C/C++ 归纳总结(杂)_c/c++ <<=-程序员宅基地
技术标签: C++
- 三元操作符
x=(y==z)?5:4-
::为与操作符
例如在main函数之外定义变量value,此时value为全局变量,则在main函数内可以通过::来对全局变量value进行赋值等操作,若单单对value操作,则可以被理解为是对main局部变量value进行操作。
-
++i和i++的效率之比
Operator Operator::operator++()
{
++value; //内部成员变量
return *this;
}
Operator Operator::operator++(int)
{
Operator temp;
temp.value=value;//从上面代码可以看出,后置++多了一个保存临时对象的操作,因此效率自然低一些。
value++;
return temp;
}对于C++内置类型,两者的效率差别不大;
对于自定义的类而言,++i 的效率更高一些。
- ++i和i++ 执行顺序
int i = 0;
while (++i) {//或改成i++
cout << i << endl;
if (i == 10)
break;
}- ++i:先加再判断,则会输出1-10。(先加再执行)
- i++:先判断再加,则一开始i=0,即是false,所以什么也没输出。(先执行再加)
- swap函数通过加减(可能发生数据溢出)或者异或(推荐)可以不产生临时变量tem
- C与C++的区别
C是面向过程化的
C++拥有面向对象的特性,首要考虑的是如何构造一个对象模型。
- extern作用
基本解释:extern可以置于变量或者函数前,以标示变量或者函数的定义在别的文件中,提示编译器遇到此变量和函数时在其他模块中寻找其定义。
第一个作用:当它与"C"一起连用时,如: extern "C" void fun(int a, int b);则告诉编译器在编译fun这个函数名时按着C的规则去翻译相应的函数名而不是C++的,C++语言在编译的时候为了解决函数的多态问题,会将函数名和参数联合起来生成一个中间的函数名称,而C语言则不会,因此会造成链接时找不到对应函数的情况,此时C函数就需要用extern “C”进行链接指定,这告诉编译器,请保持我的名称,不要给我生成用于链接的中间函数名。
第二个作用:当extern不与"C"在一起修饰变量或函数时,如在头文件中: extern int g_Int; 它的作用就是声明函数或全局变量的作用范围的关键字,其声明的函数和变量可以在本模块活其他模块中使用,记住它是一个声明不是定义!也就是说B模块(编译单元)要是引用模块(编译单元)A中定义的全局变量或函数时,它只要包含A模块的头文件即可,在编译阶段,模块B虽然找不到该函数或变量,但它不会报错,它会在连接时从模块A生成的目标代码中找到此函数。
- #include < .h> 和 #include " .h"
<>先去系统目录中找头文件,如果没有在到当前目录下找。所以像标准的头文件 stdio.h、stdlib.h等用这个方法。
而""首先在当前目录下寻找,如果找不到,再到系统目录中寻找。 这个用于include自定义的头文件,让系统优先使用当前目录中定义的。
- atexit()
atexit函数是一个特殊的函数,它是在正常程序退出时调用的函数,我们把他叫为登记函数(函数原型:int atexit (void (*)(void))):
例如:atexit(fun1);atexit(fun2);
先进后出,先使用后执行,即先执行fun2(),后执行fun1()。
- define
- define max(x,y) (((x)>(y))?(x):(y))
- define arr_size(a) ((size_of(a))/(size_of(a[0])))
在C或C++语言源程序中允许用一个标识符来表示一个字符串,称为“宏”。被定义为“宏”的标识符称为“宏名”。在编译预处理时,对程序中所有出现的“宏名”,都用宏定义中的字符串去代换,这称为“宏代换”或“宏展开”。宏定义是由源程序中的宏定义命令完成的。宏代换是由预处理程序自动完成的。
其中的“#”表示这是一条预处理命令。凡是以“#”开头的均为预处理命令。
宏只是简单的文本替换,参数需要用括号小心的括起来!
