[数据结构、读书笔记、C++] 并查集详解_按秩合并中包括根节点x在内的树中节点的个数至少是-程序员宅基地
介绍
并查集是一种树型的数据结构,用于处理一些不相交集合(disjoint sets)的 合并及查询 问题。
其主要操作为:
Union(合并) :将两个节点所在集合合并为一个集合
Find (查询) :查询某个节点属于哪个集合(即返回所在树的根节点)
图示:
通过上面的表述,恐怕我们并不清楚并查集到底是什么样子的?
下面我们用 图来表示一下
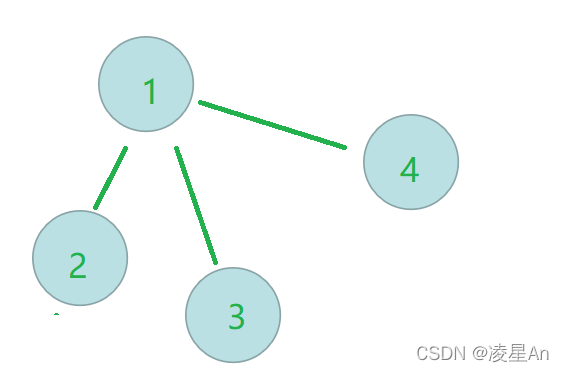
有四个节点我们编号为1,2,3,4,也可以有四棵树,每棵树只有一个节点,该节点即为根节点。这四棵树组成的集合(森林 就是我们所说的并查集

我们使用数组存储 ,上方所示即为
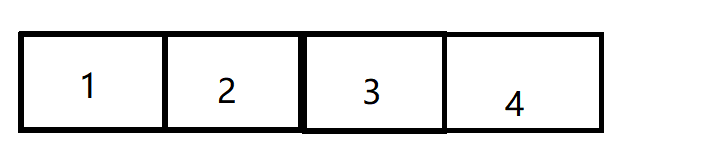
每个节点即为一个集合,每个集合的根节点为自己
合并: 所谓合并就是两棵树合并为一棵树,就是把上面两个节点联系在一起;比如我们合并1,2 两个节点,并且让2 为根节点(也可以1为根节点,这里以2为根节点示例)
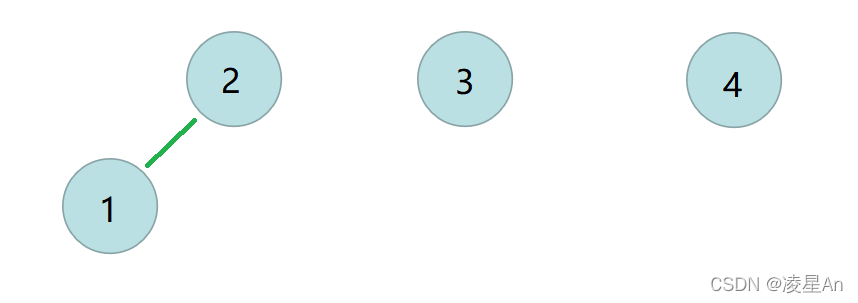
经过合并之后,只有三个集合即三棵树 ,存储的数组变化为
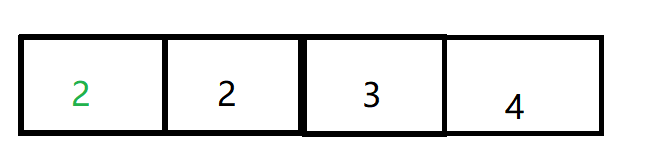
编号为1节点和编号为2的节点 为一个集合,且以2为根,故1号位置存储编号2
查询: 找到系欸但所在集合的根节点
以查询编号为1的节点为例:
我们在数组中找1号位置值为2 ,与编号不同
查找2号位置,值为2,与编号相同,所以编号为1的节点的根节点为2
代码实现
经过了上面的演示,相信大家对于并查集有了最基本的认识,下面我们进行代码实现。
并查集的基本实现
const int N ; //并查集中的节点个数
int p[N]; //存放节点所在树的根节点
void init(){
//初始化,刚开始每个节点都是一棵树,根节点就是它自己
for(int i=1;i<=N;i++){
p[i]=i;
}
}
int Find(int x){
if(p[x]!=x){
//如果不相等,则根节点并非x , 那么去找p[x]的父节点
return find(p[x]);
}
return p[x];
}
void Union(int x,int y){
// 找到x,y所在树的根节点
int px=find(x),py=find(y);
//根节点不相同,则不是一棵树,进行合并
if(px!=py){
//合并后的根节点为py
p[px]=py;
}
}
代码优化
路径压缩
在并查集的操作当中,我们最常使用的是 Find 查询操作 。查询操作的复杂度决定了整体运行效率。
那么思考一下什么情况下,查询操作效率会很低呢?
