【论文解读】【论文翻译】SAST文字检测算法_sast算法-程序员宅基地
技术标签: 文字检测 百度 文本检测 目标检测 SAST text instance 图像识别 OCR
A Single-Shot Arbitrarily-Shaped Text Detector based on,Context Attended Multi-Task Learning
简介:百度自研文字检测算法,实际上就是EAST算法的扩展,一阶段,输出为multitask,各个分支相互校正。
录用会议:ACM Multimedia 2019
作者:百度、西安电子科大
解决问题:
- 任意形状文本检测
- 相距紧密的文本很难通过分割的方式进行分离
- 长文本容易被预测为多个碎片
缺点:小文本区域检测
论文翻译:
ABSTRACT
在过去的几年中,检测任意形状的场景文本一直是一项具有挑战性的任务。本文提出了一种新的基于分割的文本检测器SAST。它利用基于全卷积网络(FCN)的上下文多任务学习框架来学习文本区域的各种几何特征,从而构造文本区域的多边形表示。考虑到文本的连续性特征,通过引入Context Attention Block 捕捉像素的长范围相关性,一次来获得更加可靠的分割结果。在后处理过程中,提出一个点到边的对齐方法,来将像素聚类称为文本实力,这样就通过一次采样图片,把高级别的特征和低级别的特征结合在一起。此外,利用所提出的几何性质可以更有效地提取任意形状文本的多边形表示。在ICDAR2015、ICDAR2017-MLT、SCUT-CTW1500和Total Text等多个基准上的实验表明,SAST在准确度方面取得了更好效果,性能也相对较高。此外,该算法在SCUT-CTW1500上以27.63 FPS的速度运行,在单块NVIDIA Titan Xp显卡上的Hmean为81.0%,超过了大多数现有的基于分割的方法。
1 INTRODUCTION
近年来,场景文本阅读以其众多的应用,如场景理解、图像和视频检索、机器人导航等,引起了学术界和工业界的广泛关注。文本检测作为文本信息提取和理解的前提,具有十分重要的意义。由于深度神经网络的兴起,各种基于卷积神经网络(CNN)的方法被提出来检测场景文本,不断刷新标准基准的性能记录[1,15,28,42]。然而,由于文本在大小、纵横比、方向、语言、任意形状以及复杂背景等方面的显著变化,文本检测仍然是一项具有挑战性的任务。本文寻求一种对任意形状的文本进行有效、高效的检测器。
为了检测任意形状的文本,特别是曲线形状的文本,一些基于分割的方法[23,35,37,44]将文本检测公式化为一个语义分割问题。他们使用全卷积网络(FCN)[27]来预测文本区域,并应用连通区域分析等后处理步骤来提取场景文本的最终坐标。由于缺乏全局上下文信息,基于分割的文本检测器有两个共同的问题,如图1所示:1)文本实例相互靠近,难以通过语义分割来分离文本实例;2)长文本实例容易被分割,特别是当字符间距较远或背景较复杂时,例如强光照的影响。除此之外,大多数基于分割的检测期都需要输出大分辨率的预测来精确描述文本区域,因此可能会遭受大量的时间消耗和复杂的后处理步骤。
一些实例分割方法[4,7,45]尝试将高级别的目标知识,活着非局部信息嵌入网络,来缓解上述问题。其中,Mask-RCNN[7],一种基于候选的分割方法,它将基于RPN的检测任务和基于ROIAlign的分割任务结合在一起,取得了相比无候选方法了更好的性能。最近,一些类似的思想[14,24,39]已经被引入解决检测任意形状文本的问题。然而,它们都面临着一个共同的挑战,即当有效文本候选的数量增加时,需要花费更多的时间,这是因为在分割过程中,特别是在有效候选密集的情况下。相比之下,我们的方法基于one-shot和高效的多任务机制,性能更加优秀。