-
const int * ,int const * ,int * const以及const int* const
- const int *a:首先要清楚,a是什么。a是指针,前面不管是const int,亦或是int const,只不过是修饰指针的而已,所以a本质上来说还是一个指针。既然是指针,就要知道它指向谁。明显,它指向一个常整形,那就说明,const修饰的int,而不是指针,也就说明指针指向的常对象是不可以改变的,但指针可以改变其要指向的哪个对象
- int * const a(int const *) 此时const 修饰 p ,也就是指针,说明这个指针是常量,既然是常量,那就要初始化指针且在以后的程序中不可再次出现修改此指针的代码出现,但指针指向的对象是可以改变的。
- const int* const a二者皆不可以改变
#include <iostream> using namespace std; int main() { int a=10; int b=20; const int* p1=&a; int const* p2=&b; p1=&b;//true *p1=5;//false p2=&a;//false *p2=5;//true }
- const 和define 的区别
define只是用作文本替换,他的生命周期存在于编译期,存在在代码段,无数据类型。
const 存在于数据段,并在堆栈上分配了空间,他可以被调用传递,也有数据类型。
- const 作用
1、定义不可改变的常量,防止误改动,可以通过指针(地址)修改常量的值
2、const修饰函数形式参数:
void fnu(A a,A b){}//效率低 void fnu(A const &a,A const &b){}A为自定义的一个类,第一个函数在调用时需要复制参数a、b,临时对象的复制构造析构都需要消耗时间。
而第二个采用了引用操作,提高了效率,加const可以保证不改变a,b。
3、const修饰函数返回值:返回值智能杯赋值给加const修饰的同类型指针。
const char *Getchar(void){}; char *ar=Getchar();//false const char *br=Getchar();//correct,因此br不可被修改4、const修饰类成员函数:若该成员函数并不对数据成员进行修改, 应尽可能将该成员函数声明为const成员函数。若将成员函数声明为const,则不允许通过其修改类的数据成员。
class Screen { public: char get() const; }; char Screen :: get() const { return _screen[_cursor]; }
- static作用
1、静态局部变量(在函数内定义的静态变量):静态局部变量属于内部变量,其作用域仅限于定义它的函数内;生存期为整个源程序,但其它函数是不能使用它的。只能初始化一次(分清初始化和赋值的区别)
2、静态全局变量(函数外定义):作用域为定义它的源文件内;生存期为整个源程序,但其它源文件中的函数也是不能使用它的。
3、静态函数: 作用域为定义它的源文件内;生存期为整个源程序,但其它源文件中的函数也是不能使用它的。(static在内存中只有一份,而其他函数在调用中维持一份复制品)
- 静态成员函数和静态成员变量
- 静态成员变量:不属于类的实例,属于类本身,调用它们时要加上操作符::或者指定this指针,作用域在类内。
静态成员变量受private控制字的影响,公用的静态数据成员,所以在类外可以直接引用。可以看到在类外可以通过对象名(实例)引用公用的静态数据成员,也可以通过类名引用静态数据成员。即使没有定义类对象,也可以通过类名引用静态数据成员。如果静态数据成员被定义为私有的,则不能在类外直接引用,而必须通过公用的成员函数引用。
- 静态成员变量初始化:类中的静态成员变量必须在类内声明,在类外初始化。
class Demo { static int i; }; int Demo::i=0
- 静态成员函数:因为不含this指针,因此不可直接访问普通成员变量,不知道是谁的普通成员变量,不属于类的实例,属于类本身,调用它们时要加上操作符::或者指定this指针(注意与inline的区别,inline是类内声明时不需要,而在类外初始化时需要加上关键字,因为类内声明且初始化的成员函数默认为inline函数)
class Demo { static void StaticSetI(Demo& d, int v); //或者如下直接在类内定义 //static void StaticSetI(Demo& d, int v){d.i = v;} int i; }; void Demo::StaticSetI(Demo& d, int v) { d.i = v;//普通成员函数蕴含this指针,而static不含,因此需要指明i是谁的i }