思考一下树的高度很大的时候。
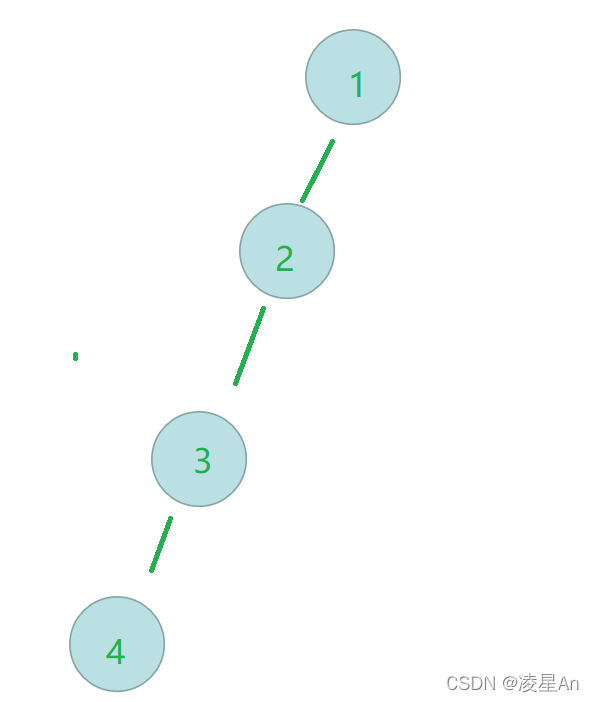
倘若我们查询4号节点,需要从4号节点往上进行查询,复杂度即为O(h),h为树的高度 ,倘若对于深处节点查询频繁的话,效率会很低。
因此,为了避免这种情况,出现了路径压缩的方式,其思想是将上面图片的树,改造为如下所示:
每个子节点的父节点即为根节点,查询操作复杂度O(1)即可
优化代码:
int Find(int x){
if(p[x]!=x){
//如果不相等,则向上查找;find函数返回的结果一定为根节点
// 查询结果赋值给p[x],设置当前节点x的父节点为根节点
p[x]=find(p[x]);
}
return p[x];
}
按秩合并
关于 秩 其实有两种解释 :一种是树的高度,另一种是树的节点个数(集合大小)我们这里采用的是 树 的高度。
按秩合并其实是一种启发式合并 即:把小的数据结构 合并到大的数据结构当中,并且只增加小的数据结构的 查询 代价 。
情况如图所示: 两个集合进行合并
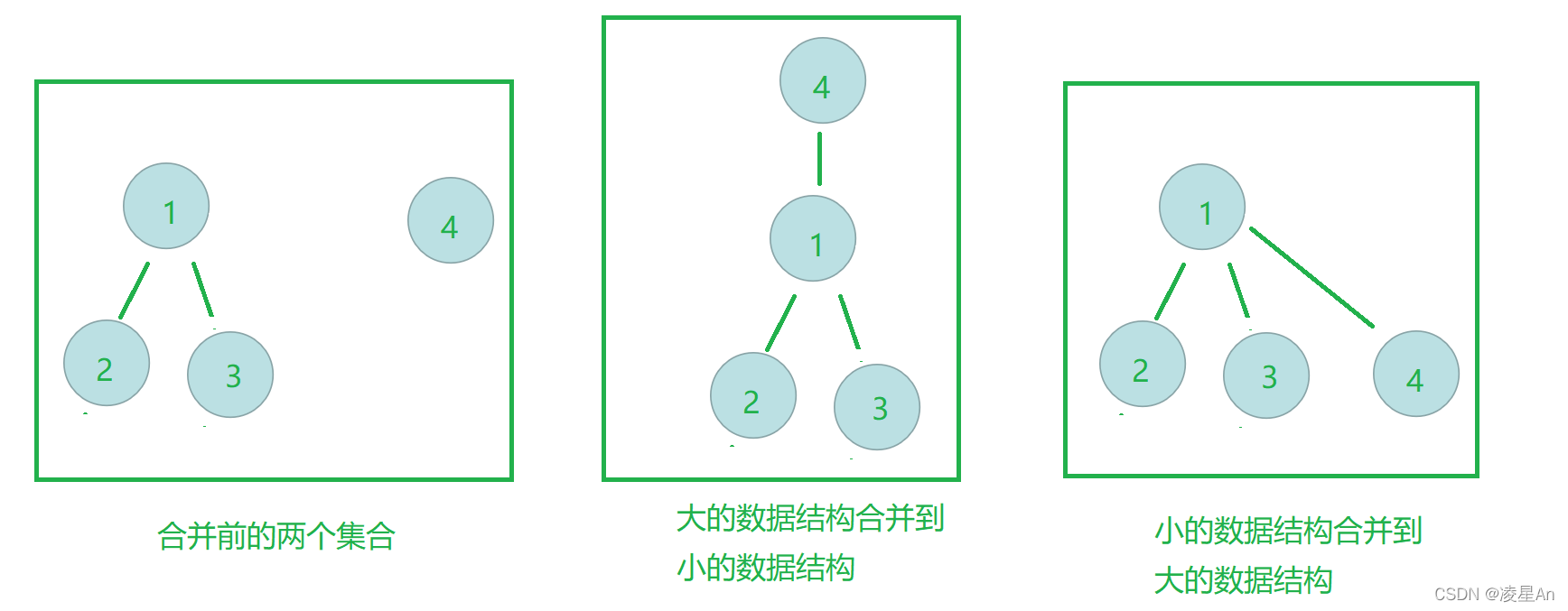
我们可以观察到最右边的图,合并后,进行查询,效率会更好,这种合并方式就是我们正在讨论的 按秩合并 。
优化代码
const int N ; //并查集中的节点个数
int p[N]; //存放节点所在树的根节点
int rank[N] ;//存放秩的数组,每个集合的秩进存放在根节点
void init(){
//初始化,刚开始每个节点都是一棵树,根节点就是它自己
//每个节点的秩为1
for(int i=1;i<=N;i++){
p[i]=i;
rank[i]=1;
}
}
int Find(int x){
if(p[x]!=x){
//路径压缩 优化
p[x]= find(p[x]);
}
return p[x];
}
void Union(int x,int y){
// 找到x,y所在树的根节点
