多线程线程数设置多少合适_多线程数量多少合适-程序员宅基地
前沿
大家都用过线程池,但是线程池数量设置为多少比较合理呢?
线程数的设置的最主要的目的是为了充分并合理地使用 CPU 和内存等资源,从而最大限度地提高程序的性能,因此让我们一起去探索吧!
首先要考虑到 CPU 核心数,那么在 Java 中如何获取核心线程数?
可以使用 Runtime.getRuntime().availableProcessor() 方法来获取(可能不准确,作为参考)
或者直接去服务器查看
温故为什么使用线程
场景
如果有两个任务需要处理,一个任务A,一个任务B
方案一:一个线程执行任务A和B,A执行完后,执行B
方案二:两个线程A和B去执行任务A 和 B,同时进行
哪个方案会快点?应该很多人会回答,肯定是方案二啊,多线程并行去处理任务A和B,肯定快啊。是这样吗?回答这个问题之前,先带着大家去回顾梳理一下。
线程执行
线程的执行,是由CPU进行调度的,一个CPU在同一时刻只会执行一个线程,我们看上去的线程A 和 线程B并发执行。
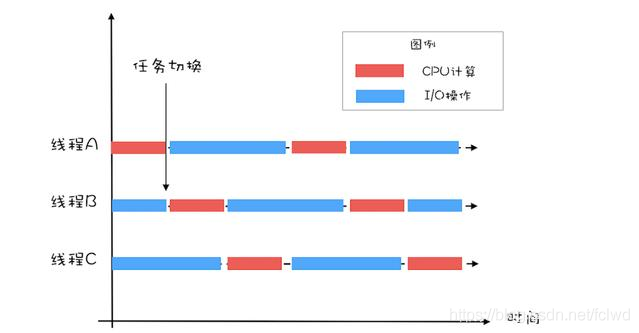
为了让用户感觉这些任务正在同时进行,操作系统利用了时间片轮转的方式,CPU给每个任务都服务一定的时间,然后把当前任务的状态保存下来,在加载下一任务的状态后,继续服务下一任务。任务的状态保存及再加载,这段过程就叫做上下文切换。
上下文切换过程是需要时间的;现在我们来看一下上面的问题,小伙伴们再看一下是哪个方案快呢?是不是有些小伙伴们会说方案一,因为不需要线程切换;方案二需要来回切换这两个线程,耗时会多点。
小伙伴们心中此时是不是会有疑惑,那为什么会有多线程?先不急,再往下看。
为什么要使用多线程
小伙伴想想在我们真实业务中,我们是什么流程?
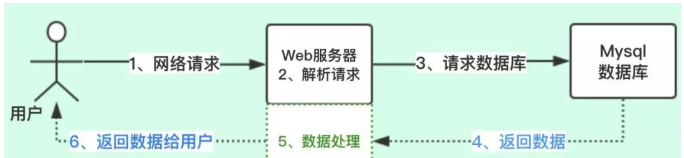
上图的流程:
1、先发起网络请求
2、Web服务器解析请求
3、请求后端的数据库获取数据
4、获取数据后,进行处理
5、把处理结果放回给用户
这个是我们处理业务的时候,常规的请求流程;我们看一下整个过程涉及到什么计算机处理。
1、网络请求----->网络IO
2、解析请求----->CPU
3、请求数据库----->网络IO
4、MySQL查询数据----->磁盘IO
5、MySQL返回数据----->网络IO
6、数据处理----->CPU
7、返回数据给用户----->网络IO
讲到这里,小伙伴们是不是感觉又不乱了,在真实业务中我们不单单会涉及CPU计算,还有网络IO和磁盘IO处理,这些处理是非常耗时的。如果一个线程整个流程是上图的流程,真正涉及到CPU的只有2个节点,其他的节点都是IO处理,那么线程在做IO处理的时候,CPU就空闲出来了,CPU的利用率就不高。
小伙伴们现在知道多线程的用处了吧,对,就是为了提升CPU利用率。
提升QPS/TPS
衡量系统性能如何,主要指标系统的(QPS/TPS)
QPS/TPS:每秒能够处理请求/事务的数量
并发数:系统同时处理的请求/事务的数量
响应时间:就是平均处理一个请求/事务需要时长
QPS/TPS = 并发数/响应时间
上面公式代表并发数越大,QPS就越大;所以很多人就会以为调大线程池,并发数就会大,也会提升QPS,所以才会出现一开始前言所说的,大多数人的误区。
其实QPS还跟响应时间成反比,响应时间越大,QPS就会越小。
虽然并发数调大了,就会提升QPS,但线程数也会影响响应时间,因为上面我们也提到了上下文切换的问题,那怎么设置线程数的呢?