- 普通变量所占空间
- char str[]="Hello"; ->size_of(str)=6
- int n=0; ->size_of(n)=4——(32位系统、64位系统都是4字节)
- char *p=str ->size_of(p)=4——(32位系统就是4字节,64位系统就是8字节)
- (long)/(unsigned long)=4 ->(32位系统就是4字节,64位系统就是8字节)
- (bool)=1——(short)=2——(float)=4——(double)=8——(long long)=8
void fun(char str[100]){ size_of(str);//4,str为地址,被认为是指针 }
- strlen和size_of
char str[]="0123456" cout<<size_of(str);//8 cout<<strlen(str);//7 char str[20]="0123456" cout<<size_of(str);//20 cout<<strlen(str);//7 char *ss="0123456" cout<<size_of(ss);//4 cout<<strlen(ss);//7
- size_of(union)->联合体的大小取决于它所有成员中占用空间最大的一个成员的大小(注意:还存在CPU对齐)
#include <iostream> using namespace std; union Test{ struct{ int x; int y; int z; }s; int k; }myUnion; int main() { myUnion.s.x = 4; myUnion.s.y = 5; myUnion.s.z = 6; myUnion.k = 0; cout<< myUnion.s.x <<endl; cout<< myUnion.s.y <<endl; cout<< myUnion.s.z <<endl; cout<< myUnion.k <<endl; }union类型是共享内存的,以size最大的结构作为自己的大小。每个数据成员在内存中得其实地址是相同的。这样的话,myun这个结构就包含u这个结构体,而大小也等于u这个结构体的大小,在内存中的排列为声明的顺序x,y,z从低到高,然后赋值的时候,在内存中,就是x的位置放置4,y的位置放置5,z的位置放置6,现在对k赋值,对k的赋值因为是union,要共享内存,所以从union的首地址开始放置,首地址开始的位置其实是x的位置,这样原来内存中x的位置就被k所赋的值代替了,就变为0了,这个时候要进行打印,就直接看内存里就行了,x的位置也就是k的位置是0,而y,z的位置的值没有改变。
- 注意:还存在CPU对齐(#pragma pack(n)->n默认为8)
union u { char c[9];//占内存9 int a;//占内存4 };取8,9,4中的最小值,即4,因此其内存大小始终为4字节的倍数,因此为12字节
- #pragma pack(n)->改变编译器的对齐方式,不使用这条指令的情况下,编译器默认采取#pragma pack(8)也就是8字节的默认对齐方式
C++故有类型的对齐取编译期对齐方式与自身大小中较小的一个。例如
#pragma pack(2) union u { char c[9]; int n=4; };取2,9,4中的最小值,即2,因此其内存大小始终为2字节的倍数,因此为10字节
测试大小端模式。
- 内联函数(inline)
- inline目的:替代C语言中宏定义来解决程序中函数调用效率的问题。
- 使用场合:
class A { int a; int read(){reutrn a;} void set(int i); }; inline void A::set(int i){a=i;}函数定义放在类声明中,则自动转换为inline函数;
成员函数定义放在类声明外(普通函数),则需要加上inline关键字
- 优点:
- 内联函数使用时直接镶嵌到目标代码中,没有调用开销,提高效率
- 内联函数是函数,可成为某个类的成员函数,会进行类型、语句检查,返回值可以进行强制转换
- 缺点:
- 并非所有的函数都可以成为内联函数,内联函数是以代码膨胀(复制)为代价的,当代码执行开销比调用开销大时,效率收获少,但此时代码量大,消耗内存多,得不偿失。
- 代码量多的函数以及循环内部的函数不可转换为内联函数
- inline和define的区别
- define是直接进行文本替换,是文本,而inline是将函数镶嵌至目标代码中,是函数
- inline会自动进行类型、语句检查,而define不会
- inline是在编译时期展开,而define则是在预编译时期展开
- 类、结构体、联合体定义的时候记得在{ }末尾加上; !!