受一般语义实例分割领域的最新研究成果[16,22,33]的启发,我们设计了一种基于分割的one-shot任意形状文本检测器(SAST),它将高层次的目标知识和低层次的像素信息融合在一个镜头中,以高精度和高效的方式检测任意形状的场景文本。通过FCN[27]网络,文本区域的多种集合属性在一个多任务学习中被同时提取出来,包括:文本中心线TCL,文本边界偏移TBO,文本中心偏移TCO和文本顶点偏移TVO。除了跳过连接之外,还将一个文本注意模块(CAB)引入到体系结构中,以聚合上下文信息以进行特征增强。为了定位图1中展示的问题,我们提出了一种点对四边的方法来进行文本实例分割,通过结合来自TVO和TCO特征图的高级别目标知识来给像素分配标签。在将TCL映射到文本实例后,基于TBO特征图映射重新构建任意形状的文本更精确的多边形表示。
基于开源数据集的实验说明了我们提出的方法在精度和性能上都获得了更好的效果。本文的贡献分为3个部分:
- 我们提出了一个one-shot的文本检测器,基于多任务学习,针对任意形状包括多方向、多语言、弯曲场景文本,并且在速度上足够快。
- 上下文注意力模块Content-Attention-Block聚合信息,以增加特征表示,而且不需要额外的计算开销。
- 点到四边对齐的方法在鲁棒性和准确性方面相比较连通域分析都具有一定的优势,能够减缓文本被分块的问题。

2 RELATED WORK
在这一部分,我们将回顾一些有代表性的基于切分和基于检测的文本检测器,以及一般语义分割的一些最新进展。有关近期场景文本探测器的全面回顾,请参见[40,49]。
基于分割的文本检测器。基于分割的方法的最大的优点是能够使用统一的方式来处理平直文本和弯曲文本。使用FCN的文本分割检测器首先对文本进行分类,然后根据文本的几何特征进行一些后处理,因此文本分割的鲁棒性对这些检测器有很强的影响。在PixelLink[2]中,正像素通过预测的正链接连接到文本实例中,并直接从分割结果中提取边界框。TextSnake[23]提出了一种新颖的任意形状文本表示方法,并将文本实例视为位于文本中心线的一系列重叠圆盘来描述不规则文本实例的几何性质形状。PSENet[35]将原始文本实例缩小到不同的尺度,并逐渐将内核扩展到文本通过渐进式比例扩展算法生成完整形状的实例。基于FCN的方法的主要挑战是分离彼此接近的文本实例。上述方法的运行时间很大程度上依赖于所采用的后处理步骤,这一步骤通常涉及多个流程,并且往往比较慢。
基于检测的文本检测器。场景文本被看作是一种特殊类型的目标,一些基于Faster R-CNN,SSD,DenseBox的方法,通过直接回归框的边界点来生成文本候选框。Textboxes[17]和RRD[18]采用SSD作为基检测器,根据文本实例的宽高比变化,调整anchor尺度和卷积核大小。He [10]等人在不使用anchor和候选框的前提下,以像素为单位的方式直接回归确定四边形文本边界的顶点坐标,并进行NMS以得到最终的检测结果。RRPN[26]生成包含文本方向角信息和前旋转感兴趣区域(RRoI),以检测任意方向的文本。由于受CNNs感受野,采用矩形框或四边形等相对简单的表示方式来描述文本,基于检测的方法在处理更具挑战性的文本实例时可能会出现不足,例如长文本或任意形状的文本。
