GBDT 原理与使用_gbdt使用-程序员宅基地
技术标签: 机器学习
基本思想
GBDT–Gradient Boosting (Regression) Decistion Tree
GBDT(Gradient Boosting Decision Tree) 又叫 MART(Multiple Additive Regression Tree),是一种用于回归的机器学习算法,该算法由多棵回归决策树组成,所有树的结论累加起来做最终答案。当把目标函数做变换后,该算法亦可用于分类或排序。
GBDT的两个不同版本
残差版本把GBDT说成一个残差迭代树,认为每一棵回归树都在学习前N-1棵树的残差。
Gradient版本把GBDT说成一个梯度迭代树,使用梯度下降法求解,认为每一棵回归树在学习前N-1棵树的梯度下降值,umass的源码实现中用的则是这一版本(准确的说是LambdaMART中的MART为这一版本,MART实现则是前一版本)。
回归决策树
GBDT中的树都是回归树,核心在于累加所有树的结果作为最终结果
回归树总体流程
1在每个节点(不一定是叶子节点)都会得一个预测值,该预测值等于属于这个节点属性的平均值
2 分枝时穷举每一个feature的每个阈值找最好的分割点,衡量最好的标准最小化均方差(1/n*误差平方和)分割后误差比原来的小
3 分枝直到每个叶子节点上属性都唯一(这太难了)或者达到预设的终止条件(如叶子个数上限)
Boosting,通过迭代多棵树来共同决策
每一棵树学的是之前所有树结论和的残差(残差=真实值-预测值)
比如A的真实年龄是18岁,但第一棵树的预测年龄是12岁,差了6岁,即残差为6岁。那么在第二棵树里我们把A的年龄设为6岁去学习,如果第二棵树真的能把A分到6岁的叶子节点,那累加两棵树的结论就是A的真实年龄;如果第二棵树的结论是5岁,则A仍然存在1岁的残差,第三棵树里A的年龄就变成1岁,继续学。
Gradient体现:
损失函数cost function不论是均方差还是均差,只要它以误差作为衡量标准,残差向量(-1, 1, -1, 1)都是它的全局最优方向,这就是Gradient。
公式推导
详细公式请参考http://blog.csdn.net/china1000/article/details/51106856
由多棵回归决策树组成,所有树的结论累加起来做最终答案。
1. 明确损失函数是误差最小
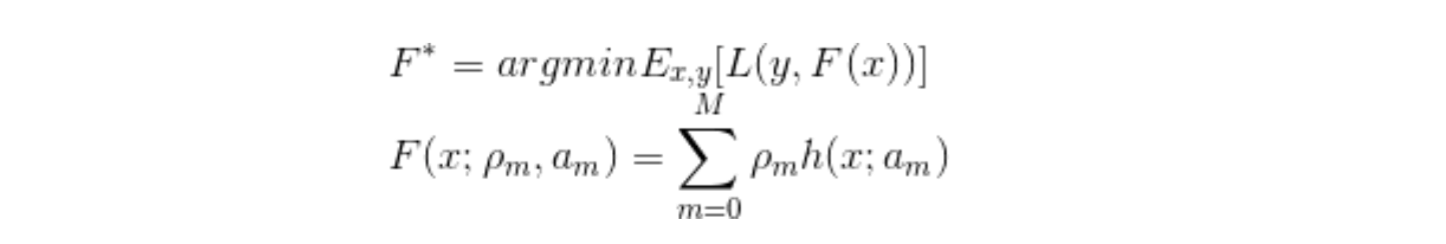
2. 构建第一棵回归树

3. 学习多棵回归树
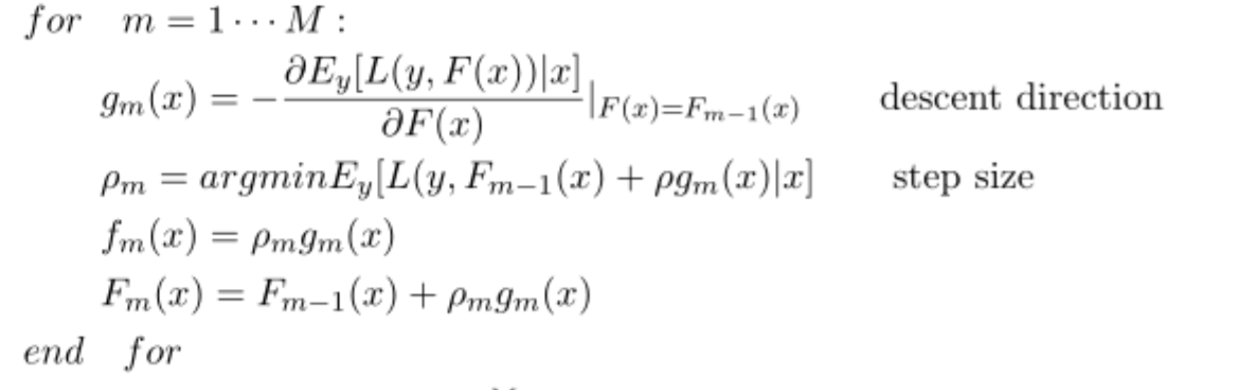
迭代:计算梯度/残差gm(如果是均方误差为损失函数即为残差)
步长/缩放因子p,用 a single Newton-Raphson step 去近似求解下降方向步长,通常的实现中 Step3 被省略,采用 shrinkage 的策略通过参数设置步长,避免过拟合
第m棵树fm=p*gm
模型Fm=Fm-1+p*gm
4. F(x)等于所有树结果累加
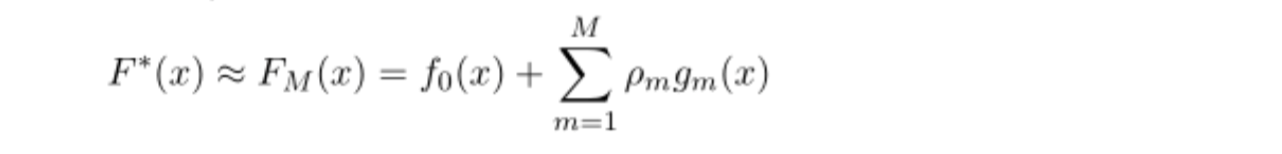
GBDT优缺点:
防止过拟合。过拟合是指为了让训练集精度更高,学到了很多”仅在训练集上成立的规律“,导致换一个数据集当前规律就不适用了。
Boosting的最大好处在于,每一步的残差计算其实变相地增大了分错实例(instance)的权重,而已经分对的实例(instance)则都趋向于0。这样后面的树就能越来越专注那些前面被分错的实例(instance)
损失函数重新构造
重新定义cost function,全局最优方向求导求Gradient,不再是残差,把“求残差”的逻辑替换为“求梯度”,可以这样想:梯度方向为每一步最优方向,累加的步数多了,总能走到局部最优点,若该点恰好为全局最优点,那和用残差的效果是一样的。
注:如果feature个数太多,每一棵回归树都要耗费大量时间,这时每个分支时可以随机抽一部分feature来遍历求最优
python使用代码
#GBDT分类(也是使用回归树)
#导入模块
from sklearn.ensemble import GradientBoostingClassifier
from sklearn import cross_validation
from sklearn.datasets import load_iris
#获取数据
iris = load_iris()
#A创建分类器
model= GradientBoostingClassifier(n_estimators=100, learning_rate=1.0, max_depth=1, random_state=0)
#切分数据集
X_train, X_test, y_train, y_test = cross_validation.train_test_split(iris.data, iris.target, test_size=0.33, random_state=42)
#训练
model.fit(X_train,y_train)
#预测
predicted= model.predict(X_test)
print(float(predicted.shape[0]-sum((predicted-y_test)*(predicted-y_test)))/predicted.shape[0])
#5折cv验证
scores = cross_validation.cross_val_score(model, iris.data, iris.target, cv=5)
print scores
##GBDT回归 常调n_estimators树的个数max_depth每颗树深度
from sklearn.ensemble import GradientBoostingRegressor
