InnoDB存储引擎详解_innodb存储引擎的状态-程序员宅基地
存储引擎是 MySQL 中具体与文件打交道的子系统,它是根据 MySQL AB 公司提供的文件访问层抽象接口定制的一种文件访问机制,这种机制就叫作存储引擎 。
文章目录
InnoDB存储引擎架构
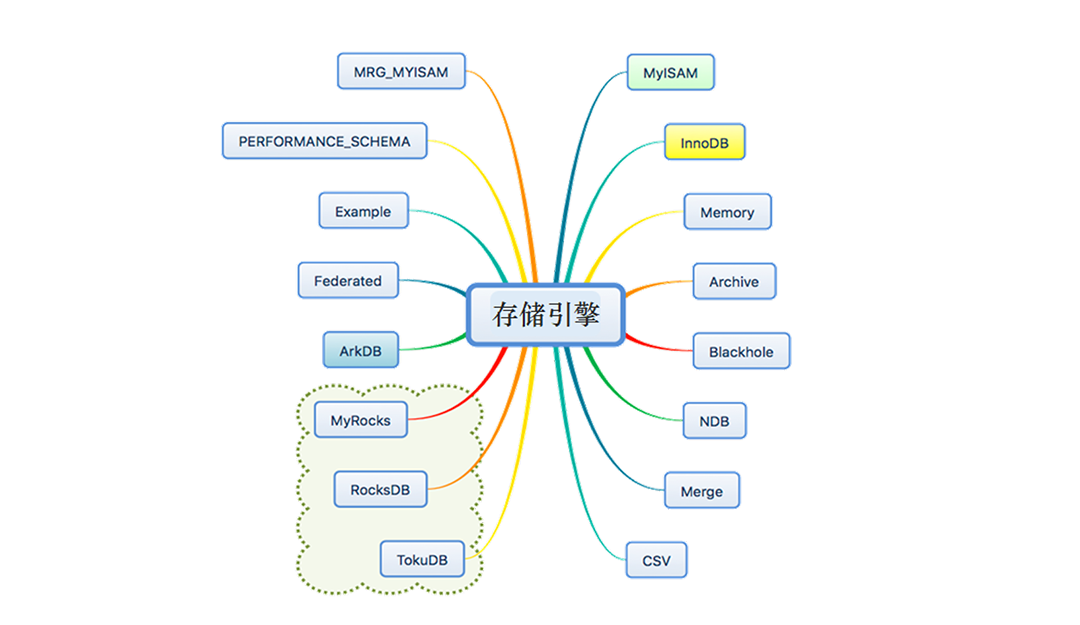
有古老的 MyISAM、支持事务的 InnoDB、内存类型的 Memory、归档类型的 Archive、列式存储的 Infobright,以及一些新兴的存储引擎,以 RocksDB 为底层基础的 MyRocks 和 RocksDB,和以分形树索引组织存储的 TokuDB, 以及国产的分布式存储引擎 ArkDB。在 MySQL 5.6 版本之前,默认的存储引擎都是 MyISAM,但 5.6 版本以后默认的存储引擎就是 InnoDB 了。
InnoDB 存储引擎的具体架构如下图所示。上半部分是实例层(计算层),位于内存中,下半部分是物理层,位于文件系统中。
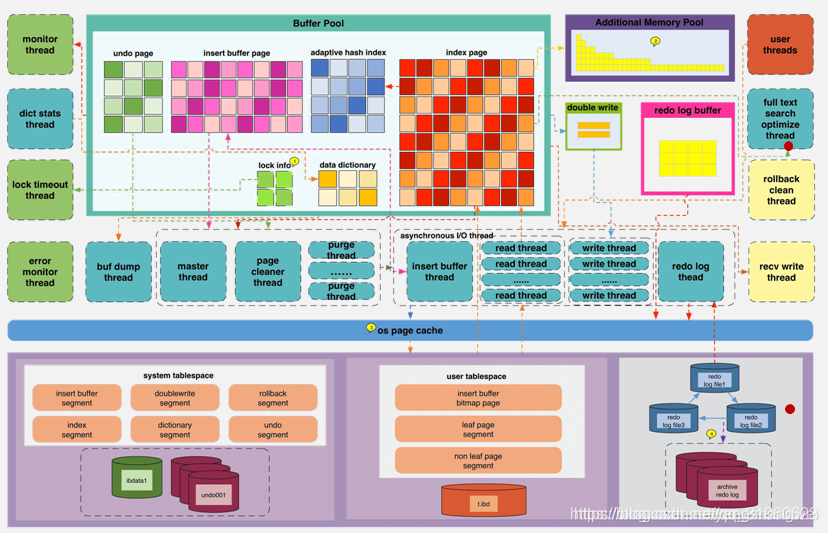
实例层
实例层分为线程和内存。InnoDB 重要的线程有 Master Thread,Master Thread 是 InnoDB 的主线程,负责调度其他各线程。
Master Thread 的优先级最高, 其内部包含几个循环:主循环(loop)、后台循环(background loop)、刷新循环(flush loop)、暂停循环(suspend loop)。Master Thread 会根据其内部运行的相关状态在各循环间进行切换。
大部分操作在主循环(loop)中完成,其包含 1s 和 10s 两种操作。
【1s 操作主要包括如下】
- 日志缓冲刷新到磁盘(这个操作总是被执行,即使事务还没有提交)。
- 最多可能刷 100 个新脏页到磁盘。
- 执行并改变缓冲的操作。
- 若当前没有用户活动,可能切换到后台循环(background loop)等。
【10s 操作主要包括如下】
- 最多可能刷新 100 个脏页到磁盘。
- 合并至多 5 个被改变的缓冲(总是)。
- 日志缓冲刷新到磁盘(总是)。
- 删除无用的 Undo 页(总是)。
- 刷新 100 个或者 10 个脏页到磁盘(总是)产生一个检查点(总是)等。
- buf_dump_thread 负责将 buffer pool 中的内容 dump 到物理文件中,以便再次启动 MySQL 时,可以快速加热数据。
- page_cleaner_thread 负责将 buffer pool 中的脏页刷新到磁盘,在 5.6 版本之前没有这个线程,刷新操作都是由主线程完成的,所以在刷新脏页时会非常影响 MySQL 的处理能力,在5.7 版本之后可以通过参数设置开启多个 page_cleaner_thread。
- purge_thread 负责将不再使用的Undo日志进行回收。
- read_thread 处理用户的读请求,并负责将数据页从磁盘上读取出来,可以通过参数设置线程数量。
- write_thread 负责将数据页从缓冲区写入磁盘,也可以通过参数设置线程数量, page_cleaner 线程发起刷脏页操作后 write_thread 就开始工作了。
