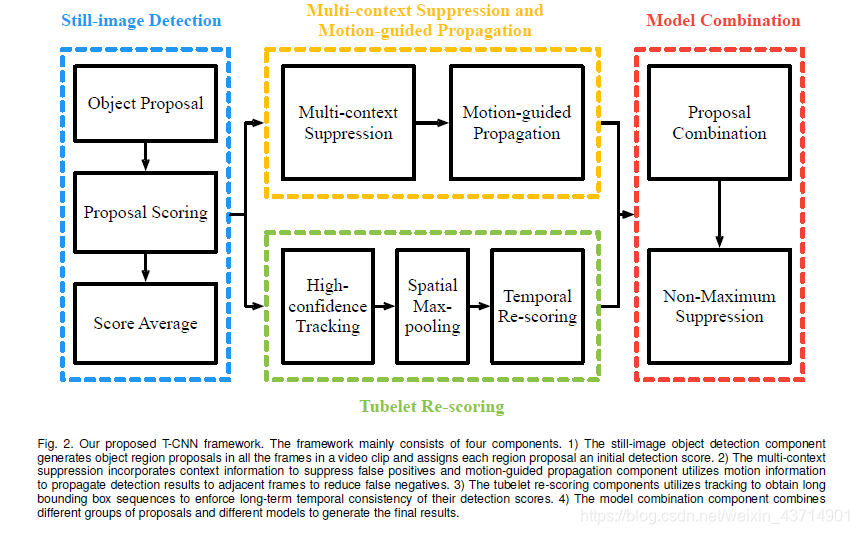
1.3.1 Still-image object detection.
我们的静态图像对象检测器采用DeepID-Net [8]和CRAFT [32]框架,并通过ILSVRC2015的ImageNet检测(DET)和视频(VID)训练数据集训练.。DeepID-Net [8]是R-CNN的扩展[3],CRAFT是Faster R-CNN的扩展[5]。这两个框架都包含对象区域提案和区域提案评分的步骤。主要的区别是,在CRAFT(也是Faster R-CNN)中,提案生成和分类被组合成一个单一的端到端网络。静态图像对象检测器被应用于各个独立帧。在提出的T-CNN框架中,剩余组件分别对两个静态图像对象检测器框架的结果进行处理。
1.3.2 Multi-context suppression.
此过程首先按降序对视频内的所有静态图像检测分数进行排序。具有高排名的检测分数的类别被视为高置信度类别,其余则被视为低置信度类别。 低置信度类别的检测分数被抑制,以减少false positive。
1.3.3 Motion-guided Propagation.
在静态图像对象检测中,在相邻帧中检测到的对象,在某些帧时可能会丢失某些对象。 运动引导传播使用诸如光流的运动信息来将检测结果局部地传播到相邻帧以减少false negative。
1.3.4 Temporal tubelet re-scoring.
从静态图像检测器的高置信度检测开始,我们首先运行跟踪算法来获得边界框序列,我们称之为tubelet。 然后根据其检测分数的统计,将tubelet分为pisitive和negative样本。 positive分数映射到较高的范围,而negative值则映射到较低的范围,从而提高分数裕量。
1.3.5 Model combination:
对于来自DeepID-Net和CRAFT的两组提案中的每一个,它们的来自于tubelet rescoring和运动引导传播的检测结果,每个最小 - 最大映射到[0,1],并通过与 IOU重叠0.5NMS的过程以获得最终结果。
1.4 deep feature flow

1.4.1 算法伪代码与公式
在的deep feature flow的思想中,一个image recognition网络被分成两个部分, N f e a t \N_{feat} Nfeat是特征提取网络, N t a s k N_{task} Ntask是识别任务网络。对于相邻帧而言,经过深层次的特征提取网络得到的是相似的特征图,在这个认知上就可以通过只对关键帧计算 N f e a t \N_{feat} Nfeat,非关键帧的特征图由关键帧计算的特征图传播而来,减少计算耗费。
a location p p p in current frame i i i to the location p + δ p p + δp p+δp in key frame k k k, δ p δp δp由光流计算 M i − > k M_{i->k} Mi−>k得到。当前帧的特征图计算公式如下:
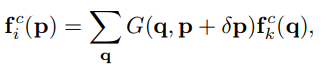
其中 G G G是双线性插值核:
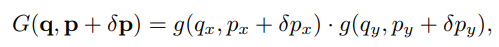
在本文中用一个CNN网络去实现flow的计算,有助于整个任务成为一个端到端的训练。下面是deep feature flow的伪代码,其中 W ( ) W() W()是将上述特征图计算公式运用到所有location和所有channel。

用图表示算法结构:

论文中用SGD下降法,i帧抽取范围在k帧的后9帧,且k帧的选取采用固定间隔,当然根据video的实际内容采用变化的关键帧选取策略是更有效的。Flow network先经过Flying Chairs dataset预训练,然后通过适当增加最后一层卷积层中的通道数量,在网络的末端将scale函数S作为同级输出添加进来。scale函数初始化为1(输出层中的权值和偏差分别初始化为0和1)。
