sparkSQL基础_spark 创建用户类-程序员宅基地
目录
1.sparksql概述
1.1、什么是Spark SQL

- Spark SQL is Apache Spark's module for working with structured data.
- SparkSQL是apache Spark用来处理结构化数据的一个模块
- SparkSQL支持查询原生的RDD。 RDD是Spark平台的核心概念,是Spark能够高效的处理大数据的各种场景的基础。
- 能够在Scala中写SQL语句。支持简单的SQL语法检查,能够在Scala中写Hive语句访问Hive数据,并将结果取回作为RDD使用。
1.2、SparkSQL的数据源
SparkSQL的数据源可以是JSON类型的字符串,JDBC,Parquent,Hive,HDFS等。
1.3、SparkSQL底层架构
(1)首先拿到sql后解析一批未被解决的逻辑计划;
(2)再经过分析得到分析后的逻辑计划;
(3)再经过一批优化规则转换成一批最佳优化的逻辑计划;
(4)再经过SparkPlanner的策略转化成一批物理计划;
(5)最后经过消费模型转换成一个个的Spark任务执行。
2. sparksql的四大特性
2.1、易整合

- 将SQL查询与Spark程序无缝混合;
- 可以使用不同的语言进行代码开发:
- java
- scala
- python
2.2、统一的数据源访问

- 以相同的方式连接到任何数据源;
- sparksql后期可以采用一种统一的方式去对接任意的外部数据源:
dataFrame = sparkSession.read.文件格式的方法名("该文件格式的路径")
2.3、兼容hive

