scikit-learn 朴素贝叶斯类库_scikit-learn multinomialnb-程序员宅基地
技术标签: 机器学习
scikit-learn 朴素贝叶斯类库
朴素贝叶斯方法是基于贝叶斯定理的一组有监督学习算法,即“简单”地假设每对特征之间相互独立。 给定一个类别 y y y 和一个从$ x_1$ 到 x n x_n xn的相关的特征向量, 贝叶斯定理阐述了以下关系:
P ( y ∣ x 1 , x 2 , … , x n ) = P ( y ) P ( x 1 , … , x n ∣ y ) P ( x 1 , … , x n ) P(y|x_1,x_2,\ldots,x_n) = \frac{P(y)P(x_1,\ldots,x_n|y)}{P(x_1,\ldots,x_n )} P(y∣x1,x2,…,xn)=P(x1,…,xn)P(y)P(x1,…,xn∣y)
使用简单(navie)的假设-每对特征之间都是相互独立的:
P ( x i ∣ y , x 1 , x 2 , … , x i − 1 , x i + 1 , … , x n ) = P ( x i ∣ y ) P(x_i|y,x_1,x_2,\ldots,x_{i-1},x_{i+1},\ldots,x_n) = P(x_i|y) P(xi∣y,x1,x2,…,xi−1,xi+1,…,xn)=P(xi∣y)
可以对关系式进行化简为:
P ( y ∣ x 1 , … , x n ) = P ( y ) ∏ i = 1 n P ( x i ∣ y ) P ( x 1 , … , x n ) P(y|x_1,\ldots,x_n) = \frac{P(y)\prod_{i=1}^{n}P(x_i|y)}{P(x_1,\ldots,x_n)} P(y∣x1,…,xn)=P(x1,…,xn)P(y)∏i=1nP(xi∣y)
由于在给定的输入中 P ( x 1 , … , x n ) P(x_1,\ldots,x_n) P(x1,…,xn)是常量,使用下面的分类规则:
P ( y ∣ x 1 , … , x n ) ∝ P ( y ) ∏ i = 1 n P ( x i ∣ y ) P(y|x_1,\ldots,x_n) \propto P(y) \prod_{i=1}^{n}P(x_i|y) P(y∣x1,…,xn)∝P(y)i=1∏nP(xi∣y)
y ^ = a r g m a x ⎵ y P ( y ) ∏ i = 1 n P ( x i ∣ y ) \hat{y} = arg \ \underbrace{max}_{y}P(y) \prod_{i=1}^{n} P(x_i|y) y^=arg y
maxP(y)i=1∏nP(xi∣y)
我们可以使用最大后验概率(Maximum A Posteriori, MAP) 来估计 P ( y ) P(y) P(y)和 P ( x i ∣ y ) P(x_i|y) P(xi∣y),前者是训练集中类别 y y y的相对频率。各种各样的的朴素贝叶斯分类器的差异大部分来自于处理 P ( x i ∣ y ) P(x_i \mid y) P(xi∣y)分布时的所做的假设不同。
尽管其假设过于简单,在很多实际情况下,朴素贝叶斯工作得很好,特别是文档分类和垃圾邮件过滤。这些工作都要求 一个小的训练集来估计必需参数。相比于其他更复杂的方法,朴素贝叶斯学习器和分类器非常快。 分类条件分布的解耦意味着可以独立单独地把每个特征视为一维分布来估计。这样反过来有助于缓解维度灾难带来的问题。
另一方面,尽管朴素贝叶斯被认为是一种相当不错的分类器,但却不是好的估计器(estimator),所以不能太过于重视从predict_proba输出的概率。
1.高斯朴素贝叶斯
GaussianNB实现了运用于分类的高斯朴素贝叶斯算法。特征的可能性(即概率)假设为高斯分布:
P ( x i ∣ y ) = 1 2 π σ y 2 e x p ⟮ − ( x i − μ y ) 2 2 σ y 2 ⟯ P(x_i \mid y) = \frac{1}{\sqrt{2\pi\sigma_y^2}} exp\lgroup -\frac{(x_i - \mu_y)^2}{2\sigma_y^2}\rgroup P(xi∣y)=2πσy21exp⟮−2σy2(xi−μy)2⟯
参数 σ y \sigma_y σy和 μ y \mu_y μy使用极大似然然估计。
2. 多项分布朴素贝叶斯