如何设置线程数
那我们如何分配线程?我们提供一个公式:
最佳线程数目 = ((线程等待时间+线程CPU时间)/线程CPU时间 )* CPU数目
备注:这个公式也是前辈们分享的,当然之前看了淘宝前台系统优化实践的文章,和上面的公式很类似,不过在CPU数目那边,他们更细化了,上面的公式只是参考。不过不管什么公式,最终还是在生产环境中运行后,再优化调整。
我们继续上面的任务,我们的服务器CPU核数为4核,一个任务线程cpu耗时为20ms,线程等待(网络IO、磁盘IO)耗时80ms,那最佳线程数目:( 80 + 20 )/20 * 4 = 20。也就是设置20个线程数最佳。
从这个公式上面我们就得出,线程的等待时间越大,线程数就要设置越大,这个正好符合我们上面的分析,可提升CPU利用率。那从另一个角度上面说,线程数设置多大,是根据我们自身的业务的,需要自己去压力测试,设置一个合理的数值。
基础常规标准
在确认了核心数后,再去判断是 CPU 密集型任务还是 IO 密集型任务:
CPU 密集型任务:
比如像加解密,压缩、计算等一系列需要大量耗费 CPU 资源的任务,大部分场景下都是纯 CPU 计算。
IO 密集型任务:
比如像 MySQL 数据库、文件的读写、网络通信等任务,这类任务不会特别消耗 CPU 资源,但是 IO 操作比较耗时,会占用比较多时间。
1、CPU密集型:操作内存处理的业务,一般线程数设置为:CPU核数 + 1 或者 CPU核数*2。核数为4的话,一般设置 5 或 8
2、IO密集型:文件操作,网络操作,数据库操作,一般线程设置为:cpu核数 / (1-0.9),核数为4的话,一般设置 40
在知道如何判断任务的类别后,让我们分两个场景进行讨论:
CPU 密集型任务
对于 CPU 密集型计算,多线程本质上是提升多核 CPU 的利用率,所以对于一个 8 核的 CPU,每个核一个线程,理论上创建 8 个线程就可以了。
如果设置过多的线程数,实际上并不会起到很好的效果。此时假设我们设置的线程数量是 CPU 核心数的 2 倍,因为计算任务非常重,会占用大量的 CPU 资源,所以这时 CPU 的每个核心工作基本都是满负荷的,而我们又设置了过多的线程,每个线程都想去利用 CPU 资源来执行自己的任务,这就会造成不必要的上下文切换,此时线程数的增多并没有让性能提升,反而由于线程数量过多会导致性能下降。
因此,对于 CPU 密集型的计算场景,理论上线程的数量 = CPU 核数就是最合适的,不过通常把线程的数量设置为CPU 核数 +1,会实现最优的利用率。即使当密集型的线程由于偶尔的内存页失效或其他原因导致阻塞时,这个额外的线程也能确保 CPU 的时钟周期不会被浪费,从而保证 CPU 的利用率。
如下图就是在一个 8 核 CPU 的电脑上,通过修改线程数来测试对 CPU 密集型任务(素数计算)的性能影响。
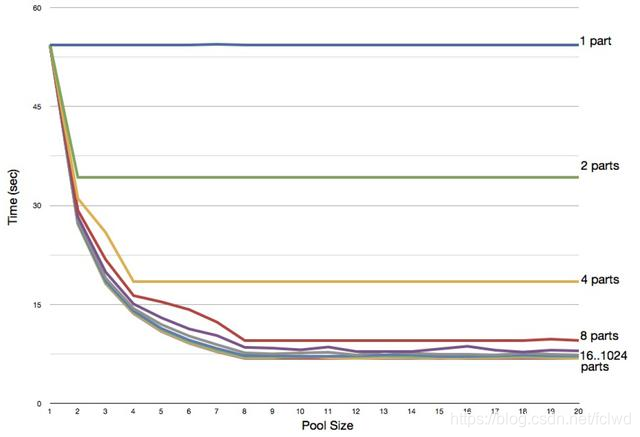
可以看到线程数小于 8 时,性能是很差的,在线程数多于处理器核心数对性能的提升也很小,因此可以验证公式还是具有一定适用性的。
除此之外,我们最好还要同时考虑在同一台机器上还有哪些其他会占用过多 CPU 资源的程序在运行,然后对资源使用做整体的平衡。
IO 密集型任务
对于 IO 密集型任务最大线程数一般会大于 CPU 核心数很多倍,因为 IO 读写速度相比于 CPU 的速度而言是比较慢的,如果我们设置过少的线程数,就可能导致 CPU 资源的浪费。而如果我们设置更多的线程数,那么当一部分线程正在等待 IO 的时候,它们此时并不需要 CPU 来计算,那么另外的线程便可以利用 CPU 去执行其他的任务,互不影响,这样的话在任务队列中等待的任务就会减少,可以更好地利用资源。
对于 IO 密集型计算场景,最佳的线程数是与程序中 CPU 计算和 IO 操作的耗时比相关的,《Java并发编程实战》的作者 Brain Goetz 推荐的计算方法如下:
线程数 = CPU 核心数 * (1 + IO 耗时/ CPU 耗时)
通过这个公式,我们可以计算出一个合理的线程数量,如果任务的平均等待时间长,线程数就随之增加,而如果平均工作时间长,也就是对于我们上面的 CPU 密集型任务,线程数就随之减少。可以采用 APM 工具统计到每个方法的耗时,便于计算 IO 耗时和 CPU 耗时。