一般实例分割。实例分割是一个具有挑战性的任务,它包含了分割和分类两个任务。最近比较成功的实例分割算法为MaskR-CNN,在开源数据集上实现了优秀的效果,但是时间消耗严重,因为器候选框数量多,网络深度大。其他的算法框架主要依赖于单个FCN生成的像素特征,然后使用类似物理模型的后处理方法如模版匹配,像素嵌入,像素聚类等生成文本实例。更具体的说,非局域网络利用自我注意力机制来生成像素特征对其他位置特征的感知。而CCNet[13]通过堆叠两个交叉注意力模块来更有效地从所有像素获取上下文信息,这大大增强了特征表示。在后处理阶段,[22]提出了一种像素相似性方案,并用一种简单而有效的图合并算法将像素聚类到实例中。Instance-Cut[16]和[41]的工作有意地预测对象边界,以便于对象实例的分离。
我们的方法SAST使用基于FCN的框架并行预测TCL、TCO、TVO、TBO特征。使用高效的CAB和点对边界对齐方法,将高级别的目标知识和低级别的像素信息结合起来。SAST能够准确高效的检测任意形状的文本。
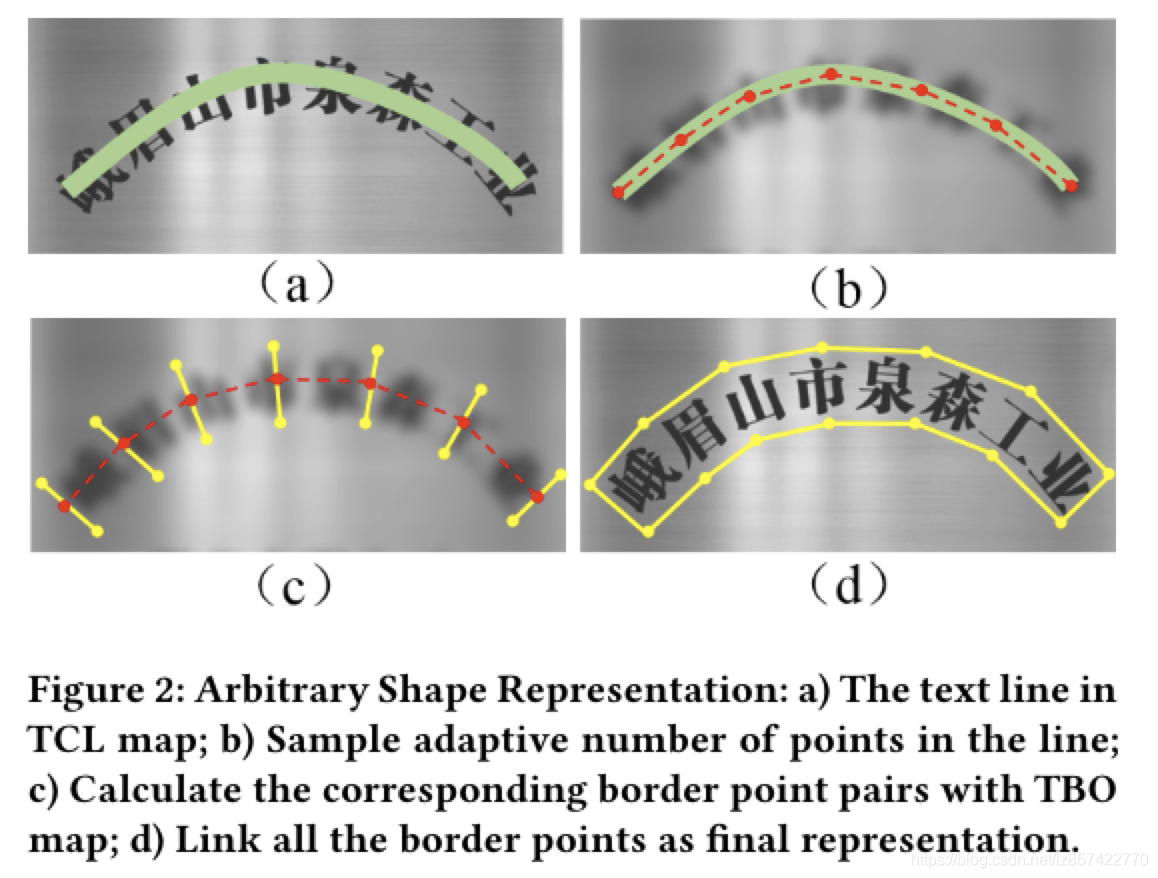
3 METHODOLOGY
在本节中,我们将详细描述我们的SAST框架,如何检测任意形状的场景文本。
3.1 Arbitrary Shape Representation
在大多数的文本检测器中,边界框,旋转矩形和四边形通常被用做表示文本实例。然而,这些方式不能表示任意形状的文本形状,例如图1b中展示的那样。基于分割的方法将任意形状的文本实例检测视作二元分割问题。大多数分割方法直接提取文本实例的轮廓作为文本的表示,文本的表示很容易收到实例分割完整性和一致性的影响。然而,PSENet[35]和TextSnake[23]试图基于收缩的文本区域逐步重构检测到的文本的多边形表示,其后处理比较复杂且往往比较缓慢。基于这些想法的启发,我们旨在涉及一个任意形状文本表示的高效方法。
在这篇文章中,我们提取文本区域的中心线TCL特征图,并且使用回归几何特征来重建文本实例的精确表示。回归几何特征如TBO,表示TCL特征中的每个像素与其对应的上下边界的对应点的偏移量。更加精确的说,如图2描述的那样,表达规则主要分为两步:文本中心点采样和边界点提取。首先我们在文本中心线从左到右等距采样n个点。通过进一步的运算,我们可以根据TCL中的采样点,在TBO中同一位置确定出相应的边界点对儿。把所有的点按照顺时针的方向链接起来,我们能够获得一个完整的文本多边形表示。与其将n设置为固定的数量,我们通过中心线长度与边界偏移对的平均偏移长度之比来自适应的设置n。几个在弯曲文本数据集上的实验证明了我们的方法对于任意形状的文本实例是有效和灵活的。
3.2 Pipeline
基于FCN的文本检测器受限于局部感受野和短程上下文信息。这使得分割一些难度文本实例非常困难。因此我们设计了一个Context Attention Block来计算长程相关性来获得有效特征。
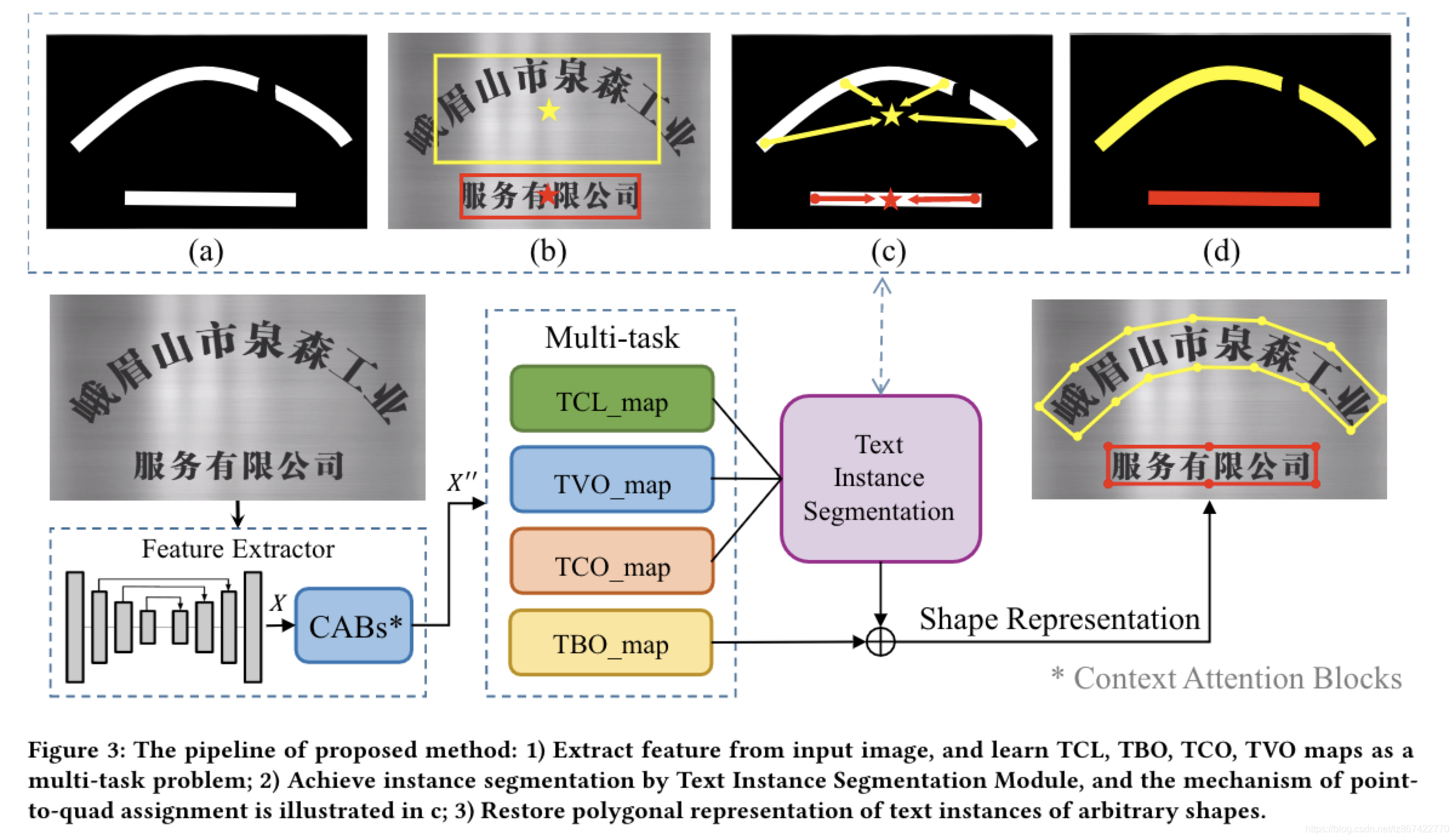
作为连通量分析的替代品,我们也提出Point-Quad Assignment来聚类TCL特征中的像素成为文本实例,使用高级特征的TCL和TVO来恢复文本实例的最小四边形边界。