clf = GradientBoostingRegressor(
loss='ls'
, learning_rate=0.1
, n_estimators=100
, subsample=1
, min_samples_split=2
, min_samples_leaf=1
, max_depth=3
, init=None
, random_state=None
, max_features=None
, alpha=0.9
, verbose=0
, max_leaf_nodes=None
, warm_start=False
)
clf.fit(train_x, train_y)
test_y= clf.predict(test_x)GBDT参数调优
系数说明参考
http://www.cnblogs.com/jasonfreak/p/5720137.html
GradientBoostingClassifier支持二进制和多类分类
from sklearn.datasets import make_hastie_10_2
from sklearn.ensemble import GradientBoostingClassifier
X, y = make_hastie_10_2(random_state=0)
X_train, X_test = X[:2000], X[2000:]
y_train, y_test = y[:2000], y[2000:]
clf = GradientBoostingClassifier(
loss='deviance', ##损失函数默认deviance deviance具有概率输出的分类的偏差
n_estimators=100, ##默认100 回归树个数 弱学习器个数
learning_rate=0.1, ##默认0.1学习速率/步长0.0-1.0的超参数 每个树学习前一个树的残差的步长
max_depth=3, ## 默认值为3每个回归树的深度 控制树的大小 也可用叶节点的数量max leaf nodes控制
subsample=1, ##树生成时对样本采样 选择子样本<1.0导致方差的减少和偏差的增加
min_samples_split=2, ##生成子节点所需的最小样本数 如果是浮点数代表是百分比
min_samples_leaf=1, ##叶节点所需的最小样本数 如果是浮点数代表是百分比
max_features=None, ##在寻找最佳分割点要考虑的特征数量auto全选/sqrt开方/log2对数/None全选/int自定义几个/float百分比
max_leaf_nodes=None, ##叶节点的数量 None不限数量
min_impurity_split=1e-7, ##停止分裂叶子节点的阈值
verbose=0, ##打印输出 大于1打印每棵树的进度和性能
warm_start=False, ##True在前面基础上增量训练(重设参数减少训练次数) False默认擦除重新训练
random_state=0 ##随机种子-方便重现
).fit(X_train, y_train) ##多类别回归建议使用随机森林
print clf.score(X_test, y_test) ##tp / (tp + fp)正实例占所有正实例的比例
test_y= clf.predict(X_test)
test_y= clf.predict_proba(X_test) ##预测概率
print clf.feature_importances_ ##输出特征重要性
print clf.train_score_ ##每次迭代后分数
##test_y= clf.predict(X_test)
##from sklearn.metrics import precision_score
##precision_score(test_y, y_test,average='micro') ##tp / (tp + fp)
##from sklearn import metrics
##fpr, tpr, thresholds = metrics.roc_curve(y_test, test_y)
##print"auc : %.4g" % metrics.auc(fpr, tpr)sklearn.ensemble.GradientBoostingRegressor
import numpy as np
from sklearn.metrics import mean_squared_error
from sklearn.datasets import make_friedman1
from sklearn.ensemble import GradientBoostingRegressor
X, y = make_friedman1(n_samples=1200, random_state=0, noise=1.0)
X_train, X_test = X[:200], X[200:]
y_train, y_test = y[:200], y[200:]
est = GradientBoostingRegressor(
loss='ls', ##默认ls损失函数'ls'是指最小二乘回归lad'(最小绝对偏差)'huber'是两者的组合
n_estimators=100, ##默认100 回归树个数 弱学习器个数
learning_rate=0.1, ##默认0.1学习速率/步长0.0-1.0的超参数 每个树学习前一个树的残差的步长
max_depth=3, ## 默认值为3每个回归树的深度 控制树的大小 也可用叶节点的数量max leaf nodes控制
subsample=1, ##用于拟合个别基础学习器的样本分数 选择子样本<1.0导致方差的减少和偏差的增加
