分层图最短路--最通俗易懂的讲解_分层最短路-程序员宅基地
技术标签: 【算法知识】
分层图最短路是指在可以进行分层图的图上解决最短路问题。分层图:可以理解为有多个平行的图。
一般模型是:在一个正常的图上可以进行 k 次决策,对于每次决策,不影响图的结构,只影响目前的状态或代价。一般将决策前的状态和决策后的状态之间连接一条权值为决策代价的边,表示付出该代价后就可以转换状态了。
一般有两种方法解决分层图最短路问题:
- 建图时直接建成k+1层。
- 多开一维记录机会信息。
当然具体选择哪一种方法,看数据范围吧 。
第一种方法:
我们建k+1层图。然后有边的两个点,多建一条到下一层边权为0的单向边,如果走了这条边就表示用了一次机会。
有N个点时,1~n表示第一层,(1+n)~(n+n)代表第二层,(1+2*n)~(n+2*n)代表第三层,(1+i*n)~(n+i*n)代表第i+1层。因为要建K+1层图,数组要开到n * ( k + 1),点的个数也为n * ( k + 1 ) 。
对于数据:
n = 4,m = 3, k = 2
0 1 100
1 2 100
2 3 100
建成图之后大概是这样的:
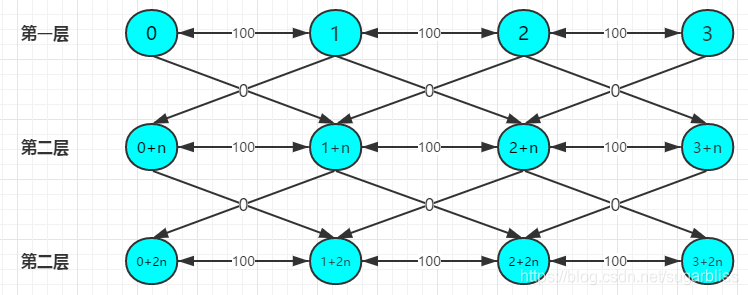
对于上面的数据:答案就是3,3+n,3+2n,中的最小值。
第一种模板:
#include <iostream>
#include <string.h>
#include <stdio.h>
#include <algorithm>
#include <queue>
#include <vector>
#define ll long long
#define inf 0x3f3f3f3f
#define pii pair<int, int>
const int mod = 1e9+7;
const int maxn = 5e4 * 42;
using namespace std;
struct node {int to,w,next;} edge[maxn];
int head[maxn], cnt;
int dis[maxn], vis[maxn];
int n, m, s, t, k;
struct Dijkstra
{
void init()
{
memset(head,-1,sizeof(head));
memset(dis,0x3f,sizeof(dis));
memset(vis,0,sizeof(vis));
cnt = 0;
}
void add(int u,int v,int w)
{
edge[cnt].to = v;
edge[cnt].w = w;
edge[cnt].next = head[u];
head[u] = cnt ++;
}
void dijkstra()
{
priority_queue<pii,vector<pii>,greater<pii> > q;
dis[s] = 0; q.push({dis[s],s});
while(!q.empty())
{
int now = q.top().second;
q.pop();
if(vis[now]) continue;
vis[now] = 1;
for(int i = head[now]; i != -1; i = edge[i].next)
{
int v = edge[i].to;
if(!vis[v] && dis[v] > dis[now] + edge[i].w)
{
dis[v] = dis[now] + edge[i].w;
q.push({dis[v],v});
}
}
}
}
}dj;
int main()
{
while(~scanf("%d%d%d", &n, &m, &k))
{
dj.init(); scanf("%d%d",&s,&t);
while(m--)
{
int u, v, w;
scanf("%d%d%d",&u, &v, &w);
for(int i = 0; i <= k; i++)
{
dj.add(u + i * n, v + i * n, w);
dj.add(v + i * n, u + i * n, w);
if(i != k)
{
dj.add(u + i * n, v + (i + 1) * n, 0);
dj.add(v + i * n, u + (i + 1) * n, 0);
}
}
}
dj.dijkstra(); int ans = inf;
for(int i = 0; i <= k; i++)
ans = min(ans, dis[t + i * n]);
printf("%d\n",ans);
}
}第二种方法:
我们把dis数组和vis数组多开一维记录k次机会的信息。
- dis[ i ][ j ] 代表到达 i 用了 j 次免费机会的最小花费.
- vis[ i ][ j ] 代表到达 i 用了 j 次免费机会的情况是否出现过.