- sparksql可以支持hivesql
2.4、支持标准的数据库连接

- sparksql支持标准的数据库连接JDBC或者ODBC
3. DataFrame概述
3.1、DataFrame是什么
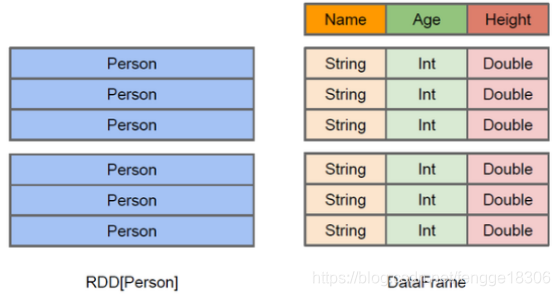
- DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库的二维表格;
- DataFrame带有Schema元信息,即DataFrame所表示的二维表数据集的每一列都带有名称和类型,但底层做了更多的优化;
- DataFrame可以从很多数据源构建:
- 比如:已经存在的RDD、结构化文件、外部数据库、Hive表。
- RDD可以把它内部元素看成是一个java对象;
- DataFrame可以把内部是一个Row对象,它表示一行一行的数据;
- 可以把DataFrame这样去理解
- RDD+schema元信息
- dataFrame相比于rdd来说,多了对数据的描述信息(schema元信息)
3.2、DataFrame和RDD的优缺点
(1)RDD
优点:
1、编译时类型安全:开发会进行类型检查,在编译的时候及时发现错误;
2、具有面向对象编程的风格。
缺点:
1、构建大量的java对象占用了大量heap堆空间,导致频繁的GC:
RDD它的数据量比较大,后期都需要存储在heap堆中,而heap堆中的内存空间有限,出现频繁的垃圾回收(GC),程序在进行垃圾回收的过程中,所有的任务都是暂停,影响程序执行的效率。
2、数据的序列化和反序列性能开销很大:
在分布式程序中,对象(对象的内容和结构)是先进行序列化,发送到其他服务器,进行大量的网络传输,然后接受到这些序列化的数据之后,再进行反序列化来恢复该对象。
(2)DataFrame
- DataFrame引入了schema元信息和off-heap(堆外空间)
优点:
1、DataFrame引入off-heap,大量的对象构建直接使用操作系统层面上的内存,不在使用heap堆中的内存,这样一来heap堆中的内存空间就比较充足,不会导致频繁GC,程序的运行效率比较高,它是解决了RDD构建大量的java对象占用了大量heap堆空间,导致频繁的GC这个缺点。
2、DataFrame引入了schema元信息---就是数据结构的描述信息,后期spark程序中的大量对象在进行网络传输的时候,只需要把数据的内容本身进行序列化就可以,数据结构信息可以省略掉。这样一来数据网络传输的数据量是有所减少,数据的序列化和反序列性能开销就不是很大了。它是解决了RDD数据的序列化和反序列性能开销很大这个缺点。
缺点:
- DataFrame引入了schema元信息和off-heap(堆外)它是分别解决了RDD的缺点,同时它也丢失了RDD的优点。
1、编译时类型不安全
编译时不会进行类型的检查,这里也就意味着前期是无法在编译的时候发现错误,只有在运行的时候才会发现
2、不在具有面向对象编程的风格
3.3、 读取文件构建DataFrame
(1) 读取文本文件创建DataFrame
第一种方式:读取text文件
//创建dataFrame
val personDF=spark.read.text("/person.txt")
//打印schema信息
personDF.printSchema
//展示数据
personDF.show
第二种方式:调用toDF方法将rdd转换成dataFrame
//加载数据
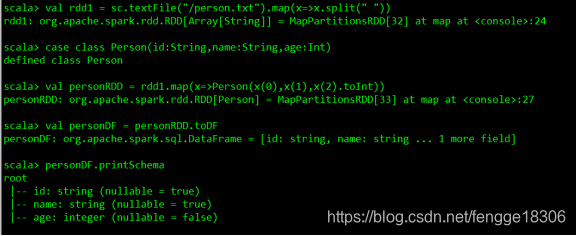
val rdd1=sc.textFile("/person.txt").map(x=>x.split(" "))
//定义一个样例类
case class Person(id:String,name:String,age:Int)
//把rdd与样例类进行关联
val personRDD=rdd1.map(x=>Person(x(0),x(1),x(2).toInt))
//把rdd转换成DataFrame
val personDF=personRDD.toDF//打印schema信息
personDF.printSchema
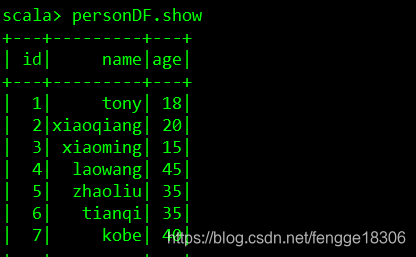
//展示数据
personDF.show
(2)读取json文件创建DataFrame
val peopleDF=spark.read.json("/people.json") //读取json文件创建dataFrame
//打印schema信息
peopleDF.printSchema
//展示数据
peopleDF.show
(3)读取parquet文件创建DataFrame
//创建DataFrame
val usersDF=spark.read.parquet("/users.parquet")//打印schema信息
usersDF.printSchema
//展示数据
usersDF.show
(4)读取JDBC中的数据创建DataFrame(MySql为例)
val mysqlDF:DataFrame = sparkSession.read.jdbc(url,tableName,properties)
(5)读取Hive中的数据加载成DataFrame
val dataFrame = sparkSession.sql("select * from people")
(6) 直接创建
val dataFrame:DataFrame = sparkSession.createDataFrame(rowRDD,schema)
3.4、DataFrame常用操作
(1)DSL风格语法
sparksql中的DataFrame自身提供了一套自己的Api,可以去使用这套api来做相应的处理。
//加载数据
val rdd1=sc.textFile("/person.txt").map(x=>x.split(" "))
//定义一个样例类
case class Person(id:String,name:String,age:Int)
//把rdd与样例类进行关联
val personRDD=rdd1.map(x=>Person(x(0),x(1),x(2).toInt))
//把rdd转换成DataFrame
val personDF=personRDD.toDF
//打印schema信息
personDF.printSchema
//展示数据
personDF.show
//查询指定的字段
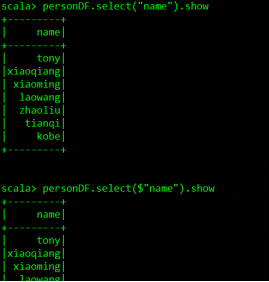
personDF.select("name").show
personDF.select($"name").show
personDF.select(col("name")).show
//实现age+1
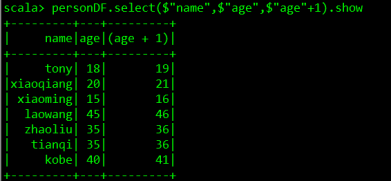
personDF.select($"name",$"age",$"age"+1).show
//实现age大于30过滤
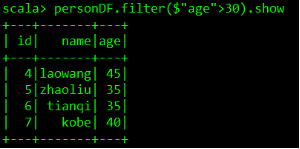
personDF.filter($"age" > 30).show
//按照age分组统计次数
personDF.groupBy("age").count.show