-
关于cout输出char*的坑。
int main() { char a[] = "c"; char b = 'b'; cout << &a << endl;//第16种重载方式,输出字符串a的首地址 cout << &b << endl;//第13种重载方式,输出乱码 cout << (void *)&a << endl;//第16种重载方式,输出字符串a的首地址 cout << (void *)&b << endl;//类型强制转换,第16种重载方式,输出字符b的首地址 const char *c = "abc"; cout << c << endl;//第13种重载方式,输出abc cout << (void*)c << endl;//类型强制转换,第16种重载方式,输出字符串c的首地址 cout << *c << endl;//第13种重载方式,输出a cout << &c << endl;//第16种重载方式,输出指向指针c的地址 system("pause"); return 0; }
- 为什么第五行cout << &b << endl;会输出乱码,原因是<<运算符重载,为了省去我们循环输出字符的麻烦,cout<<&b;被翻译为输出b指向的字符串值,但此时b是地址,因此乱码。
- 为什么第十二行cout << c << endl;输出abc,原因还是<<运算符重载,为了省去我们循环输出字符的麻烦,cout<<c;被翻译为输出c指向的字符串值,即是abc\n,而不是输出地址值
- 字符串、指针、int在内存中存放的顺序
- 字符串是从小到大依次排序(高位存放在低地址)
- 指针以及int是从大到小依次排序(高位存放在高地址)



-
对char* 和 char[]区别的一些理解
int main() { char b[] = "Hello World"; cout << (void*)b << endl;//输出地址b,由于编译器对<<重载,导致cout<<b<<endl;直接输出字符串 cout << &b << endl; cout << *b << endl; const char *c = "Hello World"; cout << (void*)c << endl;//输出地址c,由于编译器对<<重载,导致cout<<c<<endl;直接输出字符串 cout << &c << endl; cout << *c << endl; system("pause"); return 0; }
- const char * c="Hello World";是实现了3个操作: (&c!=c)
1、声明一个char*变量(也就是声明了一个指向char的指针变量)。
2、在内存中的文字常量区中开辟了一个空间存储字符串常量"Hello World"。
3、返回这个区域的地址,作为值,赋给这个字符指针变量a
最终的结果:指针变量a指向了这一个字符串常量“string1”- char b[] = "Hello World";则是实现了2个操作: (&b=b)
1声明一个char 的数组,
2为该数组“赋值”,即将”Hello World”的每一个字符分别赋值给数组的每一个元素,存储在栈上。
最终的结果:“数组的值”(注意不是b的值)等于”Hello World”,而不是b指向一个字符串常量const char *c = "Hello World";
c是const char *类型,可以类比const int*,即指针指向可以改变,但指针指向的值不可改变。
- char b[] = "Hello World";
b是 char const *类型,可以类比 int const*,即指针指向不可以改变,但指针指向的值可改变。
- 作为函数的声明的参数的时候,char []是被当做char *来处理的!两种形参声明写法完全等效!
class CxString { public: char *_pstr; int _size; CxString(const char *p){} }; // 下面是调用: int main() { CxString string6 = "c"; }可以看到,"c"实际上const char [2],然后将const char [2]传入进const char *,相当于传入地址进入函数
而当程序改成CxString string6 = 'c'; 时则会报错,因为char不可转换成char*。

- typedef
- 参考文章:https://blog.csdn.net/hai008007/article/details/80651886#commentBox
- 任何声明变量的语句前面加上typedef之后,原来是变量的都变成一种类型。不管这个声明中的标识符号出现在中间还是最后.
typedef int NUM; NUM a = 10; // 也可写成`NUM(a) = 10;` NUM(b) = 12; // 也可写成`NUM b = 12;`
- 复杂typedef
- void * (* (*fp1) (int)) [10];
fp1是指针,往外层括号看,是一个函数指针,输入参数是int,输出参数是指针,是什么指针呢,是一个大小为10的数组,数组里面有什么呢,有指向void的指针。
- float (* (*fp2) (int, int, float)) (int);
fp2是指针,往外看,是一个函数指针,其输入参数是(int,int,float),输出是一个指针,是什么指针呢,是一个函数指针,输入参数是int,输出参数是float。
- int (* (*fp4()) [10]) ();
fp4是一个函数声明,输入参数无,输出参数是一个指针,什么指针呢,是一个指向数组大小为10的指针,数组里面有什么呢,有函数指针,输入参数无,输出参数是int。
- void (*b[10]) (void (*)());
//typedef 简化 void (*b[10]) (void (*)()); typedef void (*pParam) (); typedef void (*B) (pParam); B b[10];
- 关于delete和delete []
在这个函数中,我使用了str = new char[strlen(tem.str) + 1];但只使用了delete str;通过内存调试来看,这样是ok的。因为这是简单类型,像int/char/long/int*/struct等等简单数据类型,分配简单类型内存时,内存大小已经确定,系统可以记忆并且进行管理,因此delete str 和delete []str是等效。
而在自定义类型中,比如自定义一个类的时候,A* p= new A[3];delete p;这样才只调用了p[0]的析构函数,造成了内存泄露,而使用了delete[]则调用了3个Babe对象的析构函数。
- free(delete)和malloc(free)的区别
对于内部数据(int、char、float...)等等而言,free(delete)和malloc(free)没什么区别,但是对于非内部数据而言,例如自己构造的类,用malloc(free)是库函数而不是运算符,不能执行构造函数和析构函数;而free(delete)是运算符,编译器需要进行进一步解释,因此可以。
- 运算符和函数的区别
- 语法形式上有区别
- 运算符只能重载,不能自定义,函数的名字随便起,只要是个标识符就行;但运算符不行,比如,你无法仿照其他语言的符号,自定义一个乘法运算符“”**“”
- 任何函数都可以重载或者覆盖,但通常你不能改变运算符作用于内置类型的行为,比如你不能通过重载"operator+",让3+2产生6.