min_samples_split=2, ##生成子节点所需的最小样本数 如果是浮点数代表是百分比
min_samples_leaf=1, ##叶节点所需的最小样本数 如果是浮点数代表是百分比
max_features=None, ##在寻找最佳分割点要考虑的特征数量auto全选/sqrt开方/log2对数/None全选/int自定义几个/float百分比
max_leaf_nodes=None, ##叶节点的数量 None不限数量
min_impurity_split=1e-7, ##停止分裂叶子节点的阈值
verbose=0, ##打印输出 大于1打印每棵树的进度和性能
warm_start=False, ##True在前面基础上增量训练 False默认擦除重新训练 增加树
random_state=0 ##随机种子-方便重现
).fit(X_train, y_train)
mean_squared_error(y_test, est.predict(X_test))import numpy as np
from sklearn import ensemble
from sklearn import datasets
from sklearn.utils import shuffle
from sklearn.metrics import mean_squared_error
from sklearn.metrics import r2_score
boston = datasets.load_boston()
X, y = shuffle(boston.data, boston.target, random_state=13) #抽取
X = X.astype(np.float32)
offset = int(X.shape[0] * 0.9) #设置取0.9做样本
X_train, y_train = X[:offset], y[:offset]
X_test, y_test = X[offset:], y[offset:]
##参数可以放入一个字典当中
params = {
'n_estimators': 500, 'max_depth': 4, 'min_samples_split': 2,
'learning_rate': 0.01, 'loss': 'ls'}
clf = ensemble.GradientBoostingRegressor(**params)
clf.fit(X_train, y_train)
mse = mean_squared_error(y_test, clf.predict(X_test))
r2 = r2_score(y_test, clf.predict(X_test))
print("MSE: %.4f" % mse) ##输出均方误差
print("r^2 on test data : %f" % r2) ##R^2 拟合优度=(预测值-均值)^2之和/(真实值-均值)^2之和
##绘图查看
import matplotlib.pyplot as plt
test_score = np.zeros((params['n_estimators'],), dtype=np.float64)
##计算每次迭代分数变化
for i, y_pred in enumerate(clf.staged_predict(X_test)):
test_score[i] = clf.loss_(y_test, y_pred)
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.title('Deviance')
plt.plot(np.arange(params['n_estimators']) + 1, clf.train_score_, 'b-',
label='Training Set Deviance')
plt.plot(np.arange(params['n_estimators']) + 1, test_score, 'r-',
label='Test Set Deviance')
plt.legend(loc='upper right')
plt.xlabel('Boosting Iterations')
plt.ylabel('Deviance')
##输出特征重要性
feature_importance = clf.feature_importances_
# make importances relative to max importance
feature_importance = 100.0 * (feature_importance / feature_importance.max())
sorted_idx = np.argsort(feature_importance) ##返回的是数组值从小到大的索引值
pos = np.arange(sorted_idx.shape[0]) + .5
plt.subplot(1, 2, 2)
plt.barh(pos, feature_importance[sorted_idx], align='center')
plt.yticks(pos, boston.feature_names[sorted_idx])
plt.xlabel('Relative Importance')
plt.title('Variable Importance')
plt.show()网格搜索调整超参数
from sklearn.model_selection import GridSearchCV
clf=GridSearchCV(
estimator, ##模型
param_grid, ##参数字典或者字典列表
scoring=None, ##评价分数的方法