//按照age分组统计次数降序
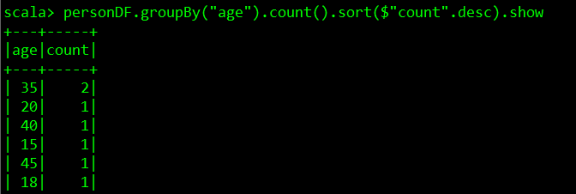
personDF.groupBy("age").count().sort($"count".desc).show
(2)SQL风格语法
- 可以把DataFrame注册成一张表,然后通过sparkSession.sql(sql语句)操作。
//DataFrame注册成表
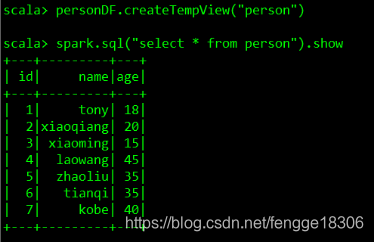
personDF.createTempView("person")
//使用SparkSession调用sql方法统计查询
spark.sql("select * from person").show
spark.sql("select name from person").show
spark.sql("select name,age from person").show
spark.sql("select * from person where age >30").show
spark.sql("select count(*) from person where age >30").show
spark.sql("select age,count(*) from person group by age").show
spark.sql("select age,count(*) as count from person group by age").show
spark.sql("select * from person order by age desc").show
4. DataSet概述
4.1、DataSet是什么
DataSet是分布式的数据集合,Dataset提供了强类型支持,也是在RDD的每行数据加了类型约束。
DataSet是在Spark1.6中添加的新的接口。它集中了RDD的优点(强类型和可以用强大lambda函数)以及使用了Spark SQL优化的执行引擎。
4.2、RDD、DataFrame、DataSet的区别
(1)RDD
RDD:弹性分布式数据集;不可变、可分区、元素可以并行计算的集合。
优点:
- RDD编译时类型安全:编译时能检查出类型错误;
- 面向对象的编程风格:直接通过类名点的方式操作数据。
缺点:
- 序列化和反序列化的性能开销很大,大量的网络传输;
- 构建对象占用了大量的heap堆内存,导致频繁的GC(程序进行GC时,所有任务都是暂停)
RDD的数据结构为:

(2)DataFrame
DataFrame以RDD为基础的分布式数据集。
优点:
- DataFrame带有元数据schema,每一列都带有名称和类型。
- DataFrame引入了off-heap,构建对象直接使用操作系统的内存,不会导致频繁GC。
- DataFrame可以从很多数据源构建;
- DataFrame把内部元素看成Row对象,表示一行行的数据。
- DataFrame=RDD+schema
缺点:
- 编译时类型不安全;
- 不具有面向对象编程的风格。
DataFrame的数据结构为:(类似于二维表)

(3)Dataset
DataSet包含了DataFrame的功能,Spark2.0中两者统一,DataFrame表示为DataSet[Row],即DataSet的子集。
(1)DataSet可以在编译时检查类型;
(2)并且是面向对象的编程接口。
(DataSet 结合了 RDD 和 DataFrame 的优点,并带来的一个新的概念 Encoder。当序列化数据时,Encoder 产生字节码与 off-heap 进行交互,能够达到按需访问数据的效果,而不用反序列化整个对象。)
Dataset中的数据结构:
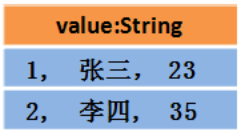
或者