我们的整体框架图描述如图3所示。它包含了3个部分,一个特征提取网络,一个多任务分支和一个后处理模块。基础网络是backbone为ResNet50的FPN,其中CAB模块产出了特征增强表示。每个文本实例都会通过多任务分支预测出TCL、TCO、TVO和TBO特征图。在后处理部分,我们使用点对边对齐方法来分割文本实例。具体来说就类似EAST算法[47],TVO特征图直接回归4个文本区域的顶点,这个特征被视作文本区域的高层目标中心。对每个TCL特征图中的像素,TCO特征图中的相对位移向量将对指出该像素所属的低层中心。通过计算检测文本框中的低层中心和高层目标中心的距离,TCL特征图中的像素能够被分成几组文本实例。与连通分量分析相比,它将高层对象知识引入计算中,它被证实更有效。3.4节将会对点对边对齐方法做更详细的介绍。我们在每个文本实例的中心线上选取合适数量的点,借助TBO映射计算上下边界对应点,最终重建任意形状场景文本的表示。
3.3 Network Architecture
在这篇文章中,我们使用移除全连接层的ResNet50作为网络的backbone。将不同层次的特征图以PFN的方式融合三次,输出的融合特征X为输入图片大小的1/4。我们连续的追加两个CAB模块在网络后来获得丰富的上下文信息。在上下文增强特征映射X''后面添加四个分支,TCL和其他增强特征并行计算,这里我们设置1*1的卷基层来让输出通道设置为:TCL, TCO, TVO, TBO:{1, 2, 8, 4},FPN中所有的特征通道数都被设置为128。

Context Attention Block。FCN的分割结果和后处理步骤主要依赖于局部信息。而我们提出的CAB利用自我注意力机制来抓取上下文信息以增强特征表示,细节描述在图4。为了减轻直接使用自我注意所带来的巨大计算开销,CAB只考虑了特征图中每个位置与同一水平或垂直列中其他位置的相似性。特征图X是RestNet50的输出,其尺寸是N*H*W*C。为了收集水平上下文信息,我们并行设置了3个卷积层来获得{fθ,fφ,fg}并将他们reshape成为{N*H}*W*C的形状,然后将fφ乘以fθ的转置来获得{N*H}*W*W尺寸的注意力特征图,并使用一个Sigmoid函数进行激活。一个水平上下文增强信息特征,最终会被resize到N*H*W*C大小,并与fg相乘。获取垂直方向的上下文信息略有不同,初始时,{fθ,fφ,fg}被转置成{N*H*C*W},如图4中蓝色盒展示的那样。同时,使用一条短路径来保持局部特征。concate水平上下文特征,竖直上下文特征和短链接特征,并使用1*1卷积层来将特征X‘的通道数减少。CAB模块能够从水平和竖直两个方向来抓取长连接像素的上下文信息。除此之外,紫色和青色方框表示的卷积层共享权重。通过串行连接两个CAB,每个像素最终可以捕获所有像素的长程依赖关系,如图4底部所示,得出一个更加有效的内容增强特征图X'',这也有助于避免在阅读更具挑战性的文本实例(如长文本)时由于感受野有限而造成的问题。
3.4 Text Instance Segmentation
对于大多数的任意形状文本检测器,采用连通分量分析等后处理技术实现文本实例分割,不能很好地融合高层次的对象知识,在复杂场景下很容易检测失败。在这一节中,我们描述如何使用高级别目标特征TCL、TCO和TVO特征图生成一个文本实例语义分割结果。
Point-to-Quad Assignment.如图3中描述的那样,文本实例分割的第一步是利用TCL和TVO特征图检测出候选文本四边形。类似EAST算法,我们将TCL特征图二值化,所有的像素值在[0, 1]之间,给定一个阈值,使用TVO特征图提供的四个顶点偏移来恢复相应的四边形边界。当然,NMS被用于抑制过度的候选框。最终的四边形候选框展示在图3b中。这些候选四边形可以被认为依赖高级知识。文本实例分割中的第二个也是最后一个步骤是将二进制TCL特征图中的映射文本区域聚类成为文本实例。