更新的时候先更新同层之间(即花费免费机会相同)的最短路,然后更新从该层到下一层(即再花费一次免费机会)的最短路。
- 不使用机会 dis[v][c] = min(min,dis[now][c] + edge[i].w);
- 使用机会 dis[v][c+1] = min(dis[v][c+1],dis[now][c]);
对于数据:
n = 4,m = 3, k = 2
0 1 100
1 2 100
2 3 100
建成图之后大概是这样的:
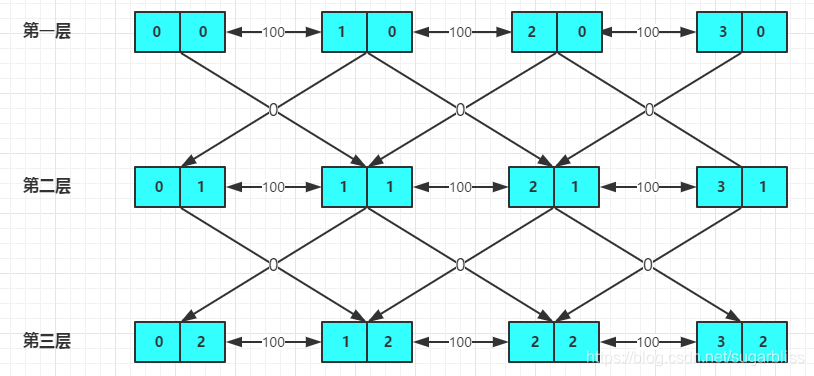
第二种模板:
#include <iostream>
#include <string.h>
#include <stdio.h>
#include <algorithm>
#include <queue>
#include <vector>
#define ll long long
#define inf 0x3f3f3f3f
#define pii pair<int, int>
const int mod = 1e9+7;
const int maxn = 1e5+7;
using namespace std;
struct node{int to, w, next, cost; } edge[maxn];
int head[maxn], cnt;
int dis[maxn][15], vis[maxn][15];
int n, m, s, t, k;
struct Dijkstra
{
void init()
{
memset(head,-1,sizeof(head));
memset(dis,127,sizeof(dis));
memset(vis,0,sizeof(vis));
cnt = 0;
}
void add(int u,int v,int w)
{
edge[cnt].to = v;
edge[cnt].w = w;
edge[cnt].next = head[u];
head[u] = cnt ++;
}
void dijkstra()
{
priority_queue <pii, vector<pii>, greater<pii> > q;
dis[s][0] = 0;
q.push({0, s});
while(!q.empty())
{
int now = q.top().second; q.pop();
int c = now / n; now %= n;
if(vis[now][c]) continue;
vis[now][c] = 1;
for(int i = head[now]; i != -1; i = edge[i].next)
{
int v = edge[i].to;
if(!vis[v][c] && dis[v][c] > dis[now][c] + edge[i].w)
{
dis[v][c] = dis[now][c] + edge[i].w;
q.push({dis[v][c], v + c * n});
}
}
if(c < k)
{
for(int i = head[now]; i != -1; i = edge[i].next)
{
int v = edge[i].to;
if(!vis[v][c+1] && dis[v][c+1] > dis[now][c])
{
dis[v][c+1] = dis[now][c];
q.push({dis[v][c+1], v + (c + 1) * n});
}
}
}
}
}
}dj;
int main()
{
while(~scanf("%d%d%d", &n, &m, &k))
{
dj.init(); scanf("%d%d",&s,&t);
while(m--)
{
int u, v, w;
scanf("%d%d%d",&u, &v, &w);
dj.add(u, v, w);
dj.add(v, u, w);
}
dj.dijkstra();
int ans = inf;
for(int i = 0; i <= k; i++)
ans = min(ans, dis[t][i]);
printf("%d\n", ans);
}
}
/*
5 6 1
0 4
0 1 5
1 2 5
2 3 5
3 4 5
2 3 3
0 2 100
*/
智能推荐
机器学习——EM算法及代码实现_用代码来实现em算法-程序员宅基地
文章浏览阅读1w次,点赞33次,收藏167次。EM算法是一种迭代算法,用于含有隐变量的概率模型参数的极大似然估计或极大后验估计。预备知识:用Y表示观测随机变量的数据,Z表示隐随机变量的数据。Y和Z连在一起称为完全数据,观测数据Y又称为不完全数据。给定观测数据Y,其概率分布是P(Y|θ),其中θ是需要估计的模型参数,它相应的对数似然估计L(θ)=logP(Y|θ)。假设Y和Z的联合概率分布是P(Y,Z|θ),那么完全数据的对数似然函数是lo..._用代码来实现em算法
Word VBA中读取Excel表格中的数据_wordvba调用excel-程序员宅基地
文章浏览阅读6.6k次,点赞5次,收藏43次。Word VBA中读取Excel表格中的数据前天有一个项目需要写详细设计报告,其中有一块重要内容是把Excel中的每一行数据做成一个Word中的表格。一共将近100行数据,如果我一行一行地手动去做,估计手就废了,于是采用Word VBA。基本编程思路创建一个空word文档word文档中,编辑好一个示例表格,作为一个母表,后续所有的表格程序都是复制这张表,然后修改复制后的新表格的数据打开Excel,遍历每一行数据取这一行关键数据,复制母表,改变复制后的表格数据代码片段Dim wb As D_wordvba调用excel
es 报表聚合,分组,求和,排序,合计,分页等综合应用_es 求和-程序员宅基地
文章浏览阅读5k次。一,最终实现:查询条件及查询结果如下图所示需要实现:分组,求和,聚合后排序,总计,分页二, 需求分析:关于分组维度es数据主键为:日期(年月日)+采购组织+采购组+门店统计维度:可根据是否选择门店,按日或按月统计可分为四种情况日+采购组织+采购组;采购组织+采购组;日+采购组织+采购组+门店;月+采购组织+采购组+门店;按正常es多条件分组求和处理方式很麻烦,可参考网上写法。可以转变思路,把每个维度拼接成一个字段,即新增四个字段,多条件分组统计转化为单条件分组统计,实现起来会简._es 求和
