Python爬虫实战---爬取豆瓣瓣电影排行前250的字段并写入MySQL数据库_python用爬虫抓取电影数据存入数据库-程序员宅基地
爬取豆瓣电影Top250
要求:
1、提取:电影名,导演,主演,拍摄时间,拍摄地,电影类型,评分,评论人数,电影宣传图片的url。
2、将提取的数据保存到mysql数据库
3、下载电影宣传图片
环境配置:Anaconda3 + MySql8.0
使用的IDE wingIDE 和 Nvicat Premium 12
简要过程:
1.访问URL,获取总电影数和每页电影数
2.使用生成器生成每一个页面URL,获取:电影名、导演评分、评论人数、电影宣传图片的url
3.访问单个电影的URL,获取:主演、拍摄地、电影类型 、拍摄时间
4.保存电影宣传图片
5.数据入库
效果图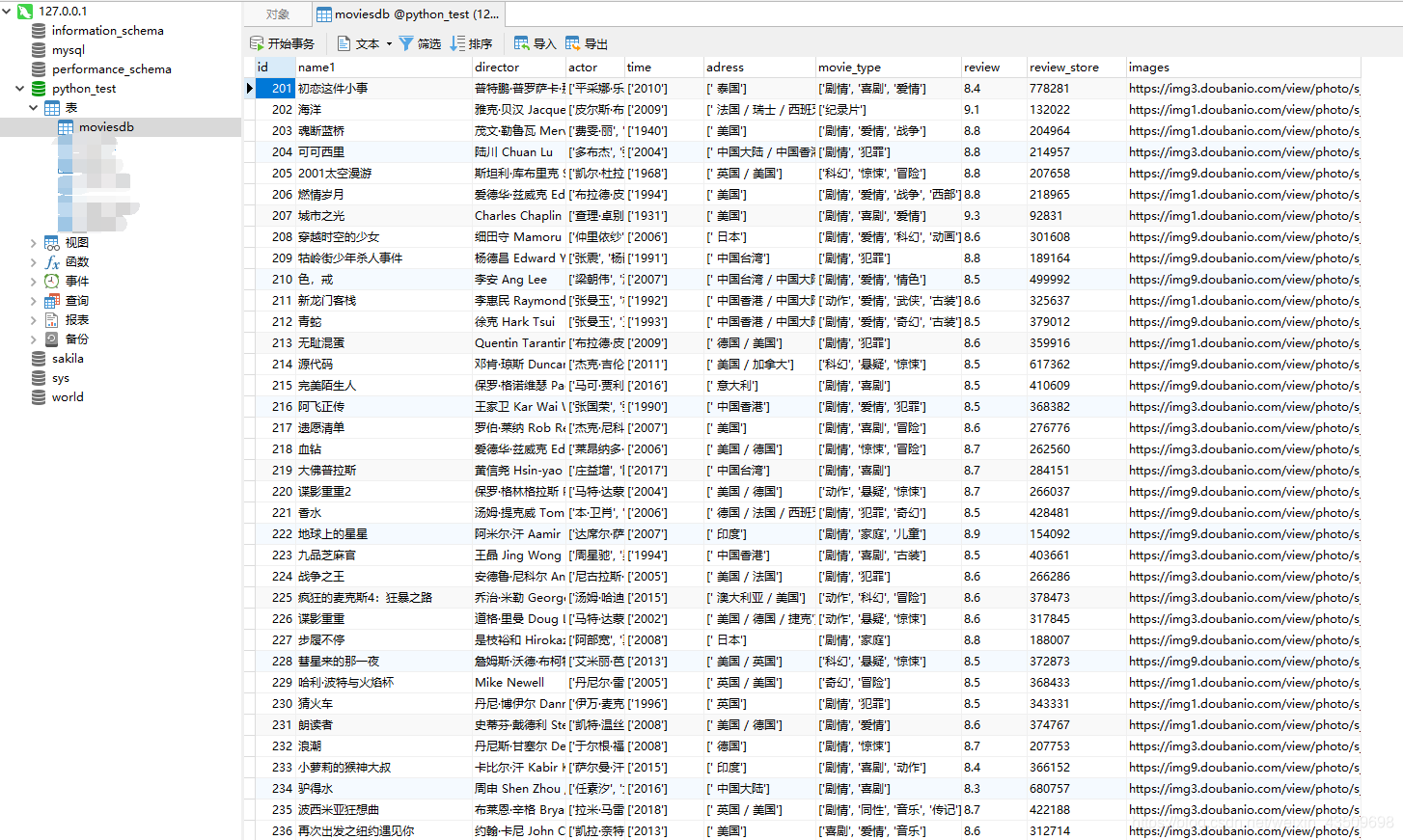
1.dbconfig.json 数据库配置文件
{
"ip": "127.0.0.1",
"port": "3306",
"user": "root",
"pwd": "123456",
"db": "python_test",
"charset": "utf8mb4"
}
2.config.py 解析配置文件
# -*- coding:utf-8 -*-
import json
class DBConfig:
"""
解析连接数据库的配置信息
"""
def __init__(self,file):
"""初始化方法"""
self.flie = file
def config(self):
"""解析文件信息"""
with open(self.flie) as f:
config_info = json.loads(f.read())
return config_info
if __name__ == "__main__":
#config_info = DBConfig("dbconfig.json")
#print(config_info.config())
3.dboperation.py 数据库操作类
# -*- coding:utf-8 -*-
import logging
import pymysql
from config import DBConfig
logging.basicConfig(format="%(asctime)s %(message)s",datefmt="%Y-%m-%d %I:%M:%S %p")
class OperatonBD:
def __init__(self,config1):
self.config1 = config1
self.connect = self.connection_db()
def connection_db(self):
try:
connect = pymysql.connect(host = self.config1["ip"],
port = eval(self.config1["port"]),
user = self.config1["user"],
password = self.config1["pwd"],
db = self.config1["db"],
charset=self.config1["charset"])
logging.warning("数据库连接成功")
return connect
except Exception as e:
logging.error("数据库连接失败",e)
return None
def search_db(self,search_sql):
try:
cursor = self.connect.cursor()
cursor.execute(search_sql)
data = cursor.fetchall()
logging.warning("数据查询成功")
return data
except Exception as e:
logging.error("查询失败",e)
return None
def update_db(self,update_sql):
try:
cursor = self.connect.cursor()
cursor.execute(update_sql)
self.connect.commit()
logging.warning("数据插入成功")
except Exception as e:
logging.error("数据更新失败",insert_sql,e)
self.connect.rollback()
return None
def create_db(self,creat_sql):
try:
cursor = self.connect.cursor()