如图3c所示,TCO特征图是指向边界框中心TCL中像素的的偏移量的像素级预测。我们假设属于同一文本实例的TCL特征图中的像素指向同一个对象级别的中心,通过将响应像素分配给第一步中生成的四边形框,将TCL映射聚类成多个文本实例。此外,我们不关心第一步生成的文本框是否完全包围输入图像的文本区域,并且预测框之外的像素将大部分分配给相应的文本实例。因为集成了高级别目标知识和低级别的像素信息,候选的后处理聚类TCL特征图中的每个像素到它所匹配的最佳文本实例。并且能够帮助不仅仅分隔近距离的文本实例,也能够在处理长文本时减少文本实例的分割问题。
3.5 Label Generation and Training Objectives
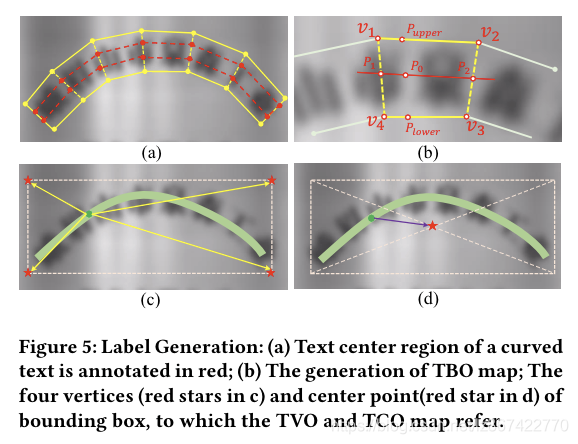
在这个部分,TCL TCO TVO 和 TBO特征图将会被详细讨论。TCL是文本区域的收缩版本,是区分文本/非文本的单通道分割特征图。其他标签特征图如TCO TVO TBO,是相对于TCL特征图汇总哪些像素的像素偏移量。对于每个文本实例,我们通过标注多边形的最小包围来计算中心和四点坐标,如图5(c)(d)中展示的那样。TCO特征图是TCL特征图和边界框中心的偏移量,而TVO是四个边界框顶点距离TCL特征图的偏移量。因此TCO和TVO特征图的通道数为2和8,因为每个点需要两个通道来表示位移{x,y}。同时,TBO决定了在TCL特征图中的上下边界,因此是一个4通道的偏移量特征图。
下面是关于TBO特征图的更多详细信息。对于一个四边形文本标注,其顶点为{V1, V2, V3, V4},其中V1为左上角顶点,排列顺序为顺时针,如图5(b)中展示的那样,TBO生成的过程主要分为两步:首先,我们在TCL特征图每个点的上下边界上找到一个对应的点对,然后计算相应的偏移量。利用四边形的上边和下边的平均斜率,可以确定出TCL特征图中相交P0的直线。并且用代数方法可以很容易地直接计算出四边形左右边直线的交点{P1,P2}。p0的一对对应点{Pupper,Plower}可以从遗下公式确定:
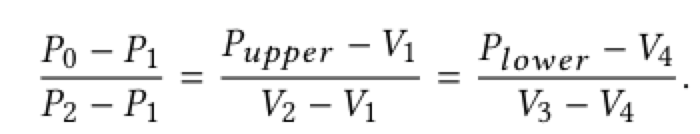
在第二步,P0和{Pupper,Plower}之间的偏移量可以轻易获得。将超过四个顶点的多边形视为一系列连接在一起的四边形,并且可以由多个四边形逐步生成多边形的TBO。对于非TCL特征图中的像素,为了方便起见,其对应的几何特征设置为0.
在训练阶段,所有的网络将会以端到端的方式进行训练,计算loss的公式如下:
![]()
其中, Ltcl,Ltco,Ltvo和Ltbo分别代表TCL, TCO,TVO,和TBO特征图的损失。第一个是二元分割损失,另外一个是回归损失。
我们利用交叉上损失训练了分割分支,使用平滑后的L1损失来优化回归。λ1、λ2、λ3和λ4是损失去那种,用来平衡四个任务,使得其在这个模型中重要程度相同,因此我们设置了{1.0, 0.5, 0.5, 1.0}来让四个损失梯度值在反向传播中作用程度均等。
4 EXPERIMENTS
为了比较SAST与现有方法的有效性,我们对icdar2015、ICDAR2017-MLT、SCUT-CTW1500和Total text四个公共文本检测数据集进行了深入的实验。
4.1 Datasets
【数据集介绍略】
4.2 Implementation Details