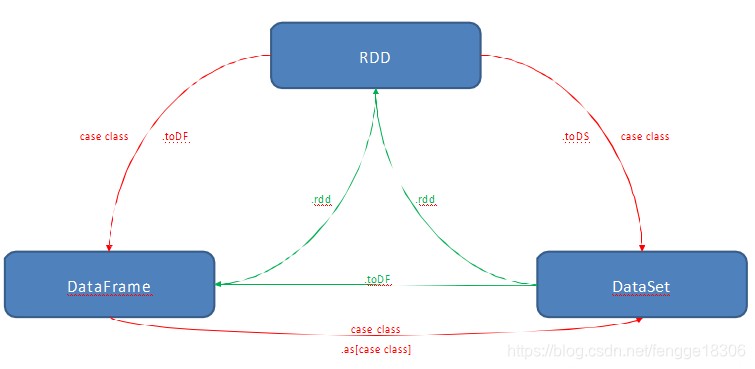
(4)三者之间的转换:
(1)RDD转换成DataFrame或DataSet,需先定义一个样例类,再将RDD与样例类进行关联,再调用.toDF方法或.toDS方法。
//定义一个样例类
case class Person(id:String,name:String,age:Int)
//把rdd与样例类进行关联
val personRDD=rdd1.map(x=>Person(x(0),x(1),x(2).toInt))
//把rdd转换成DataFrame
//需要手动导入隐式转换
import spark.implicits._
val personDF=personRDD.toDF
(2)而DataFrame或DataSet转换成RDD,只需调用.rdd方法即可。
val rdd1=dataFrame.rdd
val rdd2=dataSet.rdd
(3)DataFrame转换成DataSet:val dataSet=dataFrame.as[强类型]
(4)DataSet转换成DataFrame:val dataFrame=dataSet.toDF
4.3、构建DataSet(四种方法)
(1)通过sparkSession调用createDataset方法
ds=spark.createDataset(1 to 10) //scala集合
val ds=spark.createDataset(sc.textFile("/person.txt")) //rdd
(2)使用scala集合和rdd调用toDS方法
textFile("/person.txt").toDS
List(1,2,3,4,5).toDS
(3)把一个DataFrame转换成DataSet
dataSet=dataFrame.as[强类型]
(4)通过一个DataSet转换生成一个新的DataSet
List(1,2,3,4,5).toDS.map(x=>x*10)
智能推荐
Windows环境下redis重启_windowsredis怎么关闭-程序员宅基地
文章浏览阅读1.5w次,点赞4次,收藏26次。在redis安装的目录下打开cmd窗口输入以下命令打开启动redisredis-server redis.windows.conf如果提升Creating Server TCP listening socket *:6379: bind: No error,需要重启redis重启步骤:依次输入以下指令1.redis-cli -h 127.0.0.1 -p 6379 ..._windowsredis怎么关闭
一句话评述8个最热的原型工具-程序员宅基地
文章浏览阅读408次。早在十年前,要是提到原型工具,大概也只有笔纸和白板了。现如今,原型工具如雨后春笋般涌出,形式也各样,有在线的,也有桌面端的,让人目不暇接。今天小编就为大家吐血整理了今年夏天最热的8款原型工具。1. Mockplus链接:http://www.mockplus.cn一句话评述:简单易学的原型工具,适合追求效率的设计者。
chapter05_构建Spring Web应用程序_2_基本控制器-程序员宅基地
文章浏览阅读80次。控制器的类上方要添加 @Controller 注解用于声明,@Controller是@Component的子注解,便于自动扫描 @ComponentScan@RequestMapping注解(1) 可以添加在控制器的类上方,也可以添加在方法上方。当控制器在类上添加@RequestMapping注解时,这个注解会应用到控制器的所有方法上(2) va..._创建web应用chapter02
Java换行输出的5种方式-程序员宅基地
文章浏览阅读10w+次,点赞46次,收藏157次。///可以在格式化输出类型%n来指定输出一行,其效果等同于println///println()相当于printf(\n\n),即另起一行输出对应的参数后,再进行一次换行_java换行
Linux complete的使用记录_wait_for_completion_interruptible_timeout-程序员宅基地