在这里引用Java并发编程实战中的图,方便大家更容易理解:
还有一派的计算方式是《Java虚拟机并发编程》中提出的:
线程数 = CPU 核心数 / (1 - 阻塞系数)
其中计算密集型阻塞系数为 0,IO 密集型阻塞系数接近 1,一般认为在 0.8 ~ 0.9 之间。比如 8 核 CPU,按照公式就是 2 / ( 1 - 0.9 ) = 20 个线程数
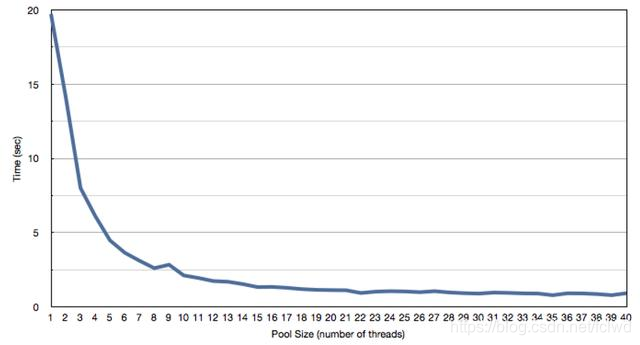
上图是 IO 密集型任务的一个测试,是在双核处理器上开不同的线程数(从 1 到 40)来测试对程序性能的影响,可以看到线程池数量达到 20 之后,曲线逐渐水平,说明开再多的线程对程序的性能提升也毫无帮助。
太少的线程数会使得程序整体性能降低,而过多的线程也会消耗内存等其他资源,所以如果想要更准确的话,可以进行压测,监控 JVM 的线程情况以及 CPU 的负载情况,根据实际情况衡量应该创建的线程数,合理并充分利用资源。
同时,有很多线程池的应用,比如 Tomcat、Redis、Jdbc 等,每个应用设置的线程数也是不同的,比如 Tomcat 为流量入口,那么线程数的设置可能就要比其他应用要大。
总结
通过对线程数设置的探究,我们可以得知线程数的设置首先和 CPU 核心数有莫大关联,除此之外,我们需要根据任务类型的不同选择对应的策略,具体的怎么设置要根据业务上需要/服务器的环境/QPS/TPS等指标等等有关系。
线程的平均工作时间所占比例越高,就需要越少的线程;线程的平均等待时间所占比例越高,就需要越多的线程;增强cpu的使用率。
针对不同的程序,进行对应的实际测试就可以得到最合适的选择。
智能推荐
写入文件D:上课软件\glib-2.0.dll时出错。请确认您有访问该自录的权限。 直接删除vm,内存不用删_写入glib-2.0.dll时出错-程序员宅基地
文章浏览阅读1.1w次,点赞6次,收藏22次。写入文件D:上课软件\glib-2.0.dll时出错。请确认您有访问该自录的权限。 直接删除vm,内存不用删直接点修改,然后然后打开安装包,重新安装就ok啦!这个是我的VM安装包:(内附注册码器)链接:https://pan.baidu.com/s/18WgJTXAu_-5SrXMJqoEeOg提取码:ub2c第一篇博客..._写入glib-2.0.dll时出错
【Java】spring mvc简单项目示例_javaspring,mvc项目案例-程序员宅基地
文章浏览阅读3.1k次。但凡进行java网站开发的人,都有学过spring mvc的开发。下面用一个获取当前时间和时区的简单示例,展现一下怎么用myeclipse 10,来创建一个spring mvc项目。 1.打开MyEclipse-->File-->New-->Web Project,在打开的对话框里面输入Project Name为GetTimeDemo,点击Finis..._javaspring,mvc项目案例
SpringBoot - @Import注解使用详解_springboot import-程序员宅基地
文章浏览阅读3.4k次。通过导入的方式,来实现把实例加入Spring容器中的功能,相当于Spring xml配置文件中的 标签。_springboot import
[tensorflow+pycharm]Skipping registering GPU devices...-程序员宅基地
文章浏览阅读1w次,点赞7次,收藏55次。用Pycharm跑VGG16报了上面的警告,还提示“Skipping registering GPU devices…”,意思是你的代码可以运行,但不使用GPU跑的,而是CPU!心痛啊!明明已经配置了tensorflow、cuda等等,看来还是没有配置好,那就继续配置吧!发现问题还是自己的tensorflow版本和cuda版本不对应导致的,查看电脑的显卡驱动版本,和cuda版本解决问题1 打开控制面板,点击“硬件和声音”2 点击“DVIDIA控制面板”3 点击“系统信息”4 在这里可以._skipping registering gpu devices...