Training.backboe是预加载ImageNet权重的ResNet-50。跳跃链接的格式是FPN的方式,卷积层的输出通道数被这只为128,最终的特征尺寸为输入图片的1/4。所有的上采样操作均使用双线性差值;分类分支使用sigmoid函数进行激活;回归分支如TCO TVO TBO特征图是最后的卷积层的直接输出。训练过程被划分为两步:warming-up阶段和fine-tuning阶段。在warming-up阶段,我们使用Adam优化器训练,学习率设置为1e-4,decay系数设置为0.94,训练数据集为SynthText。在fine-tuning阶段,学习率被重新初始化为1e-4,将模型在ICDAR 2015, ICDAR2017-MLT, SCUT-CTW1500 和 Total-Text等数据集上进行微调。
所有的实验都在如下配置的工作站中进行。PU: Intel(R) Xeon(R) CPU E5-2620 v2 @2.10GHz x16; GPU: NVIDIA TITAN Xp×4; RAM: 64GB。在训练时,我们设置每个GPU的batch_size为8。
Data Augmentation.我们随机裁剪文本图片的区域,然后放缩和pad到512*512。特别是弯曲多边形的文本标签数据,我们裁剪时注意不会跨文本实例,避免破坏多边形标注。裁剪图片区域将会被随机在4个角度之间翻转:(0◦,90◦,180◦,and270◦) 。标准化减RGB均值的方法使用的是ImageNet数据集的方法。标注为“DO NOT CARE”的文本区域或最短边低于8个像素的文本区域将会在训练过程被忽略。
Testing.在推理阶段,除非另有说明,否则对于单尺度测试,我们将长边设置为1536,对于多尺度测试,我们将长边设置为512、768、1536和2048,同时保持长宽比不变。为每个测试尺度指定一个指定的范围,并使用SNIP[31]指示的NMS组合来自不同尺度的检测(多尺度集成)。
4.3 Ablation Study
我们构建了几个消融实验来进行SAST的分析,具体讨论如下:
The Effectiveness of TBO, TCO and TVO.
The Trade-off between Speed and Accuracy.
The Effectiveness of Context Attention Blocks.
4.4 Evaluation on Curved Text Benchmark
4.5 Evaluation on ICDAR 2015
4.6 Evaluation on ICDAR2017-MLT
5 CONCLUSION AND FUTURE WORK
在这篇文章中,我们提出了一个高效的一阶段任意形状的文本检测器,该检测器带有上下文注意力模块和一种点对边的对齐方法机制,能够将高级别的目标知识和低级别的像素信息结合起来获得一个增强的分割结果。验结果表明,该方法能有效地检测任意形状的文本,并能很好地推广到多语言场景文本数据集。大量的结果表明,SAST算法可以缓解基于分段的文本检测器中的一些常见问题,如文本被分段问题和相邻文本实例的分离问题等。此外,使用一个常用的GPU,SAST运行速度很快,对于一些实时应用来说可能已经足够了,如增强现实翻译等。然而,在一些极端情况下很难检测到,这些极端情况主要是非常小的文本区域。未来,我们将致力于提高小文本检测的能力,并开发一个针对任意形状文本的端到端文本阅读系统。
智能推荐
python输入小数报错_python学习之路之int()奇怪的报错-程序员宅基地