文章浏览阅读1.5k次,点赞2次,收藏3次。之前使用complete的时候,程序总是wait_for_completion函数先执行,并且每次只有一个wait_for_completion在等待,因此对于complete函数也没有太多的深入了解。后面再次需要使用这个功能的时候,想到如果wait_for_completion函数在complete之后执行会出现上面问题?结论:如果wait_for_completion函数在complete之后执行,那么执行wait_for_completion函数时,添加就直接满足,不会再等待complete函数的_wait_for_completion_interruptible_timeout
matlab怎么显示当前文件夹和工作区_matlab显示工作区-程序员宅基地
文章浏览阅读4w次,点赞42次,收藏35次。1、第一步在我们的电脑上打开matlab,可以看到界面上目前没有显示当前文件夹和工作区,如下图所示:2、第二步我们点击主页右侧的布局,可以看到显示下的当前文件夹和工作区没有勾选上,如下图所示:3、第三步将显示下的当前文件夹和工作区进行勾选,如下图所示:4、第四步可以看到工作区和当前文件夹都显示出来了,如下图所示:5、第五步如果想关闭的话,再进行取消勾选就完成了,如下图所示:..._matlab显示工作区
随便推点
自动化毕设新颖课题-程序员宅基地
文章浏览阅读559次。 近期不少学弟学妹询问学长关于自动化专业相关的毕设选题,学长特意写下这篇文章以作回应!以下是学长亲手整理的自动化相关的毕业设计选题,都是经过学长精心审核的题目,适合作为毕设,难度不高,工作量达标,对毕设有任何疑问都可以问学长哦!相对容易工作量达标题目新颖,含创新点。_自动化毕设
ASP.NET MVC5+EF6+EasyUI 后台管理系统(45)-工作流设计-设计步骤-程序员宅基地
文章浏览阅读69次。系列目录步骤设计很重要,特别是规则的选择。我这里分为几个规则1.按自行选择(在起草时候自行选审批人,比较灵活)2.按上级(无需指定,当时需要知道用户的上司是谁,可以在职位管理设置,或者在用户表直接设置)3.按职位(选择职位,直接获得该职位的人员)4.按部门(按部门,直接获得该部分的人员)5.按人员(设置步骤时就指定人员)以上用户必须和部门,职位,上级有所关联,只要做...
Matlab给散点加上圆滑曲线_matlab将离散点连成光滑曲线-程序员宅基地
文章浏览阅读3.1w次,点赞31次,收藏172次。Matlab给散点加上圆滑曲线:clc,clear,close allx = [50,100,200,500,1000,2000,5000,10000,20000]y = [2.64,2.21,1.38,0.564,0.263,0.396,1.07,1.98,3.14]xx = 50:0.01:20000; % 插值yy = interp1(x,y,xx,'cubic');plot..._matlab将离散点连成光滑曲线
原型设计真的对用户体验那么重要吗?_原型设计到底需不需要-程序员宅基地
文章浏览阅读769次。用户体验,英文为User Experience,简称UE或UX,是用户在使用产品过程中建立起来的一种纯主观感受,是人们对于针对使用或期望使用的产品、系统或者服务的认知印象和回应。作为一个刚接触UX的新人,查资料时总会发现它与原型设计这个词紧密相连。原型设计又是什么东西?它真的对用户体验那么重要吗?为了对用户体验有更全面的了解,我又特地去查了下原型设计。首先,原型设计究竟是指什么?其次,它在用户体验_原型设计到底需不需要
laravel 5.6集成 swagger3 和swagger-ui 步骤_larveal 5.6 swagger-ui.css 加载出错-程序员宅基地
文章浏览阅读3.8k次。git地址packagist地址swagger在线edit安装swaggercomposer require zircote/swagger-php然后创建一个 swagger function getJson/** * @SWG\Swagger( * host="qs.com", * consumes={"multipart/form-data"}, * ..._larveal 5.6 swagger-ui.css 加载出错
在Visual C++中使用内联汇编_vc c++ asm-程序员宅基地
文章浏览阅读619次。在Visual C++中使用内联汇编目录: 文档内容:一、内联汇编的优缺点因为在Visual C++中使用内联汇编不需要额外的编译器和联接器,且可以处理Visual C++中不能处理的一些事情,而且可以使用在C/C++中的变量,所以非常方便。内联汇编主要用于如下场合:1.使用汇编语言写函数; 2.对速度要求非常高的代码; 3.设备驱动程_vc c++ asm