int px=find(x),py=find(y);
//根节点不相同,则不是一棵树,进行合并
if(px!=py){
// 按秩合并 优化
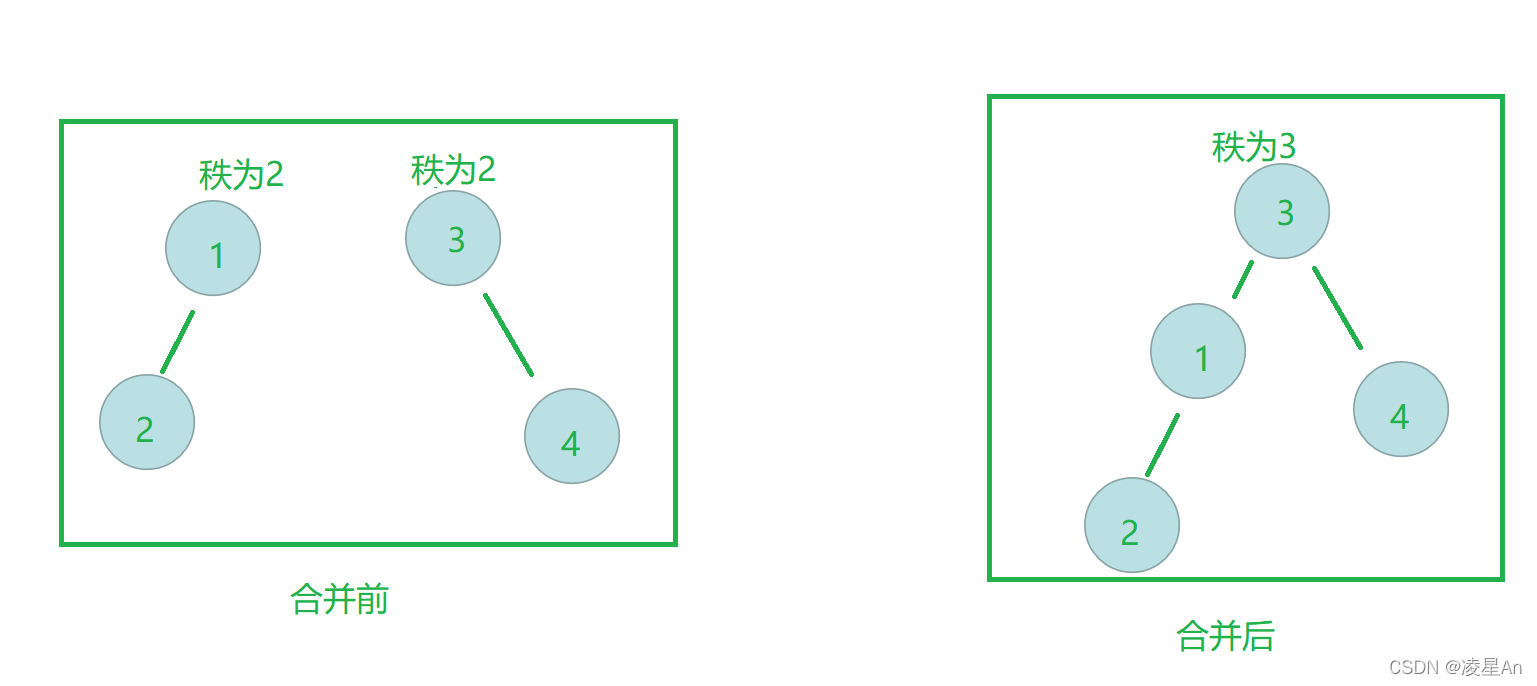
if(rank[px]<=rank[py]){
p[px]=py;
//两个集合的秩相同,合并后的集合在原基础上加1
//原因如下图所示
rank[py]+=(rank[x]==rank[y]?1:0);
}else{
p[py]=px;
}
}
}
题目练习:
1250. 格子游戏
链接: https://www.acwing.com/problem/content/1252/
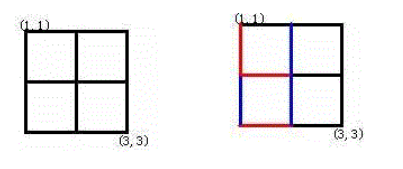
Alice和Bob玩了一个古老的游戏:首先画一个 n×n 的点阵(下图 n=3 )。
接着,他们两个轮流在相邻的点之间画上红边和蓝边:
直到围成一个封闭的圈(面积不必为 1)为止,“封圈”的那个人就是赢家。因为棋盘实在是太大了,他们的游戏实在是太长了!
他们甚至在游戏中都不知道谁赢得了游戏。
于是请你写一个程序,帮助他们计算他们是否结束了游戏?
输入格式
输入数据第一行为两个整数 n 和 m。n表示点阵的大小,m 表示一共画了 m 条线。
以后 m 行,每行首先有两个数字 (x,y),代表了画线的起点坐标,接着用空格隔开一个字符,假如字符是 D,则是向下连一条边,如果是 R 就是向右连一条边。输入数据不会有重复的边且保证正确。
输出格式
输出一行:在第几步的时候结束。
假如 m 步之后也没有结束,则输出一行“draw”。
数据范围
1≤n≤200 ,
1≤m≤24000
输入样例:
3 5
1 1 D
1 1 R
1 2 D
2 1 R
2 2 D
输出样例:
4
思路:
输入样例当中给了我们一个点,及其所画的方向 。其实根据这些信息,我们可以得到两个点的信息,那怎么判断是否形成封闭的圆呢?