- redo_log_thread 负责把日志缓冲中的内容刷新到 Redo log 文件中。
- insert_buffer_thread 负责把 Insert Buffer 中的内容刷新到磁盘。实例层的内存部分主要包含 InnoDB Buffer Pool,这里包含 InnoDB 最重要的缓存内容。数据和索引页、undo 页、insert buffer 页、自适应 Hash 索引页、数据字典页和锁信息等。additional memory pool 后续已不再使用。Redo buffer 里存储数据修改所产生的 Redo log。double write buffer 是 double write 所需的 buffer,主要解决由于宕机引起的物理写入操作中断,数据页不完整的问题。
物理层
物理层在逻辑上分为系统表空间、用户表空间、Redo日志和Undo日志等。
系统表空间里有 ibdata 文件和一些 Undo,ibdata 文件里有 insert buffer 段、double write段、回滚段、索引段、数据字典段和 Undo 信息段。
用户表空间是指以 .ibd 为后缀的文件,文件中包含 insert buffer 的 bitmap 页、叶子页(这里存储真正的用户数据)、非叶子页。InnoDB 表是索引组织表,采用 B+ 树组织存储,数据都存储在叶子节点中,分支节点(即非叶子页)存储索引分支查找的数据值。
Redo 日志中包括多个 Redo 文件,这些文件循环使用,当达到一定存储阈值时会触发checkpoint 刷脏页操作,同时也会在 MySQL 实例异常宕机后重启,InnoDB 表数据自动还原恢复过程中使用。
内存和物理结构
上面介绍了 MySQL InnoDB 存储引擎的具体架构,下面重点讲解内存和物理结构。

缓冲池(Buffer Pool)
用户读取或者写入的最新数据都存储在 Buffer Pool 中,如果 Buffer Pool 中没有找到则会读取物理文件进行查找,之后存储到 Buffer Pool 中并返回给 MySQL Server。Buffer Pool 采用LRU 机制。
Buffer Pool 决定了一个 SQL 执行的速度快慢,如果查询结果页都在内存中则返回结果速度很快,否则会产生物理读(磁盘读),返回结果时间变长,性能远不如存储在内存中。
但我们又不能将所有数据页都存储到 Buffer Pool 中,比如物理 ibd 文件有 500GB,我们的机器不可能配置能容得下 500GB 数据页的内存,因为这样做成本很高而且也没必要。
在单机单实例情况下,我们可以配置 Buffer Pool 为物理内存的 60%~80%,剩余内存用于 session 产生的 sort 和 join 等,以及运维管理使用。
如果是单机多实例,所有实例的buffer pool总量也不要超过物理内存的80%。开始时我们可以根据经验设置一个 Buffer Pool 的经验值,比如 16GB,之后业务在 MySQL 运行一段时间后可以根据 show global status like ‘%buffer_pool_wait%’ 的值来看是否需要调整 Buffer Pool 的大小。
重做日志(Redo log)