cursor.execute(creat_sql)
logging.warning("数据表创建成功")
except Exception as e:
logging.error("数据表创建失败",e)
def __del__(self):
self.connect.close()
#if __name__ == "__main__":
#configflie = "dbconfig.json"
#configs = DBConfig(configflie)
#instance = OperatonBD(configs.config())
#instance.connection_db()
#instance.search_db("show databases;")
#instance.update_db("insert into test111 values('23231322111','zhagnshan')")
#instance.create_db("create table if not exists shy111(id int(10),name varchar(100))")
4. sqls.py sql语句类
# -*- coding:utf-8 -*-
class Sql:
#添加数据
def insert_sqls(datas):
insert_sql = f'insert into moviesDB(name1,director,actor,time,adress,movie_type,review,review_store,images) values("{datas[i][0]}","{datas[i][1]}","{datas[i][2]}","{datas[i][3]}","{datas[i][4]}","{datas[i][5]}","{datas[i][6]}","{datas[i][7]}","{datas[i][8]}")'
return insert_sql
#创建表
def create_sqls():
create_sql = """
CREATE TABLE IF NOT EXISTS moviesDB (
id int PRIMARY KEY AUTO_INCREMENT,
name1 text COMMENT "电影名",
director varchar(100) COMMENT "导演",
actor text COMMENT "主演",
time VARCHAR(30) COMMENT "拍摄时间",
adress text COMMENT "拍摄地",
movie_type VARCHAR(30) COMMENT "电影类型",
review VARCHAR(30) COMMENT "评分",
review_store VARCHAR(30) COMMENT "评论人数",
images VARCHAR(1000) COMMENT "电影宣传图片的url"
)
"""
return create_sql
5.myspiderClass.py 主程序
# -*- coding:utf-8 -*-
"""
提取的字段:电影名,导演,主演,拍摄时间,拍摄地,电影类型,评分,评论人数,电影宣传图片的url。
"""
import time
import requests
from lxml import etree
import re
import os
import logging
from dboperation import OperatonBD
from config import DBConfig
from sqls import Sql
logging.basicConfig(format="%(asctime)s %(message)s",datefmt="%Y-%m-%d %I:%M:%S %p") #格式化日志
class Movies:
def __init__(self,instance,urls,data,header):
self.urls = urls
self.data = data
self.header = header
self.instance = instance
self.sql = Sql
self.instance.create_db(self.sql.create_sqls())
def it_url(self,count,n):
"""
定义一个生成器,用于生成每页url的data参数
"""
for i in range(0,count+1,n):
data["start"] = i
yield data
def movies_count(self):
"""用于获取电影的总数"""
try:
response_0 = requests.get(self.urls,headers=self.header)