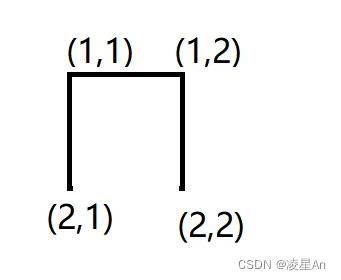
如图所示,我们只需要画一条线,线的两端为(2,1) (2,2) 即可以形成封闭的圆 。这种情况我们使用并查集是最为简单的,判断两个点是否在同一集合内,在的话可以形成封闭的圆。
代码:
#include<iostream>
#include<cstring>
using namespace std;
const int N=40000+10;
int p[N];
// 将二维坐标转换为唯一的数字表示
int get(int x,int y,int n){
x--,y--;
return x*n+y;
}
int find(int x){
if(p[x]!=x) p[x]=find(p[x]);
return p[x];
}
int main(){
int n=0,m=0;
cin>>n>>m;
//初始化
for(int i=0;i<n*n;i++){
p[i]=i;
}
for(int i=1;i<=m;i++){
int x=0,y=0;
char ch;
cin>>x>>y>>ch;
int a=get(x,y,n),b=0;
if(ch=='D'){
b=get(x+1,y,n);
}else if(ch=='R'){
b=get(x,y+1,n);
}
int pa=find(a),pb=find(b);
if(pa==pb){
//如果在同意集合内,形成了封闭的圆,直接返回结果
printf("%d\n",i);
return 0;
}
p[pa]=pb;
}
printf("draw\n");
return 0;
}
1252. 搭配购买
链接:https://www.acwing.com/problem/content/1254/
Joe觉得云朵很美,决定去山上的商店买一些云朵。
商店里有 n 朵云,云朵被编号为 1,2,…,n,并且每朵云都有一个价值。
但是商店老板跟他说,一些云朵要搭配来买才好,所以买一朵云则与这朵云有搭配的云都要买。
但是Joe的钱有限,所以他希望买的价值越多越好。
输入格式
第 1 行包含三个整数 n,m,w,表示有 n 朵云,m 个搭配,Joe有 w 的钱。
第 2∼n+1行,每行两个整数 ci,di 表示 i 朵云的价钱和价值。
第 n+2∼n+1+m 行,每行两个整数 ui,vi,表示买 ui 就必须买 vi,同理,如果买 vi 就必须买 ui。
输出格式
一行,表示可以获得的最大价值。
数据范围
1≤n≤10000,
0≤m≤5000,
1≤w≤10000,
1≤ci≤5000,
1≤di≤100,
1≤ui,vi≤n
输入样例:
5 3 10
3 10
3 10
3 10
5 100
10 1
1 3
3 2
4 2
输出样例:
1
思路:
题目中给我们提供了一些物品的价格和价值;要求买u必须要买v,买v也必须买u ; 倘若买v还必须买w ,则u,v,w 可以认为是一个整体,要买一起买,不买则全部不买;如果把所有关联的物品全部看作一个整体,对于每个整体而言,只有买或者不买两种选择,求一定价钱内能买到物品的最大价值 即可转换为经典的01背包问题 。
而那些物品可以看作一个整体,则可使用并查集进行求取,根节点存储整个集合的价格和价值。
代码:
#include<iostream>
#include<cstring>
using namespace std;
const int N=10000+10;
int p[N];
int cost[N],value[N];
int find(int x){
if(p[x]!=x) {
p[x]=find(p[x]);
}
return p[x];
}
int main(){
int n=0,m=0,w=0;
scanf("%d%d%d",&n,&m,&w);
for(int i=0;i<n;i++){
p[i]=i;
}
for(int i=0;i<n;i++){
int c=0,d=0;
scanf("%d%d",&c,&d);
cost[i]=c,value[i]=d;
}
for(int i=0;i<m;i++){
int u=0,v=0;
scanf("%d%d",&u,&v);
u--,v--;
int pu=find(u),pv=find(v);
if(pu!=pv){
p[pu]=pv;
//根节点加上新加入节点对应的价格和价值
cost[pv]+=cost[pu];
value[pv]+=value[pu];
}
}
int dp[N];
memset(dp,0,sizeof dp);
for(int i=0;i<n;i++){
if(p[i]==i){
for(int j=w;j>=cost[i];j--){
dp[j]=max(dp[j],dp[j-cost[i]]+value[i]);
}
}
}
cout<<dp[w]<<endl;
return 0;
}
237. 程序自动分析
链接:https://www.acwing.com/problem/content/239/
在实现程序自动分析的过程中,常常需要判定一些约束条件是否能被同时满足。
考虑一个约束满足问题的简化版本:假设 x1,x2,x3,… 代表程序中出现的变量,给定 n 个形如 xi=xj 或 xi≠xj 的变量相等/不等的约束条件,请判定是否可以分别为每一个变量赋予恰当的值,使得上述所有约束条件同时被满足。
例如,一个问题中的约束条件为:x1=x2,x2=x3,x3=x4,x1≠x4,这些约束条件显然是不可能同时被满足的,因此这个问题应判定为不可被满足。
现在给出一些约束满足问题,请分别对它们进行判定。
输入格式
输入文件的第 1 行包含 1 个正整数 t,表示需要判定的问题个数,注意这些问题之间是相互独立的。
对于每个问题,包含若干行:
第 1 行包含 1 个正整数 n,表示该问题中需要被满足的约束条件个数。
接下来 n 行,每行包括 3 个整数 i,j,e,描述 1 个相等/不等的约束条件,相邻整数之间用单个空格隔开。若 e=1,则该约束条件为 xi=xj;若 e=0,则该约束条件为 xi≠xj。
输出格式
输出文件包括 t 行。
输出文件的第 k 行输出一个字符串 YES 或者 NO,YES 表示输入中的第 k 个问题判定为可以被满足,NO 表示不可被满足。
数据范围
1≤n≤10^5
1≤i,j≤10^9
输入样例:
2
2
1 2 1
1 2 0
2
1 2 1
2 1 1
输出样例:
NO
YES
思路:
在这个题目当中,可以把输入分为两类,一类是相等的条件,另一类是不等的条件;倘若我们把相等的条件放在一遍,去看不等的条件,倘若不等的条件种两个变量出现在相等条件中,一定不被满足;倘若查询完毕后,没有出现刚才不满足情况,则一定是满足的。