C和C++面试秘笈三——引用和指针(2)_c++面试二级指针,指针引用等-程序员宅基地
文章浏览阅读180次。一、指针数组和数组指针的应用先看下面这一段代码。#include <stdio.h>#include <stdlib.h>int main(){ char *str[] = { "Welcome", "to", "Fortemedia", "Nanjing" }; //第一行 char **p = str + 1; _c++面试二级指针,指针引用等
C#调用Halcon中的HOperatorSet.OpenFramegrabber报错8600解决方法_halcondotnet.hoperatorexception:鈥淗alcon error #860-程序员宅基地
文章浏览阅读5.5k次,点赞2次,收藏6次。最近在研究一个C#和Halcon结合编程的程序,其中运行的时候会出现一个错误,如下:HALCON error #8600: Dynamic library could not be opened in operator open_framegrabber由于调用了Halcon中的一个算子,如下:HOperatorSet.OpenFramegrabber(“GigEVision”, 0, 0, 0, 0, 0, 0, “default”, -1,“default”, -1, “false”, “defa_halcondotnet.hoperatorexception:鈥淗alcon error #8600: dynamic library could
IOS开发之——事件处理-hiTest(69)-程序员宅基地
文章浏览阅读321次。一 概述hiTest方法的介绍hiTest底层实现原理hiTest练习二 hiTest方法的介绍2.1 hiTest方法介绍- (UIView *)hitTest:(CGPoint)point withEvent:(UIEvent *)event2.2 何时调用当事件传递给一个控件的时候就会调用2.3 调用过程看窗口是否能接收,如果不能return nil;自己不能接收事件,也不能处理事件,而且也不能把事件传递给子控件判断点在不在窗口上,如果点在窗口上,意味着窗口满足合适的v_hitest
随便推点
在ubuntu16.04上编译android源码【转】-程序员宅基地
文章浏览阅读111次。本文转载自:http://blog.csdn.net/fuchaosz/article/details/514875851 前言经过3天奋战,终于在Ubuntu 16.04上把Android6.0的源码编译出来了,各种配置,各种error,各种爬坑,特写此博客记录爬坑经历。先上图,Ubuntu上编译完后成功运行模拟器,如图:2 编译环境UbuntuKylin 1..._256g可以装ubuntu编译android源码吗
程序员在搭建网站要考虑的事情-程序员宅基地
文章浏览阅读124次。程序员在搭建网站要考虑的事情 PHP程序员在架构网站的时候,怎么才能使开发网站访问速度快,安全。 一、HTML静态化 我们都知道,效率最高、消耗最小的就是纯静态化的HTML..._自建网站平台可以实现哪些功能
python gdbm_讨论 - 廖雪峰的官方网站-程序员宅基地
文章浏览阅读651次。kaz:~ tonghua$ brew install python3==> Installing dependencies for python: gdbm**,** [email protected]**,** readline**,** sqlite and xz==> Installing python dependency: gdbmcurl: (7) Couldn't connect ..._failed to download resource "gdbm
HDU---4819:Mosaic【二维线段树】_hdu 4819-程序员宅基地
文章浏览阅读298次。题意:给定一个N*N的矩阵,每个格子都有一个数,再给出Q个询问,每次询问以(x,y)为中心的边长为L的正方形矩阵中的最大值和最小值,并修改(x,y)的值为(MAX+MIN)/2分析:1)四叉树对于查询矩阵的最值+修改问题,考虑二维线段树,参照一维线段树的写法:每次将区间二分成两个子区间,对应矩阵应对X,Y同时二分,也就是4个子矩阵,即左上、右上、左下,右下四部分,所以要建一颗四叉树..._hdu 4819
(四)多对多模式_多人可以有多条记录算多对多模式吗-程序员宅基地
文章浏览阅读3.2w次,点赞6次,收藏23次。连载之5原创:胖子刘(转载请注明出处及作者,谢谢。)(四)多对多模式多对多模式,也是比较常见的一种数据库设计模式,它所描述的两个对象不分主次、地位对等、互为一对多的关系。对于A表来说,一条记录对应着B表的多条记录,反过来对于B表来说,一条记录也对应着A表的多条记录,这种情况就是“多对多模式”。“多对多模式”需要在A表和B表之间有一个关联表,这个关联表也是“多对多模式”的核心所在_多人可以有多条记录算多对多模式吗
Error resolving template_error resolving template [20231016005427_83fe89f42-程序员宅基地
文章浏览阅读5.4k次。Error resolving template [JD/insert], template might not exist or might not be accessible by any of the configured Template Resolvers在调试接口的时候遇到了这个问题我的解决方法修改接口的@Controller=>@RestController..._error resolving template [20231016005427_83fe89f424141e9e286ff8831b3f9ada_.j