确保事务的持久性。防止在发生故障的时间点,尚有脏页未写入磁盘,在重启mysql服务的时候,根据redo log进行重做,从而达到事务的持久性这一特性。 Redo log 是一个循环复用的文件集,负责记录 InnoDB 中所有对 Buffer Pool的物理修改日志 。
redo log执行流程
当 Redo log文件空间中,检查点位置的 LSN 和最新写入的 LSN 差值(checkpoint_age)达到 Redo log 文件总空间的 75% 后,InnoDB 会进行异步刷新操作,直到降至 75% 以下,并释放 Redo log 的空间;
当 checkpoint_age 达到文件总量大小的 90% 后,会触发同步刷新,此时 InnoDB 处于挂起状态无法操作。
这样我们就看到 Redo log 的大小直接影响了数据库的处理能力,如果设置太小会导致强行 checkpoint 操作频繁刷新脏页,那我们就需要将 Redo log 设置的大一些,5.6 版本之前 Redo log 总大小不能超过 3.8GB,5.7 版本之后放开了这个限制。那既然太小影响性能,当然了也不是越大越好,需要权衡考虑。
事务提交时 log buffer 会刷新到 Redo log 文件中,具体刷新机制由参数控制 。
若参数 innodb_file_per_table=ON,则表示用户建表时采用用户独立表空间,即一个表对应一组物理文件,.frm 表定义文件和 .ibd 表数据文件。
当然若这个参数设置为 OFF,则表示用户建表存储在 ibdata 文件中,不建议采用共享表空间,这样会导致 ibdata 文件过大,而且当表删除后空间无法回收。独立表空间可以在用户删除大量数据后回收物理空间,执行一个 DDL 就可以将表空间的高水位降下来了。
在一个事务中的每一次SQL操作之后都会写入一个redo log到buffer中,在最后COMMIT的时候,必须先将该事务的所有日志写入到redo log file进行持久化(这里的写入是顺序写的),待事务的COMMIT操作完成才算完成。

由于重做日志文件打开没有使用O_DIRECT选项,因此重做日志缓冲先写入文件系统缓存。为了确保重做日志写入磁盘,必须进行一次fsync操作。由于fsync的效率取决于磁盘的性能,因此磁盘的性能决定了事务提交的性能,也就是数据库的性能。由此我们可以得出在进行批量操作的时候,不要for循环里面嵌套事务。
redo log记录形式
前面说过,redo log实际上记录数据页的变更,而这种变更记录是没必要全部保存,因此redo log实现上采用了大小固定,循环写入的方式,当写到结尾时,会回到开头循环写日志。如下图:
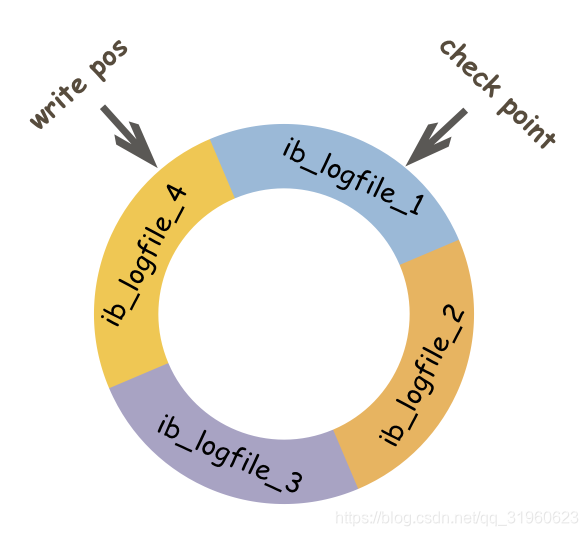
同时我们很容易得知,在innodb中,既有redo log需要刷盘,还有数据页也需要刷盘,redo log存在的意义主要就是降低对数据页刷盘的要求。在上图中,write pos表示redo log当前记录的LSN(逻辑序列号)位置,check point表示数据页更改记录刷盘后对应redo log所处的LSN(逻辑序列号)位置。write pos到check point之间的部分是redo log空着的部分,用于记录新的记录;check point到write pos之间是redo log待落盘的数据页更改记录。当write pos追上check point时,会先推动check point向前移动,空出位置再记录新的日志。