文章浏览阅读1.8k次。今天闲来无事看了下python基础知识,当学到数据类型转换的int()方法时候。发现了这么一个有意思的事情,算是IDE或是解释器的一个小BUG。(具体原因暂不明,留待以后查找问题)先讲下环境操作系统: windows10python版本:3.6.5IDE环境: pycharm edu 2018.1 x64解释器: CPython然后 int()方法的作用函数说明int(x..._"请问下面代码存在什么问题? >>> age = 18 >>> message = \"祝杜小帅\" + age +"
python cmap_Python cmap包_程序模块 - PyPI - Python中文网-程序员宅基地
文章浏览阅读1.8k次。cmapy在python中使用matplotlib colormaps和opencv。matplotlib提供了很多nice colormaps。cmapy将这些颜色映射公开为颜色列表,这些颜色列表可与opencv一起用于为图像着色或用于python中的其他绘图任务。Original imageviridis请参阅此all colormaps example中截至matplotlib 2.2.3的..._python cmap
mysql 触发器 注意事项_MySQL触发器的利弊-使用MySQL触发器时应该注意的事项-程序员宅基地
文章浏览阅读783次。在MySQL中,触发器可以在你执行INSERT、UPDATE或DELETE的时候,执行一些特定的操作。在创建触发器时,可以指定是在执行SQL语句之前或是之后执行这些操作。通过触发器,你可以实现一些业务逻辑或一些数据限制,在简化应用程序逻辑,优化系统性能时非常有用。但在使用MySQL触发器也有一些注意事项,否则会导致触发器不能工作或不按指定的方式工作。1. MySQL触发器注意事项MySQL触发器使..._加触发器会引发什么问题
kthreadd和init进程的启动(二)_init second_stage-程序员宅基地
文章浏览阅读436次。注:此文章主要基于展锐Android R代码加上学习总结自IngresGe大佬的分析文章目录一、kthreadd二、init三、Init 进程入口3.1 ueventd_main3.2 FirstStageMain3.3 SetupSelinux3.4 SecondStageMaininit.rc文件解析一、kthreadd/bsp/kernel/kernel4.14/kernel/kthread.cint kthreadd(void *unused){ struct task_struct *_init second_stage
TCP Flags标志位介绍-程序员宅基地
文章浏览阅读1.2w次,点赞3次,收藏41次。传输控制协议(Transmission Control Protocol,TCP)是一种传输层协议。TCP使数据包从源到目的地的传输更加顺畅。它是一种面向连接的端到端协议。每个数据包由TCP包裹在一个报头中,该报头由10个强制字段共20个字节和一个0到40 字节的可选数据字段组成。如下图所示:来自于https://www.geeksforgeeks.org 1.源端口号(Source Port):16bits,该字段标识发送方应用程序的端口号。 2.目..._tcp flags
Java面试题:什么是JDBC以及如何在Java中使用它进行数据库操作?-程序员宅基地