运算符本质上也是函数。只是运算符是编译器需要进行进一步解释。而函数是直接调用。
- cin.getline
cin.getline(接收字符串的变量,接收字符个数,结束字符)
当第三个参数省略时,系统默认为'\0' (回车键),因此在默认情况下getline可以接受空格并输出。
#include <iostream> using namespace std; main () { char m[20]; cin.getline(m,5); cout<<m<<endl; }
- while 与 ++ 结合起来注意事项
const char *a = "I am from China"; while (*a++ != '\0') { cout << *a; }注意,++在判断完*a != '\0'之后就执行了,而不是在此次while结束时++,其实也很好理解,因为++是在括号里面的,跟判断有关系,但跟while无太大关联。
-
为什么C++中stack的pop()函数不返回值而返回void
Stack stack; Object object;//Object是一个类,object是类的实例化。 stack.push(object); Object obj=stack.pop() ;//Object是一个类,obj是类的实例化。效率原因:
- 当一个栈顶元素被弹出(pop)后,假设返回的是值(假设值是自定义类型,例如自己创建的某一个类的实例),那么由于此时类的实例已经是在栈外的了,则必然需要在函数内部生成一个临时变量保存此类实例化,那么就需要产生有构造函数以及return后的析构函数,除此之外,在return时,要将函数内部的实例化传至函数之外,那么就需要调用其类的复制构造函数,这样的话,效率将会降低。
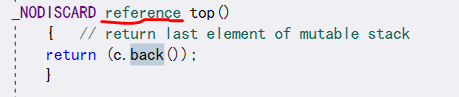
- 这也可以解释为什么要用top()来返回值,我们可以看其原码(如下图),可以看到,top()使用的是引用,因为此时类的实例仍然是在stack里面的,因此可以使用引用,而引用则不会产生上面的诸类问题,因此大大提升了效率。
贴一段看起来是官方解释的话:
One might wonder why pop() returns void, instead of value_type. That is, why must one use top() and pop() to examine and remove the top element, instead of combining the two in a single member function? In fact, there is a good reason for this design. If pop() returned the top element, it would have to return by value rather than by reference: return by reference would create a dangling pointer. Return by value, however, is inefficient: it involves at least one redundant copy constructor call. Since it is impossible for pop() to return a value in such a way as to be both efficient and correct, it is more sensible for it to return no value at all and to require clients to use top() to inspect the value at the top of the stack.