把相等条件的变量全部放入并查集,查询不等的条件,倘若对应的两个变量在一个集合内部,则必不满足;不出现刚才必不满足的情况,则一定满足。
注: 数据量最大为 10^9 以此 来申请并查集的空间,则会超过题目给予的64MB大小;反观条件次数n为 10^6,则变量最多只有2 * 10^6 ,我们可以离散化处理,将大范围的变量处理到小范围上。
代码:
#include<iostream>
#include<cstring>
#include<vector>
#include<unordered_map>
using namespace std;
/*
注:数据量过大,需要进行离散化,将数据放在较小的定义域内
*/
const int N=2000010;
int p[N];
unordered_map<int,int> map;
int find(int x){
if(p[x]!=x){
p[x]=find(p[x]);
}
return p[x];
}
//离散化处理函数
int get(int x){
static int t=1;
if(map.count(x)==0){
map[x]=t++;
}
return map[x];
}
int main(){
int t=0;
scanf("%d",&t);
while(t--){
for(int k=1;k<N;k++){
p[k]=k;
}
int n=0;
scanf("%d",&n);
vector<pair<int,int>> vec1;
vector<pair<int,int>> vec2;
for(int k=0;k<n;k++){
int i=0,j=0,e=0;
scanf("%d%d%d",&i,&j,&e);
if(e==0){
vec1.push_back({
get(i),get(j)});
}else if(e==1){
vec2.push_back({
get(i),get(j)});
}
}
//处理相等的条件
for(int k=0;k<vec2.size();k++){
int i=vec2[k].first,j=vec2[k].second;
int pi=find(i),pj=find(j);
if(pi!=pj){
p[pi]=pj;
}
}
//遍历不等的条件,继续判断
int flag=true;
for(int k=0;k<vec1.size();k++){
int i=vec1[k].first,j=vec1[k].second;
int pi=find(i),pj=find(j);
if(pi==pj){
flag=false;
break;
}
}
if(flag){
puts("YES");
}else{
puts("NO");
}
}
return 0;
}
238. 银河英雄传说
链接: https://www.acwing.com/problem/content/240/
有一个划分为 N 列的星际战场,各列依次编号为 1,2,…,N。
有 N 艘战舰,也依次编号为 1,2,…,N,其中第 i 号战舰处于第 i 列。
有 T 条指令,每条指令格式为以下两种之一:
M i j,表示让第 i 号战舰所在列的全部战舰保持原有顺序,接在第 j 号战舰所在列的尾部。
C i j,表示询问第 i 号战舰与第 j 号战舰当前是否处于同一列中,如果在同一列中,它们之间间隔了多少艘战舰。
现在需要你编写一个程序,处理一系列的指令。
输入格式
第一行包含整数 T,表示共有 T 条指令。
接下来 T 行,每行一个指令,指令有两种形式:M i j 或 C i j。
其中 M 和 C 为大写字母表示指令类型,i 和 j 为整数,表示指令涉及的战舰编号。
输出格式
你的程序应当依次对输入的每一条指令进行分析和处理:
如果是 M i j 形式,则表示舰队排列发生了变化,你的程序要注意到这一点,但是不要输出任何信息;
如果是 C i j 形式,你的程序要输出一行,仅包含一个整数,表示在同一列上,第 i 号战舰与第 j 号战舰之间布置的战舰数目,如果第 i 号战舰与第 j 号战舰当前不在同一列上,则输出 −1。
数据范围
N≤30000,T≤500000
输入样例:
4
M 2 3
C 1 2
M 2 4
C 4 2
输出样例:
-1
1
思路:
对于判断是否是同一列,我们可以使用并查集,通过判断是否属于同一个结合来进行判断。
如果属于同一列(即同一集合),还需要输出之间的距离是多少,这个需要怎么处理呢?
倘若我们有一个数组d[ ] 记录并查集中每个节点到它所属集合的根节点的距离。根节点,我们设置为每列的第一个战舰。
则 对于两艘战舰x,y (x在y前面)而言,他们的距离为 d[y]-d[x]-1 则可以直接得到结果。
因此,我们只需要维护一个数组d[ ] ;
而维护d[ ] 主要在集合合并的时候,进行更新,那怎么更新呢?
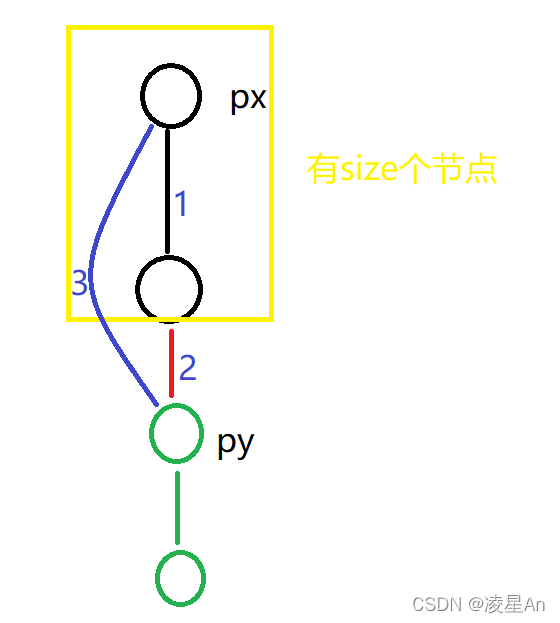
对于py集合而言,每个节点到根节点的距离只需要加上 3 的长度即可
而3的长度 ,如图所示为2 + 1的结果,线段2的长度为1 ,而线段1的长度为整个px集合节点个数
因此,还需要维护一个数组 Size [ ] 存放每个集合的节点数目
代码实现:
#include<iostream>
#include<cstring>
using namespace std;
const int N=30000+10;
int p[N];
// Size 为该集合的元素个数 dist,该节点到父结点的距离
int Size[N],dist[N];
int find(int x){
if(p[x]!=x){
int root=find(p[x]);
//dist[x] 保存的是该节点到父节点的距离
//dist[p[x]] 保存的是 x父节点到根节点的距离 (由上面的递归得到的)
dist[x]+=dist[p[x]];
p[x]=root;
}
return p[x];
}
int main(){
for(int i=1;i<N;i++){
p[i]=i;
Size[i]=1;
dist[i]=0;
}
int t=0;
cin>>t;
while(t--){
char op;
int i=0,j=0;
cin>>op>>i>>j;
if(op=='M'){
int pi=find(i),pj=find(j);
if(pi!=pj){
p[pi]=pj; //将pi集合放到pj集合中
dist[pi]=Size[pj];
Size[pj]+=Size[pi]; //更新pj集合 元素个数
}
}else if(op=='C'){