文章浏览阅读149次。JDBC(Java Database Connectivity,Java数据库连接)是Java语言连接数据库的一种规范,它为Java应用程序提供了连接各种关系数据库的统一接口。通过JDBC,Java应用程序可以访问任何提供了JDBC驱动的数据库。注意:从JDBC 4.0开始,不再需要显式加载驱动,因为驱动会在运行时自动加载。但是,如果你正在使用旧版本的JDBC或者出于某种原因需要显式加载驱动,那么仍然可以使用上述方法。通常,你可以使用try-with-resources语句来自动管理这些资源的关闭。
随便推点
hive序列生成_Hive实现自增列的两种方法-程序员宅基地
文章浏览阅读3.9k次。多维数据仓库中的维度表和事实表一般都需要有一个代理键,作为这些表的主键,代理键一般由单列的自增数字序列构成。Hive没有关系数据库中的自增列,但它也有一些对自增序列的支持,通常有两种方法生成代理键:使用row_number()窗口函数或者使用一个名为UDFRowSequence的用户自定义函数(UDF)。用row_number()函数生成代理键INSERT OVERWRITE TABLEmy_hi..._hive 生成序列
论文阅读笔记《Meta-learning for semi-supervised few-shot classification》_self-supervised continuous meta-learning for few-s-程序员宅基地
文章浏览阅读2.2k次,点赞2次,收藏15次。核心思想 本文提出一种基于半监督训练的小样本分类算法。所谓半监督就是在训练集中即包括带有标签的图片,也包含不带有标签的图片,作者认为人类在学习物品分类时,也会观察到许多非目标类别的物体,这种学习方式更加接近实际使用需求,并且可以提高算法的泛化能力。本文以原型网络(Prototypical Network)作为baseline,在此基础上提出了三种改进型,以满足无监督训练的需要。与原型网络(Prototypical Network)相似,训练集也划分为支持集与查询集,不同的是在支持集中还包含有不带有标签的_self-supervised continuous meta-learning for few-shot image classification
【终极方案】解决警告信息cudart64_100.dll_copy cudart64_100.dll-程序员宅基地
文章浏览阅读69次。【代码】【终极方案】解决警告信息cudart64_100.dll。_copy cudart64_100.dll
第一篇 使用numpy创建数组(一维、多维)_numpy创建一维数组-程序员宅基地
文章浏览阅读1.1w次,点赞5次,收藏34次。1、numpy创建一维数组[ 1] 通过列表生成数组import numpy as npdata1=[5,7,9,20]#列表类型 list arr1=np.array(data1) #ndarray数组类型 numpy.ndarrayprint(data1)print(type(data1)) #type输出数据类型#print((data1,type(data1)print(arr1)print(type(arr1))结果如下:我们可以发现数据类型已经发生了改变,li_numpy创建一维数组
Python|函数——自定义函数_自定义整数幂运算无参函数python-程序员宅基地
文章浏览阅读1.2k次。本文是笔者学习李立宗老师的Python课程后整理的学习笔记,希望能帮助到有需要的同学,侵删。_自定义整数幂运算无参函数python
c/c++的字符和字符串输入输出_c++输出字符串-程序员宅基地
文章浏览阅读1.3k次,点赞10次,收藏14次。c/c++的字符和字符串输入输出._c++输出字符串