Java多态(动态绑定)的底层原理:虚函数表_java 虚函数表-程序员宅基地
文章浏览阅读2.6k次,点赞2次,收藏13次。文章目录C++的虚函数和纯函数的区别虚函数表虚函数表的构造过程虚函数的调用过程java多态的实现是通过itable(interface method table:接口方法表), vtable(virtual method table:虚方法表)来实现方法的准确跳转。接口方法表和虚方法表的原理和C++的虚函数表类似。C++的虚函数和纯函数的区别纯函数: 在基类中只进行声明,不进行具体实现,而在子类进行具体实现,类似于java接口中的方法。注意: C++允许多重继承,是通过抽象类来实现java中接口作_java 虚函数表
webpack 热加载原理探索_webpack热加载原理-程序员宅基地
文章浏览阅读6.2k次。前言在使用 dora 作为本地 server 开发一个 React 组件的时候,默认使用了 hmr 插件。每次修改代码后页面直接更新,不需要手动 F5 ,感觉非常惊艳,这体验一旦用上后再也回不去了。当时的 hot reload 实际上配置的是 live reload,也就是每次修改页面刷新。开发小组件每次更新也蛮快的,但如果一个应用应该使用上真正的 hot reload 才比较靠谱。所..._webpack热加载原理
随便推点
错误解决ModuleNotFoundError: No module named ‘imutils‘_modulenotfounderror: no module named 'imutils-程序员宅基地
文章浏览阅读5.4k次,点赞3次,收藏7次。ModuleNotFoundError: No module named 'imutils’解决办法:打开cmd激活你的环境:activate tensorflow安装: pip install imutils安装完成!_modulenotfounderror: no module named 'imutils
插件系列 => 时间格式化 DayJs 多少时间之前_vant4 dayjs-程序员宅基地
文章浏览阅读693次,点赞2次,收藏3次。1.创建timeFilter.js文件import Vue from 'vue';import dayjs from 'dayjs';import 'dayjs/locale/zh-cn';import relativeTime from 'dayjs/plugin/relativeTime';dayjs.extend(relativeTime);dayjs.locale('zh-cn');// 全局过滤器:处理相对时间Vue.filter('relativeTime', (value)_vant4 dayjs
查看Linux磁盘及内存占用情况_linux占用-程序员宅基地
文章浏览阅读10w+次,点赞54次,收藏333次。查看磁盘使用情况: df -k:以KB为单位显示磁盘使用量和占用率 df -m:以Mb为单位显示磁盘使用量和占用率 df –help:查看更多df命令及使用方法 查看内存占用情况: 1.top PID:当前运行进程的ID USER:进程属主 PR:每个进程的优先级别 NInice:反应一个进程“优先级”状态的值,其取值范围是-20至19,一 共40个级别。这个值_linux占用
java编程时无法找到类_Java无法访问类,找不到类文件-程序员宅基地
文章浏览阅读2.7k次。当我尝试在IntelliJ中创建项目时,我在此行收到以下错误:Sentence sent = new Sentence();sent.emptySegments();错误:Error:(151, 10) java: cannot access javax.xml.bind.RootElementclass file for javax.xml.bind.RootElement not foundS..._java无法访问 找不到类文件
HBase环境搭建_hbase搭建-程序员宅基地
文章浏览阅读6.1k次,点赞3次,收藏19次。1.一共需要搭建3台节点,1个主节点2个从节点。在安装之前需要配置好虚拟机网络静态IP,同步时间,关闭防火墙和使用Linux SSH(安全Shell)。2.安装java,Hadoop,zookeeper并配置环境变量,修改配置文件安装hbase 配置环境变量,修改配置文件将以上所有配置好的文件分发给其他两个节点拷贝命令如下scp -r (要拷贝的文件路径名称) 目的地用户@主机:目的地路径名称..._hbase搭建
UVa 11105 - Semi-prime H-numbers(筛选法)-程序员宅基地
文章浏览阅读1.4k次。类似于筛选素数的方法,枚举前缀和即可。_uva 11105