int pi=find(i),pj=find(j);
if(pi==pj){
//若i==j 则 距离为0 否则 abs()
printf("%d\n",max(0,abs(dist[i]-dist[j])-1));
}else{
printf("-1\n");
}
}
}
return 0;
}
239. 奇偶游戏
链接: https://www.acwing.com/problem/content/description/241/
小 A 和小 B 在玩一个游戏。
首先,小 A 写了一个由 0 和 1 组成的序列 S,长度为 N。
然后,小 B 向小 A 提出了 M 个问题。
在每个问题中,小 B 指定两个数 l 和 r,小 A 回答 S[l∼r] 中有奇数个 1 还是偶数个 1。
机智的小 B 发现小 A 有可能在撒谎。
例如,小 A 曾经回答过 S[1∼3] 中有奇数个 1,S[4∼6] 中有偶数个 1,现在又回答 S[1∼6] 中有偶数个 1,显然这是自相矛盾的。
请你帮助小 B 检查这 M 个答案,并指出在至少多少个回答之后可以确定小 A 一定在撒谎。
即求出一个最小的 k,使得 01 序列 S 满足第 1∼k 个回答,但不满足第 1∼k+1 个回答。
输入格式
第一行包含一个整数 N,表示 01 序列长度。
第二行包含一个整数 M,表示问题数量。
接下来 M 行,每行包含一组问答:两个整数 l 和 r,以及回答 even 或 odd,用以描述 S[l∼r] 中有偶数个 1 还是奇数个 1。
输出格式
输出一个整数 k,表示 01 序列满足第 1∼k 个回答,但不满足第 1∼k+1 个回答,如果 01 序列满足所有回答,则输出问题总数量。
数据范围
N≤10^9,M≤5000
输入样例:
10
5
1 2 even
3 4 odd
5 6 even
1 6 even
7 10 odd
输出样例:
3
思路1:
我们观察数据范围,发现为10^9的空间,过于庞大,所以会使用离散化的技巧 来进行优化。
我们思考题目,发现S其实一个前缀和数组,S[i]表示 i位置及其前面所含的1的个数 ; [l,r]范围的1的个数 即为S[ r ]- S [ l-1 ]
[ l,r ] 如果有奇数个1 ,则 S[ r ]和S[ l-1 ] 奇偶性必不相同,两者一个为奇数,另一个必定为偶数
倘若[l,r]范围内有偶数个1,则则 S[ r ]和S[ l-1 ] 奇偶性相同,一个为奇数,另一个必定为奇数 或者一个为偶数,另一个必定为偶数
通过上面的描述,我们发现,输入的回答,可以使用条件集合进行表示
对于x位置而言 x数字表示S[x]为偶数 x+Base 数字表示S[x]位置为奇数
注:Base其实是一个不妨碍的整数
集合当中存放必然成立的条件
我们可以通过代码来回顾一下这个方案
代码实现:
#include<iostream>
#include<string>
#include<unordered_map>
using namespace std;
const int N=5000*4+10;
// 将Base设置为[x,y] 和[x+Base,y+Base] 区间互不影响的数值即可
int Base=N/2;
int p[N];
//进行离散化处理
unordered_map<int,int> map;
int get(int x){
static int t=0;
if(map.count(x)==0){
map[x]= ++t;
}
return map[x];
}
//并查集 find 函数
int find(int x){
if(p[x]!=x){
p[x]=find(p[x]);
}
return p[x];
}
int main(){
//初始化并查集
for(int i=0;i<N;i++){
p[i]=i;
}
int n=0,m=0;
scanf("%d%d",&n,&m);
int result=m;
for(int i=1;i<=m;i++){
int l=0,r=0;
string type;
cin>>l>>r>>type;
int x=get(l-1),y=get(r);
if(type=="even"){
//区间内有偶数个1 则 S[x] 和S[y] 奇偶性相同,
//如果不同,必不合法
if(find(x+Base)==find(y)||find(x)==find(y+Base)){
result=i-1;
break;
}
//S[x] 和S[y] 奇偶性相同,
//则 S[x]为奇数则S[y] 必为奇数 x+Base表示S[x]为奇数
// S[x]为偶数则S[y] 必偶数
p[find(x)]=find(y);
p[find(x+Base)]=find(y+Base);
}else{
//区间内有奇数个1 则 S[x] 和S[y] 奇偶性不同,
//如果相同,必不合法
if(find(x)==find(y)||find(x+Base)==find(y+Base)){
result=i-1;
break;
}
//S[x] 和S[y] 奇偶性不同,
//则 S[x]为奇数则S[y] 必为偶数
// S[x]为偶数则S[y] 必为奇数
p[find(x+Base)]=find(y);
p[find(x)]=find(y+Base);
}
}
printf("%d\n",result);
return 0;
}
思路2:
带边权的并查集:
我们观察数据范围,发现为10^9的空间,过于庞大,所以会使用离散化的技巧 来进行优化。
我们思考题目,发现S其实一个前缀和数组,S[i]表示 i位置及其前面所含的1的个数 ; [l,r]范围的1的个数 即为S[ r ]- S [ l-1 ]
[ l,r ] 如果有奇数个1 ,则 S[ r ]和S[ l-1 ] 奇偶性必不相同,两者一个为奇数,另一个必定为偶数
倘若[l,r]范围内有偶数个1,则则 S[ r ]和S[ l-1 ] 奇偶性相同,一个为奇数,另一个必定为奇数 或者一个为偶数,另一个必定为偶数
d[x] 表示 x 与根节点 的 奇偶性关系,0表示奇偶性相同,1表示奇偶性不同
[x,y]区间若有奇数个1,则S[x-1] 与S[y ]奇偶性不同
若 px=py 则d[x] ^ d [y] ==1 则无矛盾 ;d[ x ] ^d[ y ] == 0 则有矛盾
[x,y]区间若有偶数个1,则S[x-1] 与S[y ]奇偶性相同
若 px=py 则d[x] ^ d [y] ==0 则无矛盾 ;d[ x ] ^d[ y ] == 1 则有矛盾
问题一:
[x,y]区间若有奇数个1,则S[x-1] 与S[y ]奇偶性不同
若px!=py,则需要合并区间 根节点p[px]=py 而d[ ] 如何更新呢?