- swap函数中单指针以及双指针的区别
- 指针三要素(int *p=new int(1);)
&p(指针的地址)->p(整形1的地址)->*p(整形1地址上的内容,即为1)
- 单指针(传入参数是目标内容的地址)
#include <iostream> using namespace std; void swap_self(int* e, int* f) { int *tem; tem = e; e = f; f = tem; } int main() { int a = 3; int d = 4; int *b = &a; int *c = &d; swap_self(b, c); system("pause"); return 0; }上述代码的目的就是通过交换两个指针中目标内容的地址(也就是b和c),以此来达到通过指针地址去读取目标内容地址,通过目标内容地址去读取内容时产生了交换。
为什么上述代码做不到交换?因为在进入swap_self的时候,函数生成了两个临时指针e和f,其中&e(指针地址)和&f由编译器生成决定,但e(目标内容的地址)和f由传入参数b和c决定,而在swap_self函数里面,仅仅是交换临时指针中的e(目标内容的地址)和f,并没有对main函数中真正想要去交换的指针的b和c作变换,因此等到swap_self结束时,将会释放掉临时指针e和f,那么此时swap的作用将毫无意义。
而在函数的参数列表中加入&的符号就可以改进:swap_self(int*& e, int*& f)。因为此时将不会产生临时指针变量,对e和f操作也就是对b和c操作,因此交换的是传入参数指针的目标内容地址。
- 双指针(传入参数是指针的地址,因为有两个取内容运算符,第一次从&b->*&b(b),第二次从b->*b)
#include <iostream> using namespace std; void swap_self_double(int** e, int** f) { int *tem; tem = *e; *e = *f; *f = tem; } int main() { int a = 3; int d = 4; int *b = &a; int *c = &d; swap_self_double(&b, &c); system("pause"); return 0; }为什么上述代码可以交换?因为这时候不同于上面情况,这里是通过内存地址来操作的。首先传入的是b和c指针的地址,而后生成了两个临时指针变量e和f,此时e和f保存的信息是指针地址,不同于上述的目标内容地址。此时我们对*e和*f(指针地址上的目标内容地址进行修改),由于此时是直接对内存地址修改,因此此信息不会因为函数的结束而回收等操作,虽然在函数结束后e和f指针会被释放,但是这是他们已经交换了在指针地址上对应的目标内容的地址,且不会因为指针的释放而改变内存地址,因此此时是可以交换的。
智能推荐
CTF-web Xman-2018 010 editor 简单使用_010editor底部窗口如何调出来-程序员宅基地
文章浏览阅读3.3k次,点赞3次,收藏10次。在学msic时候,发现010是一个非常好用的工具,除了是一个查看和修改文件的编译器外,还有很多自带的脚本可以帮助我们辅助分析文件格式 这是他的主界面,可以通过选项改变观察方式在插入点的位置直接输入就可以覆盖原来的数据,点击delet就可以删除前一字节一些基本的查找 删除自然不在话下,就不多说了脚本安装一般可以识别的格式会自动提醒你安装相应的脚本,否则需要自己手动..._010editor底部窗口如何调出来
win7 to win10_windows7 to window 10-程序员宅基地
文章浏览阅读749次。upgrade:https://www.microsoft.com/en-us/software-download/windows10win10 iso download:http://www.iwin10.com/xiazai/826.html_windows7 to window 10
python中图形绘制技术的应用_【Python】Pyecharts 组合图形绘制实践-程序员宅基地
文章浏览阅读542次。Pyecharts 组合图形绘制实践大家好,之前跟大家分享了用 Pyecharts 绘制桑基图和饼图:有同学提了一个问题,在 Pyecharts 中如何绘制多个图形,今天我们来分享下组合图的绘制。在实际的工作需求中,我们经常需要绘制多个甚至多种不同类型的图形,有时候还需要将它们放在一个页面中,达到一个可视化看板的效果。在本文中将利用 pyecharts 来实现这个需求,同时满足动态可视化的效果,再..._python page,pie,bar
阿里云windows server 2012 r2服务器搭建网站_本地windows server 2012 r2部署网站-程序员宅基地
文章浏览阅读3.6k次。(一)安装必要的环境以及软件可参考这篇博客https://blog.csdn.net/phpzhi/article/details/80564381在修改httpd.conf文件时,可能会因为端口的冲突问题导致安装不成功建议将Listen 80 端口修改为其它的如8088.启动apache服务:net start Apache24关闭apache服务:net stop A..._本地windows server 2012 r2部署网站