myhtml_0 = etree.HTML(response_0.text)
b = myhtml_0.xpath("//span[@class='count']/text()") #['(共250条)']
counts = eval(re.search("\d+",myhtml_0.xpath("//span[@class='count']/text()")[0]).group()) #250
n = len(myhtml_0.xpath("//div/a/span[1][@class='title']/text()"))
return counts,n
except Exception as e:
logging.WARNING("请求访问失败",e)
return None
def movies_url(self):
"""获取html"""
count,n = self.movies_count()
try:
for dt in self.it_url(count,n):
global k
response = requests.get(self.urls,headers=self.header,params=dt)
#print(response.url) #用于校验url是否正确
if response.status_code == requests.codes.ok:
html = response.text
if k <= count/n:
logging.warning(f"第{k}请求成功,URL为{response.url}")
self.parsing(html) #调用解析html方法
k = k + 1
except:
return None
def parsing(self,html):
"""用于解析html"""
myhtml = etree.HTML(html)
name = myhtml.xpath("//div[@class='hd']/a/span[1][@class='title']/text()")
directors = myhtml.xpath("//div[@class='bd']/p/text()")
director = [ i for i in directors if "导演" in i] # 取出列表中无导演的字段
dr=director[1][director[1].find(":")+1:director[1].find("主演")].strip() #找出导演
director_list = [ director[i][director[i].find(":")+1:director[i].find("主")].strip() for i in range(len(director))] #导演列表
url_1 = myhtml.xpath("//div[@class='hd']/a/@href") #返回电影的子列表
actor = []
time = []
adress = []
movie_type = []
for url in url_1:
html_1 = requests.get(url,headers=header).text
html_1s = etree.HTML(html_1)
actor.append(html_1s.xpath("//span[@class='actor']/span/a/text()")) #主演
time.append(list(map(lambda x:x.strip("()"),html_1s.xpath("//span[@class='year']/text()")))) #拍摄时间
ad = re.findall('<span class="pl">制片国家/地区:</span>(.*?)<br/>', html_1) #找出拍摄地
adress.append(ad)
movie_type.append(html_1s.xpath("//span[@property='v:genre']/text()")) #电影类型
review = myhtml.xpath("//span[@class='rating_num']/text()") #评分
#b = myhtml.xpath("//div[@class='star']/span[4]/text()") #评论人数列表 '2100959人评价'
review_store = list(map(lambda x:eval(x.replace("人评价","")),myhtml.xpath("//div[@class='star']/span[4]/text()")))
images = myhtml.xpath("//li/div/div/a/img/@src") #图片列表