其中特征图传播计算公式 W W W的梯度用 f i f_i fi的特征倒数代替,其由三部分组成, f k f_k fk和 S i − > k S_{i->k} Si−>k的倒数可以通过链式法则简单求得, M i − > k M_{i->k} Mi−>k对于每一个位置 p p p和通道 c c c,有公式:
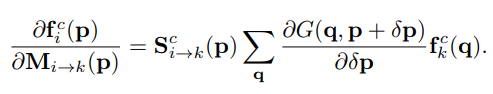
1.4.2 baseline模型选取和网络结构
Flow network选取FlowNet architecture (the “Simple” version),该模型为当时SOTA模型。本文为了对比,对该网络进行了简单化,增加两组网络FlowNet Half,FlowNet Inception。有兴趣的可以看原文。
特征提取网络使用了 ResNet-50 and ResNet-101 models pre-trained for ImageNet classification as defaults。The last 1000-way clas-sification layer is discarded. The feature stride is reduced from 32 to 16 to produce denser feature maps, following the practice of DeepLab for semantic segmentation, and
R-FCN for object detection. The first block of the conv5 layers are modified to have a stride of 1 instead of 2. The holing algorithm [4] is applied on all the 3×3 convolutional kernels in conv5 to keep the field of view (dilation=2). A randomly initialized 3×3 convolution is appended to conv5 to reduce the feature channel dimension to 1024, where the holing algorithm is also applied (dilation=6). The resulting 1024-dimensional feature maps are the intermediate feature maps for the subsequent task.
特征网络后接一层随机初始化的1x1conv层,输出通道数为(C+1),其中C是类别数量,1是背景类别。再接一层softmax对输出层的每个像素计算所属类别概率。实现语义分割任务,且该任务只有一层需要学习的参数。The semantic segmentation accuracy is measured by the pixel-level mean intersection-over-union (mIoU) score.
该模型还采用了R-FCN。在feature map后接两个全卷积网络分支,一个分支接在512维后实现region proposal,另一个接在剩下的一半feature map后实现detection。在region proposal分支,使用RPN网络,选9个anchor,用两个1x1conv分别输出18个objectness scores和36个bbox regression values。在detection分支,也用两个1x1conv分别输出每一组回归器/分类器的C+1scores和4bbox。 评价指标using the standard mean average precision (mAP) metric。
