并发爬虫-python-HyperSpy_hyperspy库安装-程序员宅基地
并发爬虫-python-HyperSpy
HyperSpy结构
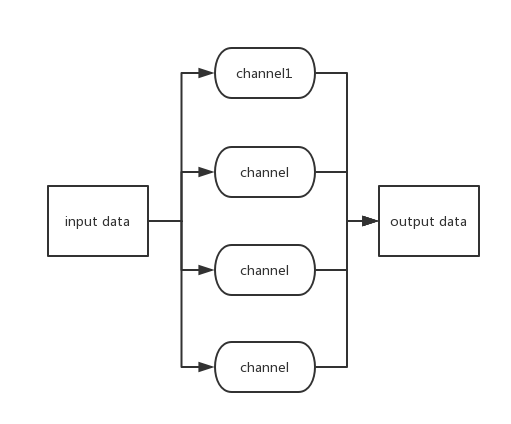
- 参考
HyperSpy().addChanel(urlGen, urlFilter, contentSpy, storeRoutine).start(),其中使用addChanel方法添加了四个channel(被@channel修饰的函数). - HyperSpy的关键思想是数据流入一个通道,再从通道中流出新的数据,作为下一个通道的输入数据: 在调用start方法后,HyperSpy首先为urlGen创建5个线程,随后循环执行urlGen方法主体,直到urlGen返回的二元组的第一个元素为True(表示urlGen已经运行完了),随后HyperSpy会将urlGen输出的数据作为第二个通道urlFilter的输入数据,开始进入通道二.
- 编写通道方法时记得使用@channel装饰器,并且在每个通道方法内一定要返回一个二元组
(finished, result),并且其中result必须是一个列表. - 你可能注意到通道方法都有四个参数:
session, ctx, lock, data. session是requests.Session的一个实例, ctx是单个通道所有线程共享的数据,对齐修改你可能需要使用lock进行同步,data是上个通道输出的数据,如果没有前一个通道那么data就是一个空列表.
实例代码
# 这个实例目标是爬取一个网站的新闻,需要先从列表页面获取文章的url.对于获取到的文章url,会先查询数据库url是
# 否存在,如果存在则直接过滤掉,如果不存在则可以根据url爬取文章标题和正文,然后按(url, title, content)的格式存入
# 数据.所以实例设计了四个通道,urlGen负责爬取文章url,urlFilter负责过滤掉爬过的url,contentSpy负责爬取文章title
# 和content,storeRoutine负责数据库接入.注意数据库连接是不能线程共享的...所以urlFilter和storeRoutine都只用了
# 一个线程来跑
import pymysql
from hyperspy import HyperSpy, channel
from bs4 import BeautifulSoup, element
host = 'http://news.nwpu.edu.cn'
basePattern = host + '/gdyw'
db = pymysql.connect("localhost","root","root","test")
cursor = db.cursor()
# channel装饰器参数含义:
# nt: 线程数
# sp: 指示每次从数据输入中拿多少数据,如果sp<=0,表示一次取完,每次拿取的数据作为data实参传入
# initParams: 初始化参数,会被存放到ctx(channel context)中
@channel(nt=5, initParams={'limit': 10, 'counter': -1, 'perProcessNum': 10})
def urlGen(session, ctx, lock, data):
target = []
result = []
lock.acquire()
num = ctx.limit - ctx.counter
if num == 0:
lock.release()
return (True, None)
elif num > ctx.perProcessNum:
num = ctx.perProcessNum
for _ in range(num + 1):
ctx.counter += 1
if ctx.counter == 0: target.append(basePattern + '.htm')
elif ctx.counter < ctx.limit: target.append(basePattern + '/' + str(ctx.counter) + '.htm')
else: break
lock.release()
for u in target:
r = session.get(u)
soup = BeautifulSoup(r.content, 'html.parser')
for li in soup.select('body .list-main .wrapper .fl ul li'):
if not 'style' in li:
href = li.select('.fr a')[0]['href'].replace('../', '')
result.append(host + '/' + href)
return (False, result)
@channel(nt=1, sp=0)
def urlFilter(session, ctx, lock, data):
result = []
sql = "select id from XiGongDa where url=%s"
for url in data:
cursor.execute(sql, (url))
if len(cursor.fetchall()) == 0:
result.append(url)
return (True, result)
@channel(nt=5)
def contentSpy(session, ctx, lock, data):
def findText(p):
content = ''
if isinstance(p, element.Tag):
for child in p.contents:
content += findText(child)
elif isinstance(p, element.NavigableString):
return p
return content
if data:
result = []
for url in data:
r = session.get(url)
if r.status_code == 200:
try:
soup = BeautifulSoup(r.content, 'html.parser')
div = soup.select('body .list-main .wrapper .fl .artical form div')[0]
title = div.select('h5')[0].contents[0]
content = ''
for p in div.select('.nr .v_news_content')[0].contents:
content += findText(p)
result.append((url, title, content))
except Exception as e:
print(e)