fit_params=None, ##fit的参数 字典
n_jobs=1, ##并行数 -1全部启动
iid=True, ##每个cv集上等价
refit=True, ##使用整个数据集重新编制最佳估计量
cv=None, ##几折交叉验证None默认3
verbose=0, ##控制详细程度:越高,消息越多
pre_dispatch='2*n_jobs', ##总作业的确切数量
error_score='raise', ##错误时选择的分数
return_train_score=True ##如果'False',该cv_results_属性将不包括训练得分
)
clf.cv_results_ ##结果表 常看mean_test_score std_test_score
clf.cv_results_.keys() ##clf.cv_results_['mean_test_score']
clf.best_estimator_ ##最优模型
clf.best_score_ ##最优分数
clf.best_params_ ##最优参数from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import classification_report
from sklearn import metrics
from sklearn.datasets import make_hastie_10_2
from sklearn.ensemble import GradientBoostingClassifier
X, y = make_hastie_10_2(random_state=0)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, random_state=0)##test_size测试集合所占比例
##设置参数
tuned_parameters= [{
'n_estimators':range(20,81,10),
'max_depth':range(3,14,2),
'learning_rate':[0.1, 0.5, 1.0],
'subsample':[0.6,0.7,0.75,0.8,0.85,0.9]
}]
##设置分数计算方法精度/召回
scores = ['precision', 'recall'] ## roc_auc
for score in scores:
print("评测选择 %s" % score)
clf = GridSearchCV(GradientBoostingClassifier(), tuned_parameters, cv=5,
scoring='%s_macro' % score)
clf.fit(X_train, y_train)
print(clf.best_params_)
means = clf.cv_results_['mean_test_score'] ##tp / (tp + fp)
stds = clf.cv_results_['std_test_score']
for mean, std, params in zip(means, stds, clf.cv_results_['params']):
print("%0.3f (+/-%0.03f) for %r" % (mean, std * 2, params))
##预测
y_true, y_pred = y_test, clf.predict(X_test)
##y_true, y_pred = y_test, clf.predict_proba(X_test)
print(classification_report(y_true, y_pred))
##print"Accuracy : %.4g" % metrics.accuracy_score(y_true, y_pred)参考http://blog.csdn.net/w28971023/article/details/8240756
http://blog.csdn.net/a819825294/article/details/51188740
智能推荐
STlink烧录STM32_stlink接线图stm32-程序员宅基地
文章浏览阅读1.4k次。使用STlink烧录STM32代码_stlink接线图stm32
VMD测量原子之间的键长键角_vmd 统计键长-程序员宅基地
文章浏览阅读3k次。VMD中可以用于测量键长键角的功能_vmd 统计键长
使用腾讯优图SDK,实现人脸识别、身份证OCR识别_腾讯优图刷掌sdk 文档-程序员宅基地
文章浏览阅读1.9w次。由于公司业务需要对接身份证识别信息,然后在网上找了好久,发现云脉做OCR在国内做的还不错,但是由于是收费的,只能放弃。最后是找到了腾讯优图,目前的腾讯优图使用是免费的,也没有使用触发限制。 腾讯优图身份证识别主要是把图片上传云端,然后云端处理完结果,返回给我们处理完的结果。腾讯优图SDK接入网址 http://open.youtu.qq.com/身份证OCRAPI文档 http:/..._腾讯优图刷掌sdk 文档
2022熔化焊接与热切割考试模拟100题模拟考试平台操作-程序员宅基地
文章浏览阅读1.1k次。题库来源:安全生产模拟考试一点通公众号小程序2022年熔化焊接与热切割练习题是熔化焊接与热切割考试100题新版教材大纲题库!2022熔化焊接与热切割考试模拟100题模拟考试平台操作根据熔化焊接与热切割最新教材汇编。熔化焊接与热切割模拟考试题库随时根据安全生产模拟考试一点通模拟在线真实考试。1、【单选题】 MUI-1000型自动带极堆焊机制造机械零件时,堆焊层金属不包括()。(C)A、高合金钢B、不锈钢C、低合金钢2、【单选题】 下列不属于电弧焊的是()。(C)...