7-2 从键盘输入三个数到a,b,c中,按公式值输出 (30 分)_7-2 从键盘输入三个数到a,b,c中,按公式值输出-程序员宅基地
文章浏览阅读4k次。在同一行依次输入三个值a,b,c,用空格分开,输出 b* b-4* a* c的值输入格式:在一行中输入三个数。输出格式:在一行中输出公式值。输入样例:在这里给出一组输入。例如:3 4 5输出样例:在这里给出相应的输出。例如:-44代码:a,b,c = input().split()a,b,c = eval(a),eval(b),eval(c)d = b*b-4*a*cprint(d)..._7-2 从键盘输入三个数到a,b,c中,按公式值输出
用Blend 修改 WPF ComboBox的背景色和字体颜色 详情介绍_wpf 修改combobox 箭头颜色-程序员宅基地
文章浏览阅读9.6k次,点赞5次,收藏14次。Blend是VS 2015中自带的,所以框架.NET Framework4.5及以上。用Blend打开页面1、拖一个下拉框ComboBox,并添加几项默认值,以方便测试看效果。_wpf 修改combobox 箭头颜色
随便推点
vb.net 接口POST方式传参数提交返回值_vb.net webclient post-程序员宅基地
文章浏览阅读1k次。Try Dim WebClientObj As New System.Net.WebClient() Dim PostVars As New System.Collections.Specialized.NameValueCollection() 'URL _vb.net webclient post
解决EditText 键盘imeOptions 设置后与换行冲突问题-程序员宅基地
文章浏览阅读604次。解决EditText 键盘imeOptions 设置后与换行冲突问题EditText imeOptions 设置必然需要设置singleLines=true 或者设置 inputType=“textXXX”, 这就不太符合需求。 解决办法:继承 EditTextpublic InputConnection onCreateInputConnection(EditorInfo outAttrs) { InputConnection connection = super.onCreate_解决edittext 键盘imeoptions 设置后与换行冲突问题
Pycharm配置Anaconda中的Tensorflow环境详解_pycharm配置anaconda的tensorflow-程序员宅基地
文章浏览阅读4.9w次,点赞6次,收藏21次。Pycharm配置Anaconda中的Tensorflow环境详解1.打开Pycharm软件,新建工程,点击File->Default Settings->Project Interprete2.默认的应该是anaconda下的python环境,我们点击Existing enviroment:3.点击右边...添加:4.找到anaconda目录下的envs,因为我装了两次Tensorfnslow(每创建一个环境,就可以安装一个,不冲突),所以可以看到我这边会有两个这种_pycharm配置anaconda的tensorflow
符号扩展,零扩展与符号缩减-程序员宅基地
文章浏览阅读1.6w次,点赞23次,收藏101次。1. 符号位扩展,零扩展,符号位缩减1.1 符号位扩展高级程序设计语言允许程序员使用包含不同大小整数的对象表达式。那么,当一个表达式的两个操作数大小不同时,有些语言会报错,有些语言则会自动将操作数转换成一个统一的格式。这种转换是有代价的,因此如果你不希望编译器在你不知情的情况下自动加入各种转换到原本非常完美的代码中,你就需要掌握编译器如何处理这些表达式。以-64为例,其8位的二进制补码(1100 0_符号扩展
【引用】DMA内存申请--dma_alloc_coherent_dma引用-程序员宅基地
文章浏览阅读2.8k次。在项目驱动过程中会经常用到dma传输数据,而dma需要的内存有自己的特点,一般认为需要物理地址连续,并且内存是不可cache的,在linux内核中提供一个供dma所需内存的申请函数dma_alloc_coheren. 如下所述:dma_alloc_coherent()dma_alloc_coherent() -- 获取物理页,并将该物理页的总线地址保存于dma_handle,返回该物理页的虚拟地址_dma引用
JAVA—— Linux(二)_java llinux-程序员宅基地
文章浏览阅读1.1k次。文章目录1 Linux文件管理1.1 touch命令1.2 vi与vim命令1.2.1 vi/vim介绍1.2.2 vi/vim模式1.2.3 打开和新建文件1.2.4 三种模式切换1.2.5 文件查看**1) cat命令**2) grep命令3) tail命令4)less命令1.2.6 vim定位行**1.2.7 异常处理**1.2.8 操作扩展1.3 echo 命令第二步: 将**命令的成功结果** **追加** 指定文件的后面第三步: 将**命令的失败结果** **追加** 指定文件的后面1.4 _java llinux