MultinomialNB实现了服从多项分布数据的朴素贝叶斯算法,也是用于文本分类(这个领域中数据往往以词向量表示,尽管在实践中 tf-idf 向量在预测时表现良好)的两大经典朴素贝叶斯算法之一。布参数由每类 y y y 的 θ y = ( θ y 1 , … , θ y n ) \theta_y = (\theta_{y1},\ldots,\theta_{yn}) θy=(θy1,…,θyn)向量决定, 式中 n n n 是特征的数量(对于文本分类,是词汇量的大小) θ y i \theta_{yi} θyi 是样本中属于类 y y y 中特征 i i i 概率 P ( x i ∣ y ) P(x_i \mid y) P(xi∣y)。
参数 θ y \theta_y θy 使用平滑过的最大似然估计法来估计,即相对频率计数:
θ ^ y i = N y i + α N y + α n \hat{\theta}_{yi} = \frac{N_{yi} + \alpha}{N_y + \alpha n} θ^yi=Ny+αnNyi+α
式中 N y i = ∑ x ∈ T x i N_{yi} = \sum_{x \in T} x_i Nyi=∑x∈Txi 是 训练集 T T T 中 特征 i i i在类 y y y 中出现的次数, N y = ∑ i = 1 ∣ T ∣ N y i N_{y} = \sum_{i=1}^{|T|} N_{yi} Ny=∑i=1∣T∣Nyi 是类 y y y 中出现所有特征的计数总和。
先验平滑因子 α ≥ 0 \alpha \ge 0 α≥0 应用于在学习样本中没有出现的特征,以防在将来的计算中出现0概率输出。 把 α = 1 \alpha = 1 α=1 被称为拉普拉斯平滑(Lapalce smoothing),而 α < 1 \alpha < 1 α<1 被称为利德斯通平滑(Lidstone smoothing)。
3. 伯努利朴素贝叶斯
BernoulliNB实现了用于多重伯努利分布数据的朴素贝叶斯训练和分类算法,即有多个特征,但每个特征 都假设是一个二元 (Bernoulli, boolean) 变量。 因此,这类算法要求样本以二元值特征向量表示;如果样本含有其他类型的数据, 一个BernoulliNB实例会将其二值化(取决于binarize参数)。
伯努利朴素贝叶斯的决策规则基于
P ( x i ∣ y ) = P ( i ∣ y ) x i + ( 1 − P ( i ∣ y ) ) ( 1 − x i ) P(x_i \mid y) = P(i \mid y) x_i + (1 - P(i \mid y))(1 - x_i) P(xi∣y)=P(i∣y)xi+(1−P(i∣y))(1−xi)
与多项分布朴素贝叶斯的规则不同 伯努利朴素贝叶斯明确地惩罚类 y y y中没有出现作为预测因子的特征 i i i ,而多项分布分布朴素贝叶斯只是简单地忽略没出现的特征。
BernoulliNB一共有4个参数,其中3个参数的名字和意义和MultinomialNB完全相同。唯一增加的一个参数是binarize。这个参数主要是用来帮BernoulliNB处理二项分布的,可以是数值或者不输入。如果不输入,则BernoulliNB认为每个数据特征都已经是二元的。否则的话,小于binarize的会归为一类,大于binarize的会归为另外一类。
在文本分类的例子中,词频向量(word occurrence vectors)(而非词数向量(word count vectors))可能用于训练和用于这个分类器。 BernoulliNB可能在一些数据集上可能表现得更好,特别是那些更短的文档。实际使用时,最好对两个模型都进行评估。
4. 在莺尾花数据集上的测试代码及结果
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
from sklearn.preprocessing import StandardScaler
from sklearn.naive_bayes import GaussianNB, MultinomialNB
from sklearn.pipeline import Pipeline
from sklearn.neighbors import KNeighborsClassifier
#解决中文显示乱码的问题
from matplotlib.font_manager import FontProperties