实验证明DFF算法可以在损失极少精度的代价下大幅提升计算效率。在训练中指定帧 i i i和它的ground truth, k k k帧为 i i i- l l l+1,…, i i i。但是在optical flow计算和key frame schedule上还是有很大探索空间。
1.4.3 FlowNet
FlowNet使用CNN来预测两帧之间的光流图,整个是一个编码解码结构。
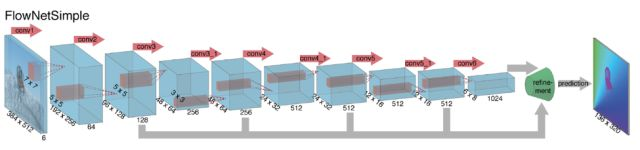
上面是FlowNetSimple,直接将两张图片cat到一起为6通道作为input。
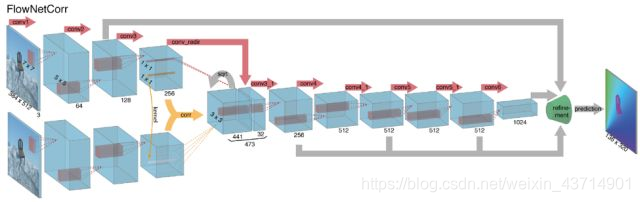
下面的是FlowNetCorr,先分别提前两幅图的特征图,然后再两张图的特征在空间维做卷积运算,相当于计算两幅图的相关性,之后再进行编码解码操作。
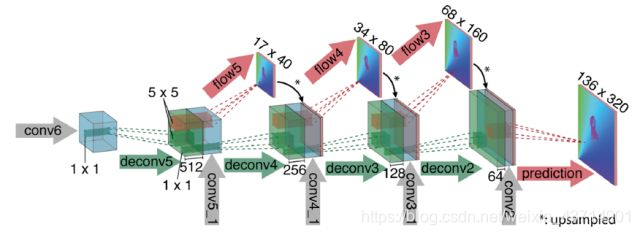
在解码过程中,每次deconv的输入包含三部分:上一层的输出,上一层输入预测的低尺度光流图,以及对应尺度的编码层特征图。如下图所示:
作者还通过将一些3D椅子模型随机覆盖在一些背景图片上合成图像,制作了约有22K的图像对的数据集FlyingChair,并且FlowNet在上面表现出来最好的效果,且在速度上大大领先传统算法,实现实时光流计算。但是在真实数据集上的表现还是不如传统办法,于是升级到2.0版本,在损失极小计算性能的前提下追平传统算法的准确度。
FlowNet2.0增加了具有3D运动的数据库FlyingThings3D和更复杂的训练策略。详情请查看link.
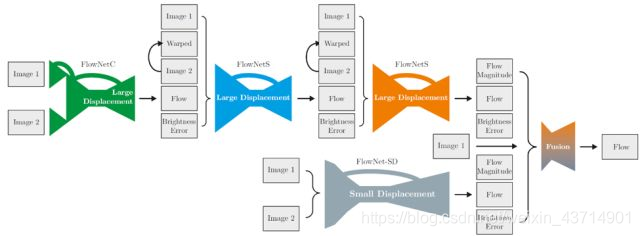
[在训练模型,提高模型准确率上,可以通过合成数据集、训练策略、模型融合、模块增加的方式实现。
例如flownet2在堆叠的flownet上训练当前模块时,可以固定之前的模块参数,这样能获得最优的结果。在堆叠模块(stacking)输入上,除了image1和image2,还可以加上前一个模块的输出,误差图像等等。这也是模型融合的一个方法。因为堆叠导致的计算量增大,可以通过减小每层的通道数来抵消。
在flownet2中还有一个小技巧,将7x7和5x5的卷积换成多层3x3卷积来增加对小位移的分辨率。在inception中也有此操作,不过是为了大幅减少计算量。
flownet2现在简单数据集上训练,再在有更复杂信息的数据集上训练能得到更好的效果。]
智能推荐
Java Web开发_异步处理以及前端中Vue框架的简单使用(Day3)_后端异步前端怎么处理-程序员宅基地
文章浏览阅读304次。此博客主要记录在学习黑马程序员2023版JavaWeb开发课程的一些笔记,方便总结以及复习。_后端异步前端怎么处理
python数据类型01_python[80., 20., 1000, 200]-程序员宅基地
文章浏览阅读1w次。文章目录数值类型整型(int)long(长整型)浮点数复数不同进制表示数值类型转换数据类型信息获取math 模块、cmath 模块python数学函数abs(x)ceil()cmp()exp()fabs()floor()log()log10()max()min()modf()pow()round()sqrt()python随机数函数choice()randrange()random()seed()..._python[80., 20., 1000, 200]
机器视觉halcon轮廓线处理关键算子-常州龙熙机器视觉培训班_halcon中的轮廓线 导数-程序员宅基地
文章浏览阅读876次,点赞23次,收藏21次。halcon 轮廓线处理 关键算子_halcon中的轮廓线 导数
自动驾驶人机交互HMI产品技术方案_自动驾驶hmi用什么开发-程序员宅基地
文章浏览阅读544次。HMI产品是L4车辆的人机交互程序,为高速运营、港口单车、测试路测等提供状态可视化、任务交互、自动驾驶行车控制、编队控制功能。_自动驾驶hmi用什么开发