启动innodb的时候,不管上次是正常关闭还是异常关闭,总是会进行恢复操作。因为redo log记录的是数据页的物理变化,因此恢复的时候速度比逻辑日志(如binlog)要快很多。重启innodb时,首先会检查磁盘中数据页的LSN,如果数据页的LSN小于日志中的LSN,则会从checkpoint开始恢复。还有一种情况,在宕机前正处于checkpoint的刷盘过程,且数据页的刷盘进度超过了日志页的刷盘进度,此时会出现数据页中记录的LSN大于日志中的LSN,这时超出日志进度的部分将不会重做,因为这本身就表示已经做过的事情,无需再重做。
回滚日志(Undo log)
解决了事务的原子性。 重做日志记录了事务的行为,可以很好的通过其对页进行“重做”操作。但是事务有时候还需要进行回滚操作,也就是ACID中的A(原子性),这时就需要Undo log了。因此在数据库进行修改时,InnoDB存储引擎不但会产生Redo,还会产生一定量的Undo。这样如果用户执行的事务或语句由于某种原因失败了,又或者用户一条ROLLBACK语句请求回滚,就可以利用这些Undo信息将数据库回滚到修改之前的样子。
Undo log是InnoDB MVCC事务特性的重要组成部分。当我们对记录做了变更操作时就会产生Undo记录,Undo记录默认被记录到系统表空间(ibdata)中,但从5.6开始,也可以使用独立的Undo 表空间。
Undo记录中存储的是老版本数据,当一个旧的事务需要读取数据时,为了能读取到老版本的数据,需要顺着undo链找到满足其可见性的记录。当版本链很长时,通常可以认为这是个比较耗时的操作。
基本文件结构
为了保证事务并发操作时,在写各自的undo log时不产生冲突,InnoDB采用回滚段(Rollback Segment,简称Rseg)的方式来维护undo log的并发写入和持久化。回滚段实际上是一种 Undo 文件组织方式,每个回滚段又有多个undo log slot。具体的文件组织方式如下图所示:

Undo log的格式
在InnoDB引擎中,undo log分为:
- insert undo log
- update undo log
insert undo log是指在insert操作中产生的undo log,因为insert操作的记录,只对事务本身可见,对其他事务不可见(这是事务隔离性的要求),故该undo log可以在事务提交后直接删除,不需要进行purge操作。而update undo log记录的是delete和update操作产生的undo log。该undo log可能需要提供MVCC机制,因此不能在事务提交时就进行删除,提交时放入undo log链表,等待purge线程进行最后的删除。下面是两种undo log的结构图。

purge线程
对于一条delete语句 delete from t where a = 1,如果列a有聚集索引,则不会进行真正的删除,而只是在主键列等于1的记录delete flag设置为1,即记录还是存在在B+树中。而对于update操作,不是直接对记录进行更新,而是标识旧记录为删除状态,然后新产生一条记录。那这些旧版本标识位删除的记录何时真正的删除?怎么删除?