问题二:
[x,y]区间若有偶数个1,则S[x-1] 与S[y ]奇偶性相同
若px!=py,则需要合并区间 根节点p[px]=py 而d[ ] 如何更新呢?
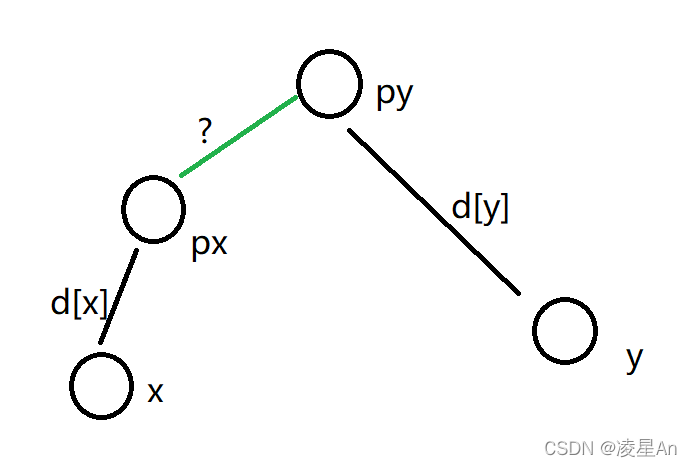
对于问题一而言:
我们希望d[x] ^ d[ y ] ^ ? =1
倘若d[ x ]^d[y ] =0 则?=1 而 d[x] ^d[y ] = 1 的话,则 ?=0
因此? =d [ x ] ^d[ y ]^ 1
同理:
对于问题一而言:
我们希望d[x] ^ d[ y ] ^ ? =0
倘若d[ x ]^d[y ] =0 则?=0 而 d[x] ^d[y ] = 1 的话,则 ?=1
因此? =d [ x ] ^d[ y ]
我们可以通过代码来回顾一下这个方案
代码实现:
#include<iostream>
#include<cstring>
#include<unordered_map>
#include<string>
using namespace std;
const int N=5000*2+10;
int p[N],d[N];
//离散化处理
unordered_map<int,int> map;
int get(int x){
static int t=1;
if(map.count(x)==0){
map[x]=t++;
}
return map[x];
}
int find(int x){
if(p[x]!=x){
int root=find(p[x]);
d[x]^=d[p[x]];
p[x]=root;
}
return p[x];
}
int main(){
for(int i=1;i<N;i++){
p[i]=i;
}
int n=0,m=0;
scanf("%d%d",&n,&m);
for(int i=1;i<=m;i++){
int l=0,r=0;
string type;
cin>>l>>r>>type;
// 我们要判断 l-1和r位置的奇偶性
int x=get(l-1),y=get(r);
//偶数为0 ,奇数为1
int t=0;
if(type=="odd"){
t=1;
}
int px=find(x),py=find(y);
if(px!=py){
p[px]=py;
d[px]=d[x]^d[y]^t;
}else{
if( (d[x]^d[y])!= t){
printf("%d\n",i-1);
return 0;
}
}
}
printf("%d\n",m);
return 0;
}
代码模板:
按秩合并+路径压缩
const int N ; //并查集中的节点个数
int p[N]; //存放节点所在树的根节点
int rank[N] ;//存放秩的数组,每个集合的秩进存放在根节点
void init(){
//初始化,刚开始每个节点都是一棵树,根节点就是它自己
//每个节点的秩为1
for(int i=1;i<=N;i++){
p[i]=i;
rank[i]=1;
}
}
int Find(int x){
if(p[x]!=x){
//路径压缩 优化
p[x]= find(p[x]);
}
return p[x];
}
void Union(int x,int y){
// 找到x,y所在树的根节点
int px=find(x),py=find(y);
//根节点不相同,则不是一棵树,进行合并
if(px!=py){
// 按秩合并 优化
if(rank[px]<=rank[py]){
p[px]=py;
//两个集合的秩相同,合并后的集合在原基础上加1
//原因如下图所示
rank[py]+=(rank[x]==rank[y]?1:0);
}else{
p[py]=px;
}
}
}
维护每个集合的大小
const int N ; //并查集中的节点个数
int p[N]; //存放节点所在树的根节点
int size[N] ;//根节点位置存放集合大小
void init(){
//初始化,刚开始每个节点都是一棵树,根节点就是它自己
//每个集合的大小为1
for(int i=1;i<=N;i++){
p[i]=i;
size[i]=1;
}
}
int Find(int x){
if(p[x]!=x){
//路径压缩 优化
p[x]= find(p[x]);
}
return p[x];
}
void Union(int x,int y){
// 找到x,y所在树的根节点
int px=find(x),py=find(y);
p[px]=py;
size[py]+=size[px];
}
维护到根节点距离
const int N ; //并查集中的节点个数
int p[N]; //存放节点所在树的根节点
int dist[N] ;//到根节点的距离
void init(){
//初始化,刚开始每个节点都是一棵树,根节点就是它自己
for(int i=1;i<=N;i++){
p[i]=i;
dist[i]=0;
}
}
int Find(int x){
if(p[x]!=x){
//路径压缩 优化
int root= find(p[x]);
dist[x]+=dist[p[x]];
p[x]=root;
}
return p[x];
}
void Union(int x,int y){
// 找到x,y所在树的根节点
int px=find(x),py=find(y);
p[px]=py;
size[px] ? 根据具体情况进行初始化
//合并的时候我们仅更新px到合并后根节点py的距离
//原px的其他节点会在find函数中自动更新距离
}
智能推荐
RT-Thread GD32F4xx 看门狗驱动_gd32f4xx实现软件复位-程序员宅基地
文章浏览阅读1.3k次。RT-Thread 下GD32F4xx 独立看门驱动开发与调试记录_gd32f4xx实现软件复位
Linux虚拟机环境搭建spark_linux中使用spark-程序员宅基地
文章浏览阅读577次,点赞4次,收藏5次。Linux环境搭建Spark分为两个版本,分别是Scala版本和Python版本。本环境以 Python 环境为例。_linux中使用spark
Could not find resource mybatis-config.xml :找不到mybatis的配置文件_exception in thread "main" java.io.ioexception: co-程序员宅基地