#电影名,导演,主演,拍摄时间,拍摄地,电影类型,评分,评论人数,电影宣传图片的url
datas = [i for i in zip(name,director_list,actor,time,adress,movie_type,review,review_store,images)]
self.save_date(datas)
def save_date(self,datas):
try:
for i in range(len(datas)):
insert_sql = f'insert into moviesDB(name1,director,actor,time,adress,\movie_type,review,review_store,images) values("{datas[i][0]}","{datas[i][1]}","{datas[i][2]}","{datas[i][3]}","{datas[i][4]}","{datas[i][5]}","{datas[i][6]}","{datas[i][7]}","{datas[i][8]}")'
self.instance.update_db(insert_sql)
time.sleep(2) #防止时间太频繁,造成封IP
image_url = datas[i][8] #获取图片的url
filename = f"./images/{datas[i][0]}.png" #获取图片的名称
self.download_image(image_url,filename) #下载图片
except Exception as e:
print("sql语句错误",e)
def download_image(self,image_url,filename):
if not os.path.isdir("images"):
os.mkdir("images")
r = requests.get(image_url)
with open(filename,"wb") as F:
F.write(r.content)
logging.warning("图片保存成功")
if __name__ == "__main__":
k = 1
configfile = "dbconfig.json"
configs = DBConfig(configfile)
instance = OperatonBD(configs.config())
header = {
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)\
Chrome/84.0.4147.105 Safari/537.36"}
data = {
"start":0,"filter":""}
urls = "https://movie.douban.com/top250"
m = Movies(instance,urls,data,header)
m.movies_url()
注:纸上得来终觉浅,绝知此事要躬行。
智能推荐
zabbix短信告警oracle,zabbix 实现短信告警-程序员宅基地
文章浏览阅读402次。之前一直调用飞信接口发送告警信息,最近购买了第三方短信接口。所以准备使用接口发送告警。短信接口是基于https的摘要认证。https认证还是自己做的,调用接口的时候还需要load证书。感觉超级难用,不管那么多,先让它跑起来再说。废话不多说,先上代码。#!/usr/bin/envpython#coding:utf-8importrequestsfromrequests.authimport..._zabbix实现短信告警
soapui中文操作手册(四)----MOCK服务_soapui设置成中文-程序员宅基地
文章浏览阅读6.8k次,点赞2次,收藏12次。转载地址:http://www.cnblogs.com/zerotest/p/4670005.htmlWeb Service Mocking是武器库一个非常有用的工具。这是解决“如果没有Web服务如何创建针对性的Web服务测试”问题的办法。Web Service Mocking将在这里派上用场。它允许你实际的Web服务产生之前,创建近似或模拟的Web Service。在本教_soapui设置成中文
Swift 包管理器 (SPM):管理 iOS 中的依赖关系_ios spm-程序员宅基地
文章浏览阅读845次,点赞29次,收藏7次。Swift 包管理器 (SPM):管理 iOS 中的依赖关系_ios spm
SCI论文润色真有必要吗?-程序员宅基地