其实InnoDB是通过undo日志来进行旧版本的删除操作的,在InnoDB内部,这个操作被称之为purge操作,原来在srv_master_thread主线程中完成,后来进行优化,开辟了purge线程进行purge操作,并且可以设置purge线程的数量。purge操作每10s进行一次。
为了节省存储空间,InnoDB存储引擎的undo log设计是这样的:一个页上允许多个事务的undo log存在。虽然这不代表事务在全局过程中提交的顺序,但是后面的事务产生的undo log总在最后。此外,InnoDB存储引擎还有一个history列表,它根据事务提交的顺序,将undo log进行连接,如下面的一种情况:

在执行purge过程中,InnoDB存储引擎首先从history list中找到第一个需要被清理的记录,这里为trx1,清理之后InnoDB存储引擎会在trx1所在的Undo page中继续寻找是否存在可以被清理的记录,这里会找到事务trx3,接着找到trx5,但是发现trx5被其他事务所引用而不能清理,故再去history list中取查找,发现最尾端的记录时trx2,接着找到trx2所在的Undo page,依次把trx6、trx4清理,由于Undo page2中所有的记录都被清理了,因此该Undo page可以进行重用。
InnoDB存储引擎这种先从history list中找undo log,然后再从Undo page中找undo log的设计模式是为了避免大量随机读操作,从而提高purge的效率。
InnoDB 存储引擎
核心特性
InnoDB 存储引擎的核心特性包括:MVCC、锁、锁算法和分类、事务、表空间和数据页、内存线程以及状态查询。
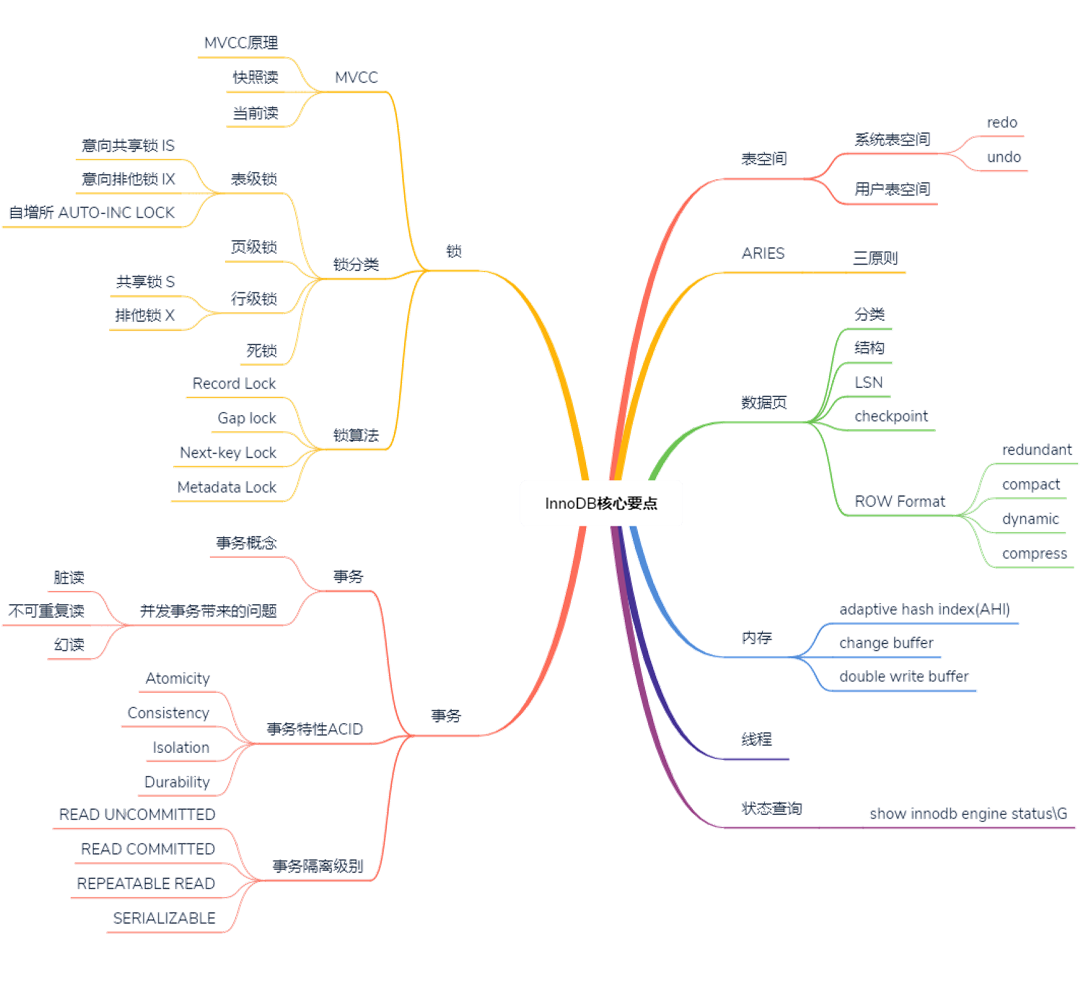
ARIES 三原则
ARIES 三原则,是指 Write Ahead Logging(WAL),先写日志,再写磁盘。
- 先写日志后写磁盘,日志成功写入后事务就不会丢失,后续由 checkpoint 机制来保证磁盘物理文件与 Redo 日志达到一致性;
- 利用 Redo 记录变更后的数据,即 Redo 记录事务数据变更后的值;
- 利用 Undo 记录变更前的数据,即 Undo 记录事务数据变更前的值,用于回滚和其他事务多版本读。
本文小结
主要梳理了 MySQL数据库的体系结构,存储引擎和分类,重点讲解了 InnoDB 存储引擎的体系结构、特性,InnoDB 也是 MySQL 今后重点发力的地方,很多地方都默认采用 InnoDB 进行存储,还有 InnoDB 引擎内部的组成和各版本对比。
智能推荐
input的file组件按钮上默认文字的修改_input type=file修改按钮上的文字-程序员宅基地
文章浏览阅读3.6w次,点赞6次,收藏5次。表单里用于上传的file组件上面,默认的是中文的“浏览”两个字,但是做英文或是其他外文网页的时候,页面上出现两个中文字看着比较别扭,找了找,没有什么直接的办法,只能用文本框和按钮来模拟,不过还是挺好用的:_input type=file修改按钮上的文字
工业现场相机坐标系和机械手坐标系的标定_labview 9点标定-程序员宅基地