myfont = FontProperties(fname='/home/liyuanshuo/Downloads/simheittf/simhei.ttf')
def iris_type(s):
it = {
b'Iris-setosa': 0, b'Iris-versicolor': 1, b'Iris-virginica': 2}
return it[s]
def GasssianNB_test():
data = np.loadtxt('iris.data', dtype=float, delimiter=',', converters={
4: iris_type})
print(data)
x, y = np.split(data, (4, ), axis=1)
x = x[:, :2]
print(x)
print(y)
gnb = Pipeline([('sc', StandardScaler()), ('clf', GaussianNB())])
gnb.fit(x, y.ravel())
#下面使用多项式分布贝叶斯和K紧邻分类作为对比
# gnb = MultinomialNB().fit(x, y.ravel())
# gnb = KNeighborsClassifier(n_neighbors=5).fit(x, y.ravel())
#下面画图展示结果
N, M = 500, 500 #横纵各采样多少个值
x1_min, x1_max = x[:, 0].min(), x[:, 0].max() #第0列的范围
x2_min, x2_max = x[:, 1].min(), x[:, 1].max() #第一列的范围
t1 = np.linspace(x1_min, x1_max, N)
t2 = np.linspace(x2_min, x2_max, N)
x1, x2 = np.meshgrid(t1, t2) #生成网格采样点
x_test = np.stack((x1.flat, x2.flat), axis=1) #测试点
# mpl.rcParams['font.sans-serif'] = ['simhei']
mpl.rcParams['axes.unicode_minus'] = False
# plt.rcParams['font.sans-serif'] = ['simhei']
plt.rcParams['axes.unicode_minus'] = False
cm_light = mpl.colors.ListedColormap(['#77E0A0', '#FF8080', '#A0A0FF'])
cm_dark = mpl.colors.ListedColormap(['g', 'r', 'b'])
y_hat = gnb.predict(x_test) #预测值
y_hat = y_hat.reshape(x1.shape) #保证输入和输出的形状相同
plt.figure(facecolor='w')
plt.pcolormesh(x1, x2, y_hat, cmap=cm_light) #显示预测值
plt.scatter(x[:, 0], x[:, 1], c='y', edgecolors='k', s=50, cmap=cm_dark) #显示样本
plt.xlabel(u'花萼长度', fontsize=14, fontproperties=myfont)
plt.ylabel(u'花萼宽度', fontsize=14, fontproperties=myfont)
plt.xlim(x1_min, x1_max)
plt.ylim(x2_min, x2_max)
plt.title('GaussianNB对莺尾花数据分类结果', fontsize=18, fontproperties=myfont)
plt.grid(True)
plt.show()
plt.savefig('GaussianNB对莺尾花数据分类结果.png')
#训练集上的预测结果
y_hat = gnb.predict(x)
y = y.reshape(-1)
result = y_hat==y
print(y_hat)
print(result)
acc = np.mean(result)
print('训练集分类准确率: %.2f%%'%(100*acc))
if __name__ == '__main__':
GasssianNB_test()
结果图片如下:
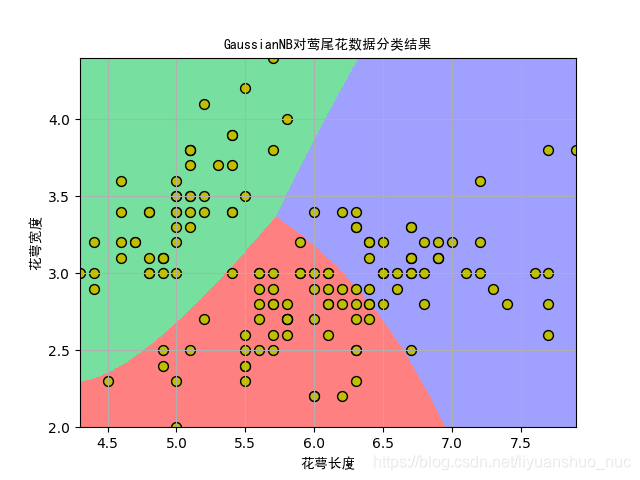
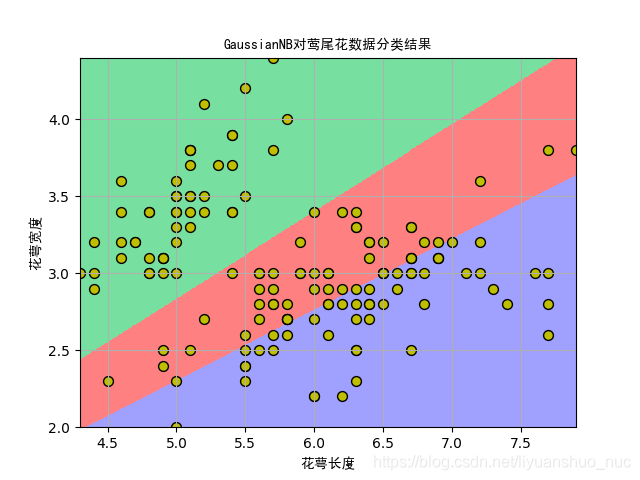
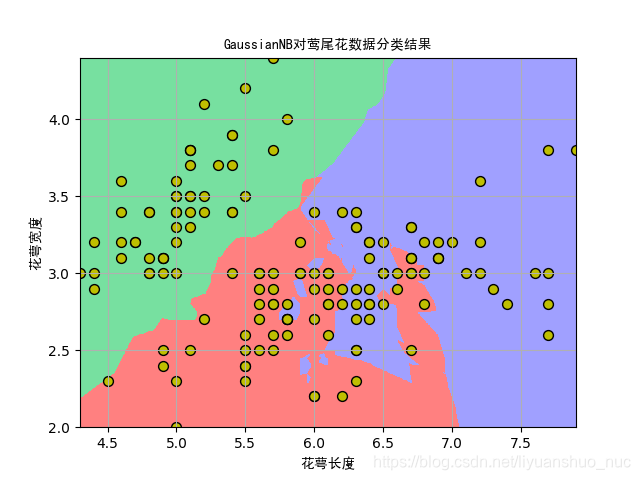
5使用随机数据实现的代码
import numpy as np
from sklearn.naive_bayes import GaussianNB, MultinomialNB
from sklearn import metrics
def MultinomialNB_test():
np.random.seed(0)
M = 20
N = 5
x = np.random.randint(2, size=(M, N))
x = np.array(list(set([tuple(t) for t in x])))
M = len(x)
y = np.arange(M)
print('样本个数: %d,特征数目: %d'%x.shape)
print('样本为:\n', x)
mnb = MultinomialNB(alpha=1)
mnb.fit(x, y)
y_hat = mnb.predict(x)
print('预测类别: ', y_hat)
print('预测准确率: %.2f%%'%(100*np.mean(y_hat==y)))
print('系统得分: ', mnb.score(x, y))
print('系统得分: ', metrics.accuracy_score(y, y_hat))
err = y_hat != y
for i, e in enumerate(err):
if e:
print(y[i], ': \t', x[i], '被认为与', x[y_hat[i]], '一个类别')
if __name__ == '__main__':
MultinomialNB_test()s
智能推荐
php 公众号 获取菜单,微信公众号利用PHP创建自定义菜单的方法-程序员宅基地
文章浏览阅读184次。在使用通用接口前,你需要做以下两步工作:1.拥有一个微信公众账号,并获取到appid和appsecret(在公众平台申请内测资格,审核通过后可获得)2.通过获取凭证接口获取到access_token注意:access_token是第三方访问api资源的票据;access_token对应于公众号是全局唯一的票据,重复获取将导致上次获取的access_token失效。访问下面这个地址(注意替换你的ap..._php公众号菜单创建后获取
未明学院:用excel不好吗?为什么还要学python?_excel 为什么还要学python-程序员宅基地
文章浏览阅读311次。原创:未明学院在互联网管理、金融、物流等领域,往往离不开数据处理、统计分析等辅助决策的操作。传统的商业分析(Business Analysis),定性占比很大,以相对简单的数据处理为辅助,人们使用的分析工具主要是Excel;然而,自Excel2007版起,最大支持的工作表大小为16,384 列 × 1,048,576 行,超出最大行列数单元格中的数据将会丢失。在大数据背景的..._excel 为什么还要学python
交易平台开发:构建安全/高效/用户友好的在线交易生态圈-程序员宅基地
文章浏览阅读768次,点赞10次,收藏8次。在数字化浪潮的推动下,农产品现货大宗商品撮合交易平台已成为连接全球买家与卖家的核心枢纽。随着电子商务的飞速发展,一个安全、高效、用户友好的交易平台对于促进交易、提升用户体验和增加用户黏性至关重要。本文将深入探讨交易平台开发的关键要素,助您构建一个成功的在线交易生态圈。综上所述,农产品/现货大宗商品/等交易平台开发需要关注技术架构、用户体验、安全与风险控制等核心要素,并遵循最佳实践,不断迭代优化。同时,紧跟未来趋势,利用人工智能、区块链等技术,为用户打造更加安全、高效、便捷的在线交易生态圈。
eNSP的使用-程序员宅基地
文章浏览阅读1.6k次。1-进入华为路由器界面配置ipThe device is running!####################################Nov 1 2016 23:39:24-08:00 Huawei %%01IFNET/4/BOARD_ENABLE(l)[0]:Board 1 has been available. <Huawei>Nov 1 2016 23:39:2..._has been available.