文章浏览阅读1.4w次,点赞47次,收藏51次。项目场景:之前运行出来过,后面重新导入了一下 结果报错了 (代码是没有问题的)问题描述:Exception in thread “main” java.io.IOException: Could not find resource mybatis-config.xml :找不到mybatis的配置文件原因分析:找不到mybatis配置文件原来mybatis.xml文件没有放在 target 下的 classes 中,导致报错。解决方案:将 mybatis.xml拷贝到 target 下的_exception in thread "main" java.io.ioexception: could not find resource myba
R语言ggplot2可视化使用ggsave将可视化图像结果保存为SVG文件实战-程序员宅基地
文章浏览阅读1.1w次,点赞5次,收藏14次。R语言ggplot2可视化使用ggsave将可视化图像结果保存为SVG文件实战#使用ggsave将可视化图像结果保存为SVG文件 require("ggplot2")#some sample data head(diamonds) #to see actually what will be plotted and compare qplot(clarity, data=diamonds, fill=cut, geom="bar")#save the plot in_ggsave
HTML - 元素/标签详解_元素中的头部-程序员宅基地
文章浏览阅读4.9k次,点赞17次,收藏82次。HTML头部元素 元素包含了所有的头部标签元素。在 元素中你可以插入脚本(scripts), 样式文件(CSS),及各种meta信息。可以添加在头部区域的元素标签为: , , , , , , . 标签定义了不同文档的标题。 在 HTML/XHTML 文档中是必须的。定义了浏览器工具栏的标题当网页添加到收藏夹时,显示在收藏夹中的标题显示在搜索引擎结果页面的标题 标签描述了基本的链接地址/链接目标,_元素中的头部
Spring Boot + MinIO 实现文件切片极速上传技术_spring boot minio实现文件切片极速上-程序员宅基地
文章浏览阅读7.5k次,点赞35次,收藏58次。文件切片上传是指将大文件分割成小的片段,然后通过多个请求并行上传这些片段,最终在服务器端将这些片段合并还原为完整的文件。这种方式有助于规避一些上传过程中的问题,如网络不稳定、上传中断等,并能提高上传速度。通过本文,我们深入了解了如何使用Spring Boot和MinIO实现文件切片上传技术。通过文件切片上传,我们能够提高文件上传的速度,优化用户体验。在实际应用中,我们可以根据需求进行性能优化和功能拓展,使得文件上传系统更加强大和可靠。_spring boot minio实现文件切片极速上
随便推点
温故而知新,一文锤实Redis知识图谱(6)-程序员宅基地
文章浏览阅读956次,点赞22次,收藏21次。Redis 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息队列。它支持多种数据结构,如字符串、列表、集合、有序集合和哈希表。Redis 速度非常快,因为它使用了内存作为存储介质。它还支持持久化,可以将数据定期保存到磁盘。Redis 是用 C 语言编写的,并且可以跨平台运行。它支持 Linux、Windows、Mac OS X 和 Solaris。Redis 非常适合用作缓存,因为它可以非常快速地检索数据。它还可以用作数据库,因为它支持多种数据结构。
尚硅谷和尚学堂的区别_传智播客和尚学堂哪个更好些啊?-程序员宅基地
文章浏览阅读2.7k次。张笑翔,你做个几个企业项目呀?你真会忽悠呀,呵呵,我真佩服你,人面兽心,答应给我们的课时费怎么老是出尔反尔,你当初说一年给我们20万,这也是小数目呀,你一年挣上千万呀,你真是不够意思!!!而且连这20万都给不够数啊!后来才明白你说的是一天课600,一年是600X365=21900,这样是年薪20万,哈哈。如果20万的话,我们要工作333天才能拿到。。。一年的工作日也不过365-52x2=261天。..._尚新途和尚学堂
uni-app怎么获取view距离顶部的高度_uniapp获取view高度-程序员宅基地
文章浏览阅读2.6w次,点赞4次,收藏5次。通过uni.createSelectorQuery() 来实现,注意:要获得的高度,是在页面上已经有了dom之后才能获得const query = uni.createSelectorQuery() query.select('#ListConS').boundingClientRect() query..._uniapp获取view高度
ROS-Noetic踩坑_noetic和melodic有什么区别-程序员宅基地
文章浏览阅读8.8k次,点赞2次,收藏27次。本科时候图方便仅仅使用了Windows下的V-REP(想想用gazebo还要学Linux和ROS就好麻烦…),最近由于需要学习了ROS,也算是填上本科时候埋下的坑(>﹏<)。本文主要针对ROS wiki教程基于ROS Noetic踩得雷做一下总结,关于如何学习ROS,可以参考知乎高赞,马学长的回答ROS学习入门(抛砖引玉篇)。ROS安装目前有在维护的版本有Kinetic、Melodic以及Noetic。由于我的Ubuntu版本是20.04,所以选择了Noetic,并且Noetic是最新版本_noetic和melodic有什么区别
c语言 - main函数参数解释_int main(int argc, char const *argv[])在c语言中什么意思-程序员宅基地
文章浏览阅读482次。选项指定生成的可执行文件的名称。运行程序时,可以在程序名称后面添加任意个数的参数。这个示例程序会将命令行参数的个数、程序名称以及每个参数的值都打印出来。你可以将上面的代码保存为一个名为。举一个在Linux下使用。函数带参数的示例程序。来编译源文件,并使用。_int main(int argc, char const *argv[])在c语言中什么意思
前端对接微信公众号网页开发流程,JSSDK使用_开发微信网页流程-程序员宅基地
文章浏览阅读1.6k次。前面两篇文章讲解了和,本篇文章讲解关于微信JSSDK的使用,_开发微信网页流程