return (False, result)
else: return (True, None)
@channel(nt=1)
def storeRoutine(session, ctx, lock, data):
if data:
for url, title, content in data:
sql = "insert into XiGongDa(url, title, content) values (%s, %s, %s)"
try:
cursor.execute(sql, (url, title, content))
db.commit()
except Exception as e:
print (e)
db.rollback()
return (False, None)
else: return (True, None)
# 添加四个函数作为channel,HyperSpy将根据添加顺序,依次执行四个函数
HyperSpy().addChanel(urlGen, urlFilter, contentSpy, storeRoutine).start()
db.close()
实例运行结果

HyperSpy完整实现
import threading
import time
import datetime
from requests import session
def timestamp():
return datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
def getFuncName(func):
s = str(func)
i = s.find('function ')
s = s[i + 9:]
i = s.find(' ')
return s[:i]
class DynamicObject(object):
pass
class Channel(object):
def __init__(self, name, handler, nt = 1):
self.name = name
self.handler = handler
self.nt = nt
self.next = None
self.counter = 0
self._din = []
self._dinSize = 0
self._dout = []
self.ilock = threading.Lock()
self.olock = threading.Lock()
def setDin(self, data):
self.counter = 0
self._din = data
self._dinSize = len(data)
def getDin(self, n):
self.ilock.acquire()
data = None
if self.counter < self._dinSize:
if n <= 0:
data = self._din[:]
self._din.clear()
self.counter += self._dinSize
else:
tmp = self._dinSize - self.counter
if n > tmp: n = tmp
data = self._din[self.counter:self.counter + n]
self.counter += n
self.ilock.release()
return data
def putDout(self, data):
if data and isinstance(data, list):
self.olock.acquire()
self._dout.extend(data)
print ("channel data size: %d" % len(self._dout), end='\r')
self.olock.release()
def getDout(self):
data = self._dout[:]
self._dout.clear()
return data
class Pipeline(object):
def __init__(self):
self.head = Channel(None, None)
self.tail = self.head
self.size = 0
def addLast(self, c):
self.tail.next = c
self.tail = c
self.size += 1
def channels(self):
channel = self.head.next
i = 0
while i < self.size:
yield channel
i += 1
channel = channel.next
class HyperSpy(object):
def __init__(self):
self.pipeline = Pipeline()
self.session = session()
self.session.headers.update({
'Accept': 'text/html, application/xhtml+xml, image/jxr, */*',
'Accept-Encoding':'gzip, deflate',
'Accept-Language':'zh-Hans-CN, zh-Hans; q=0.5',
'Connection':'Keep-Alive',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36 Edge/15.15063'
})
def __wrapChannel(self, name, handler, nt, sp, initParams):
hlock = threading.Lock()
ctx = DynamicObject()
for k, v in initParams.items(): ctx.__setattr__(k, v)
channel = Channel(name, None, nt)
def inner():
finished = False
while not finished:
finished, dout = handler(self.session, ctx, hlock, channel.getDin(sp))
channel.putDout(dout)
channel.handler = inner
return channel
def addChanel(self, *params):
for p in params:
name, handler, nt, sp, initParams = p
self.pipeline.addLast(self.__wrapChannel(name, handler, nt, sp, initParams))
return self
def start(self):
tstart = time.time()