python 偏函数(functoosl, partial)_functoosl.wrap-程序员宅基地
文章浏览阅读396次。functools在python中是一个很重要的模块,提供了很多有用的高阶函数(一个可以接受函数作为参数或者返回值是一个函数的 函数)。比如其中一个就是偏函数(Partial function)。在介绍函数参数时,我们就讲过,通过设定参数的默认值,可以降低调用函数的难道,比如: python中int函数,把字符串转换成数字,有一个参数是base,默认值是10,表示函数十进制转换,如果改变这个bas_functoosl.wrap
Vue中的nextTick方法的作用是什么?_vue nexttick的作用-程序员宅基地
文章浏览阅读365次。更新循环结束之后调用该回调函数。这样可以确保回调函数在操作更新后的。更新后执行回调的方式。这对于确保在更新视图后操作。通过将回调函数传递给。更新后执行的操作,例如获取渲染后的。更新循环结束之后执行延迟回调。元素的尺寸、触发子组件的更新等。更新视图时,通常是异步执行的,方法来处理一些需要在。_vue nexttick的作用
随便推点
AOP--面向切面编程-程序员宅基地
文章浏览阅读417次。切入点表达式:描述切入点方法的一种表达式。
MFC添加背景图片_mfc设置背景图片-程序员宅基地
文章浏览阅读5.5k次,点赞8次,收藏92次。很长时间没有接触MFC相关的知识了,我大概是在大二时候学习的MFC相关知识及图像处理,现在由于要帮个朋友完成个基于C++的程序,所以又回顾了下相关知识。的确,任何知识一段时间过后都比较容易忘记,但回顾起来还是很有印象的。这篇文章主要是回顾以前的MFC基础知识,给对话框添加背景图片和给按钮button添加背景图片;希望此篇基础性文章对大家有所帮助!同时为下次做MFC相关知识提供..._mfc设置背景图片
MTCNN 论文学习_mtcnn算法论文-程序员宅基地
文章浏览阅读772次。Joint Face Detection and Alignment using Multi-task Cascaded Convolutional NetworkAbstract1. Introduction2. ApproachA. Overall FrameworkB. CNN ArchitectureC. Training3. Experiments论文地址:https://arxiv...._mtcnn算法论文
GPU加速计算_gpu实际使用功率怎么算的-程序员宅基地
文章浏览阅读944次。GPU加速计算NVIDIA A100 Tensor Core GPU 可针对 AI、数据分析和高性能计算 (HPC),在各种规模上实现出色的加速,应对极其严峻的计算挑战。作为 NVIDIA 数据中心平台的引擎,A100 可以高效扩展,系统中可以集成数千个 A100 GPU,也可以利用 NVIDIA 多实例 GPU (MIG) 技术将每个 A100 划分割为七个独立的 GPU 实例,以加速各种规模的工作负载。第三代 Tensor Core 技术为各种工作负载的更多精度水平提供加速支持,缩短获取洞见以及产品_gpu实际使用功率怎么算的
用 Python 制作各种用途的二维码-程序员宅基地
文章浏览阅读191次。当你提到二维码时,大多数人想到的是仓库管理或产品标签等 "工业 "应用,但这篇文章在很大程度上是关于二维码的个人和社会用途。有趣的事实二维(QR)码是在1994年发明的,最近几年由于新冠肺炎的出现,它的"非接触 "特性使其应用广泛。二维码具备良好的解决方案。它可以被几乎所有的手机使用默认的照片应用程序扫描,同样,扫描它们也会根据它们的背景触发某种动作。例如,一个含有URL的QR码允许你在浏览器中打..._python实现二维码隐藏
k8s修改pod固化方案_pod怎么固化配置-程序员宅基地
文章浏览阅读1.6k次。方案思路:先在docker 容器级别将所需改动完成,然后commit该容器为一个新的镜像到仓库,最后在k8s ds中启用该镜像。操作流程:一、定位到apigateway后台docker容器,并进入[root@hdp1 shanghaibank-hotfix]# docker ps |grep apigateway923002acb833 63f4ed014d9b _pod怎么固化配置