文章浏览阅读2.7w次,点赞36次,收藏216次。原文:https://blog.csdn.net/kaychangeek/article/details/73878994参考:https://blog.csdn.net/qq_16481211/article/details/79764730工业现场使用视觉时一般需要相机坐标系和机械手臂坐标系的转化,这里介绍一种比较简单的标定方案。没有使用到标定板。经过几个项目的测试,精度还算可以,如果..._labview 9点标定
最短路径问题——单源最短路径问题-程序员宅基地
文章浏览阅读346次。根据结点的拓扑排序次序来对有向无环图进行边的松弛操作(由于无环,则负环路肯定不存在)。每次松弛从当前结点出发的所有边。伪代码:邻接表存储:;邻接矩阵存储:。_单源最短路径
【图像拼接】基于SURT特征匹配结合RANSAC滤除离群点图像拼接附Matlab代码-程序员宅基地
文章浏览阅读669次,点赞25次,收藏11次。图像拼接是一种计算机视觉技术,用于将两幅或多幅图像组合成一幅全景图像。图像拼接在许多应用中都有应用,例如全景摄影、无人机航拍和医疗成像。在图像拼接中,一个关键的步骤是特征匹配。特征匹配是找到两幅图像中对应的特征点。这些特征点可以是角点、边缘点或其他视觉特征。SURF特征匹配SURF(加速鲁棒特征)是一种广泛使用的特征匹配算法。SURF算法通过检测图像中的Hessian矩阵来找到特征点。Hessian矩阵是一个图像梯度的二阶导数矩阵。SURF算法计算每个特征点的方向和尺度。
AE内置效果1_match grain-程序员宅基地
文章浏览阅读639次。文章目录解释步骤match grain(添加杂色)解释 addgrain是用来合成CG渲染视频、绿幕素材、蓝幕素材的效果,甚至是直接加到CG场景里面,在AE里面比较相似的效果叫做match grain addgrain最关键的一点就是:从无到有的生成一些噪点出来步骤选择effect->Noise&Grain->addgrain修改基础设置:1、一般..._match grain
Mybatis的你所不知ResultMap生成方式_根据sql语句生成resultmap-程序员宅基地
文章浏览阅读4.1k次,点赞4次,收藏6次。三种方式//第一种 @ConstructorArgs({ @Arg(column = "id", javaType = Integer.class, id = true), @Arg(column = "userName", javaType = String.class, id = false), @Arg(column = "password", javaType = String.class, id = false)} _根据sql语句生成resultmap
随便推点
设计模式-结构型模式(适配器、桥、组合、装饰器、外观、亨元、代理)-程序员宅基地
文章浏览阅读541次。通过使用 Proxy 对象,我们可以附加一些额外的功能,例如记录请求日志或缓存数据,而不改变 RealSubject 的代码。如,定义了一个英文翻译类,现需适配成中文翻译类,那么就可以使用适配器模式,在构造方法中构造英文类,再去实现中文方法。如,在一个文件系统中,一个文件夹可以包含多个文件和子文件夹,可用组合模式来表示这个文件系统的结构。例如,在游戏中有多种武器和角色,我们可以使用桥接模式将武器和角色分离开来,从而可自由地组合它们。提供一个简单的接口,用于访问底层复杂系统的一些功能。_结构型模式