文章浏览阅读381次,点赞10次,收藏7次。总的来说,sci论文润色虽然不会改变论文的学术内容和贡献,但它能够显著的提升论文的质量和可读性,从而增加论文被接受和引用的机会。在论文投稿前都是需要润色的,特别是英文论文投稿,一定得靠谱。但如果是一些小问题,比如语法语句错误,专业言论不恰当,那么你的文章会在投稿过程中外审评定完以后,也会给你返修意见和修改机会。如果是新作者,或者是对自己的语言能力不那么自信,那么是很有必要的。其他人的视角可能会发现你忽略的错误或不清晰的表达,同时也可以提供有关论文结构和逻辑的反馈意见。关于SCI论文润色的常见方法。
Prometheus监控数据格式的学习-程序员宅基地
文章浏览阅读1.1k次,点赞33次,收藏9次。Prometheus 指标(metrics)的数据形式是一种简单的文本格式(容易通过 HTTP 协议被 Prometheus 服务器拉取)。每一行包含了一个指标的数据,通常包括指标名称、可选的一组标签以及指标的值。Prometheus 的指标数据可以有不同类型,如 Counter、Gauge、Histogram 和 Summary,它们的表示形式会有所不同。
数字图像处理(10): OpenCV 图像阈值化处理_binarization threshold-程序员宅基地
文章浏览阅读5.6k次,点赞26次,收藏43次。目录1 什么是阈值化-threshold()2 二进制阈值化3 反二进制阈值化4 截断阈值化5 反阈值化为06 阈值化为07 小结参考资料1 什么是阈值化-threshold()图像的二值化或阈值化 (Binarization)旨在提取图像中的目标物体,将背景以及噪声区分开来。通常会设定一个阈值,通过阈值将图像的像素划分为两类:大于阈值的..._binarization threshold
随便推点
使用安卓模拟器时提示关闭hyper-v_hyperv影响 模拟器-程序员宅基地
文章浏览阅读1.6w次。本电脑是宏碁传奇X,cpu是r7 5800u,显卡rtx3050;使用了雷电、mumu两款安卓模拟器,雷电启动报错g_bGuestPowerOff fastpipeapi.cpp:1161,使用了网上的所有方案都不行,包括开启VT(amd开启SVM),命令关闭hyper-v服务等;尝试mumu模拟器,安装时支持vt项检测不通过,后来发现mumu模拟器在amd的cpu上只支持32位版,换装32位版检测通过,但是只要打开模拟器就提示需要关闭hyper-v,我已经确认关闭后,启动依旧这样提示,查找了网上很_hyperv影响 模拟器
【大厂秘籍】系列 - Mysql索引详解-程序员宅基地
文章浏览阅读564次。MySQL官方对索引定义:是存储引擎用于快速查找记录的一种数据结构。需要额外开辟空间和数据维护工作。● 索引是物理数据页存储,在数据文件中(InnoDB,ibd文件),利用数据页(page)存储。● 索引可以加快检索速度,但是同时也会降低增删改操作速度,索引维护需要代价。
CSS实现当鼠标停留在一个元素上时,使得两个元素的样式发生改变_css鼠标悬浮修改其他元素样式-程序员宅基地
文章浏览阅读825次。使用兄弟选择器实现同时改变两个元素的样式_css鼠标悬浮修改其他元素样式
文献学习-40-基于可迁移性引导的多源模型自适应医学图像分割-程序员宅基地
文章浏览阅读4.8k次,点赞32次,收藏43次。香港中文大学袁奕萱教授团队提出了一种名为多源模型自适应 (MSMA) 的新型无监督域适应方法。MSMA 旨在仅利用预训练的源模型(而非源数据)将知识迁移到未标记的目标域,从而实现对目标域的有效分割。
(4)FPGA开发工具介绍(第1天)-程序员宅基地
文章浏览阅读8.8k次。(4)FPGA开发工具介绍(第1天)1 文章目录1)文章目录2)FPGA初级课程介绍3)FPGA初级课程架构4)FPGA开发工具介绍(第1天)5)技术交流6)参考资料2 FPGA初级课程介绍1)FPGA初级就业课程共100篇文章,目的是为了让想学FPGA的小伙伴快速入门。2)FPGA初级就业课程包括FPGA简介、Verilog HDL基本语法、Verilog HDL 入门实例、FPGA入门实例、Xilinx FPGA IP core设计、Xilinx FPGA原语与U_fpga开发工具
js中的定时器如何使用_js定时器用法-程序员宅基地
文章浏览阅读1.4k次。JS提供了一些原生方法来实现延时去执行某一段代码,下面来简单介绍一下setTiemout、setInterval、setImmediate、requestAnimationFrame。首先,我们先来了解一下什么是定时器:JS提供了一些原生方法来实现延时去执行某一段代码下面来简单介绍一下setTimeout() :在指定的毫秒数后调用函数或计算表达式。setTimeout(code,millisec,lang)参数 描述code 必需。要调用的函数后要执行的 JavaScript 代码串。_js定时器用法