Matlab画散点图并拟合(使用cftool函数拟合)_matlab散点图拟合函数-程序员宅基地
文章浏览阅读4w次,点赞13次,收藏120次。Matlab根据坐标点进行绘制散点图并拟合成图像可以使用cftool函数,下面以二维数据拟合进行举例:(1)首先输入数据点x=[0.20,2,4.01,5.99,8.08,9.98,11.96,14.00,15.99,18.00,19.98,21.98,23.99,25.97,28.01,30.00,32.04,33.99,35.98,37.99,39.99,42.00,43.99,45...._matlab散点图拟合函数
Java 命令行运行参数大全_命令行运行java参数-程序员宅基地
文章浏览阅读6.8k次。javac 用法:javac 其中,可能的选项包括: -g 生成所有调试信息 -g:none 不生成任何调试信息 -g:{lines,vars,source} _命令行运行java参数
随便推点
阿里云mysql空间不足_阿里云MySQL 实例空间使用率过高的原因和解决方法-程序员宅基地
文章浏览阅读419次。用户在使用 MySQL 实例时,会遇到空间使用告警甚至超过实例限额被锁定的情况。在 RDS 控制台的实例基本信息中,即会出现如下信息:本文将介绍造成空间使用率过高的常见原因及其相应的解决方法。对于MySQL 5.6版本的实例,升级实例规格和存储空间后即可解锁实例,关于如何升级实例配置,请参见变更配置。•常见原因造成 MySQL 实例空间使用率过高,主要有如下四种原因:Binlog 文件占用高。数据..._阿里云m2实例数超过限制99999
JQuery信息提示框插件 jquery.toast.js 的使用-程序员宅基地
文章浏览阅读1.1w次,点赞5次,收藏13次。1.下载https://github.com/kamranahmedse/jquery-toast-plugin在线预览地址2.导入在页面中引入jquery.toast.css文件,jquery和jquery.toast.js文件。<link type="text/css" rel="stylesheet" href="css/jquery.toast.css">..._jquery.toast.js
vue2+vue3——1~35-程序员宅基地
文章浏览阅读271次。vue2+vue3
电脑远程控制软件哪个好用?(4款远程控制软件推荐)_安企神控制软件-程序员宅基地
文章浏览阅读940次,点赞12次,收藏19次。本文介绍了四款远程控制电脑的软件,这四款远程控制电脑软件操作方法都很简单,大家可以根据自己的需要选择合适的软件即可。在另一台电脑的Chrome浏览器中登录同一个谷歌账号,打开谷歌远程桌面选择要控制的电脑,再输入PIN码即可远程控制电脑。是一款好用的电脑远程控制软件,用户可以通过网络远程连接到其他计算机,轻松实现远程监控、远程技术支持。在两台电脑上都登录QQ账号,主控端电脑打开要控制的好友聊天窗口,单击右上角的更多按钮。,在管理者的电脑上安装管理端,在员工的电脑上安装员工端,安装好后会自动进行连接和上线。_安企神控制软件
80 Gbps 的 USB4 2.0 要来了!_usb4+2.0-程序员宅基地
文章浏览阅读1w次,点赞10次,收藏7次。整理 | 郑丽媛出品 | CSDN(ID:CSDNnews)两年前,英特尔在公布新一代 Thunderbolt 4(以下简称雷电 4)接口标准时曾说:“不是所有 USB4 都能和雷电 4 平起平坐。”如今看来,这句话的顺序可能要颠倒一下了:本月初,USB 推广组官宣了 USB4 v2.0,其可通过 USB Type-C 提供高达 80 Gbps(相当于 10GB/s)的数据传输速率——不仅是 U..._usb4+2.0
【jdk8 jdk17 jdk21 在线中文文档】-程序员宅基地
文章浏览阅读123次。jdk8中文文档jdk17在线文档jdk21在线文档