Inversion_inversion csdn-程序员宅基地
文章浏览阅读197次。HDU 6098 线段树加优化 一开始妙想的就是线段树,时间是nlognlognnlognlogn的,就是很无脑地计算每一段区间的最大值然后算出每一个BiB_i,但是超时了。在这个基础上加优化,注意到每一个合数,他的答案就是其每一个因数的答案的最大值,画一下就能看出来,加上这个就过了。 #include using namespace std;const_inversion csdn
操作系统之共享存储区详解(Linux shm)_学习下面共享存储区的内容,并用共享存储区的方式实现“观察者——报告者”问题(共-程序员宅基地
文章浏览阅读2.2k次,点赞3次,收藏13次。在学习操作系统的时候,老师讲到进程间通信,今天在这里介绍一下进程通信中的共享存储区通信一、基本介绍共享内存分为两种,以下是维基百科上的说法:硬件术语共享内存指在多处理器的计算机系统中,可以被不同中央处理器访问的大容量内存。由于多个CPU需要快速访问存储器,这样就要对存储器进行缓存。由于其他处理器可能也要存取,任一缓存数据更新后,共享内存就需要立即更新,否则不同处理器可能用到不同的数据(参见..._学习下面共享存储区的内容,并用共享存储区的方式实现“观察者——报告者”问题(共
springboot 静态目录访问以及下载文件破损_springboot文件下载残缺-程序员宅基地
文章浏览阅读1.8k次。static目录的访问情景项目中需要做一个模板文件下载的功能,可以采用将文件流写入response,然后返回response这种方式。但本次直接使用的a标签,地址指向目标文件路径,从而实现文件下载。问题于是需要访问静态文件,springboot中将静态文件放置在resource下的static中,templates用来存放html页面文件。但访问的时候,直接报404。静态文件访问不到..._springboot文件下载残缺
一个工作7年JAVA工程师面试总结:掌握这些技术,offer拿到手软_7年java软件工程师面试-程序员宅基地
文章浏览阅读2.2k次,点赞3次,收藏40次。曾面试了阿里集团(菜鸟网络,蚂蚁金服),网易,滴滴,点我达,最终收到点我达,网易offer,蚂蚁金服二面挂掉,菜鸟网络一个月了还在流程中…最终有幸去了网易。但是要特别感谢点我达的领导及HR,真的非常非常好,很感谢他们一直的关照和指导。小编在这里给大家整理了包括但不限于:JAVA基础和进阶类、Spring、Spring boot、Spring MVC、MyBatis、MySQL、JVM等面试题。_7年java软件工程师面试
【8】tkinter代码---对图片进行高斯滤波、边缘锐化、中值滤波、旋转图片、灰度处理等图像处理_tk锐化 教程-程序员宅基地
文章浏览阅读129次。设置窗口,打开单张图片,对图片进行高斯滤波、边缘锐化、中值滤波、旋转图片、灰度处理几个方面的图像增强处理,最后将处理过的图片保存在本地。运行界面对图片处理界面。_tk锐化 教程