ltstart, ltend = tstart, None
print('[%s] hyperspy started' % timestamp())
data = []
for c in self.pipeline.channels():
c.setDin(data)
t = []
for i in range(c.nt):
t.append(threading.Thread(target=c.handler, args=()))
t[i].start()
for i in range(c.nt):
t[i].join()
data = c.getDout()
ltend = time.time()
print ("[%s] channel <%s> finished, data size: %d, time used: %fs" % (timestamp(), c.name, len(data), ltend - ltstart))
ltstart = ltend
print('[%s] hyperspy finished, time used: %fs' % (timestamp(), time.time() - tstart))
return data
def channel(nt, sp=10, initParams={}):
'''nt: total thread num, sp: data quantity processed by single thread at one time'''
def wrap(handler):
return (getFuncName(handler), handler, nt, sp, initParams)
return lambda handler: wrap(handler)
智能推荐
2D医学图像分割大模型:SAM-Med2D-程序员宅基地
文章浏览阅读2.1k次,点赞21次,收藏29次。[_sam-med2d
深圳Java培训:Javaweb现在流行用什么框架?_深圳流行开发框架-程序员宅基地
文章浏览阅读126次。深圳Java培训:Javaweb现在流行用什么框架?Java是开源的,框架很多,这些框架都能解决特定的问题,提高开发效率、简化我们的代码复杂度,现在除了很多大家通用的一些主流框架外,很多公司针对自己的业务会自定义一些公司内部的框架,当然作为学习者我们首先要清楚Javaweb都有哪些框架需要学习。回答这个问题首先要看我们的项目规模,对于”体量”较小的单应用项目,和需要处理海量数据、高并发的分布式..._深圳流行开发框架
云卷云舒_云卷云舒任逍遥 博客-程序员宅基地
文章浏览阅读107次。_云卷云舒任逍遥 博客
ESP32开发之蓝牙播放mp3_esp32 蓝牙音频-程序员宅基地
文章浏览阅读1.6k次。esp32 蓝牙播放mp3_esp32 蓝牙音频
Python数据结构与算法(5)--搜索和排序,你掌握了多少-程序员宅基地
文章浏览阅读797次,点赞24次,收藏27次。Map():创建一个空映射,返回空映射对象;put(key, val):将key‐val关联对加入映射中,如果key已存在,将val替换旧关联值;get(key):给定key,返回关联的数据值,如不存在,则返回None;del:通过del map[key]的语句形式删除key‐val关联;len():返回映射中key‐val关联的数目;in:通过key in map的语句形式,返回key是否存在于关联中,布尔值#我们用一个HashTable类来实现ADT Map,该类包含了两个列表作为成员。
linux0.12-6-4(head.s)-程序员宅基地
文章浏览阅读440次。学习记录,打卡。卷起来! (-:
随便推点
RSA的运用和前后端签名的一些看法_rsa puk pvk-程序员宅基地
文章浏览阅读1.1k次。RSA的运用和前后端签名的一些看法RSA在验签过程的使用场景分析不按照上述方式验签会造成的问题日常前后端交互简化版的RSA应用分析RSA在验签过程的使用场景分析 RSA的文章有很多。原理性学术性的对于我这样普通的码农毫无意义,对于我来说,我只想知道为什么我们要用RSA,以及什么 情况下我们需要使用它?这是一篇粗浅且迅速入门的文章。首先,我要介绍RSA验签的流程,稍后再分析为啥要这样做。..._rsa puk pvk
SpringMVC ajax请求参数为json时注意事项_ajax json请求对参数有要求吗-程序员宅基地
文章浏览阅读230次。SpringMVC Ajax请求参数为json时的几个注意事项如果请求参数为json,请求时必须加上contentType:‘application/json;charset=UTF-8’① data写成标准json字符串格式*’{’‘name:“tom”,“age”:39}’*,key必须加引号,单引号/双引号均可,但必须得加,大括号外边也必须加上引号否则会报错,控制台会报错,报错如下警告 [http-nio-8082-exec-12] org.springframework.web.ser_ajax json请求对参数有要求吗
php数组函数-程序员宅基地
文章浏览阅读130次。数组函数一、数组操作的基本函数数组的键名和值array_values($arr); 获得数组的值array_keys($arr); 获得数组的键名array_flip($arr); 数组中的值与键名互换(如果有重复前面的会被后面的覆盖)in_array("apple",$arr); 在数组中检索applearray_search("apple",$arr); 在数组中检索apple ,如...
MySQL远程操作记录删除_mysql 远程访问-程序员宅基地
文章浏览阅读341次。1、改表法。可能是你的帐号不允许从远程登陆,只能在localhost。这个时候只要在localhost的那台电脑,登入mysql后,更改 "mysql" 数据库里的 "user" 表里的 "host" 项,从"localhost"改称"%"mysql-uroot-pvmwaremysql>usemysql;mysql>updateusersethost='%'w...
python修饰符作用_python函数修饰符@的使用-程序员宅基地
文章浏览阅读334次。python函数修饰符@的作用是为现有函数增加额外的功能,常用于插入日志、性能测试、事务处理等等。创建函数修饰符的规则:(1)修饰符是一个函数(2)修饰符取被修饰函数为参数(3)修饰符返回一个新函数(4)修饰符维护被维护函数的签名例子1:被修饰函数不带参数def log(func):def wrapper():print('log开始 ...')func()print('log结束 ...')re...
cocos creator 十三水棋牌_福州十三水源码下载-程序员宅基地
文章浏览阅读4.4k次。下载地址:https://download.csdn.net/download/u012443049/10556049_福州十三水源码下载