spring boot校园健康监测管理系统 毕业设计-附源码151047-程序员宅基地
文章浏览阅读35次。校园健康检测管理系统主要功能模块包括:健康打卡、请假管理、返校管理、信息上报、中高风险地区管理等,采取面对对象的开发模式进行软件的开发和硬体的架设,能很好的满足实际使用的需求,完善了对应的软体架设以及程序编码的工作,采取Mysql作为后台数据的主要存储单元,采用Springboot框架、MVVM模式进行业务系统的编码及其开发,实现了本系统的全部功能。
工控系统概述_普渡模型-程序员宅基地
文章浏览阅读1.6w次,点赞9次,收藏38次。工业控制系统安全-工控系统概述简短介绍工控系统架构、组成部分、功能以及术语等方面,掌握基本工控系统知识。工控系统指的是工业自动化控制系统,主要利用电子电气、机械、软件组合实现。主要是使用计算机技术,微电子技术,电气手段,使工厂的生产和制造过程更加自动化、效率化、精确化,并具有可控性及可视性。普渡参考模型普渡企业参考架构(Purdue Enterprise Reference Archi..._普渡模型
随便推点
使用VLC轻松体验本地视频推流、拉流、播放功能_vlc推流-程序员宅基地
文章浏览阅读1.7w次,点赞5次,收藏42次。使用VLC轻松体验本地视频推流、拉流、播放功能_vlc推流
Vs2019安装libtorch(CPU版)和OpenCV_libkineto_srcs-程序员宅基地
文章浏览阅读1k次,点赞2次,收藏5次。libtorch_libkineto_srcs
redis java 发布订阅_java实现 redis的发布订阅(简单易懂)-程序员宅基地
文章浏览阅读252次。redis的应用场景实在太多了,现在介绍一下它的几大特性之一 发布订阅(pub/sub)。特性介绍:什么是redis的发布订阅(pub/sub)? Pub/Sub功能(means Publish, Subscribe)即发布及订阅功能。基于事件的系统中,Pub/Sub是目前广泛使用的通信模型,它采用事件作为基本的通信机制,提供大规模系统所要求的松散耦合的交互模式:订阅者(如客户端)以事件订..._java 后台获取redis订阅频道
java web访问webroot_java web 之 WebRoot和WebContent目录-程序员宅基地
文章浏览阅读255次。WebRoot和WebContent都是程序的根文件夹,无本质区别,一下是两者的共同点和不同点:共同点:都有一个WEB-INF文件夹,其下文件不可直接访问;WEB-INF是安全目录,所谓安全,就是用户客户端无法访问,只有服务器端可以访问。如果想在页面中直接访问,需要通过web.xml对要访问的文件进行映射。WEB-INF下除了web.xml,还有一个classes文件夹,放置*.class文件,类..._访问/webroot
C语言之函数(全部)_c语言 函数按范围 几种-程序员宅基地
文章浏览阅读689次,点赞13次,收藏14次。两年半成为编程高手之C语言函数部分。_c语言 函数按范围 几种
[云原生专题-11]:容器 - 如何构建自己的docker镜像:Docker Dockerfile_docker构建最原始的镜像-程序员宅基地
文章浏览阅读2.7w次。作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_程序员宅基地本文网址:目录前言:第1章(方法1):动态构建:基于现有的docker镜像进行修改第2章(方法2):静态构建:基于现有的docker镜像重新构建自己的镜像2.1 步骤1:开发机器:安装应用程序开发所需要的依赖环境2.2 步骤2:开发机器:编写自己的Linux应用程序2.3 步骤3:构建机器:生成Linux应用程序,可以是c++的*.so,也可以是java的*.jar,也可以是python_docker构建最原始的镜像